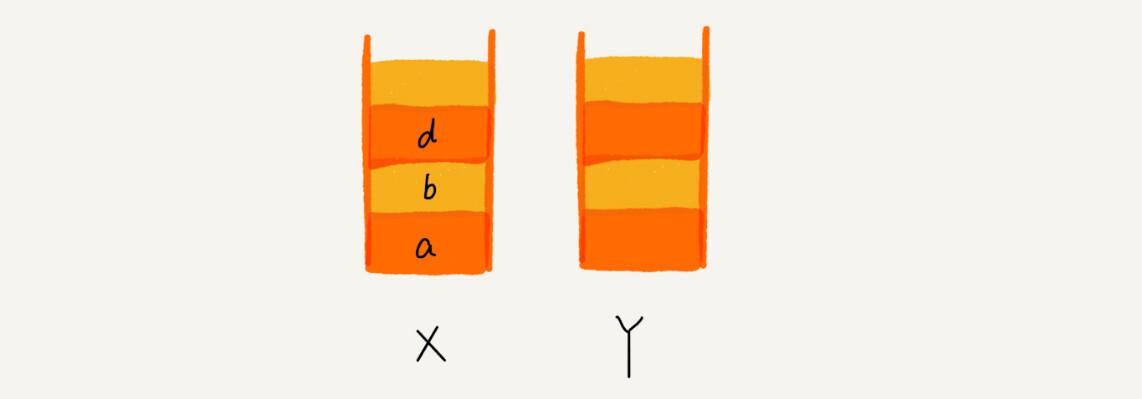文章目录
前言:浏览器与栈的纠缠如何理解“栈”?如何实现一个“栈”?基于数组的顺序栈基于链表的链式栈 解答开篇
??作者简介:大家好,我是黑洞晓威,一名大二学生,希望和大家一起进步。
?本文收录于 算法,本专栏是针对大学生、初学算法的人准备,解析常见的数据结构与算法,同时备战蓝桥杯。
前言:浏览器与栈的纠缠
浏览器的前进、后退功能,我想你肯定很熟悉吧?
当你依次访问完一串页面a-b-c之后,点击浏览器的后退按钮,就可以查看之前浏览过的页面b和a。当你后退到页面a,点击前进按钮,就可以重新查看页面b和c。但是,如果你后退到页面b后,点击了新的页面d,那就无法再通过前进、后退功能查看页面c了。
假设你是浏览器的开发工程师,你会如何实现这个功能呢?
这就要用到我们今天要讲的“栈”这种数据结构。带着这个问题,我们来学习今天的内容。
如何理解“栈”?
关于“栈”,我有一个非常贴切的例子,就是一摞叠在一起的盘子。我们平时放盘子的时候,都是从下往上一个一个放;取的时候,我们也是从上往下一个一个地依次取,不能从中间任意抽出。 后进者先出,先进者后出,这就是典型的“栈”结构。
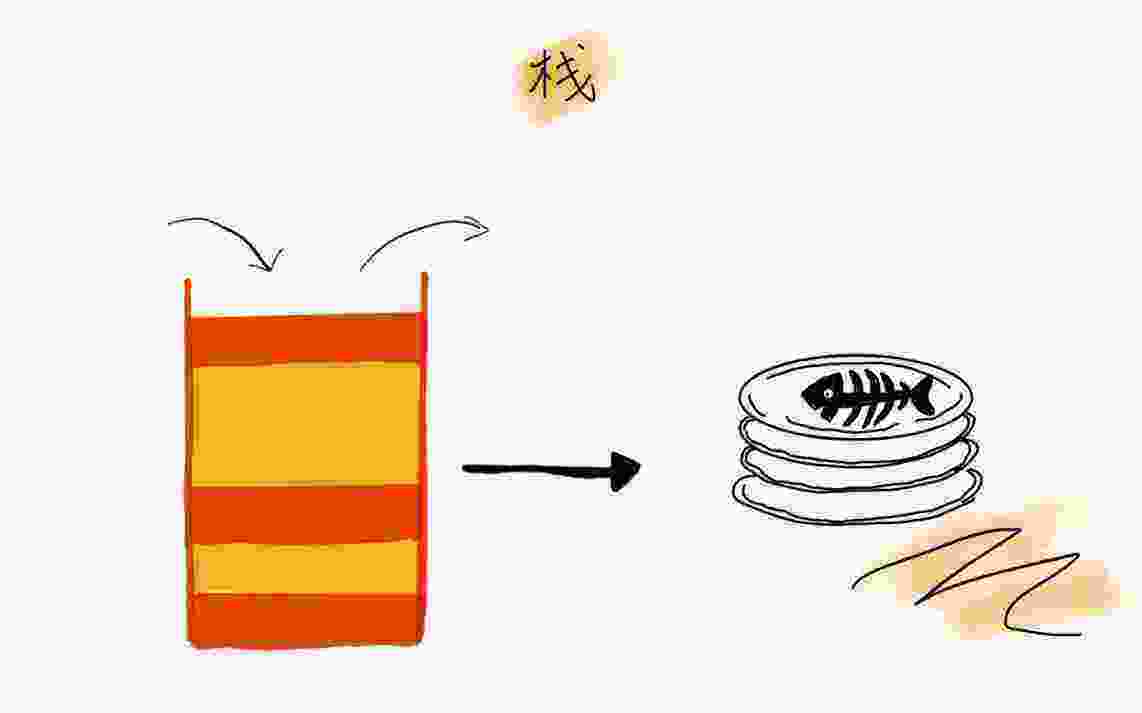
从栈的操作特性上来看, 栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。
我第一次接触这种数据结构的时候,就对它存在的意义产生了很大的疑惑。因为我觉得,相比数组和链表,栈带给我的只有限制,并没有任何优势。那我直接使用数组或者链表不就好了吗?为什么还要用这个“操作受限”的“栈”呢?
事实上,从功能上来说,数组或链表确实可以替代栈,但你要知道,特定的数据结构是对特定场景的抽象,而且,数组或链表暴露了太多的操作接口,操作上的确灵活自由,但使用时就比较不可控,自然也就更容易出错。
当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,这时我们就应该首选“栈”这种数据结构。
如何实现一个“栈”?
从刚才栈的定义里,我们可以看出,栈主要包含两个操作,入栈和出栈,也就是在栈顶插入一个数据和从栈顶删除一个数据。理解了栈的定义之后,我们来看一看如何用代码实现一个栈。
实际上,栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作 顺序栈,用链表实现的栈,我们叫作 链式栈。
基于数组的顺序栈
我这里实现一个基于数组的顺序栈。
// 基于数组实现的顺序栈public class ArrayStack { private String[] items; // 数组 private int count; // 栈中元素个数 private int n; //栈的大小 // 初始化数组,申请一个大小为n的数组空间 public ArrayStack(int n) { this.items = new String[n]; this.n = n; this.count = 0; } // 入栈操作 public boolean push(String item) { // 数组空间不够了,直接返回false,入栈失败。 if (count == n) return false; // 将item放到下标为count的位置,并且count加一 items[count] = item; ++count; return true; } // 出栈操作 public String pop() { // 栈为空,则直接返回null if (count == 0) return null; // 返回下标为count-1的数组元素,并且栈中元素个数count减一 String tmp = items[count-1]; --count; return tmp; }}基于链表的链式栈
基于链表实现的链式栈的代码:
/* * 用链表作为栈的底层 */public class SingleLinkedListStack {// 用链表作为栈的底层public SingleLinkedList<E> list;public SingleLinkedListStack() { list = new SingleLinkedList();}@Overridepublic void push(E e) {// TODO Auto-generated method stublist.addFirst(e);}@Overridepublic E pop() {// TODO Auto-generated method stubreturn (E) list.removeFirst();}@Overridepublic E peek() {// TODO Auto-generated method stubreturn list.getfirst();}@Overridepublic int getSize() {// TODO Auto-generated method stubreturn list.getSize();}@Overridepublic boolean isEmpty() {// TODO Auto-generated method stubreturn list.isEmpty();}@Overridepublic String toString() { StringBuilder sb=new StringBuilder(); sb.append("stack "); sb.append("push:>"); for(int i=0;i<list.getSize();i++) { sb.append(list.get(i)); sb.append("->"); } sb.append("null");return sb.toString();}}了解了定义和基本操作,那它的操作的时间、空间复杂度是多少呢?
不管是顺序栈还是链式栈,我们存储数据只需要一个大小为n的数组就够了。在入栈和出栈过程中,只需要一两个临时变量存储空间,所以空间复杂度是O(1)。
注意,这里存储数据需要一个大小为n的数组,并不是说空间复杂度就是O(n)。因为,这n个空间是必须的,无法省掉。所以我们说空间复杂度的时候,是指除了原本的数据存储空间外,算法运行还需要额外的存储空间。
空间复杂度分析是不是很简单?时间复杂度也不难。不管是顺序栈还是链式栈,入栈、出栈只涉及栈顶个别数据的操作,所以时间复杂度都是O(1)。
解答开篇
好了,我想现在你已经完全理解了栈的概念。我们再回来看看开篇的思考题,如何实现浏览器的前进、后退功能?其实,用两个栈就可以非常完美地解决这个问题。
我们使用两个栈,X和Y,我们把首次浏览的页面依次压入栈X,当点击后退按钮时,再依次从栈X中出栈,并将出栈的数据依次放入栈Y。当我们点击前进按钮时,我们依次从栈Y中取出数据,放入栈X中。当栈X中没有数据时,那就说明没有页面可以继续后退浏览了。当栈Y中没有数据,那就说明没有页面可以点击前进按钮浏览了。
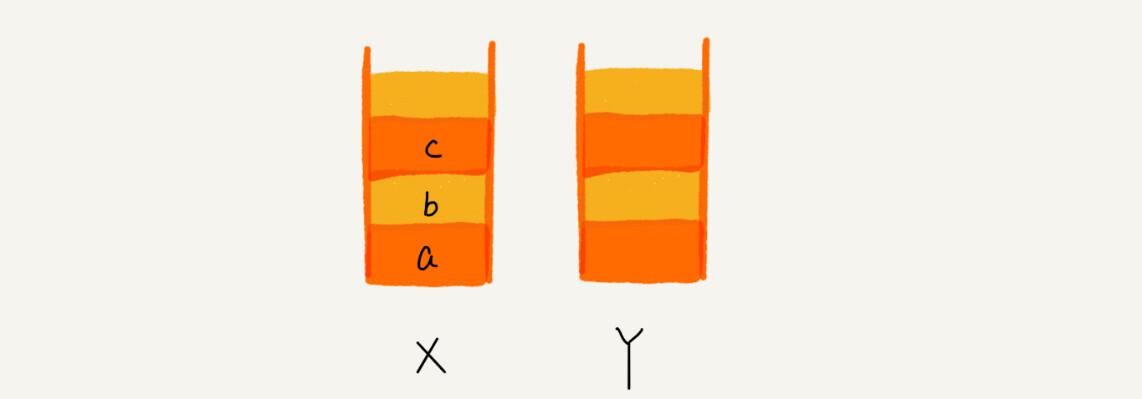
比如你顺序查看了a,b,c三个页面,我们就依次把a,b,c压入栈,这个时候,两个栈的数据就是这个样子:
当你通过浏览器的后退按钮,从页面c后退到页面a之后,我们就依次把c和b从栈X中弹出,并且依次放入到栈Y。这个时候,两个栈的数据就是这个样子:
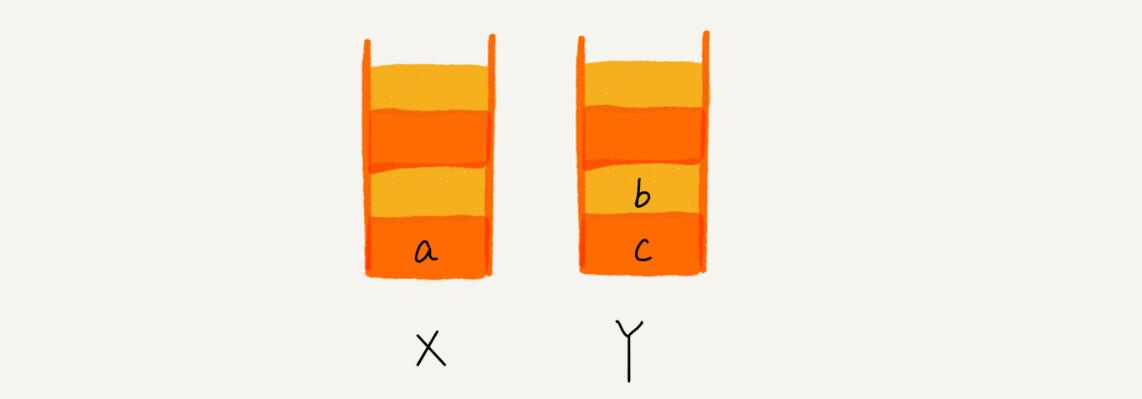
这个时候你又想看页面b,于是你又点击前进按钮回到b页面,我们就把b再从栈Y中出栈,放入栈X中。此时两个栈的数据是这个样子:
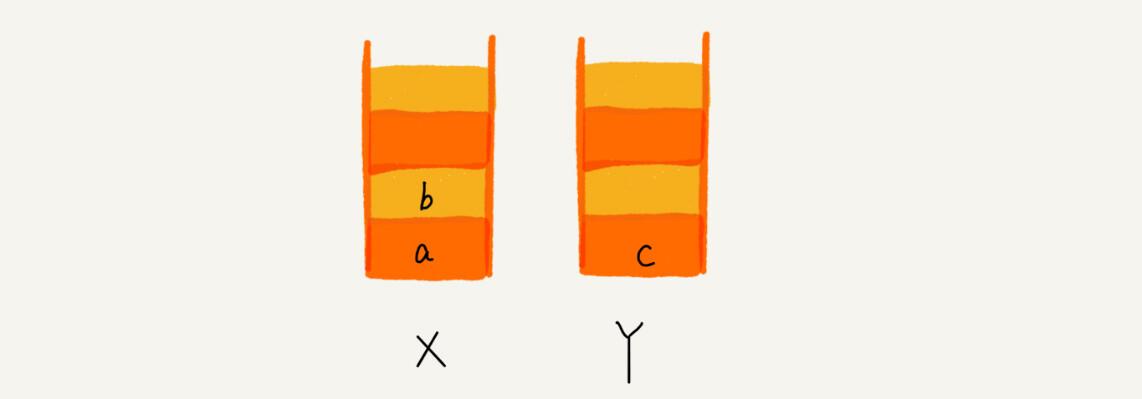
这个时候,你通过页面b又跳转到新的页面d了,页面c就无法再通过前进、后退按钮重复查看了,所以需要清空栈Y。此时两个栈的数据这个样子: