Python 获得pdf中的文字、图片文字方法
下载word版文件
OCR,全称Optical character recognition,中文译名叫做光学文字识别。它把图像中的字符,转换为机器编码的文本的一种方法。OCR技术在印刷行业应用得非常多,也广泛用于识别图片中的文字数据 – 比如护照,支票,银行声明,收据,统计表单,邮件等。
pytesseract,即Python-tesseract,是Google Tesseract ORC引擎的封装。首次于2014年提出,支持的图片格式有’JPEG’, ‘PNG’, ‘PBM’, ‘PGM’, ‘PPM’, ‘TIFF’, ‘BMP’, ‘GIF’,只需要简短的代码就能够提取图片中的字符合文字了,极大方便文字工作。
一、准备工作
1,安装pillow或者PIL,主要用来打开本地图片
pip install PIL
pip install pillow
2,安装pytesseract,主要用来将图片里面文字转化字符串或者pdf
pip install pytesseract
3,安装 Tesseract-OCR应用程序
进入https://pan.baidu.com/s/1qXumxdltxOnb0geaE_1U-Q
下载tesseract-ocr-w64-v5.0.0.exe
设置环境变量:新增系统变量TESSDATA_PREFIX
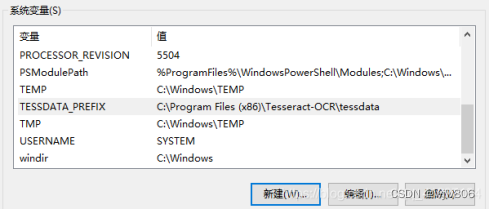
新增PATH路径:
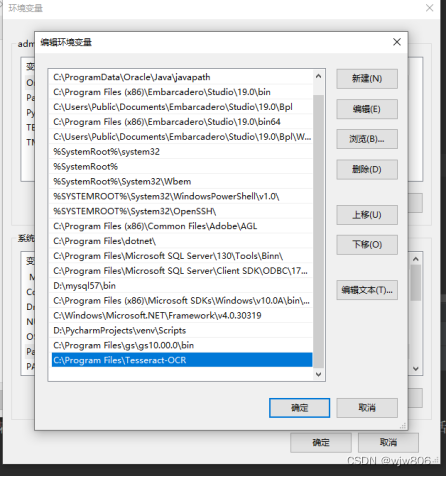
配置就完成
测试是否安装成功
输入tesseract -v如果出现版本号则安装成功,如下图所示

进行识别
打开cmd->定位到所要识别的图片的位置
输入如下语句:tesseract pic3.png a [ -l chi_sim]
pic3.png是你图片的名称,a是保存文字的txt文件,后缀名可省略,默认的识别语言是英文,如果是中文要利用-l chi_sim换成中文

4,修改 pytesseract 源码中的路径
进入python目录\Lib\site-packages\pytesseract,用Notepad++打开pytesseract.py,将源码第26行的路径修改成安装Tesseract-OCR应用程序路径。
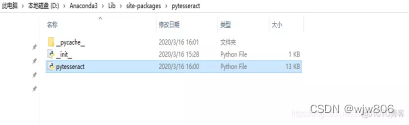
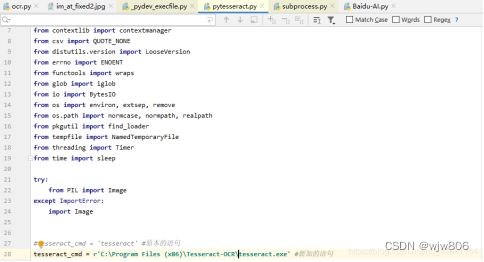
tesseract_cmd = 'tesseract.exe'
修改成
tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
5,安装中文字库
进入https://pan.baidu.com/s/1GfspC5uef73B2Oa8YudBgQ,下载中文库复制到 Tesseract-OCR 安装目录下的 tessdata 文件夹中,
(实际上是chi_sim.traineddata最好在C:\Program Files \Tesseract-OCR目录下)
二、利用Python提取PDF文本的简单方法实例
一般情况下,Ctrl+C 是最简单的方法,当无法 Ctrl+C 时,我们借助于 Python,以下是具体步骤:
第一步,安装工具库
1、tika — 用于从各种文件格式中进行文档类型检测和内容提取
2、wand — 基于 ctypes 的简单 ImageMagick 绑定
3、pytesseract — OCR 识别工具
安装这些工具
| 1 2 3 | pip install tika wand pytesseract |
第二步,编写代码
假如 pdf 文件里面既有文字,又有图片,以下代码可以直接识别文字:
| 1 2 3 4 5 6 7 8 9 10 | import io import pytesseract import sys
from PIL import Image from tika import parser from wand.image import Image as wi
text_raw = parser.from_file("example.pdf") print(text_raw['content'].strip()) |
这还不够,我们还需要能失败图片的部分:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | def extract_text_image(from_file, lang='deu', image_type='jpeg', resolution=300): print("-- Parsing image", from_file, "--") print("---------------------------------") pdf_file = wi(filename=from_file, resolution=resolution) image = pdf_file.convert(image_type) image_blobs = [] for img in image.sequence: img_page = wi(image=img) image_blobs.append(img_page.make_blob(image_type)) extract = [] for img_blob in image_blobs: image = Image.open(io.BytesIO(img_blob)) text = pytesseract.image_to_string(image, lang=lang) extract.append(text) for item in extract: for line in item.split("\n"): print(line) |
合并一下,完整代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | import io import sys
from PIL import Image import pytesseract from wand.image import Image as wi from tika import parser
def extract_text_image(from_file, lang='deu', image_type='jpeg', resolution=300): print("-- Parsing image", from_file, "--") print("---------------------------------") pdf_file = wi(filename=from_file, resolution=resolution) image = pdf_file.convert(image_type) for img in image.sequence: img_page = wi(image=img) image = Image.open(io.BytesIO(img_page.make_blob(image_type))) text = pytesseract.image_to_string(image, lang=lang) for part in text.split("\n"): print("{}".format(part))
def parse_text(from_file): print("-- Parsing text", from_file, "--") text_raw = parser.from_file(from_file) print("---------------------------------") print(text_raw['content'].strip()) print("---------------------------------")
if __name__ == '__main__': parse_text(sys.argv[1]) extract_text_image(sys.argv[1], sys.argv[2]) |
这里,是将pdf全部转换成图片,再进行识别图片识别的,如果文档内容比较多,效率会比较慢。好处是识别的文本连续性比较好
image = pdf_file.convert(image_type)
可以逐页逐图进行识别
def extract_text(file_name):
extract_text = '' # 用于存储提取的文本
doc = fitz.open(file_name)
# 遍历每一页pdf
print('pages:',len(doc))
for i in range(len(doc)):
img_list = doc.get_page_images(i) # 提取该页中的所有img
# 遍历每页中的图片,
for num, img in enumerate(img_list):
img_name = f"d:/pdfall2txt/{i + 1}{num + 1}.png" # 存储的图片名
pix = fitz.Pixmap(doc, img[0]) # image转pixmap
if pix.n - pix.alpha >= 4: # 如果差值大于等于4,需要转化后才能保存为png
pix = fitz.Pixmap(fitz.csRGB, pix)
pix.save(img_name) # 存储图片
pix = None # 释放Pixmap资源
image = Image.open(img_name)
text = pytesseract.image_to_string(image, 'chi_sim') # 调用tesseract,使用中文库,要求库文件放在C:\Program Files (x86)\Tesseract-OCR目录想
extract_text += text # 写入文本
os.remove(img_name)
return extract_text
三、报错解决
1. convert: FailedToExecuteCommand `“gswin64c.exe”
参考:
Stackoverflow:Imagemagick FailedToExecuteCommand `“gswin32c.exe”
ImageMagick之PDF转换成图片(image)
报错信息中的gswin32c.exe指得就是Ghostscript(https://ghostscript.com/releases/gsdnld.html),下载这个东西,进行安装。
2、pytesseract错误
下载安装tesseract-ocr-w64-v5.0.0.exe

import pytesseract
from PIL import Image
from urllib import request
import time
pytesseract.pytesseract.tesseract_cmd=r'C:\Program Files\Tesseract-OCR\tesseract.exe'
image=Image.open('img\pic3.png')#所要识别的图片的位置
#默认是英文,中文的要将语言改成中文。
text=pytesseract.image_to_string(image,lang='chi_sim')
print(text)
四、相关文件下载地址
1、ImageMagick
ImageMagick不知道需不需安装,不过安装一下没问题
ImageMagick – Download
| Version | Description |
| ImageMagick-7.1.0-51-Q16-HDRI-x64-dll.exe |
|
https://imagemagick.org/archive/binaries/ImageMagick-7.1.0-51-Q16-HDRI-x64-dll.exe
2、下载语言包,
GitHub - tesseract-ocr/tessdata: Trained models with support for legacy and LSTM OCR engine
下载后,打开压缩文件,将文件复制到C:\Program Files (x86)\Tesseract-OCR\tessdata目录下(实际上可以放在C:\Program Files (x86)\Tesseract-OCR目录下)
3、下载gs1000w64.exe
Ghostscript : Downloads
4、下载tika-server.jar
http://search.maven.org/remotecontent?filepath=org/apache/tika/tika-server/1.24/tika-server-1.24.jar
5、下载tesseract-ocr-w64-setup-v4.0.0-beta.1.20180414
https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v4.0.0-beta.1.20180414.exe
6、下载tesseract-ocr-w64-v5.0.0.exe
进入https://pan.baidu.com/s/1qXumxdltxOnb0geaE_1U-Q
示例:
def extract_text(file_name):
extract_text = '' # 用于存储提取的文本
doc = fitz.open(file_name)
# 遍历每一页pdf
print('pages:',len(doc))
for i in range(len(doc)):
img_list = doc.get_page_images(i) # 提取该页中的所有img
# 遍历每页中的图片,
for num, img in enumerate(img_list):
img_name = f"d:/pdfall2txt/{i + 1}{num + 1}.png" # 存储的图片名
pix = fitz.Pixmap(doc, img[0]) # image转pixmap
if pix.n - pix.alpha >= 4: # 如果差值大于等于4,需要转化后才能保存为png
pix = fitz.Pixmap(fitz.csRGB, pix)
pix.save(img_name) # 存储图片
pix = None # 释放Pixmap资源
image = Image.open(img_name)
text = pytesseract.image_to_string(image, 'chi_sim') # 调用tesseract,使用中文库,要求库文件放在C:\Program Files (x86)\Tesseract-OCR目录想
extract_text += text # 写入文本
os.remove(img_name)
return extract_text