
文章目录
每篇前言一、read_xml1. path_or_buffer2. xpath3. namespaces4. elems_only5. attrs_only6. names7. encoding8. parser9. stylesheet10. compression11. storage_options 二、to_xml1. path_or_buffer2. index3. root_name4. row_name5. na_rep6. attr_cols7. elem_cols8. namespaces9. pretty_print10. 其他 三、书籍推荐
每篇前言
??作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6 |
pandas读写xml文件依赖的需要安装lxml库,所以需要安装:pip install lxml
一、read_xml
语法格式:
pd.read_xml( path_or_buffer: FilePathOrBuffer, xpath: str | None = "./*", namespaces: dict | list[dict] | None = None, elems_only: bool | None = False, attrs_only: bool | None = False, names: list[str] | None = None, encoding: str | None = "utf-8", parser: str | None = "lxml", stylesheet: FilePathOrBuffer | None = None, compression: CompressionOptions = "infer", storage_options: StorageOptions = None,) -> DataFrame:1. path_or_buffer
接受XML字符串或者XML文件路径
(1)读取xml字符串:
import pandas as pdimport numpy as nptest = """<collection shelf="New Arrivals"><class className="1班"> <code>2022001</code> <number>10</number> <teacher>小白</teacher></class><class className="2班"> <code>2022002</code> <number>20</number> <teacher>小红</teacher></class><class className="3班"> <code>2022003</code> <number>30</number> <teacher>小黑</teacher></class></collection>"""df = pd.read_xml(test)print(df)运行结果: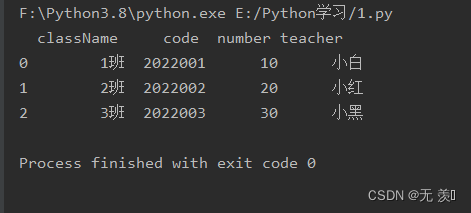
(2)读取xml文件:
import pandas as pdimport numpy as npdf = pd.read_xml('test.xml')print(df)运行结果: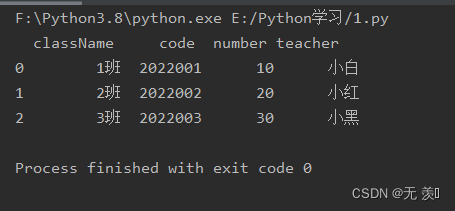
2. xpath
用于解析迁移到DataFrame所需的节点集的XPath。
import pandas as pdimport numpy as nptest = """<collection shelf="New Arrivals"><class className="1班"> <code>2022001</code> <number>10</number> <teacher>小白</teacher></class><class className="2班"> <code>2022002</code> <number>20</number> <teacher>小红</teacher></class><class className="3班"> <code>2022003</code> <number>30</number> <teacher>小黑</teacher></class></collection>"""# 读取classdf = pd.read_xml(test, xpath=".//class")print(df)运行结果: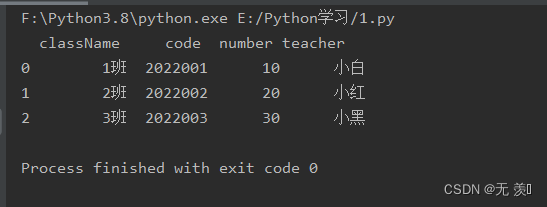
3. namespaces
XML文档中定义的名称空间为字典,key为名称空间前缀,value为URI。接收字典参数。用处较少。
4. elems_only
接收bool类型, 默认为 False。只解析指定xpath的子元素。默认情况下,返回所有子元素和非空文本节点。
import pandas as pdimport numpy as nptest = """<collection shelf="New Arrivals"><class className="1班"> <code>2022001</code> <number>10</number> <teacher>小白</teacher></class><class className="2班"> <code>2022002</code> <number>20</number> <teacher>小红</teacher></class><class className="3班"> <code>2022003</code> <number>30</number> <teacher>小黑</teacher></class></collection>"""# elems_only=False时df = pd.read_xml(test, xpath=".//class",elems_only=False)print(df)# elems_only=True时df = pd.read_xml(test, xpath=".//class",elems_only=True)print(df)运行结果:
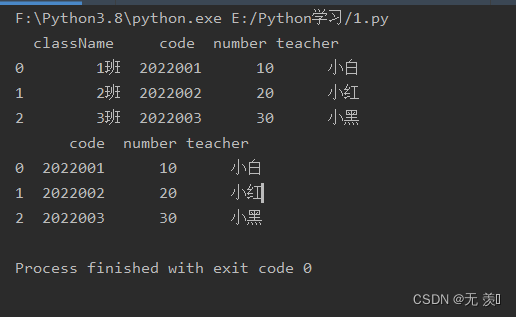
5. attrs_only
只解析指定xpath的属性。 接收bool类型, 默认为 False,返回所有属性。
import pandas as pdimport numpy as nptest = """<collection shelf="New Arrivals"><class className="1班"> <code>2022001</code> <number>10</number> <teacher>小白</teacher></class><class className="2班"> <code>2022002</code> <number>20</number> <teacher>小红</teacher></class><class className="3班"> <code>2022003</code> <number>30</number> <teacher>小黑</teacher></class></collection>"""df = pd.read_xml(test, xpath=".//class",attrs_only=False)print(df)df = pd.read_xml(test, xpath=".//class",attrs_only=True)print(df)运行结果: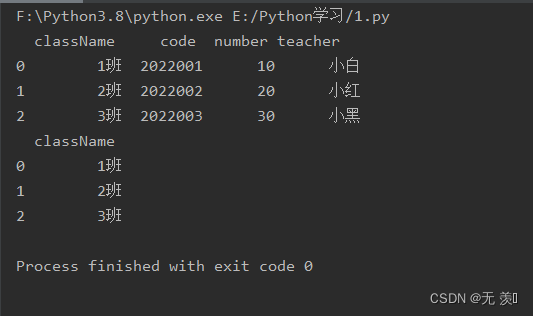
6. names
重命令DataFrame的列名,接收列表类型。
import pandas as pdimport numpy as nptest = """<collection shelf="New Arrivals"><class className="1班"> <code>2022001</code> <number>10</number> <teacher>小白</teacher></class><class className="2班"> <code>2022002</code> <number>20</number> <teacher>小红</teacher></class><class className="3班"> <code>2022003</code> <number>30</number> <teacher>小黑</teacher></class></collection>"""df = pd.read_xml(test, xpath=".//class",names=['班级','学号','年龄','名字'])print(df)运行结果: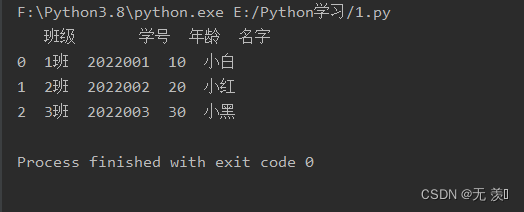
7. encoding
xml文件的编码格式,默认为 ‘utf-8’
8. parser
切换检索数据的解析器模块,支持‘lxml’ 和‘etree’,默认是‘lxml’。
9. stylesheet
接收str、path对象或类文件对象。URL、类文件对象或包含XSLT脚本的原始字符串。这个样式表应该将复杂的、深度嵌套的XML文档扁平化,以便于解析。要使用此功能,必须安装lxml模块并指定“lxml”作为解析器。xpath必须引用XSLT转换后生成的已转换XML文档的节点,而不是原始XML文档。目前仅支持XSLT 1.0脚本,不支持更高版本。
10. compression
接收str或dict,默认为“infer”。用于动态解压缩磁盘上的数据。如果“infer”和“path_or_buffer”类似于路径,则从以下扩展名检测压缩:“”。gz“,”。bz2’,‘。zip“,”。xz“,”。zst“,”。焦油’,‘。焦油。gz“,”.tar。xz’或’.tar。bz2’(否则不压缩)。如果使用“zip”或“tar”,则zip文件只能包含一个要读取的数据文件。如果不解压缩,请设置为“无”。也可以是键“method”设置为{‘zip’、‘gzip’,‘bz2’、‘zstd’、‘tar’}之一的dict,其他键值对被转发到zipfile。ZipFile,gzip。GzipFile,bz2.bz2文件,zstandard。Zstd解压缩器或目标文件。分别为TarFile。例如,可以使用自定义压缩字典为Zstandard解压缩传递以下内容:compression={‘method’:‘zstd’,‘dict_data’:my_compression_dict}。
11. storage_options
接收dict字典类型。对于特定存储连接有意义的额外选项,例如主机、端口、用户名、密码等。对于HTTP(S)URL,键值对被转发到urllib.request。请求作为标头选项。对于其他URL(例如以“s3://”和“gcs://”开头),键值对被转发到fsspec.open
二、to_xml
语法格式:
DataFrame.to_xml( self, path_or_buffer: FilePathOrBuffer | None = None, index: bool = True, root_name: str | None = "data", row_name: str | None = "row", na_rep: str | None = None, attr_cols: str | list[str] | None = None, elem_cols: str | list[str] | None = None, namespaces: dict[str | None, str] | None = None, prefix: str | None = None, encoding: str = "utf-8", xml_declaration: bool | None = True, pretty_print: bool | None = True, parser: str | None = "lxml", stylesheet: FilePathOrBuffer | None = None, compression: CompressionOptions = "infer", storage_options: StorageOptions = None, ) -> str | None:1. path_or_buffer
接收字符串、路径对象(实现os.PathLike[str])或实现write()函数的类文件对象。如果为“无”,则结果将作为字符串返回。
(1)写入字符串:
import pandas as pdimport numpy as npdf = pd.DataFrame({'name': ['小明', '小红', '小张'], 'age': [18, 19, 29], 'class': [1, 2, np.nan]})print(df)xml = df.to_xml()print(xml)运行结果: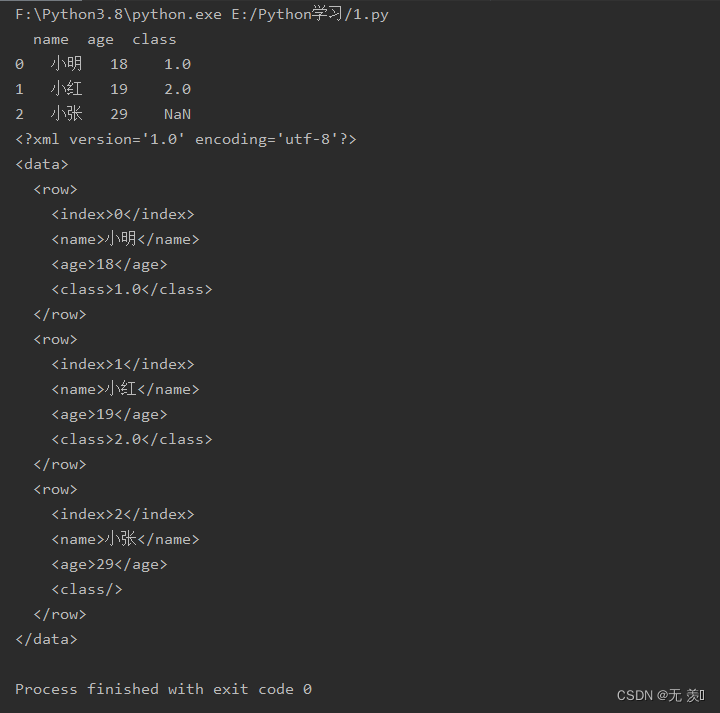
(2)写入xml文件:
import pandas as pdimport numpy as npdf = pd.DataFrame({'name': ['小明', '小红', '小张'], 'age': [18, 19, 29], 'class': [1, 2, np.nan]})print(df)df.to_xml('test.xml')运行结果: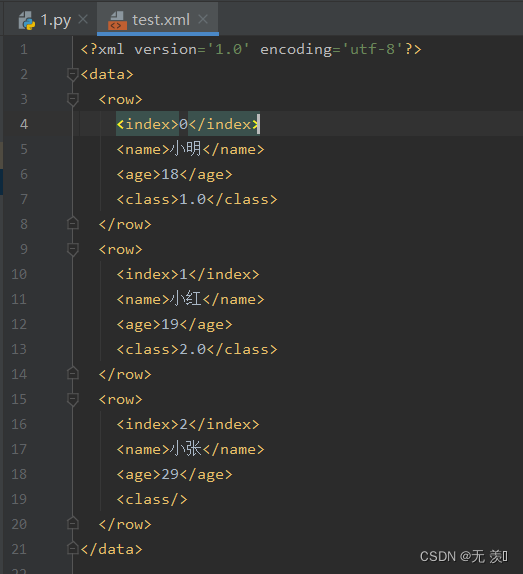
2. index
是否写入索引,接收bool类型,默认为False。
import pandas as pdimport numpy as npdf = pd.DataFrame({'name': ['小明', '小红', '小张'], 'age': [18, 19, 29], 'class': [1, 2, np.nan]})# print(df)xml = df.to_xml(index=False)print(xml)xml = df.to_xml(index=True)print(xml)运行结果:
<?xml version='1.0' encoding='utf-8'?><data> <row> <name>小明</name> <age>18</age> <class>1.0</class> </row> <row> <name>小红</name> <age>19</age> <class>2.0</class> </row> <row> <name>小张</name> <age>29</age> <class/> </row></data><?xml version='1.0' encoding='utf-8'?><data> <row> <index>0</index> <name>小明</name> <age>18</age> <class>1.0</class> </row> <row> <index>1</index> <name>小红</name> <age>19</age> <class>2.0</class> </row> <row> <index>2</index> <name>小张</name> <age>29</age> <class/> </row></data>3. root_name
XML文档中根元素的名称,接收字符串,默认为:‘data’
import pandas as pdimport numpy as npdf = pd.DataFrame({'name': ['小明', '小红', '小张'], 'class': [1, 2, np.nan]})# print(df)xml = df.to_xml(root_name='test')print(xml)运行结果(修改为test):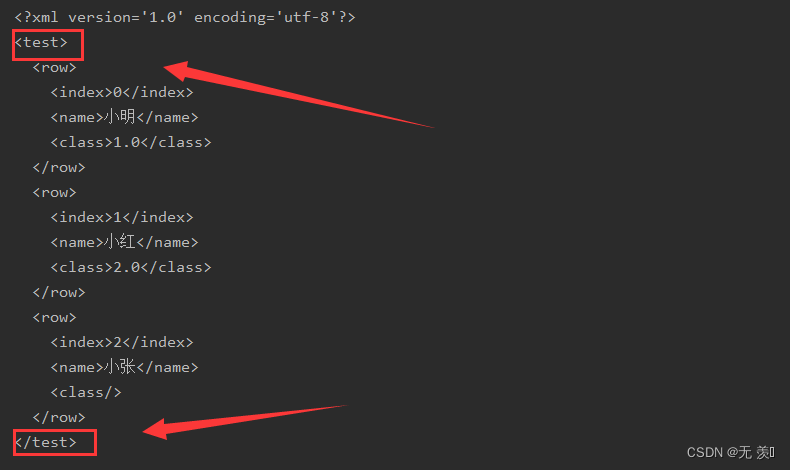
4. row_name
XML文档中row元素的名称,接收字符串,默认为:‘row’
import pandas as pdimport numpy as npdf = pd.DataFrame({'name': ['小明', '小红', '小张'], 'class': [1, 2, np.nan]})# print(df)xml = df.to_xml(row_name='test1')print(xml)运行结果: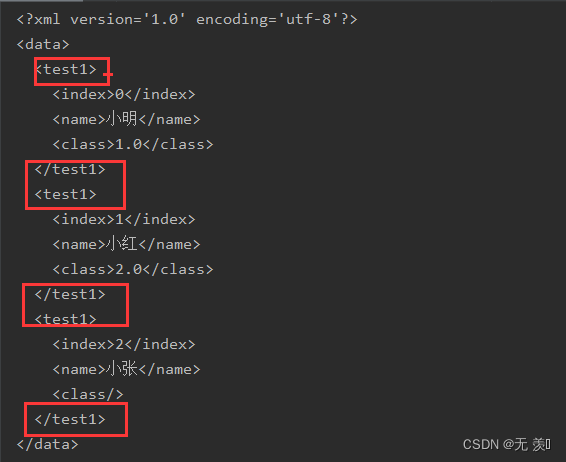
5. na_rep
填充缺失值,接收字符串类型。
import pandas as pdimport numpy as npdf = pd.DataFrame({'name': ['小明', '小红', '小张'], 'class': [1, 2, np.nan]})# print(df)xml = df.to_xml(na_rep='3')print(xml)运行结果: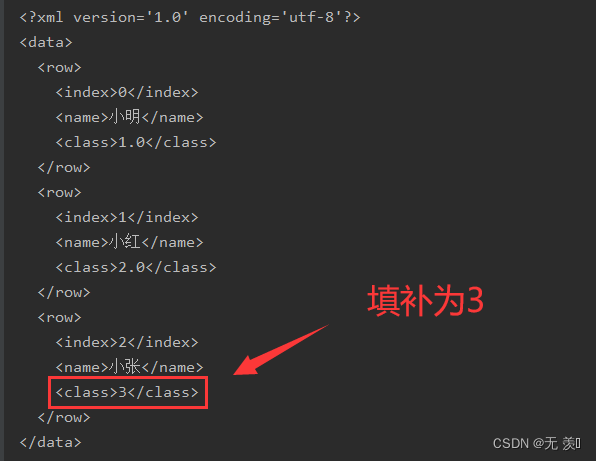
6. attr_cols
要作为属性写入行元素的列的列表。分层列将用下划线平展,以分隔不同的级别。
7. elem_cols
要作为行元素中的子级写入的列的列表。默认情况下,所有列输出为行元素的子级。分层列将用下划线平展,以分隔不同的级别。
8. namespaces
在根元素中定义的所有名称空间。字典的键应该是字典对应uri的前缀名和值。默认名称空间应该被赋予空的字符串键。
import pandas as pdimport numpy as npdf = pd.DataFrame({'name': ['小明', '小红', '小张'], 'class': [1, 2, np.nan]})# print(df)xml = df.to_xml(namespaces={"": "https://www.baidu.com"})print(xml)运行结果: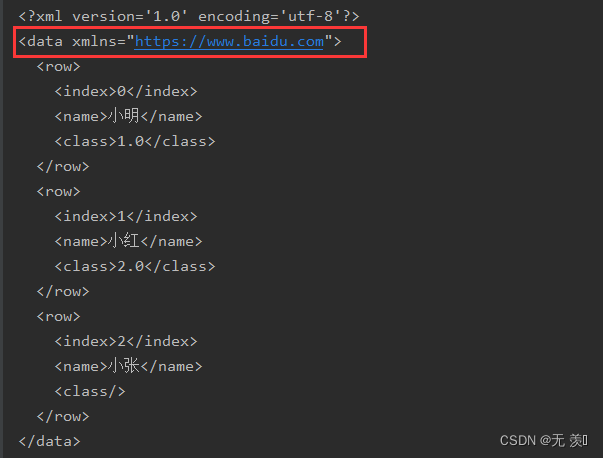
9. pretty_print
是否格式化xml文档,默认为True。
import pandas as pdimport numpy as npdf = pd.DataFrame({'name': ['小明', '小红', '小张']})# print(df)xml = df.to_xml(pretty_print=False)print(xml)xml = df.to_xml(pretty_print=True)print(xml)运行结果:
10. 其他
其他的参数用处和read_xml中一样
三、书籍推荐
书籍展示:《元宇宙:图说元宇宙、设计元宇宙(全两册)》
【书籍内容简介】
世间可曾存在着这样一个时空?那里高度自由,不会受到任何来自外界的干涉和干扰;那里无限可能,可凭个人喜好随性创造……有的,就叫“元宇宙”!
元宇宙,可以满足不同人不同的期许,可以实现不同人不同的梦想,甚至可以容下世间所有截然不同的存在!心动吗?别急,在此之前,我们需要先明白“什么是元宇宙”,以及,“如何架构属于自己的元宇宙”——
北京大学出版社联合文津图书奖得主、全国十大科普教育平台“量子学派”与中国科学院院士,共同推出《元宇宙:图说元宇宙、设计元宇宙(全两册)》一书,不仅用场景化的叙事艺术带你轻松入门元宇宙,更有320幅手绘插图、十一维元宇宙关系图谱和大拉页版“2140世界设定”,助你直观地了解并且亲手架构独一无二的元宇宙!
元宇宙时代已缓缓开启,做好准备就启程吧!
京东自营:https://item.jd.com/13577756.html