大家好~~~我是开心学编程,学到无极限的@jxwd😀
写在前面:
各位小伙伴还在为C语言的学习而苦恼嘛?
还在为没有知识体系而烦心嘛?
别急。因为~~~~
接下来的两个多月,我会持续推出C语言的有关知识内容。
都是满满的干货,从零基础开始哦~,循序渐进😀,直至将C中知识基本全部学完🐂。
关注我♥,订阅专栏 0基础C语言保姆教学,
就可以持续读到我的文章啦😀🐕~~~~
本文为万字长文,满满干货。为防止找不到,可以收藏再看呦😀
本文为第5节——数组(文末附前4章的链接呦👉)
jxwd,让你服气,拒绝水文,从我做起!
目录
一维数组的创建和初始化
一维数组的创建
一维数组的初始化
补充:
另外,这里作为一个知识的补充,我们说一下指定初始化器:
一维数组的使用
数组的边界
一维数组在内存中的存储
二维数组的创建和初始化
二维数组的创建
二维数组的初始化
二维数组的使用
二维数组在内存中的存储
我们在之前的介绍中,已经领悟这一点:数组是一组相同元素的集合。
那为什么会有数组?
试想,倘若我们想要创建100个整形变量,难道要一个一个创建吗?那岂不是太麻烦了?
于是乎,就诞生了数组。
一维数组的创建和初始化
一维数组的创建
那么,数组创建的语法形式是怎么样的呢?
以一维数组为例:
简而言之,是这个样子的:

这里的type_f 指的是数组里的元素类型
arr_name是数组名
const_n是一个常量表达式,用来指定数组的大小。注意,这里不可以是负数。
我们来看:假设这样一个代码:
char arr2[5] ;如上所示,这里的arr2为数组名,数组里有5个char类型元素。
那么,我们的数组的方括号里[ ]的值一定得是常量表达式吗?
就比如说,我这么创建可以吗?
int n = 3;
int a[n];与上面创建方式的区别在于,我们数组a里面的n是一个变量。
那么,这样的创建方式可以吗?
我们可以来看一下:
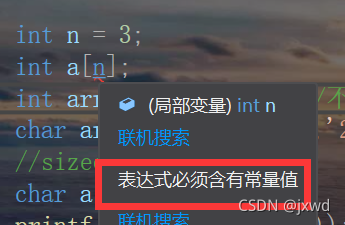
由上图可知,在vs2019中,会报错,而且报错的理由就是表达式必须要含有常量值。哪怕你是const修饰的变量。(下面我们会讲到:const修饰的变量具有常变量属性)
但是,我在这里给出答案:
在C99之前,这种写法是不允许的,而在C99之后,这种写法是允许的。而我们vs编译器的编译环境并不能很好的支持C99的语法,如果我们在gcc编译器或者其他对新语法更加支持的编译器下,这种写法是可以的。
我们在这里可以给大家演示一下:(不过我们会用到一系列还没有介绍过的东西,所以我们只要看结果就行,不用关注过程)
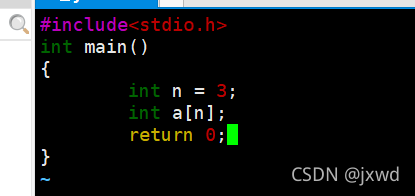
这是我们写的代码
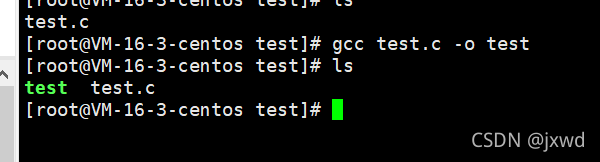

这两个图片说明我们编译和运行成功。没有报错,那么就说明我们写的代码是正确的。
也就是说,这种写法是可以的。但必须说的是,在C99标准之后才支持这种写法。
需要注意一下的是,变长数组是不支持初始化的。并且变长数组也是不能用static、extern等关键字修饰的。
况且我们以后如果用变长数组一般都用动态开辟,直接用这样的变长数组还是很少的。
一维数组的初始化
什么叫做初始化?
可以理解为,就是在创建的时候,给上值。
就比如:
char arr2[5] = {'0','1','2','3','4'};在这五个元素里,我分别给上了5个字符,作为数组的值。
创建好之后,我们在调试->监视的窗口下观察到。

如图所示,我们成功的在arr2的数组里面创建了5个char类型的元素。
那如果我在里面写的元素比5个还要多呢?显然,编译器会报错。
当然,这是初始化的一种方式。
还有另外一种方式,即数组的不完全初始化。
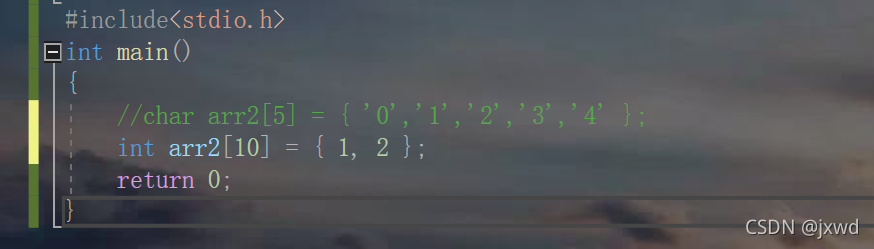
如图,我创建一个 arr2的数组的时候,我指定它有10个int大小的空间,但是,我只是初始化了1,2两个int ,那这样可以吗?
答案是可以的。
那会出现什么样的结果呢?
我们还是通过调试来看一下:
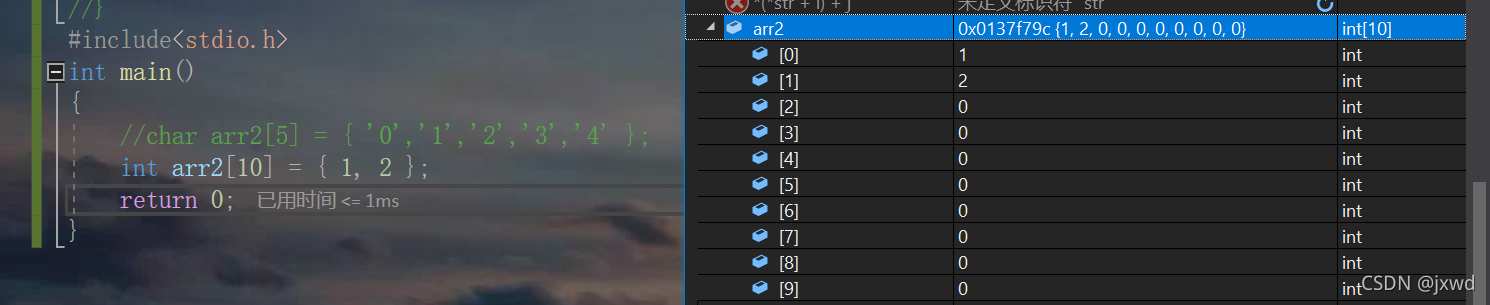
如图:第一个和第二个元素被初始化成了1和2,而后面的一众元素全都被默认初始化成了0。
这种初始化的方式叫做不完全初始化。
那么,如果我以后想把数组的元素全部置为0,就直接写int arr2[10] = { 0 };就完事了。
好,下面再介绍一种初始化的方式:
int a[] = { 1, 2, 3};请问:这个数组还会是10个元素的大小吗?肯定不会是。
我们可以再来调试看看:
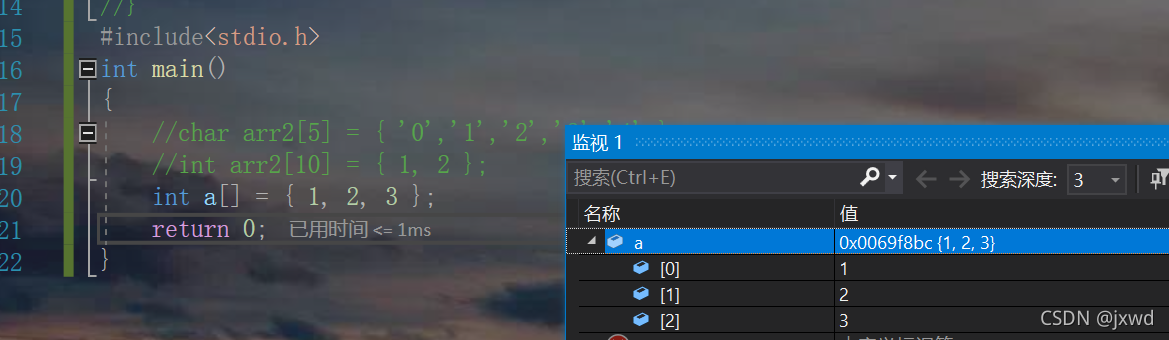
我们这个时候会发现,这个数组只有3个元素,并且它只对前面的3个元素进行了初始化。
所以,在初始化数组的时候,可以不指定数组的大小。但是操作系统会根据初始化的内容来自动开辟空间。
另外提一嘴:来看看我们下面两种初始化方式的差异:
char arr1[] = { 'a','b','c'};//方式1
char arr2[] = "abc"; //方式2我们可以依然借助调试来看:

我们可以清楚的看到,arr2里是有4个元素,即字符a,b,c和\0;而在arr1中只有3个元素。
这是因为,“abc”是一个字符串,在字符串后面是默认含有一个‘\0'的。
我们可以来求一下这两个数组的大小:
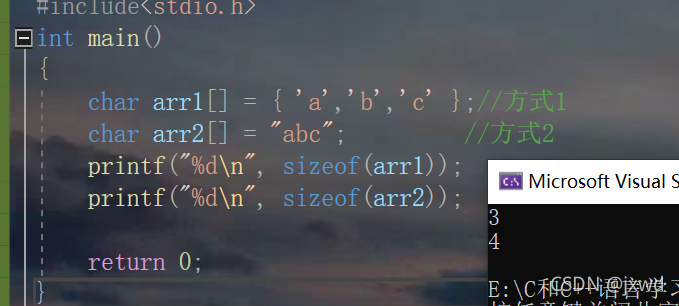
我们可以清晰的看到,arr2的大小是4,而arr1的大小是3。单位都是字节。
我们之前还讲过一个strlen,我们如果用它来求,得到的会是什么结果呢?
我们来看:
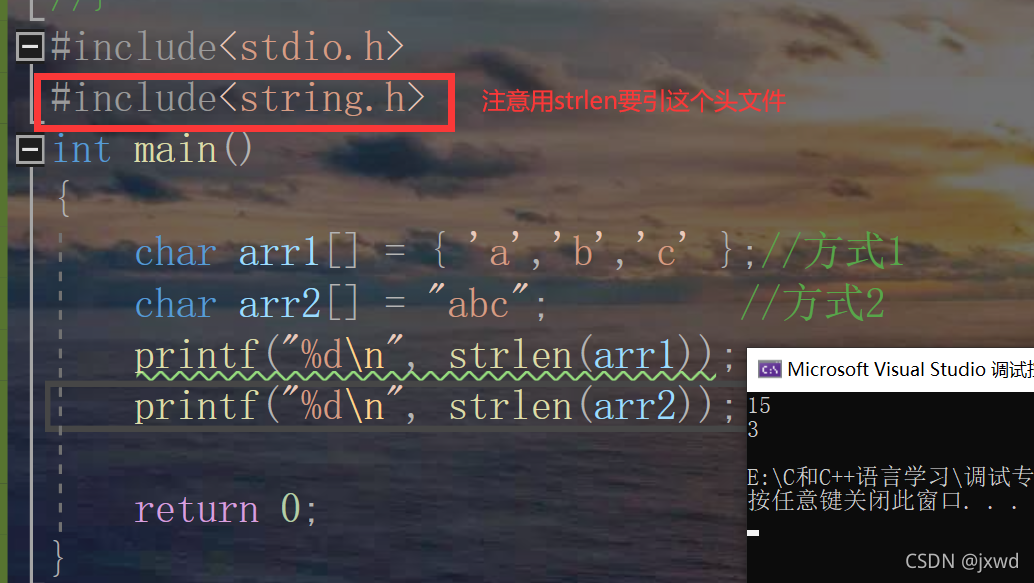
如图:arr1打印出来的实际上是一个随机值,而arr2打印出来的是3。
原因是什么呢?那sizeof和strlen又有什么关系和区别呢?
今天,我们就和大家来把sizeof和strlen的关系探讨清楚:
1、首先,sizeof是一个操作符(或者叫运算符);而strlen是库函数,使用时要引用头文件string.h
2、用途不同。sizeof是计算一个数组(或者其他类型)所占的空间大小,而strlen专门用于求字符串的长度,将’\0'前面的字符串的长度计算出来。
3、算的方法机制不同。sizeof不会受到'\0'等字符的影响,关注的是空间的大小,有多少空间就计算出多少空间。而strlen是遇到'\0'的时候才会停止,关注的是字符串的长度。并且也是在第一次遇到'\0'的时候就停止了。如果没有遇到'\0',那么它将会是一个随机值(因为它会一直往后找,直到碰到'\0')
补充:
另外,这里作为一个知识的补充,我们说一下指定初始化器:
它是另外一种数组初始化的方式。
需要注意的是,这种语法形式同样是在C99编译器之后才支持的,而我们前面说过,VS对C99的标准支持的不是那么好,所以这种初始化的方式在vs编译器下依然会报错。所以我们等会的举例在vscode的gcc环境中进行。
那么这种初始化是什么呢?
在传统的初始化数组中,必须要初始前一个元素,才能初始化下面的元素。
举个例子:
比如说int a[10];
就比如说,如果你想初始化a[5]为1,你必须先初始化a[5]前面的元素。
就是说,必须这样
int a[10] = { 0, 0, 0, 0, 0, 1};//传统是初始方法那么如果指定初始化器来初始化这一个数组,那么我们可以这样:
int a[10] = {[5] = 1};//C99提供的初始化方法这是什么意思呢?就是直接把下标为5的元素初始化为1。
那么a[5]前面和后面元素的初始化是怎么界定呢?
我们再来在gcc编译器上面尝试一下,这一次我们用vscode(因为在vs上C99支持的不是很好。)
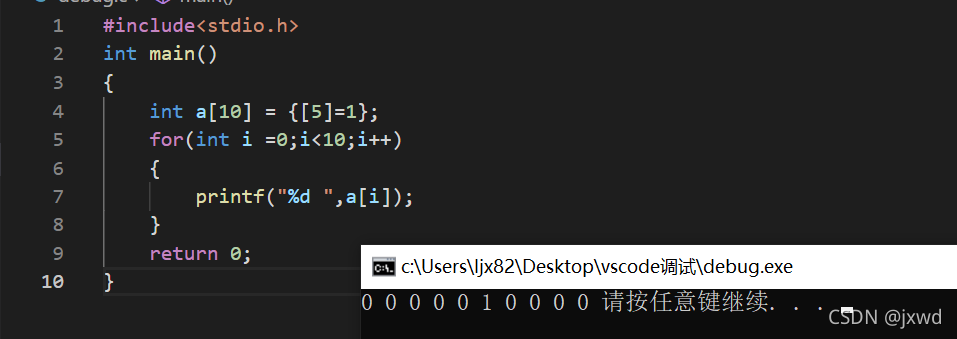
如上图所示,我们将数组a以这种方式初始化,那么它的第六个元素(下标为5)被初始化成了1,而其他的都默认被初始化成了0。
而如果我们这样初始化:
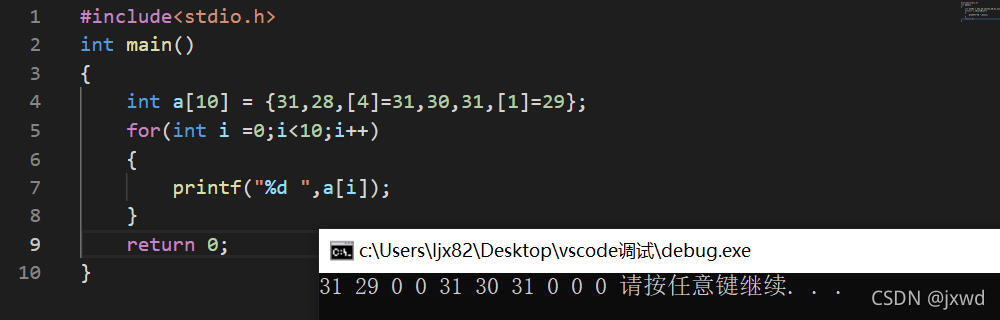
可以看到,这样的初始化方式还有两个特性:
1、 如果初始化容器后面有更多的值,那么这些值将用于初始化指定元素后面的值。以上面的代码为例,[4]=31,30,31,那么第五个元素是31,后面的元素30,31就会默认放在第六个和第七个位置作为a[5]和a[6]的初始化的值。
2、如果再次初始化指定的元素,那么最后初始化的将取代之前的初始化。比如上面的[1]=29,那么会将原先第二个位置上的元素28改变成29。
那么这样如果这样初始化,会发生什么?
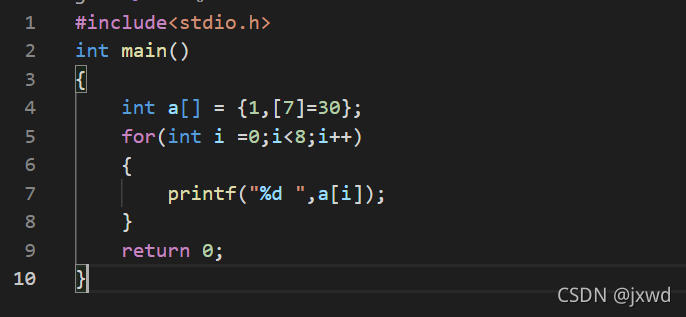
如果我们在[]内未指定元素的个数,那么编译器会自动把数组大小设置为足够装得下初始化的值。
那么,上面的代码所运行的结果就是

一维数组的使用
使用即可以访问并可以修改,即可读可写。
那么数组怎么样访问呢?
我们在之前介绍了 [ ] 这么一个下标引用操作符。
那么,我们就可以用 [ ]来对数组进行访问。
我们知道,数组的每个元素都是有编号的。并且下表是从0开始。

还是这张图,可以很清楚的反应出数组的元素和下标的关系。
那么,我想要打印出数组的第4个元素,该怎么做呢?
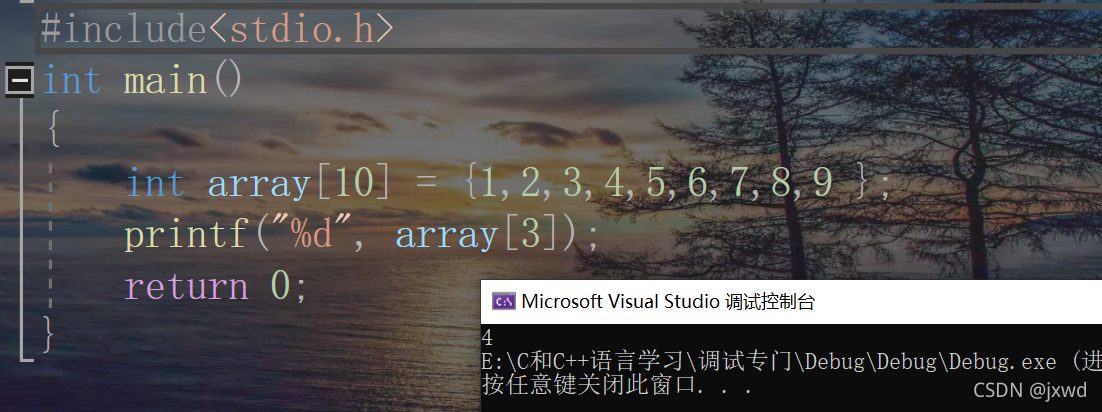
数组的第四个元素,下标为3,所以我们可以用array[3]来表示。
所以,上面的例子中,我们就用array[3]来表示数组array的下标为3的元素。
那我如果想把数组中的全部元素都打印出来,可以怎么办呢?
实际上,我们在前面的叙述中已经有渗透了。

如上图:
我们先把 数组的中元素的个数计算了出来(方法是用数组的大小除以数组每个元素的大小),然后再以for循环的方式将其一一打印了出来。
那我想在数组里面写入元素,应该怎么弄呢?
很简单,我们可以用scanf来实现:
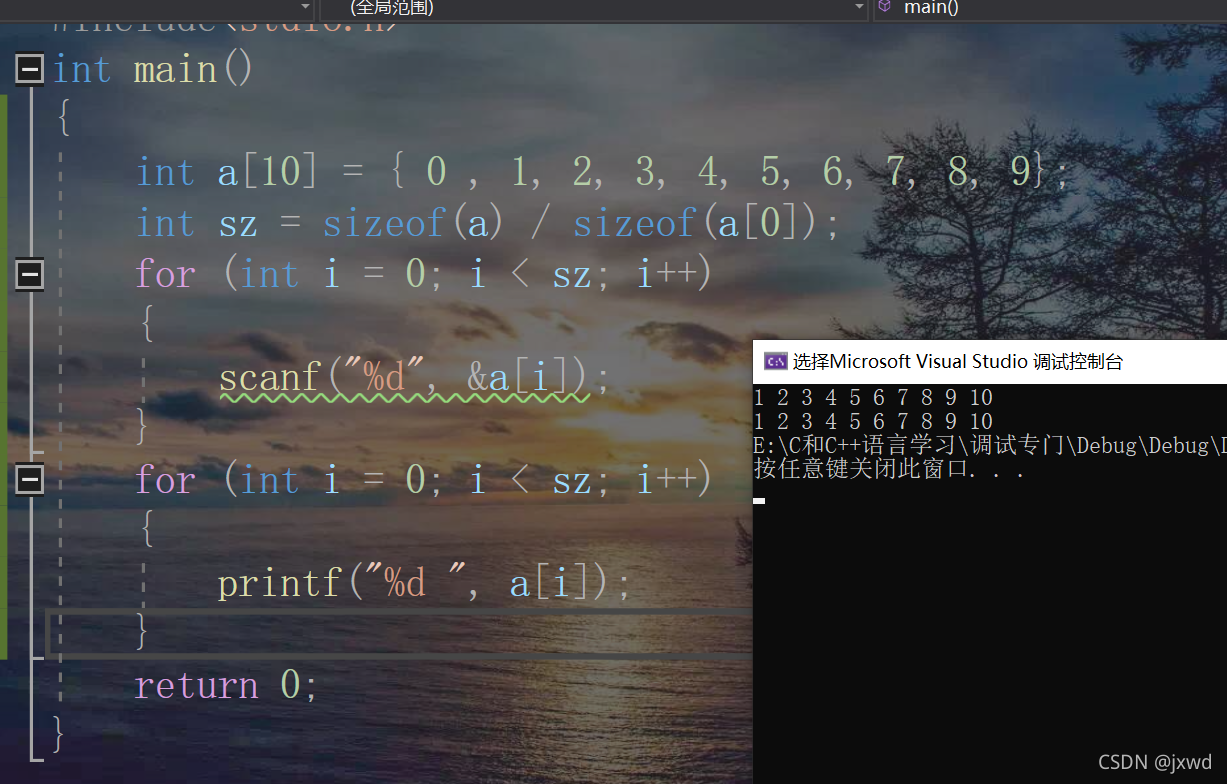
如图,当我们输入1-10的时候,对应的元素就变成了我们输入的了。
同样的道理,数组的每个元素也是支持算术、赋值等运算的。
比如,还是刚刚那个数组,我们想要把所有的元素都乘以2,可以这样:
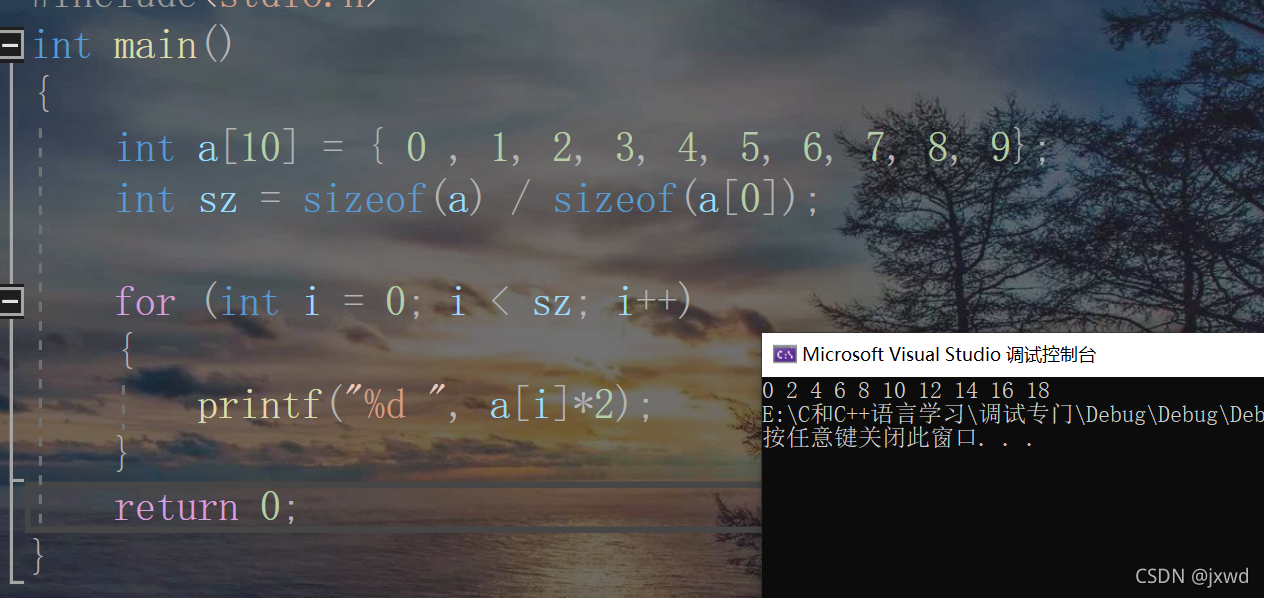
所以,这样的数组是可读可写的。
那如果有一天,我想让我的数组变成只可读的,就是说其他人不能够修改我的数组里的值,这个时候,我们可以怎么办呢?
这个时候,我们就会用到我们之前所说的一个关键字:const
const是什么?
我们在这里刚好可以和大家谈谈。我们如果一个变量int a=10;我们可以对变量a进行加减乘除的运算。因为这里的a是一个变量。但是,我们一旦加上了const修饰,那么就变成了只可读但是不可以写的变量了。
所以,总结一下上面所说的就是:如果一个变量被const修饰,它就变成了只读的属性。
有了上面的知识基础,我们就可以这样创建一个数组:
const int a[3] = { 0, 1, 2};这样,我们的数组a中的每一个元素就变成了只能去访问而不能去修改的变量了。因为数组中的每一个元素的类型都是const int。
另外,在一个函数中,如果不想要形参被修改的话,可以用const来修饰,这样的话,会对变量起到一个保护的作用。
数组的边界
我们说,数组是有元素个数大小的。那么,如果我访问的元素超出了数组的元素的范围,结果会怎么样呢?
我们举个例子:
会发现,我们编译不会存在问题。那么我们运行呢?
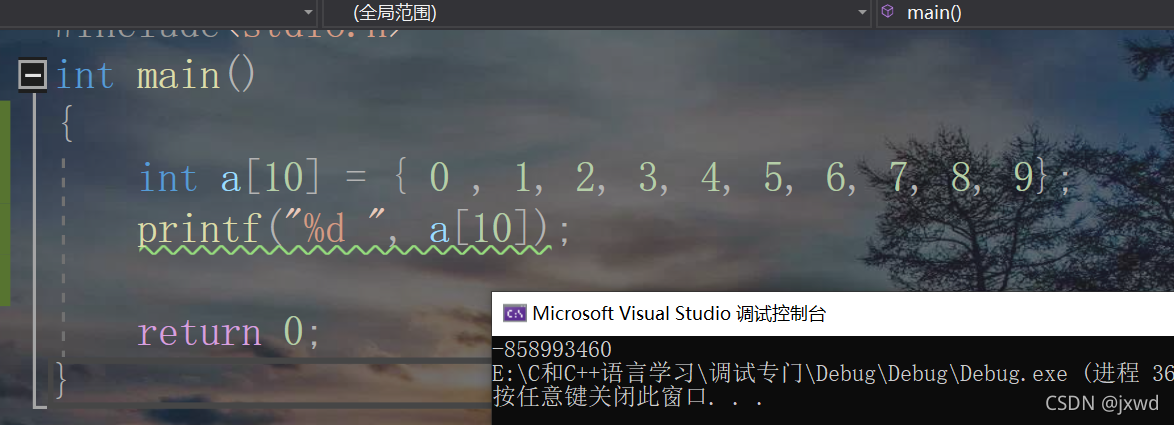 可以看出,它是一个随机值。
可以看出,它是一个随机值。
因为当数组访问越界的时候,它其实只是内存中的一个随机的一块区域的值,而这一块区域我们并没有去使用它的权限,所以它实际上是内存上某一块区域的一个随机值。
那为什么会出现这样的情况?编译器会什么会让数组越界的情况发生而不会报错?
原因很简单,就是C对于程序员是足够信任的。所以,它相信程序员不会写出越界的数组,因此,就不再设置专门的步骤来检测数组是否越界。这样的好处是使得程序变得更加优化。不用每一次都去检验数组是否越界,从而会增加程序运行的速度。
一维数组在内存中的存储

这是为什么呢?
我们需要知道这样一个事情:数组在内存中的存储是连续的。而一个字节给一个地址编号。
所以,它们的地址是挨着的。
那为啥每相邻的元素的地址相差的是4,而不是1?
原因很简单,因为我们在数组中存储的每一个元素是int类型。每个int类型的空间占4个字节。
并且随着数组下标的增长,地址由小到大。
二维数组的创建和初始化
实际上,一维数组弄懂了,二维就很简单了,基本上都是”依此类推“。
二维数组的创建
我们如果创建了这样一个数组:
int a[3][4];我们会发现,它似乎比我们刚刚所说的一维数组多了一个[ ]
那它是什么意思呢?
我们有这样两种方式来理解:
1、它实际上是一个矩阵。3行4列。
2、把它想象成是一个数组的数组。就是说,它实际上是数组int a[3]中含有4个元素,而这4个元素都是数组。
二维数组的初始化
类比着一维数组:
我们可以有一下几种初始化的方式:
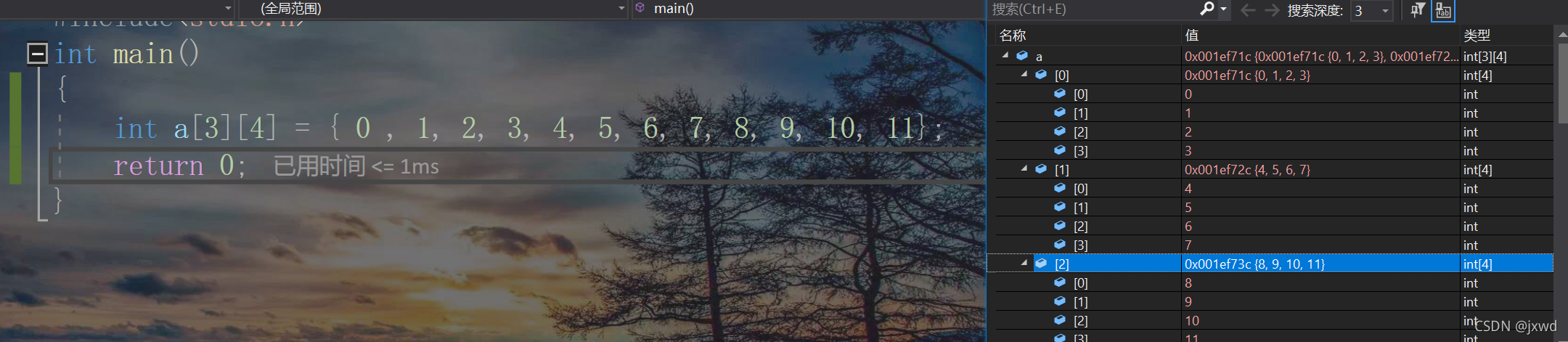
最老实的一种,就是把每一个元素都一一列举出来。那么在创建这个数组的时候,就会默认先把一行布满,然后接着下一行去排列。
第二种,就是不完全初始化:
类比一维数组,二维数组也一样,如果在大括号里面所列举的元素的个数小于[ ]中的元素的个数,那么就在后面默认补0;
第三种初始化的方式,可以这样:

这样的话,第一行就被初始化成了1,然后第一行不足的补零;第二行、第三行同理。
另外,在初始化二位数组的时候,可以省略行数,但不可以省略列数。具体的原因等我们讲到指针的时候再来说。
二维数组的使用
二维数组的访问,同样是可以用下标的方式来实现:
比如,我想把上图中数组的每一个元素都打印出来,我们可以这样:

这里的a[i][j]表示的正是访问第i行第j列的元素
二维数组在内存中的存储
还以刚刚上面的数组举例,我们将它们的地址依次打印出来:
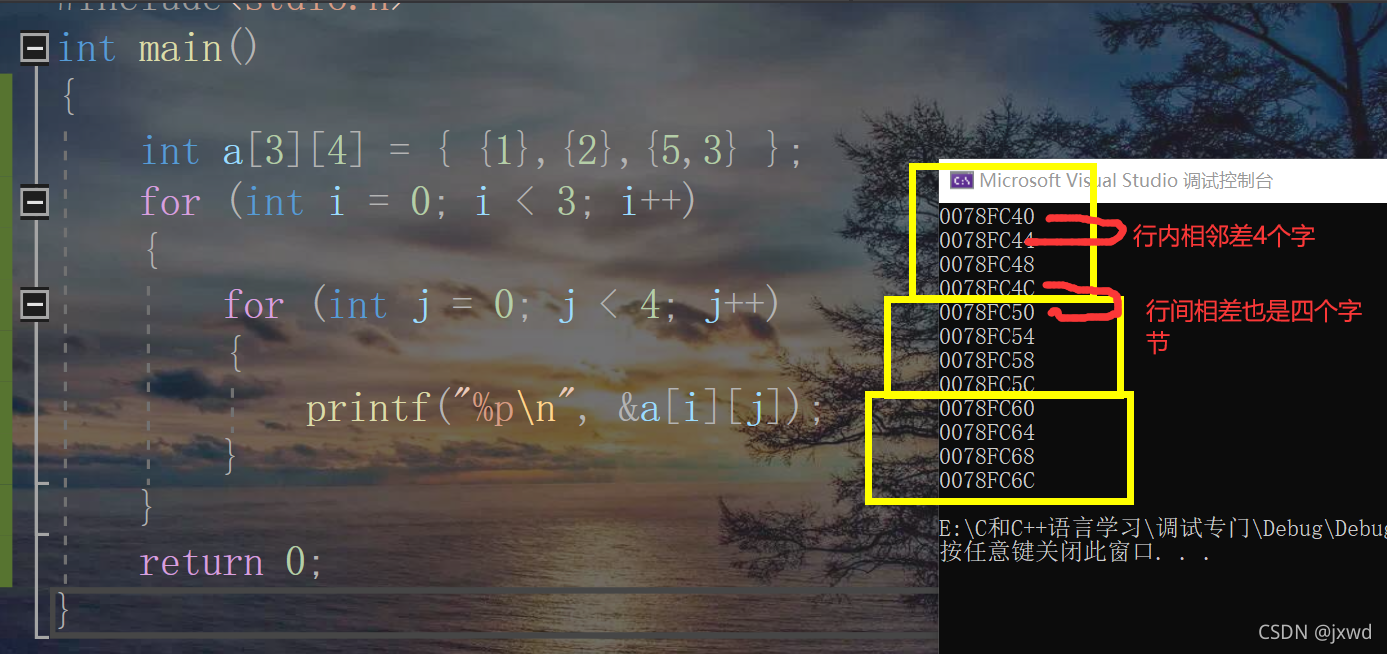
那么如果这样说的话,我们的二维数组就可以这样来理解:
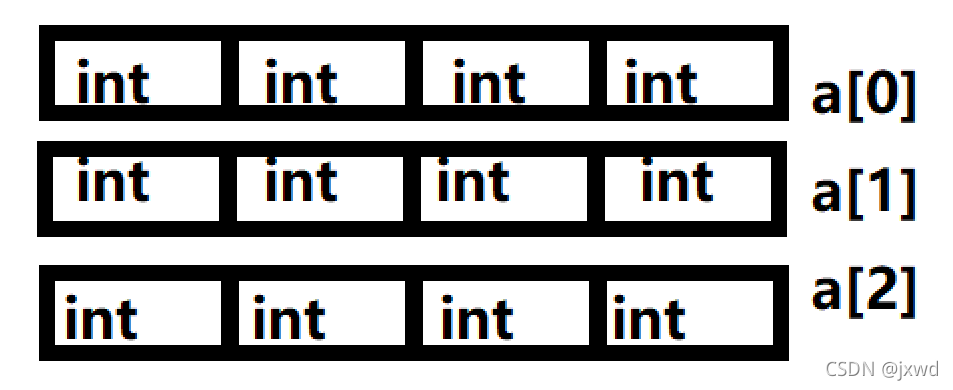
(我们逻辑上的二维数组)
这个a[3][4]数组中,可以拆分为a[0],a[1],a[2]三个一维数组,然后每个一维数组中有4个int类型的元素

(实际空间中存储的二维数组)
其实,我们的C中还支持多维数组。比如三维数组就可以用int a[3][5][6]这样来表示。
但是,我们在实际应用中,其实很少会用到。一般最多用到二维数组。
到了C++之后,你会发现甚至数组用的都比较少了😀
关于数组与函数、数组与指针,我们将会在讲解完指针之后,专门开设一节,来说清楚三者之间的用法联系。
好了,本节的内容就到此为止啦~~~关注我,订阅专栏,就能持续看到我的文章啦😀😀
0基础C语言保姆教程——第4节 函数_xdnxl的博客-CSDN博客
0基础C语言自学教程——第三节 分支与循环_xdnxl的博客-CSDN博客
0基础C保姆自学 第二节——初步认识C语言的全部知识框架_xdnxl的博客-CSDN博客
C语言自学保姆教程——第一节--编译准备与第一个C程序_xdnxl的博客-CSDN博客