目录
1、准备工作
2、训练步骤
2.1、生成训练用tif和box文件
2.2、生成lstm文件
2.3、生成lstmf文件
2.4、生成lstmf清单文件
2.5、开始训练
2.6、生成traineddata文件
2.7、安装字体
3、验证与测试
4、提高准确率
5、提升训练效率
6、避坑指南
原文链接:http://www.juzicode.com/image-ocr-tesseract-ocr5-train
Tesseract除了可以使用官方提供的语言包(traineddata文件),还可以自己训练模型,特别适用于某些官方语言包识别效果不佳的场景下。我们今天就以手写数字mnist数据集为例,来看下Tesseract-OCR5.0如何训练自己的模型,以及如何提高准确率、提升训练效率。
1、准备工作
- 安装tesseract5.0版本,可以参考这里:Tesseract-OCR5.0软件安装和语言包安装(Windows系统)。
- 安装python3(从mnist文件生成训练用的tif和box文件,以及编写自动训练、测试脚本)。
- 从github仓下载traineddata_best类型的traineddata文件,可以选择eng.traineddata,用来初次训练字体;下载地址:https://github.com/tesseract-ocr/tessdata_best,下载后保存在当前工作目录下,另外拷贝一份到系统变量“TESSDATA_PREFIX”路径下,也即tesseract安装路径的tessdata\\文件夹下。
- mnist数据集文件,包含60000个训练图片和标签、10000个测试图片和标签;用来训练和测试;下载地址:http://yann.lecun.com/exdb/mnist/,下载的4个文件接下后保存在当前工作目录的mnist\\文件夹下。
- 在当前工作目录下新建一个out_mnist\\文件夹,用来存放所有输出的文件。
准备工作完成后当前工作目录下是这样的:
2、训练步骤
在讨论步骤前,先对一些配置作出约定:
- 输出文件都存放在out_mnist\\路径下;
- 中间文件的文件名一般使用LANG.FONT.EXPn.xxx的形式,其中设置LANG=arabnum,FONT=mnist,EXPn=exp0,这样tif文件名称为arabnum.mnist.exp0.tif,box文件为arabnum.mnist.exp0.box,以此类推。
2.1、生成训练用tif和box文件
首先生成训练用的tif图片,将60000个训练图片合成到一个tif文件里,直接从mnist训练图片文件中提取数据,合成tif图片,注意按照顺序提取,这样后面的标签文件也按照顺序提取,就可以做到一一对应。mnist文件的读取方法可以参考 mnist数据集的获取、访问、使用例子。
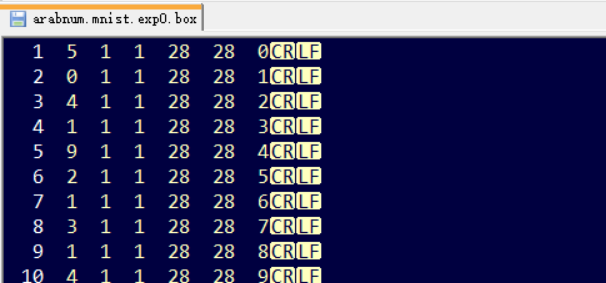
接着生成训练用的box文件,因为mnist数据集里面包含了标签数据,所以不需要自己使用工具来标注图片,这样描述图片的box文件就可以直接根据训练标签文件里的序号和标签值来生成。box文件里的一行数据由下列几个元素组成:
标签值 起始位置x坐标 起始作为y坐标 图片宽度 图片高度 在tif文件中的编号(从0开始编号)mnist的图片是28×28像素的,所以可以设置图片宽度为28,图片高度为28,起始点的坐标x和y都设置为1。标签值是从训练标签文件中按照顺序提取的标签值,最后一列数据从0开始编号即可,最后编号到59999,box文件是这个样子的:
2.2、生成lstm文件
从当前工作目录下的训练用traineddata文件中抽取lstm文件,这里用当前目录下的eng.traineddata文件生成eng.lstm文件:
combine_tessdata -e eng.traineddata out_mnist\\eng.lstm打印输出:
Extracting tessdata components from eng.traineddata
Wrote out_mnist\eng.lstm
Version string:4.00.00alpha:eng:synth20170629:[1,36,0,1Ct3,3,16Mp3,3Lfys64Lfx96Lrx96Lfx512O1c1]
17:lstm:size=11689099, offset=192
18:lstm-punc-dawg:size=4322, offset=11689291
19:lstm-word-dawg:size=3694794, offset=11693613
20:lstm-number-dawg:size=4738, offset=15388407
21:lstm-unicharset:size=6360, offset=15393145
22:lstm-recoder:size=1012, offset=15399505
23:version:size=80, offset=154005172.3、生成lstmf文件
这一步利用tif图片文件生成lstmf文件,如下命令会生成arabnum.mnist.exp0.lstmf文件,这个是典型tesseract命令:
tesseract out_mnist\arabnum.mnist.exp0.tif out_mnist\arabnum.mnist.exp0 -l eng --psm 13 lstm.train- out_mnist\arabnum.mnist.exp0.tif 输入图像
- out_mnist\arabnum.mnist.exp0 输出的lstmf文件名称
- -l eng 使用的字体,使用tesseract安装目录tessdata\\文件夹下的eng.traineddata
- –psm 13 分割模式
- lstm.train 配置文件,指明进行lstm训练,使用tesseract安装目录tessdata\\config文件夹下的配置文件
打印输出:
..........
Warning: Invalid resolution 1 dpi. Using 70 instead.
Loaded 6/6 lines (1-6) of document out_mnist\arabnum.mnist.exp0.lstmf
Page 8
Warning: Invalid resolution 1 dpi. Using 70 instead.
Loaded 7/7 lines (1-7) of document out_mnist\arabnum.mnist.exp0.lstmf
Page 9
Warning: Invalid resolution 1 dpi. Using 70 instead.
Loaded 8/8 lines (1-8) of document out_mnist\arabnum.mnist.exp0.lstmf
Page 10
Warning: Invalid resolution 1 dpi. Using 70 instead.
Loaded 9/9 lines (1-9) of document out_mnist\arabnum.mnist.exp0.lstmf
..........mnist的60000个训练图片,该步骤会耗时4-5小时。
2.4、生成lstmf清单文件
手动新建一个arabnum.mnist.exp0.list.txt文本文件,输入上一步骤生成的lstmf文件的路径和文件名,可以使用相对路径,输入“out_mnist\arabnum.mnist.exp0.lstmf”,文件内容是这个样子的:

2.5、开始训练
使用lstmtraining命令开始训练,这一步生成mod_out_checkpoint文件:
lstmtraining --debug_interval -5 --max_iterations 9000 --target_error_rate 0.01 --continue_from=out_mnist\eng.lstm --model_output=out_mnist\mod_out --train_listfile=out_mnist\arabnum.mnist.exp0.list.txt --traineddata=eng.traineddata - –debug_interval -5 调试打印等级
- –max_iterations 9000 最大迭代次数
- –target_error_rate 0.01 期望错误率
- –continue_from=out_mnist\eng.lstm 基于eng字体的lstm文件(步骤2.2)
- –model_output=out_mnist\mod_out 输出checkpoint文件的名称
- –train_listfile=out_mnist\arabnum.mnist.exp0.list.txt 训练清单文件名称(步骤2.3和2.4)
- –traineddata=eng.traineddata 训练使用的字体,当前工作目录下
输出打印:
Loaded file out_mnist\eng.lstm, unpacking...
Warning: LSTMTrainer deserialized an LSTMRecognizer!
Continuing from out_mnist\eng.lstm
Loaded 10/10 lines (1-10) of document out_mnist\arabnum.mnist.exp0.lstmf
Iteration 0: GROUND TRUTH : 2
Iteration 0: ALIGNED TRUTH : 22
Iteration 0: BEST OCR TEXT : ps
File out_mnist\arabnum.mnist.exp0.lstmf line 5 :
Mean rms=4.213%, delta=16.667%, train=300%(100%), skip ratio=0%
Iteration 1: GROUND TRUTH : 5
Iteration 1: ALIGNED TRUTH : 55
Iteration 1: BEST OCR TEXT : by
File out_mnist\arabnum.mnist.exp0.lstmf line 0 :
Mean rms=4.146%, delta=16.667%, train=300%(100%), skip ratio=0%
..........
..........
Mean rms=0.015%, delta=0%, train=0%(0%), skip ratio=0%
Iteration 2299: GROUND TRUTH : 4
File out_mnist\arabnum.mnist.exp0.lstmf line 9 (Perfect):
Mean rms=0.015%, delta=0%, train=0%(0%), skip ratio=0%
2 Percent improvement time=2, best error was 10.3 @ 60
At iteration 62/2300/2300, Mean rms=0.015000%, delta=0.000000%, char train=0.000000%, word train=0.000000%, skip ratio=0.000000%, New best char error = 0.000000 wrote best model:out_mnist\mod_out_0.000000_62_2300.checkpoint wrote checkpoint.
Finished! Error rate = 02.6、生成traineddata文件
这一步生成mnist.traineddata文件:
lstmtraining --stop_training --traineddata=eng.traineddata --continue_from=out_mnist\mod_out_checkpoint --model_output=mnist.traineddata - –stop_training 停止训练
- –traineddata=eng.traineddata 训练使用的字体,当前工作目录下
- –continue_from=out_mnist\mod_out_checkpoint 中间文件名称(步骤2.5)
- –model_output=mnist.traineddata 生成字体文件的traineddata文件名称
输出打印:
Loaded file out_mnist\mod_out_checkpoint, unpacking...2.7、安装字体
最后将生成的mnist.traineddata文件拷贝到tesseract安装目录的tessdata\\路径下,即完成字体的安装。
3、验证与测试
接下来就是利用tesseract命令行或者pytesseract对测试集的图片进行识别,然后和测试集标签比对识别是否正确并统计其准确率,可以用python实现自动测试和比对,核心代码如下:
right_count=0
with open(test_image_file,'rb') as pf_image, open(test_label_file,'rb') as pf_label:
for __ind in range(sample_count):
ind = __ind + offset
img = mnist.read_image_p(pf_image, image_head_len, ind)
label= mnist.read_label_p(pf_label, label_head_len, ind)
text = ts.image_to_string(img,lang,config=config).strip('\x0c').strip('\n')
logger.info('ind:%d, label:%d, text:%s',ind,label,str(bytes(text,encoding='utf8')))
if text == str(label):
right_count += 1打开test_image_file表示的测试图片文件和test_label_file表示的测试标签文件,每次读出1张图片和1个标签,读出的图片传入到pytesseract的image_to_string()进行识别,然后将结果和读出的标签数据进行比对,如果结果一样就将right_count的数值加1,最后统计出准确率。
因为tesseract有13种分割模式,为了减少测试时间,这里先用小样本数据1000个图片对不同的分割模式进行了实验:
('--psm 0', 'exception')
('--psm 1', '0', '0.0')
('--psm 2', 'exception')
('--psm 3', '0', '0.0')
('--psm 4', '2', '0.002')
('--psm 5', '107', '0.107')
('--psm 6', '879', '0.879')
('--psm 7', '890', '0.89')
('--psm 8', '927', '0.927')
('--psm 9', '912', '0.912')
('--psm 10', '890', '0.89')
('--psm 11', '3', '0.003')
('--psm 12', '2', '0.002')
('--psm 13', '932', '0.932')其中psm=0和2时发生异常识别错误,psm=1,3,4,5,11,12的准确率或者为0,或者只有0.1,惨不忍睹,psm=6,7,10正确率不到0.9,psm=8,9,13时的准确率稍高在0.91-0.93。
接下来在3种准确率较高的psm=8,9,13分割模式下,用所有的10000个图片进行测试:
config=--psm 13 right_count=9445 right_ratio=0.944500
config=--psm 9 right_count=9261 right_ratio=0.926100
config=--psm 8 right_count=9422 right_ratio=0.942200最高的模式仍然是psm=13时,正确率为0.9445,这个准确率还有很大的提升空间的。
4、提高准确率
从前面的训练步骤可以看到,开始训练时需要用到一个已经存在的字体eng.traineddata,比如第2.2步抽取它的lstm文件、第2.5步的训练等。既然这个原始字体训练出来的新字体识别的准确率不高,很可能跟选择的这个初始字体有关,那是不是可以用我们训练好的新字体替代eng.traineddata再训练一次呢,这样产生的第2代的新字体是不是可以有更好地表现?如此迭代多次之后,得到第3代、第4代、第5代字体呢?
回到步骤2.1步~步骤2.7,将eng.traineddata相关的内容替换为mnist.traineddata,新生成的第2代字体取名为mnist2nd,依次替代命令行里面的参数训练第2代字体,类似的方法再训练出第3、第4、第5代字体,将每一代字体都用测试集进行测试,得到了下面的测试结果:
mnist1st 13 9445 0.944500
mnist1st 8 9422 0.942200
mnist1st 9 9261 0.926100
mnist2nd 13 9707 0.970700
mnist2nd 8 9685 0.968500
mnist2nd 9 9493 0.949300
mnist3rd 13 9733 0.973300
mnist3rd 8 9710 0.971000
mnist3rd 9 9527 0.952700
mnist4th 13 9682 0.968200
mnist4th 8 9659 0.965900
mnist4th 9 9471 0.947100
mnist5th 13 9743 0.974300
mnist5th 8 9720 0.972000
mnist5th 9 9494 0.949400画出来的曲线图是这样的:
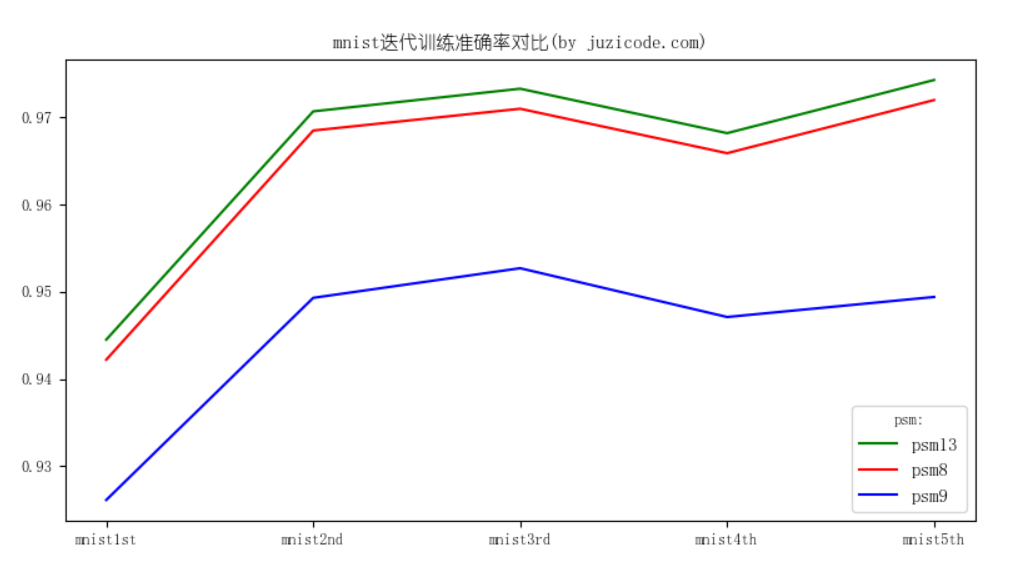
从这里可以看到,第2代字体较第1代有明显提升,绿色代表的psm=13,提升了近3个百分点,达到0.973300,再往后第3代稍有提升,第4代反而下降了一点点,到了第5代又升到0.9743。
桔子菌用单步方式没有再往后测试了,因为训练到第5代字体断断续续用了快2天的时间,接下来有必要提升下训练的效率了。
5、提升训练效率
要提升训练的效率先要找到最耗时的步骤:其中步骤2.3提取lstmf文件耗时最长,桔子菌的电脑耗时4-5小时,其他的步骤都比较少,多的才10分钟左右。找到了阻塞点,接下来就是如何提高效率。在步骤2.3中可以将样本进行拆分,比如将60000个样本分成10组,每组6000条数据丢到一个线程里去提取lstmf文件,理论上会降低到原来的1/10右。经过实际测试,拆分lstmf文件后,单代字体的训练在步骤2.3上只用了15-20分钟左右,最后训练出20代字体耗时9小时左右。
测试环节为了对比每代的准确率,需要将每一代生成的字体对所有样本进行测试,所以可以通过拆分样本和拆分字体的方法,丢到多个线程里去执行。桔子菌用psm13的方式测试完20代字体耗时6小时左右,最后得到的准确率是这样的:
lang=mnist0–config=–psm13–right_count=9521–right_ratio=0.952100
lang=mnist1–config=–psm13–right_count=9471–right_ratio=0.947100
lang=mnist2–config=–psm13–right_count=9779–right_ratio=0.977900
lang=mnist3–config=–psm13–right_count=9762–right_ratio=0.976200
lang=mnist4–config=–psm13–right_count=9797–right_ratio=0.979700
lang=mnist5–config=–psm13–right_count=9755–right_ratio=0.975500
lang=mnist6–config=–psm13–right_count=9836–right_ratio=0.983600
lang=mnist7–config=–psm13–right_count=9843–right_ratio=0.984300
lang=mnist8–config=–psm13–right_count=9817–right_ratio=0.981700
lang=mnist9–config=–psm13–right_count=9845–right_ratio=0.984500
lang=mnist10–config=–psm13–right_count=9836–right_ratio=0.983600
lang=mnist11–config=–psm13–right_count=9832–right_ratio=0.983200
lang=mnist12–config=–psm13–right_count=9778–right_ratio=0.977800
lang=mnist13–config=–psm13–right_count=9832–right_ratio=0.983200
lang=mnist14–config=–psm13–right_count=9862–right_ratio=0.986200
lang=mnist15–config=–psm13–right_count=9831–right_ratio=0.983100
lang=mnist16–config=–psm13–right_count=9848–right_ratio=0.984800
lang=mnist17–config=–psm13–right_count=9842–right_ratio=0.984200
lang=mnist18–config=–psm13–right_count=9859–right_ratio=0.985900
lang=mnist19–config=–psm13–right_count=9882–right_ratio=0.988200
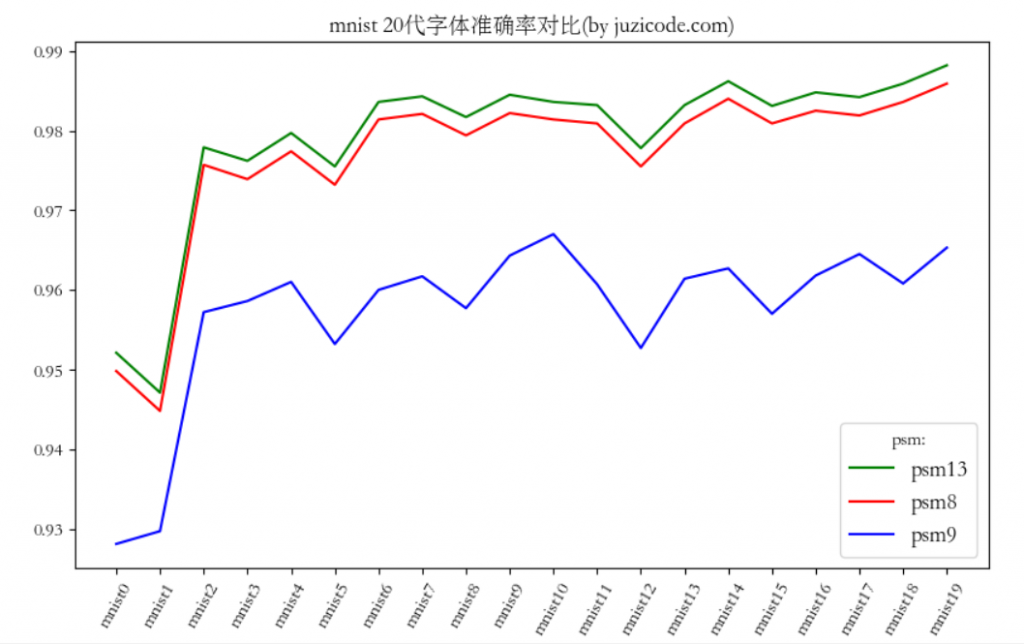
从最终的测试结果看,第3-6代较第1-2代提升了3个百分点,这点和前面单步训练看到的效果差不多,到了第7代(mnist6)之后提升效果非常缓慢了,最好的情况是在pms=13、第20代字体时,准确确率为0.988200。
如果你想试试更多的迭代次数,获取更好的训练效果,桔子菌已经将数据集、训练脚本、测试脚本都打包好了,可以戳这里获取:tesseract训练mnist-by-juzicode.com-vx桔子code
6、避坑指南
1、注意Tesseract 4.0和5.0版本的训练方式和3.0相差甚远,3.0方式的训练不再适用4.0和5.0的LSTM训练。
2、生成tif文件时用训练集的单张图片作为tif图片的一页即可,这样box文件也更简单。
3、步骤2.2生成eng.lstm文件时,选用的初始traineddata文件必须是从traindata_best中下载的文件,否则会报错out_mnist\eng.lstm is an integer (fast) model, cannot continue training:
Loaded file out_mnist\eng.lstm, unpacking...
Warning: LSTMTrainer deserialized an LSTMRecognizer!
Error, out_mnist\eng.lstm is an integer (fast) model, cannot continue training
Failed to continue from: out_mnist\eng.lstm4、步骤2.4生成文件清单arabnum.mnist.exp0.list.txt时,如果文件内容像下面这样有多余的换行符\r(CR):
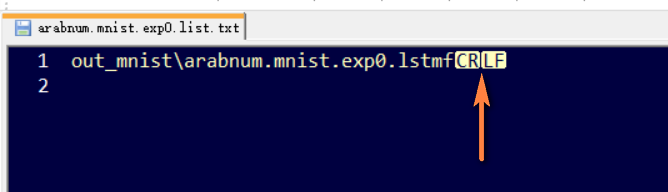
在步骤2.5则会报错Load of page 0 failed:
Loaded file out_mnist\eng.lstm, unpacking...
Warning: LSTMTrainer deserialized an LSTMRecognizer!
Continuing from out_mnist\eng.lstm
Deserialize header failed: out_mnist\arabnum.mnist.exp0.lstmf
Load of page 0 failed!
Load of images failed!!最简单的解决办法是去掉2个换行符\r\n(CR LF)。
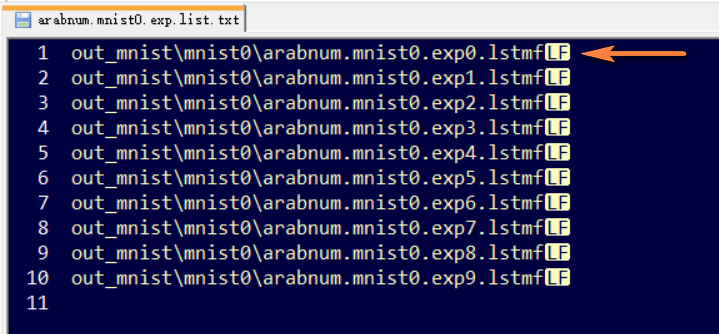
当使用多个lstmf文件训练时,每个文件名之间必须要保留一个换行符,则必须去掉\r(CR)符号,只保留\n(LF),如下图所示:
推荐阅读:
有了这个方法群聊斗图你就不会输了
pytesseract提取识别图片中的文字
Tesseract-OCR5.0软件安装和语言包安装(Windows系统)
新鲜上架的Python3.10,来个match-case尝尝鲜
你别耍我,0.1+0.2居然不等于0.3?
有了这款神器,什么吃灰文件都统统现形
一行代码深度定制你的专属二维码(amzqr)
桔子菌和超市老板田大爷的一次角色互换经历