?作者简介:博主是一位.Net开发者,同时也是RPA和低代码平台的践行者。
?个人主页:会敲键盘的肘子
?系列专栏:UiPath
?专栏简介:UiPath在传统的RPA(Robotic process automation)的基础上,增加了See(AI通过计算机视觉阅读用户的计算机屏幕)和Think(通过机器学习来发现平台能够为用户构建什么自动化流程)从而不断帮助用户自动化构建流程,而不仅仅是用户自主发现,自主构建。并且在构建的过程当中,做到了Low-code甚至是No-code的程度,让每一位员工都可以自主使用。
?座右铭:总有一天你所坚持的会反过来拥抱你。

?写在前面:
PDF 是一种广泛使用的文档共享格式。在本课程中,我们将了解 PDF 文档的类型以及从 PDF 文档中提取数据时可以使用的方法。我们还将研究处理不稳定选取器时使用的锚点基准功能。
?本文关键字:RPA、UiPath、Low-code、No-code、PDF自动化、提取数据、锚点基准功能、.Net
文章目录
1️⃣ 背景♈ 什么是RPA♉ 什么是UiPath♊ 为什么使用UiPath♋ 为什么要用PDF自动化 2️⃣ 概述♈ 环境♉ 摘要♊ 您将学到的内容 3️⃣ PDF自动化♈ 前置知识♉ 安装 UiPath PDF 活动包♊ 从 PDF 提取文本块或整个文档⭐ 背景⭐方法一:读取 PDF 文本⭐方法二:使用 OCR 读取 PDF⭐方法三:屏幕抓取工具 ♋ 从 PDF 提取单个数据段⭐ 背景⭐ 获取文本活动——Get Text Activity⭐ 录制器⭐ 从多个文件中获取 ♌ 锚点基准活动⭐ 背景⭐ 锚点基准活动⭐ Modern Design Experience activity 4️⃣ 总结5️⃣ 参考资料
1️⃣ 背景
♈ 什么是RPA
RPA(Robotic process automation) 代表机器人过程自动化。
它是一种软件程序,可在与计算机应用程序交互时模仿人类行为并实现重复的、基于规则的流程的自动化。
♉ 什么是UiPath
UiPath 是一种机器人流程自动化工具,用于自动化枯燥和重复的任务。它由罗马尼亚企业家 Daniel Dines 和 Marius Trica 于 2005 年创立。它还消除了自动化无聊任务的人工干预,并为所有活动提供了拖放功能,它是最简单的 RPA 工具。
♊ 为什么使用UiPath
UiPath在传统的RPA的基础上,增加了See(AI通过计算机视觉阅读用户的计算机屏幕)和Think(通过机器学习来发现平台能够为用户构建什么自动化流程)从而不断帮助用户自动化构建流程,而不仅仅是用户自主发现,自主构建。并且在构建的过程当中,做到了Low-code甚至是No-code的程度,让每一位员工都可以自主使用。
♋ 为什么要用PDF自动化
获取原生PDF中某一部分的获取文本写入到另一个文件中(比如研究员可以批量处理包含某些关键字的文本文档而不是靠人工肉眼去筛选);从扫描中得到的PDF获取文本和图像(比如由扫描机获取的发票,财务人员可以运行RPA批量处理这些电子发票);精准的从获取PDF某个位置的文本并批量处理这些PDF,解放双手的同时降低了错误率;原生PDF:由电子文本转换而来的PDF,比如从Word转换成的PDF
扫描PDF:由扫描图像组成的PDF,比如扫描件中的发票
2️⃣ 概述
♈ 环境
UiPath Studio Community 2022.4.3
Windows 10
.Net
♉ 摘要
PDF 是一种广泛使用的文档共享格式。在本课程中,我们将了解 PDF 文档的类型以及从 PDF 文档中提取数据时可以使用的方法。我们还将研究处理不稳定选取器时使用的锚点基准功能。
♊ 您将学到的内容
安装 UiPath PDF 活动包;使用读取 PDF 文本活动、使用OCR 读取 PDF活动和屏幕抓取向导,从 PDF 中提取大文本段;从 PDF 文档中提取单段信息;使用选取器从具有相同布局的多个文件中提取可变值;使用锚点基准活动从一系列具有相同结构的 PDF 文件中提取可变值。3️⃣ PDF自动化
♈ 前置知识
无论是原生PDF还是扫描PDF,UiPath 都允许您根据需要导航、识别和使用 PDF 数据。在我们继续之前,您应该已经熟悉了提取数据,以及如何使用和编辑选取器。对于这两个主题,都有单独的博文进行详细介绍,所以一定要观看这些博文,避免您在学习过程中未能完全理解其中的某些内容。
♉ 安装 UiPath PDF 活动包
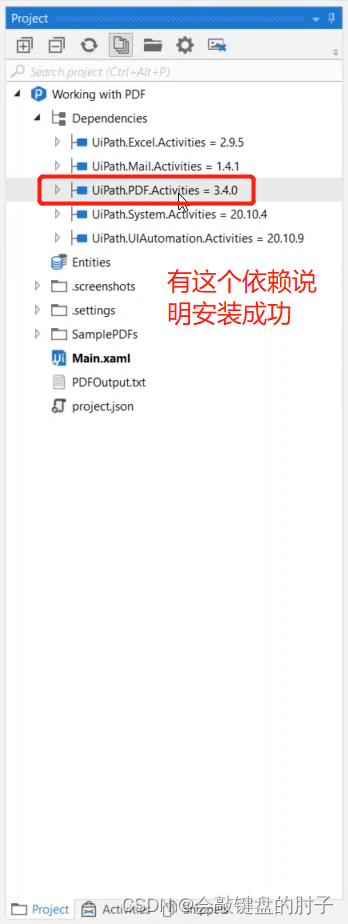
首先,确保安装了处理 PDF 文件所需的所有活动和依赖项。如果活动面板中的搜索PDF结果为空,则意味着您必须安装它们。只需转到包管理器,搜索 PDF,然后安装 UiPath PDF 活动包。单击安装之后,务必单击保存,以便实际安装活动集,并更新项目依赖项。

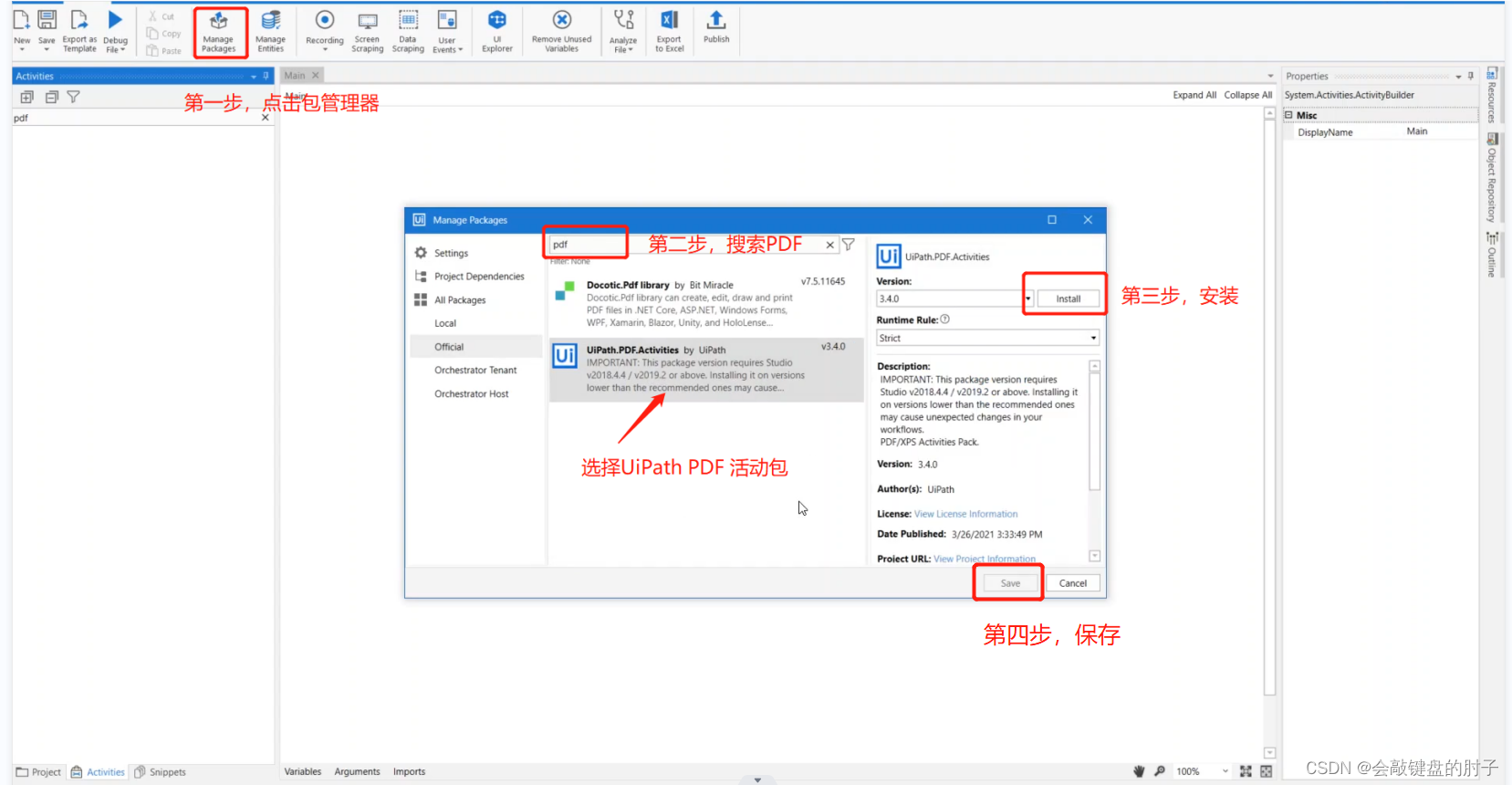
我们可以看到,要使用的最低Studio版本是2018.4.4或2019.2。在以前的Studio版本上安装包可能会导致问题。
接下来,您可能已经意识到这样一个事实:PDF 文件可以包含文本、图像,有时还可以包含实际上是秘密图像的文本。一种基本的识别方法是直接选择您感兴趣的元素。如您所见,选择文本很方便,而图像会作为块立即显现出来。稍后我们将了解如何处理这两种情况。
UiPath 有各种各样的活动和方法来满足您所有的 PDF 需求,并且我们根据它们的预期用途将它们分为两类:第一类,用于更大的文本块或整个文档;第二类,用于从 PDF 文件中提取特定的文本项,如名称、产品、发票值等。我们将从第一类开始,因为这是最简单的。
♊ 从 PDF 提取文本块或整个文档
⭐ 背景
我们要读取下图PDF,上部分是文本,下部分是图像。

⭐方法一:读取 PDF 文本
要读取整个 PDF 文档或页面,可以使用读取 PDF 文本活动。这非常简单:选择要读取的文件,操作将输出一个包含文件内容的文本变量。我们将结果保存为文本文件,并在消息框中显示,但您可以使用其他字符串操作修改生成的文本或从中提取信息。如下图:
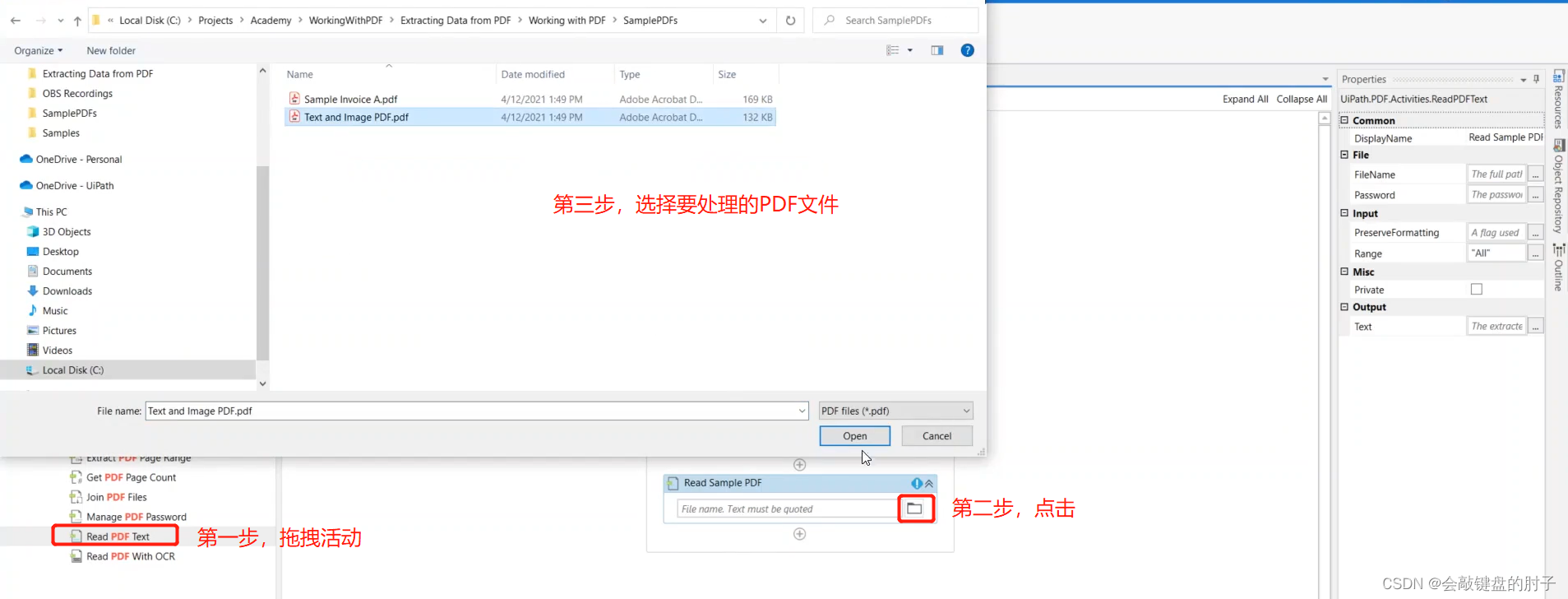
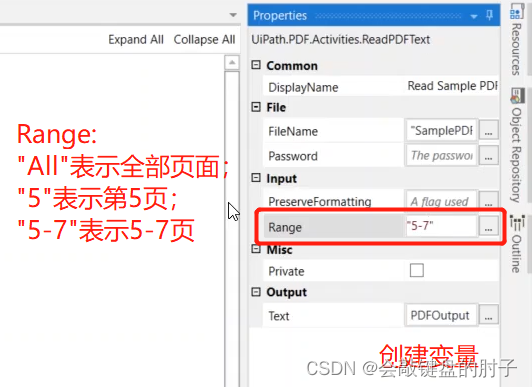
Range 参数很重要,因为它定义了实际要读取的内容。可以将它设置为所有的页面,设置为All,或者设置为一个特定的页面,比如第 5 页或第 12 页,或者一系列页面,比如从第 3 页到第 7 页。我们有一个单页文档,因此可以将其设置为“全部”或 1。如下图:
我们希望把文本写入到一个txt文件中,并通过弹窗显示出文本。如下图:
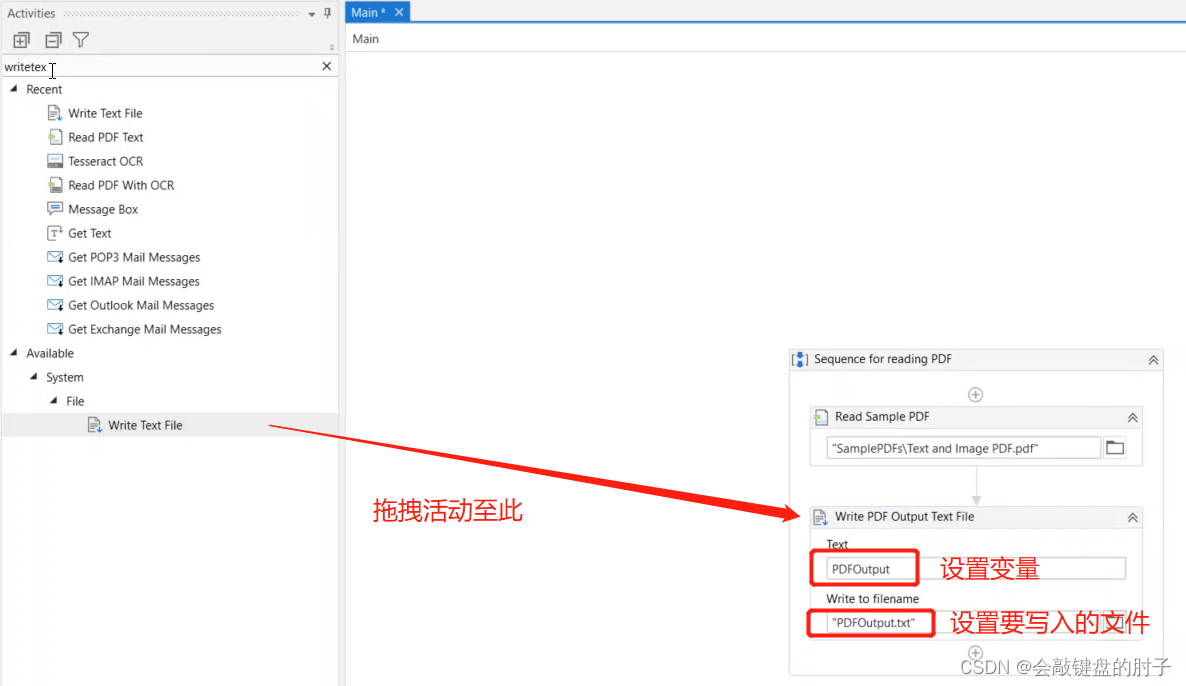

让我们运行项目,获取如下结果。
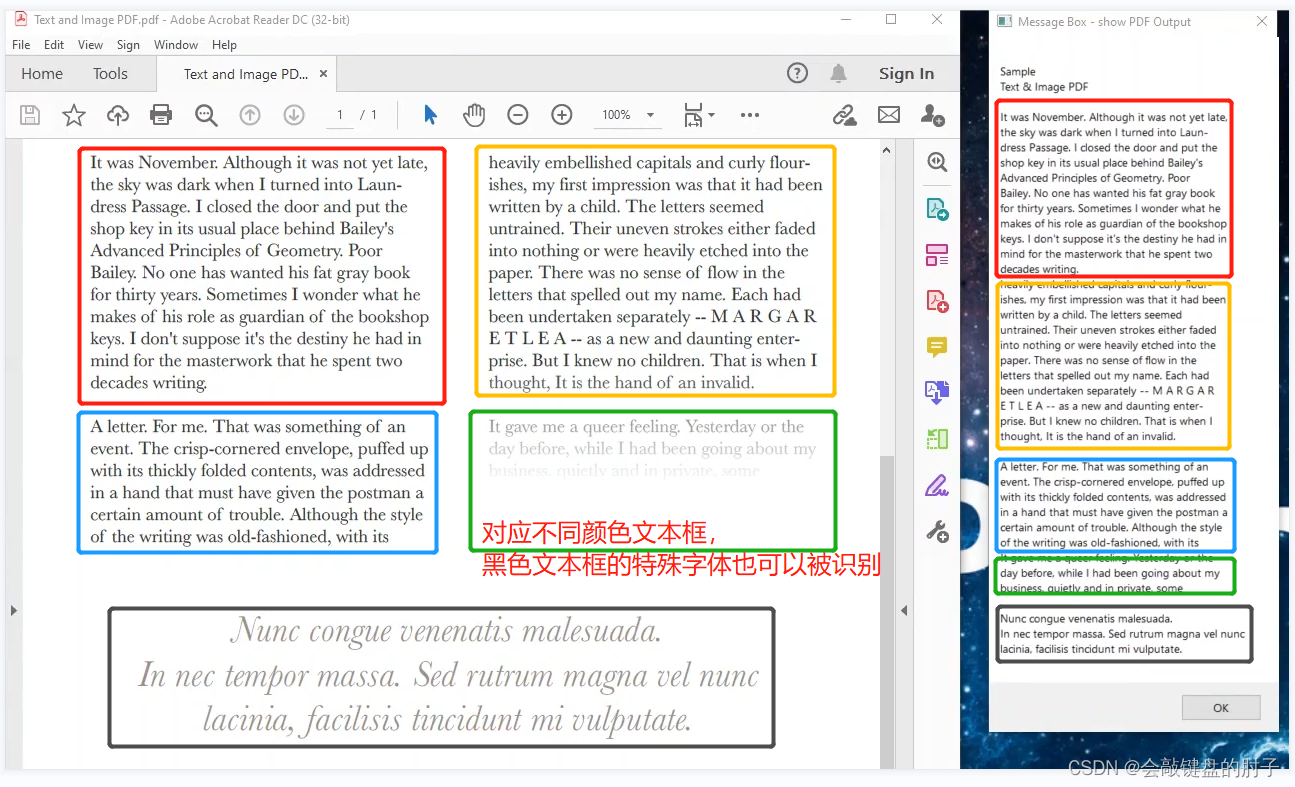
当我们查看读取 PDF 文本操作的结果时,我们发现只有文档的文本部分被转换。文本的前两列存在,但下半部分是一个图像,系统已将其完全忽略。
⭐方法二:使用 OCR 读取 PDF
因此我们需要一个活动读取 PDF 中的图像,该操作名为使用 OCR 读取 PDF。顾名思义,它会使用光学字符识别来扫描PDF 文档中的图像,并将所有文本作为变量输出。它与非 OCR 同级操作略有不同,因为它需要 OCR 引擎。
我们只需在活动窗格中搜索 OCR 即可找到可用的引擎。Studio 集成了 Google、Microsoft 和 Abbyy 的 OCR 引擎。引擎本身具有在整个应用程序中遇到的常见 OCR 参数:如允许的字符、拒绝的字符、语言、缩放比例等。不同的引擎可能有不同的参数,因此,如果您需要关于其工作方式的详细说明,请务必观看高级用户界面交互视频。这里使用Tesseract OCR 引擎运行。另外,我们删除读取 PDF 文本活动。
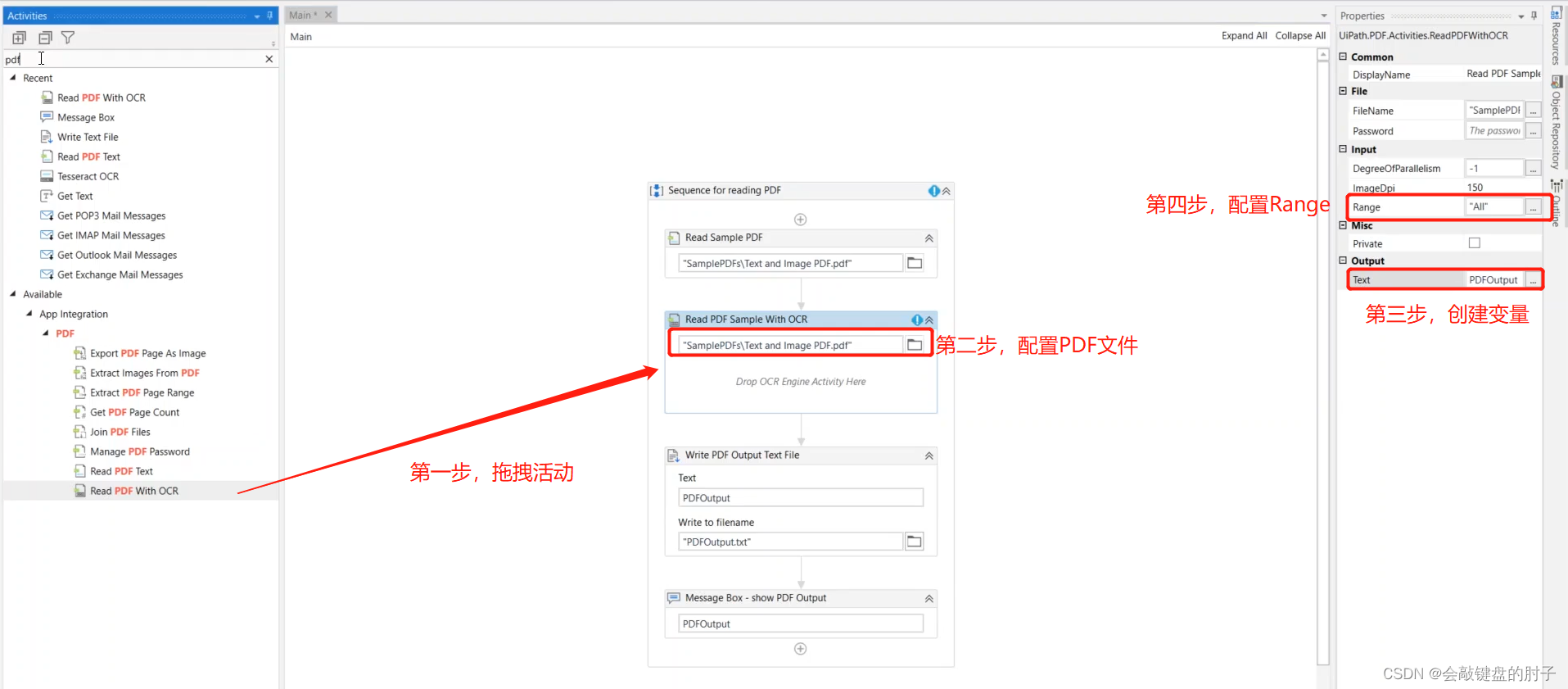
接下来,配置OCR引擎,
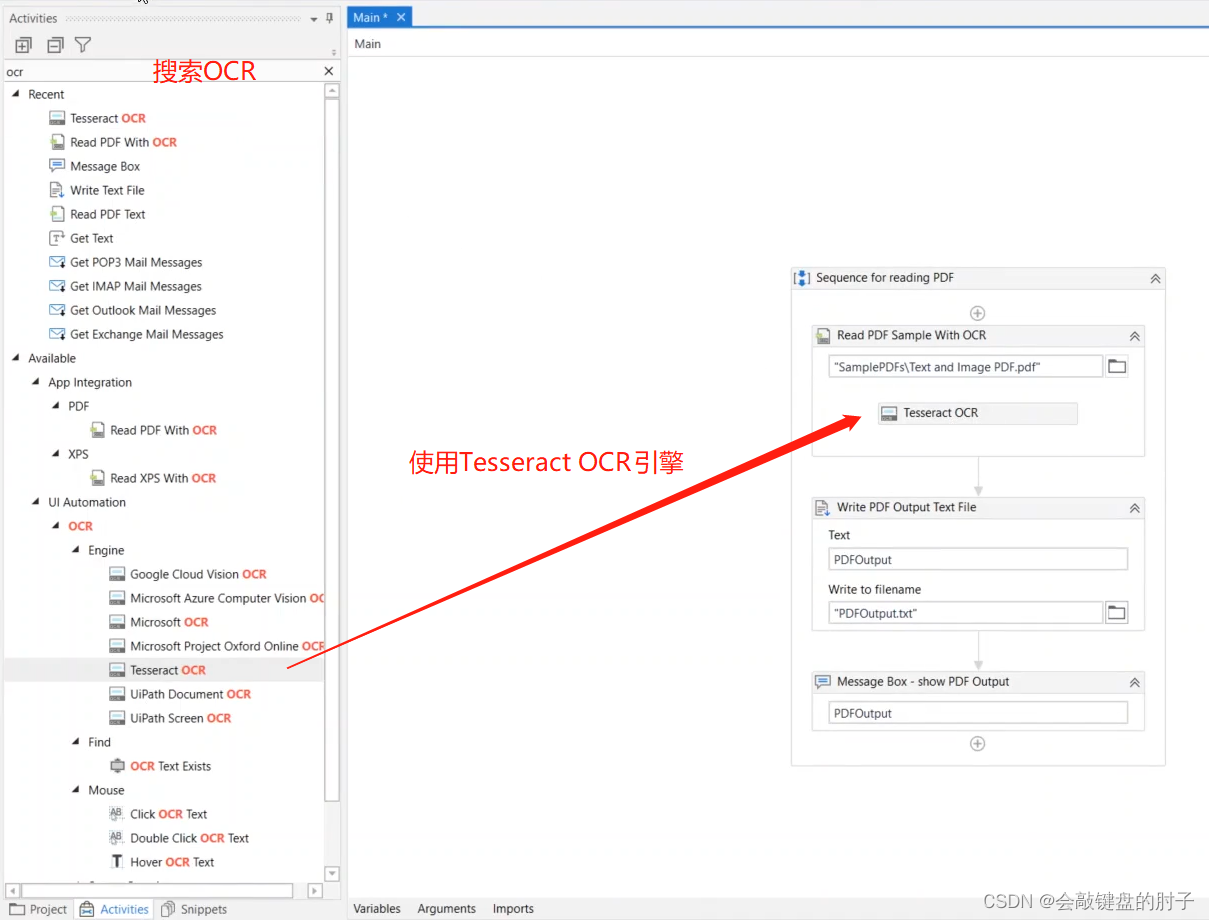
您可以直接看到下半部分,也就是 PDF 的图像部分,现在它也被转换成了文本,这没有问题。但是,如果仔细观察,您会发现文档的文本和图像部分的两列交织在一起。这是因为大多数 OCR 引擎还不够智能,无法自动识别文档中的 2 列布局。实际上,ABBY 是个例外,因为它保留了文档结构。所以,在与本例类似的特定情况下,ABBY 能够分离列。
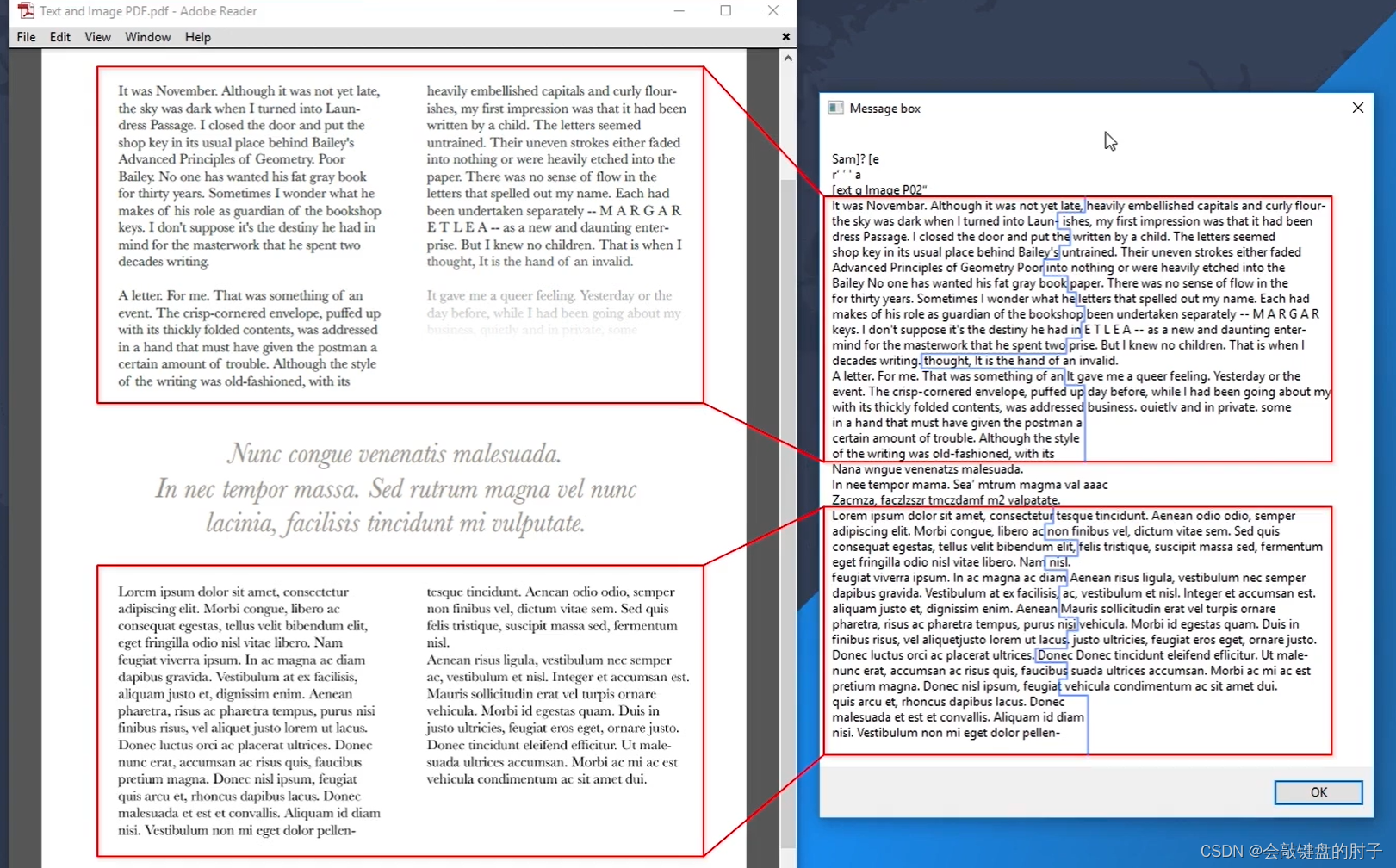
一般来说,对于 OCR 技术,值得注意的一点是,它的质量会随着源图像的质量降低而迅速下降。正如您在本例中看到的,最终结果在很大程度上取决于字体大小、字体风格和图像分辨率,这些因素不一定始终在您的控制范围内。因此,只要有可能,就不要使用 OCR 读取 PDF操作。需要注意的是,这两种读取 PDF 的操作是独立的:它们不需要打开其他应用程序,因此可以在后台运行。今天您将看到的大多数其他 PDF 方法都不具备这种特性,因此,如果后台操作对您很重要。
⭐方法三:屏幕抓取工具
抓取大文本块和小文本块的另一种方法是使用方便的屏幕抓取工具。在主工具栏中可以访问这种工具,它实际上是一个交互式向导,会为您生成所需的操作。点击下图按钮,打开屏幕抓取工具,

只需指定需要抓取的文本元素,UiPath 就会显示这个预览窗口,并提供一些选项。如果这是您第一次遇到,下面会说明它的工作原理:这是一个预览区域,显示在您刚才的选择中识别的文本元素。这是当前使用的抓取方法,如果单击此处的下拉列表,可以看到其他可用方法。而这个按钮用于在屏幕上指定另一个要抓取的元素。通常 UiPath 会检测出适合您的情况的最佳方法。
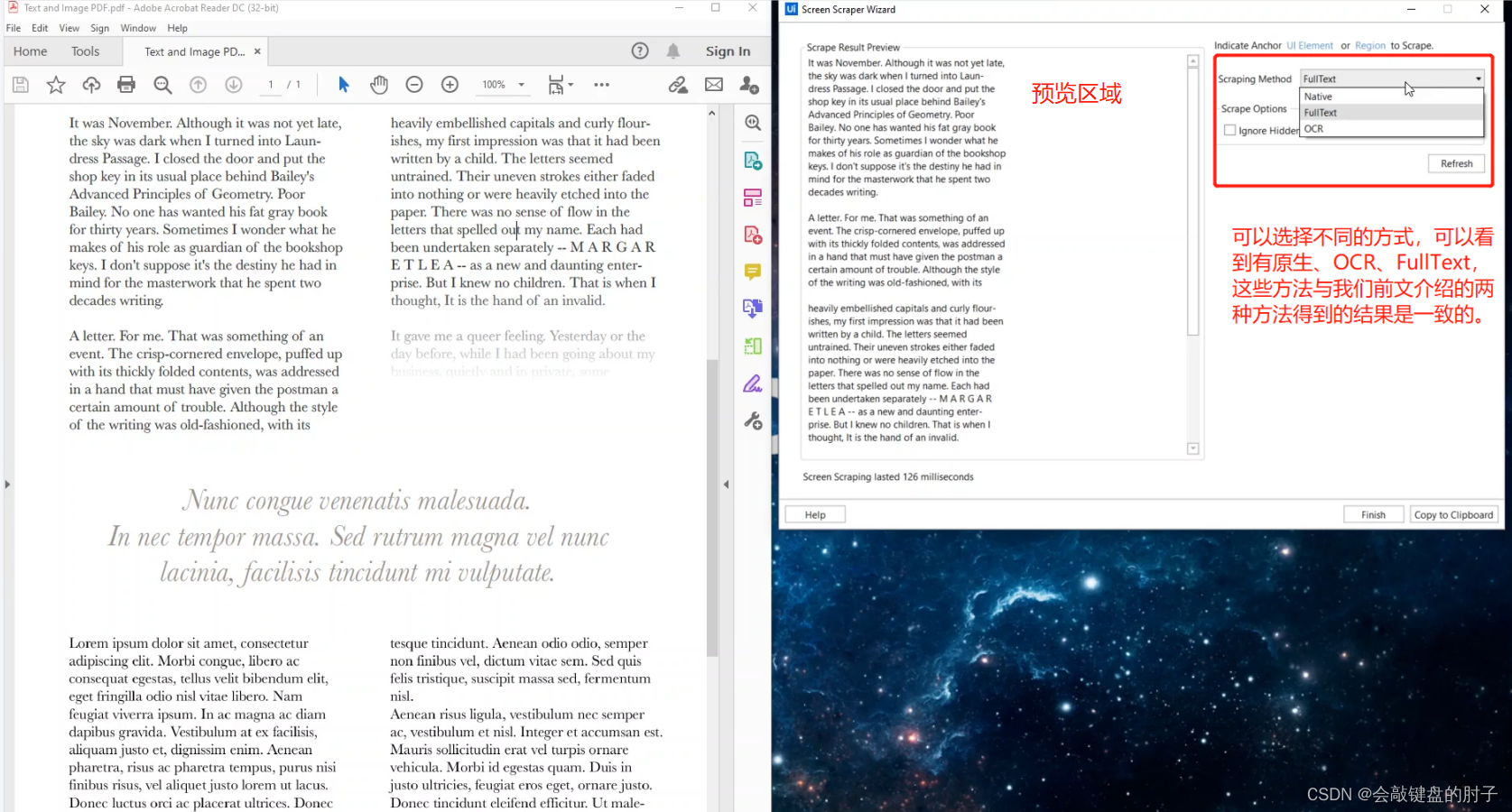
当我们通过在右侧的下拉菜单中选择抓取方法名称,并单击刷新来更改它时,预览会相应地更新。我们将使用默认的全文方法,并单击完成。在 UiPath 中,将新创建的序列连接到起始节点,并查看其内部。
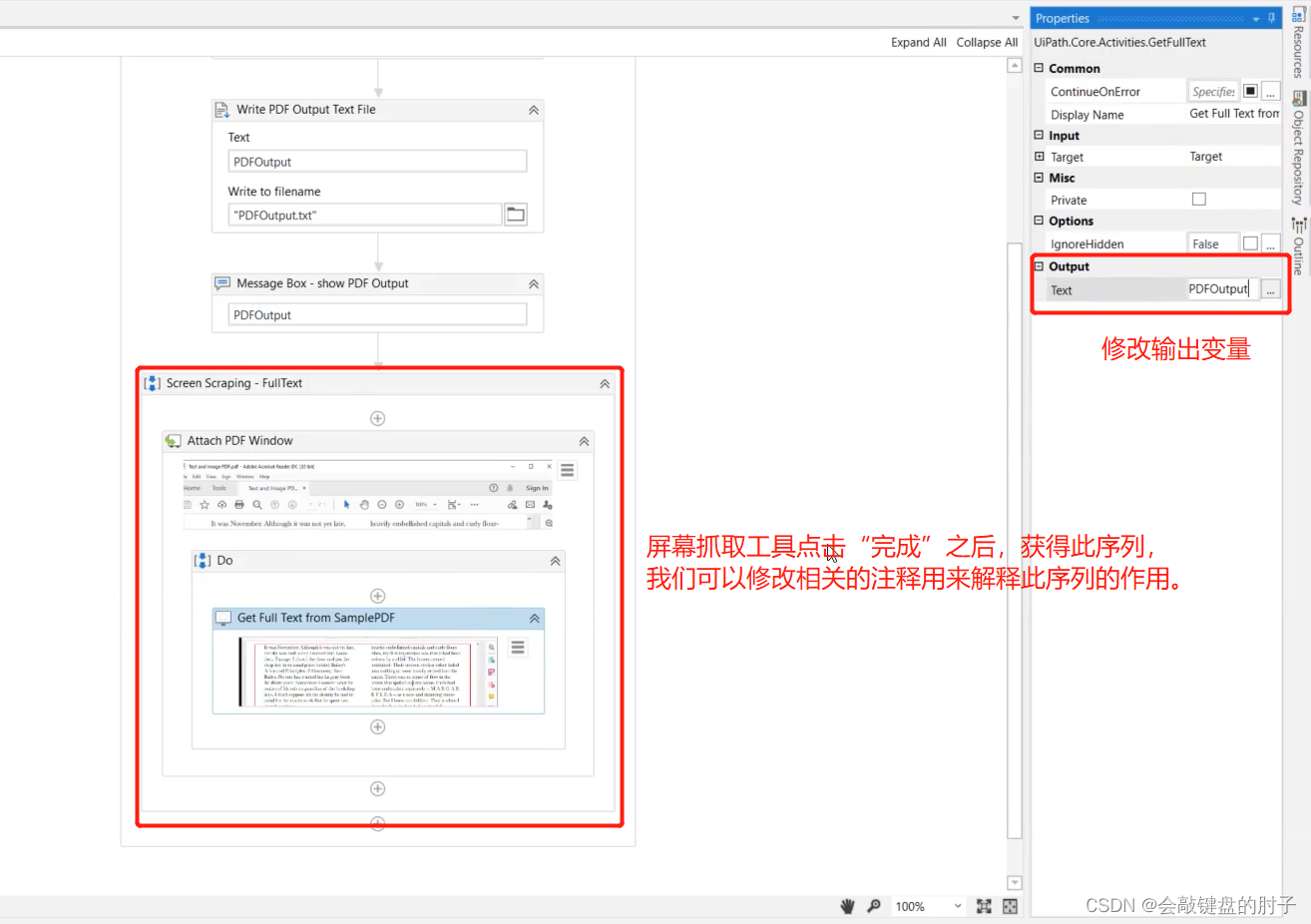
如果在上一步中,我们选择了一种不同的抓取方法,比如 OCR,我们就会得到这些操作。
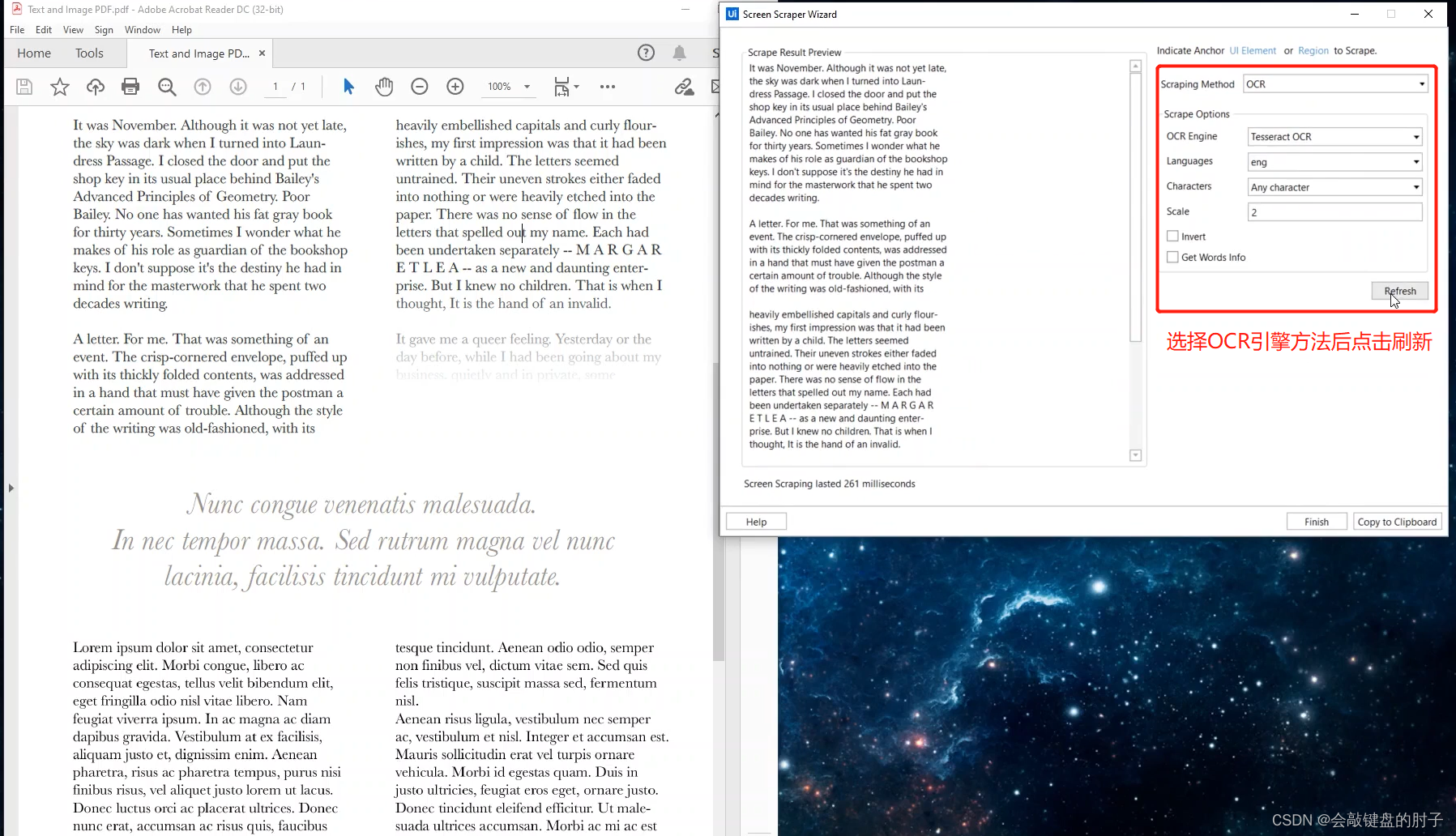
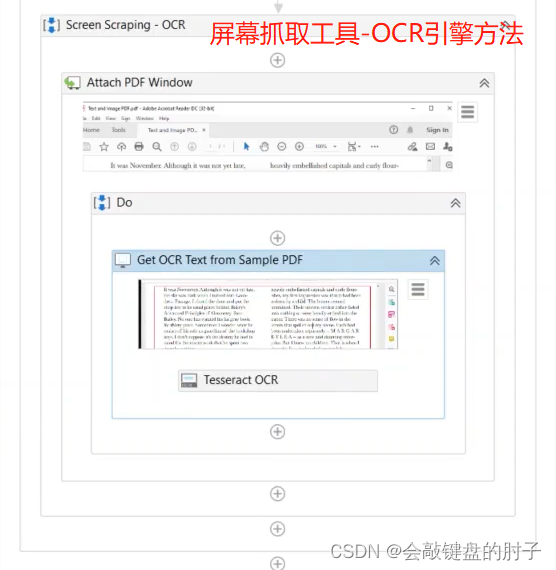
在本例中,这三种方法都有很好的效果,就像我们之前看到的:只有 OCR 方法可以读取图像和文本。
因此,这 3 种技术可以用来提取更大的文本段。现在,我们回顾一下!我们分析了从 PDF 文件中提取文本的方法,并使用了三种不同的方法进行该操作。
♋ 从 PDF 提取单个数据段
⭐ 背景
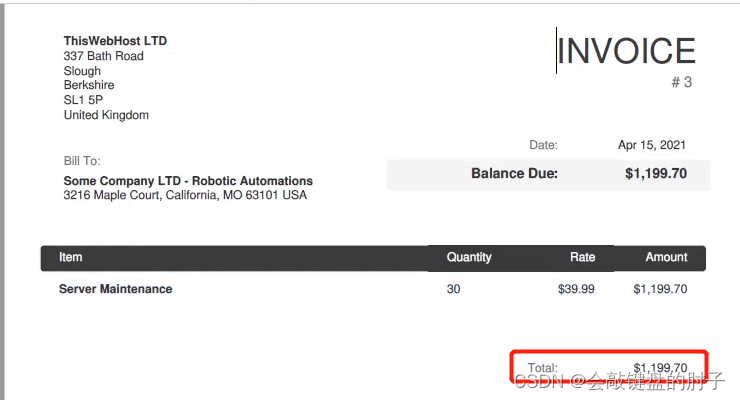
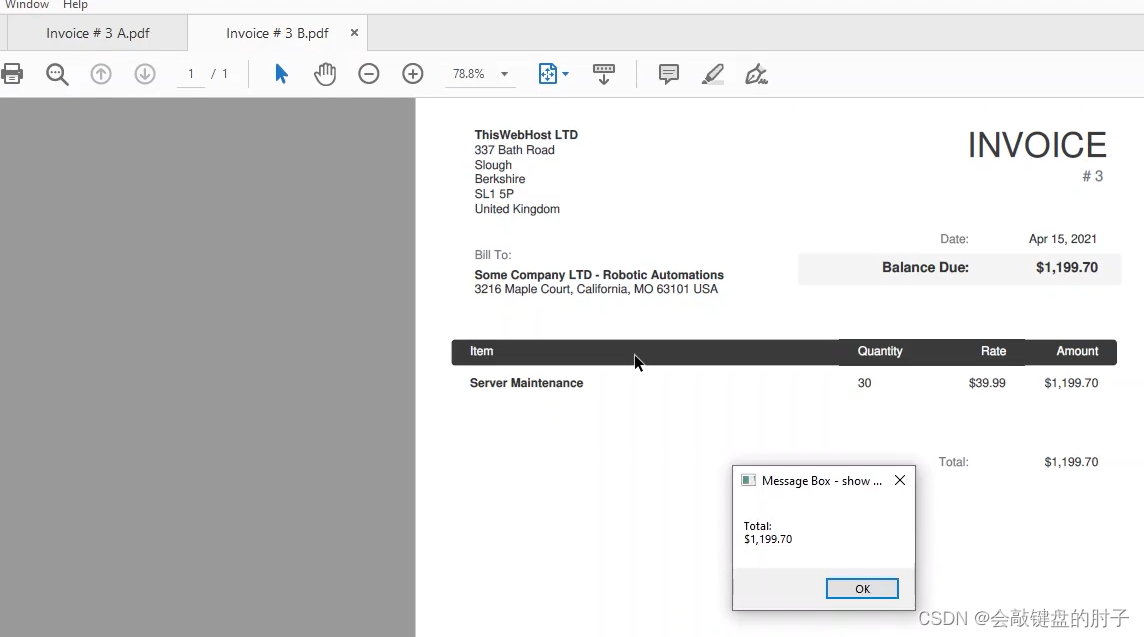
以一家中型公司为例,它面临着从一个月内生成的所有发票中提取特定数据的艰巨任务。PDF文件中所需的数据是信用额、到期余额和发票号。要手动提取此数据,将需要大量工时,但我们可以自动化此过程。让我们看看PDF自动化后,从PDF文件中提取特定数据是多么容易。
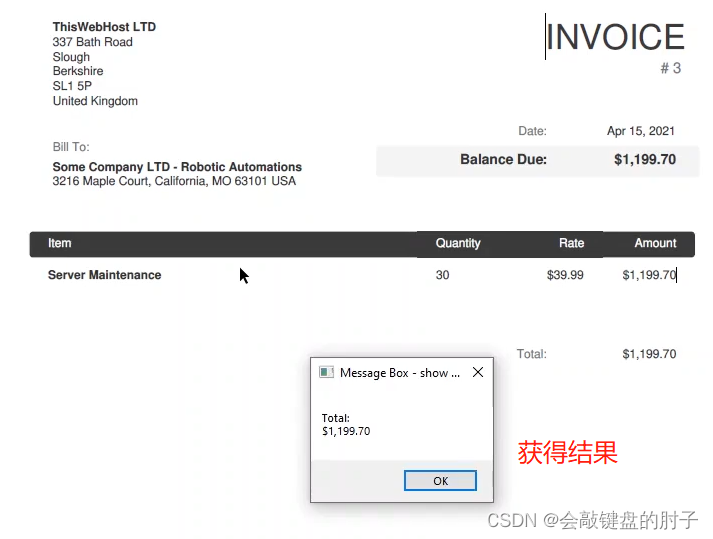
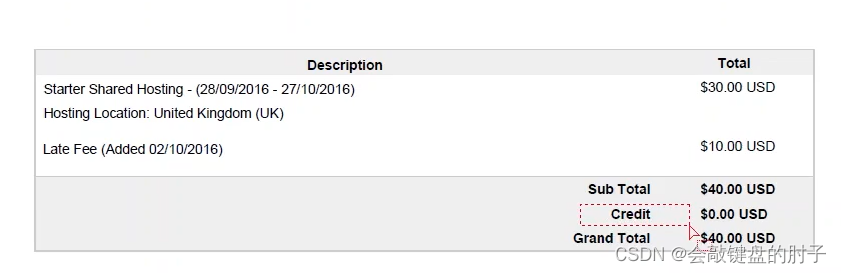
发票如下图,我们要获取总额。
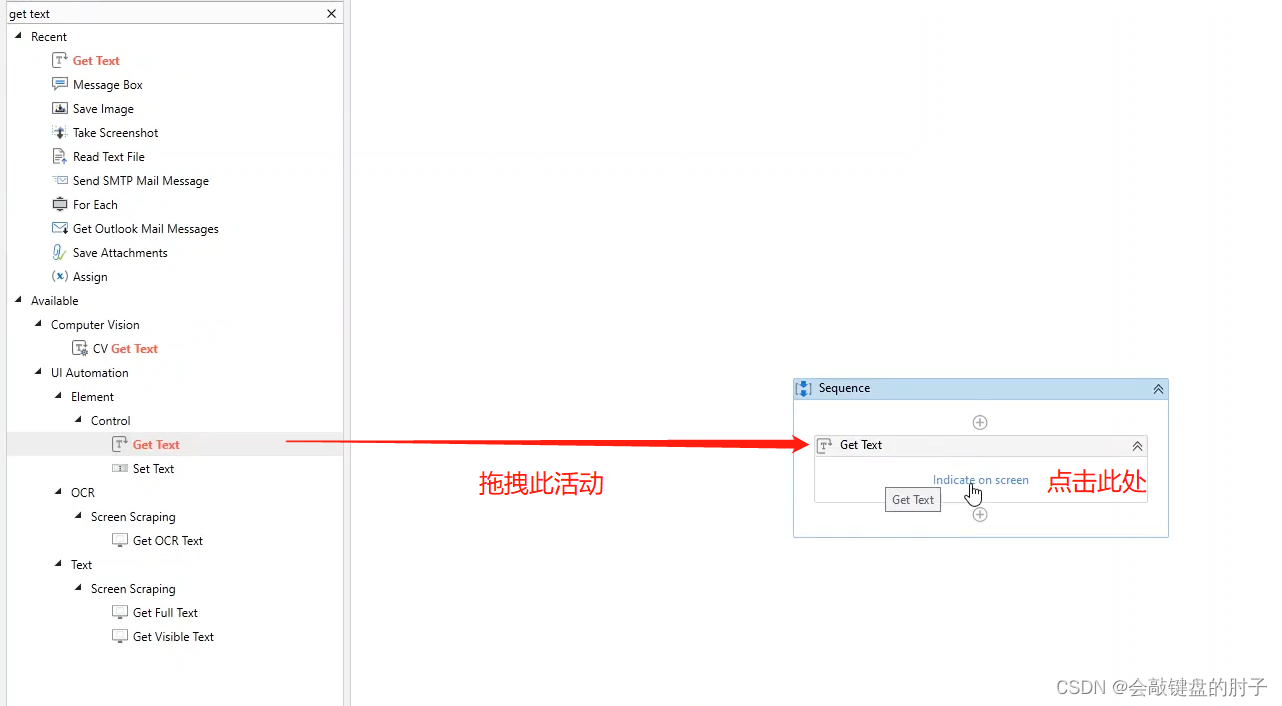
⭐ 获取文本活动——Get Text Activity
对于普通 PDF 来说,有几个获取数据的选项,第一个是众所周知的获取文本操作。现在,此操作将只从这一特定文件中获取该特定文本元素的值。如下图,
Step1
Step2
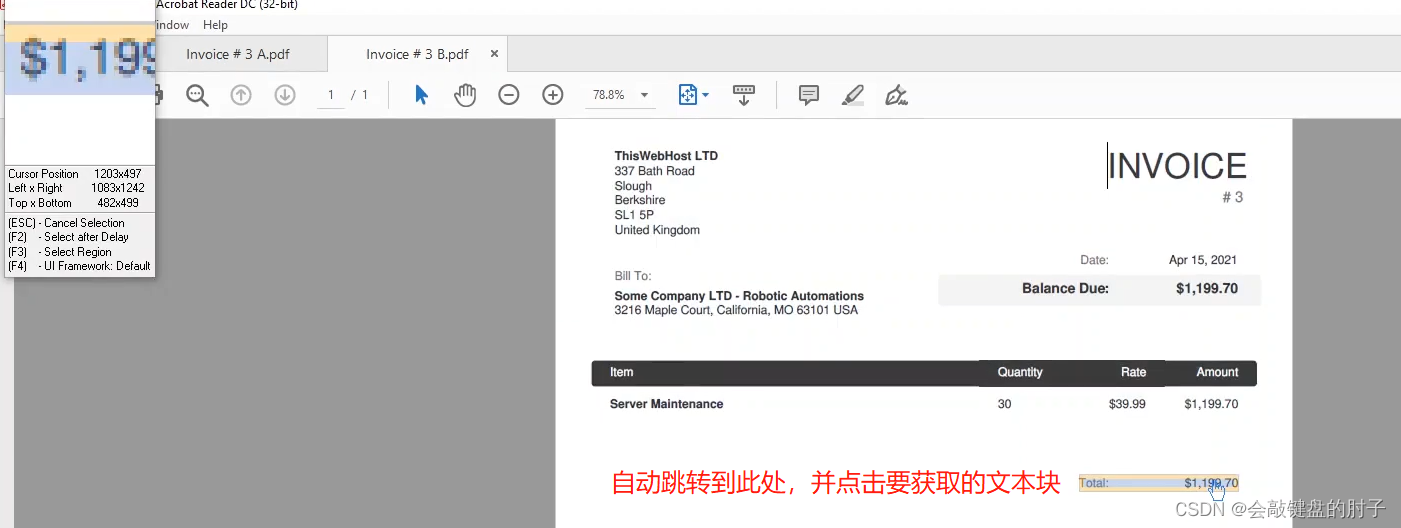
Step3
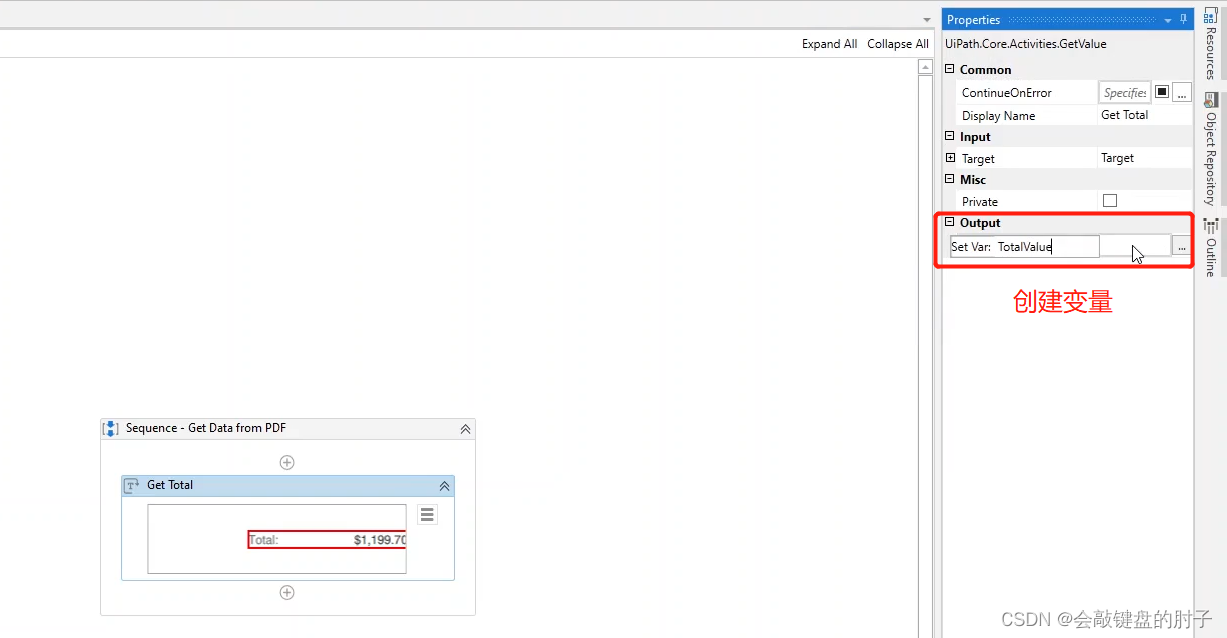
Step4

结果
⭐ 录制器
获取文本也可以在录制器中访问,就在这里。只需指向您感兴趣的元素,UiPath 就会为您生成获取文本操作及其输出变量,无需其他操作,我们将在消息框中显示它。
Step1
Step2
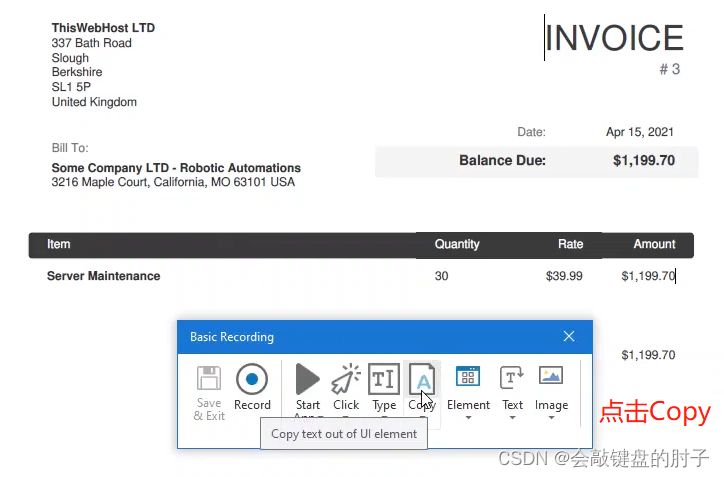
Step3
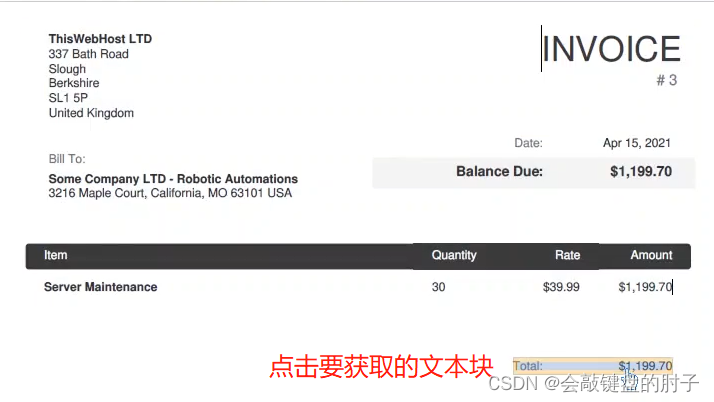
Step4
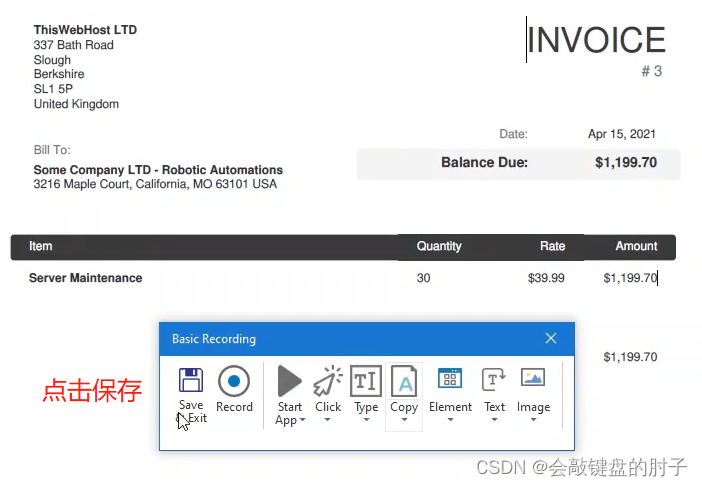
Step5
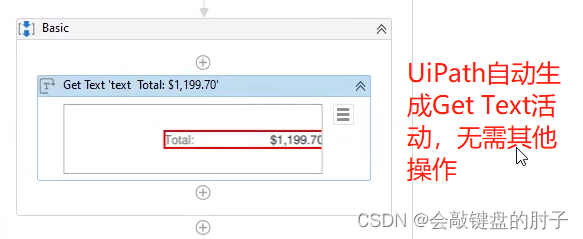
录制器获得的结果与Get Text 活动一致,再此不过多赘述。
⭐ 从多个文件中获取
但是,假设您实际上想要从一系列类似的 PDF 发票中提取总值,而不是仅仅从一个文件中提取,应该怎么办?像大多数用户界面交互一样,获取文本操作使用选取器来识别正确的元素并获取其值。因此,正如您可能已经猜到的,我们需要对其进行一些调整,以扩展其作用域。
自动执行此操作的方法是使用修复功能。因为我们关闭了第一个 PDF 文件,所以选取器编辑器以红色显示验证,这意味着选取器无效,如下图。
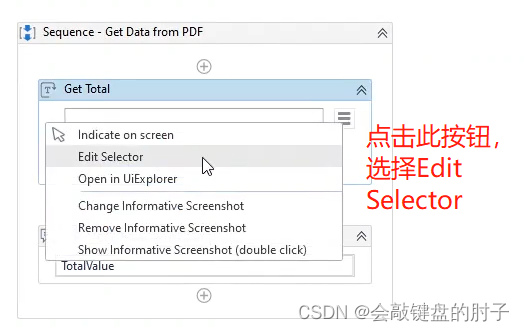
出现如下界面,
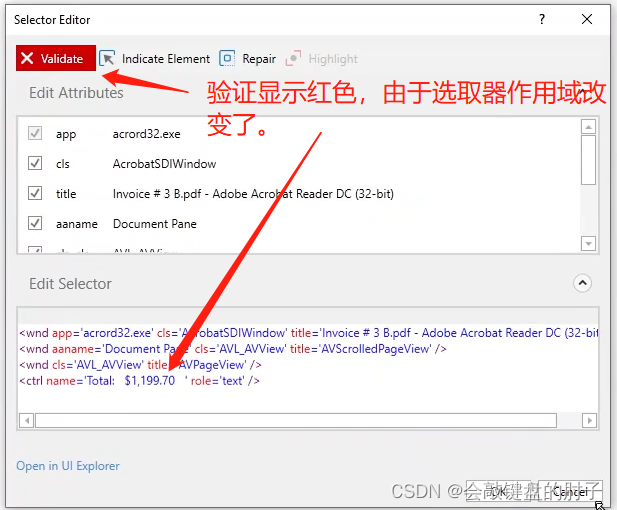
但是,我们可以直接单击修复并指向另一个类似的元素,该元素也应该与当前选取器匹配,并且 UiPath 将尝试为您修复选取器,如下图。
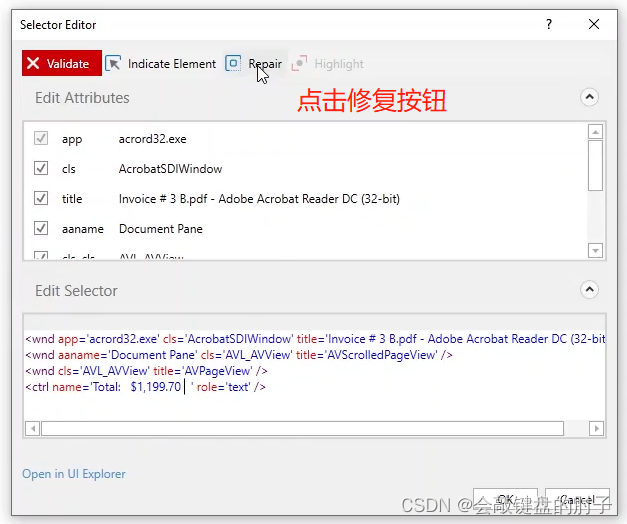

在本例中,它是有效的,但由于情况并非总是如此,我们还可以手动修改它,看看具体结果如何。但是,这里要提醒一下:我们将不会讨论选取器的一般方面,而只是解释这个具体的示例。但我强烈建议您观看“选取器”视频,里面详细介绍了它们如何工作,如何编辑和调试它们。它们是用户界面自动化的核心部分,因而更好地理解它们会在其他情况下也有用。
因此,我们将取消这个操作,不保存更改,然后再次打开选取器。这一次两个 PDF 文件都打开了,并且初始的选取器是有效的。我们将选择在用户界面探测器中打开它,以便获得更好的视图,如下图。

选中的容器是实际组成选取器的容器,因此,我们将重点讨论这些容器。
重新选择文本,
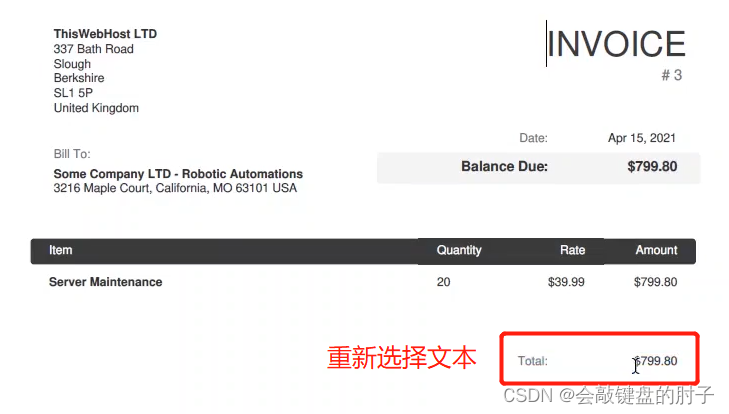
此时用户界面探测器改变,如下图,
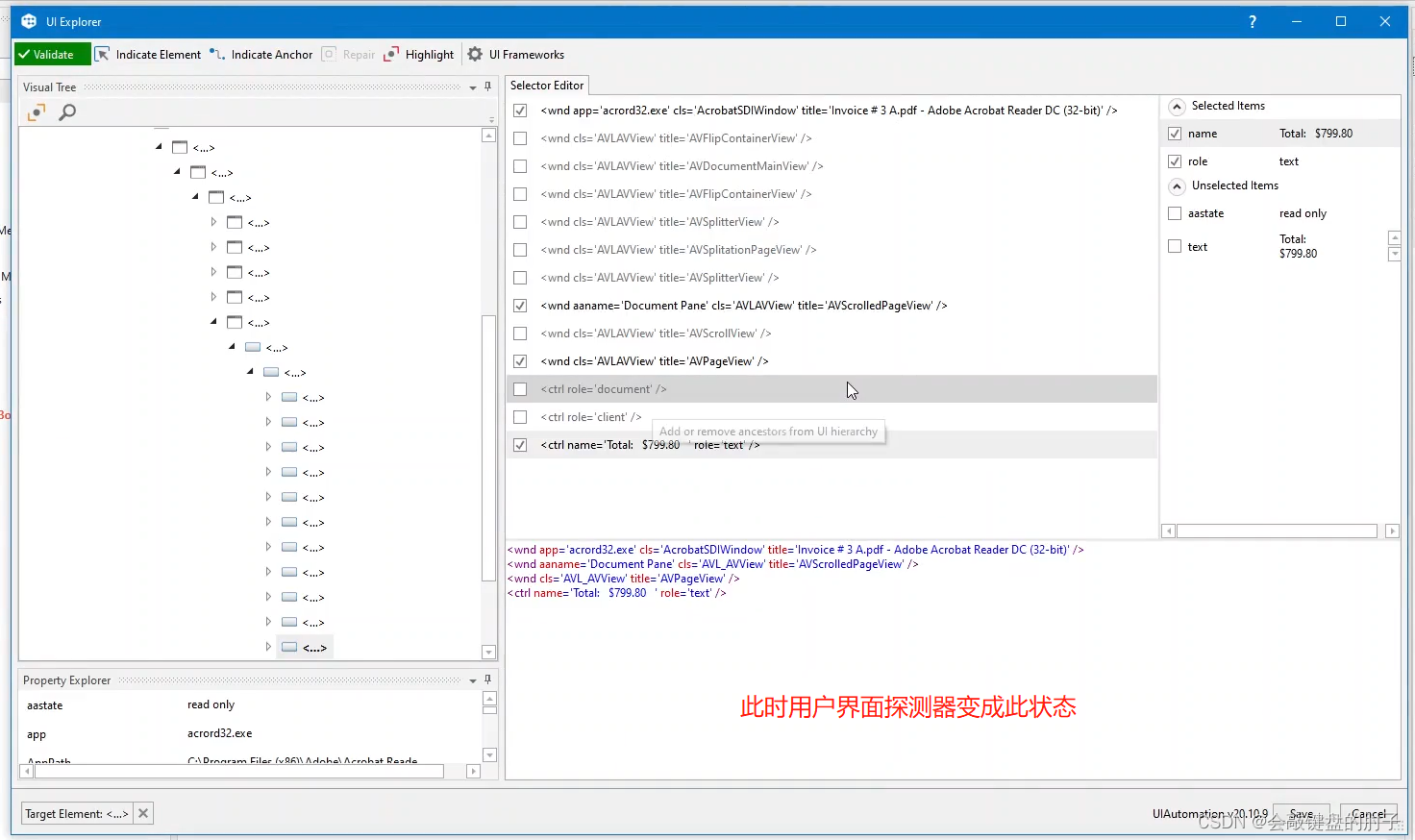
我们还将删除 Title 参数以使用其他文件,方法是单击 Explorer 中的顶层选取器并取消选中右侧的标题,如下图。
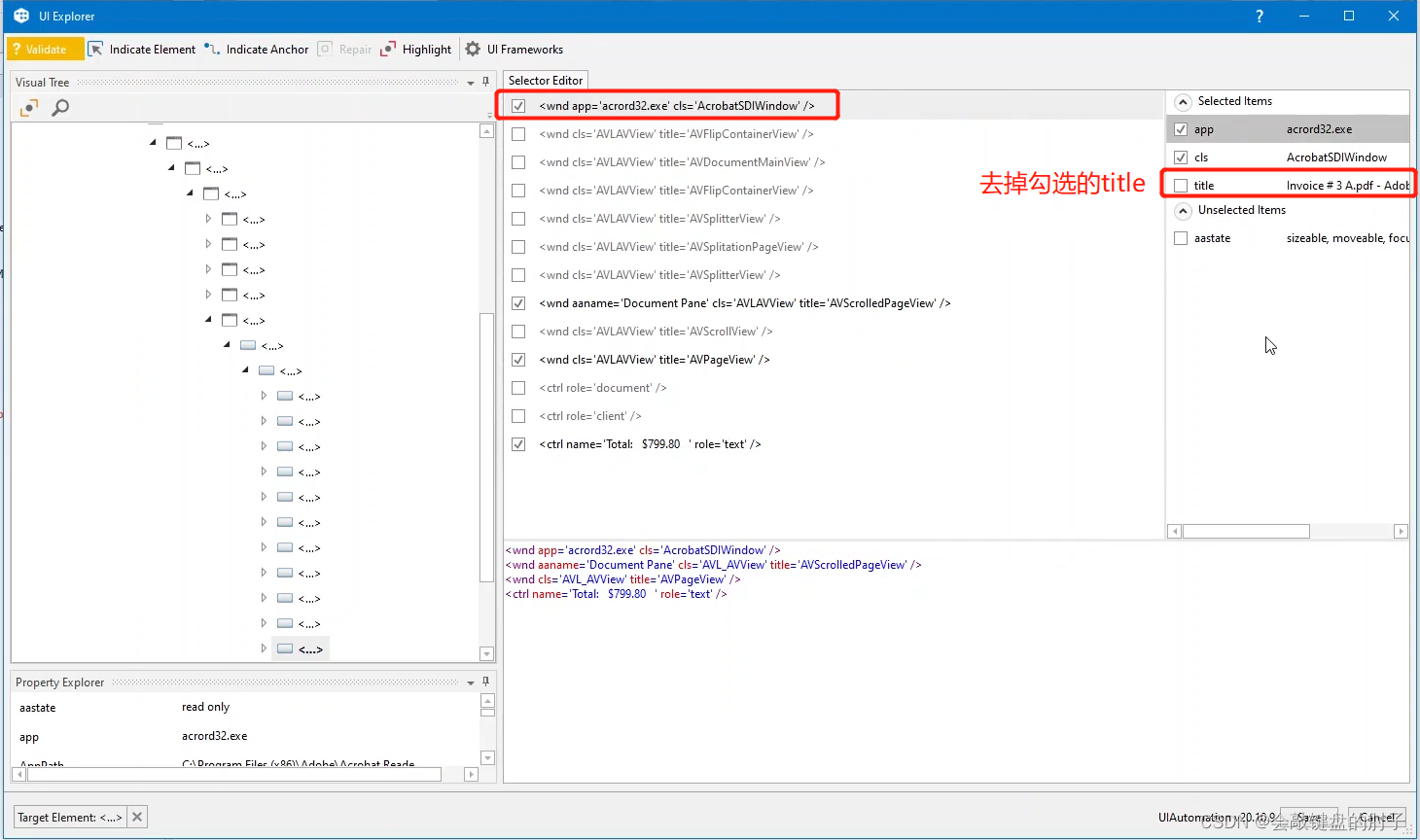
最后一个元素存在实际值,所以我们需要删除它,使它也适用于其他值,如下图。
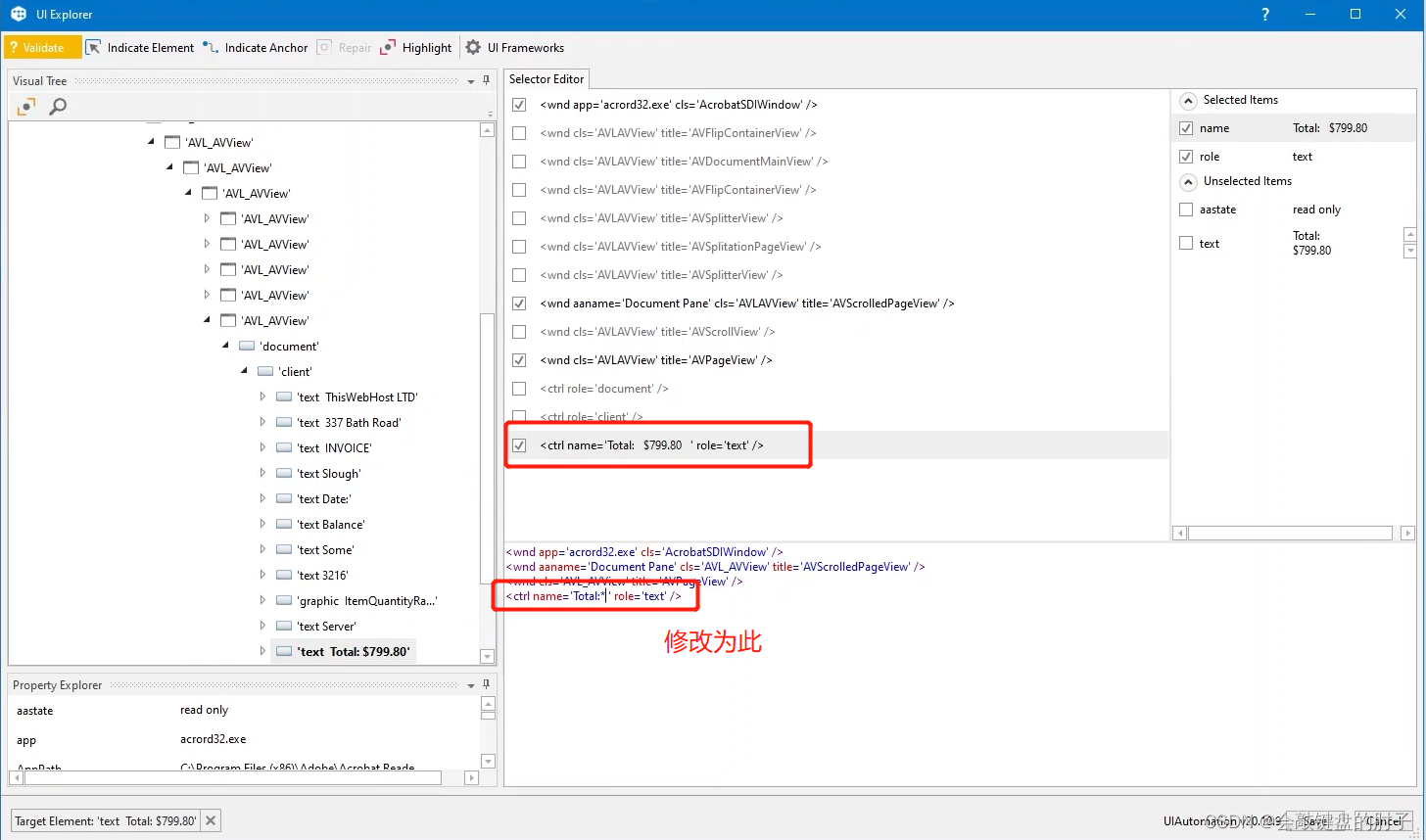
通过反复试验,我们发现最好对此项使用更独特的行名称属性。然后,我们只需单击保存,通过单击验证来验证选择器,然后单击确定。现在,它对这两个文件都有效。它从这张发票和另一张发票中都提取到了正确的值。
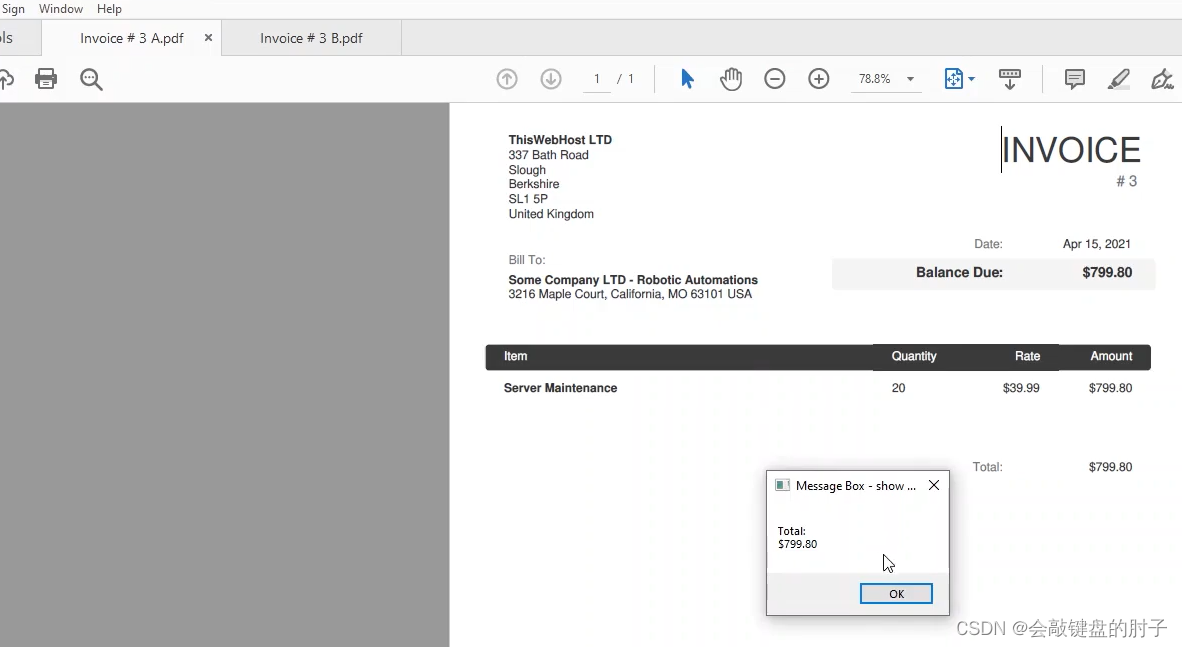
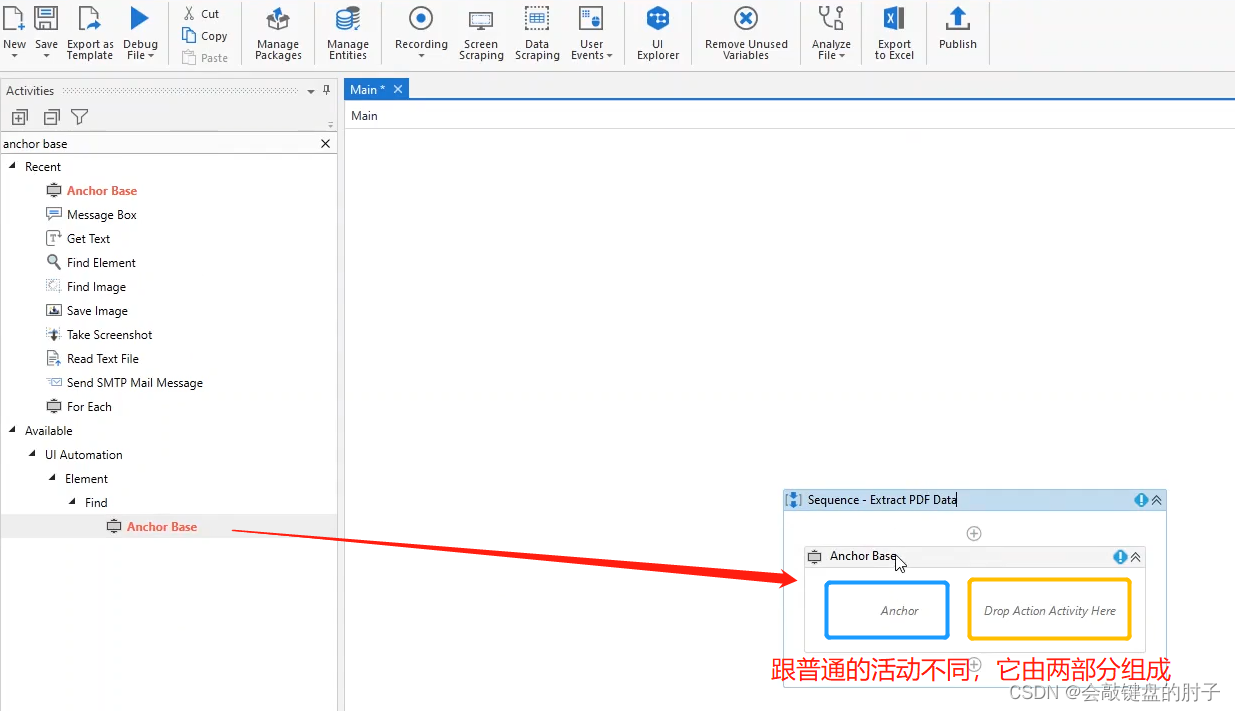
♌ 锚点基准活动
⭐ 背景
我们可能希望从PDF发票中获取值。但是这个值UI元素具有不稳定的选择器,而标签元素是稳定的。也就是说,我们要获取的文本的位置是不固定的,我们需要找一处固定的元素(锚点),以此来获得我们需要的文本内容。
⭐ 锚点基准活动
锚点基准活动由两个操作组成,因为它执行的操作与另一个固定元素或锚点有关,如下图。
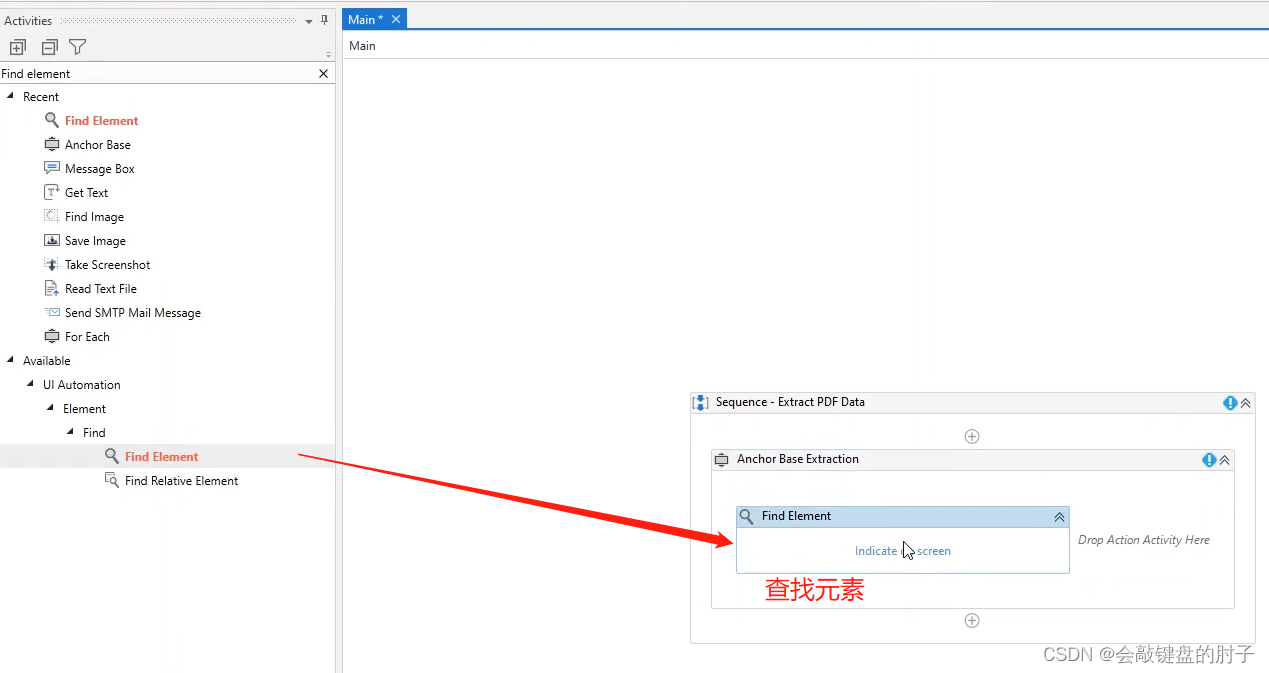
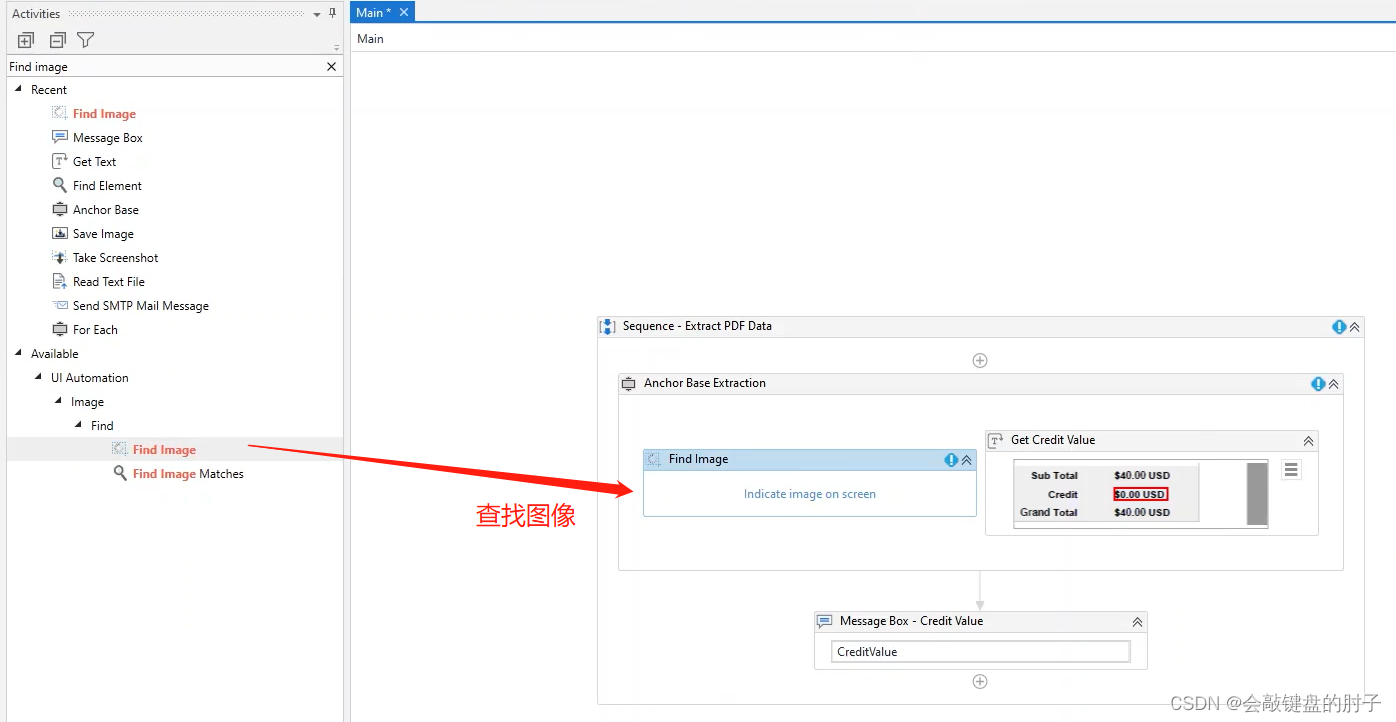
典型的锚点是查找元素操作。我们将使用它来精确定位一个固定元素,接近我们的目标元素;通常是它的名称,这里的 Credit。
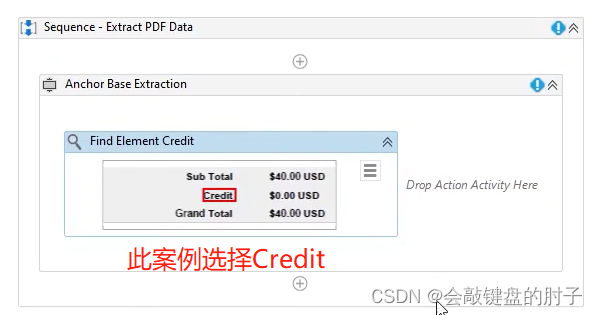
接下来,我们要执行的操作是获取文本。
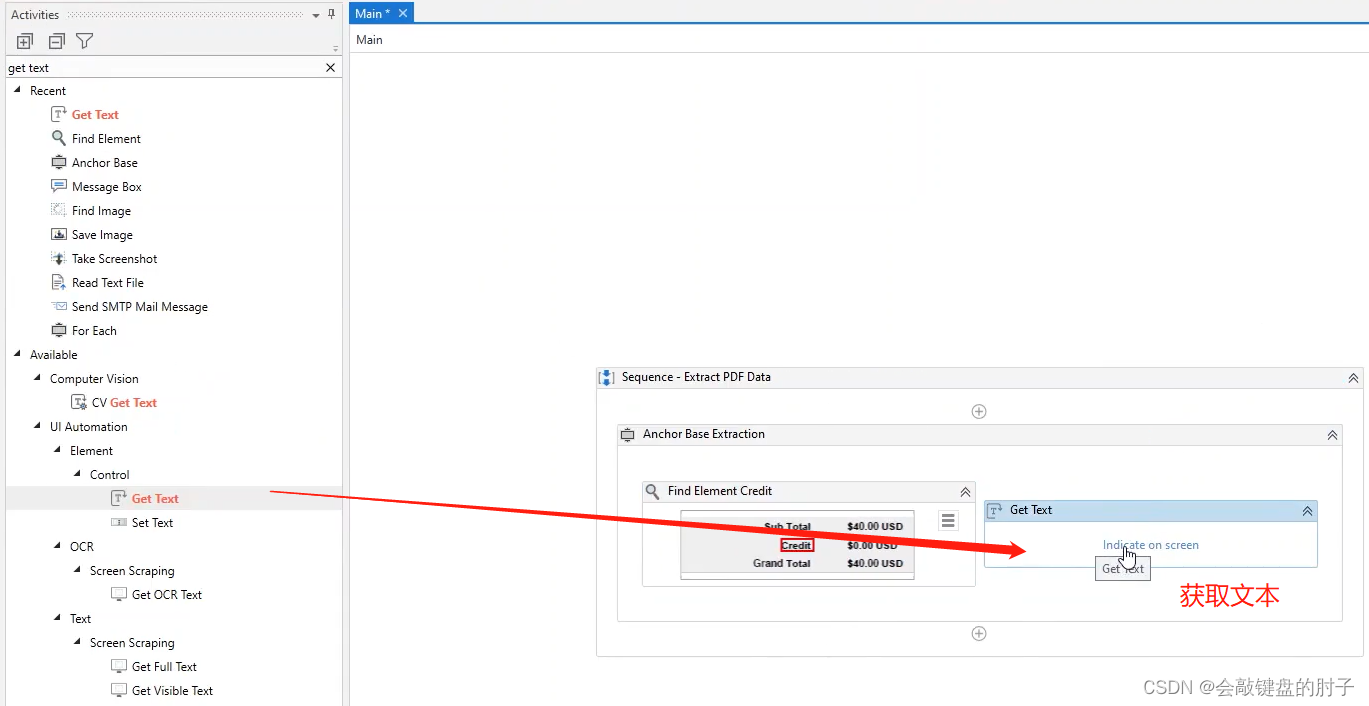
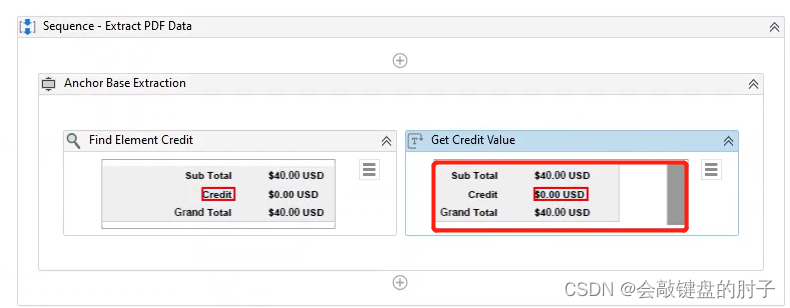
虽然这两个操作都有关联的选取器,但您会注意到它们更简单一些。
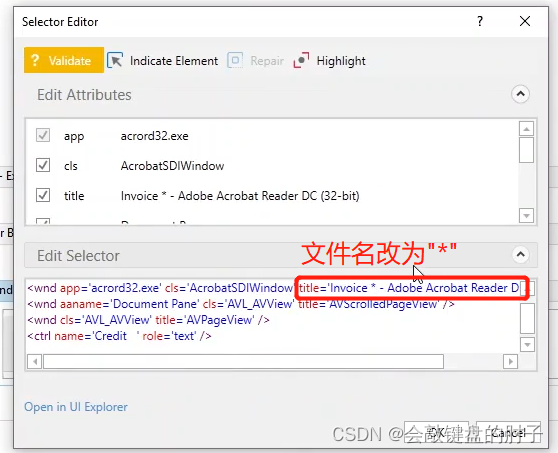
接下来对于锚点元素,用*替换文件名部分,如下图。
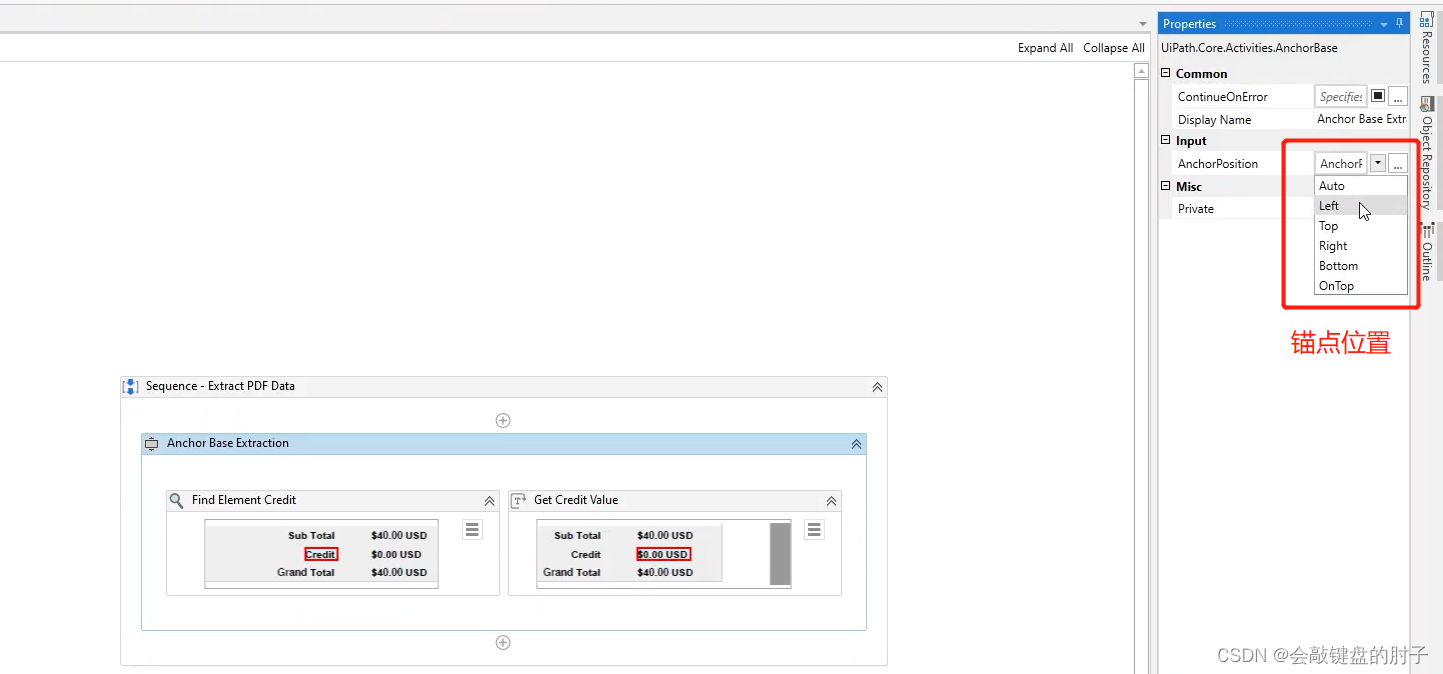
锚点基准还有一个可选参数,锚点位置。它用于更清楚地定义在何处查找数据。我们可以让它保持原样,或者把它改成左侧,因为这就是我们的锚点与文本关联的位置。
我们放上MessageBox活动之后运行,可以看到准备获取到了我们需要的值,并且两个文档都有效。
锚点基准活动非常灵活,这意味着您可以在其中使用各种操作。例如,可以将查找元素操作替换为查找图像,如下图。
优点是现在 PDF 文档的结构不再那么重要,重要的是它在可见文档的任何地方都包含特定指定图像。此外,您不必再处理这么多的选择器;而且由于 PDF 文件在所有系统上看起来都一样,因此可以使用查找图像而不存在其常见的缺点。
注意
在指定要查找的图像之前,最好将文档的缩放比例设置为实际大小,以确保图像完整并且准确。只需进入“视图”、“缩放”和“实际大小”。
然后回到 UiPath,单击以指定一个图像,在本例中是 Credit,并在其周围选择锚点。这样就行了,如下图。
这个方法有时比其他方法更可靠,因为只要图像和数据存在并且彼此之间的关系相同,它甚至可以处理文档中的重大结构更改。特别是因为“查找图像”操作可以处理合理的比例变化量,还有其他一些原因,PDF 文档非常稳定。
注意
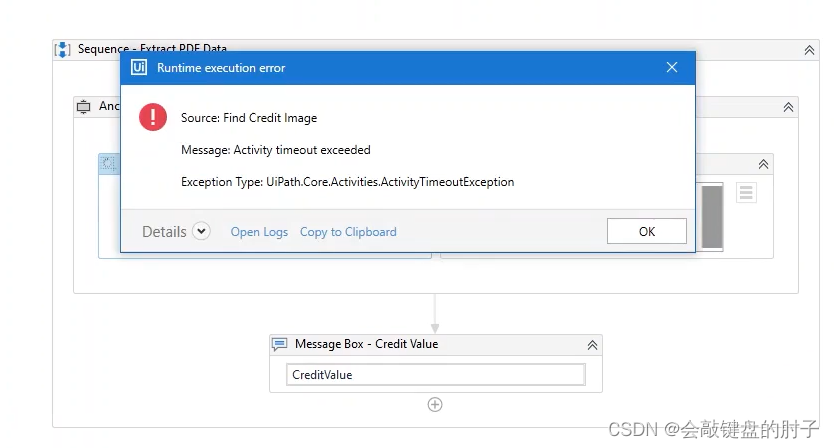
另外需要注意的重要一点是,介绍的最后这两种方法要求打开 PDF 文档,并且您尝试与之交互的数据必须可见,否则将失败。所以在构建最终的自动化系统时一定要考虑到这点,如下图。
⭐ Modern Design Experience activity
打开Modern Design Experience activity,如下图,
拖拽Use Application活动并点击
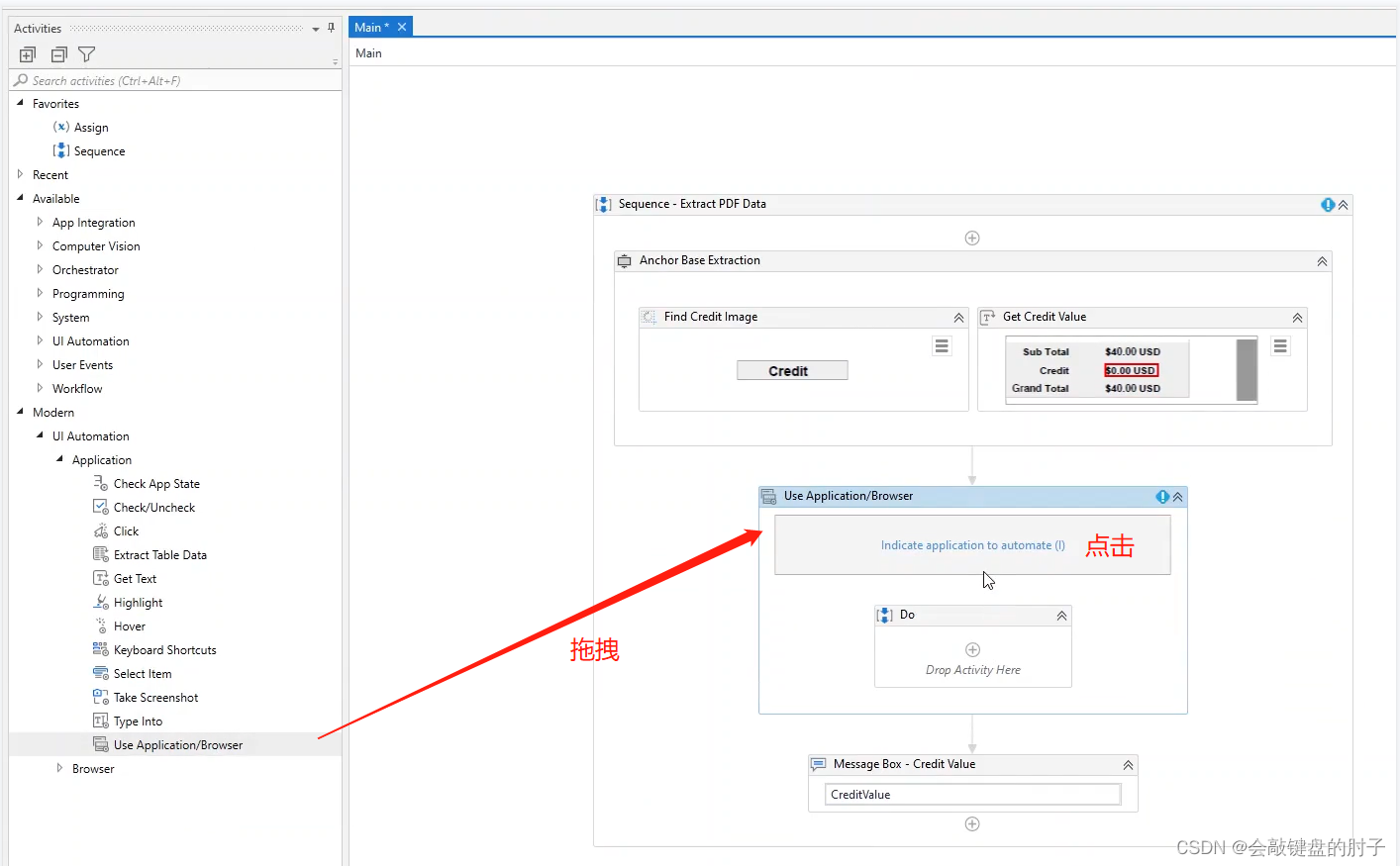
此时在要获取文本的PDF上点击,获取如下结果,
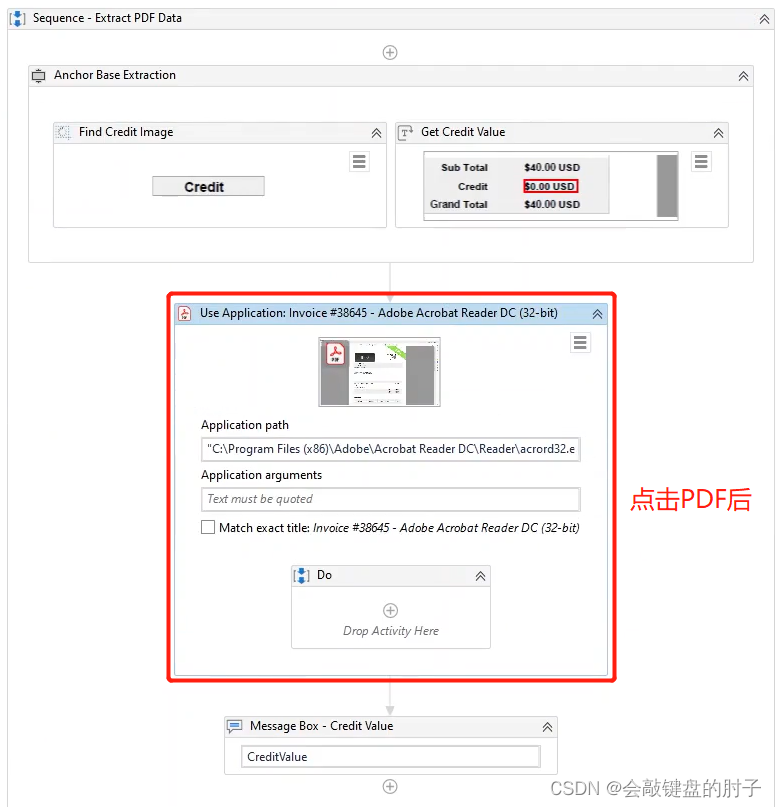
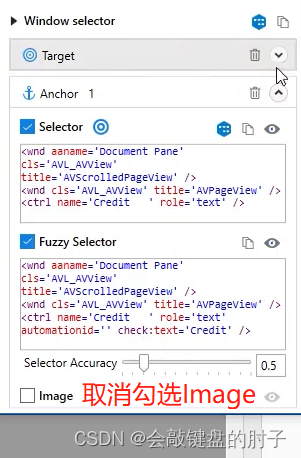
我们点击选择器,修改文件名为"*",如下图,

拖拽Get Text,
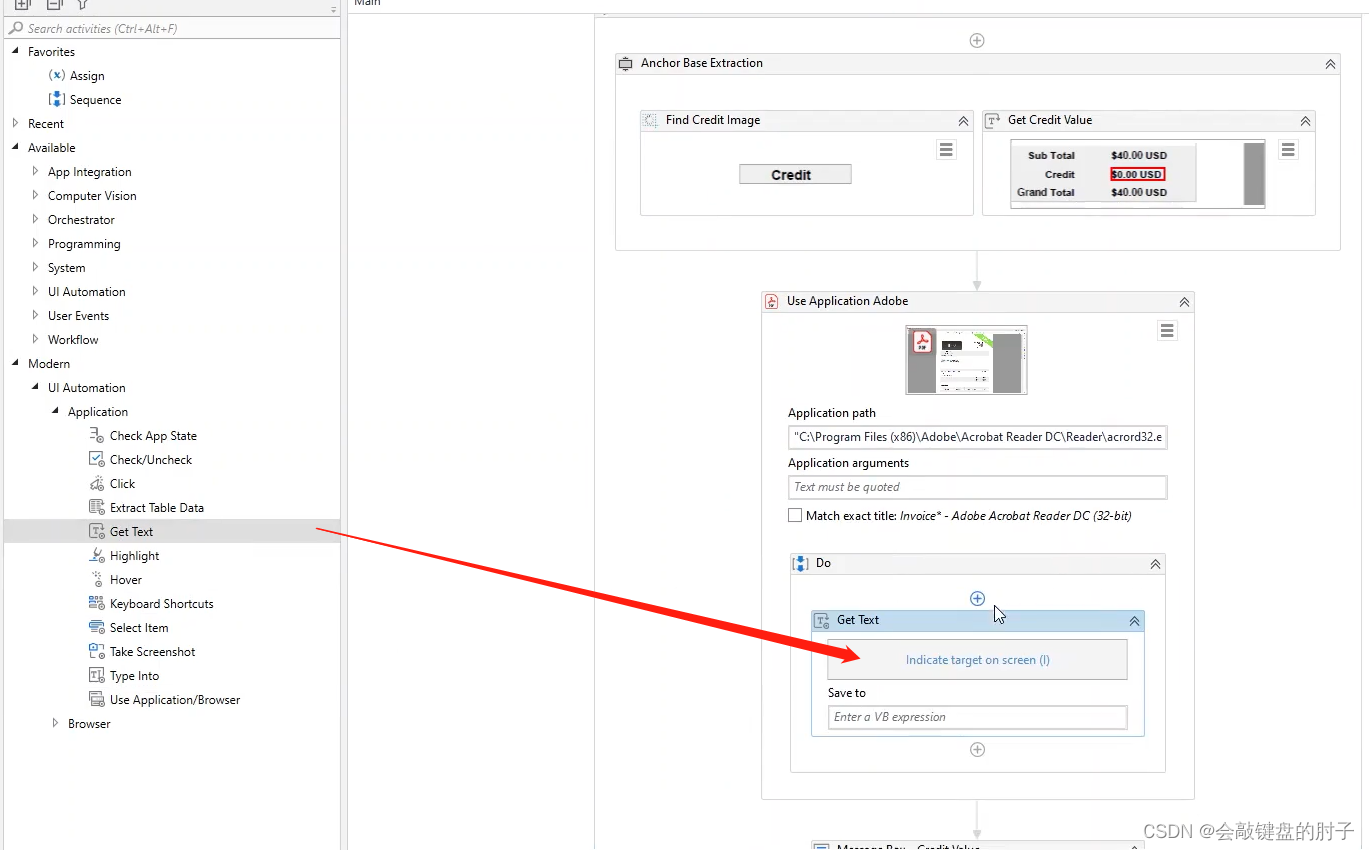
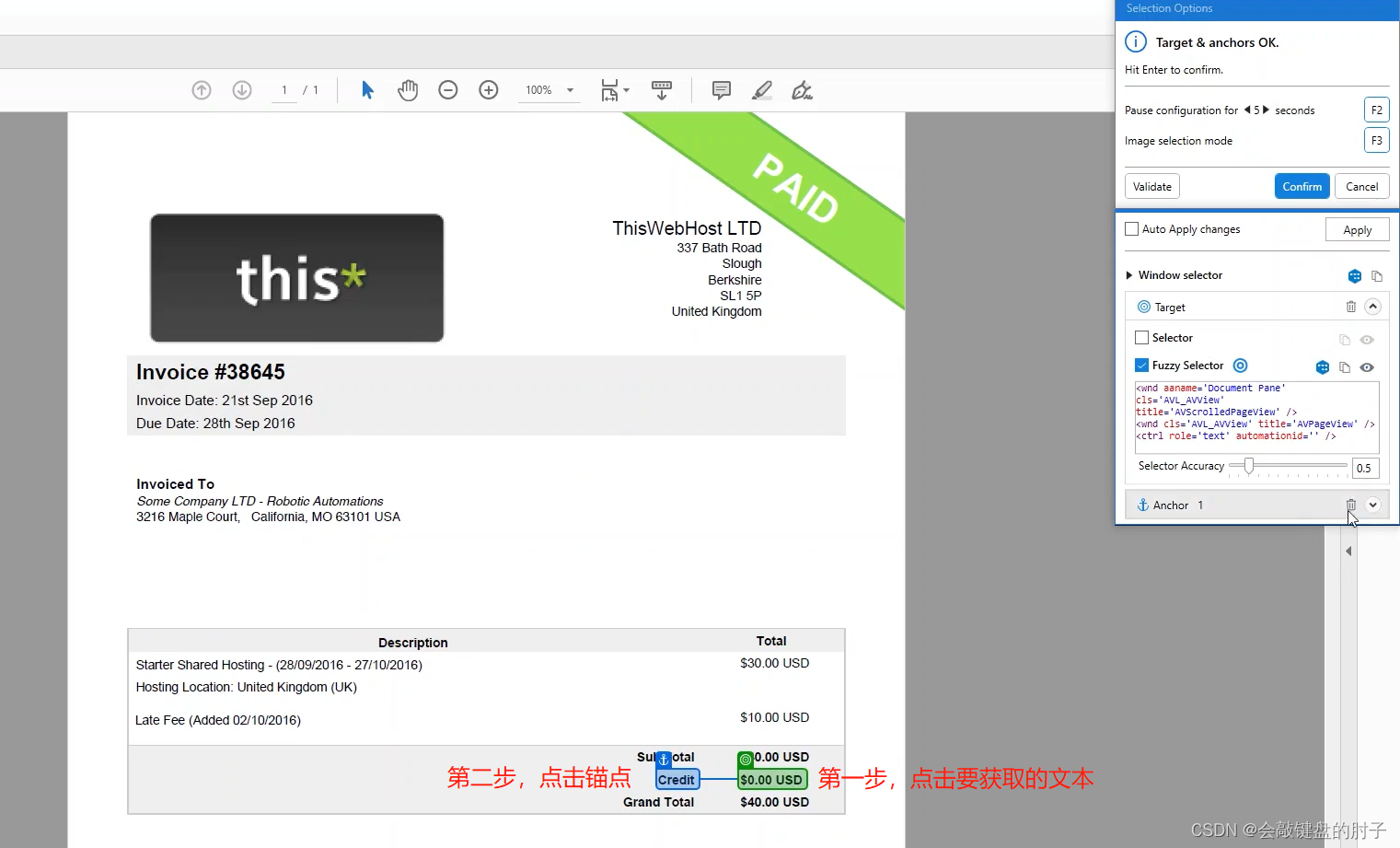
设置要获取的文本和锚点,
最后序列的效果,
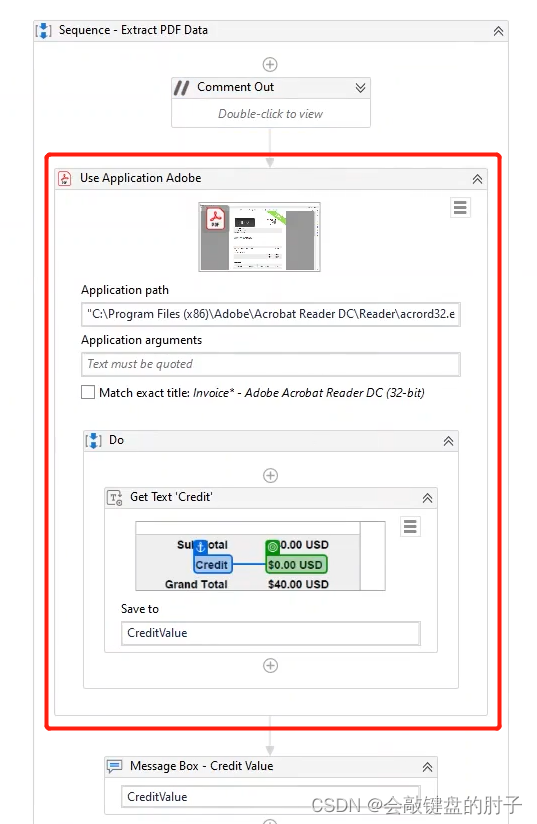
最后,我们运行序列,得到的结果与之前的一致。
4️⃣ 总结
关键点:
从PDF文件中的元素提取文本,我们可以使用Anchor Base activity或Get Text Activity。Anchor Base activity只支持在锚块中查找元素和查找图像。图像自动化不处理选择器,但其可靠性也要低得多。Modern activities 在其目标定位方法中集成了锚。5️⃣ 参考资料
PDF Activities Pack
Read PDF Text
Read PDF with OCR
Anchor Base
⭐写在结尾:
文章中出现的任何错误请大家批评指出,一定及时修改。
希望写在这里的小伙伴能给个三连支持!