目录
一,摘要
二、更新
边界框预测
类别预测
跨尺寸预测
特征提取器
(新的网络:Darknet-53)
三、失败的尝试
一,摘要
作者在原YOLO的基础上对网络进行了调整,使得模型更大但是精准度更高(尤其是对小物体的检测能力),速度也依然很快。
二、更新
训练了一个新的分类器网络。
边界框预测
使用 维度聚类(dimension cluster) 固定锚框(anchor boxes)来选择边界框。
神经网络为每个边界框预测4个坐标(tx,ty,tw,th),如果目标cell距图像左上角的边距为(cx,cy),对应边界框的高和宽为(pw,ph),那么网络预测值可表示如下:
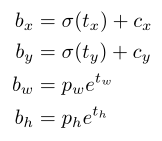
通过sigmoid函数进行中心坐标预测,强制将值限制在0和1之间。YOLO不是预测边界框中心的绝对坐标,它预测的是偏移量:相对于预测对象的网格单元的左上角;通过特征图cell归一化维度。
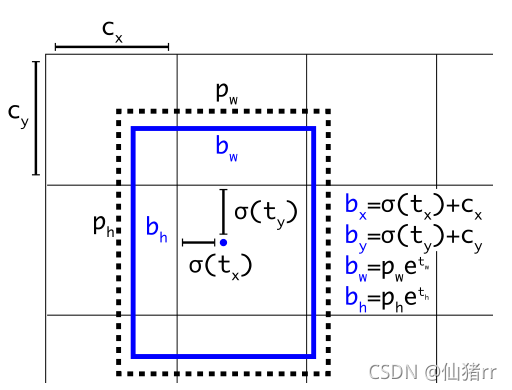
YOLOv3 使用逻辑回归预测每个边界框的对象分(objectness score)。如果当前预测的边界框比之前其他的任何边界框更好的与 ground truth 对象重合,那它的分数就是 1。如果当前预测的边界框不是最好的,但它和 ground truth 对象重合了一定的阈值以上,神经网络会忽略这个预测。我们使用的阈值是 0.5。我们的系统只为每个 ground truth 对象分配一个边界框。如果当前的边界框未分配给相应的 ground truth 对象,那它仅仅是检测错了对象,不会对坐标或分类预测造成影响。
类别预测
YOLO v3采用多标签分类方法,每个边界框预测可能包含多个类。在训练过程中,使用二元交叉熵损失来进行类别预测。
类置信度表示检测到的物体属于一个具体类的概率值,物体分数也通过一个sigmoid函数,表示概率值。
不使用softmax,因为预测的每个框只包含一个类,然而一些数据集的包含大量重叠标签(如人和女人)。多标签分类使得YOLO v3可用于更复杂的领域,如图像数据集。
跨尺寸预测
为了识别更多的物体,尤其小物体,YOLOv3使用三个不同尺度进行预测,三个不同尺度步幅分别是32、16和8。(输入416 × 416的图像,检测尺度分别为13 × 13、26 × 26、52 × 52)每个尺度分别预测三个边界框,使用 k-means 聚类来确定边界框的先验,三个尺寸对应九个聚类,这九个先验框在COCO数据集上分别是:

网络降采样输入图像,一直到第一个检测层,步幅是32;然后,将此层上采样2倍与之前同样大小的特征图进行按通道堆叠(concatenation ) ,第二个检测层步幅16;使用相同的上采样过程到检测层步幅为8(见下图)。


这种方法使我们能够从早期特征映射中的上采样特征和更细粒度的信息中获得更有意义的语义信息。
在基本特征提取器中增加了几个卷积层,并用最后的卷积层预测一个三维张量:边界框、框中目标、分类预测。以COCO数据集为例,所得的张量为N × N × [3∗(4+1+80)](N × N为输出特征图的格点数,3个锚框,4个边界框偏移值,1个目标预测,80种分类预测)。
特征提取器
(新的网络:Darknet-53)
使用一个新的网络(Darknet-53)进行特征提取。该网络融合了YOLO v2、Darknet-19和残差网络,由连续的3×3和1×1的卷积层组合而成,使用了一些残差块,加深网络层数,引入Resnet中的跨层加和操作(输入特征图和输出特征图对应维度相加,concat操作指特征图按通道维度拼接),使网络变得更大,一共53个卷积层,在保持速度的同时,有效地提高了检测的精度。


YOLO v3只有卷积层,调整卷积步长控制输出特征图的尺寸(使得输入不受特别限制)。小尺寸特征图检测大尺寸物体,大尺寸特征图检测小尺寸物体,形成金字塔结构。
上采样:作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将8*8的图像变换为16*16。上采样层不改变特征图的通道数。
三、失败的尝试
Anchor box 坐标的偏移预测。尝试常规的 Anchor box 预测方法,比如使用线性激活来将坐标 x,y 的偏移预测为边界框宽度或高度的倍数。这种做法降低了模型的稳定性而且效果不佳。
用线性方法预测 x,y,而不是使用逻辑方法预测。尝试使用线性激活来直接预测 x,y 的偏移,而不是使用逻辑激活,这降低了 mAP 成绩。
Focal loss。尝试使用 focal loss,但它使 mAP 大概降低了 2 个点。这可能是因为它具有单独的对象预测和条件类别预测,YOLOv3 对于 focal loss 函数试图解决的问题已经具有相当的鲁棒性。
双 IOU 阈值和真值分配。在训练期间,Faster RCNN 用了两个 IOU 阈值,如果预测的边框与标注边框的重合度不低于 0.7 ,那判定它为正样本;如果在 [0.3~0.7] 之间,则忽略;如果低于 0.3 ,就判定它为负样本。但是这种方法效果并不好。
论文原文:https://arxiv.org/abs/1804.02767
参考:https://zhuanlan.zhihu.com/p/83218931
参考:https://www.jianshu.com/p/043966013dde
参考:https://zhuanlan.zhihu.com/p/76802514
PS:小白初学,欢迎大家指正