
文章目录
每篇前言二、Excel文件1. read_excel()iosheet_nameheadernamesindex_colusecolssqueezeskiprows 2. to_excel()excel_writersheet_namena_repindexcolumns 二、书籍推荐
每篇前言
??作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6 |
二、Excel文件
包括xls和xlsx两种格式均得到支持,底层是调用了xlwt和xlrd进行excel文件操作,相应接口为read_excel()和to_excel()
1. read_excel()
格式代码:
pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, parse_cols=None, usecols=None, squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, comment=None, skip_footer=0, skipfooter=0, convert_float=True, mangle_dupe_cols=True, **kwds)常用参数:
io:文件路径
sheet_name:默认是sheetname为0(第一个sheet表);sheet_name=“Sheet1”(指定表名);返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。
header :指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header = None
names:指定列的名字,传入一个list数据
index_col:指定列为索引列,默认None列(0索引)用作DataFrame的行标签。
usecols:该参数为返回指定的列。int或list,默认为None。
如果为None则解析所有列
如果为int则表示要解析的最后一列
如果为int列表则表示要解析的列号列表
如果字符串则表示以逗号分隔的Excel列字母和列范围列表(例如“A:E”或“A,C,E:F”)。范围包括双方
squeeze:boolean,默认为False,如果解析的数据只包含一列,则返回一个Series。
dtype:列的类型名称或字典,默认为None,也就是不改变数据类型。其作用是指定列的数据类型。
io
指定文件路径
>>> import pandas as pd>>>>>> df = pd.read_excel(r'E:\Python学习\test.xls')>>> print(df) 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女sheet_name
默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe。
>>> import pandas as pd>>>>>> # 一、默认情况>>> df = pd.read_excel(r'E:\Python学习\test.xls')>>> print(df) 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女>>>>>> # 二、指定第一个sheet表格>>> # 1. 索引方式>>> df = pd.read_excel(r'E:\Python学习\test.xls', sheet_name=0)>>> print(df) 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女>>> # 2. sheet表名方式指定第一个>>> df = pd.read_excel(r'E:\Python学习\test.xls', sheet_name='Sheet1')>>> print(df) 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女>>>>>> # 三、指定多个表格>>> df = pd.read_excel(r'E:\Python学习\test.xls', sheet_name=[0, 1])>>> print(df){0: 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女, 1: 学科 成绩0 语文 1001 数学 902 英语 80}>>>>>> # 三、返回全表>>> # 1. sheetname=None>>> df = pd.read_excel(r'E:\Python学习\test.xls', sheet_name=None)>>> print(df){'Sheet1': 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女, 'Sheet2': 学科 成绩0 语文 1001 数学 902 英语 80}>>> # 2. 指定多表时选择全部>>> df = pd.read_excel(r'E:\Python学习\test.xls', sheet_name=[0, 1])>>> print(df){0: 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女, 1: 学科 成绩0 语文 1001 数学 902 英语 80}header
指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header = None
>>> import pandas as pd>>>>>> # 一、默认第一行数据作为列名>>> df = pd.read_excel(r'E:\Python学习\test.xls')>>> print(df) 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女>>> df = pd.read_excel(r'E:\Python学习\test.xls', header=0)>>> print(df) 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女>>>>>> # 二、数据不含作为列名的行>>> df = pd.read_excel(r'E:\Python学习\test.xls', header=None)>>> print(df) 0 1 20 姓名 年龄 性别1 小白 20 男2 小黑 21 男3 小红 20 女names
指定列的名字,传入一个list数据
>>> import pandas as pd>>>>>> 设置列名为A、B、C>>> df = pd.read_excel(r'E:\Python学习\test.xls', names=['A', 'B', 'C'])>>> print(df) A B C0 小白 20 男1 小黑 21 男2 小红 20 女index_col
指定列为索引列,默认None列(0索引)用作DataFrame的行标签。
>>> import pandas as pd>>>>>>> # 设置第一列为行索引>>> df = pd.read_excel(r'E:\Python学习\test.xls', index_col=0)>>> print(df) 年龄 性别姓名小白 20 男小黑 21 男小红 20 女usecols
该参数为返回指定的列。int或list,默认为None。如果为None则解析所有列,如果为int则表示要解析的最后一列,如果为int列表则表示要解析的列号列表,如果字符串则表示以逗号分隔的Excel列字母和列范围列表(例如“A:E”或“A,C,E:F”)。范围包括双方
>>> import pandas as pd>>>>>> # 一、传入字符串>>> # 1. 指定不连续列>>> df = pd.read_excel(r'E:\Python学习\test.xls', usecols="A,C")>>> print(df) 姓名 性别0 小白 男1 小黑 男2 小红 女>>> # 2. 指定A、B、C列>>> df = pd.read_excel(r'E:\Python学习\test.xls', usecols="A,B:C")>>> print(df) 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女>>>>>> # 二、传入列表>>> # 1. 索引方式>>> df = pd.read_excel(r'E:\Python学习\test.xls', usecols=[0, 1, 2])>>> print(df) 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女>>> # 2. 表头方式>>> df = pd.read_excel(r'E:\Python学习\test.xls', usecols=['姓名', '年龄', '性别'])>>> print(df) 姓名 年龄 性别0 小白 20 男1 小黑 21 男2 小红 20 女squeeze
默认为False,如果解析的数据只包含一列,True则返回一个Series。
>>> import pandas as pd>>>>>> # 只读取第一列,设置为Series>>> df = pd.read_excel(r'E:\Python学习\test.xls', usecols="A",squeeze=True)>>> print(df)0 小白1 小黑2 小红Name: 姓名, dtype: object>>> print(type(df))<class 'pandas.core.series.Series'>skiprows
省略开头指定行数的数据
>>> import pandas as pd>>>>>> # 跳过第一行数据>>> df = pd.read_excel(r'E:\Python学习\test.xls', skiprows=1)>>> print(df) 小白 20 男0 小黑 21 男1 小红 20 女>>> print(type(df))<class 'pandas.core.frame.DataFrame'>2. to_excel()
语法格式:
pandas.to_excel(self, excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)常用参数:
excel_writer : 字符串或ExcelWriter 对象,文件路径或现有的ExcelWritersheet_name :字符串,默认“Sheet1”,将包含DataFrame的表的名称。na_rep : 字符串,默认‘ ’,缺失数据表示方式float_format : 字符串,默认None,格式化浮点数的字符串columns : 序列,可选,要编写的列header : 布尔或字符串列表,默认为Ture。写出列名。如果给定字符串列表,则假定它是列名称的别名。index :布尔,默认的Ture,写行名(索引)index_label : 字符串或序列,默认为None。如果需要,可以使用索引列的列标签。如果没有给出,标题和索引为true,则使用索引名称。如果数据文件使用多索引,则需使用序列。excel_writer
指定文件路径
>>> import pandas as pd>>>>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]>>> df = pd.DataFrame(data)>>> print(df) A B C0 1 2 NaN1 3 4 5.0# 写入指定路径下>>> df.to_excel(r'E:\Python学习\test1.xlsx')在指定路径下文件新文件: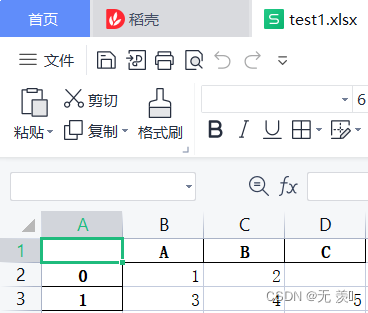
sheet_name
指定sheet表名,可以接受字符串,默认为“sheet1”
1)写入单个sheet:
>>> import pandas as pd>>>>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]>>> df = pd.DataFrame(data)>>> print(df) A B C0 1 2 NaN1 3 4 5.0# 设置sheet表名为test>>> df.to_excel(r'E:\Python学习\test1.xlsx', sheet_name='test')运行结果: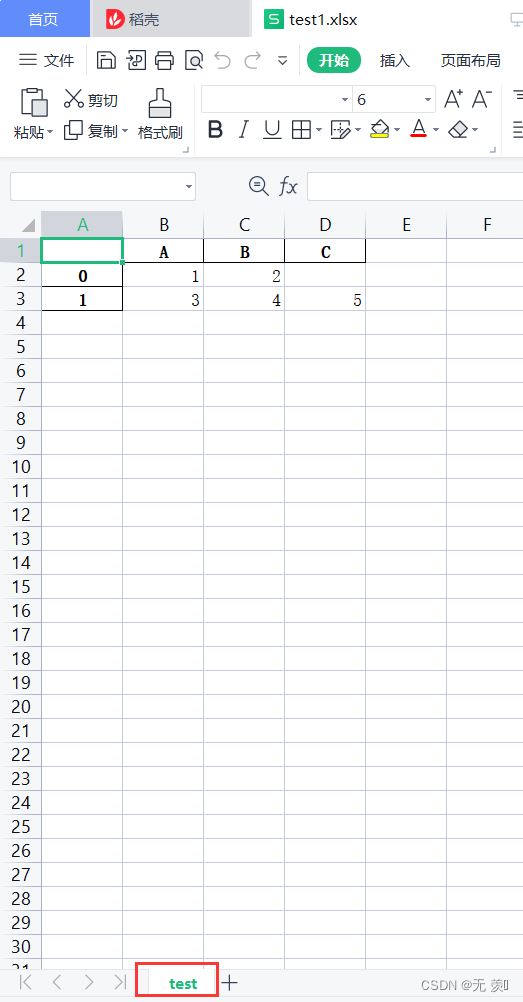
2)写入多个sheet表:
>>> import pandas as pd>>>>>> df1 = pd.DataFrame([{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}])>>> df2 = pd.DataFrame([{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}])>>>>>> with pd.ExcelWriter(r'E:\Python学习\test.xlsx') as writer:... df1.to_excel(writer, sheet_name='test1')... df2.to_excel(writer, sheet_name='test2')运行结果:
na_rep
表示替补缺失数据,不写默认为空
>>> import pandas as pd>>>>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]>>> df = pd.DataFrame(data)>>> print(df) A B C0 1 2 NaN1 3 4 5.0# 把空值替换为100>>> df.to_excel(r'E:\Python学习\test.xlsx', na_rep='100')运行结果: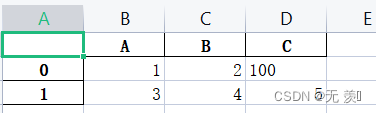
index
表示是否写行索引,默认为True
1)不写入行索引:
>>> import pandas as pd>>>>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]>>> df = pd.DataFrame(data)>>> print(df) A B C0 1 2 NaN1 3 4 5.0>>> df.to_excel(r'E:\Python学习\test.xlsx', index=False)运行结果:
2)写入行索引:
>>> import pandas as pd>>>>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]>>> df = pd.DataFrame(data)>>> print(df) A B C0 1 2 NaN1 3 4 5.0>>> df.to_excel(r'E:\Python学习\test.xlsx', index=True)运行结果: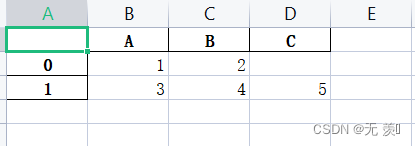
columns
指定要写入的列
>>> import pandas as pd>>>>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]>>> df = pd.DataFrame(data)>>> print(df) A B C0 1 2 NaN1 3 4 5.0# 只写入A、B列>>> df.to_excel(r'E:\Python学习\test.xlsx', columns=['A','B'])运行结果: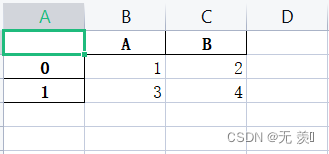
二、书籍推荐
书籍展示:《元宇宙:图说元宇宙、设计元宇宙(全两册)》
【书籍内容简介】
世间可曾存在着这样一个时空?那里高度自由,不会受到任何来自外界的干涉和干扰;那里无限可能,可凭个人喜好随性创造……有的,就叫“元宇宙”!
元宇宙,可以满足不同人不同的期许,可以实现不同人不同的梦想,甚至可以容下世间所有截然不同的存在!心动吗?别急,在此之前,我们需要先明白“什么是元宇宙”,以及,“如何架构属于自己的元宇宙”——
北京大学出版社联合文津图书奖得主、全国十大科普教育平台“量子学派”与中国科学院院士,共同推出《元宇宙:图说元宇宙、设计元宇宙(全两册)》一书,不仅用场景化的叙事艺术带你轻松入门元宇宙,更有320幅手绘插图、十一维元宇宙关系图谱和大拉页版“2140世界设定”,助你直观地了解并且亲手架构独一无二的元宇宙!
元宇宙时代已缓缓开启,做好准备就启程吧!
京东自营:https://item.jd.com/13577756.html