目录
一,keepalived介绍
1,keepalived是什么
2、Keepalived工作原理
3、Keepalived 体系主要模块及其作用
二,keepalived服务主要功能
1,管理LVS负载均衡软件
2,支持故障自动切换
3、实现LVS集群中节点的健康检查
4、实现LVS负载调度器、节点服务器的高可用性
三,脑裂的形成和解决
1,什么是脑裂
2,出现脑裂的原因
3,预防脑裂的发生
四,部署LVS-DR +Keepalived集群
1,关闭防火墙,核心防护,下载ipvsadm,keepalived
2,添加虚拟子接口
3,调整proc响应参数
4,配置负载均衡策略
5,切换到lvs1(主)
6,验证
一,keepalived介绍
keeplived 软件起初是专门为LVS 负载均衡 软件设置的,用来管理并监控LVS集群中各个服务节点的状态,后来加入了可以实现高可用的VRRP 功能。因此,keepalived除了能管理LVS 集群以外,还可以为其它服务(如:Nginx、Haproxy、Mysql等)实现高可用。keepalived 软件主要是通过 VRRP 协议 实现高可用的功能。VRRP是Virtual Router Redundancy Protocol(虚拟路由器冗余协议)的速写,VRRP出现的目的就是为了解决静态路由单点故障的问题,它能保证当个别节点出现问题时,整个网络可以不间断的运行。1,keepalived是什么
Keepalived是一款专为LVS 和HA 设计的一款健康检查工具。
支持故障自动切换、支持节点健康状态检查2、Keepalived工作原理
Keepalive是一个基于VRRP协议来实现的LVS服务高可用方案,可以解决静态路由出现的单点故障问题。在一个LVS服务集群中,通常有 主服务器(MASTER) 和备服务器(BACKUP) 两种角色的服务器,但是对外表现为一个虚拟IP,主服务器会发送VRRP通告信息给备份服务器,当备服务器收不到VRRP消息的时候,即主服务器异常的时候,备份服务器就会接管虚拟IP,继续提供服务,从而保证高可用性。在Keepalive服务之间,只有作为主的服务器会一直发送VRRP广播包,告诉备它还活着,此时备不会抢占主,当主不可用时,备监听不到主发送的广播包后,就会启动相关服务器接管资源,保证业务的连续性,接管速度最快可以小于1秒。3、Keepalived 体系主要模块及其作用
Keepalive体系架构中主要有三个模块,分别是core、check和vrrp
core模块: 为keepalive的核心、负责主进程的启动,维护及全局配置文件的加载和解析check模块: 负责健康检查,常见的方式有端口检查及URL检查vrrp模块: 是来实现VRRP协议的二,keepalived服务主要功能
1,管理LVS负载均衡软件
Keepalive可以通过读取自身的配置文件,实现通过更底层的接口直接管理LVS的配置以及控制服务的启动、停止功能
2,支持故障自动切换
Keepalived可以实现任意两台主机之间,例如:Master和Backup主机之间的故障转移和自动切换,这个主机可以是普通的不能停机的业务服务器,也可以是LVS负载均衡,Nginx反向代理这样的服务器。Keepalived高可用功能实现的简单原理为,两台主机同时安装好Keepalived软件并启动服务,开始正常工作时,由角色为Master的主机获得所有资源并对用户提供服,角色为Backup的主机为Master主机的热备,当角色为Master的主机失效或出现故障时,角色为Backup的主机将自动接管Master主机的所有工作,包括接管VIP资源及相应资源服务,当角色为Master的主机故障修复后,又会自动接管回他原来处理的工作,角色Bachup的主机则同时释放Master主机时它接管的工作,此时,两台主机将恢复到最初启动时各自的原始及工作状态。3、实现LVS集群中节点的健康检查
Keepalived可以通过在自身的Keepalived.conf文件里配置LVS的节点IP和相关参数实现对LVS的直接管理;除此之外,当LVS集群中的某一个甚至是几个节点服务器同时发生故障无法提供服务时,Keepalived服务会自动将失效的节点服务器从LVS的正常转发队列中清除出去,并将请求调度到别的正常节点服务器上,从而保证最终用户的访问不受影响;当故障的节点服务器被修复以后,Keepalived服务又会自动地把它们加入到正常转发队列中,对客户提供服务。
4、实现LVS负载调度器、节点服务器的高可用性
一般企业集群需要满足三个特点: 负载均衡、健康检查、故障切换 ,使用LVS+Keepalived完全可以满足需求
keeplived的检查方式
ping方式检查(不全面)
基于脚本检查(周期检查master服务器的服务是否停止,停止之后使用停止keeplived,进行漂移,并邮件告警
三,脑裂的形成和解决
1,什么是脑裂
当MASTER节点出现网络堵塞等现象时,BACKUP节点因无法及时检测到MASTER节点的heartbeat而认为MASTER节点已经挂掉了,就抢来了MASTER节点的VIP,并接管了MASTER节点的资源。而MASTER节点认为自己还是正常的,这就出现了同一个服务集群中,同一个VIP地址同时飘在两个节点上的现象,即产生了两个MASTER节点,正常情况下是一个节点对外提供服务,现在也变成了两个节点能同时被用户访问到,对于一个集群同时存在两个MASTER状态的现象,我们称之为脑裂
2,出现脑裂的原因
通常,脑裂现象的出现是由以下几种情况引起的:
高可用集群服务器队列之间的心跳线链路发生了故障,如心跳线的断裂、老化等导致各节点之间无法正常通信;集群服务器队列之间的IP配置发生了冲突;网卡或交换机等负责连接心跳线的设备发生了故障;高可用服务器上未禁止iptables防火墙规则的生成,导致心跳消息无法传输;在同一个VRRP实例中,各节点上的virtual_router_id设置的参数不同;开启了抢占模式,但是未设置抢占延时。3,预防脑裂的发生
为了减少或避免HA集群中出现脑裂现象,我们可以采取以下措施:
添加冗余心跳线,如双线条线等;启动“智能”磁盘锁,只有正在提供服务的MASTER节点才能锁住或者解锁共享磁盘,当MASTER节点出现了短暂的网络堵塞等情况时会自动加锁,BACKUP节点也无法接管资源,只有当MASTER出现故障无法提供服务时才会自动解锁共享磁盘,并交由BACKUP节点接管设置仲裁机制,例如出现检测不到心跳线的情况时,MASTER节点和BACKUP节点都去ping一下网关IP,如果ping不通则主动释放资源或者放弃抢占资源;通过脚本来监控和监测节点是否处于正常工作状态,如果MASTER节点出现了异常,并在脚本设定的期限内无法恢复正常,则杀死当前MASTER的服务进程,将资源交由BACKUP节点来接管。四,部署LVS-DR +Keepalived集群
根据上篇博客https://blog.csdn.net/m0_54594153/article/details/126731030?spm=1001.2014.3001.5502操作,再添加一台LVS服务器做(备用)负载均衡调度器
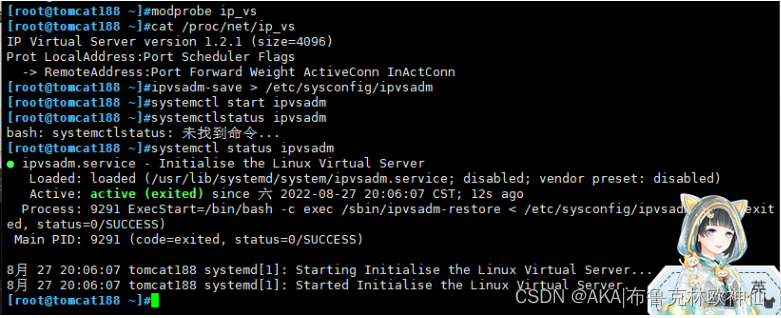
1,关闭防火墙,核心防护,下载ipvsadm,keepalived
systemctl stop firewalldsetenforce 0yum -y install ipvsadm keepalivedmodprobe ip_vs 加载模块信息
cat /proc/net/ip_vs 查看ipvs 版本信息
ipvsadm-save > /etc/sysconfig/ipvsadm 创建一个ipvsadm的一个配置文件
systemctl start ipvsadm
2,添加虚拟子接口

并且重启

3,调整proc响应参数
由于lvs负载均衡器和各个节点需要共用vip地址,应该关闭linux内核系统重定向响应参数,不充当路由器
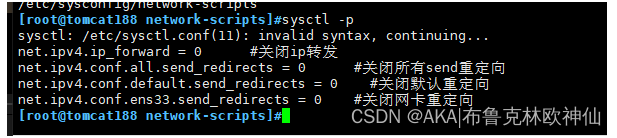
vim /etc/sysctl.conf #编辑内核proc参数 net.ipv4.ip_forward = 0 #关闭ip转发 net.ipv4.conf.all.send_redirects = 0 #关闭所有send重定向 net.ipv4.conf.default.send_redirects = 0 #关闭默认重定向 net.ipv4.conf.ens33.send_redirects = 0 #关闭网卡重定向
sysctl -p #查看内核参数

刷新生效
4,配置负载均衡策略
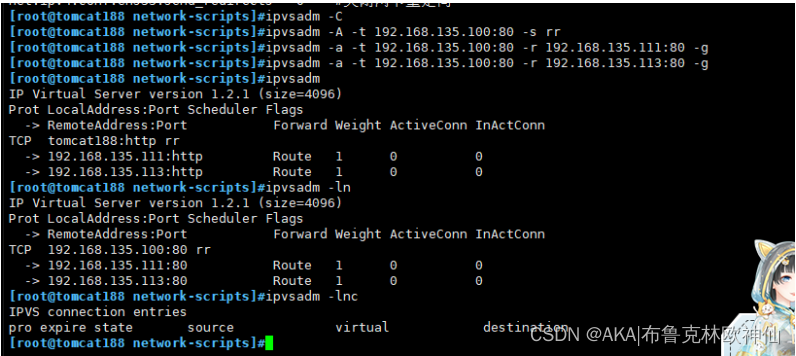
[root@tomcat188 network-scripts]#ipvsadm -C
[root@tomcat188 network-scripts]#ipvsadm -A -t 192.168.135.100:80 -s rr
[root@tomcat188 network-scripts]#ipvsadm -a -t 192.168.135.100:80 -r 192.168.135.111:80 -g
[root@tomcat188 network-scripts]#ipvsadm -a -t 192.168.135.100:80 -r 192.168.135.113:80 -g
[root@tomcat188 network-scripts]#ipvsadm
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP tomcat188:http rr
-> 192.168.135.111:http Route 1 0 0
-> 192.168.135.113:http Route 1 0 0
[root@tomcat188 network-scripts]#ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.135.100:80 rr
-> 192.168.135.111:80 Route 1 0 0
-> 192.168.135.113:80 Route 1 0 0
[root@tomcat188 network-scripts]#ipvsadm -lnc
IPVS connection entries
pro expire state source virtual destination
[root@tomcat188 network-scripts
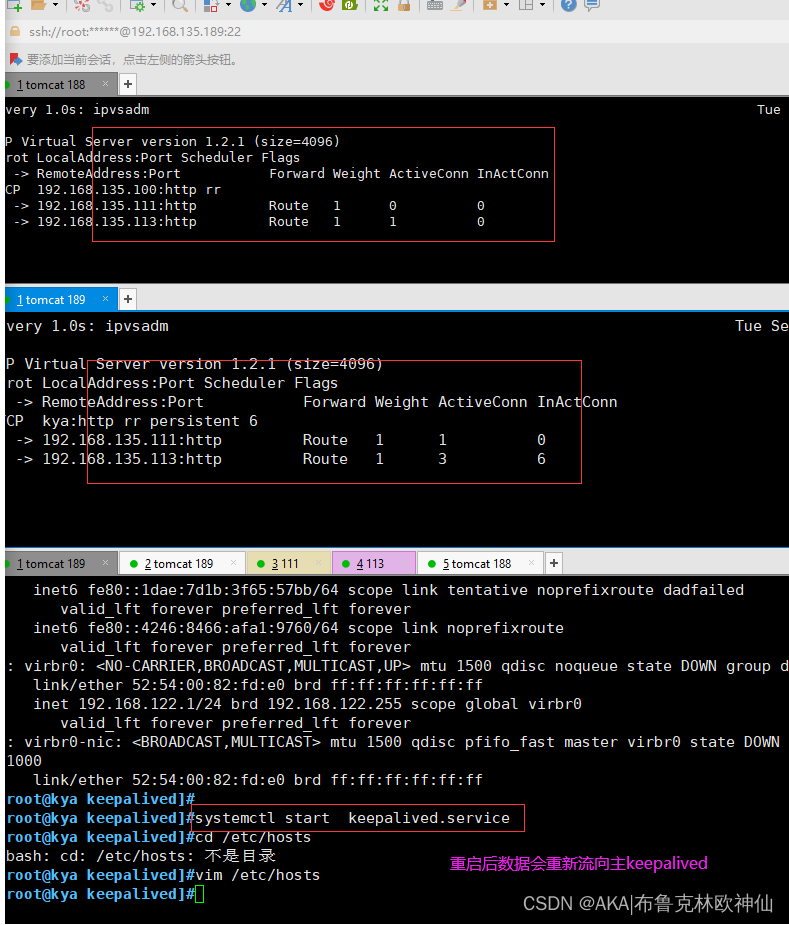
5,切换到lvs1(主)
进入keepalived的配置文件,把原来的删掉,添加以下内容

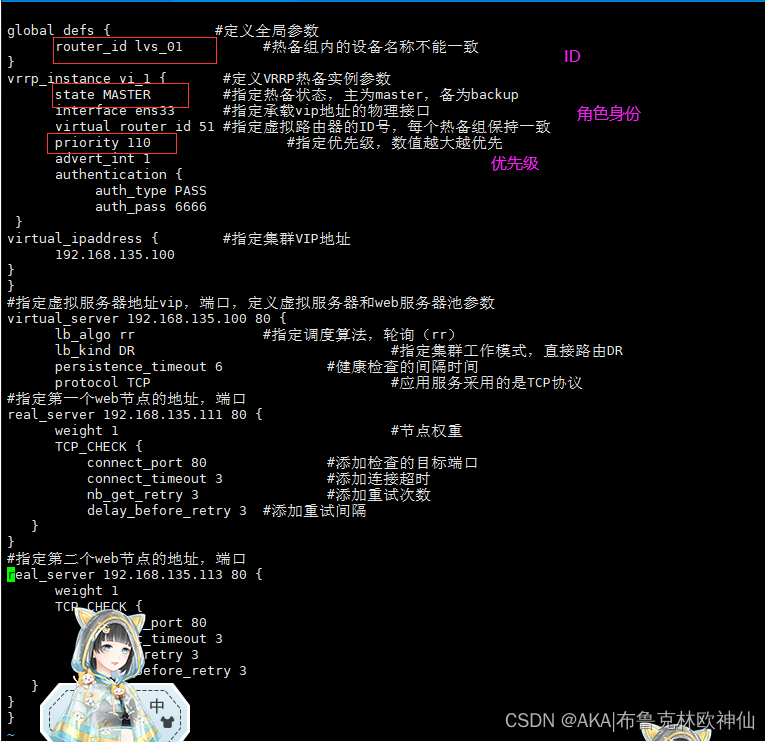
global_defs { #定义全局参数 router_id lvs_01 #热备组内的设备名称不能一致}vrrp_instance vi_1 { #定义VRRP热备实例参数 state MASTER #指定热备状态,主为master,备为backup interface ens33 #指定承载vip地址的物理接口 virtual_router_id 51 #指定虚拟路由器的ID号,每个热备组保持一致 priority 110 #指定优先级,数值越大越优先 advert_int 1 authentication { auth_type PASS auth_pass 6666 }virtual_ipaddress { #指定集群VIP地址 192.168.135.100}}#指定虚拟服务器地址vip,端口,定义虚拟服务器和web服务器池参数virtual_server 192.168.135.100 80 { lb_algo rr #指定调度算法,轮询(rr) lb_kind DR #指定集群工作模式,直接路由DR persistence_timeout 6 #健康检查的间隔时间 protocol TCP #应用服务采用的是TCP协议#指定第一个web节点的地址,端口real_server 192.168.135.111 80 { weight 1 #节点权重 TCP_CHECK { connect_port 80 #添加检查的目标端口 connect_timeout 3 #添加连接超时 nb_get_retry 3 #添加重试次数 delay_before_retry 3 #添加重试间隔 }}#指定第二个web节点的地址,端口real_server 192.168.135.113 80 { weight 1 TCP_CHECK { connect_port 80 connect_timeout 3 nb_get_retry 3 delay_before_retry 3 }}}LVS(主)
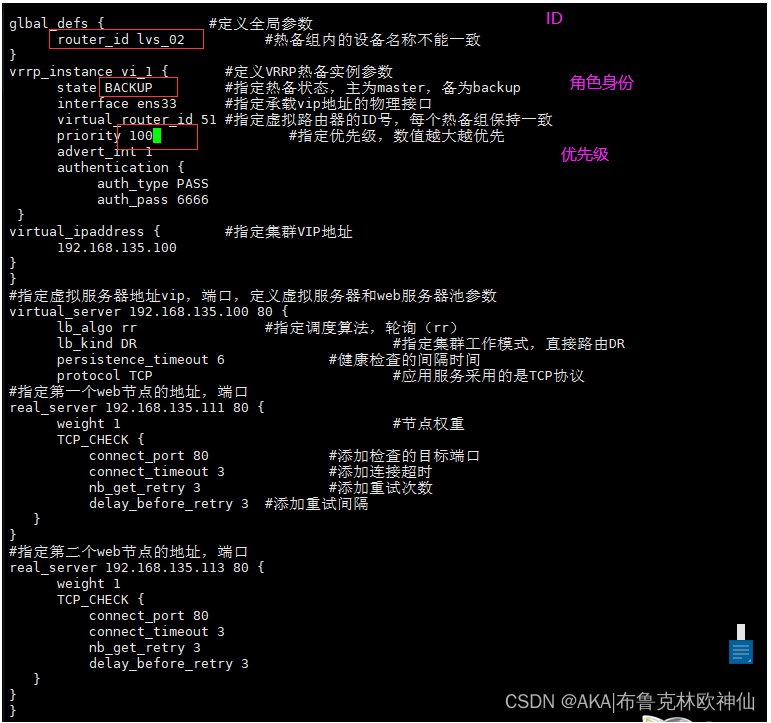
LVS(备)
查看两台lvs网卡,都没有ens33:0
使用 ip addr,查看网卡
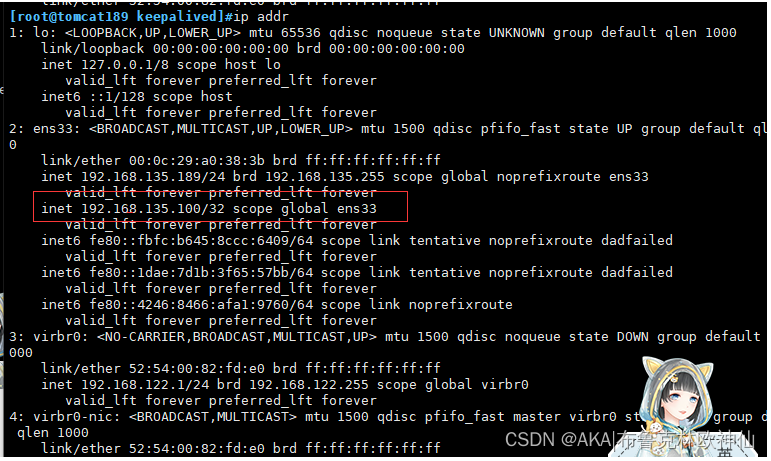
6,验证
用windows访问192.168.135.100
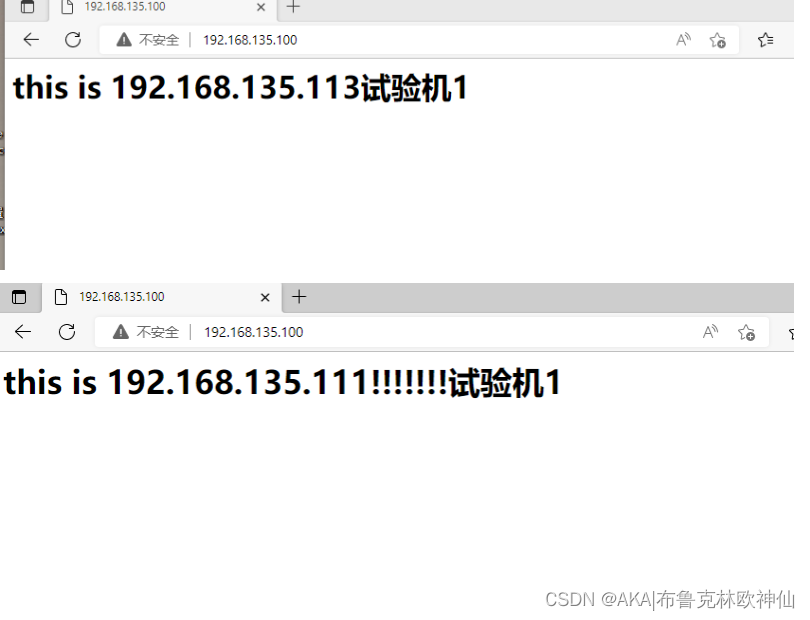
查看数据请求

关闭掉keeplived模拟故障
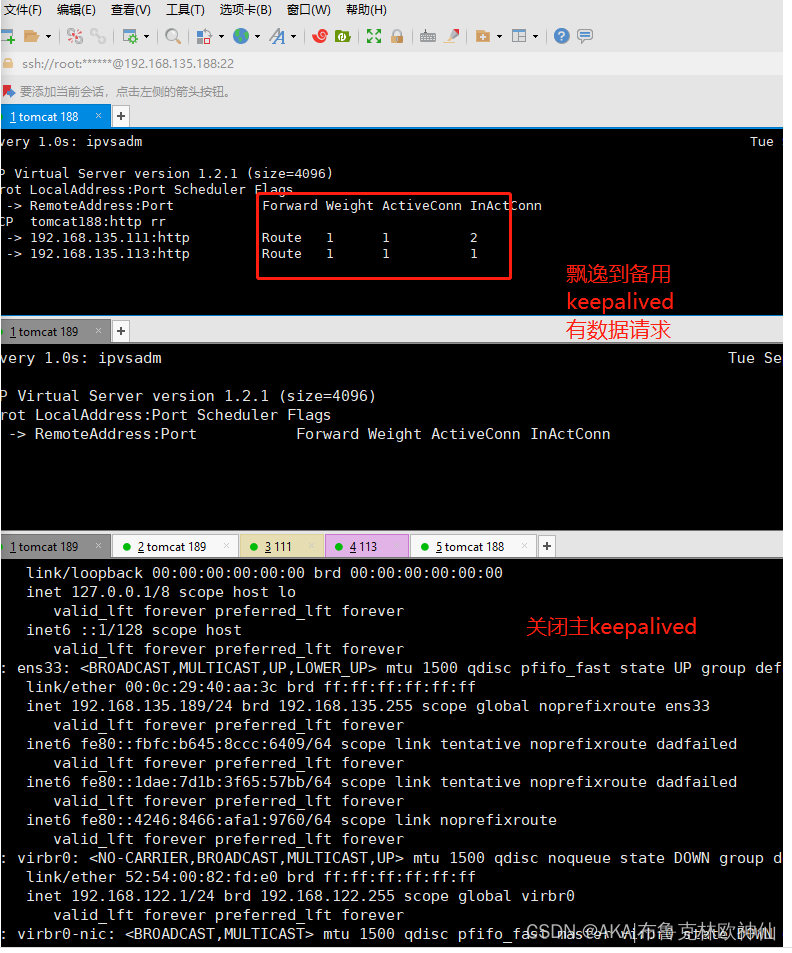
重启一下后,又会再次漂移回lvs主