作为一个cuda爱好者 一定要好好看看
不再让CPU和总线拖后腿:Exafunction让GPU跑的更快!确实只用cpu会卡的一比...
在云服务中使用 GPU 是获得低延迟深度学习推理服务最经济的方式。使用 GPU 的主要瓶颈之一是通过 PCIe 总线在 CPU 和 GPU 内存之间复制数据的速度。对于许多打算用于高分辨率图像和视频处理的深度学习模型来说,简单地复制输入会大大增加系统的整体延迟,特别是当非推理任务,如解压缩和预处理也可以在 GPU 上执行时。
在这篇博文中,研究者们将展示如何在 TensorFlow 中直接通过 GPU 内存传递模型输入和输出以进行模型推理,完全绕过 PCIe 总线和 CPU 内存。
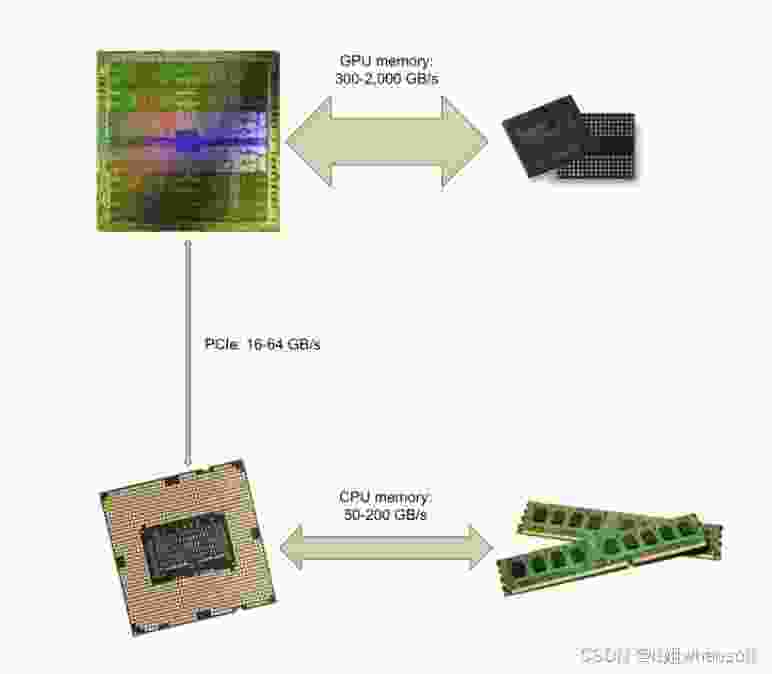
由于大多数 GPU 代码是用 CUDA 编写的,本文将使用 TensorFlow 的 C++ 接口来演示这种技术。这样有利于对接其他库的接口,如用于 GPU 加速的图像预处理的 OpenCV 和用于硬件加速的视频解码的 NVIDIA NVDEC。
初始设置
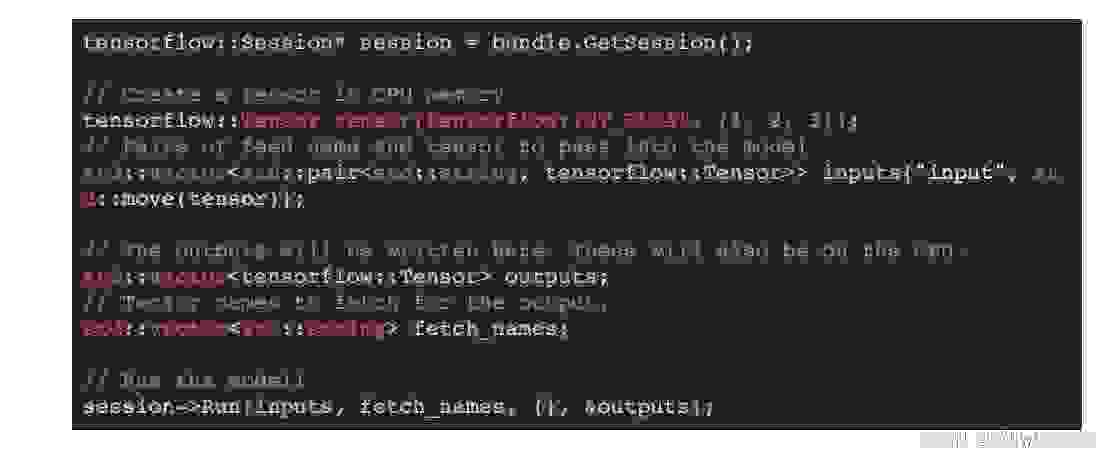
在 TensorFlow 的 C++ 接口中,tensorflow::LoadSavedModel 被用来加载模型包:

然后可以使用 tensorflow::Session 来运行模型包。默认情况下,这将使用 CPU。
使用 GPU
使用 GPU 就比较麻烦了。首先,用户必须从会话中创建一个 tensorflow::CallableOptions 的实例,以指定哪些张量被传入和传出 GPU 内存而不是 CPU 内存。此外,有必要指定内存将从哪个 GPU 中输入和获取。在这个例子中,为了简单起见,本文将把所有的输入和输出的张量(Tensor)放在第一个 GPU 上。
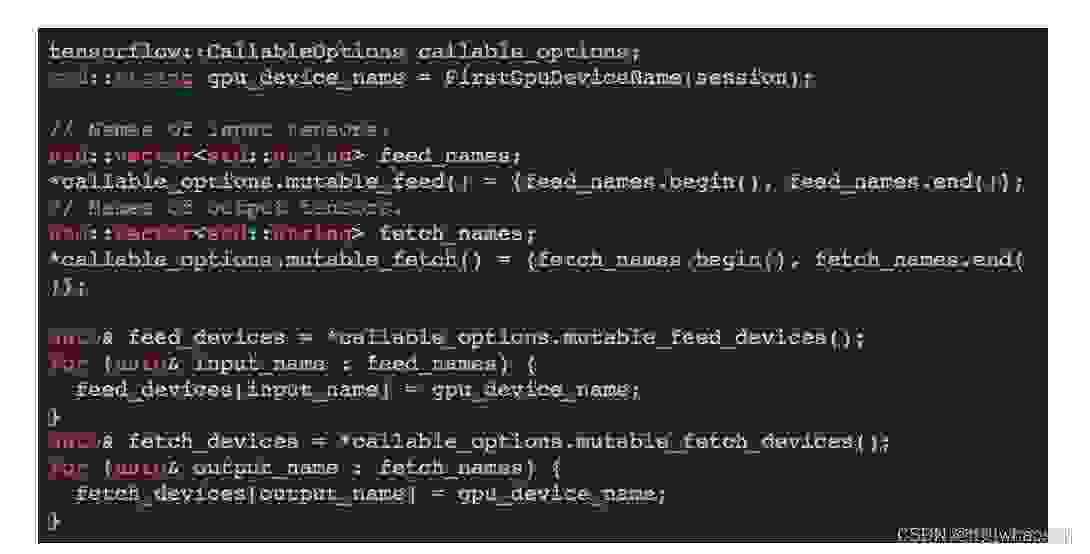
使用下面的函数可以获得 GPU 设备的名称:

现在,用户可以创建一个 tensorflow::Session::CallableHandle 的实例,这个类封装了如何在 GPU 上运行带有输入和输出的 TensorFlow 图的方法。创建和销毁可调用对象的代价比较大,所以最好只在模型初始化时创建和销毁可调用对象。另外,可调用的对象应该在会话本身被销毁之前被销毁。

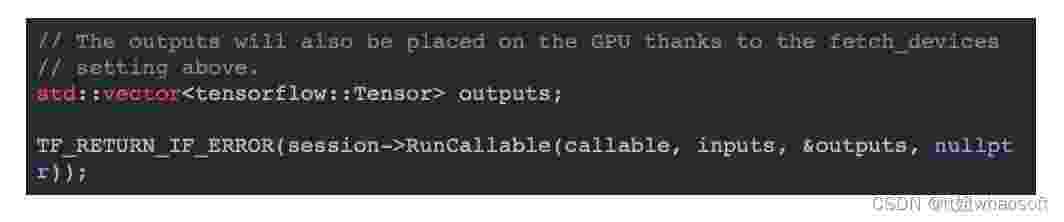
接下来就可以创建一些输入张量了。在这个例子中,本文将只使用 TensorFlow 内置的 GPU 分配器,但其实也是可以通过 tensorflow::TensorBuffer 接口将外部张量传入外部 GPU 缓冲区。

最后就可以运行模型了。现在,TensorFlow 既可以直接使用来自 GPU 的输入,也可以将输出放在同一个 GPU 上 whaosoft aiot http://143ai.com
使用 CUDA stream
尽管 TensorFlow 内部使用 CUDA stream,但上述样例中所有的 CUDA 操作仍然是同步的。运行 cudaDeviceSynchronize 必须要在分配内存之前,以确保不会破坏先前分配好的 TensorFlow 内存。还必须在写入输入后进行同步操作,以确保 TensorFlow 能获取到有效的输入。TensorFlow 本身也会在模型执行结束时与 GPU 进行同步,以确保输出的张量是有效的。
显然,人们希望 GPU 能尽可能长时间地异步运行以减少 CPU 造成的阻塞。幸运的是,用户可以访问内部的 TensorFlow CUDA stream。TensorFlow CUDA stream 的输入必须与 TensorFlow 的流同步,而输出的使用对象必须在访问内存之前与 TensorFlow 的流同步。使用 TensorFlow CUDA stream,我们可以完全取消与 CPU 的同步。
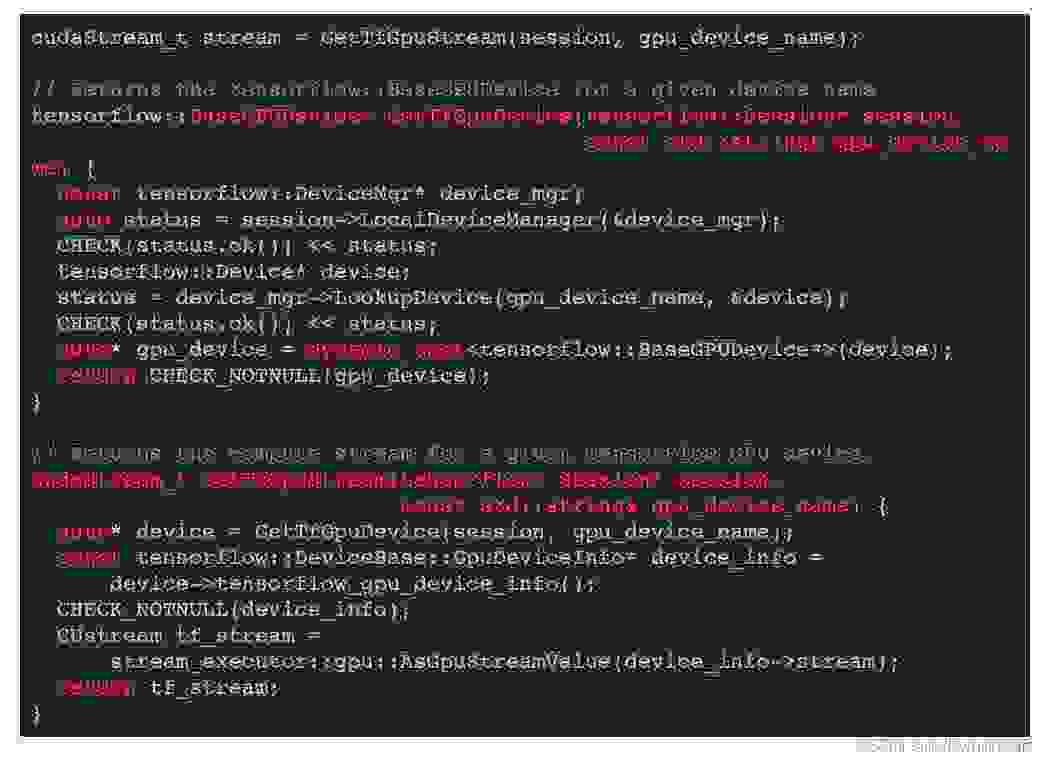
具体来说,首先,在 CallableOptions 上设置一个额外的选项,以便在模型执行结束时禁用 TensorFlow 的内部同步。 
可以使用下面的辅助函数访问内部流,需要注意的是参数包括设备名称。
创建模型的输入,并如下面的代码所示运行。注意这里没有调用 cudaDeviceSynchronize!
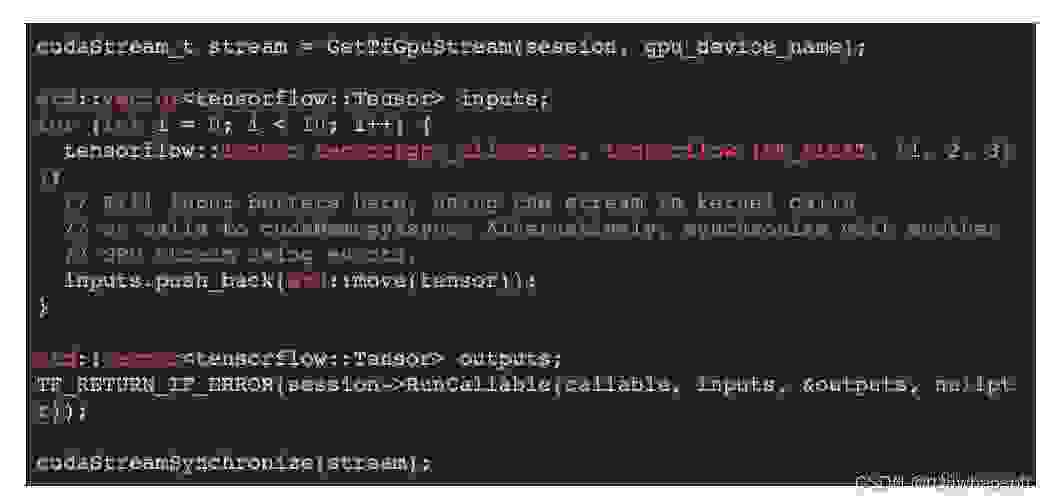
请注意,如果 TensorFlow 内部需要将内存从 GPU 复制到 CPU,那么在运行模型时仍然可能发生 CPU 与 GPU 同步。然而,在向模型传递输入和输出时不再固有的需要任何与 CPU 的同步。
结论
作者旨在通过这篇文章演示如何只通过 GPU 将输入和输出传递给 TensorFlow,这样一来可以绕过 PCIe 总线,减少开销和有限的 CPU 内存带宽。在 Exafunction,研究者们将在他们的模型服务解决方案——ExaDeploy——中使用这样的技术,以最大限度地提高 GPU 的利用率,即使是那些具有非常大的输入和输出的模型。