涵盖所有考点,复习绝对高效,点赞+留邮箱获取pdf版本
山东大学编译原理复习提纲
一、简答与计算
1.1 必考
1. 编译过程
画图表示编译过程的各阶段,并简要说明各阶段的功能: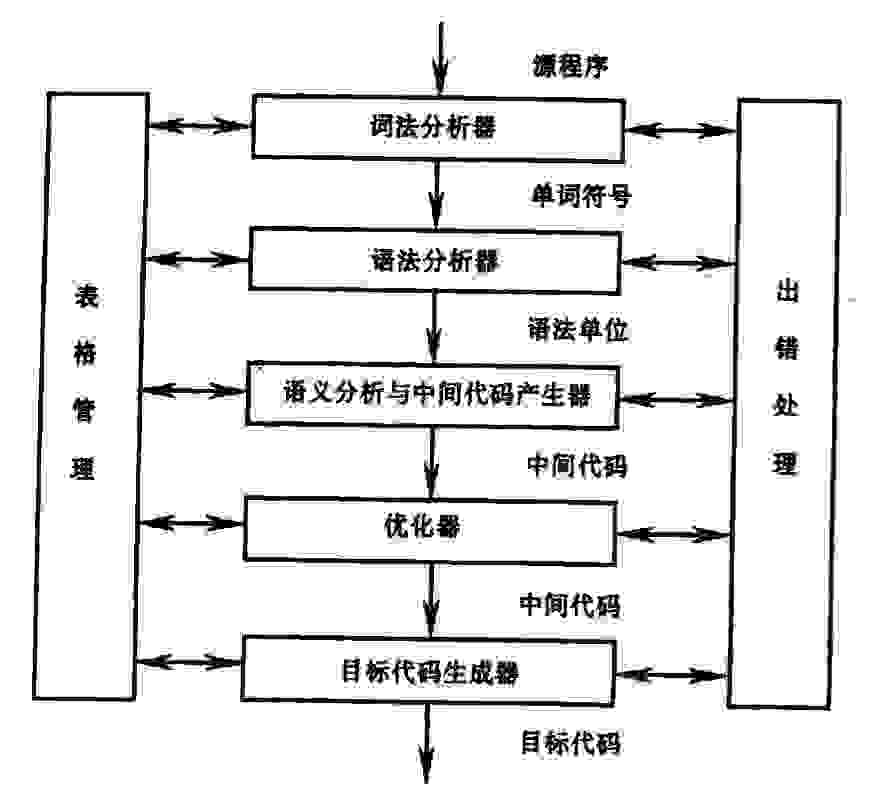 词法分析器:输入源程序,进行词法分析,输出单词符号;语法分析器:根据文法构建分析表,对单词符号进行语法分析,检查程序是否符合语法规则;语义分析与中间代码生成器:按照文法翻译规则对语法分析器归约出的语法单位进行语义分析,并把它们翻译成一定形式的中间代码;优化器:对中间代码进行优化处理;目标代码生成器:把中间代码翻译成目标代码。
词法分析器:输入源程序,进行词法分析,输出单词符号;语法分析器:根据文法构建分析表,对单词符号进行语法分析,检查程序是否符合语法规则;语义分析与中间代码生成器:按照文法翻译规则对语法分析器归约出的语法单位进行语义分析,并把它们翻译成一定形式的中间代码;优化器:对中间代码进行优化处理;目标代码生成器:把中间代码翻译成目标代码。 2. 消除左递归


如果从开始符号依次推导出 A1 A2 A3 ,则按其逆序排序时得到的产生式最少。
3. 消除回溯

通过反复提取左公因子可以消除回溯。
4. 提左公因子

5. 后缀表达式
中缀转后缀算法:
初始化符号栈,顺序读取中缀表达式,遇到 ( 则将其入栈,遇到 ) 则依次弹出栈顶元素到结果串中,直到遇到 ( ,将其出栈但不附加到结果串;
遇到 +-,弹出栈顶的所有操作符,附加到结果串中,然后自己进栈;
遇到 */,先让栈顶的 */ 出栈,附加到结果串中,然后自己进栈;
遇到数字,直接附加到结果串中;
最后若符号栈非空,将符号栈栈顶元素依次附加到结果串中。
// 中缀转后缀vector<string> interToPost(vector<string> vec){vector<string> res;stack<string> op_stack;for (int i = 0; i < vec.size(); i++) {if (vec[i] == "(")op_stack.push(vec[i]);else if (vec[i] == ")") {while (op_stack.top() != "(") {res.push_back(op_stack.top());op_stack.pop();}// 左括号出栈op_stack.pop(); }// 遇到+-,先让栈中的+-*/出栈else if (vec[i] == "+" || vec[i] == "-") {while (!op_stack.empty() && op_stack.top() != "(") {res.push_back(op_stack.top());op_stack.pop();}op_stack.push(vec[i]);}// 遇到*/,先让栈中的*/出栈else if (vec[i] == "*" || vec[i] == "/") {while (!op_stack.empty() && (op_stack.top() == "*" || op_stack.top() == "/")) {res.push_back(op_stack.top());op_stack.pop();}op_stack.push(vec[i]);}elseres.push_back(vec[i]);}while (!op_stack.empty()) {res.push_back(op_stack.top());op_stack.pop();}return res;}计算后缀表达式:
初始化数据栈,顺序读取后缀表达式,遇到操作符 op 则将栈次顶元素 op 栈顶元素,弹出操作数并压入运算结果;
遇到数据,则直接压入栈顶;
最终栈顶元素就是结果。
// 计算后缀表达式double solvePostPrefix(vector<string> post_prefix) {stack<double> dataStack;double num1, num2, result;for (auto x : post_prefix) {if (x == "+" || x == "-" || x == "*" || x == "/") {num1 = dataStack.top();dataStack.pop();num2 = dataStack.top();dataStack.pop();if (x == "+")result = num2 + num1;if (x == "-")result = num2 - num1;if (x == "*")result = num2 * num1;if (x == "/")result = num2 / num1;dataStack.push(result);}else {double num = strToDouble(x);dataStack.push(num);}}return dataStack.top();}1.2 选考
1. 编译、翻译和解释
翻译程序:把一种语言程序(源语言)转换成另一种语言程序(目标语言);编译程序:源语言为高级语言,目标语言为低级语言的翻译程序;解释程序:以源语言作为输入,但不产生目标程序,而是边翻译边执行源程序本身。2. 中间代码
是一种含义明确、便于处理的记号系统,通常独立于具体的硬件但与指令形式有某种程度的接近,或者能够比较容易的转换为机器指令,常见的形式有:
三元式;间接三元式;四元式;逆波兰式;树形表示。3. 目标代码
把中间代码变换为特定机器上的低级语言代码,产生出足以发挥硬件效率的目标代码是一件非常不容易的事情。常见的形式有:
汇编指令代码:需要汇编才能执行;
绝对指令代码:可以立即执行;
可重定位指令代码:运行前必须借助于一个链接装配程序,把各个目标模块(包括系统提供的库模块)连接在一起,确定程序装入内存中的起始地址,使之成为一个可以运行的绝对指令代码程序。
4. 属性文法
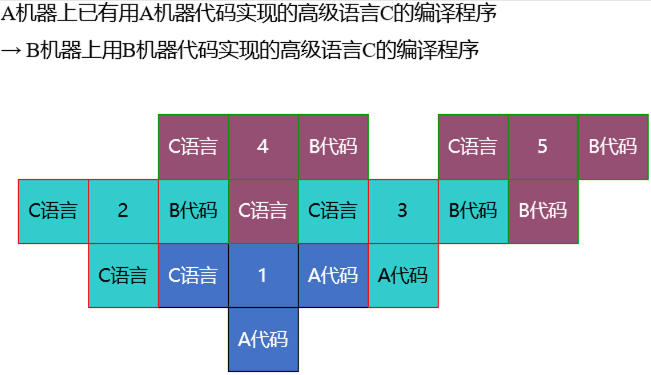
S-属性文法:只含有综合属性的文法;L-属性文法:含有综合属性或继承属性,且改继承属性仅依赖于: 产生式体该符号左边的那些属性;产生式头的继承属性;5. T 型图
6. 高级语言的分类
强制式语言:面向底层和语句,每个语句的执行引起若干存储单元中值的改变;
应用式语言:更注重程序所表示的功能,每条语句都封装了复杂的功能;
基于规则的语言:检查一定的条件,当它满足值,则执行适当的动作;
面向对象的语言:主要特征是封装性、继承性、多态性。
7. 闭包
用 Σ* 表示 Σ 上所有符号串的全体,空字 ε 也在其中,称为 Σ 的闭包。
Σ = {a, b},则 Σ* = {ε, a, b, aa, ab, bb, aaa, …}。8. 上下文无关文法

9. 构造文法


10. 二义文法
如果一个文法的某个句子对应两棵不同的语法树,即其最左( 最右)推导不唯一,称该文法为二义文法。对程序设计语言来说,常常希望它的文法是无二义的,因为我们希望对它每个语句的分析是唯一的。
消除文法二义性的关键步骤:
划分优先级和结合性;优先级高一级的运算,增加一层产生式;递归非终结符在左边,运算具有左结合性,否则具有右结合性。例子:改写二义文法
E -> E + E E -> E * EE -> (E) | -E | id优先级从低到高: [+];[*];[( ), -, id];
结合性:
左结合:[+, *]
右结合:[-]
无结合:[id]
非终结符与运算:
E:+ (E产生式,左递归)T:* (T产生式,左递归)F:-,( ),id (F产生式,右递归)
E → E + T | TT → T * F | FF → (E) | -E | id11. 构造正规式

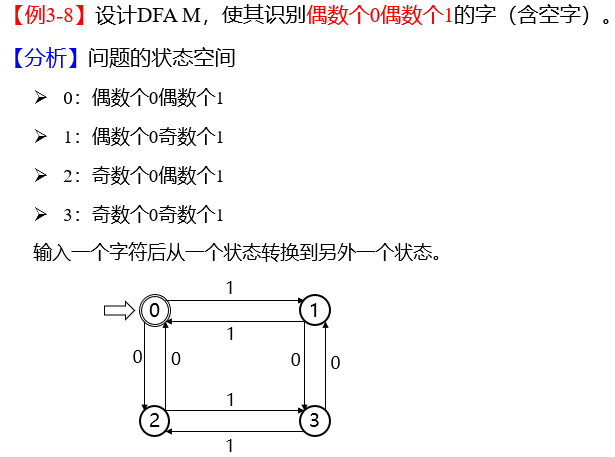
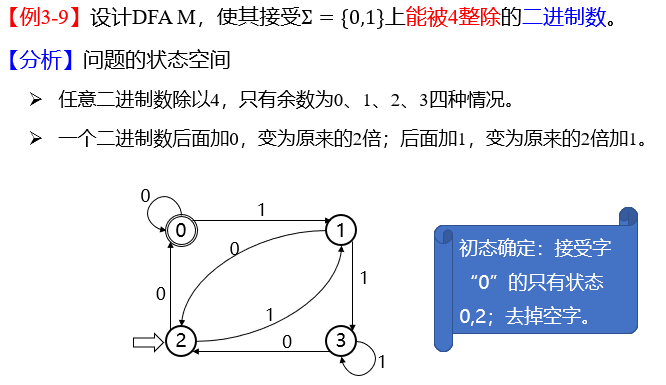
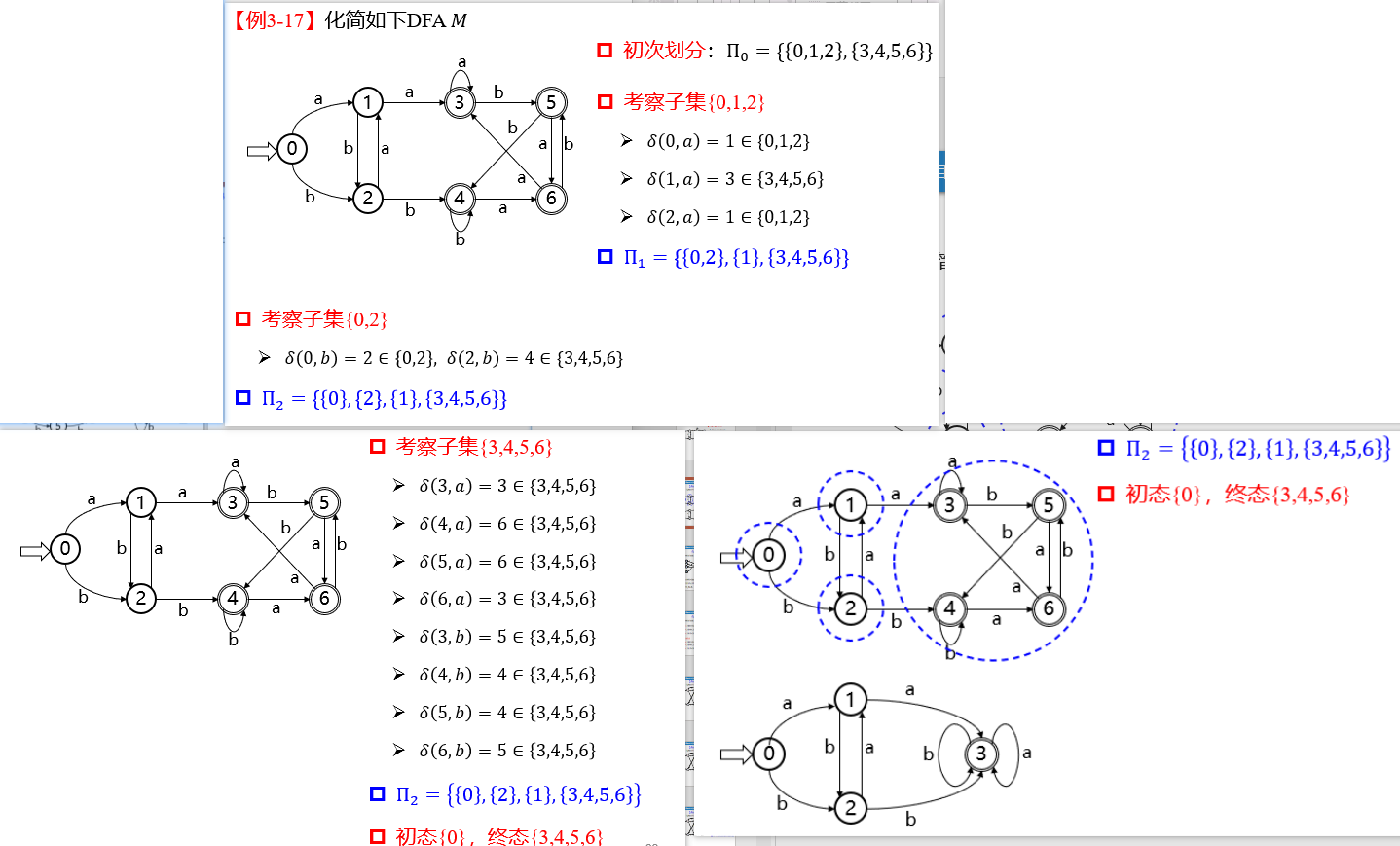
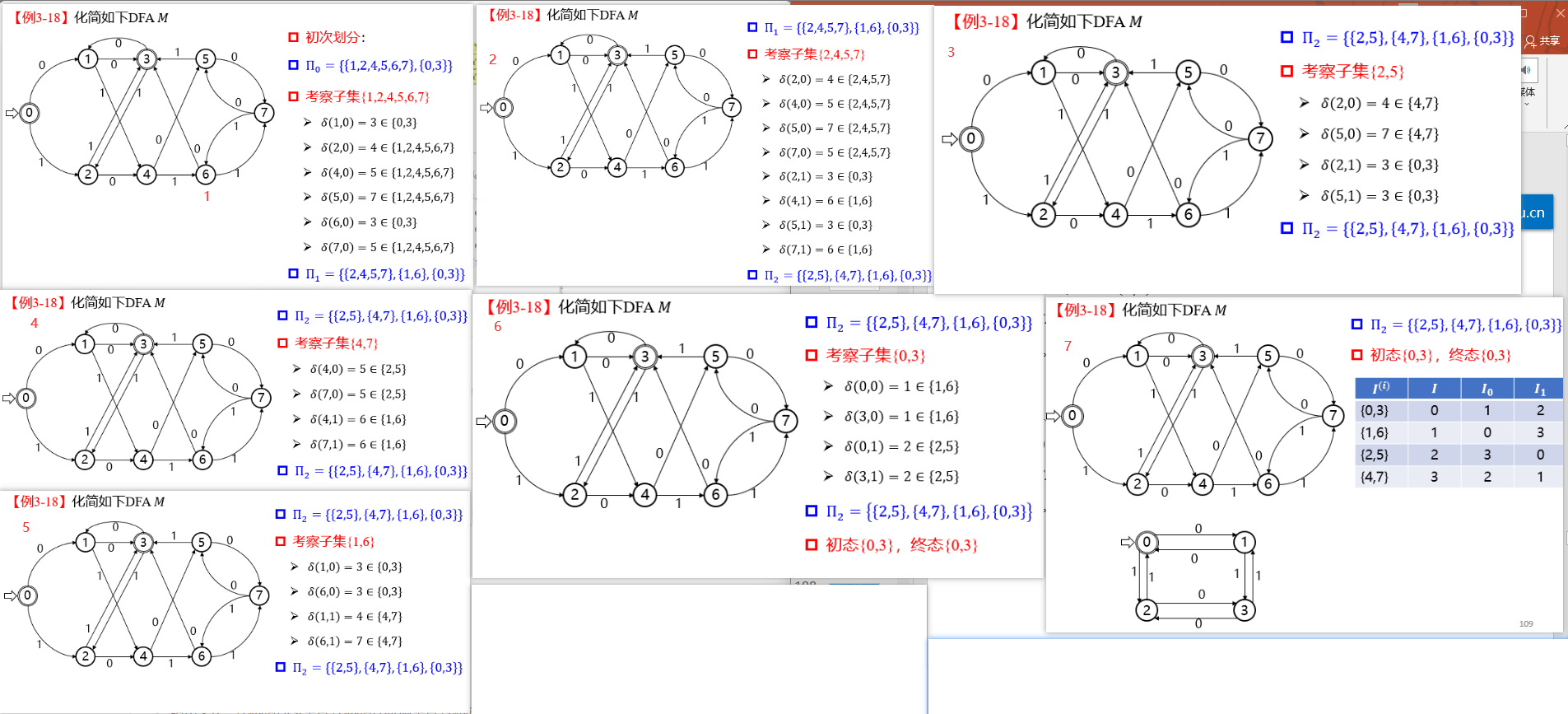
12. DFA

设计 DFA 例题
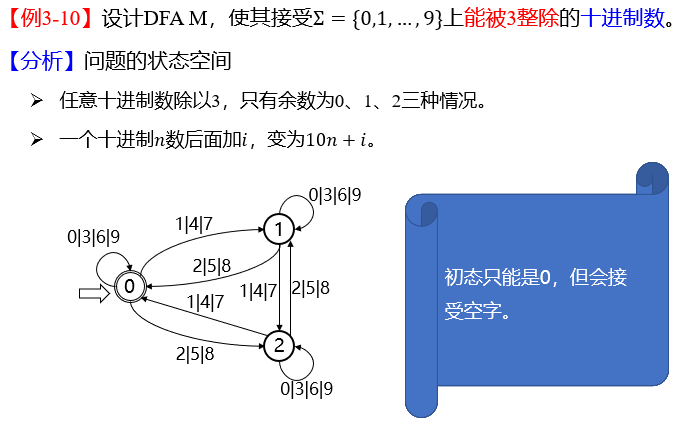
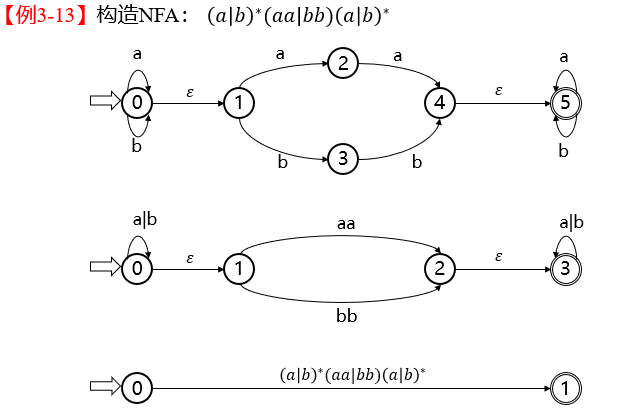
13. NFA

构造 NFA 例题
14. 句柄
**句型:**从文法开始符号推导出来的任一文法符号串;
**句子:**从文法开始符号推导出来的任一终结符号串;
**短语:**对文法 G[S],如果有 S =>* αAδ 且 A =>+ β,则称 β 是句型 αAδ 相对于非终结符号 A 的短语。
短语是语法树中所有子树的边缘,是相对于子树根节点的短语。
例如:
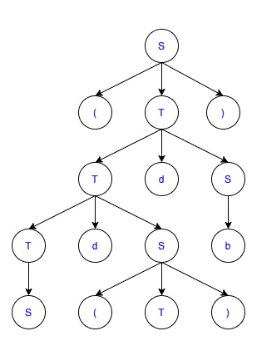
短语是 S,(T),Sd(T),b,Sd(T)db,(Sd(T)db);
**直接短语:**对文法 G[S],如果有 S =>* αAδ 且 A => β,则称 β 是句型 αAδ 相对于非终结符号 A 的短语。
直接断语是所有二层子树的边缘,在上图中只有三个二层子树。
例如:上图的直接短语是 S,(T),b;
**句柄:**最左直接短语;
句柄是最左二层子树的边缘。
例如:上图的句柄是 S;
**素短语:**至少包含一个终结符的短语,并且除它自身之外不再包含其他素短语;
例如:上图的素短语是 (T),b;
**最左素短语:**句型最左边的素短语,是算符优先分析法的规约对象;
例如:上图的最左素短语是 (T);
例子:


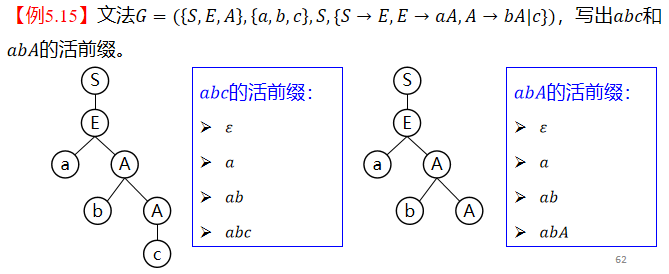
**活前缀:**是句型的一个前缀,不含句柄以后的任何符号;
例子:
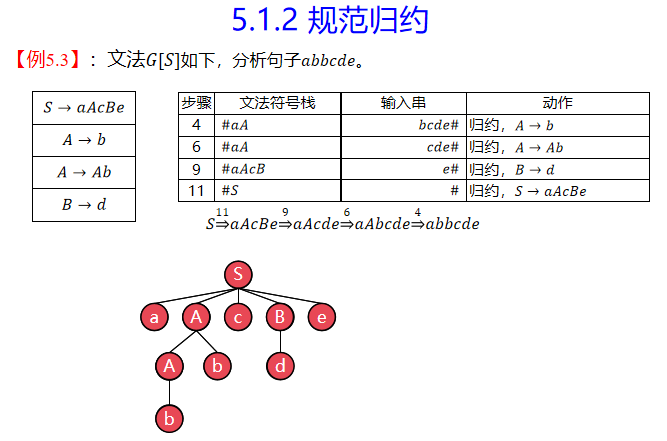
15. 规范规约
规范规约是最右推导的逆过程,因此也称为最左规约。
16. 根据 FA 写正规式
是根据正规式构造 FA 的逆过程。
17. 符号表
用于登记源程序的各类信息,如变量名、常量名、过程名等,以及编译各阶段的进展状况。当扫描器识别出一个标识符后,把该名字填入符号表,在语义分析阶段回填类型,在目标代码生成阶段回填地址。
符号表的作用和地位:(重点)
收集符号属性;语义合法性检查的依据,如重复变量定义;作为目标代码生成阶段地址分配的依据。符号表的主要属性:
符号名:变量、过程、类的名称;符号数据类型:整型、实型、布尔型;符号声明类别:static 、const 等;符号存储方式:堆区存储还是栈区存储等;符号作用域:全局变量与局部变量; 符号表的组织方式:
构造多个符号表,具有相同属性种类的符号组织在一起;把所有符号项都组织在一张大的符号表中;折中了上述两种方案,根据符号属性的相似程度分类成若干张表;使用对象组织,需要编译器的支持,但非常方便管理;符号表项的排列:
数组:线性组织;链表:Hash 表,跳表;树形:二叉树,平衡二叉树。 18. 运行时空间组织
运行时存储器的划分:
代码区:编译生成的目标代码;静态区:编译时就可以完全确定的数据;栈区:栈式内存分配;堆区:堆式内存分配;存储分配策略:
**静态分配策略:**在编译时对所有数据对象分配固定的存储单元,且在运行时始终保持不变;**栈式动态分配策略:**在运行时把存储器作为一个栈进行管理,运行时,每当调用一个过程,它所需要的存储空间就动态地分配于栈顶,一旦退出,它所占空间就予以释放;**堆式动态分配策略:**在运行时把存储器组织成堆结构,以便用户关于存储空间的申请与归还(回收),凡申请者从堆中分给一块,凡释放者退回给堆;活动记录:
为了管理过程在一次执行中所需要的信息,使用一个连续的存储块,这样的一个连续存储块称为活动记录, 一般包括:
局部变量:源代码中在过程体中声明的变量;临时单元:为了满足表达式计算要求而不得不预留的临时变量;内情向量:内情向量是静态数组的特征信息,用来描述数组属性信息的一些常量,包括数组类型、维数、各维的上下界及数组首地址;返回地址:调用位置的地址;动态链:SP 指向当前过程的动态链地址(也是帧起始地址),它又指向调用该过程的上一过程的帧起始地址,用于过程结束后回收分配的帧;它和函数的嵌套定义关系无关,只与调用顺序有关;静态链:指向当前过程的直接父过程的帧起始地址,用于访问非局部数据,它只与函数嵌套定义关系有关。 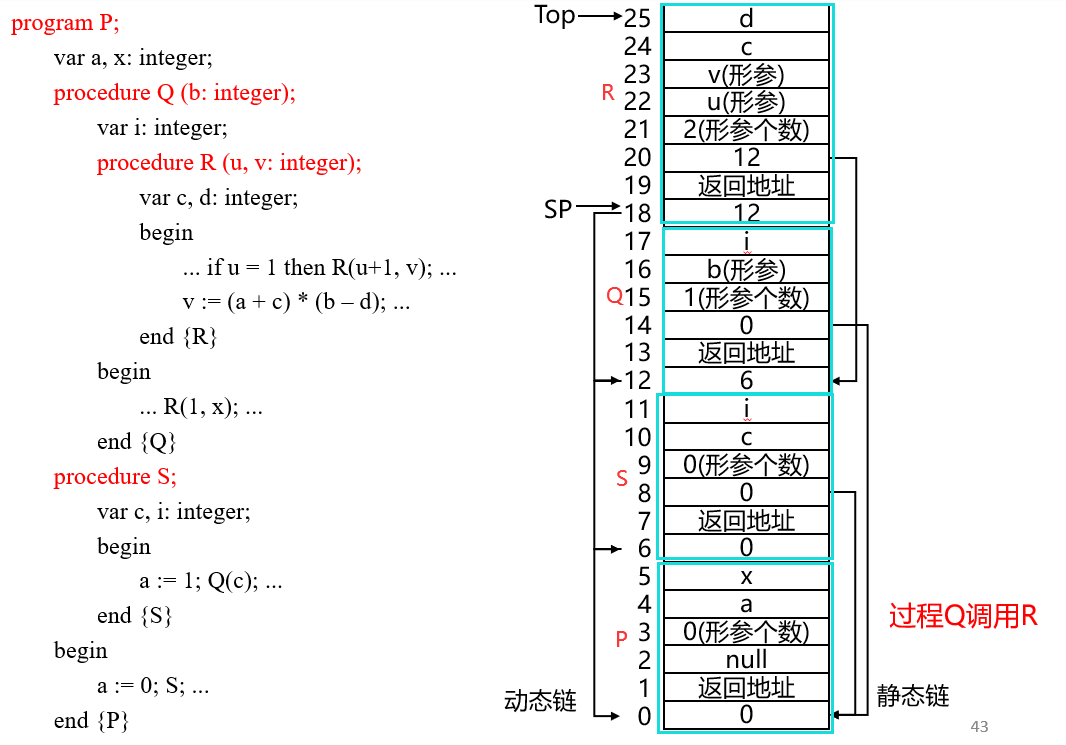
19. 优化手段
源代码级别:选择适当的算法,例如快排优于插排;语义动作级别:生成高效的中间代码,例如在词法分析阶段加入错误检查;中间代码级别:安排专门的优化阶段,例如DAG 优化; 局部优化:例如 DAG 优化;循环优化:包含代码外提、强度削弱、删除归纳变量、复写传播等; 目标代码级别:考虑如何有效地利用寄存器,例如窥孔优化。 20. 待用/活跃信息
当翻译 A = B op C 时:
A、B、C 是否还会在基本块内被引用; 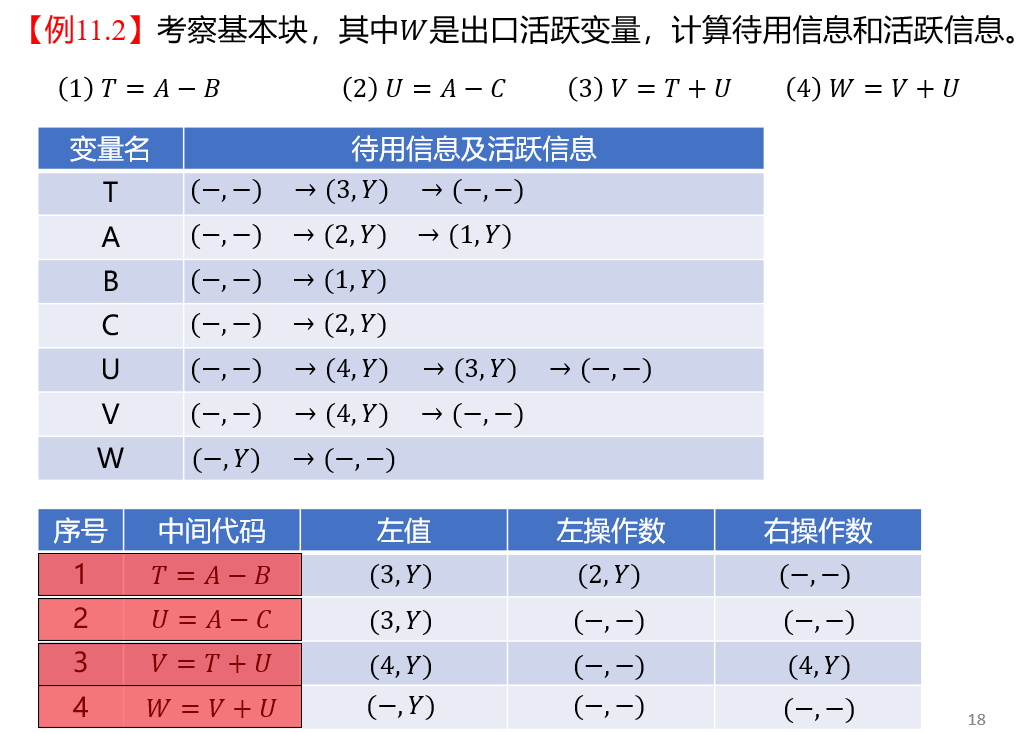
21. LL(1)分析
对于一个不含回溯和左递归的文法,LL(1) 方法从左到右扫描输入串,维护一个状态栈和一个符号栈,每一步只向右查看一个符号,根据状态栈顶、符号栈顶和分析表的内容来确定下一步的动作,最终分析出整个句子。
22. LR(1)分析
LR(1) 分析适合大多数上下文无关文法,它从左到右扫描符号串,能记住移进和规约出的整个符号串,即 “记住历史”,还可以根据所用的产生式推测未来可能碰到的输入符号,即 “展望未来”,根据 “历史”、“展望” 和分析表的内容来确定下一步的动作,最终分析出整个句子。
23. display 表
为提高访问非局部变量的速度,引入指针数组指向本过程的所有外层,成为嵌套层次显示表,display 表是一个栈,自顶向下依次指向当前层、直接外层、直接外层的直接外层,直到最外层。
24. 语法制导翻译法
对单词符号串进行语法分析,构造语法分析树,然后根据需要遍历语法树并在语法树的各结点处按语义规则进行计算。这种有源程序的语法结构驱动的处理办法就是语法制导翻译法。
二、综合题
2.1 词法分析
给定正规式: ①构造NFA ②确定化 ③最小化
例题
① + ②
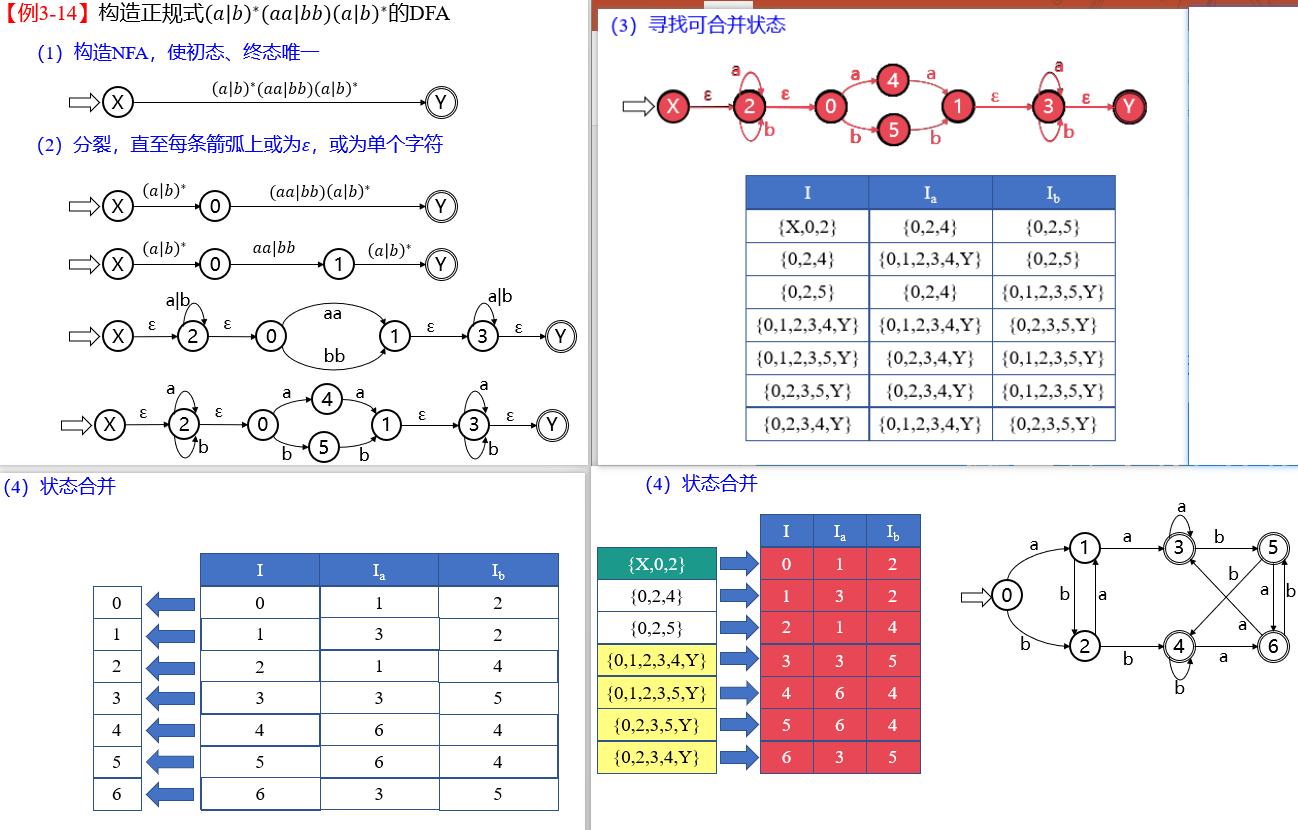
③
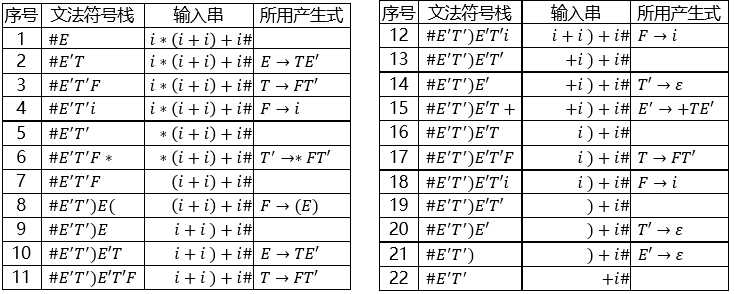
2.2 LL(1) 分析
给出文法:①构造First集合 ②构造Follow集合 ③构造LL(1)分析表 ④识别句子
例题
前提:LL(1) 适用条件

①求 First(X)

A -> Bc
B -> ε
则 First(A) = { c };
若 A -> B
B -> ε
则 First(A) = { ε };
②求 Follow(X)

③构造分析表


④分析过程

2.3 LR(1) 分析
给出文法:①构造拓广文法 ②求First集合 ③构造LR(1)项目集规范族 ④构造LR(1)分析表并消除二义性 ⑤识别句子
构造带向前搜索符的DFA,无归约-归约冲突则是LR(1)文法。
例题1
构造文法G[S]的LR(1)项目集规范族:S -> aCaCbS -> aDbC -> aD -> a①构造拓广文法:
S' -> SS -> aCaCbS -> aDbC -> aD -> a②求 First 集合:
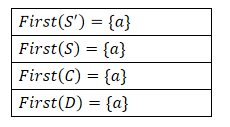
③构造 LR(1) 项目集规范族:
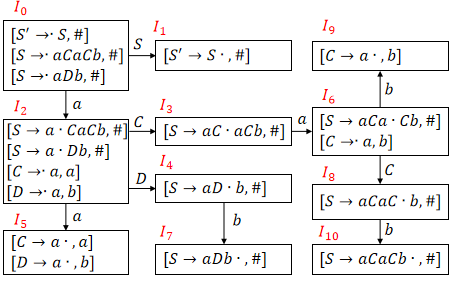
④构造 LR(1) 分析表并消除二义性:

消除二义性需要认为定义运算优先级,发生移入-规约冲突时选择正确的项填入。
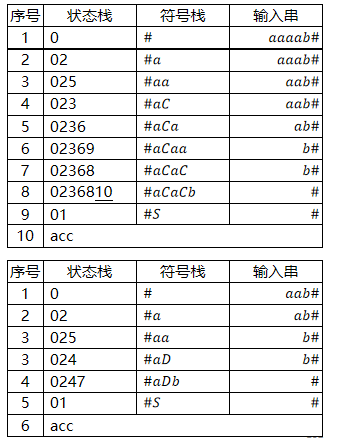
⑤识别句子 aaaab 和 aab :
例题2
对下列文法做 LR(1) :
S -> AS | bA -> SA | a


2.4 中间代码生成
给出翻译模式和高级语言程序,翻译句子,一般涉及多种类型句子的综合,也可能涉及声明语句填写符号表。
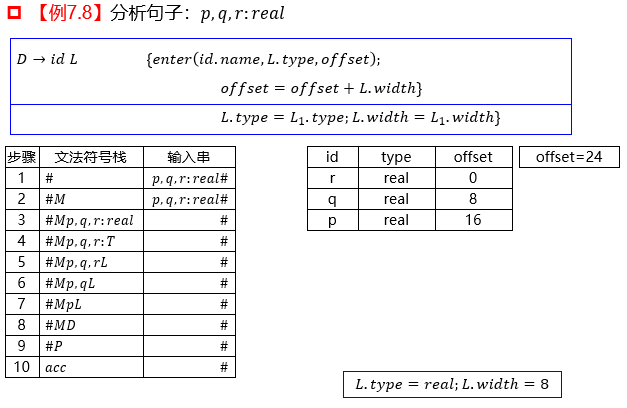
1. 过程中的说明语句


2.算术表达式的翻译



3. 布尔表达式的翻译
重点:回填。


4. 控制流语句的翻译
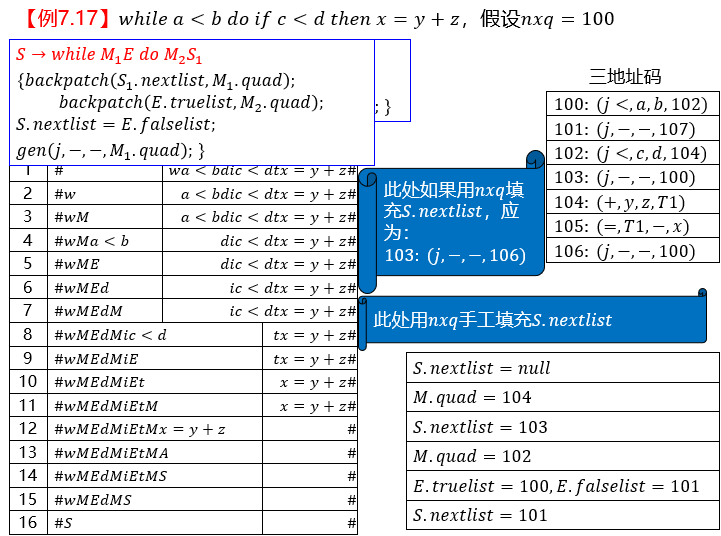
重点:if 和 while 。


2.5 目标代码生成
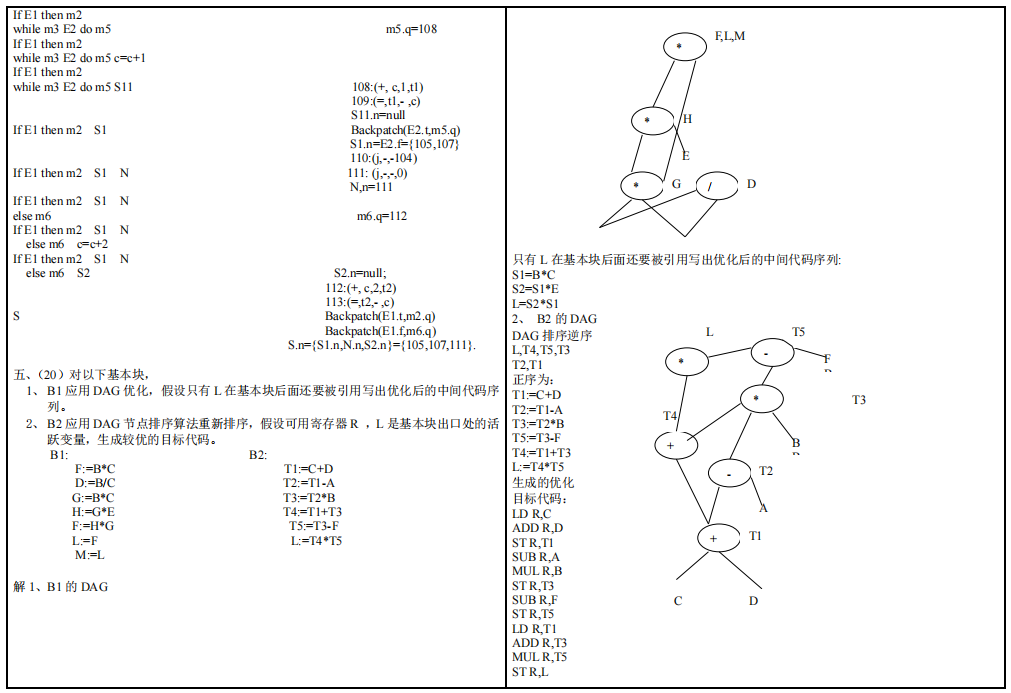
给出基本块代码:①构造DAG ②写出优化后的中间代码 ③写出DAG目标优化后的中间代码 ④根据变量活跃性和寄存器信息,写出目标代码。
例题1
给出基本块代码为:

①构造DAG
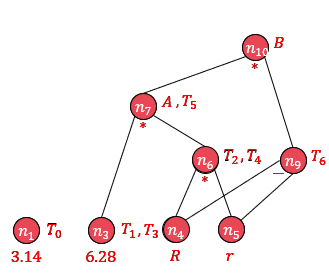
②写出优化后的中间代码

③写出DAG目标优化后的中间代码
(1) T6 = R - r(2) T2 = R * r(3) T4 = T2(4) T1 = 6.28(5) T3 = 6.28(6) A = 6.28 * T2(7) T5 = A(8) B = A * T6(9) T0 = 3.14④根据变量活跃性和寄存器信息,写出目标代码
假定 B 是基本块出口之后活跃的,有寄存器 R0 和 R1 可用,目标代码为:
DAG 优化中,不活跃变量,目标代码依然要生成计算其值的代码,只是不生成存储到主存的代码。计算代码被优化是后续优化完成的,不是 DAG 完成的。
LD R0, RSUB R0, r R0: T6 R1: \LD R1, RMUL R1, r R0: T6 R1: T2ST R0, T6LD R0, 6.28 R0: 6.28 R1: T2MUL R0, R1 R0: A R1: T2MUL R0, T6 R0: B R1: T2ST R0, B附:历年考试回忆
2004-2005
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MmUNQHdO-1655768860486)(https://s2.loli.net/2022/06/21/kX5Cfm2ILzv4ibW.png)]
2015-2016
一、简答(30 分)
1.给了一个文法(具体忘了),让证明二义性。
2.写出文法,表示{0、1}集上的所有正规式
3.解释 S-属性文法
4.说出传地址和传质这两种参数传递方式的异同
5.结合具体例子谈一谈回填思想
二、(babbb)* 画 NFA 转 DFA ,最小化(15 分)
三、(1)一个文法,判断是否为 LL(1)文法(10 分)
(2)上题中的文法是否为 SLR 文法,给出证明(15 分)
(与课本上例子不同之处在于有 B ——〉ε)
四、利用语法指导思想写四元式(15 分)
(比较简单,就是一个 while-do 语句)
五、给出一段中间代码,画 DAG 图;只有 R 在代码块外是活跃的,做优化;如
果有寄存器 R0 和 R1,写出目标代码。(15 分)
2016-2017
一、简答题
1.编译流程图及各部分的作用。⒉举例说明文法二义性。
3.什么是L属性文法?
4.写出允许过程嵌套的C活动记录结构。5.中间代码优化有哪几种?
6.符号表作用。
二、词法分析
RE NFA DFA最小化DFA整个流程走一遍
三、自上而下文法分析
给了一个文法,证明文法是LL1的,画表。
四、自下而上文法分析
给了一个文法,证明文法是LR1的,画表。
五、中间代码生成
—段代码,四元式翻译。涉及循环和判断的嵌套。
六、代码优化和目标代码生成。
给了一个代码段,
先画DAG图,然后优化,最后输出汇编代码。
2017-2018

2019-2020
一、五个小题(25分)
1.判断一个文法是否二义
2.编译的前端,后端,什么是一遍扫描
3.什么是S属性
4.什么是语法制导翻译
5.在语法制导翻译中,空返产生式的作用(M->e)
二、自动机(15分)
一个单词表由a,b组成,请写出代表偶数个a的正规式,NFA,并确定化、最小化
三、判断一个文法是不是LL(1)的,如果是就写出预测分析表,不是就说明原因(15分)
四、判断一个文法是不是SLR(1)的,如果是就写出预测分析表,不是就说明原因(15分)
五、中间代码生成程序(15分)
while a<c and b<d do if c==1 then c:=c+1 else c:=c+2;
六、代码优化(15分)
DAG优化,最后写出四元式的形式(这个是一个坑,四元式是目标代码,也就是此时要做目标代码生成)
同时目标代码生成要列表(Rvalue 寄存器描述,Avalue地址描述)
2020-2021

2021-2022
一、简答题
画编译流程图;判断一个文法是不是二义文法;给一个句型,找它的句柄;中缀表达式转后缀,比较长,最好使用算法一步步推导;消除循环左递归;给一个 DFA,把它转换为正规式二、计算题
词法分析:给定正规式 ①构造NFA ②确定化 ③最小化LL(1)分析,给出文法 ①构造First集合 ②构造Follow集合 ③构造LL(1)分析表(可能涉及消除二义文法冲突)④识别句子LR(1)分析,给出文法 ①构造拓广文法 ②构造拓广文法的LR(1)项目集规范族 ③构造LR(1)分析表(及消除二义文法冲突) ④识别句子给出基本块代码 ①构造DAG ②写出优化后的中间代码 ③写出DAG目标优化后的中间代码 ④根据变量活跃性和寄存器信息,写出目标代码给出翻译模式和高级语言程序,翻译句子while a < b do if c > d then x = y * z ,会给出翻译规则。 整体比较简单,高分应该挺多。把本文涉及到的知识点全部搞清楚,应付考试游刃有余
后续同学们考完试,可以把回忆版私发给我,我在此文中持续更新。