
公司是做外贸的,所以需要爬取一些外国网站的商品竞品数据,但是在爬取某个网站的时候,遇到了五秒盾的阻拦。
说实话,一开始自己并不了解五秒盾,毕竟在之前爬国内网站的时候,并没有遇到过这种防护措施,但是在爬取这个外国邮件网站的时候,返回的文本中,总是有如下的信息:

一直让 “Just a moment...”,一开始自己以为是加载缓慢,但是每次都有,这就不得不引起警觉。
在vscode中显示了一下html代码,并在浏览器上看了一下界面,发现是这样的
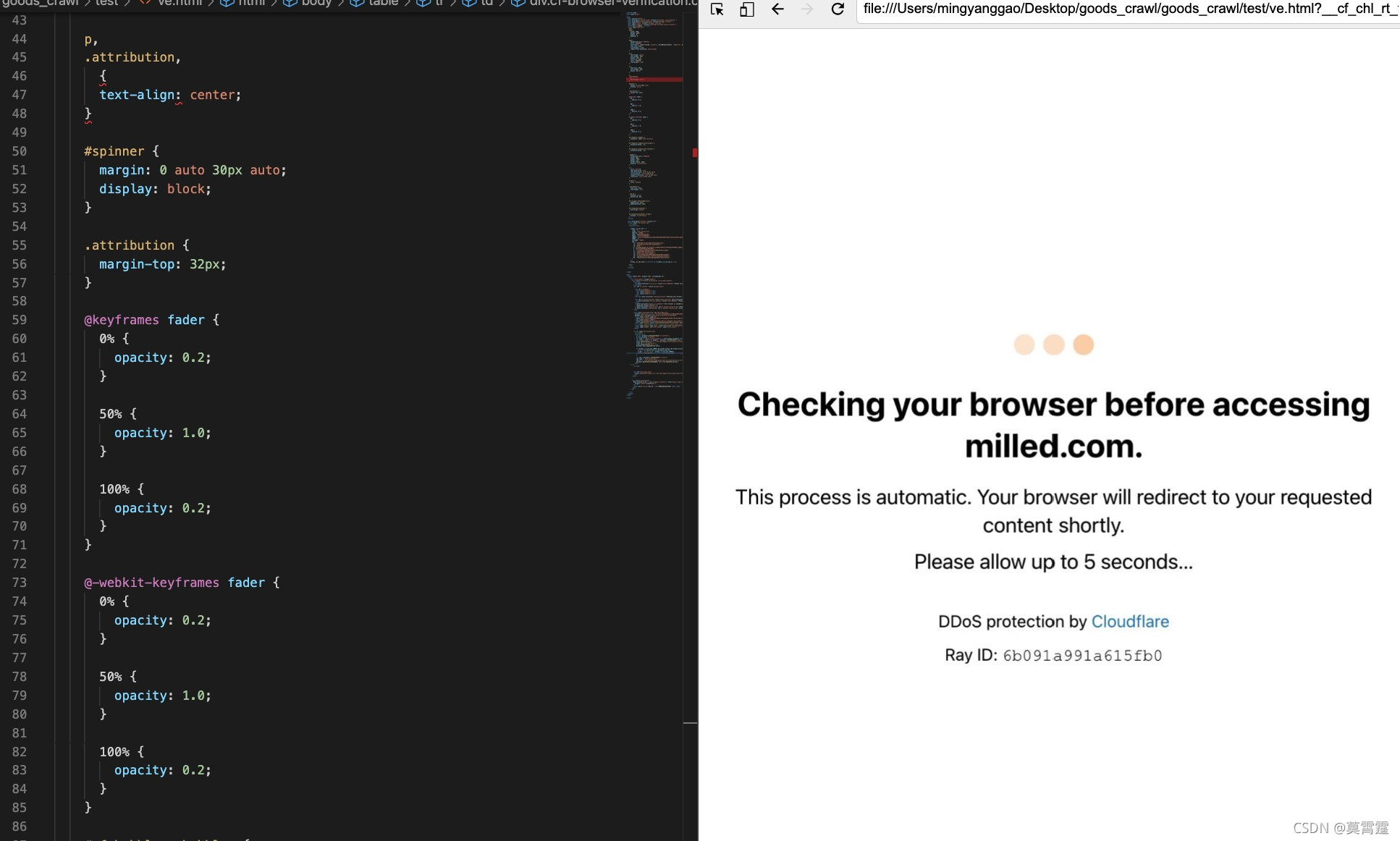
这个. "DDoS protection by Cloudflare" 是个啥子鬼?
但是看到DDoS protection by这种字样,感觉应该是防止DDoS攻击的,但是这个“Cloudflare”又是个啥?
在网上查询了一下,原来是所谓“五秒盾”的东东,而且网上有针对这小盾盾现成的python模块,也就是cloudscraper模块,使用requests和scrapy都可以.
网上针对requests使用cloudscraper的比较多,但是本人使用scrapy,所以参考AroayCloudScraper(https://githubmemory.com/repo/hwpchn/AroayCloudScraper)模块重新修改了一下,进行爬取的时候,毫不费力的就饶过了对方设置五秒盾的网站,简直不要太过完美!
事情原本到这步已经告一段落,毕竟其他的事情就是用scrapy的xpath获取数据就可以了,但是........
两周后,当领导要求再次爬取得这个网站的时候,我发现,原来的代码竟然不管用了!
原因是代码返回了这个错误:
![]() what? 要钱了?!
what? 要钱了?!
本着能白嫖绝不付费的原则,我找了一下该模块的git,但是上面显示并没有付费内容,而且提示了貌似一年才更新一次.....
但是这个模块还能否继续使用呢?我决定在google先查为妙,查询结果中,有一个是在scrapy中设置: 'COOKIES_ENABLED': True, 即可使用,但是我试了一下,并没有神马卵用......
事到如今,看来这种方法应该是行不通了,还有其他办法,当然有!
首先想到的就是用selenium+chrome模拟浏览器去将数据采集下来,这种方法虽然有些繁琐,且一直为高级爬虫工程师所不齿,但是我大中华某位伟人曾经说过:“不管黑猫白猫,只要抓住耗子的就是好cat”。
说干就干!
立马在电脑上开始安装selenium,chromedriver,至于chrome,因为公司配的都是苹果电脑(不要问为啥,就是这么豪横!),但是我的是M1芯片的,所以要使用ARM架构的chrome。
安装步骤,以及对应版本的chromedriver就不展示了,总之万事皆备,只欠代码了!
忙不迭的将原来写过测试某宝的代码贴上测试一波,其中覆盖window.navitor.webdirver的值都已经妥妥的安排明白了,但是,竟然不行!

打开的浏览器界面,依然停留在五秒盾,我与对面的数据依旧还有一盾之隔!
怎么办?!怎么办?!领导限定的日期已经到了,再不出数据,就要被用键盘打死了😭 😭 😭
但是越是到这个时候,越不能慌张,毕竟写bug咱在行,找解决方法尤甚啊!
于是乎,我开启了疯狂搜索模式,功夫不负有心人,众里寻她千百度,方法就在隔壁拐角处!
我找到了一个webdirver的驱动模块,但是并不是selenium,而是undetected_chromedriver(GitHub - ultrafunkamsterdam/undetected-chromedriver: Custom Selenium Chromedriver | Zero-Config | Passes ALL bot mitigation systems (like Distil / Imperva/ Datadadome / CloudFlare IUAM))
这个模块可以完美的模拟chrome浏览器,并且不用设置js默认值,也就是无需自己再添加瞒天过海的设置,只要简单的几行代码就可以。

测试了一下,报错,说是我chrome的版本不匹配,而且undetected_chromedriver只支持chrome96及以上的版本!但是我的mac下载的就是最新的ARM架构的chrome,最多就是95。
为山九仞,可不能功亏一篑,我急忙查看该模块的git说明,幸好,有解释:
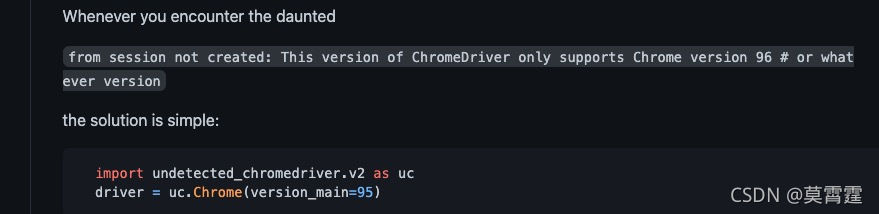
也就是说该模块支持自定义chrome版本!
可以可以,这个结果很让我满意,忙不迭的测试一波,原本的数据页面在等待了五秒验证之后,真的出现了!果然很好很强大!
但是在之前代码中,我使用递归函数的方式,但是需要每翻一页就要打开安装一次chrome,本着提(能)高(懒)效(即)率(懒)的方式,修改了下代码,换成了循环遍历的方式:

好了,本次使用python+undetected_chromedriver+chrome绕过五秒盾的方法分享就到这,下次再见!😜 😜 😜