文章目录
- 前言
- 一、二叉树的顺序结构
- 二、堆的概念及结构
- 三、堆的实现
- 1.向下调整算法
- 2.堆的创建
- 四、堆的整体代码
- 五、建堆的时间复杂度
- 六、堆排序以及top-k问题
- 1.堆排序
- 2.TOP-K问题
- 总结
前言
之前我们已经了解过了树和二叉树的基本结构和概念,同时也了解了二叉树的存储结构有顺序结构和链式结构,如果还没有了解过请转到-》点击我了解树和二叉树的基本结构和概念
这次我们就学习一下二叉树的顺序结构—堆和堆排序以及TOP-K问题
一、二叉树的顺序结构
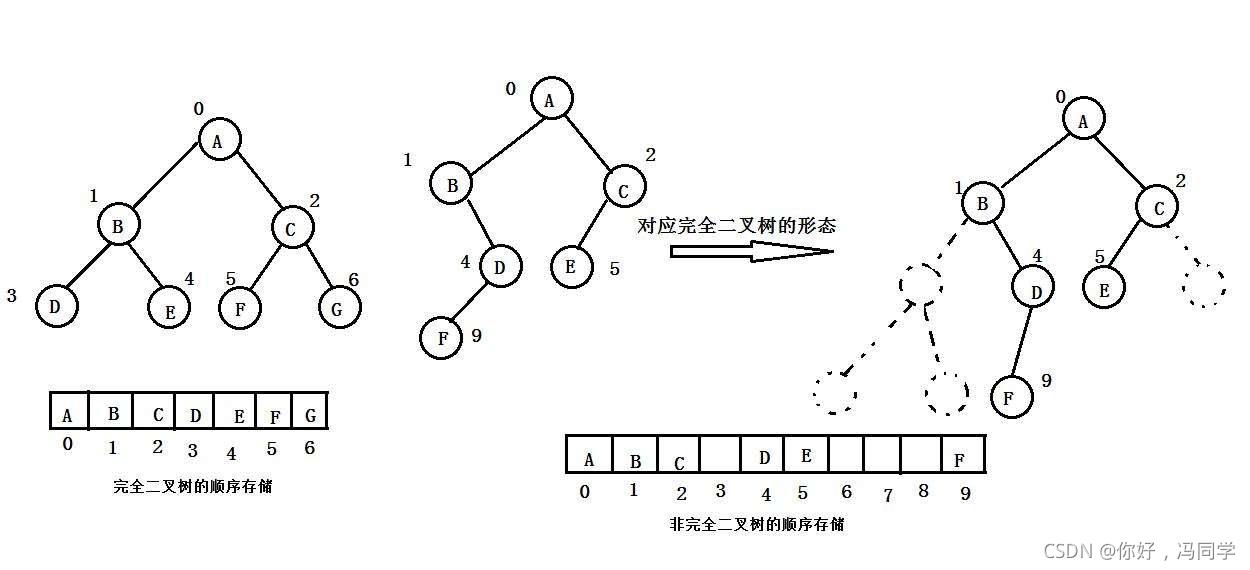
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。
现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
二、堆的概念及结构
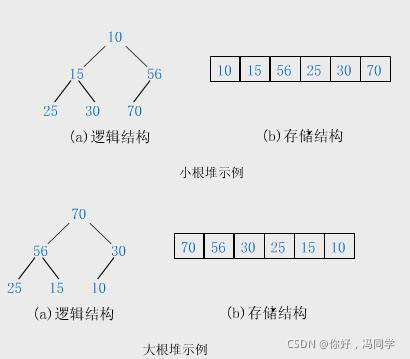
如果有一个关键码的集合K = { k0,k1 ,k2 ,…,kn-1 },把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足:Ki <= K 2i+1且Ki <= K 2i+1 ( K i >= K 2i+1且 K i >= K 2i+2) i = 0,1,2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
三、堆的实现
1.向下调整算法
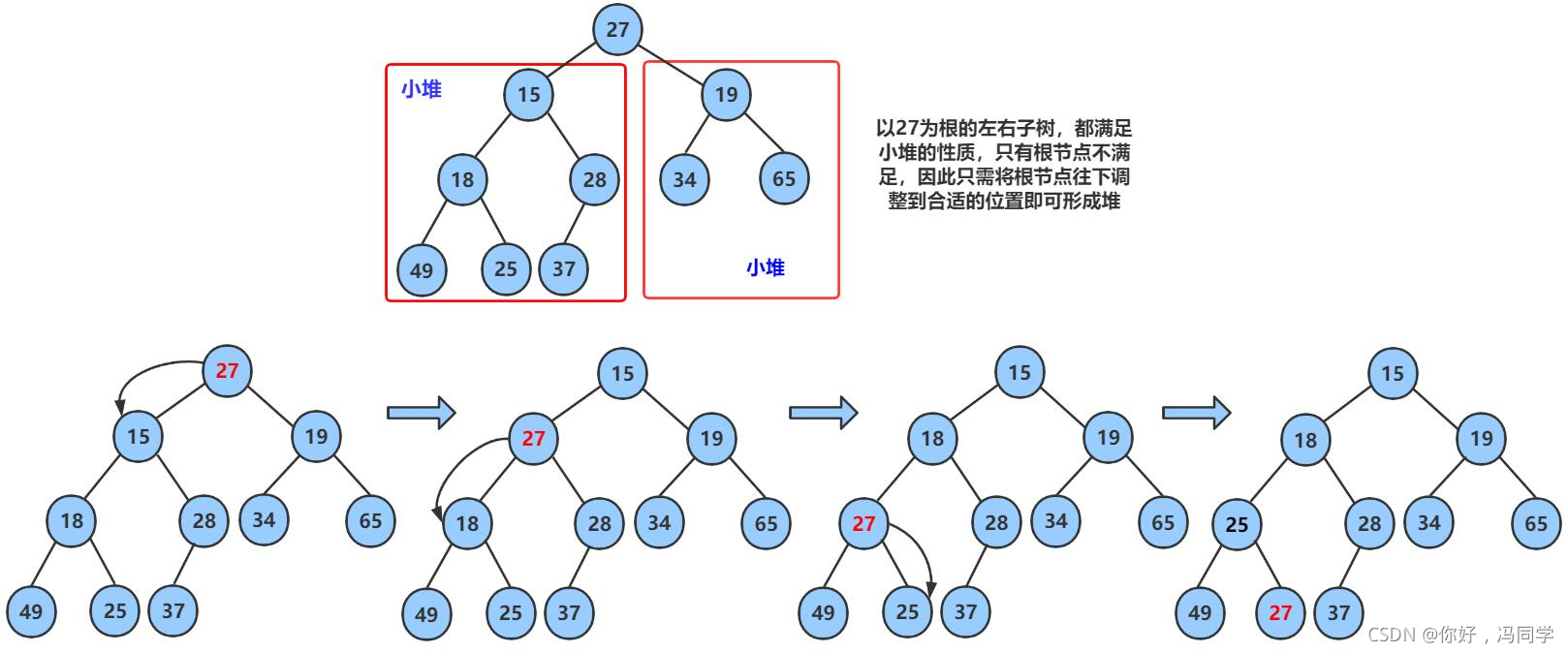
现在我们给出一个数组,逻辑上看做一颗完全二叉树。我们通过从根节点开始的向下调整算法可以把它调整成一个小堆。向下调整算法有一个前提:左右子树必须是一个堆,才能调整。
假设有这么一个数组:int array[] = {27,15,19,18,28,34,65,49,25,37},我需要把这个数组建成小堆,因为对于27(array[0])来说,它的左右子树的都是小堆,所以只需要将27向下调整即可
代码如下:
//向下调整
void AdjustDown(HPDataType* a, int n, int parent)
{
int child = parent * 2 + 1;//默认左孩子小于右孩子
while (child < n)
{
if (child + 1 < n && a[child + 1] < a[child])//右孩子小于左孩子就换一下
{
child++;
}
if (a[child] < a[parent])
{
swap(&a[parent], &a[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
代码测试:
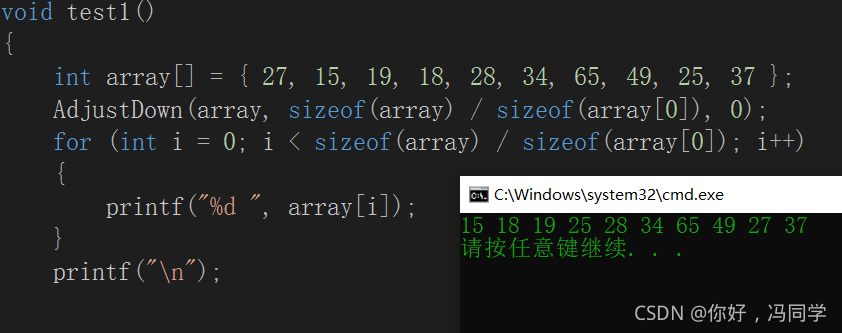
向下调整算法简单的来说,就是父亲结点和它左右孩子中较小(大)的一个给一个父节点交换位置,如果不满足父亲结点比孩子结点小(大),就结束调整,此时就将父结点为根结点的这棵树调成了小(大)堆。
通过父节点的下标,找到它孩子的下标,但是我们默认左孩子为最小(最大),只需要和右孩子比较一下就可以知道谁最大,再将它们中值大的下标赋给child。(物理结构是数组,但是逻辑结构是一棵完全二叉树)
2.堆的创建
上面我们说到,如果对一个数组要建(大小)堆,前提是对于数组的每个元素都满足它的左右子树都是(大小)堆。但是此时,我们给出一个数组,例如:int a[] = {1,5,3,8,7,6},我们需要将它建为一个大堆
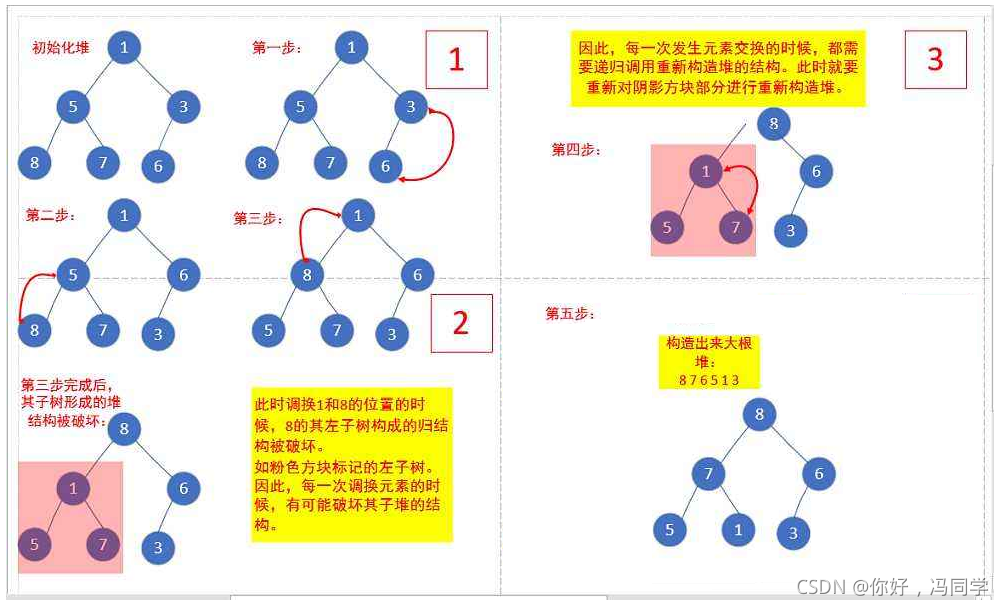
但是通过画图我们发现1、5、3的左右子树都不是大堆,那我们该如何调整呢?首先我们需要知道对于只有一个结点的树(物理结构还是一个数组),我们既可以把它看成大堆,也可以把它看成小堆,因为这个结点的左右子树都是空。其次我们再来观察这个图,可以把8、7、6当成一个大堆,但是3、5、1还不是,所以我们可以将3-6这颗子树调整为大堆,再将5-8-7这颗子树调整为大堆。最后,对于1来说,它的左右子树都是大堆,只需要调整它自己即可
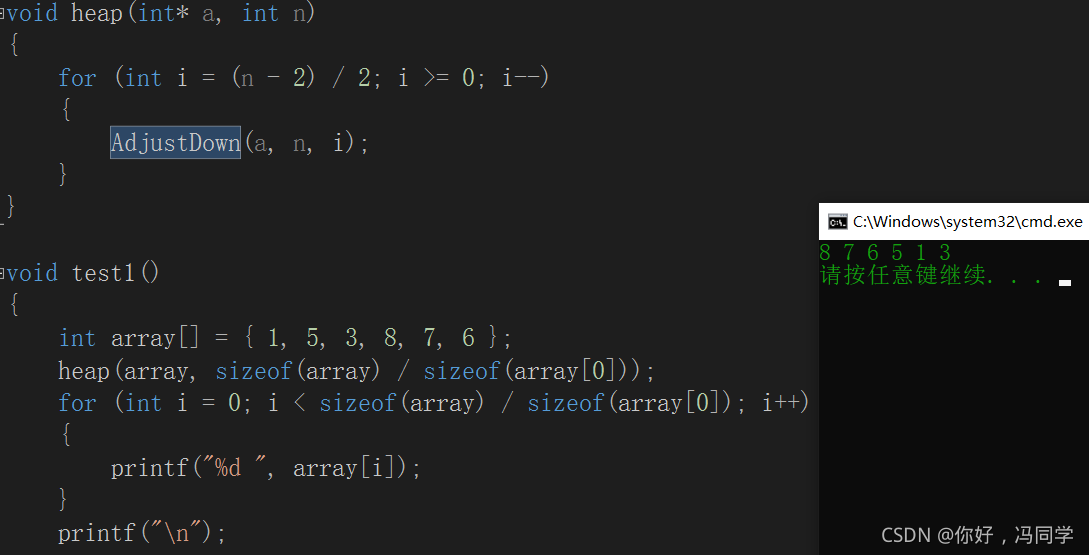
void heap(int* a, int n)
{
for (int i = (n - 2) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);//从倒数第一个非叶子结点开始调整
}
}
代码测试:
四、堆的整体代码
//打印堆中的数据
void HeapPrint(Heap* hp)
{
for (int i = 0; i < hp->size; i++)
{
printf("%d ", hp->a[i]);
}
printf("\n");
}
//交换堆中的两个数据
void swap(HPDataType* a, HPDataType* b)
{
HPDataType tmp = *a;
*a = *b;
*b = tmp;
}
//向上调整
void AdjustUp(HPDataType* a, int child)
{
assert(a);
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])
{
swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//向下调整
void AdjustDown(HPDataType* a, int n, int parent)
{
int child = parent * 2 + 1;//默认左孩子小于右孩子
while (child < n)
{
if (child + 1 < n && a[child + 1] < a[child])//右孩子小于左孩子就换一下
{
child++;
}
if (a[child] < a[parent])
{
swap(&a[parent], &a[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
// 堆的构建
void HeapInit(Heap* hp)
{
assert(hp);
hp->a = NULL;
hp->capacity = hp->size = 0;
}
// 堆的销毁
void HeapDestory(Heap* hp)
{
assert(hp);
free(hp->a);
hp->a = NULL;
hp->capacity = hp->size = 0;
}
// 堆的插入
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
if (hp->capacity == hp->size)
{
int newcapacity = hp->capacity == 0 ? 4 : hp->capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(hp->a, sizeof(HPDataType)*newcapacity);
if (tmp == NULL)
{
printf("realloc fail\n");
}
hp->a = tmp;
hp->capacity = newcapacity;
}
hp->a[hp->size] = x;
hp->size++;
AdjustUp(hp->a, hp->size - 1);
}
// 堆顶数据的删除
void HeapPop(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
swap(&hp->a[0], &hp->a[hp->size - 1]);
hp->size--;
AdjustDown(hp->a, hp->size, 0);
}
// 取堆顶的数据
HPDataType HeapTop(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
return hp->a[0];
}
// 堆的数据个数
int HeapSize(Heap* hp)
{
assert(hp);
return hp->size;
}
// 堆的判空
bool HeapEmpty(Heap* hp)
{
assert(hp);
return hp->size == 0;
}
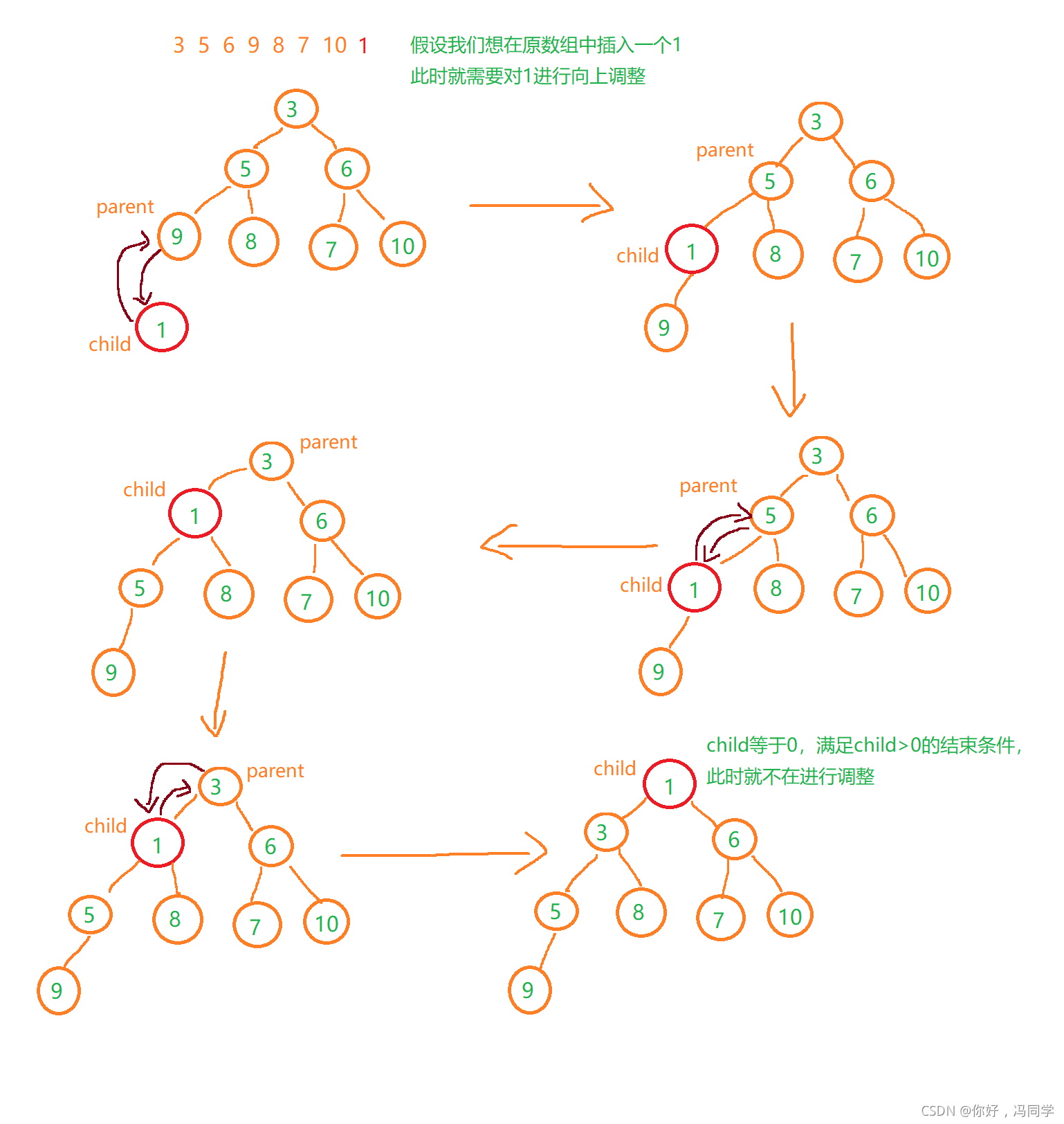
我们发现在插入数据时,我们使用的是向上调整,而不是向下调整。因为我们是在数组尾插入数据,对于这个数本身,它已经是小(大)堆了,所以只需要对和它上面的数(它到根节点(下标为0)的这条路径上所有的结点)进行比较
请看图:
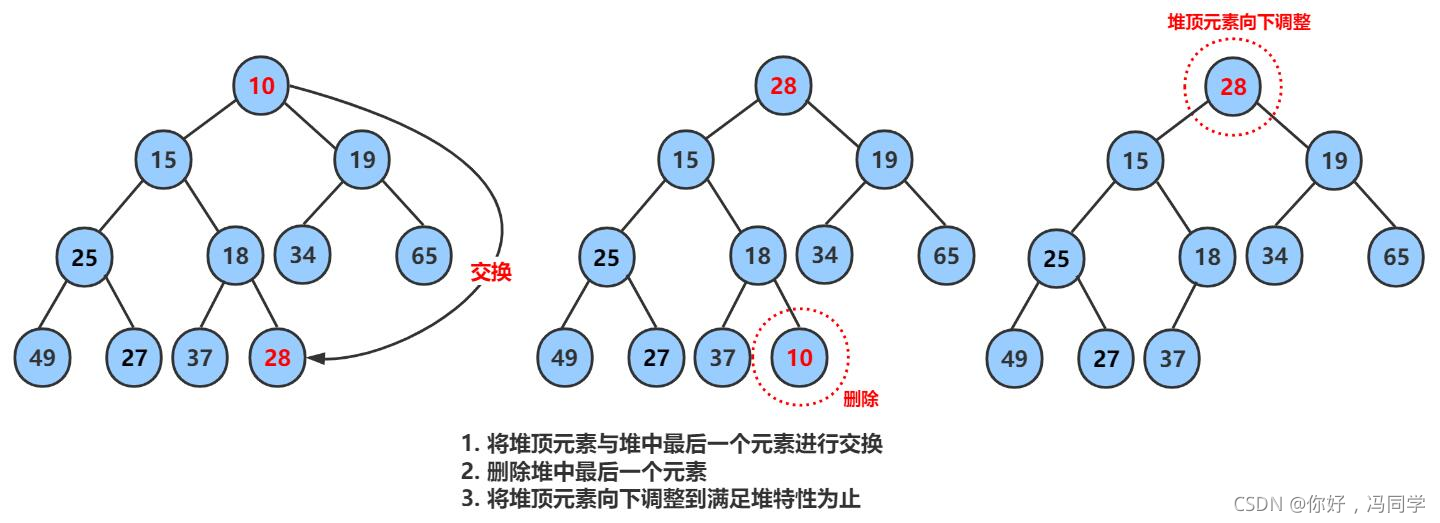
堆的删除
删除堆是删除堆顶的数据,将堆顶的数据根最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法。
五、建堆的时间复杂度
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果):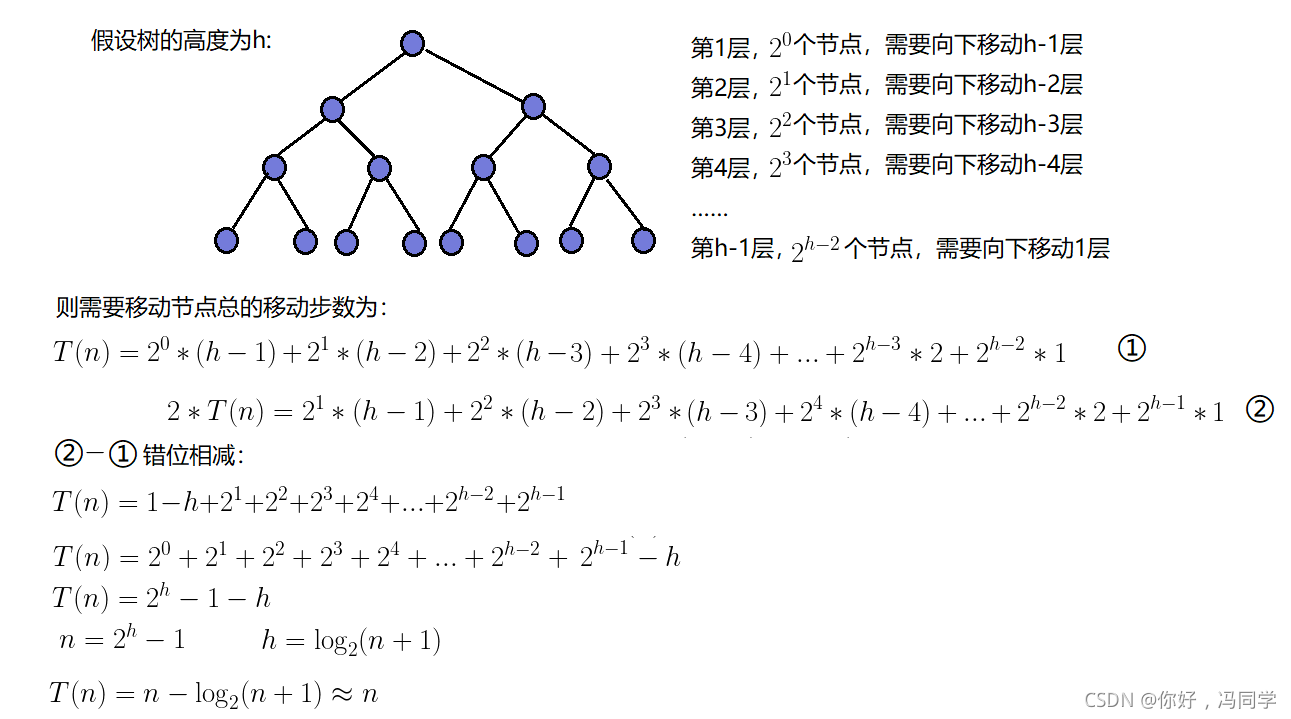
六、堆排序以及top-k问题
1.堆排序
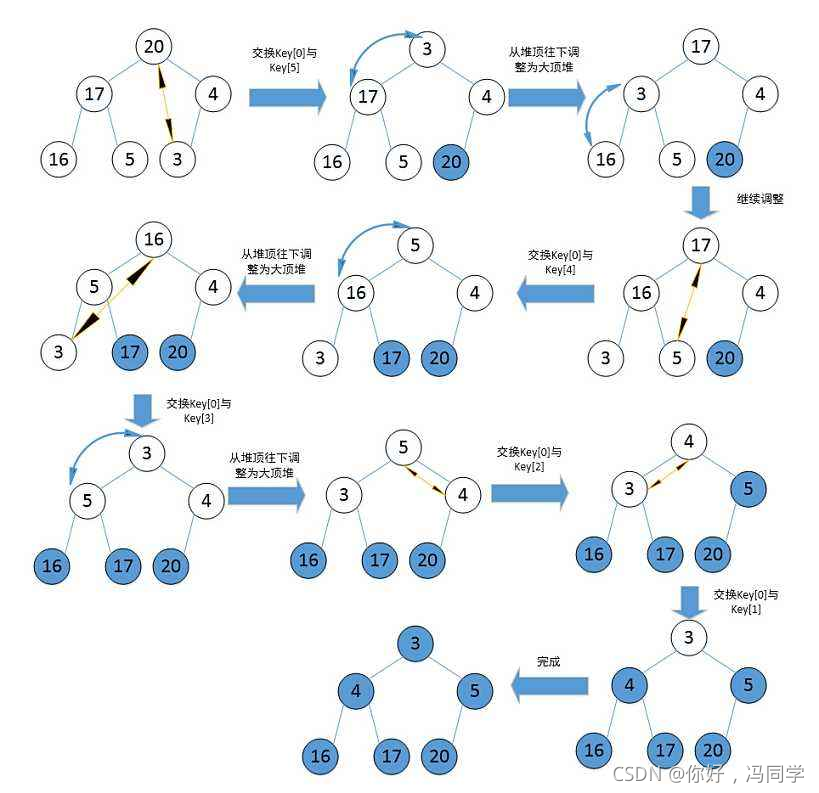
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
1.建堆
- 升序:建大堆
- 降序:建小堆
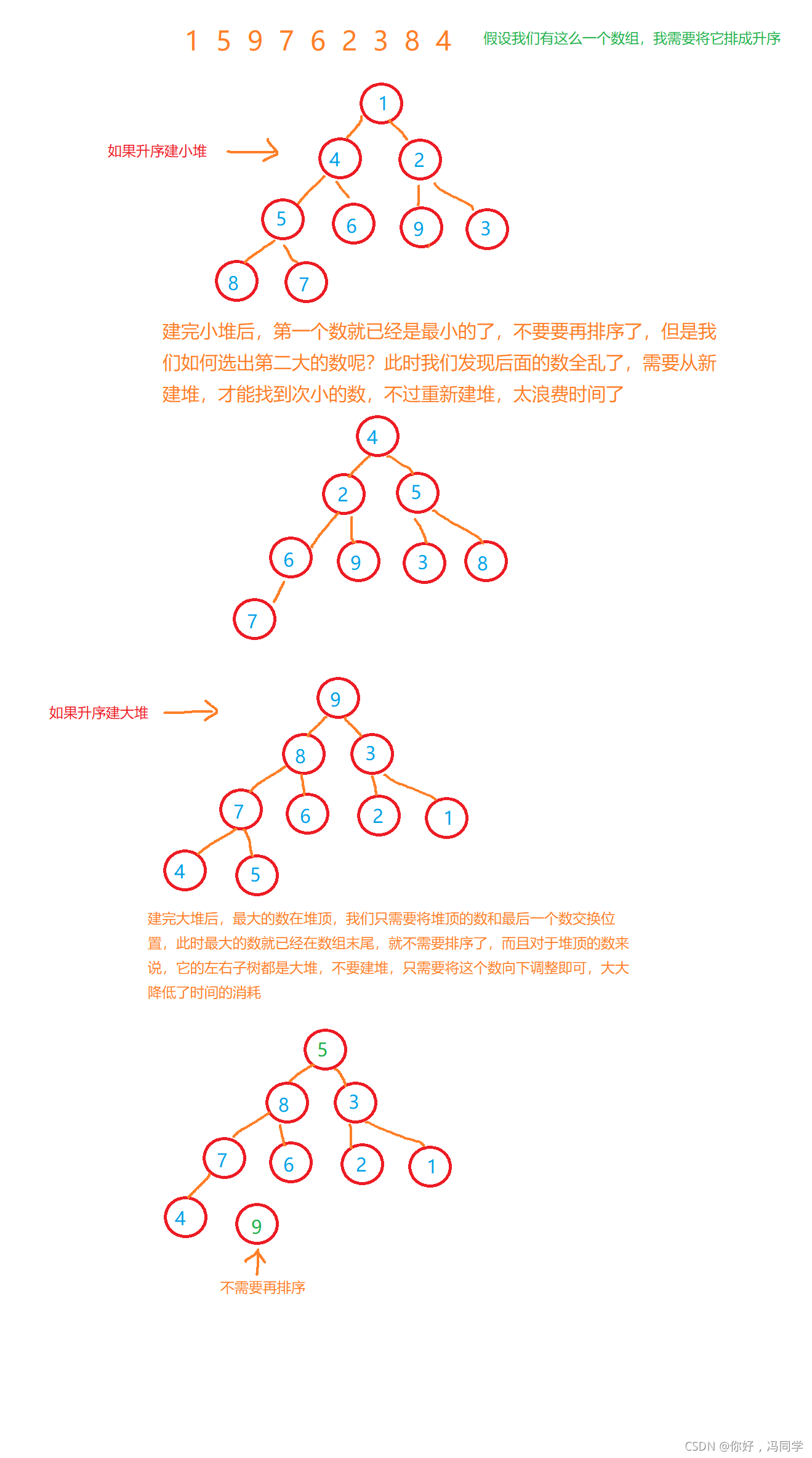
2.利用堆删除思想来进行排序
建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
void AdjustDown(int* a, int n, int root)//升序建大堆,降序建小堆,建堆的时间复杂度O(N)
{
int parent = root;
int child = parent * 2 + 1;//默认是左孩子
while (child < n)
{
if (child + 1 < n && a[child] < a[child + 1])
{
child += 1;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else{
break;
}
}
}
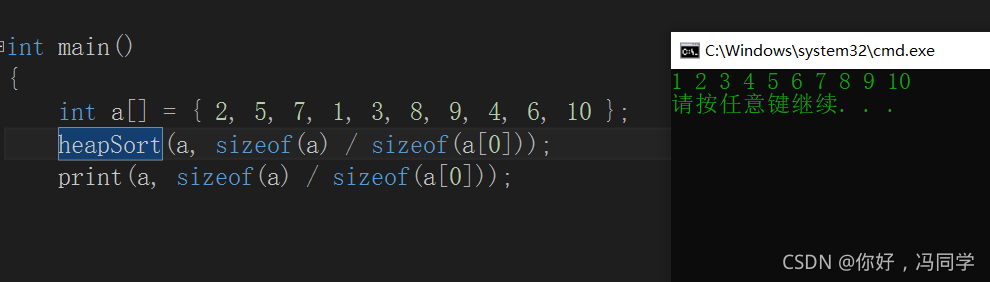
void heapSort(int* a, int n)
{
for (int i = (n - 2) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}
代码测试:
2.TOP-K问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
1. 用数据集合中前K个元素来建堆
- 找最大的前K个,建立K个数的小堆
- 找最小的前K个,建立K个数的大堆
为什么找最大的前K个,建立K个数的小堆?
因为小堆的堆顶是最小的,如果剩余的数中有比这个数大的,那么它就需要将堆顶替换掉,再进行向下调整,新堆的堆顶又是最小的,一直和剩余中的数比较,直到比完,最终整个堆的数就是我们要找的前K个最大的数。同理:找最小的前K个,建立K个数的大堆
void PrintTopK(int* a, int n, int k)
{
int* tmp = (int*)malloc(sizeof(int)* k);
for (int i = 0; i < k; i++)
{
tmp[i] = a[i];
AdjustUp(tmp, i);
}
for (int i = 0; i < 10000; i++)
{
if (a[i] > tmp[0])
{
tmp[0] = a[i];
AdjustDown(tmp, k, 0);
}
}
for (int i = 0; i < k; i++)
{
printf("%d ", tmp[i]);
}
printf("\n");
}
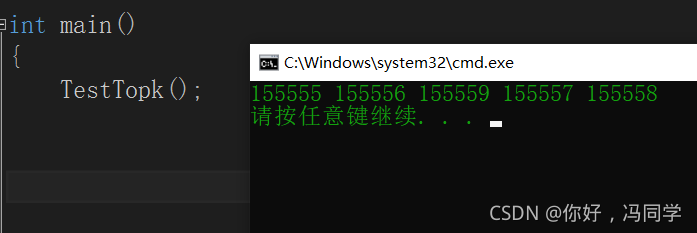
void TestTopk()
{
int* a = (int*)malloc(sizeof(int)* 10000);
for (int i = 0; i < 10000; i++)
{
a[i] = rand() % 10000;
}
a[10] = 155555;
a[45] = 155556;
a[695] = 155557;
a[157] = 155558;
a[4598] = 155559;
PrintTopK(a, 10000, 5);
}
这里我们随机出10000个数,但每个数的大小不超过9999,但我们将数组中的其中5个数改为大于9999的数(分别是155555,155556,155557,155558,155559)。
最终我们将找出数组中5个最大的数,也就是修改的这几个。
测试:
总结
这次我们学习了堆(二叉树的顺序结构)——物理结构是数组,逻辑结构是完全二叉树,也学习了堆的应用,例如:堆排序,TOP-K问题。我们知道了,对于不同的排序,我们需要建什么堆,求数据中前K个最小(最大)的数,我们又该怎么办。后面我们也将学习二叉树的链式结构以及其它的数据结构。