初识Python之零基础教程(上)_盼小辉丶的博客
初识Python之零基础教程(上)
- 0. 学习目标
- 1. Python 程序的运行
- 1.1 Python 交互式解释器
- 1.2 Python 程序脚本
- 2. 变量与赋值
- 3. 数据
- 3.1 原子数据类型
- 3.2 结构数据类型
- 3.2.1 通用的序列运算
- 3.2.2 列表
- 3.2.3 字符串
- 3.2.4 元组
- 3.2.5 集合
- 3.2.6 字典
0. 学习目标
Python 是简洁、易学、面向对象的编程语言。它不仅拥有强大的原生数据类型,也提供了简单易用的控制语句。本节的主要目标是介绍 Python 基础知识,并为接下来的学习奠定基础,本文并非详尽的 Python 教程,但会完整的介绍学习数据结构和算法所需的 Python 基础知识及基本思想,并给出相应的实战示例及解释。
通过本节学习,应掌握以下内容:
- 掌握
python编程基础 - 掌握
Python的原生数据类型
1. Python 程序的运行
1.1 Python 交互式解释器
由于 Python 是一门解释型语言,因此对于简单示例只需要通过交互式会话就能进行学习。通过命令行启动 Python 后,可以看到 Python 解释器提示符为 >>>:

运行提供的 Python 语句将会返回相应结果。例如, 在命令提示符后使用 print 函数:
>>> print("Data Structures and Algorithms in Python")
>>> Data Structures and Algorithms in Python
1.2 Python 程序脚本
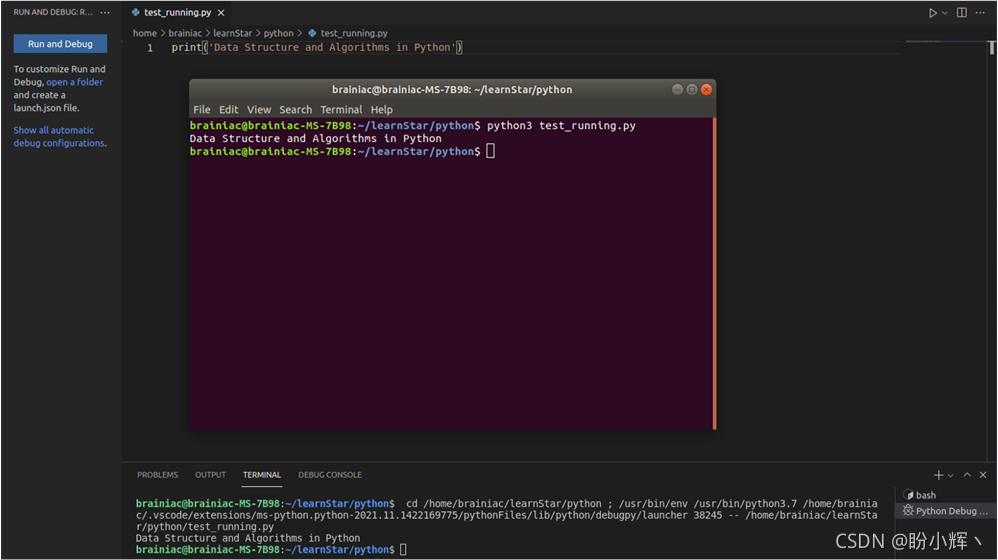
但是,我们不能所有程序都在 Python 交互式解释器中一行一行的执行,因此我们需要编写程序文件,例如在文件 test_running.py 文件中写入以下语句:
print("Data Structures and Algorithms in Python")
使用 python 命令执行该脚本文件:
python test_running.py
脚本的运行输出结果如下:
Data Structures and Algorithms in Python
除此之外,我们也可以通过诸如 PyChram 和 VSCode 等编辑器运行调试编写完成的 Python 程序。
2. 变量与赋值
变量的名字在编程语言中也称标识符,Python 中的标识符以字母或者下划线(_)开头,并且区分大小写( VAR 和 var 表示不同变量)。虽然并非必须,但是为了使代码易于理解和阅读,应当使标识符能够表达变量的含义。
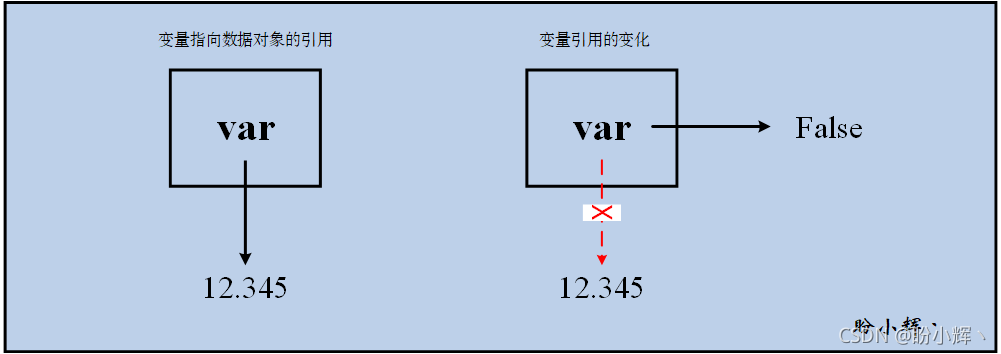
当标识符第一次出现在赋值 (assignment) 语句(变量名=值)的左侧时,会创建对应的 Python 变量。赋值语句将变量名与值关联起来。Python 会为这个值分配内存空间,然后让这个变量指向这个值,变量存储指向数据的引用,而不是数据本身。当改变变量的值时,Python 会为这个新的值分配另一个内存空间,然后让这个变量指向这个新值。
>>> var = 12.345
>>> var
12.345
>>> var = var + 2
>>> var
14.345
>>> var = False
>>> var
False
赋值语句 var = 12.345 用于创建变量 var,并且令 var 保存指向数据对象 12.345 的引用。Python 会先计算赋值运算符右边的表达式,然后将指向结果数据对象的引用赋给左边的变量名。如果数据的类型发生改变,例如将布尔值 False 赋值给 var,则变量 var 的类型也会变成布尔类型。这体现了 Python 的动态特性,即赋值语句可以改变变量的引用,同样的变量可以指向不同类型的数据。
3. 数据
由于 Python 是面向对象编程的编程语言,因此,在 Python编程语言中,数据同样是对象,而对象是类的实例。类是对数据的构成以及数据所能进行操作的描述,这与抽象数据类型十分类似。
3.1 原子数据类型
Python 提供 int 和 float 类来实现整数类型和浮点数类型,并包含标准数学运算符(可以通过括号改变运算优先级),下面给出整数类型、浮点数类型及运算符的使用示例:
>>> 10 - 5 * 5
-15
>>> (10 - 5) * 5
25
>>> 12.5 * 3.3
41.25
>>> 12 / 2
6.0
>>> 13 / 2
6.5
>>> 13 // 2
6
>>> 3 ** 3
27
>>> 13 % 2
1
Python 通过 bool 类实现布尔数据类型,其可能的状态值包括 True 和 False,布尔运算符有 and、or 以及 not,同时布尔对象也可以用于相等 (==)、大于 (>) 等比较运算符的计算结果。
下面给出布尔类型及运算符的使用示例:
>>> True
True
>>> False or True
True
>>> not (True and False)
True
>>> 11 != 111
True
>>> 1024 <= 1024
True
>>> (1024 >=1000) and (1024 <= 1000)
False
3.2 结构数据类型
除了上述原子数据类型外,Python 还包含许多原生的结构数据类型:1) 有序结构数据类型——列表、字符串以及元;2) 无序结构数据类型——集和与字典。
需要注意的是这里的有序是指在插入的时候,保持插入的顺序性:
>>> list([1,2,3,7,5])
[1, 2, 3, 7, 5]
>>> set([1,2,3,7,5])
{1, 2, 3, 5, 7}
3.2.1 通用的序列运算
有序数据结构也可以称为序列。序列在处理系列值时非常有用,例如我们有一个购物清单,如果使用列表来表示(所有元素都放在方括号内,元素间用逗号分隔),形式如下:
>>> shopping = ['cabbage', 'apple', 'beef']
序列可以包含其他序列,例如上示列表中,每个元素就由字符串序列组成,同时列表中也可以包含列表:
>>> shopping = [['cabbage', 2], ['apple', 5], ['beef', ‘50’]]
序列支持一系列 Python 运算,如下所示:
🔍 索引
序列中的所有的每个元素都有其索引 (indexing),索引是从 0 开始递增的,利用索引就可以访问序列中的每个元素了:
>>> shopping = ['cabbage', 'apple', 'beef']
>>> shopping[0]
'cabbage'
在 Python 中也可以使用负数索引,用于从右向左进行编号,即 -1 是序列最后一个元素的位置,这在我们仅需取序列末尾元素时非常有用:
>>> shopping[-2]
'apple'
序列也可以直接进行索引操作,而无需首先将其赋值给变量:
>>> ['cabbage', 'apple', 'beef'][-1]
'beef'
同样如果函数的返回结果为一个序列,我们也可以直接对其进行索引操作 (关于 input 函数将在 4.1 节详细描述):
>>> example = input('Please enter your name: ')[1]
Please enter your name: alice
>>> example
'l'
🔍 切片
索引的作用是用来访问单个元素,而切片 (slicing) 则可以用于访问序列中指定范围内的元素,切片使用两个冒号分隔的两个索引:
>>> number = [1, 2, 3, 4, 5]
>>> number[1:4]
[2, 3, 4]
>>> number[1:-1]
[2, 3, 4]
从以上示例可以看出,第一个索引指向的元素包含在切片内,第二个索引指向的元素不在切片内。
使用切片语法时,如果省略第二个索引,则切片会取到序列末尾;如果省略第一个索引,则切片会从序列开头开始取;如果两个索引都省略,则会取整个序列:
>>> url = 'https://www.python.org'
>>> sever = url[12:-4]
>>> sever
'python'
>>> domain = url[12:]
>>> domain
'python.org'
>>> protocol = url[:5]
>>> protocol
'https'
>>> copy_url = url[:]
>>> copy_url
'https://www.python.org'
🔍 连接
可使用加法运算符将多个序列连接为一个,但需要注意的是,不同类型的序列不能进行连接:
>>> ['a', 'b', 'c'] + ['d', 'e'] + ['f']
['a', 'b', 'c', 'd', 'e', 'f']
>>> 'Hello ' + 'world!'
'Hello world!'
>>> 'Hello' + ['a', 'b', 'c']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "list") to str
🔍 重复
可使用乘法运算符将一个序列重复多次来创建一个新序列:
>>> 'love you!' * 3
'love you!love you!love you!'
>>> [1,2] * 5
[1, 2, 1, 2, 1, 2, 1, 2, 1, 2]
>>> [None] * 5
[None, None, None, None, None]
🔍 成员
使用运算符 in 可以检查特定值是否包含在序列中,并返回指示是否满足的布尔值:满足时返回 True, 不满足时返回 False:
>>> names = ['root', 'xiaohui', 'xiaohuihui']
>>> 'root' in names
True
>>> 'hui' in names
False
🔍 长度
内置函数len返回序列包含的元素个数:
>>> names = ['root', 'xiaohui', 'xiaohuihui']
>>> len(names)
3
3.2.2 列表
除了可以应用通用的序列操作外,列表有很多特有的方法:
1 基本列表操作
接下来将介绍用于创建、修改列表的方法。
🔍 list 函数
使用函数 list 可以将创建空列表或将任何序列转换为列表:
>>> empty_list = list()
>>> []
>>> string_test = list('Python')
>>> string_test
['P', 'y', 't', 'h', 'o', 'n']
range 是一个常见的 Python 函数,它常与列表一起讨论。使用 range 可以生成值序列的范围对象,然后利用 list 函数,能够以列表形式看到范围对象的值,同时也和切片语法类似,其支持使用步长参数:
>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(range(1, 10))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(range(1, 10, 2))
[1, 3, 5, 7, 9]
🔍 修改列表元素
修改列表只需结合索引使用普通赋值语句即可,使用索引表示法可以修改特定位置的元素:
>>> numbers[0] = 11
>>> numbers
[11, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>
使用切片语法可以同时给多个元素赋值,通过使用切片赋值,可将切片替换为长度与其不同的序列,或者插入、删除元素:
>>> fruits = ['apple', 'orange', 'banana', 'pear', 'strawberry']
>>> fruits[2:] = ['lemon', 'watermelon']
>>> fruits
['apple', 'orange', 'lemon', 'watermelon']
🔍 删除元素
从列表中删除元素可以使用 del 语句:
>>> fruits = ['apple', 'orange', 'banana', 'pear', 'strawberry']
>>> del fruits[0]
>>> fruits
['orange', 'banana', 'pear', 'strawberry']
>>> del fruits[1:3]
>>> fruits
['orange', 'strawberry']
2 列表方法
方法是与对象紧密联系的函数,方法调用与函数类似,需要在方法名前加上了对象和句点:
object.method(arg)
🔍 index 方法
index 方法在列表中查找指定值第一次出现的索引:
>>> fruits = ['apple', 'orange', 'banana', 'pear', 'strawberry']
>>> fruits.index('orange')
1
>>> fruits.index('lemon')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: 'lemon' is not in list
查找单词“orange”时,返回其索引 4,但是当搜索列表中不存在的单词“lemon”时,会引发异常。
🔍 count 方法
count 方法用于统计指定元素在列表中的数量:
>>> fruits = ['apple', 'orange', 'banana', 'apple', 'orange', ['apple']]
>>> fruits.count('apple')
2
>>> fruits.count(['apple'])
1
🔍 append 方法
append 方法用于将一个对象添加到列表末尾:
>>> fruits = ['apple', 'orange', 'banana', 'pear', 'strawberry']
>>> fruits.append('lemon')
>>> fruits
['apple', 'orange', 'banana', 'pear', 'strawberry', 'lemon']
需要注意的是,与其他修改列表的方式类似,append 方法也是原地操作的,它不会返回修改后的新列表,而是直接在旧列表上进行修改。
🔍 insert 方法
insert 方法用于在列表的指定位置插入一个新元素:
>>> fruits = ['apple', 'orange', 'banana', 'pear', 'strawberry']
>>> fruits.insert(2, 'lemon')
>>> fruits
['apple', 'orange', 'lemon', 'banana', 'pear', 'strawberry']
🔍 pop 方法
pop 方法用于在列表中删除一个指定位置(默认为最后一个)的元素,并返回这一元素:
>>> fruits = ['apple', 'orange', 'banana', 'pear', 'strawberry']
>>> fruits.pop()
'strawberry'
>>> fruits
['apple', 'orange', 'banana', 'pear']
>>> fruits.pop(1)
'orange'
>>> fruits
['apple', 'banana', 'pear']
🔍 remove 方法
remove 方法用于移除在列表中首次出现的指定元素,但列表中之后出现的同样元素,并不会被删除:
>>> fruits = ['apple', 'orange', 'banana', 'apple', 'strawberry', 'apple']
>>> fruits.remove('apple')
>>> fruits
['orange', 'banana', 'apple', 'strawberry', 'apple']
🔍 sort 方法
sort 方法用于对列表原地排序,原地排序意味着对原来的列表按顺序排列,而不是返回排序后列表的副本:
>>> x = [1, 3, 4, 9, 8, 2]
>>> x.sort()
>>> x
[1, 2, 3, 4, 8, 9]
由于 sort 修改原列表且不返回任何值,最终的结果列表是经过排序的。如果要获取排序后的列表的副本,而不修改原列表,需使用函数 sorted:
>>> x = [1, 3, 4, 9, 8, 2]
>>> y = sorted(x)
>>> y
[1, 2, 3, 4, 8, 9]
>>> x
[1, 3, 4, 9, 8, 2]
sorted 方法同样可以用于其他序列,但返回值总是一个列表:
>>> sorted('Hello world!')
[' ', '!', 'H', 'd', 'e', 'l', 'l', 'l', 'o', 'o', 'r', 'w']
🔍 clear 方法
clear 方法就地清空列表的内容:
>>> x = [1, 3, 4, 9, 8, 2]
>>> x.clear()
>>> x
[]
🔍 copy 方法
我们已经知道 Python 是基于值的管理方式,因此常规复制只是将另一个名称关联到列表,它们指向的是同一个列表,因此修改其中一个列表,另一个也会改变:
>>> fruits = ['apple', 'orange', 'banana', 'strawberry']
>>> fruits_2 = fruits
>>> fruits_2[1] = 'lemon'
>>> fruits
['apple', 'lemon', 'banana', 'strawberry']
copy 方法用于复制列表,区别在于其使两个变量指向不同的列表,将列表 listB 关联到 listA 的副本:
>>> listA = ['apple', 'orange', 'banana', 'strawberry']
>>> listB = listA.copy()
>>> listB[1] = 'lemon'
>>> listA
['apple', 'orange', 'banana', 'strawberry']
3.2.3 字符串
Python 没有专门用于表示字符的类型,因此一个字符就是只包含一个元素的字符串。前面介绍了列表的方法,而字符串所拥有的方法要更多,其很多方法都是从模块 string 中“继承”而来的。这里并不会介绍所有字符串的方法,只会介绍一些对于之后数据结构和算法最有用的方法。
🔍 lower 和 upper 方法
lower 方法返回字符串的小写版本,而 upper 方法返回字符串的大写版本:
>>> string_1 = 'Hello World!'
>>> string_1.lower()
'hello world!'
>>> string_1.upper()
'HELLO WORLD!'
🔍 count 方法
count 方法返回字符串中指定子串出现的次数:
>>> string_2 = 'data structure and algorithms'
>>> string_2.count('a')
4
>>> string_2.count('th')
1
🔍 center、ljust 和 rjust 方法
center、ljust 和 rjust 方法返回一个字符串,原字符串居中 (center) /居左 (ljust) /居右 (rjust),使用指定字符填充新字符串,使其长度为指定的 width:
>>> string_3 = 'Hello world!'
>>> string_3.center(16, '*')
'**Hello world!**'
>>> string_3.ljust(16, '*')
'Hello world!****'
>>> string_3.rjust(16, '-')
'----Hello world!'
🔍 find 方法
find 方法在字符串中查找指定子串,如果找到,就返回第一个找到的子串的第一个字符的索引,否则返回 -1:
>>> string_1 = 'Explicit is better than implicit. Simple is better than complex.'
>>> string_1.find('is')
9
find 方法还支持使用可选参数指定查找的起点和终点,第二个参数指定搜索起点,第三个参数指定搜索终点:
>>> string_1 = 'Explicit is better than implicit. Simple is better than complex.'
>>> string_1.find('is', 10)
41
>>> string_1.find('is', 10, 40)
-1
🔍 split 方法
split 方法用于使用指定分隔符将字符串拆分为序列:
>>> zen_of_python = 'Beautiful is better than ugly. Explicit is better than implicit.'
>>> zen_of_python.split('is')
['Beautiful ', ' better than ugly. Explicit ', ' better than implicit.']
>>> zen_of_python.split()
['Beautiful', 'is', 'better', 'than', 'ugly.', 'Explicit', 'is', 'better', 'than', 'implicit.']
如果没有指定分隔符,默认情况下使用单个或多个连续的空白字符作为分隔符。
🔍 join 方法
与 split 方法相反,join 方法用于使用指定分割符合并序列的元素,并返回合并后的字符串:
>>> ''.join(['1','2','3'])
'123'
>>> fruits = ['apple', 'orange', 'lemon', 'banana']
>>> '--'.join(fruits)
'apple--orange--lemon--banana'
>>> ''.join([1,2,3])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: sequence item 0: expected str instance, int found
需要注意的是,所合并序列的元素必须都是字符串。
3.2.4 元组
元组与列表非常相似,区别在于,元组和字符串一样是不可修改的。元组的所有元素包含在圆括号内并且以逗号分隔。元组允许使用适用于通用序列的任一操作:
>>> tuple_1 = tuple()
>>> tuple_1
()
>>> tuple_1 = tuple([1,2,3])
>>> len(tuple_1)
3
>>> tuple_1[0:1]
(1,)
>>>
可以使用 tuple 函数创建元素,如果尝试改变元组中的元素,就会导致异常:
>>> tuple_1 = (1,2,3)
>>> tuple_1[1] = 4
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
3.2.5 集合
集合 (set) 是无序的不重复元素序列,形式为以花括号包含、以逗号分隔的一系列值,可以使用大括号 {} 或者 set() 函数创建集合(创建一个空集合必须用 set() 而不能使用 {},因为 {} 是用来创建一个空字典):
>>> setA = {'apple', 'banana', 'lemon'}
>>> setA
{'lemon', 'banana', 'apple'}
>>> setB = set(['apple', 'banana', 'lemon'])
>>> setB
{'lemon', 'banana', 'apple'}
1 基本集合运算
集合支持以下运算:
>>> setA = {'apple', 'banana', 'lemon'}
>>> len(setA)
3
>>> 'apple' in setA
True
>>> setB = {'apple', 'banana', 'orange'}
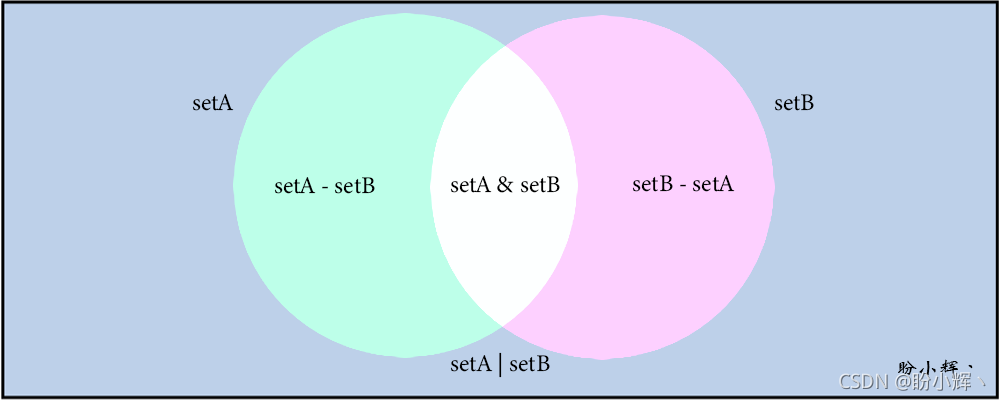
>>> setA | setB
{'banana', 'apple', 'lemon', 'orange'}
>>> setA & setB
{'apple', 'banana'}
>>> setA - setB
{'lemon'}
>>> setB - setA
{'orange'}
>>> setA <= setB
False
>>> setC = {'apple', 'banana'}
>>> setC <= setA
True
2 基本集合方法
集合同样支持一系列方法,其中一些方法具有相对应的运算符,如 union、intersection、difference 等:
🔍 union、intersection、difference 与 issubset 方法
union、intersection、difference 与 issubset 方法分别对应于集合运算符 |、&、- 和 <=:
>>> setA = {'lemon', 'banana', 'apple'}
>>> setB = {'banana', 'apple', 'orange'}
>>> setA.union(setB)
{'banana', 'apple', 'lemon', 'orange'}
>>> setA.intersection(setB)
{'apple', 'banana'}
>>> setA.difference(setB)
{'lemon'}
>>> setA.issubset(setB)
False
🔍 add 方法
add 方法用于向集合中添加元素:
>>> setA = {'lemon', 'banana', 'apple'}
>>> setA.add('orange')
>>> setA
{'lemon', 'banana', 'apple', 'orange'}
>>> setA.add('apple')
>>> setA
{'lemon', 'banana', 'apple', 'orange'}
🔍 remove 方法
remove 方法用于从集合中移除指定元素:
>>> setA = {'lemon', 'banana', 'apple', 'orange'}
>>> setA.remove('apple')
>>> setA
{'lemon', 'banana', 'orange'}
>>> setA.remove('apple')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'apple'
从上示例可以看出,使用 remove 方法时当元素不存在,则会引发错误。
🔍 pop 方法
pop 方法用于从集合中移除随机元素,并且返回值为移除的元素:
>>> setA = {'banana', 'apple', 'lemon', 'orange'}
>>> setA.pop()
'banana'
>>> setA
{'apple', 'lemon', 'orange'}
🔍 clear 方法
clear 方法用于清空集合:
>>> setA
{'apple', 'lemon', 'orange'}
>>> setA.clear()
>>> setA
set()
3.2.6 字典
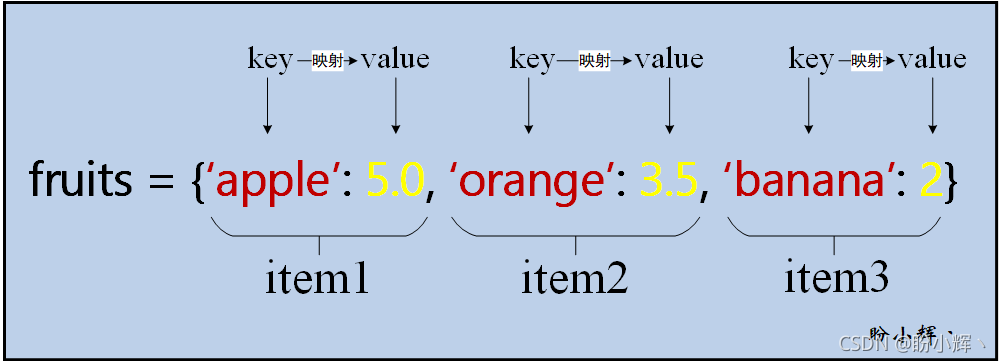
字典由键及其相应的值组成,每个键-值对称为一项 (item)。在以下示例中,键为水果名,而值为价格。整个字典放在花括号内,每个键与其值之间都用冒号 (:) 分隔,项之间用逗号分隔,空字典用 {} 表示:
>>> fruits = {'apple': 5.0, 'orange': 3.5, 'banana': 2}
>>> fruits
{'apple': 5.0, 'orange': 3.5, 'banana': 2}
需要注意的是,字典并不是根据键来进行有序维护的,键的位置是由散列来决定的。
1 基本字典运算
字典的基本运算符如下所示:
🔍 创建字典
可使用函数 dict 从其他映射或键-值对序列创建字典:
>>> fruits = [('apple', 5.0), ('orange', 3.5)]
>>> d_fruits = dict(fruits)
>>> d_fruits
{'apple': 5.0, 'orange': 3.5}
同样也可以通过实参来调用 dict 函数:
>>> d_fruit = dict(apple=5.0,orange=3.5)
>>> d_fruit
{'apple': 5.0, 'orange': 3.5}
字典中的键可以是任何不可变的类型,如实数、字符串或元组,但不能是列表,因为列表是可变类型。
🔍 访问字典中的值
访问字典的语法与访问序列的语法十分相似,只不过是使用键来访问,而不是下标:
>>> fruits = {'apple': 5.0, 'orange': 3.5, 'banana': 2}
>>> fruits['apple']
5.0
字典中同样可以使用成员运算符,但表达式 key in dictA 或 key not in dictA (其中 dictA 是一个字典)查找的是键而不是值:
>>> fruits = {'apple': 5.0, 'orange': 3.5, 'banana': 2}
>>> 5.0 in fruits
False
>>> 'apple' in fruits
True
len(dictA) 返回字典 dictA 中包含的项(键-值对)数:
>>> fruits = {'apple': 5.0, 'orange': 3.5, 'banana': 2}
>>> len(fruits)
3
🔍 修改字典元素
修改字典中的元素,可以使用 d[key] = value 将值 value 关联到键 key 上,如果字典中原本没有的键 key,将会在字典中创建一个新项:
>>> fruits = {'apple': 5.0, 'orange': 3.5, 'banana': 2}
>>> fruits['apple'] = 5.5
>>> fruits
{'apple': 5.5, 'orange': 3.5, 'banana': 2}
>>> fruits['lemon'] = 6.0
>>> fruits
{'apple': 5.5, 'orange': 3.5, 'banana': 2, 'lemon': 6.0}
🔍 删除字典元素
del dictA[key] 用于删除键为 key 的项:
>>> fruits = {'apple': 5.0, 'orange': 3.5, 'banana': 2}
>>> del fruits['apple']
>>> fruits
{'orange': 3.5, 'banana': 2}
2 基本字典方法
与其他内置类型一样,字典也有其特有方法:
🔍 get 方法
get 方法的存在,可以弥补访问字典中没有的项时引发错误的问题:
>>> fruits = {'apple': 5.0, 'orange': 3.5, 'banana': 2}
>>> fruits['lemon']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'lemon'
>>> print(fruits.get('lemon'))
None
如上所示,使用get来访问不存在的键时,并不会引发异常,而是返回None,可以通过使用可选参数,在访问的键不存在时返回指定的值而不是None:
>>> print(fruits.get('lemon', 4.0))
4.0
🔍 keys、values 和 items 方法
items 方法返回一个包含所有字典项的列表(也称为字典视图),其中每个元素都为 (key, value) 的形式;keys 方法返回一个包含字典中的所有键的字典视图;values 方法返回一个由字典中的值组成的字典视图:
>>> fruits = {'apple': 5.0, 'orange': 3.5, 'banana': 2}
>>> fruits.keys()
dict_keys(['apple', 'orange', 'banana'])
>>> fruits.values()
dict_values([5.0, 3.5, 2])
>>> fruits.items()
dict_items([('apple', 5.0), ('orange', 3.5), ('banana', 2)])
登录后可发表评论
点击登录