数据分析必备手册-Seaborn详细教程
seaborn库安装:官方文档: 关系绘图relplot1. 基本使用:2. 添加hue参数:3. 添加col和row参数:4. 指定具体的列:5. 绘制折线图: 分类绘图1. 分类散点图:1.1. stripplot:1.2. swarmplot:1.3. 横向分类散点图: 2. 分类分布图:2.1. 箱线图:2.2. 小提琴图: 3. 分类统计图:3.1. 条形图:3.2. 柱状图:3.3. 点线图: 分布绘图单变量分布:二变量分布:散点图:六边形图:jointplot其他常用参数: 成对绘图(pairplot): 线性回归绘图FacetGrid结构图普通的Axes绘图:FacetGrid基本使用:绘制多个图形:添加颜色观察字段:设置每个图形的尺寸:设置图例:设置标题:设置坐标轴:`g.set`方法:`g.fig`: 样式风格设置自带的样式:风格设置函数:1. `sns.axes_style`: 2. `sns.set_style()`:3. `sns.set`: 调色盘设置定性调色盘:1. 默认调色盘:2. hls圆形颜色系统:3. 分类颜色:4. 用xkcd颜色: 连续的颜色盘:离散的色盘:官方文档: Seaborn实例1. 有一组温度数据,按照时间和温度绘制折线图2. 有以下国家数据,根据时间绘制条形图3. 有链家网的数据,请按照以下要求实现绘图
seaborn库
Seaborn是一种基于matplotlib的图形可视化库。他提前已经定义好了一套自己的风格。然后也封装了一系列的方便的绘图函数,之前通过matplotlib需要很多代码才能完成的绘图,使用seaborn可能就是一行代码的事情。总结一句话:使用seaborn绘图比matplotlib更好看,更简单!
安装:
通过pip:pip install seaborn。通过anaconda: conda install seaborn。 官方文档:
https://seaborn.pydata.org/tutorial.html
Seaborn用起来还是很方便!
关系绘图
relplot
这个函数功能非常强大,可以用来表示多个变量之间的关联关系。默认情况下是绘制散点图,也可以绘制线性图,具体绘制什么图形是通过kind参数来决定的。
实际上以下两个函数就是relplot的特例:
scatterplot:relplot(kind='scatter')。lineplot:relplot(kind='line')。 1. 基本使用:
import seaborn as snstips = sns.load_dataset("tips",cache=True)sns.relplot(x="total_bill",y="tip",data=tips)效果图如下:
2. 添加hue参数:
hue参数是用来控制第三个变量的颜色显示的。比如我们在以上图的基础之上体现出星期几的参数,那么可以通过以下代码来实现:
sns.relplot(x="total_bill",y="tip",hue="day",data=tips)效果图如下:
3. 添加col和row参数:
col和row,可以将图根据某个属性的值的个数分割成多列或者多行。比如在以上图的基础之上我们想要把Lunch(午餐)和Dinner(晚餐)分割成两个图来显示,那么可以通过以下代码来实现:
sns.relplot(x="total_bill",y="tip",hue="day",col="time",data=tips)效果图如下:
也可以再在row上添加一个新的变量,比如把性别按照行显示出来,代码如下:
sns.relplot(x="total_bill",y="tip",hue="day",col="time",row="sex",data=tips)效果图如下:
4. 指定具体的列:
有时候我们的图有很多,默认情况下会在一行中全部展示出来,那么我们可以通过col_wrap来指定具体多少列。示例代码如下:
sns.relplot(x="total_bill",y="tip",col="day",col_wrap=2,data=tips)效果图如下: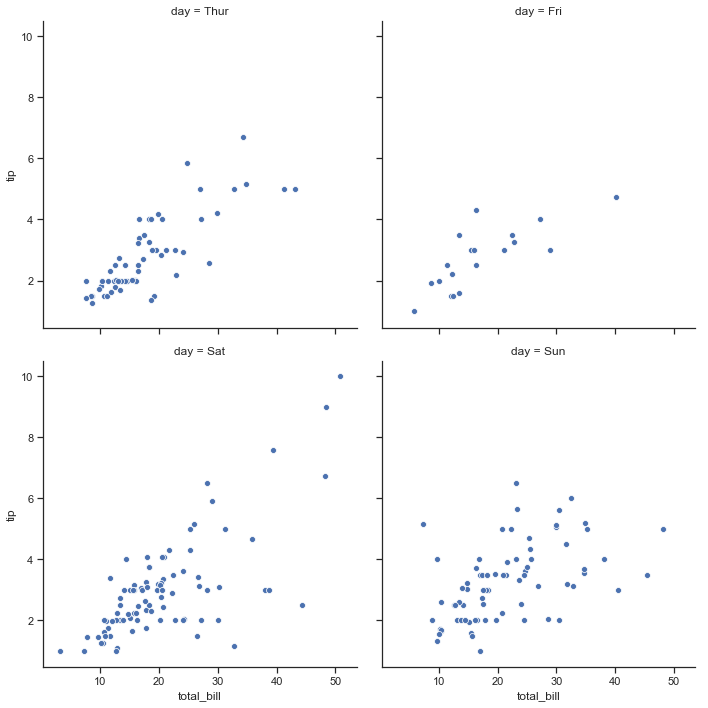
5. 绘制折线图:
relplot通过设置kind="line"可以绘制折线图。并且他的功能比plt.plot更加强大。plot只能指定具体的x和y轴的数据(比如x轴是N个数,y轴也必须为N个数)。而relplot则可以在自动在两组数据中进行计算绘图。示例代码如下:
fmri = sns.load_dataset("fmri")sns.relplot(x="timepoint",y="signal",kind="line",data=fmri)效果图如下: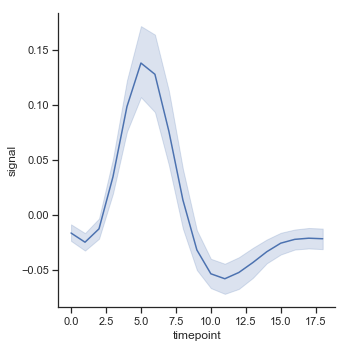
当然也可以添加其他的参数,用来控制整个图的样式和结构。示例代码如下:
# 设置hue为event,就会根据event来绘制不同的颜色# 设置col为region,就会根据region值的个数来绘制指定个数的图# 设置style为event,就会根据event来设置线条的样式sns.relplot(x="timepoint",y="signal",kind="line",hue="event",col="region",style="event",data=fmri)效果图如下: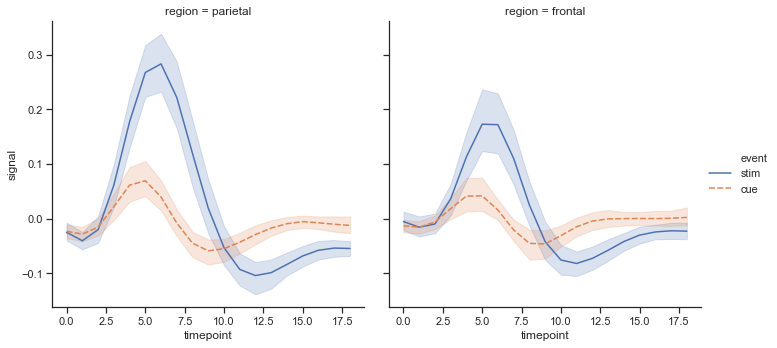
分类绘图
分类图的绘制,采用的是sns.catplot来实现的。cat是category的简写。这个方法默认绘制的是分类散点图,如果想要绘制其他类型的图,同样也是通过kind参数来指定。并且分类绘图中,分成分类散点图,分类分布图,分类统计图。
1. 分类散点图:
分类散点图比较适合数据量不是很多的情况,他是用catplot来实现,但是也有以下两个特别的方法。
stripplot():catplot(kind="strip"),默认的。swarmplot():catplot(kind="swarm")。 1.1. stripplot:
示例代码如下:
sns.catplot(x="day",y="total_bill",data=tips,hue="sex")示例图如下: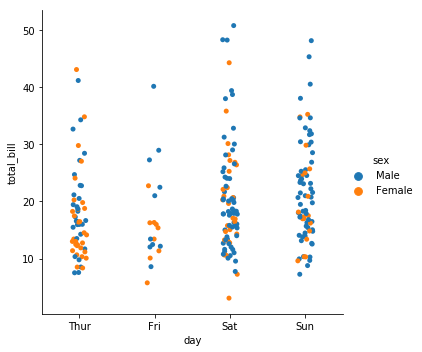
1.2. swarmplot:
以上图展示的是按照星期几的分类散点图,看起来这些点有点重合,如果想要散开来,那么可以使用catplot(kind="swarm")。示例代码如下:
sns.catplot(x="day",y="total_bill",kind="swarm",data=tips,hue="sex")
catplot方法不能使用size和style参数。
1.3. 横向分类散点图:
想要将垂直的分类散点图变成横向的,只需要把x和y对应的值进行互换即可。
sns.catplot(y="day",x="total_bill",kind="swarm",data=tips,hue="sex")效果图如下:
2. 分类分布图:
分类分布图,主要是根据分类来看,然后在每个分类下数据的分布情况。也是通过catplot来实现,以下三个方法分别是不同的kind参数:
boxplot():catplot(kind="box")。violinplot():catplot(kind="violin")。 2.1. 箱线图:
示例代码如下:
athletes = pd.read_csv("athlete_events.csv")countries = { 'CHN':'中国', 'JPN':"日本", 'KOR':'韩国', 'USA':"美国", 'CAN':"加拿大", 'BRA':"巴西", 'GBR':"英国", 'FRA':"法国", 'ITA':"意大利", 'ETH':"埃塞俄比亚", 'KEN':"肯尼亚", 'NIG':"尼日利亚",}plt.rcParams['font.sans-serif'] = ['FangSong']# print(plt.rcParams.keys())need_athletes = athletes[athletes['NOC'].isin(list(countries.keys()))]g = sns.catplot(x="NOC",y="Height",data=need_athletes,kind="box",hue="Sex")g.fig.set_size_inches(20,5)g.set_xticklabels(list(countries.values()))效果图如下: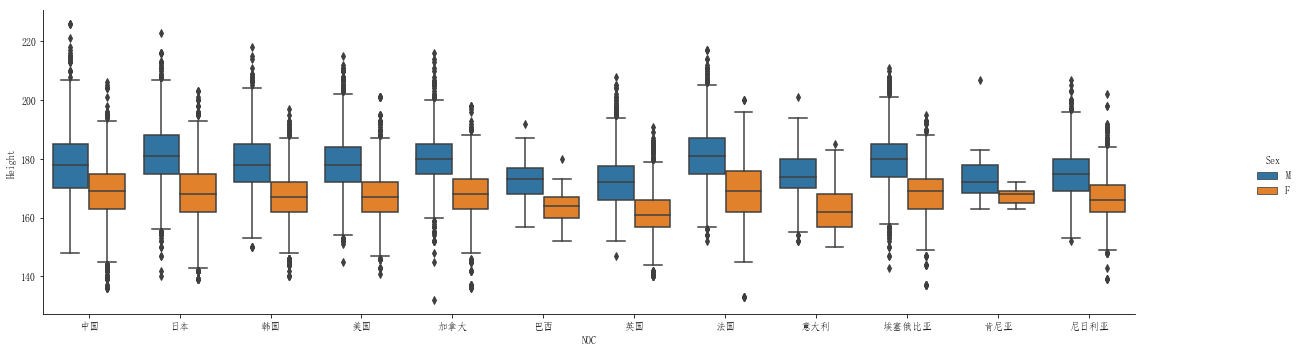
2.2. 小提琴图:
小提琴实际上就是两个对称的核密度曲线合并起来,然后中间是一个箱线图(也可以为其他图)组成的。通过小提琴图可以看出数据的分布情况。
示例代码如下:
sns.catplot(x="day",y="total_bill",data=tips,kind="violin",hue="sex",split=True)效果图如下: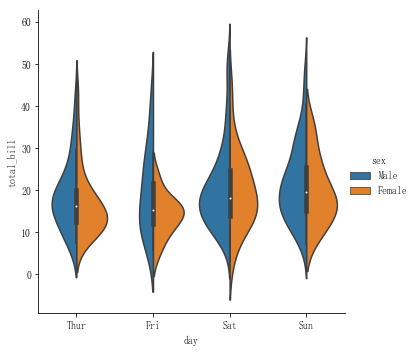
小提琴的中间默认绘制的是箱线图,也可以修改为其他类型的。可以通过inner参数修改,这个参数有以下几个选项:
box:默认的,箱线图。
quartile:四分位数。上下四分位数加中位数。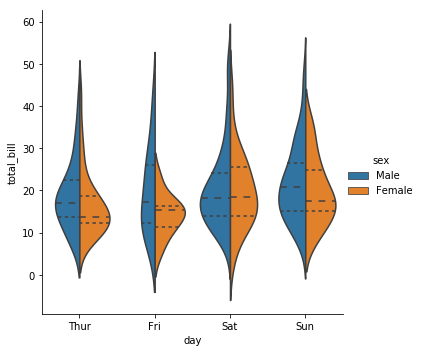
point:散点。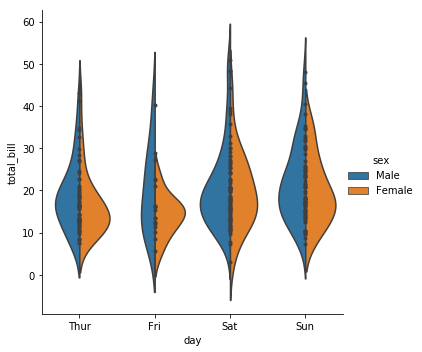
stick:线条。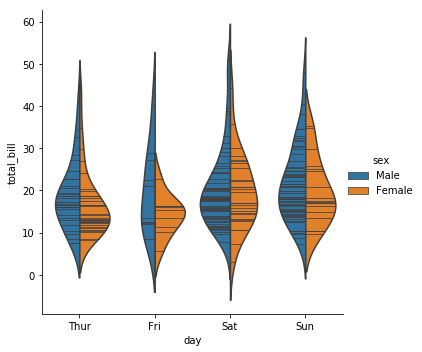
3. 分类统计图:
分类统计图,则是根据分类,统计每个分类下的数据的个数或者比例。有以下几种方式:
barplot():catplot(kind="bar")。pointplot():catplot(kind="point")。countplot():catplot(kind="count")。 3.1. 条形图:
seaborn中的条形图具有统计功能,可以统计出比例,平均数,也可以按照你想要的统计函数来统计。
示例代码如下:
1. 统计平均数:
# 统计星期三到星期天的消费总额的平均数sns.catplot(x="day",y="total_bill",data=tips,kind="bar")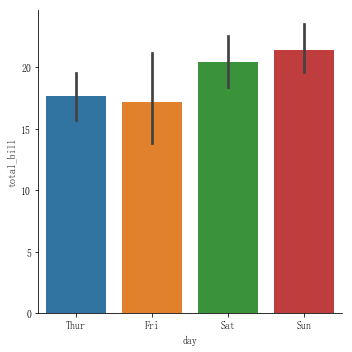
2. 统计比例:
# 统计男女中获救的比例 sns.catplot(data=titanic,kind="bar",x="sex",y="survived")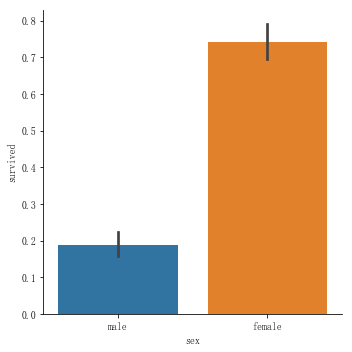
3. 自定义统计函数:
# 自定义统计函数,统计出每个性别下获救的人数 sns.barplot(x="sex",y="survived",data=titanic,estimator=lambda values:sum(values))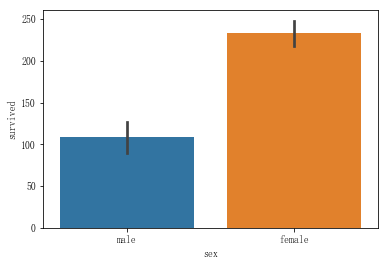
3.2. 柱状图:
柱状图是专门用来统计某个单一变量出现数量的图形。示例代码如下:
sns.catplot(x="sex",data=titanic,kind="count")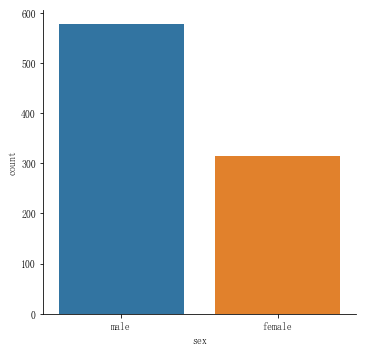
也可以通过使用hue参数来指定分组:
sns.catplot(x="day",kind="count",data=tips,hue="sex")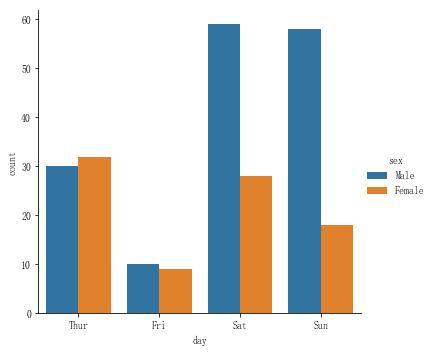
3.3. 点线图:
点线图可以非常方便的看到变量之间的趋势变化。示例代码如下:
sns.catplot(x="sex",y="survived",data=titanic,kind="point",hue="class")效果图如下: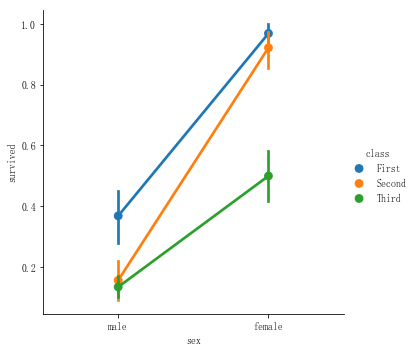
分布绘图
分布绘图分为单一变量分布,多变量分布,成对绘图。以下进行讲解。
单变量分布:
单一变量主要就是通过直方图来绘制。在seaborn中直方图的绘制采用的是distplot,其中dist是distribution的简写,不是histogram的简写。
示例代码如下:
sns.set(color_codes=True)titanic = sns.load_dataset("titanic")titanic = titanic[~np.isnan(titanic['age'])]sns.distplot(titanic['age'])效果图如下: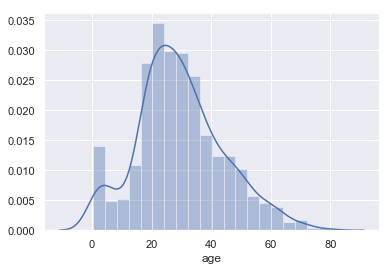
有以下常用参数:
kde(核密度曲线):这个代表是否要显示kde曲线,默认是显示的,如果显示kde曲线,那么y轴表示的就是概率,而不是数量。也可以设置为False关掉。 示例代码如下:
sns.distplot(titanic['age'],kde=False)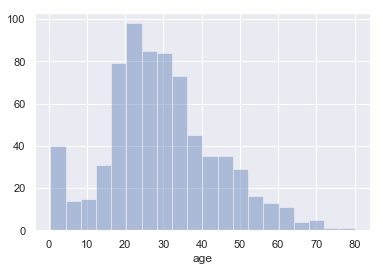
bins:代表这个直方图显示的数量。也可以通过自己设置。 示例代码如下:
sns.distplot(titanic['age'],bins=30)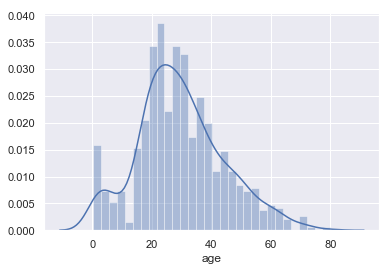
rug:代表是否需要显示底部的胡须下线,下面的胡须线越密集的地方,说明数据量越多。 示例代码如下:
sns.distplot(titanic['age'],rug=True)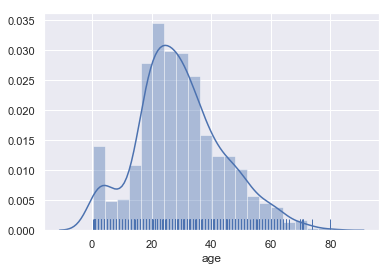
二变量分布:
多变量分布图可以看出两个变量之间的分布关系。一般都是采用多个图进行表示。
多变量分布图采用的函数是jointplot。
散点图:
示例代码如下:
tips = sns.load_dataset("tips")g = sns.jointplot(x="total_bill", y="tip", data=tips)效果图如下:
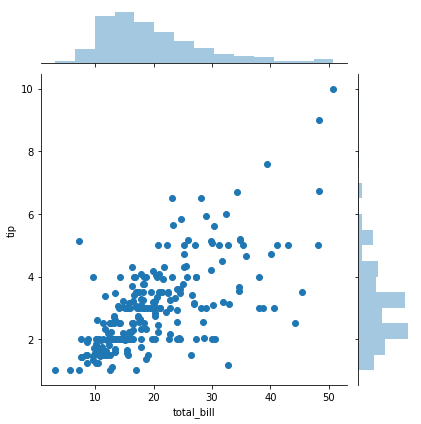
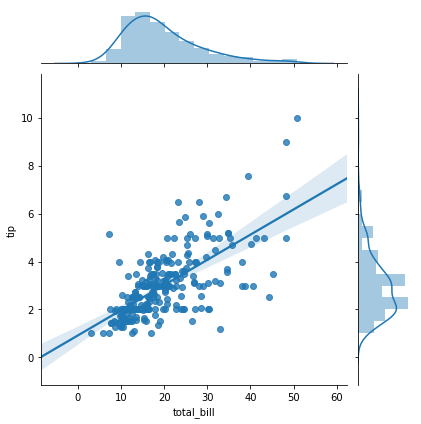
通过设置kind='reg'可以设置回归绘图和核密度曲线。
示例代码如下:
g = sns.jointplot(x="total_bill", y="tip", data=tips,kind="reg")效果图如下:
六边形图:
对于一些数据量特别大的数据,用散点图不太利于观察,比如查看奥运会中国运动员的身高和体重分布情况,如果用散点图将会是以下的效果:
athletes = pd.read_csv("athlete_events.csv")china_athletes = athletes[athletes['NOC']=='CHN']sns.jointplot(x="Height",y="Weight",data=china_athletes)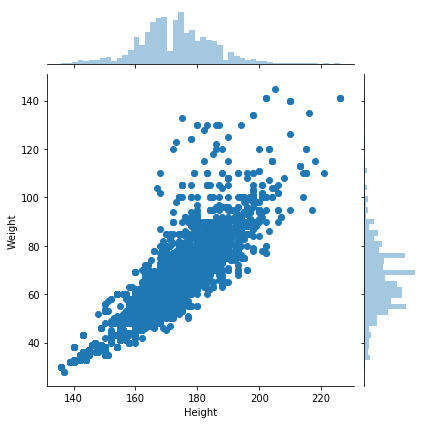
针对这种数据量比较大的情况,可以采用六边形图来绘制,也就是将之前的散点变成六边形,六边形有一个区间大小,之前这些点落在这个六边形中越多颜色越深。
示例代码如下:
sns.jointplot(x="Height",y="Weight",data=china_athletes,kind="hex")默认情况,在x轴的区间内,可以展示100个六边形,所以默认情况下六边形的尺寸会比较小,如果想要展示得更大一点,那么可以设置减少六边形的个数,通过gridsize设置。
示例代码如下:
sns.jointplot(x="Height",y="Weight",data=china_athletes,kind="hex",gridsize=20)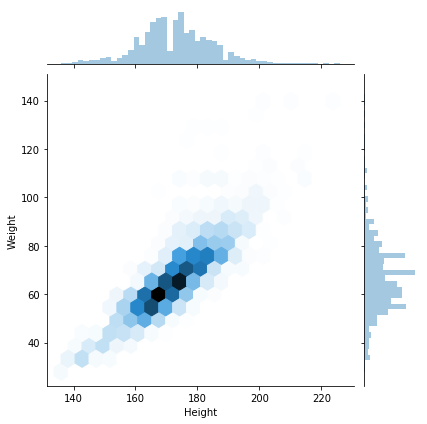
更多请参考:
jointplot其他常用参数:
x,y,data:绘制图的数据。kind:scatter、reg、resid、kde、hex。color:绘制元素的颜色。height:图的大小,图会是一个正方形。ratio:主图和副图的比例,只能为一个整形。space:主图和副图的间距。dropna:是否需要删除x或者y值中出现了NAN的值。marginal_kws:副图的一些属性,比如设置bins、rug等。 成对绘图(pairplot):
pairplot可以把某个数据集中某几个字段之间的关系图一次性绘制出来。比如iris鸢尾花数据,我们想要看到petal_width、petal_height、sepal_width以及sepal_height之间的关系,那么我们就可以通过pairplot来绘制。
示例代码如下:
sns.pairplot(iris,vars=['sepal_length',"sepal_width",'petal_length','petal_width'])效果图如下: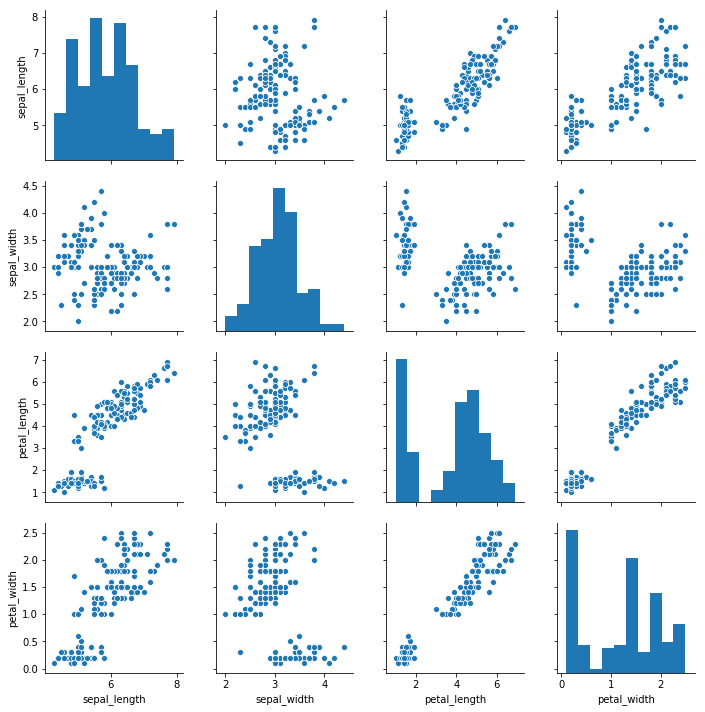
默认情况下,对角线的图(x和y轴的列相同)是直方图,其他地方的图是散点图,如果想要修改这两种图,可以通过diag_kind和kind来实现。
其中这两个参数可取的值为:
diag_kind:auto, hist, kde。kind:scatter, reg。 示例代码如下:
sns.pairplot(iris,vars=['sepal_length',"sepal_width",'petal_length','petal_width'],diag_kind="kde",kind="reg")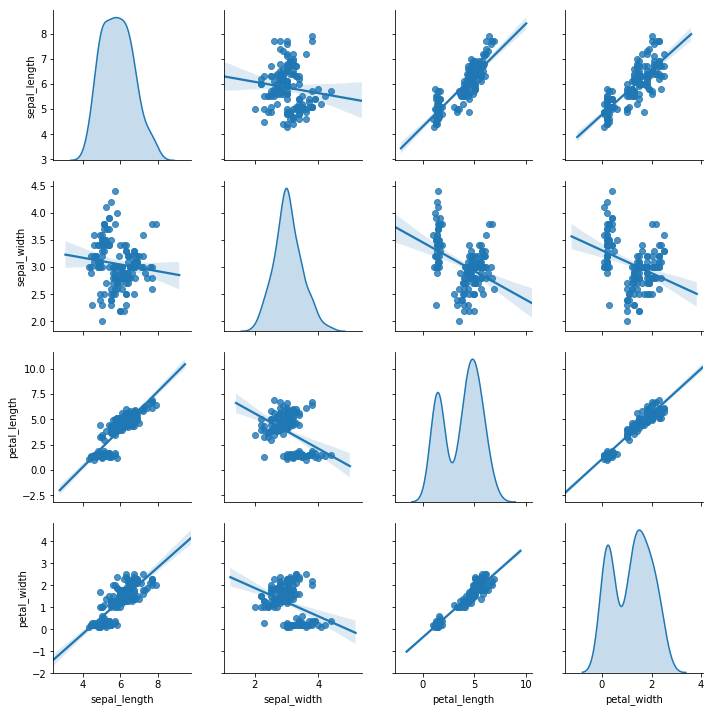
线性回归绘图
线性回归图可以帮助我们看到数据的关系趋势。在seaborn中可以通过regplot和lmplot两个函数来实现。regplot的x和y可以为Numpy数组、Series等变量。而lmplot的x和y则必须为字符串,并且data的值不能为空:
regplot(x,y,data=None)。lmplot(x,y,data)。 示例代码如下:
sns.lmplot(x="total_bill",y="tip",data=tips)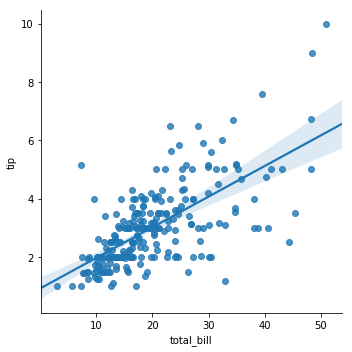
也可以通过regplot来实现。示例代码如下:
sns.regplot(x=tips["total_bill"],y=tips["tip"])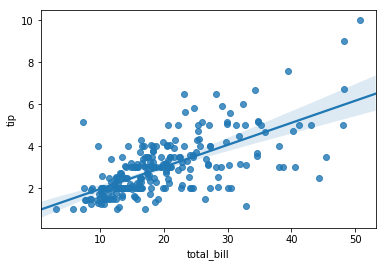
更多请参考文档:https://seaborn.pydata.org/tutorial/regression.html
FacetGrid结构图
之前我们在绘图的时候,学了relplot、catplot、lmplot等,这些函数可以通过col、row等在一个Figure中绘制多个图。这些函数之所以有这些功能,是因为他们的底层使用了FacetGrid来组装这些图形。今天我们就来学习FacetGrid的使用。
普通的Axes绘图:
在学习FacetGrid绘图之前,先来了解一下,实际上seaborn的绘图函数中也有大量的直接使用Axes进行绘图的,凡是函数名中已经明确显示了这个图的类型,这种图都是使用Axes绘图的。
比如sns.scatterplot、sns.lineplot、sns.barplot等。Axes绘图可以直接使用之前matplotlib的一些方式设置图的元素。
示例代码如下:
fig,[ax1,ax2] = plt.subplots(2,1,figsize=(10,10))sns.scatterplot(x="total_bill",y="tip",data=tips,ax=ax1)sns.barplot(x="day",y="total_bill",data=tips,ax=ax2)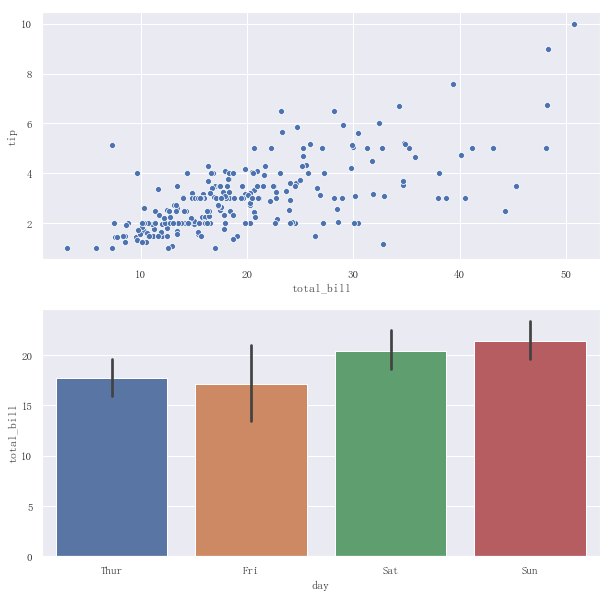
FacetGrid基本使用:
先创建一个FacetGrid对象,然后再调用这个对象的map方法。其中map方法的第一个参数是一个函数,后续map将调用这个函数来绘制图形。后面的参数就是传给这个函数的参数。
示例代码如下:
tips = sns.load_dataset("tips")g = sns.FacetGrid(tips)g.map(plt.scatter,"total_bill","tip")效果图如下: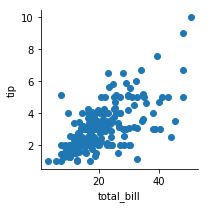
其中第一个参数是可以绘制Axes图,并且可以接收color参数的函数。可以取的值如下:
| 参数 | 描述 | 对应使用了FacetGrid函数 |
|---|---|---|
plt.plot/sns.lineplot | 绘制折线图 | sns.relplot(kind="line") |
plt.hexbin | 绘制六边形图形 | sns.jointplot(kind="hex") |
plt.hist | 绘制直方图 | sns.distplot |
plt.scatter/sns.scatterplot | 绘制散点图 | sns.relplot(kind="scatter") |
sns.stripplot | 绘制分类散点图 | sns.catplot(kind="strip") |
sns.swarmplot | 绘制散开来的分类散点图 | sns.catplot(kind="swarm") |
sns.boxplot | 绘制箱线图 | sns.catplot(kind="box") |
sns.violinplot | 绘制小提琴图 | sns.catplot(kind="violin") |
sns.pointplot | 绘制点线图 | sns.catplot(kind="point") |
sns.barplot | 绘制条形图 | sns.catplot(kind="bar") |
sns.countplot | 绘制数量柱状图 | sns.catplot(kind="count") |
sns.regplot | 绘制带有回归线的散点图 | sns.lmplot |
绘制多个图形:
FacetGrid可以通过col和row参数,来在一个Figure上绘制多个图形,其中col和row都是数据集中的某个列的名字。只要指定这个名字,那么就会自动的按照指定列的值的个数绘制指定个数的图形。
示例代码如下:
g = sns.FacetGrid(tips,col="day",col_wrap=2)g.map(sns.regplot,"total_bill","tip")效果图如下: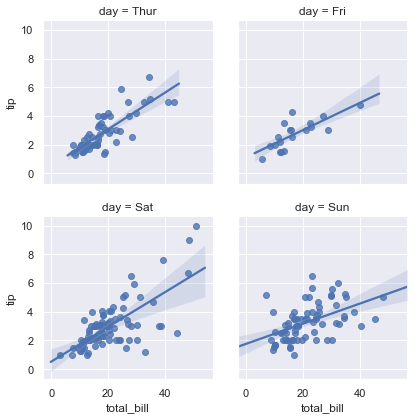
添加颜色观察字段:
可以通过添加hue参数来控制每个图中元素的颜色来观察其他的字段。
示例代码如下:
g = sns.FacetGrid(tips,col="day",hue="time")g.map(sns.regplot,"total_bill","tip")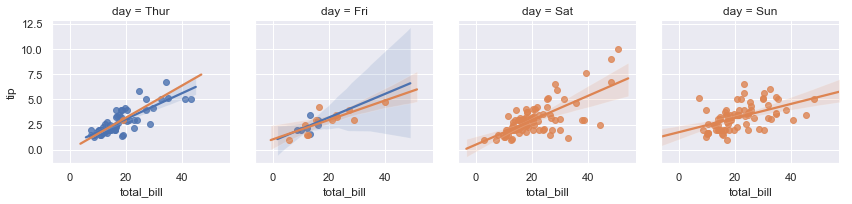
也可以通过hue_kws参数来添加hue散点的属性,比如设置散点的样式等。
设置每个图形的尺寸:
使用FacetGrid绘制出图形后,有时候我们想设置每个图形的尺寸或者是宽高比,那么我们可以通过在FacetGrid中设置height和aspect来实现,其中height表示的是每个图形的尺寸(默认是宽高一致),aspect表示的是宽度/高度的比例。
示例代码如下:
g = sns.FacetGrid(tips,col="day",row="time",height=10,aspect=2)g.map(sns.regplot,"total_bill","tip")效果图如下: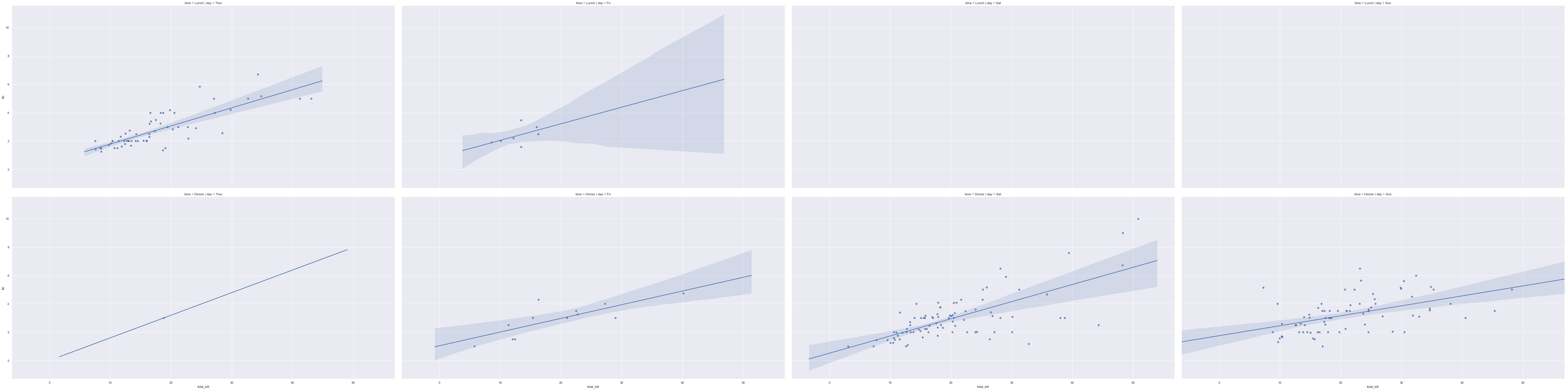
设置图例:
默认情况下,不会添加图例,我们可以通过g.add_legend()来添加图例。
示例代码如下:
g = sns.FacetGrid(tips,col="day",hue="time")g.map(sns.regplot,"total_bill","tip")g.add_legend()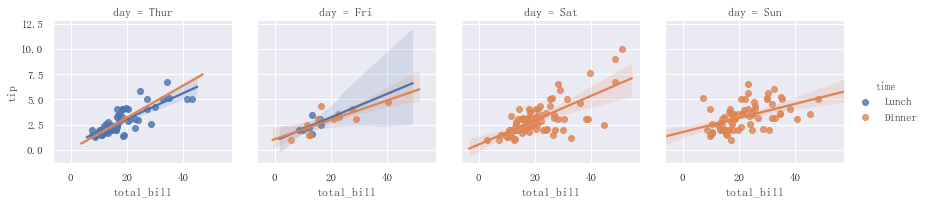
另外还可以:
通过title来控制图例的标题。通过label_order来控制图例元素的顺序。 示例代码如下:
sns.set(rc={"font.sans-serif":"simhei"})g3 = sns.FacetGrid(tips,col="day",hue="time")g3.map(plt.scatter,"total_bill","tip")new_labels = ['午餐','晚餐']g3.add_legend(title="时间")for t,l in zip(g3._legend.texts,new_labels): t.set_text(l)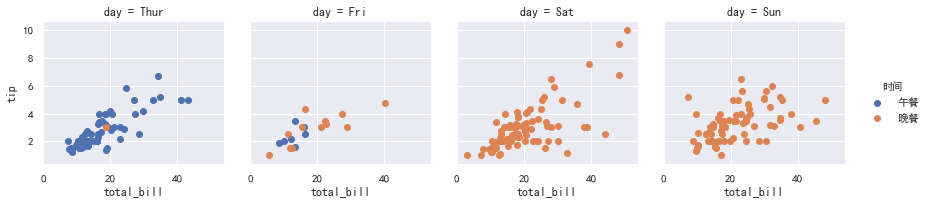
设置标题:
设置标题可以通过g.set_titles(template=None,row_template=None,col_template=None)来实现,这三个参数分别代表的意义如下:
template:给图设置标题,其中有{row_var}:绘制每行图像的名称,{row_name}:绘制每行图像的值,{col_var}:绘制每列图像的名称,{col_name}:绘制每列图像的值这几个参数可以使用。col_template:给图像设置列的标题。其中有{col_var}以及{col_name}可以使用。row_template:给图像设置行的标题。其中有{row_var}以及{row_name}可以使用。 示例代码如下:
g = sns.FacetGrid(tips,col="day",row="time")g.map(sns.regplot,"total_bill","tip")g.set_titles(template="时间{row_name}/星期{col_name}")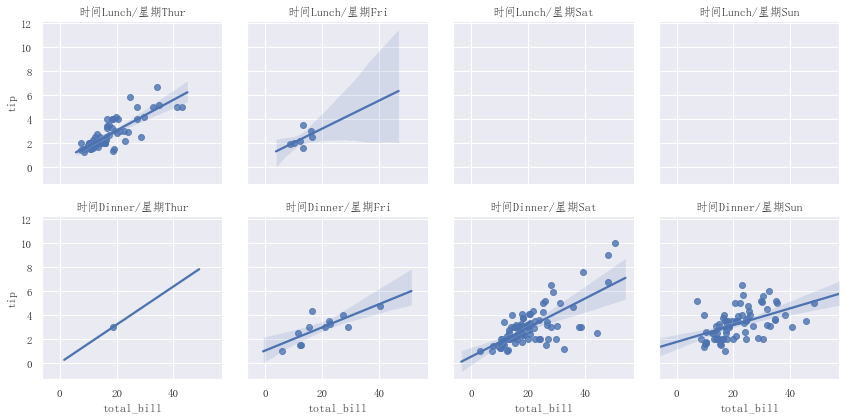
设置坐标轴:
g.set_axis_labels(x_var,y_var):一次性设置x和y的坐标的标题。g.set_xlabels(label):设置x轴的标题。g.set_ylabels(label):设置y轴的标题。g.set(xticks,yticks):设置x和y轴的刻度。g.set_xticklabels(labels):设置x轴的刻度文字。g.set_yticklabels(labels):设置y轴的刻度文字。 示例代码如下:
g.set(xticks=range(0,60,10),xticklabels=['$0','$10','$20','$30','$40','$50'])效果图如下: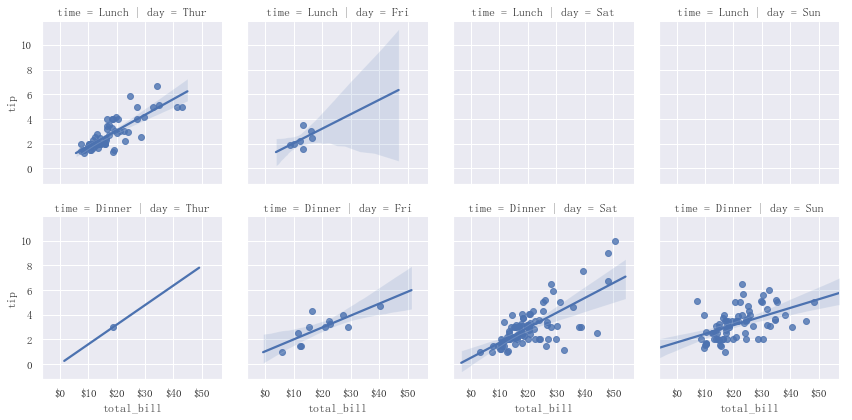
g.set方法:
g.set方法可以对FacetGrid下的每个子图Axes设置属性。其中可以设置的参数完全是根据Axes的属性来的。比如可以设置每个Axes的facecolor等。
关于Axes有哪些属性,请参考matplotlib.Axes的官方文档:https://matplotlib.org/api/axes_api.html?highlight=axes#matplotlib.axes.Axes。
g.fig:
通过g.fig,可以获取到当前的Figure对象。然后通过Figure对象再可以设置其他的属性,比如dip等。
样式风格设置
用seaborn绘图,比直接使用matplotlib绘图更加的美观。原因就是因为seaborn中已经将一些属性的样式进行了调整。我们可以直接使用,也可以修改他的样式。
自带的样式:
seaborn中自带了5种样式。分别是:
white:纯白色的。
sns.set_style("white") axes = sns.scatterplot(x="total_bill",y="tip",data=tips)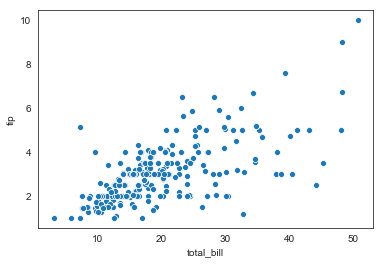
whitegrid:带有网格的白色的。
sns.set_style("whitegrid") axes = sns.scatterplot(x="total_bill",y="tip",data=tips)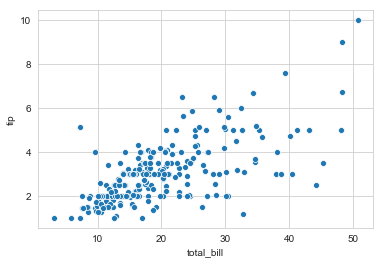
dark:灰色的。
sns.set_style("dark") axes = sns.scatterplot(x="total_bill",y="tip",data=tips)
darkgrid:带有网格的灰色的(网格线是白色的)。
sns.set_style("darkgrid") axes = sns.scatterplot(x="total_bill",y="tip",data=tips)
ticks:白色的,并且在轴上带有刻度条的。
sns.set_style("ticks") axes = sns.scatterplot(x="total_bill",y="tip",data=tips)
风格设置函数:
在seaborn中,可以通过三个函数来设置样式。分别是sns.set_style、sns.axes_style以及sns.set方法。
以下对着三种方法进行讲解。
1. sns.axes_style:
sns.axes_style(style=None,rc=None)。
这个函数调用的时候如果不传递任何参数,那么将会返回可以设置的所有属性。有时候我们不知道什么属性可以设置,那么可以打印下这个函数的返回值:
sns.axes_style()输入如下:
{'axes.facecolor': 'white', 'axes.edgecolor': 'black', 'axes.grid': False, 'axes.axisbelow': 'line', 'axes.labelcolor': 'black', 'figure.facecolor': (1, 1, 1, 0), 'grid.color': '#b0b0b0', 'grid.linestyle': '-', 'text.color': 'black', 'xtick.color': 'black', 'ytick.color': 'black', 'xtick.direction': 'out', 'ytick.direction': 'out', 'lines.solid_capstyle': 'projecting', 'patch.edgecolor': 'black', 'image.cmap': 'viridis', 'font.family': ['sans-serif'], 'font.sans-serif': ['DejaVu Sans', 'Bitstream Vera Sans', 'Computer Modern Sans Serif', 'Lucida Grande', 'Verdana', 'Geneva', 'Lucid', 'Arial', 'Helvetica', 'Avant Garde', 'sans-serif'], 'patch.force_edgecolor': False, 'xtick.bottom': True, 'xtick.top': False, 'ytick.left': True, 'ytick.right': False, 'axes.spines.left': True, 'axes.spines.bottom': True, 'axes.spines.right': True, 'axes.spines.top': True}这个函数也可以用来设置样式,但是只能通过with语句调用。
示例代码如下:
with sns.axes_style("dark",{"ytick.left":True}): sns.scatterplot(x="total_bill",y="tip",data=tips)2. sns.set_style():
sns.set_style(style=None,rc=None)。
这个函数跟sns.axes_style一样,也是用来设置绘图风格。但是这个函数的风格设置,不是临时的,而是一旦设置了,那么下面的所有绘图都是用这个风格。
示例代码如下:
sns.set_style("darkgrid")sns.scatterplot(x="total_bill",y="tip",data=tips)3. sns.set:
sns.set(context='notebook', style='darkgrid', palette='deep', font='sans-serif', font_scale=1, color_codes=True, rc=None)。
set方法也是用来设置样式的,他的功能更加强大。除了style以外,还可以设置调色板,字体,字体大小,颜色等,也可以设置其他的matplotlib.rcParams可以接收的参数。
示例代码如下:
sns.set(rc={"lines.linewidth":4})fmri = sns.load_dataset("fmri")sns.lineplot(x="timepoint",y="signal",data=fmri)效果图如下: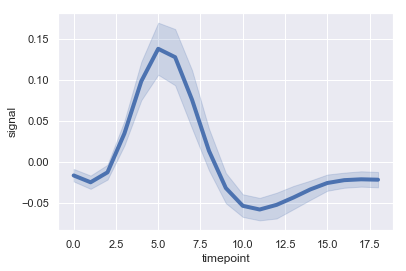
调色盘设置
seaborn可以非常迅速的做出优美的图形,其中就应该得力于他的调色盘机制。seaborn根据应用场景提供了三种不同类型的调色盘:定性的、连续的、发散的。
定性调色盘:
定性调色盘。一般在数据不连续,比较离散,想体现分类的情况下使用。在seaborn中,使用sns.color_palette来创建调色盘。
1. 默认调色盘:
在seaborn中,默认情况下就设置了一些颜色供绘图使用。使用sns.color_palette即可获取。并且我们可以通过sns.palplot来绘制调色盘。
示例代码如下:
current_palette = sns.color_palette()sns.palplot(current_palette)效果图如下:
默认的调色盘有10种颜色。这些颜色都有6种风格。分别是:deep,muted,pastel, bright,dark,colorblind。这几种风格的颜色不变,主要调整的是亮度和饱和度。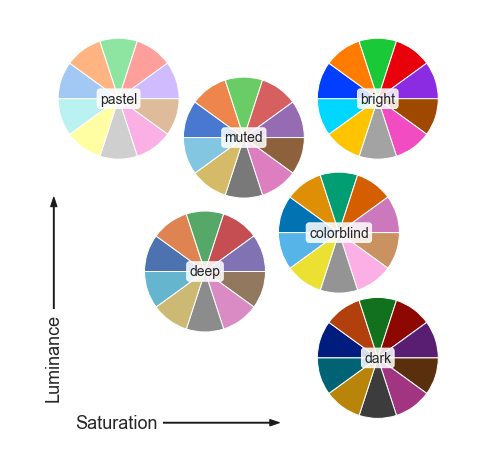
current_palette = sns.color_palette("dark")sns.palplot(current_palette)
2. hls圆形颜色系统:
hls圆形颜色系统是颜色按照顺序,经过偏移,无缝形成一个圆形。我们在使用这个调色盘的时候,可以指定需要使用多少种颜色。
示例代码如下:
# 使用hls圆形颜色系统,取20个颜色sns.palplot(sns.color_palette("hls",20))
也可以使用另外一个函数sns.hls_palette(n_colors=6, h=0.01, l=0.6, s=0.65)来实现。这个函数可以传递更多的参数。比如我们可以通过更改hue来更改开始的颜色,通过更改l来调整亮度,通过更改s来调整饱和度。
示例代码如下:
sns.palplot(sns.hls_palette(10,h=0.4,l=0.4,s=0.5))
另外也可以通过sns.husl_palette来实现色系的调整,这个方法比sns.hls_palette亮度和饱和度更加的均匀。
sns.palplot(sns.husl_palette(10))
3. 分类颜色:
分类颜色是seaborn已经提前给你定义了一些颜色,使用这些颜色在做分类分组的时候可以按照自己的需求选择。
示例代码如下:
sns.palplot(sns.color_palette("Paired"))
关于分类的颜色选择,可以通过sns.choose_colorbrewer_palette("qualitative")来查看。这个方法只能用在jupyter notebook中。可以选择不同的样式,然后还可以调节饱和度等。
效果图如下:
4. 用xkcd颜色:
xkcd是一个漫画名称或者是工作室。xkcd开展了一项众包活动,为随机的RGB颜色命名。这产生了一组954种命名颜色。我们可以从sns.xkcd_palette里面提取颜色。提取到后,如果想要用在palette参数中,那么还需要放到sns.xkcd_palette中。所有的xkcd颜色的名称可以参考官网:https://xkcd.com/color/rgb/。
示例代码如下:
# 获取名字为blue green的颜色print(sns.xkcd_rgb["blue green"])# 用xkcd的颜色名称构建一个palette对象colors = ["windows blue", "amber", "greyish", "faded green", "dusty purple"]sns.palplot(sns.xkcd_palette(colors))连续的颜色盘:
有时候我们绘图的时候,想要使用一个同种色系,但是不同深浅,这时候就可以使用连续的颜色盘。
示例代码如下:
sns.palplot(sns.color_palette("Blues"))
默认颜色是从浅入深,如果想要从深变浅,那么可以在色系后加一个_r。
示例代码如下:
sns.palplot(sns.color_palette("Blues_r"))
我们也可以通过sns.choose_colorbrewer_palette("sequential")查看有哪些色系可供选择。
效果图如下:
离散的色盘:
离散的色盘,是两边的颜色逐渐加深,中间的颜色最淡。或者是中间的颜色最深,两边的颜色最淡。一般离散的色盘可以用于比如温度,零度以上可以用红色表示,零度以下用蓝色表示。越红的地方,表示温度越高,越蓝的地方,表示温度越低。
示例代码如下:
values = [12,15,17,18,-5,-10]with sns.color_palette("RdBu_r"): sns.barplot([1,2,3,4,5,6],sorted(values))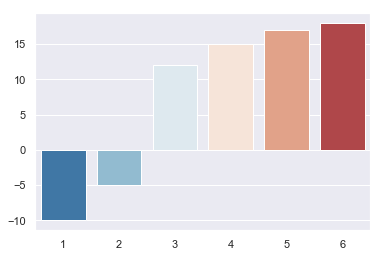
也可以通过sns.choose_colorbrewer_palette("diverging")查看离散的色盘有哪些可以选择。
还可以通过sns.diverging_palette(h_neg, h_pos, s=75, l=50, sep=10, n=6, center='light', as_cmap=False)来自定义离散色盘。在这里不再做过多讲解。
官方文档:
https://seaborn.pydata.org/tutorial/color_palettes.html。
Seaborn实例
1. 有一组温度数据,按照时间和温度绘制折线图
bj_temps = [29,27,23,22]bj_hours = ["20时","23时","2时","5时"]plt.figure(figsize=(5,2))axes = sns.lineplot(range(0,4),bj_temps,marker="o")axes.set_xticks(range(0,4))axes.set_xticklabels(bj_hours)效果图如下: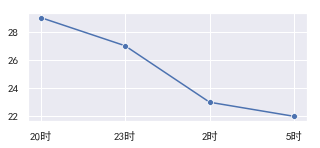
2. 有以下国家数据,根据时间绘制条形图
legals = pd.read_csv("../法人人数年度数据.csv",encoding='GB18030')temp_legals = legals[1:11]# 清理数据new_legals = pd.DataFrame()for index in temp_legals.index: row_values = temp_legals.loc[index] for x in range(2009,2018): year = "%d年"%x series = pd.Series({"指标":row_values['指标'],'年份':year,"数量":row_values[year]}) new_legals = pd.concat([new_legals,series.to_frame().T])new_legals.reset_index(drop=True,inplace=True)# 开始绘图plt.figure(figsize=(20,5))sns.barplot(x="年份",y="数量",hue="指标",data=new_legals)plt.legend(ncol=4)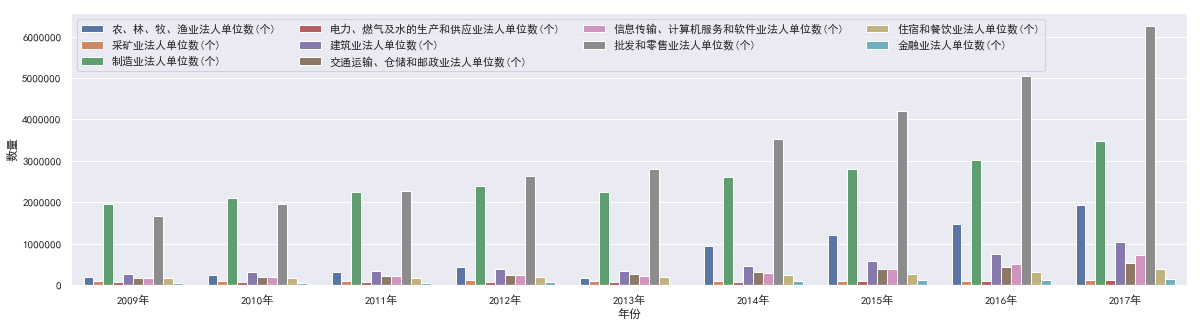
3. 有链家网的数据,请按照以下要求实现绘图
x轴是Region(行政区),y轴是每个区的平均每平米的单价,绘制条形图。x轴是Region(行政区),y轴是每平米的单价,绘制箱线图。x轴是Region,y轴是每平米的单价,绘制swarm图。以上三个图需要绘制在一个figure上。
lianjia = pd.read_csv("../lianjia.csv",encoding='utf-8')lianjia['UnitPrice'] = lianjia['Price']/lianjia['Size']house_mean = lianjia.groupby('Region')['UnitPrice'].mean().sort_values(ascending=False).to_frame().reset_index()fig,axes_arr = plt.subplots(3,1,figsize=(20,15))sns.barplot(x="Region",y="UnitPrice",data=house_mean,ax=axes_arr[0])sns.boxplot(x="Region",y="UnitPrice",data=lianjia,ax=axes_arr[1])sns.swarmplot(x="Region",y="UnitPrice",data=lianjia,ax=axes_arr[2])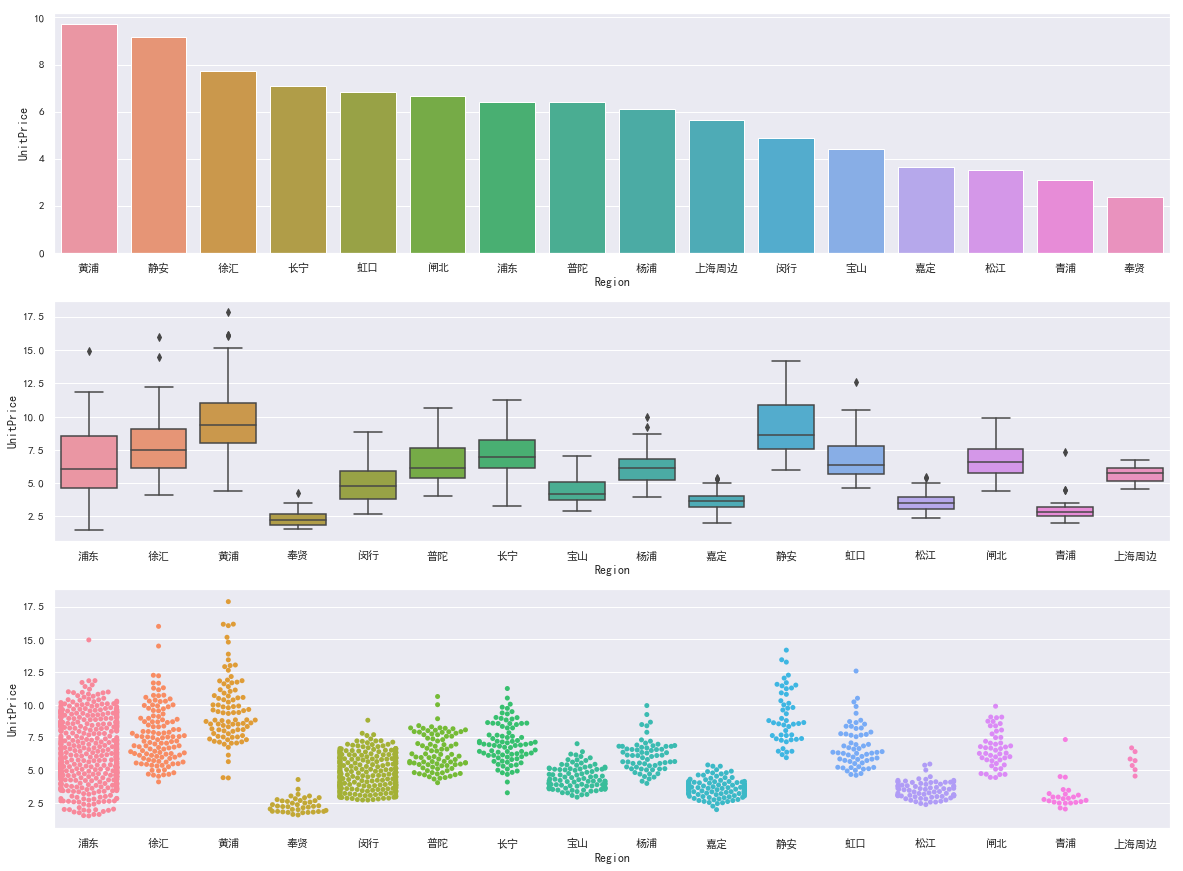
使用FacetGrid绘制尺寸与单价的关系,并且区分有无电梯。
fg = sns.FacetGrid(lianjia,col="Elevator",height=6,aspect=2)fg.map(sns.regplot,"Size","UnitPrice")fg.add_legend()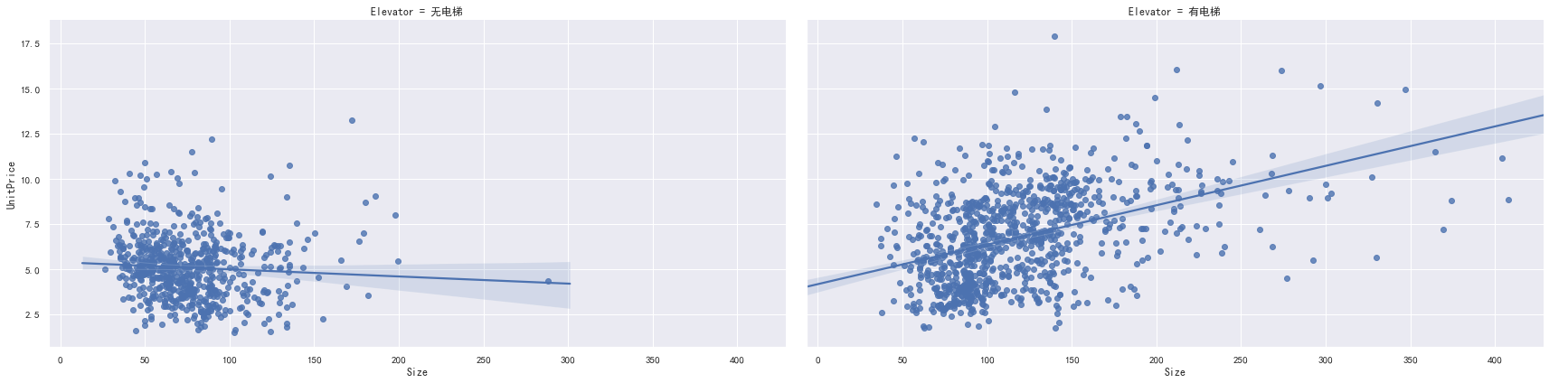
加油!
感谢!
努力!