说在前面
在尼恩的(50+)读者社群中,经常遇到一个 API网关 架构方面的问题:
(1) 尼恩老师,最近公司我们在规划业务出口网关(目的,整合规范外部调用,如短信平台 mqtt 等) 我在做整理技术方案,但是没有什么思路。老师,这方面有没有什么参考资料呀
(2) 高并发业务出口网关,如何做系统架构?
(3 )等等等等…
刚刚,在尼恩的社群(50+)中,有小伙伴又问了这个问题。
其实,尼恩作为技术中台的架构师, 网关是尼恩架构的重点, 所以,一直想带大家从 架构到实操, 完成一个 10Wqps 超高并发 网关实操指导。
而且尼恩指导简历的过程中,也指导过小伙伴写过 10Wqps 超高并发 网关简历,里边涉及到大量的设计模式, 小伙伴的简历,里边立马金光闪闪。
后面有机会,带大家做一下这个高质量的实操,并且指导大家写入简历。
尼恩手上的资料涉密,不能公开。
现在,先结合互联网的公开资料,梳理了 业务架构、技术选型、架构演进等三个方案,为小伙伴们提供一些重要的API网关的参考资料。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从这里获取:码云
API 网关的业务架构
从应用程序架构的变迁过程可以发现,随着业务多变性、灵活性的不断提高,应用程序需要以更加灵活的组合来应对。
同时为了应对业务的细分以及高并发的挑战,微服务的架构被广泛使用,由于微服务架构中应用会被拆分成多个服务。
为了方便客户端对这些服务的调用于是引入了 API 的概念。今天我们就来看看API 网关的原理以及它是如何应用的。
网关一词最早出现在网络设备,比如两个相互独立的局域网之间通过路由器进行通信, 中间的路由被称之为网关。
落实在开发层面来说,就是客户端与微服务系统之间存在的网关。从业务层面来说,当客户端完成某个业务的时候,需要同时调用多个微服务。
如图 1 所示,当客户端发起下单请求需要调用:商品查询、库存扣减以及订单更新等服务。
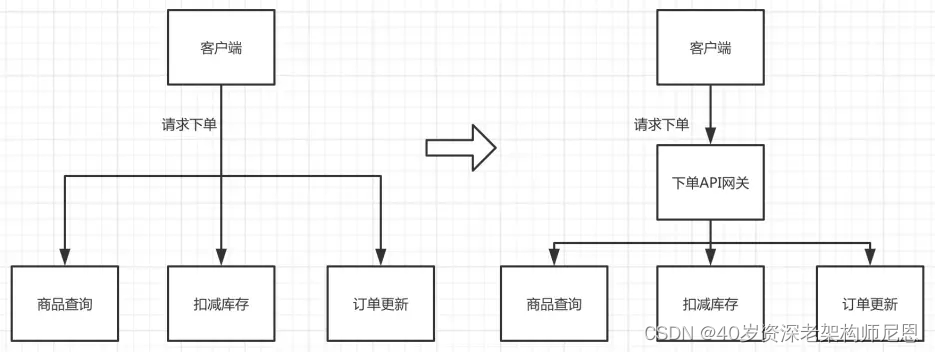
图1 :API 网关加入前后对比
如果这些服务需要客户端分别调用才能完成,会增加请求的复杂度,同时也会带来网络调用性能的损耗。因此,针对微服务的应用场景就推出了 API 网关的调用。
在客户端与微服务之间加入下单 API 网关,客户端直接给这个 API 网关下达命令,由于后者完成对其他三个微服务的调用并且返回结果给客户端。
从系统层面来说,任何一个应用系统如果需要被其他系统调用,就需要暴露 API,这些 API 代表着的功能点。
正如上面下单的例子中提到的,如果一个下单的功能点需要调用多个服务的时候,在这个下单的 API 网关中就需要聚合多个服务的调用。
这个聚合的方式有点像设计模式中的门面模式(Facade),它为外部的调用提供了一个统一的访问入口。
不仅如此,如图 2 所示,API 网关还可以协助两个系统的通信,在系统之间加上一个中介者协助 API 的调用。
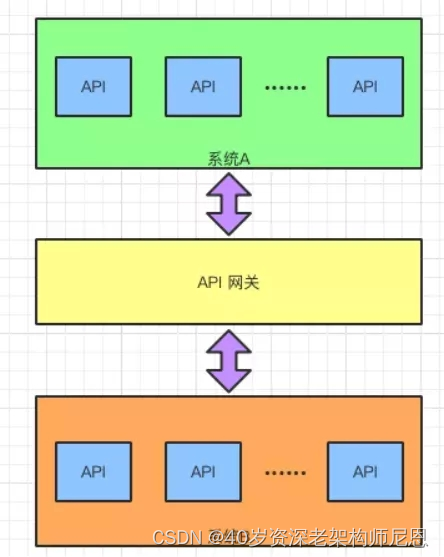
图 2:对接两个系统的 API 网关
从客户端类型层面来说,为了屏蔽不同客户端调用差异也可以加入 API 网关。
如图 3 所示,在实际开发过程中 API 网关还可以根据不同的客户端类型(iOS、Android、PC、小程序),提供不同的 API 网关与之对应。
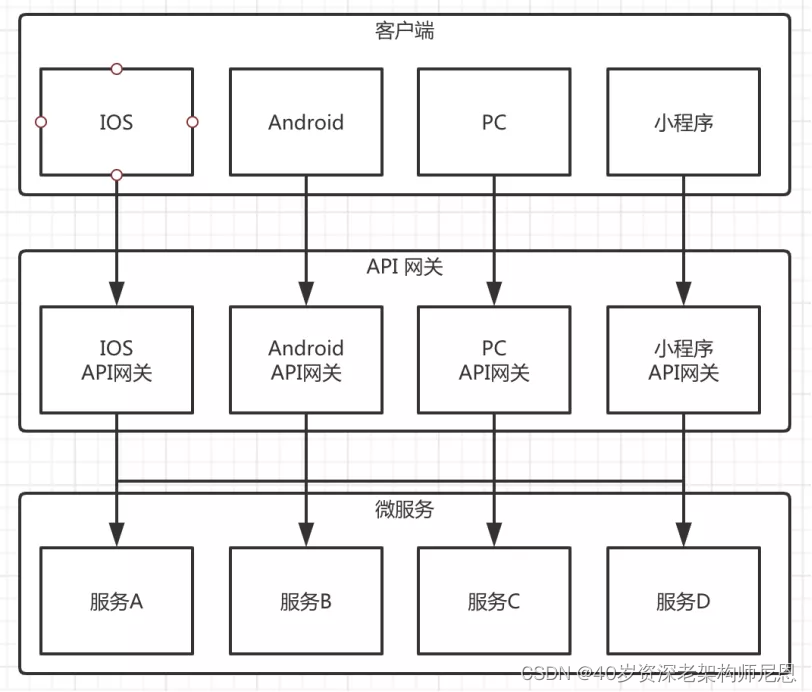
图 3:对接客户端和服务端的 API 网关
由于 API 网关所处的位置是客户端与微服务交界的地方,因此从功能上它还包括:路由,负载均衡,限流,缓存,日志,发布等等。
这里的参考资料:
尼恩编著的400页PDF电子书 《SpringCloud Alibaba 技术圣经》
尼恩编著的500页 PDF电子书 《Java高并发核心编程 卷3 加强版》,清华大学出版社出版
pdf领取方式,请参见公众号: 技术自由圈
API 网关选型
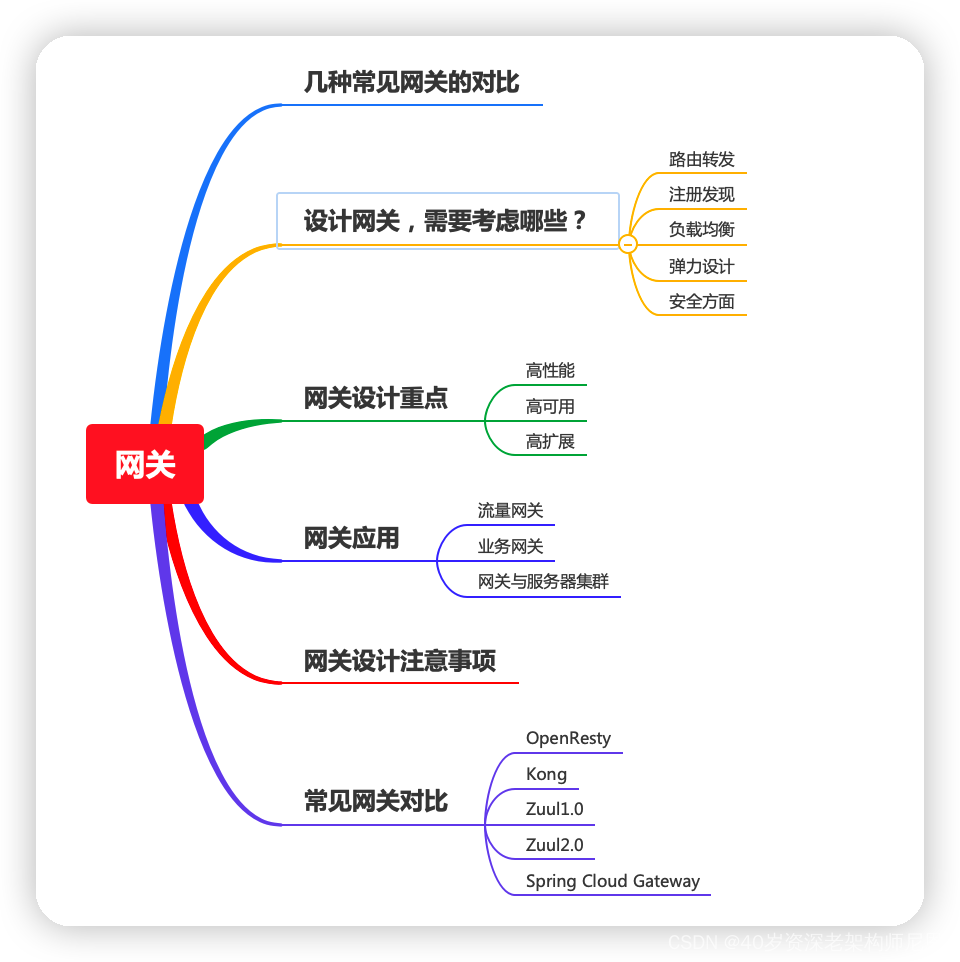
来看下 API 网关如何设计、五种 API 网关的技术选型对比。
这里的参考资料:
尼恩编著的400页PDF电子书 《SpringCloud Alibaba 技术圣经》
尼恩编著的500页 PDF电子书 《Java高并发核心编程 卷3 加强版》,清华大学出版社出版
pdf领取方式,请参见公众号: 技术自由圈
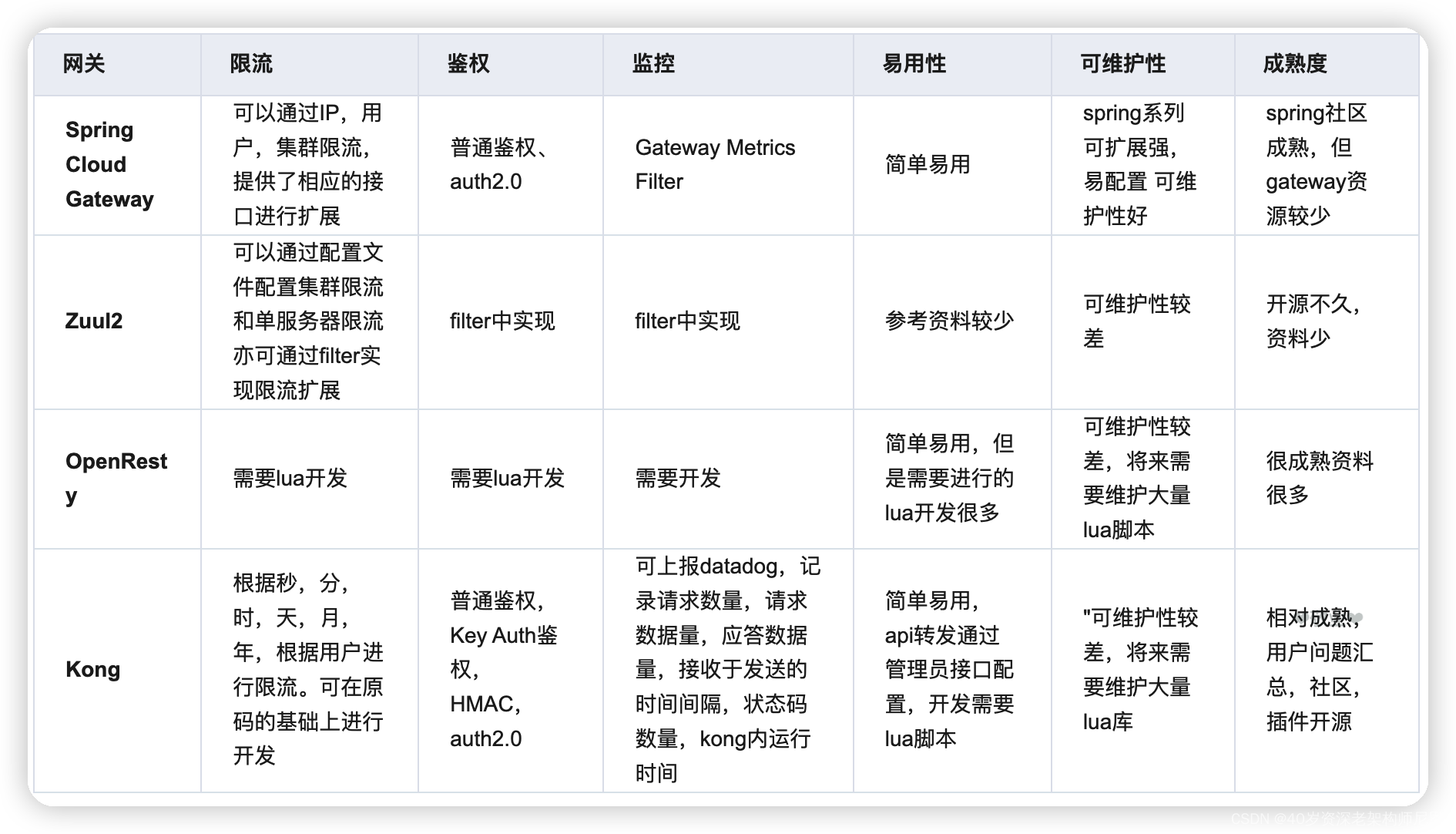
几种常见网关的对比
先来个几款 API 网关的对比,让大家有个整体的印象。
设计网关,需要考虑哪些?
如果让你设计一个 API 网关,你会考虑哪些方面?
路由转发
请求先到达 API 网关,然后经过断言,匹配到路由后,由路由将请求转发给真正的业务服务。
注册发现
各个服务实例需要将自己的服务名、IP 地址和 port 注册到注册中心,然后注册中心会存放一份注册表,Gateway 可以从注册中心获取到注册表,然后转发请求时只需要转发到对应的服务名即可。
负载均衡
一个服务可以由多个服务实例组成服务集群,而 Gateway 配置的通常是一个服务名,如 passjava-member 服务,所以需要具备负载均衡功能,将请求分发到不同的服务实例上。
弹力设计
网关还可以把弹力设计中的那些异步、重试、幂等、流控、熔断、监视等都可以实现进去。这样,同样可以像 Service Mesh 那样,让应用服务只关心自己的业务逻辑(或是说数据面上的事)而不是控制逻辑(控制面)。
安全方面
SSL 加密及证书管理、Session 验证、授权、数据校验,以及对请求源进行恶意攻击的防范。错误处理越靠前的位置就是越好,所以,网关可以做到一个全站的接入组件来对后端的服务进行保护。当然,网关还可以做更多更有趣的事情,比如:灰度发布、API聚合、API编排。
灰度发布
网关完全可以做到对相同服务不同版本的实例进行导流,还可以收集相关的数据。这样对于软件质量的提升,甚至产品试错都有非常积极的意义。
API 聚合
使用网关可以将多个单独请求聚合成一个请求。在微服务体系的架构中,因为服务变小了,所以一个明显的问题是,客户端可能需要多次请求才能得到所有的数据。这样一来,客户端与后端之间的频繁通信会对应用程序的性能和规模产生非常不利的影响。于是,我们可以让网关来帮客户端请求多个后端的服务(有些场景下完全可以并发请求),然后把后端服务的响应结果拼装起来,回传给客户端(当然,这个过程也可以做成异步的,但这需要客户端的配合)。
API 编排
同样在微服务的架构下,要走完一个完整的业务流程,我们需要调用一系列 API,就像一种工作流一样,这个事完全可以通过网页来编排这个业务流程。我们可能通过一个 DSL 来定义和编排不同的 API,也可以通过像 AWS Lambda 服务那样的方式来串联不同的 API。
网关设计重点
网关设计重点主要是三个, 高性能、高可用、高扩展:
高性能
在技术设计上,网关不应该也不能成为性能的瓶颈。对于高性能,最好使用高性能的编程语言来实现,如 C、C++、Go 和 Java。网关对后端的请求,以及对前端的请求的服务一定要使用异步非阻塞的 I/O 来确保后端延迟不会导致应用程序中出现性能问题。C 和 C++ 可以参看 Linux 下的 epoll 和 Windows 的 I/O Completion Port 的异步 IO 模型,Java 下如 Netty、Spring Reactor 的 NIO 框架。
高可用
因为所有的流量或调用经过网关,所以网关必须成为一个高可用的技术组件,它的稳定直接关系到了所有服务的稳定。网关如果没有设计,就会成变一个单点故障。因此,一个好的网关至少要做到以下几点。
集群化。网关要成为一个集群,其最好可以自己组成一个集群,并可以自己同步集群数据,而不需要依赖于一个第三方系统来同步数据。服务化。网关还需要做到在不间断的情况下修改配置,一种是像 Nginx reload 配置那样,可以做到不停服务,另一种是最好做到服务化。也就是说,得要有自己的 Admin API 来在运行时修改自己的配置。持续化。比如重启,就是像 Nginx 那样优雅地重启。有一个主管请求分发的主进程。当我们需要重启时,新的请求被分配到新的进程中,而老的进程处理完正在处理的请求后就退出。高可用性涵盖了内部和外部的各种不确定因素,这里讲一下网关系统在高可用性方面做的努力。
高扩展
因为网关需要承接所有的业务流量和请求,所以一定会有或多或少的业务逻辑。而我们都知道,业务逻辑是多变和不确定的。比如,需要在网关上加入一些和业务相关的东西。因此,一个好的 Gateway 还需要是可以扩展的,并能进行二次开发的。当然,像 Nginx 那样通过 Module 进行二次开发的固然可以。
另外,在运维方面,网关应该有以下几个设计原则。
业务松耦合,协议紧耦合。在业务设计上,网关不应与后面的服务之间形成服务耦合,也不应该有业务逻辑。网关应该是在网络应用层上的组件,不应该处理通讯协议体,只应该解析和处理通讯协议头。另外,除了服务发现外,网关不应该有第三方服务的依赖。应用监视,提供分析数据。网关上需要考虑应用性能的监控,除了有相应后端服务的高可用的统计之外,还需要使用 Tracing ID 实施分布式链路跟踪,并统计好一定时间内每个 API 的吞吐量、响应时间和返回码,以便启动弹力设计中的相应策略。用弹力设计保护后端服务。网关上一定要实现熔断、限流、重试和超时等弹力设计。如果一个或多个服务调用花费的时间过长,那么可接受超时并返回一部分数据,或是返回一个网关里的缓存的上一次成功请求的数据。你可以考虑一下这样的设计。DevOps。因为网关这个组件太关键了,所以需要 DevOps 这样的东西,将其发生故障的概率降到最低。这个软件需要经过精良的测试,包括功能和性能的测试,还有浸泡测试。还需要有一系列自动化运维的管控工具。网关设计注意事项
不要在网关中的代码里内置聚合后端服务的功能,而应考虑将聚合服务放在网关核心代码之外。可以使用 Plugin 的方式,也可以放在网关后面形成一个 Serverless 服务。网关应该靠近后端服务,并和后端服务使用同一个内网,这样可以保证网关和后端服务调用的低延迟,并可以减少很多网络上的问题。这里多说一句,网关处理的静态内容应该靠近用户(应该放到 CDN 上),而网关和此时的动态服务应该靠近后端服务。网关也需要做容量扩展,所以需要成为一个集群来分担前端带来的流量。这一点,要么通过 DNS 轮询的方式实现,要么通过 CDN 来做流量调度,或者通过更为底层的性能更高的负载均衡设备。对于服务发现,可以做一个时间不长的缓存,这样不需要每次请求都去查一下相关的服务所在的地方。当然,如果你的系统不复杂,可以考虑把服务发现的功能直接集成进网关中。为网关考虑 bulkhead 设计方式。用不同的网关服务不同的后端服务,或是用不同的网关服务前端不同的客户。另外,因为网关是为用户请求和后端服务的桥接装置,所以需要考虑一些安全方面的事宜。具体如下:
加密数据。可以把 SSL 相关的证书放到网关上,由网关做统一的 SSL 传输管理。校验用户的请求。一些基本的用户验证可以放在网关上来做,比如用户是否已登录,用户请求中的 token 是否合法等。但是,我们需要权衡一下,网关是否需要校验用户的输入。因为这样一来,网关就需要从只关心协议头,到需要关心协议体。而协议体中的东西一方面不像协议头是标准的,另一方面解析协议体还要耗费大量的运行时间,从而降低网关的性能。对此,我想说的是,看具体需求,一方面如果协议体是标准的,那么可以干;另一方面,对于解析协议所带来的性能问题,需要做相应的隔离。检测异常访问。网关需要检测一些异常访问,比如,在一段比较短的时间内请求次数超过一定数值;还比如,同一客户端的 4xx 请求出错率太高……对于这样的一些请求访问,网关一方面要把这样的请求屏蔽掉,另一方面需要发出警告,有可能会是一些比较重大的安全问题,如被黑客攻击。网关应用
流量网关
流量网关,顾名思义就是控制流量进入集群的网关,有很多工作需要在这一步做,对于一个服务集群,势必有很多非法的请求或者无效的请求,这时候要将请求拒之门外,降低集群的流量压力。
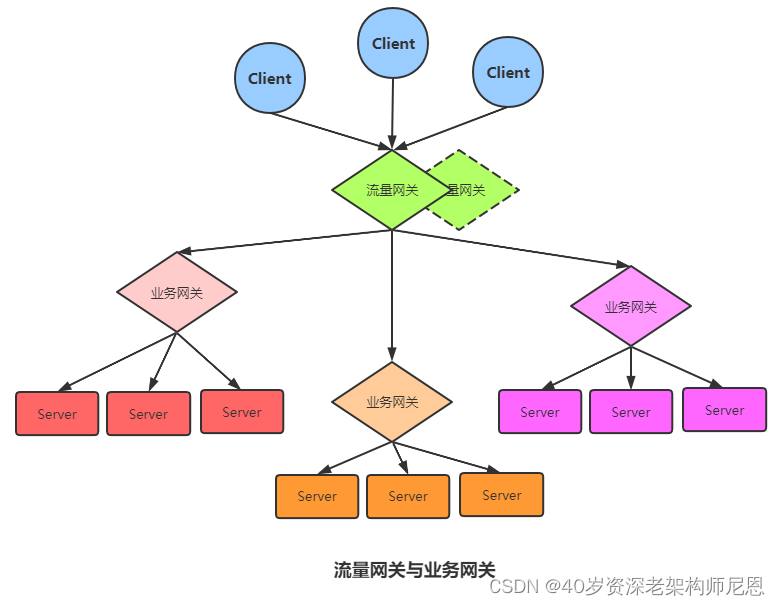
定义全局性的、跟具体的后端业务应用和服务完全无关的策略网关就是上图所示的架构模型——流量网关。流量网关通常只专注于全局的Api管理策略,比如全局流量监控、日志记录、全局限流、黑白名单控制、接入请求到业务系统的负载均衡等,有点类似防火墙。Kong 就是典型的流量网关。
下面是kong的架构图,来自官网:
这里需要补充一点的是,业务网关一般部署在流量网关之后、业务系统之前,比流量网关更靠近业务系统。通常API网指的是业务网关。 有时候我们也会模糊流量网关和业务网关,让一个网关承担所有的工作,所以这两者之间并没有严格的界线。
业务网关
当一个单体应用被拆分成许许多多的微服务应用后,也带来了一些问题。一些与业务非强相关的功能,比如权限控制、日志输出、数据加密、熔断限流等,每个微服务应用都需要,因此存在着大量重复的代码实现。而且由于系统的迭代、人员的更替,各个微服务中这些功能的实现细节出现了较大的差异,导致维护成本变高。另一方面,原先单体应用下非常容易做的接口管理,在服务拆分后没有了一个集中管理的地方,无法统计已存在哪些接口、接口定义是什么、运行状态如何。
网关就是为了解决上述问题。作为微服务体系中的核心基础设施,一般需要具备接口管理、协议适配、熔断限流、安全防护等功能,各种开源的网关产品(比如 zuul)都提供了优秀高可扩展性的架构、可以很方便的实现我们需要的一些功能、比如鉴权、日志监控、熔断限流等。
与流量网关相对应的就是业务网关,业务网关更靠近我们的业务,也就是与服务器应用层打交道,那么有很多应用层需要考虑的事情就可以依托业务网关,例如在线程模型、协议适配、熔断限流,服务编排等。下面看看业务网关体系结构:
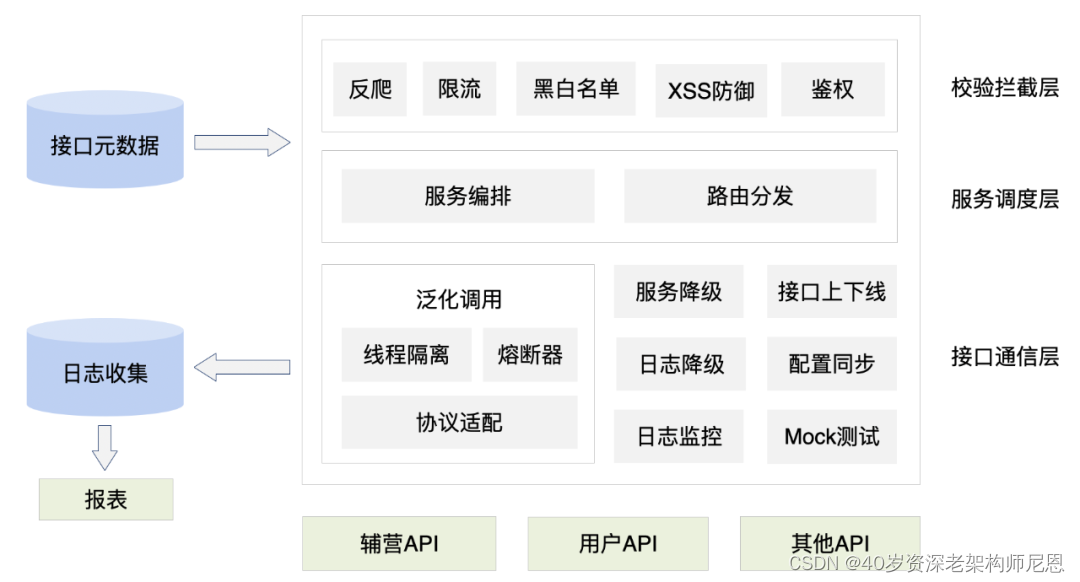
从这个图中可以看出业务网关主要职责以及所做的事情, 目前业务网关比较成熟的 API 网关框架产品有三个 分别是:Zuul1、Zuul2 和 SpringCloud Gateway, 后面再进行对比。
网关与服务器集群
回到我们服务器上,下面图介绍了网关(Gateway)作用,可知 Gateway 方式下的架构,可以细到为每一个服务的实例配置一个自己的 Gateway,也可以粗到为一组服务配置一个,甚至可以粗到为整个架构配置一个接入的 Gateway。于是,整个系统架构的复杂度就会变得简单可控起来。
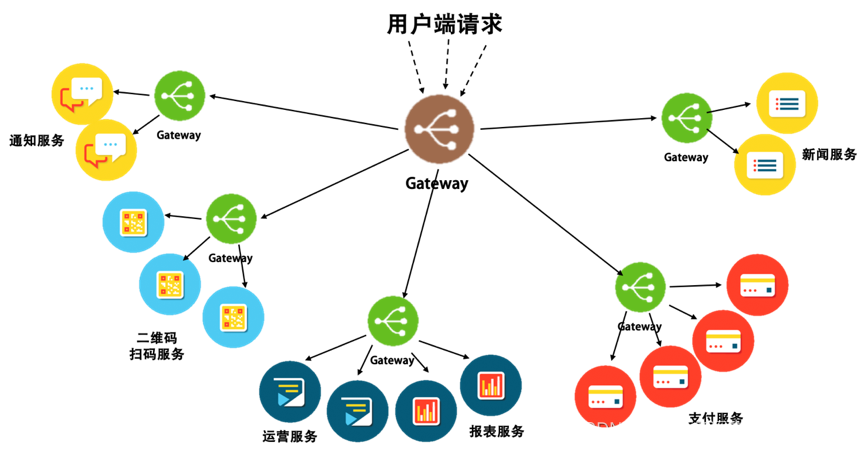
这张图展示了一个多层 Gateway 架构,其中有一个总的 Gateway 接入所有的流量(流量网关),并分发给不同的子系统,还有第二级 Gateway 用于做各个子系统的接入 Gateway(业务网关)。可以看到,网关所管理的服务粒度可粗可细。通过网关,我们可以把分布式架构组织成一个星型架构,由网络对服务的请求进行路由和分发。下面来聊聊好的网关应该具备哪些功能,也就是网关设计模式。
常见网关对比
既然对比,就先宏观上对各种网关有一个了解,后面再挑一些常用的或者说应用广泛的详细了解。
目前常见的开源网关大致上按照语言分类有如下几类:
Nginx+lua:OpenResty、Kong、Orange、Abtesting gateway 等Java:Zuul/Zuul2、Spring Cloud Gateway、Kaazing KWG、gravitee、Dromara soul 等Go:Janus、fagongzi、Grpc-gatewayDotnet:OcelotNodeJS:Express Gateway、Micro Gateway按照使用数量、成熟度等来划分,主流的有 4 个:
OpenRestyKongZuul/Zuul2Spring Cloud GatewayOpenResty
OpenResty是一个流量网关,根据前面对流量网关的介绍就可以知道流量网关的指责。
OpenResty基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
通过揉和众多设计良好的 Nginx 模块,OpenResty 有效地把 Nginx 服务器转变为一个强大的 Web 应用服务器,基于它开发人员可以使用 Lua 编程语言对 Nginx 核心以及现有的各种 Nginx C 模块进行脚本编程,构建出可以处理一万以上并发请求的极端高性能的 Web 应用
OpenResty 最早是顺应 OpenAPI 的潮流做的,所以 Open 取自“开放”之意,而Resty便是 REST 风格的意思。虽然后来也可以基于 ngx_openresty 实现任何形式的 web service 或者传统的 web 应用。
也就是说 Nginx 不再是一个简单的静态网页服务器,也不再是一个简单的反向代理了。第二代的 openresty 致力于通过一系列 nginx 模块,把nginx扩展为全功能的 web 应用服务器。
ngx_openresty 是用户驱动的项目,后来也有不少国内用户的参与,从 openresty.org 的点击量分布上看,国内和国外的点击量基本持平。
ngx_openresty 目前有两大应用目标:
通用目的的 web 应用服务器。在这个目标下,现有的 web 应用技术都可以算是和 OpenResty 或多或少有些类似,比如 Nodejs, PHP 等等。ngx_openresty 的性能(包括内存使用和 CPU 效率)算是最大的卖点之一。Nginx 的脚本扩展编程,用于构建灵活的 Web 应用网关和 Web 应用防火墙。有些类似的是 NetScaler。其优势在于 Lua 编程带来的巨大灵活性。Kong
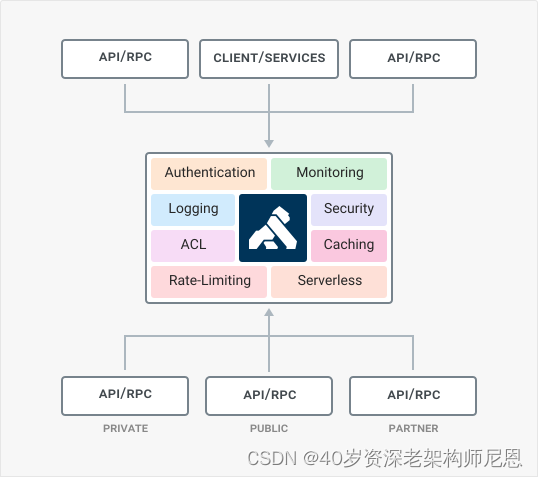
相关连接:官网、Github
Kong基于OpenResty开发,也是流量层网关, 是一个云原生、快速、可扩展、分布式的Api 网关。继承了OpenResty的高性能、易扩展性等特点。Kong通过简单的增加机器节点,可以很容易的水平扩展。同时功能插件化,可通过插件来扩展其能力。而且在任何基础架构上都可以运行。具有以下特性:
提供了多样化的认证层来保护Api。可对出入流量进行管制。提供了可视化的流量检查、监视分析Api。能够及时的转换请求和相应。提供log解决方案可通过api调用Serverless 函数。Kong解决了什么问题
当我们决定对应用进行微服务改造时,应用客户端如何与微服务交互的问题也随之而来,毕竟服务数量的增加会直接导致部署授权、负载均衡、通信管理、分析和改变的难度增加。
面对以上问题,API GATEWAY是一个不错的解决方案,其所提供的访问限制、安全、流量控制、分析监控、日志、请求转发、合成和协议转换功能,可以解放开发者去把精力集中在具体逻辑的代码,而不是把时间花费在考虑如何解决应用和其他微服务链接的问题上。
图片来自Kong官网:
可以看到Kong解决的问题。专注于全局的Api管理策略,全局流量监控、日志记录、全局限流、黑白名单控制、接入请求到业务系统的负载均衡等。
Kong的优点以及性能
在众多 API GATEWAY 框架中,Mashape 开源的高性能高可用API网关和API服务管理层——KONG(基于 NGINX+Lua)特点尤为突出,它可以通过插件扩展已有功能,这些插件(使用 lua 编写)在API请求响应循环的生命周期中被执行。于此同时,KONG本身提供包括 HTTP 基本认证、密钥认证、CORS、TCP、UDP、文件日志、API请求限流、请求转发及 NGINX 监控等基本功能。目前,Kong 在 Mashape 管理了超过 15,000 个 API,为 200,000 开发者提供了每月数十亿的请求支持。
Kong架构
Kong提供一些列的服务,这就不得不谈谈内部的架构:
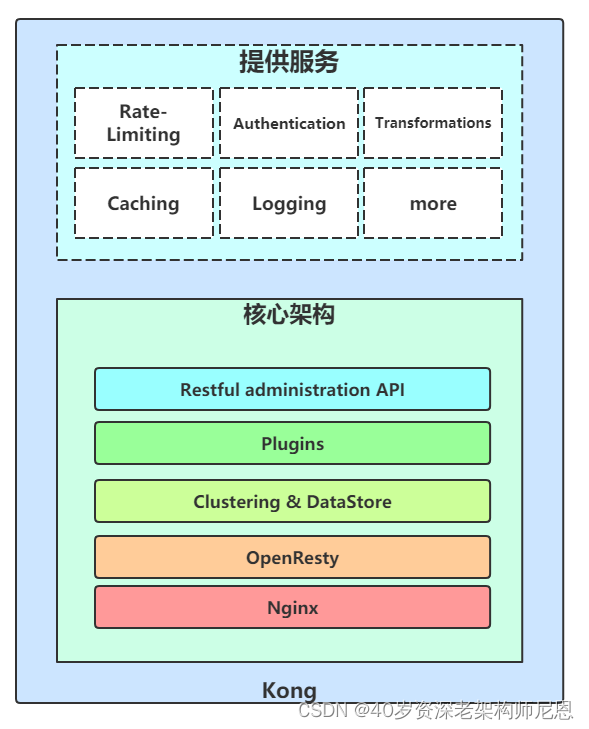
首先最底层是基于Nginx, Nginx是高性能的基础层, 一个良好的负载均衡、反向代理器,然后在此基础上增加Lua脚本库,形成了OpenResty,拦截请求, 响应生命周期,可以通过Lua编写脚本,所以插件比较丰富。
关于Kong的一些插件库以及如何配置,可以参考简书:开源API网关系统(Kong教程)入门到精通
Zuul1.0
Zuul是所有从设备和web站点到Netflix流媒体应用程序后端请求的前门。作为一个边缘服务应用程序,Zuul被构建来支持动态路由、监视、弹性和安全性。它还可以根据需要将请求路由到多个Amazon自动伸缩组。
Zuul使用了一系列不同类型的过滤器,使我们能够快速灵活地将功能应用到服务中。
过滤器
过滤器是Zuul的核心功能。它们负责应用程序的业务逻辑,可以执行各种任务。
Type : 通常定义过滤器应用在哪个阶段Async : 定义过滤器是同步还是异步Execution Order : 执行顺序Criteria : 过滤器执行的条件Action : 如果条件满足,过滤器执行的动作Zuul提供了一个动态读取、编译和运行这些过滤器的框架。过滤器之间不直接通信,而是通过每个请求特有的RequestContext共享状态。
下面是Zuul的一些过滤器:
Incoming
Incoming过滤器在请求被代理到Origin之前执行。这通常是执行大部分业务逻辑的地方。例如:认证、动态路由、速率限制、DDoS保护、指标。
Endpoint
Endpoint过滤器负责基于incoming过滤器的执行来处理请求。Zuul有一个内置的过滤器(ProxyEndpoint),用于将请求代理到后端服务器,因此这些过滤器的典型用途是用于静态端点。例如:健康检查响应,静态错误响应,404响应。
Outgoing
Outgoing过滤器在从后端接收到响应以后执行处理操作。通常情况下,它们更多地用于形成响应和添加指标,而不是用于任何繁重的工作。例如:存储统计信息、添加/剥离标准标题、向实时流发送事件、gziping响应。
过滤器类型
下面是与一个请求典型的生命周期对应的标准的过滤器类型:
PRE : 路由到Origin之前执行ROUTING : 路由到Origin期间执行POST : 请求被路由到Origin之后执行ERROR : 发生错误的时候执行这些过滤器帮助我们执行以下功能:
身份验证和安全性 : 识别每个资源的身份验证需求,并拒绝不满足它们的请求监控 : 在边缘跟踪有意义的数据和统计数据,以便给我们一个准确的生产视图动态路由 : 动态路由请求到不同的后端集群压力测试 : 逐渐增加集群的流量,以评估性能限流 : 为每种请求类型分配容量,并丢弃超过限制的请求静态响应处理 : 直接在边缘构建一些响应,而不是将它们转发到内部集群Zuul 1.0 请求生命周期
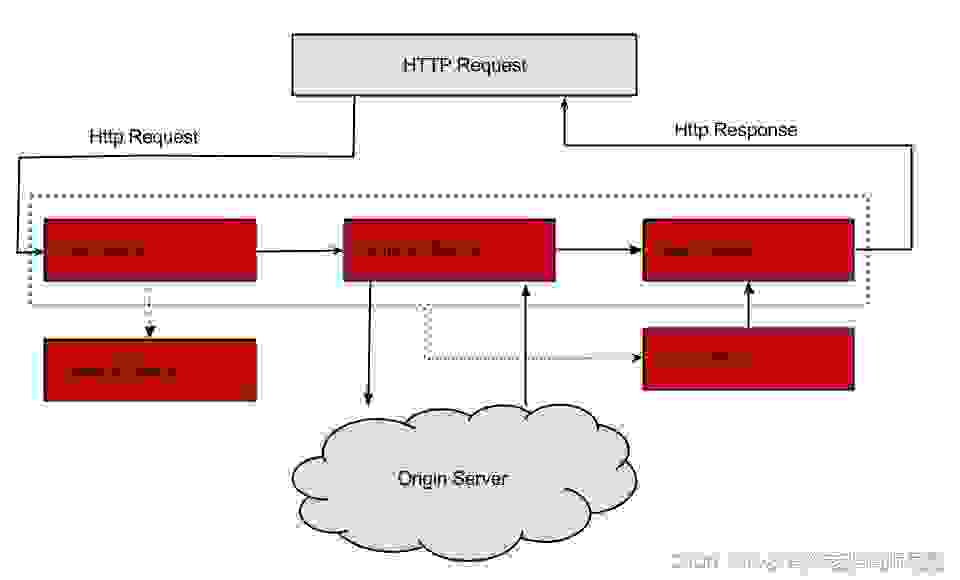
Netflix宣布了通用API网关Zuul的架构转型。Zuul原本采用同步阻塞架构,转型后叫作Zuul2,采用异步非阻塞架构。Zuul2和Zuul1在架构方面的主要区别在于,Zuul2运行在异步非阻塞的框架上,比如Netty。Zuul1依赖多线程来支持吞吐量的增长,而Zuul 2使用的Netty框架依赖事件循环和回调函数。
原理详见这篇: 尼恩编著的500页 PDF电子书 《Java高并发核心编程 卷3 加强版》,清华大学出版社出版
Zuul2.0
Zuul 2.0 架构图

上图是Zuul2的架构,和Zuul1没有本质区别,两点变化:
前端用Netty Server代替Servlet,目的是支持前端异步。后端用Netty Client代替Http Client,目的是支持后端异步。过滤器换了一下名字,用Inbound Filters代替Pre-routing Filters,用Endpoint Filter代替Routing Filter,用Outbound Filters代替Post-routing Filters。Inbound Filters : 路由到 Origin 之前执行,可以用于身份验证、路由和装饰请求
Endpoint Filters : 可用于返回静态响应,否则内置的ProxyEndpoint过滤器将请求路由到Origin
Outbound Filters : 从Origin那里获取响应后执行,可以用于度量、装饰用户的响应或添加自定义header
有两种类型的过滤器:sync 和 async。因为Zuul是运行在一个事件循环之上的,因此从来不要在过滤中阻塞。如果你非要阻塞,可以在一个异步过滤器中这样做,并且在一个单独的线程池上运行,否则可以使用同步过滤器。
上文提到过Zuul2开始采用了异步模型
优势是异步非阻塞模式启动的线程很少,基本上一个CPU core上只需启一个事件环处理线程,它使用的线程资源就很少,上下文切换(Context Switch)开销也少。非阻塞模式可以接受的连接数大大增加,可以简单理解为请求来了只需要进队列,这个队列的容量可以设得很大,只要不超时,队列中的请求都会被依次处理。
不足,异步模式让编程模型变得复杂。一方面Zuul2本身的代码要比Zuul1复杂很多,Zuul1的代码比较容易看懂,Zuul2的代码看起来就比较费劲。另一方面异步模型没有一个明确清晰的请求->处理->响应执行流程(call flow),它的流程是通过事件触发的,请求处理的流程随时可能被切换断开,内部实现要通过一些关联id机制才能把整个执行流再串联起来,这就给开发调试运维引入了很多复杂性,比如你在IDE里头调试异步请求流就非常困难。另外ThreadLocal机制在这种异步模式下就不能简单工作,因为只有一个事件环线程,不是每个请求一个线程,也就没有线程局部的概念,所以对于CAT这种依赖于ThreadLocal才能工作的监控工具,调用链埋点就不好搞(实际可以工作但需要进行特殊处理)。
总体上,异步非阻塞模式比较适用于IO密集型(IO bound)场景,这种场景下系统大部分时间在处理IO,CPU计算比较轻,少量事件环线程就能处理。
Zuul 与 Zuul 2 性能对比
图片来源:Zuul’s Journey to Non-Blocking

Netflix给出了一个比较模糊的数据,大致Zuul2的性能比Zuul1好20%左右,这里的性能主要指每节点每秒处理的请求数。为什么说模糊呢?因为这个数据受实际测试环境,流量场景模式等众多因素影响,你很难复现这个测试数据。即便这个20%的性能提升是确实的,其实这个性能提升也并不大,和异步引入的复杂性相比,这20%的提升是否值得是个问题。Netflix本身在其博文22和ppt11中也是有点含糊其词,甚至自身都有一些疑问的。
Spring Cloud Gateway
这里的基础资料: 尼恩编著的 400页PDF电子书 《SpringCloud Alibaba 技术圣经》
SpringCloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。
SpringCloud Gateway 作为 Spring Cloud 生态系统中的网关,目标是替代 Zuul,在Spring Cloud 2.0以上版本中,没有对新版本的Zuul 2.0以上最新高性能版本进行集成,仍然还是使用的Zuul 2.0之前的非Reactor模式的老版本。而为了提升网关的性能,SpringCloud Gateway是基于WebFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。
Spring Cloud Gateway 的目标,不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,和限流。
Spring Cloud Gateway 底层使用了高性能的通信框架Netty。
SpringCloud Gateway 特征
SpringCloud官方,对SpringCloud Gateway 特征介绍如下:
(1)基于 Spring Framework 5,Project Reactor 和 Spring Boot 2.0
(2)集成 Hystrix 断路器
(3)集成 Spring Cloud DiscoveryClient
(4)Predicates 和 Filters 作用于特定路由,易于编写的 Predicates 和 Filters
(5)具备一些网关的高级功能:动态路由、限流、路径重写
从以上的特征来说,和Zuul的特征差别不大。SpringCloud Gateway和Zuul主要的区别,还是在底层的通信框架上。
简单说明一下上文中的三个术语:
Filter(过滤器)
和Zuul的过滤器在概念上类似,可以使用它拦截和修改请求,并且对上游的响应,进行二次处理。过滤器为org.springframework.cloud.gateway.filter.GatewayFilter类的实例。
Route(路由)
网关配置的基本组成模块,和Zuul的路由配置模块类似。一个Route模块由一个 ID,一个目标 URI,一组断言和一组过滤器定义。如果断言为真,则路由匹配,目标URI会被访问。
Predicate(断言):
这是一个 Java 8 的 Predicate,可以使用它来匹配来自 HTTP 请求的任何内容,例如 headers 或参数。断言的输入类型是一个 ServerWebExchange。
网关对比总结

这里的基础资料: 尼恩编著的 400页PDF电子书 《SpringCloud Alibaba 技术圣经》
基于Spring Cloud Gateway 实现业务网关
API 网关的定义中我们提到了为什么要使用 API 网关,是为了解决客户端对多个微服务进行访问的问题。
由于服务的切分导致一个操作需要同时调用多个服务,因此为这些服务的聚合提供一个统一的门面,这个门面就是 API 网关。
针对于 API 网关有很多的实现方式,例如:Zuul,Kong 等等。这里我们以 Spring Cloud Gateway 为例展开给大家介绍其具体实现。
一般来说,API 网关对内将微服务进行集合,对外暴露的统一 URL 或者接口信息供客户端调用。
那么客户端是如何与微服务进行连接,并且进行沟通的,需要引入下面几个重要概念 。
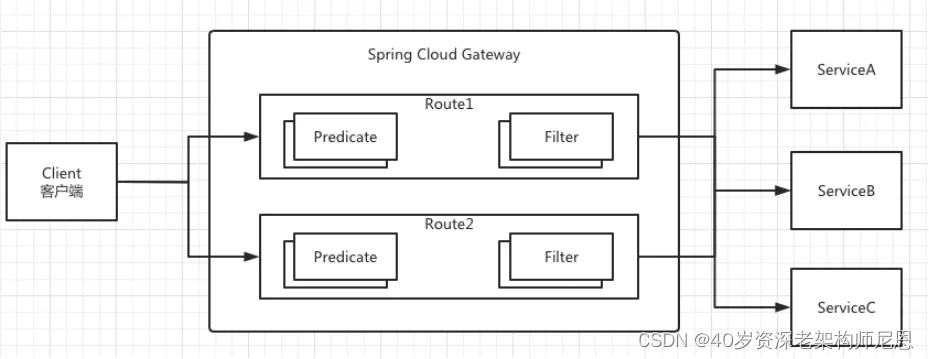
图 4:路由、断言和过滤器
如图 4 所示,Spring Cloud Gateway 由三部分组成:
①路由(Route):任何一个来自于客户端的请求都会经过路由,然后到对应的微服务中。
每个路由会有一个唯一的 ID 和对应的目的 URL。同时包含若干个断言(Predicate)和过滤器(Filter)。
②断言(Predicate):当客户端通过 Http Request 请求进入 Spring Cloud Gateway 的时候,断言会根据配置的路由规则,对 Http Request 请求进行断言匹配。
说白了就是进行一次或者多次 if 判断,如果匹配成功则进行下一步处理,否则断言失败直接返回错误信息。
③过滤器( Filter):简单来说就是对流经的请求进行过滤,或者说对其进行获取以及修改的操作。注意过滤器的功能是双向的,也就是对请求和响应都会进行修改处理 。
一般来说 Spring Cloud Gateway 中的过滤器有两种类型:
Gateway FilterGlobal FilterGateway Filter 用在单个路由和分组路由上。Global Filter 可以作用于所有路由,是一个全局的 Filter。
Spring Cloud Gateway 工作原理
尼恩编著的500页 PDF电子书 《Java高并发核心编程 卷3 加强版》,清华大学出版社出版
说完了 Spring Cloud Gateway 定义和要素,再来看看其工作原理。总的来说是对客户端请求的处理过程。
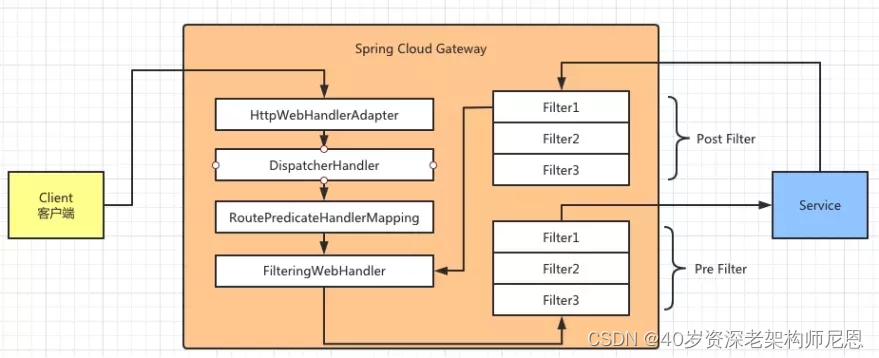
图 5:Spring Cloud Gateway 处理请求流程图
如图 5 所示,当客户端向 Spring Cloud Gateway 发起请求,该请求会被 HttpWebHandlerAdapter 获取,并且对请求进行提取,从而组装成网关上下文。
将组成的上下文信息传递到 DispatcherHandler 组件。DispatcherHandler 作为请求分发处理器,主要负责将请求分发到对应的处理器进行处理。
这里请求的处理器包括 RoutePredicate HandlerMapping (路由断言处理映射器) 。
路由断言处理映射器用于路由的查找,以及找到 路由后返回对应的 FilteringWebHandler。
其负责组装 Filter 链表并执行过滤处理,之后再将请求转交给应用服务,应用服务处理完后,最后返回 Response 给客户端 。
其中 FilteringWebHandler 处理请求的时候会交给 Filter 进行过滤的处理。
这里需要注意的是由于 Filter 是双向的所以,当客户端请求服务的时候,会通过 Pre Filter 中的 Filter 处理请求。
当服务处理完请求以后返回客户端的时候,会通过 Post Filter 再进行一次处理。
2Wqps Spring Cloud Gateway 网关实践
上面介绍了 Spring Cloud Gateway 的定义和实现原理,下面根据几个常用的场景介绍一下 Spring Cloud Gateway 如何实现网关功能的。
我们会根据基本路由、权重路由、限流、动态路由几个方面给大家展开介绍。
基本路由
基本路由,主要功能就是在客户端请求的时候,根据定义好的路径指向到对应的 URI。这个过程中需要用到 Predicates(断言)中的 Path 路由断言处理器。
基本路由 可以通过配置文件实现, 具体请参见 尼恩 400页 pdf 《SpringCloud Alibaba 圣经》
这里不做赘述
权重路由
这个使用场景相对于上面的简单路由要多一些。
由于每个微服务发布新版本的时候,通常会保持老版本与新版版同时存在。
然后通过网关将流量逐步从老版本的服务切换到新版本的服务。
这个逐步切换的过程就是常说的灰度发布。
此时,API 网关就起到了流量分发的作用,通常来说最开始的老版本会承载多一些的流量,例如 90% 的请求会被路由到老版本的服务上,只有 10% 的请求会路由到新服务上去。
从而观察新服务的稳定性,或者得到用户的反馈。当新服务稳定以后,再将剩下的流量一起导入过去。
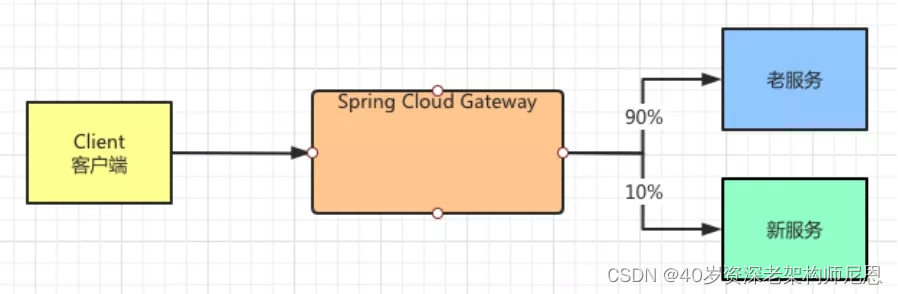
图 6:灰度发布,路由到新/老服务
在两个配置中对应的 URI 分别是新老两个服务的访问地址,通过http://localhost:8888/v1和http://localhost:8888/v2来区别。
在 Predicates(断言)中定义了的 Path 是想通的都是“/gatewaytest”,也就是说对于客户端来说访问的路径都是一样的,从路径上客户不会感知他们访问的是新服务或者是老服务。
主要参数是在 Weight,针对老/新服务分别配置的是 90 和 10。
也就是有 90% 的流量会请求老服务,有 10% 的流量会请求新服务。
简单点说,如果有 100 次请求,其中 90 次会请求 v1(老服务),另外的 10 次会请求 v2(新服务)。
限流
当服务在短时间内迎来高并发,并发量超过服务承受的范围就需要使用限流。例如:秒杀、抢购、下单服务。
通过请求限速或者对一个时间窗口内的请求进行限速来保护服务。当达到限制速率则可以拒绝请求,返回错误代码,或者定向到友好页面。
一般的中间件都会有单机限流框架,支持两种限流模式:
控制速率控制并发这里通过 Guava 中的 Bucket4j 来实现限流操作。
由于需要对于用户请求进行监控,因此通过实现 GatewayFilter 的方式自定义 Filter,然后再通过 Gateway API Application 应用这个自定义的 Filter。
可以基于令牌桶限流,因此需要设置桶的容量(capacity),每次填充的令牌数量(refillTokens)以及填充令牌的间隔时间(refillDuration)。
那么当用户访问 rateLimit 路径的时候就会根据客制化的 Filter 进行限流。
这里的限流只是给大家提供一种思路,通过实现 GatewayFilter,重写其中的 Filter 方法,加入对流量的控制代码,然后在 Spring Cloud Gateway 中进行应用就可以了。
有关令牌桶、漏桶限流的具体知识,请参见
尼恩编著的500页 PDF电子书 《Java高并发核心编程 卷3 加强版》,清华大学出版社出版
动态路由
由于 Spring Cloud Gateway 本身也是一个服务,一旦启动以后路由配置就无法修改了。
无论是上面提到的编码注入的方式还是配置的方式,如果需要修改都需要重新启动服务。
如果回到 Spring Cloud Gateway 最初的定义,我们会发现每个用户的请求都是通过 Route 访问对应的微服务,在 Route 中包括 Predicates 和 Filters 的定义。
只要实现 Route 以及其包含的 Predicates 和 Filters 的定义,然后再提供一个 API 接口去更新这个定义就可以动态地修改路由信息了。
按照这个思路需要做以下几步来实现:
①定义 Route、Predicates 和 Filters
其中 Predicates 和 Filters 包含在 Route 中。实际上就是 Route 实体的定义,针对 Route 进行路由规则的配置。
②实现路由规则的操作,包括添加,更新,删除
有了路由的定义(Route,Predicates,Filters),然后再编写针对路由定义的操作。
例如:添加路由,删除路由,更新路由之类的。编写 RouteServiceImpl 实现 ApplicationEventPublisherAware。
主要需要 override 其中的 setApplicationEventPublisher 方法,这里会传入 ApplicationEventPublisher 对象,通过这个对象发布路由定义的事件包括:add,update,delete。
③对外部提供 API 接口能够让用户或者程序动态修改路由规则
从代码上来说就是一个 Controller。这个 Controller 中只需要调用 routeServiceImpl 就行了,主要也是用到客制化路由实现类中的 add,update,delete 方法。
说白了就是对其进行了一次包装,让外部系统可以调用,并且修改路由的配置。
④启动程序进行路由的添加和更新操作
假设更新 API 网关配置的服务在 8888 端口上。
于是通过 http://localhost:8888/actuator/gateway/routes 访问当前的路由信息,由于现在没有配置路由这个信息是空。
那么通过 http://localhost:8888/route/add 方式添加一条路由规则。可以设置 Route,当 Predicates 为 baidu 的时候,将请求引导到 www.baidu.com 的网站进行响应。
此时再通过访问 http://localhost:8888/baidu 的路径访问的时候,就会被路由到 www.baidu.com 的网站。
此时如果需要修改路由配置,可以通过访问 http://localhost:8888/route/update 的 API 接口,通过 Post 方式传入 Json 结构
在更新完成以后,再访问 http://localhost:8888/CTO 的时候就会把引导到目标的网站了。
这里的参考资料:
尼恩编著的400页PDF电子书 《SpringCloud Alibaba 技术圣经》
尼恩编著的500页 PDF电子书 《Java高并发核心编程 卷3 加强版》,清华大学出版社出版
pdf领取方式,请参见公众号: 技术自由圈
10W qps 天翼网关系统 架构演进历程
原文链接:https://xie.infoq.cn/article/c6703d216c43c2b522b9b4ffa
作者:陈鑫、余文、丁嘉嘉
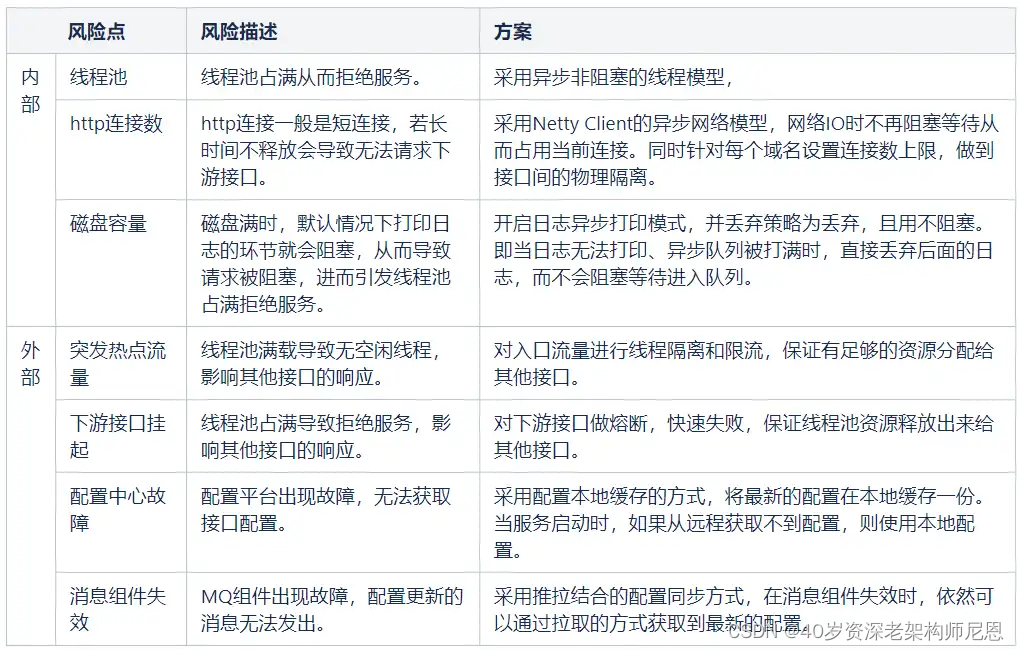
1、前言
天翼账号是中国电信打造的互联网账号体系产品,利用中国电信管道优势为企业提供用户身份认证能力。 其中网关系统是天翼账号对外能力开放体系的重要组成:业务侧它以集中入口、集中计费、集中鉴权管控为目标,技术侧它支持隔离性、可配置、易开发、动态路由、可降级、高并发等场景。
自 2017 年天翼账号网关系统上线以来,历经数次互联网的营销大促活动,特别是 2021 年的春节红包活动和刚过去双 11 活动,天翼账号网关系统在 10 万级 QPS 和 10 亿级日请求量的情况下,各项指标依然保持平稳,顺利保障合作方活动的开展。在天翼账号产品能力不断提升的背后,是天翼账号网关系统架构技术迭代发展的过程。
2、天翼账号网关演进
2.1 重点演进历程介绍
2017 年~ 2021 年天翼账号网关系统经历数次重要更迭升级,每次升级都给产品带来新的发展机会,系统总体演进过程如下:

2.2 天翼账号网关系统 1.0
2017 年初,天翼账号技术团队基于开源微服务网关 Zuul 组件开展了网关系统 1.0 的建设。
Zuul 是 Spring Cloud 工具包 Netflix 分组的开源微服务网关,它和 Eureka、ribbon、hystrix 等组件配合使用,本质是通过一系列的核心 filter,来实现请求过程的认证安全、动态路由、数据转化、熔断保护等功能。
其系统核心运行流程如下:
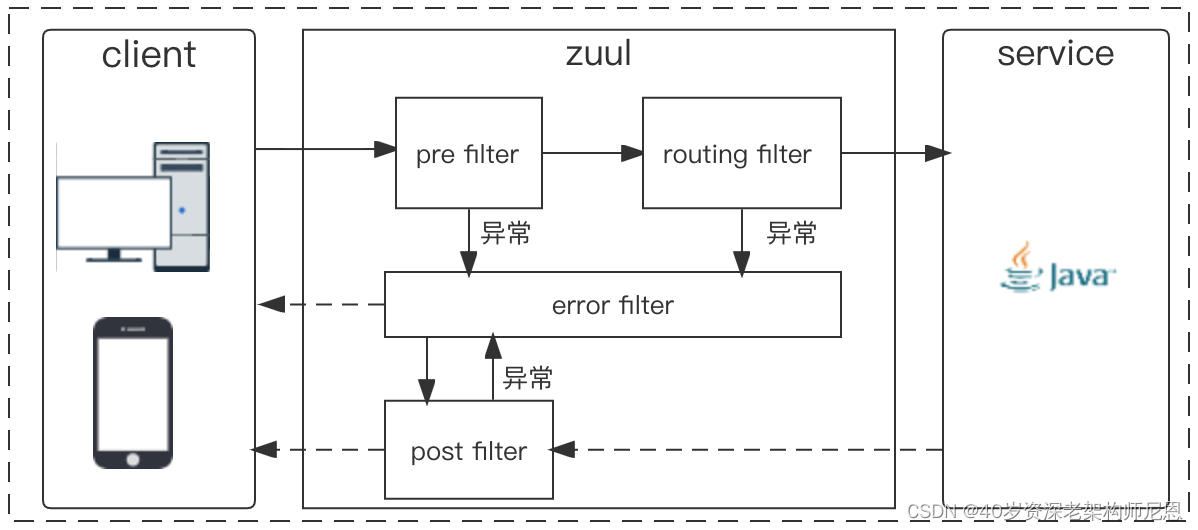
2018 年中,随着天翼账号推出免密认证系列产品的快速发展,网关系统 1.0 的缺点日益凸显主要表现在两个方面:
性能瓶颈: 微服务网关 Zuul 组件基于 Servlet 框架构建,采用的是阻塞和多线程方式实现,高并发下内部延迟严重,会造成连接增多和线程增加等情况,导致阻塞发生,在实际业务应用中单机性能在 1000 QPS 左右。灵活度有限:为了实现路由和 Filter 动态配置,研发人员需要花费时间去整合开源适配 Zuul 组件控制系统。为应对业务高峰,技术侧常采用横向扩展实例的策略来实现对高并发的支持,该策略给系统稳定性带来一定的风险,同时部署大量的网关服务器也提高产品的运营维护成本,因此网关系统架构升级迫在眉睫。
2.3 天翼账号网关系统 2.0
2.3.1 技术选型
互联网企业常见的方案有基于 Openresty 的 Kong、Orange,基于 Go 的 Tyk 和基于 Java 的 Zuul:
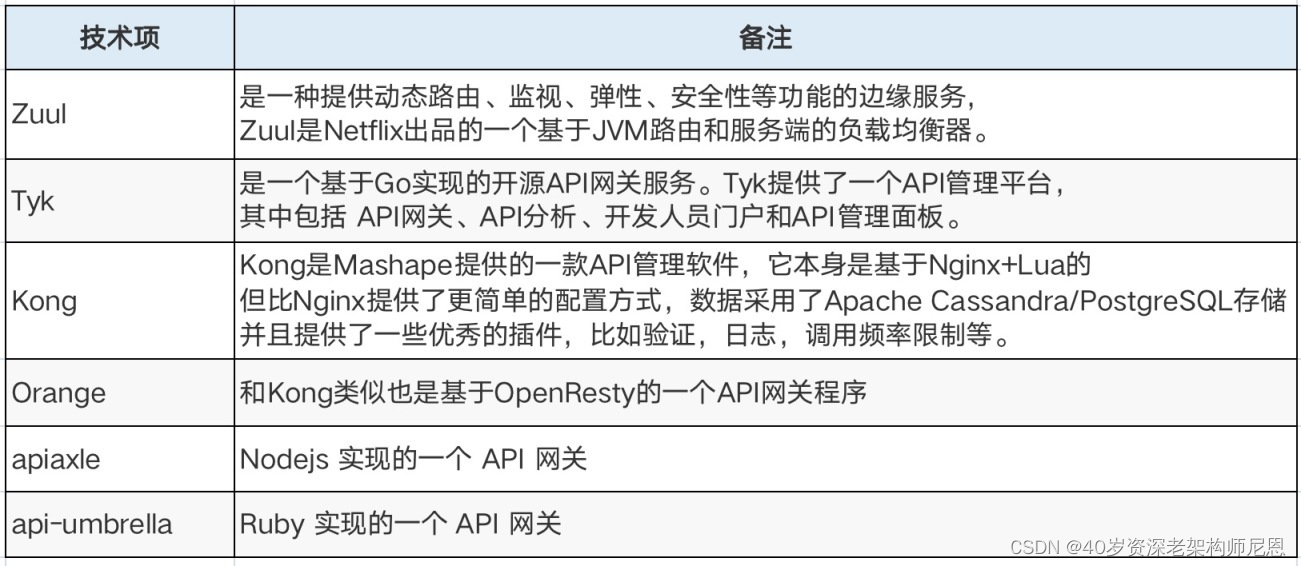
apiaxle、api-umbrella: 考虑到学习成本和项目后期发展的兼容性,其语言和框架不在团队优先考虑范围
Zuul:目前正在应用中,Zuul 处理请求的方式是针对每个请求都启用一个线程来处理。通常情况下,为了提高性能,所有请求被放到处理队列中,等待空闲线程来处理。当存在大量请求超时后会造成 Zuul 线程阻塞,目前只能通过横向扩展 Zuul 实例实现对高并发的支持。而 Zuul2.0 将 HTTP 请求的处理方式从同步变成了异步,以此提升处理性能。但团队内部对继续采用 Zuul 比较慎重,原因主要有以下两点:
版本稳定性需要斟酌 ,Zuul 的开源社区比较活跃,一直在更新状态应用企业较少,除了 Netflix,目前 Zuul 在企业中的应用还比较少,性能和稳定性方面还有待观察Nginx: 高性能的 HTTP 和反向代理 Web 服务器,应用场景涉及负载均衡、反向代理、代理缓存、限流等场景。但 Nginx 作为 Web 容器应用场景较少。Nginx 性能优越,而 Nginx 开发主要是以 C/C++ 模块的形式进行,整体学习和开发成本偏高。Nginx 团队开发了 NginxScript,可以在 Nginx 中使用 JavaScript 进行动态配置变量和动态脚本执行。
目前行业应用非常成熟的扩展是由章亦春将 Lua 和 Nginx 黏合的 ngx_Lua 模块,将 Nginx 核心、LuaJIT、ngx_Lua 模块、多功能 Lua 库和常用的第三方 Nginx 模块整合成为 OpenResty。开发人员安装 OpenResty,使用 Lua 编写脚本,部署到 Nginx Web 容器中运行,能轻松地开发出高性能的 Web 服务。OpenResty 具有高性能,易扩展的特点,成为了团队首选。同时也面临两个选项:
基于 OpenResty 自建,例如:一个类似于某东 JEN 的系统对开源框架二次开发,例如:Kong、Orange根据调研结果,团队衡量学习成本和开发周期等因素,最终决定采用对 Kong 框架二次开发的方案。以下是调研后的一些对比总结,仅供参考,如有疏漏,请不吝指出。

2.3.2 架构升级
天翼账号技术团队制定了网关系统 2.0 演进方案,部署架构如图:
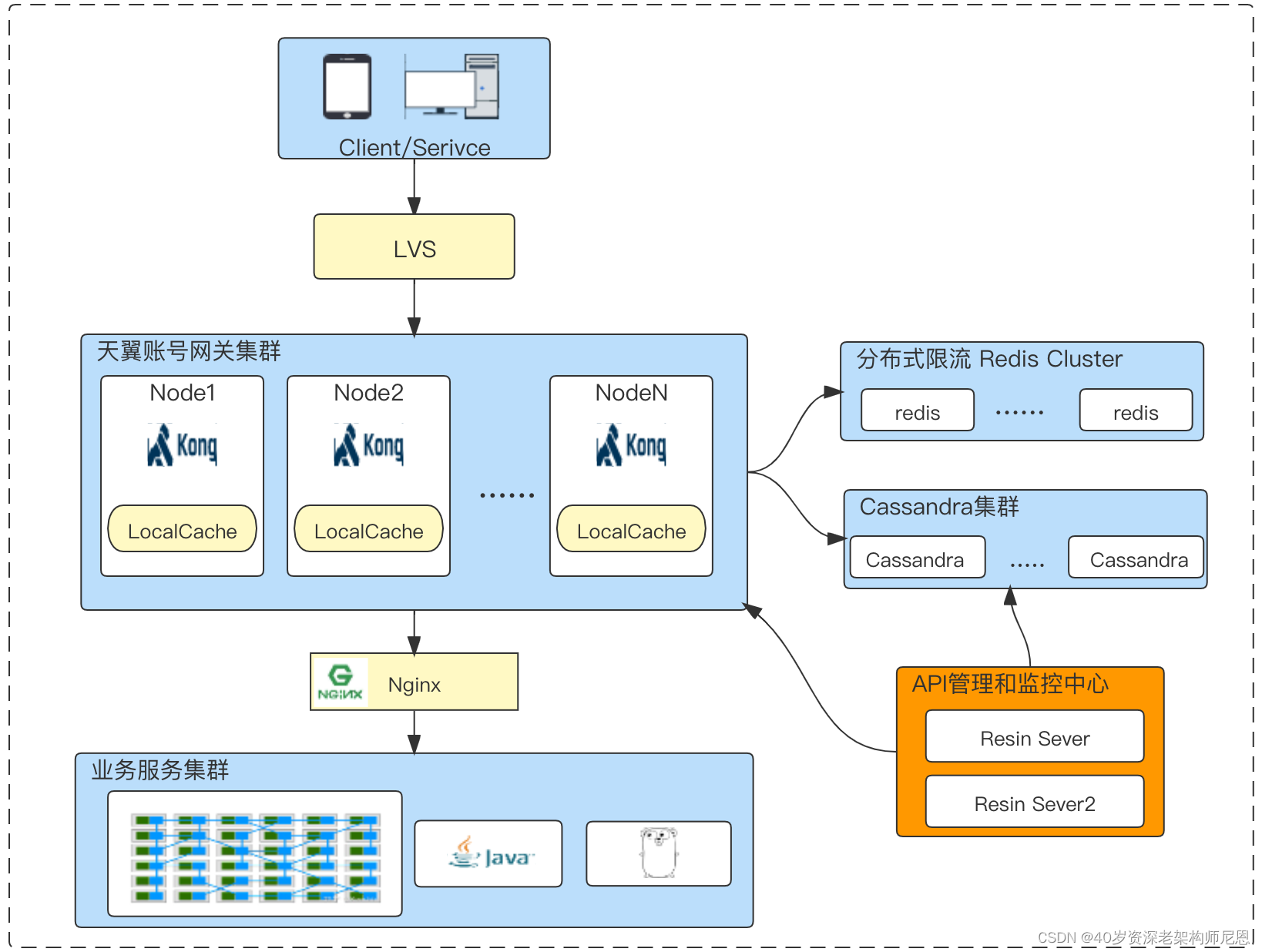
除了 Kong 网关自带的原生组件外,2.0 网关系统还相继研发出:加密鉴权、日志处理、参数转换、接口协议、消息队列、服务稳定、链路追踪及其它等 8 大类共计约 30 多个组件。
丰富的自研组件,保障了系统架构平稳的升级和业务的灵活性:
支持产品 Appkey 认证,SSL/TLS 加密,支持针对 IP 或应用的黑、白名单符合自身业务的协议插件,包括了常见的加密、签名算法和国密 sm2,sm3,sm4 等金融级别的算法监控和统计方面增加了基于 Redis、Kafka 的异步日志汇聚、统计方式,并支持 Zipkin、Prometheus 的追踪、监控增加多种按业务精细化分类的限流熔断策略,进一步完善服务保障体系
2.3.3 效果
网关 2.0 通过对 Kong 组件自研插件的开发和改造,实现了符合产品特性、业务场景的相关功能,也抽象了网关的通用功能。相较于 1.0 版本,具备以下优点:
支持插件化,方便自定义业务开发支持横向扩展,高性能、高并发、多级缓存高可用、高稳定性,具备隔离、限流、超时与重试、回滚机制插件热启用,即插即拔、动态灵活、无需重启,能快速适用业务变化为了验证新架构的性能,团队对网关系统 2.0 进行了压测:

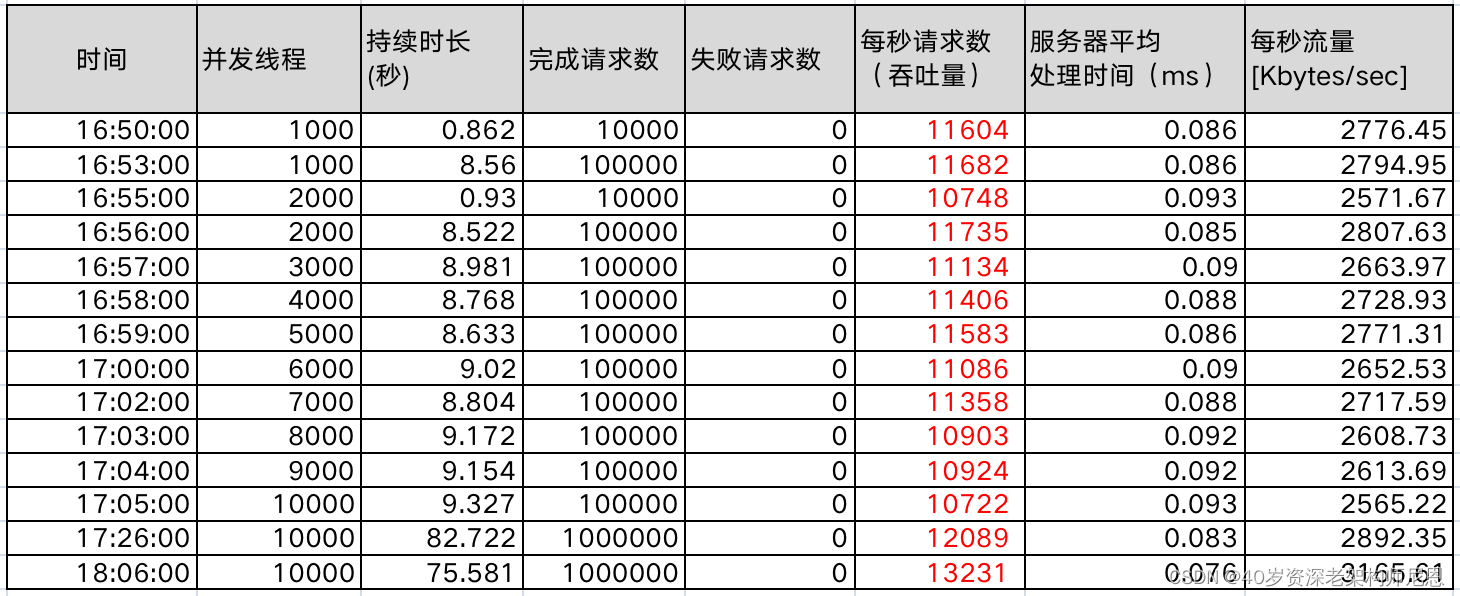
压测结果表明,天翼账号网关系统 2.0 已经达到单机万级 QPS,自研插件运行效率较高,对于网关性能的影响较小。
天翼账号网关系统 2.0 初期是基于 Kong-v0.14.0 版本开发,运行至 2019 年 5 月时,Kong 已经更新到 v1.1.X 版本,有很多重要的功能和核心代码更新,而且为了便于跟 Kubernetes 集成,团队决定将版本升至 v1.1.X。
通过同步迁移、并行运行的方式天翼账号网关系统 2.1 于 2019 年 9 月完成 Kong-v1.3 版本的升级。
期间天翼账号网关系统仍平稳地完成了 2018 年阿里双 11 活动、2019 年春节活动等大型高并发场景的支撑工作。
2020 年 3 月,网关 2.1 及底层微服务完成了镜像化改造,即可通过 Kubernetes 自动编排容器的方式部署,在动态扩容等方面有较大的提升。
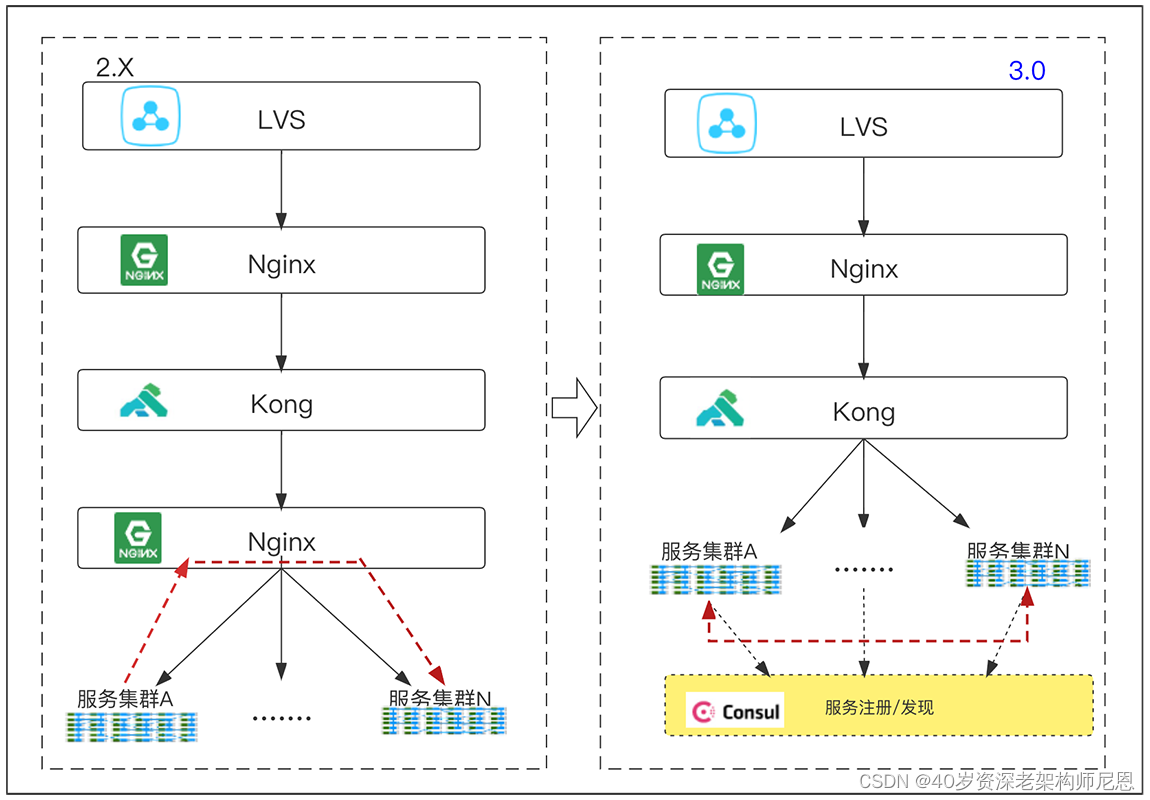
2.4 天翼账号网关系统 3.0
随着免密认证逐渐成为互联网应用作为首选登录方式,互联网头部企业要求认证产品 SLA 相关技术指标对齐其内部指标,为了支撑产品精细化运营和进一步的发展,保障产品 SLA 合同及性能指标,技术团队制定了网关系统 3.0 演进方案。
3.0 网关部署架构图如下:

2.4.1 DP(Data Plane) 升级
2.4.1.1 Kong 组件升级
团队摸余(鱼)工程师对开源项目 Kong 的版本发布一直保持着较高的关注度,总结两年来 Kong 主要版本升级新特性:
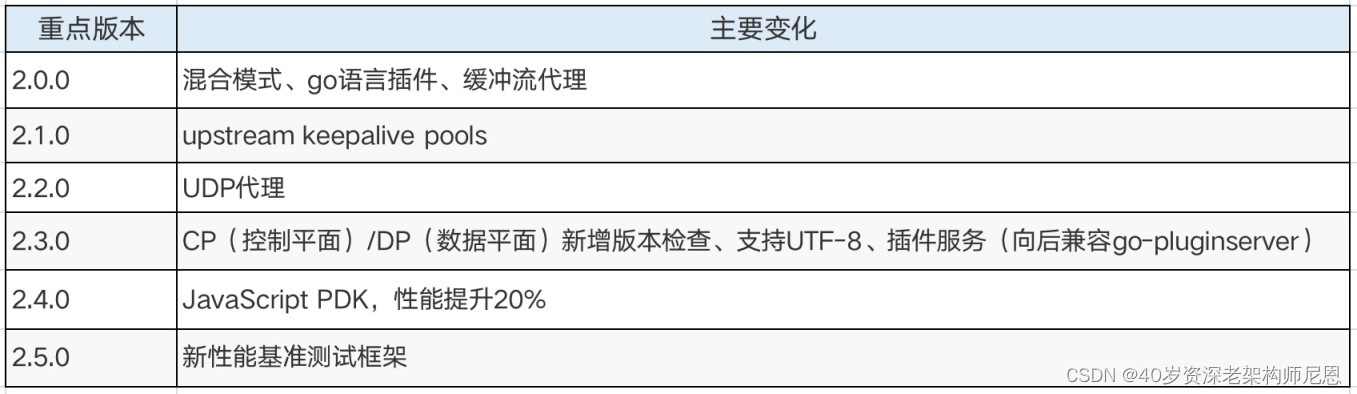
考虑到 Kong 2.5.0 版本为刚刚发布的版本,采用的企业用户不多,且开源社区对之前发布的 V2.4.0 版有较好的评价,因此团队评审后决定升级到 V2.4.0。
Kong 2.4.0 采用 OpenResty1.19.3.1,基于 Nginx 1.19.3,官方文档测试单 Worker 可达 269,423 QPS。以 2.0 版本同样环境压测,天翼账号网关系统 3.0(Kong 2.4) QPS 可达到 2W+,对比天翼账号网关 2.X(Kong 1.3) QPS 1W+,性能预估可提升 80% 以上。
Kong 2.4.0 组件采用控制面 / 数据面(CP/DP) 混合部署新模式,具备以下优势:
功能解耦混合部署模式,CP 负责将配置数据推动到 DP 节点,DP 节点负责流量数据处理。
运行稳定当 CP 不可用时,DP 可按照本地存储的配置进行流量业务处理,待 CP 恢复,DP 会自动连接更新配置。
支持多语言插件在原有 Lua 插件的基础上,支持使用 JavaScript 、TypeScript、GO 编写插件,后端 GO 语言团队可进行相关扩展。
支持 UDP 代理Routes、Services、Load Balancing、日志插件支持 UDP 代理,满足业务发展需要。
2.4.1.2 精确网关分组
顶层采用分域名业务隔离,同时根据业务特性、保障级别、访问并发量等特点,
对网关集群进行分组,完成子业务关联性解耦,在应对大流量冲击时降低对业务的影响,同时方便运维侧精准扩容。
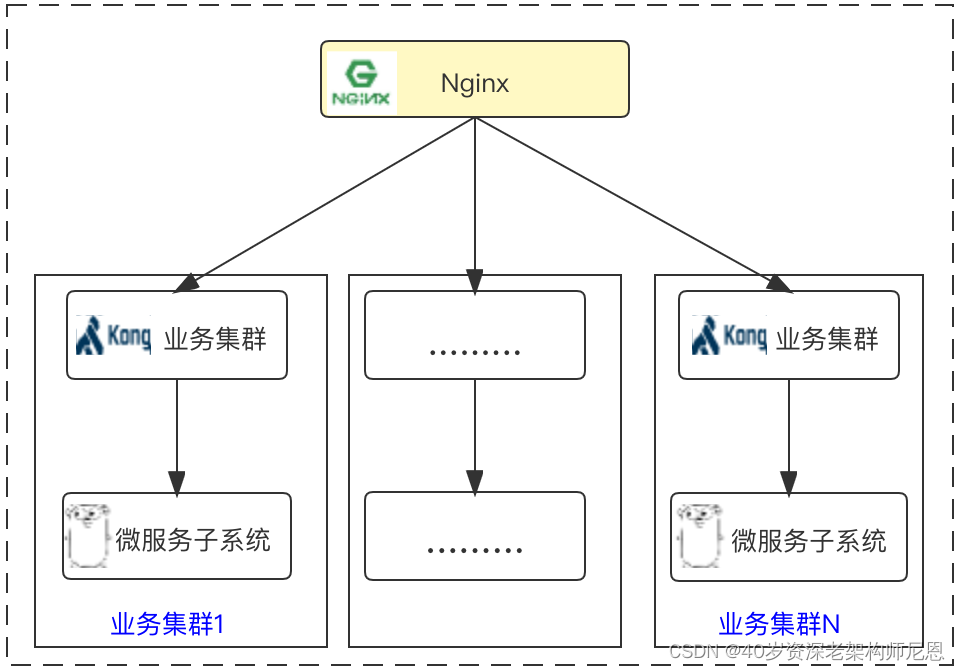
2.4.1.3 混合云
新建阿里云节点,作为天翼账号产品双活系统的补充节点,在高并发时可由 DNS 调度实现自动切换,确保提供无间断的服务。
2.4.2 CP(Control Plane) 升级
2.4.2.1 优化调用链路
增加 Consul 作为服务发现、配置管理中心服务,替换原有 Nginx 层路由功能。
对 Kong 组件提供 DNS 路由及发现服务,通过 Check 方式检查微服务是否可用。
2.4.2.2 新增插件
DP 缓存控制插件Kong 2.4 采用 DP 和 CP 混合部署模式,DP 平面的节点无管理端口,原 Kong 1.3 通过 admin API 管理缓存的模式无法适用现有场景,因此研发了 c-cache-manage 插件,添加后,可通过数据层面 URL 请求对 DP 缓存进行管理。
流量复制插件为了测试网关 3.0 的适用性,团队自研流量复制插件,复制现网流量对网关 3.0 进行测试,整个测试过程不影响现网环境。
插件运行流程如下:
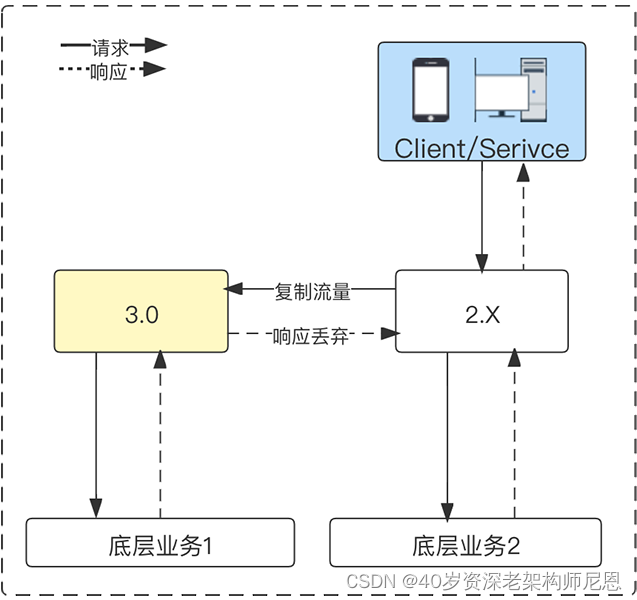
Konga 配置界面参考:
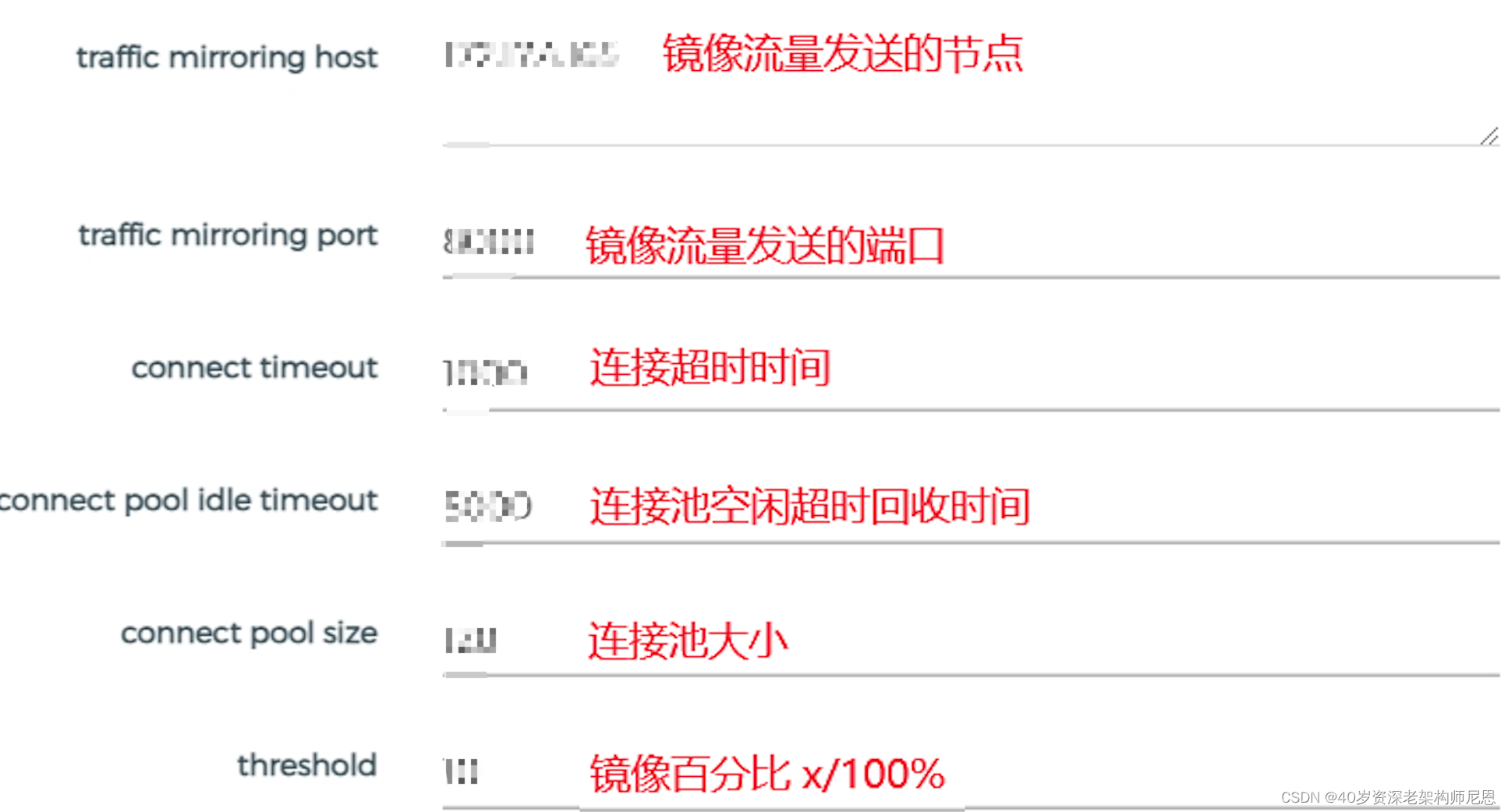
为了更好的展示 DP 和 CP 层面的数据,对自带 Prometheus 插件进行改造,增加 DP、CP 角色维度,区分并收集数据平面相关监控指标。
2.4.2.3 完善预警监控
在系统原有的监控的基础上,增加业务处理监控,通过业务处理监控,可将异常被动通知,转为主动发现。业务出现异常,可第一时间协助客户处理,提升系统的效能。
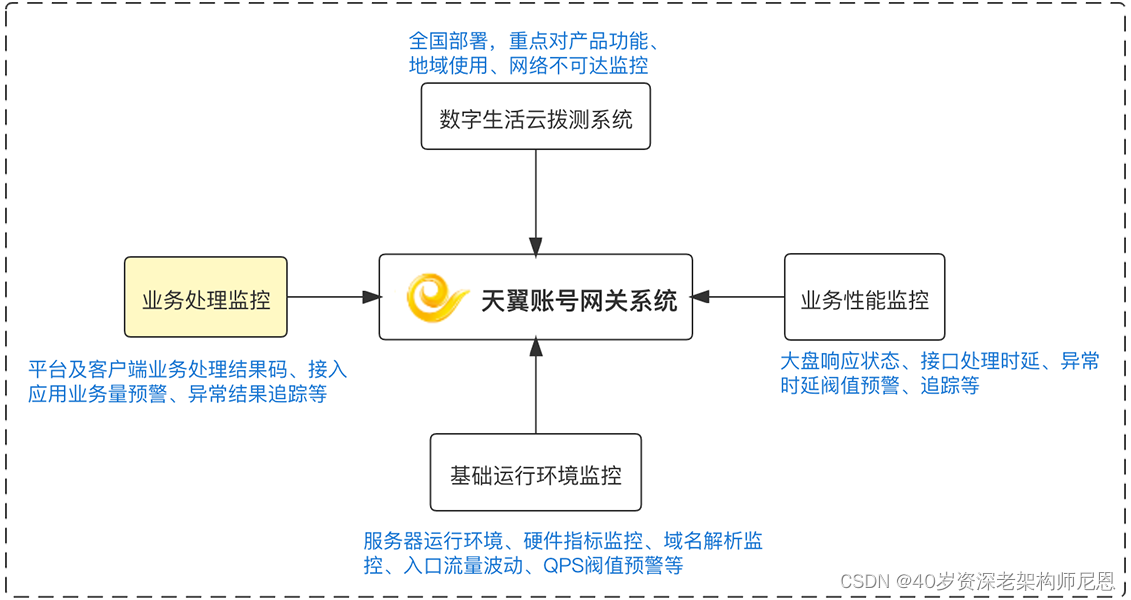
2.4.3 效果
演进完成后天翼账号网关系统 3.0 具备以下优势:
高并发,可支撑十万级 QPS高可用 ,保障系统 SLA 达到 99.96%灵活性伸缩性、 DNS 调度自动切换,可通过阿里云 ACK 迅速扩容丰富开发和应用场景,支持多语言插件(Go、Javascript、Lua), 支持 UDP 代理天翼账号网关系统 3.0 的部署,有效地保障了系统服务 SLA 等各项指标的达成。在今年双 11 期间十万级并发高峰时,系统 TP99 保持在 20MS 以内,总体表现非常稳定。
3、后序
天翼账号网关经过多次演进,已日趋完善,总结其优势如下:
系统性能大幅度提升,天翼账号网关系统 3.0 相较 1.0 性能提升 20 倍以上统一网关流量入口,超过 90% 以上流量由天翼账号网关系统管控系统可用性得到加强,建立了基于 DNS 调度自动切换的三节点、混合云稳定架构标准化可复用的插件,如频控限流、降级熔断、流量复制、API 协议等标准化插件丰富的多语言插件能力,Lua、Go、Javascript 的插件,可满足不同技术团队的需求天翼账号网关系统在中国电信统一账号能力开放平台中处于举足轻重的地位,它的迭代升级,为平台十万级高并发提供了坚实的保障,也为系统维护减少了难度、提升了便捷性,顺利支撑业务达成亿级收入规模。
天翼账号技术团队在 follow 业界主流网关技术的同时,也注重强化网关插件的标准化、服务化建设,希望通过网关能力反哺其它产品赋能大网。
随着中国电信服务化、容器化、全面上云的战略推进,天翼账号网关的系统架构也将随之变化,从全传统环境到部分云化再到全量上云,不断的向更贴近业务,更适用技术发展的形态演进。
本文的版本计划和基础学习资料:
尼恩作为技术中台的架构师, 网关是尼恩架构的重点, 所以,后面会大家从 架构到实操, 完成一个 10Wqps 超高并发 网关实操指导。
而且尼恩指导简历的过程中,也指导过小伙伴写过 10Wqps 超高并发 网关简历,里边涉及到大量的设计模式, 小伙伴的简历,里边立马金光闪闪。后面有机会,带大家做一下这个高质量的实操,并且指导大家写入简历。
所以,这个材料后面也会进行持续迭代,大家可以找尼恩来获取最新版本和技术交流。
尼恩编著的400页PDF电子书 《SpringCloud Alibaba 技术圣经》
尼恩编著的500页 PDF电子书 《Java高并发核心编程 卷3 加强版》,清华大学出版社出版
pdf领取方式,请参见公众号: 技术自由圈
推荐阅读:
尼恩N篇硬核架构 文章 ,帮你实现 架构自由:
《吃透8图1模板,人人可以做架构》
《10Wqps评论中台,如何架构?B站是这么做的!!!》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《100亿级订单怎么调度,来一个大厂的极品方案》
《2个大厂 100亿级 超大流量 红包 架构方案》
… 更多架构文章,正在添加中
实现你的响应式 自由:
《响应式圣经:10W字,实现Spring响应式编程自由》
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Nacos (史上最全)》
《nacos高可用(图解+秒懂+史上最全)》
《sentinel (史上最全)》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《SpringCloud+Dubbo3 = 王炸 !》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
《Linux命令大全:2W多字,一次实现Linux自由》
实现你的 网络 自由:
《TCP协议详解 (史上最全)》
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
《阿里一面:你做过哪些代码优化?来一个人人可以用的极品案例》
《网易二面:CPU狂飙900%,该怎么处理?》
《场景题:假设10W人突访,你的系统如何做到不 雪崩?》
《Nginx面试题(史上最全 + 持续更新)》
《K8S面试题(史上最全 + 持续更新)》
《操作系统面试题(史上最全、持续更新)》
《Docker面试题(史上最全 + 持续更新)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《单例模式(史上最全)》
《红黑树( 图解 + 秒懂 + 史上最全)》
《分布式事务 (秒懂)》
《Docker原理(图解+秒懂+史上最全)》
《Zookeeper Curator 事件监听 - 10分钟看懂》
《Netty 粘包 拆包 | 史上最全解读》
《Netty 100万级高并发服务器配置》
《Springcloud 高并发 配置 (一文全懂)》