今年的金九银十,我和大多数的同行一样加入了升职涨薪的潮水,我早在2个月前就开始准备,我觉得自己在技术方面完全没有问题,于是这两个月我每天在公司摸鱼2小时,回家刷2小时,前前后后刷了几千到面试题,Leetcode也刷了100多道!
说实话我在去面试腾讯的时候我一点都不紧张,甚至有点开心,毕竟自己马上就要实现大厂梦了,甚至已经把租房选好了!
前两面都没什么问题,第三面的时候我和往常一样信心满满地去面试,这两天已经在幻想自己去工作第一天怎么做自我介绍了,可惜我大意了,没有闪。面试官问了我一个难度偏高的高并发系统设计实战题:
面对海量数据的计数器要如何做?
我:“???阿巴阿巴阿巴阿巴”
面试官:“好的,我没什么问题了,如果有问题也不会到我这里”
面试结束。
等了一个月都没有等来第四面的通知,我也没有去面试别的互联网企业,毕竟当时都觉得自己比过了,有几家还算可以的企业面试我都推掉了,只能是在现在这家公司继续干几个月(但是因为面试请假比较多,公司也看出来了,一直在打压我,相当的煎熬),熬到今年的金三银四再冲一次腾讯,誓要吊打面试官!
于是我找到了我无所不能的学长,问问他当初是如何去学习高并发系统设计的?
学长:“现在是知识付费时代,报培训机构啊!”
我:“没钱啊!”
学长:“开玩笑的啦,这个资料你拿过去学就完事了,看完这个要是还学不会我建议你去当滴滴司机!”
我:“是不是真的这么厉害?”
学长:“不信?那我撤回了!”
我:“你撤回啊,我都下载完了,不怕!”
在学习这个之前我请了年假,出去旅游放松了一下,疏解了一下自己的心情,也是好好调整自己的状态,备战金三银四,不能够再出现任何的差池。旅游回来后我迅速进入状态(说实话旅游放松是真的舒服,大家有机会一定要去),仔细看了一下作者的写作风格比较偏博文,相对来说距离感比较小,你并不会觉得这是个大佬。
在讲解知识点的时候也是由浅入深,循序渐进,让我们很好去理解,还有实战去帮助大家去巩固,在面试官的刁难下你也能够从容面对!
下面我就来介绍一下这份学习资料有多厉害!
Step ①:基础
首先,我们需要了解一下知识点:
-
高并发系统:它的通用设计方法是什么
-
架构分层:我们为什么一定要这么做?
-
系统设计目标(一):如何提升系统性能?
-
系统设计目标(二):系统怎样做到高可用?
-
系统设计目标(三):如何让系统易于扩展?


Step ②:数据库
在第一步中,我已经从宏观的角度带你了解了高并发系统设计的基础知识,你已经知晓了,我们系统设计的目的是为了获得更好的性能、更高的可用性,以及更强的系统扩展能力。
那么在这一步,我们正式进入演进篇,我会再从局部出发,带你逐一了解完成这些目标会使用到的一些方法,这些方法会针对性地解决高并发系统设计中出现的问题。
-
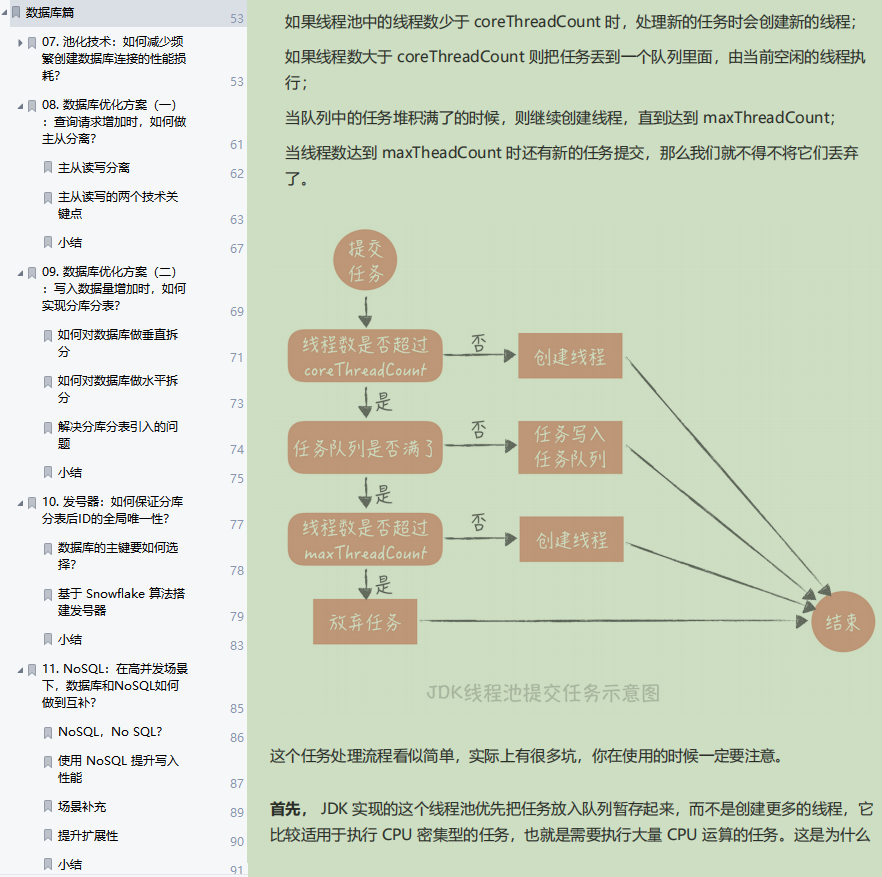
池化技术:如何减少频繁创建数据库连接的性能损耗?
-
数据库优化方案(一):查询请求增加时,如何做主从分离?
-
数据库优化方案(二):写入数据量增加时,如何实现分库分表?
-
发号器:如何保证分库分表后ID的全局唯一性?
-
NoSQL:在高并发场景下,数据库和NoSQL如何做到互补?
Step ③:缓存
通过前面数据库篇的学习,你已经了解了在高并发大流量下,数据库层的演进过程以及库表设计上的考虑点。
那么我将从缓存定义、缓存分类和缓存优势劣势三个方面全方位带你掌握缓存的设计思想和理念,带你针对性地掌握使用缓存的正确姿势,以便让你在实际工作中能够更好地使用缓存提升整体系统的性能。
-
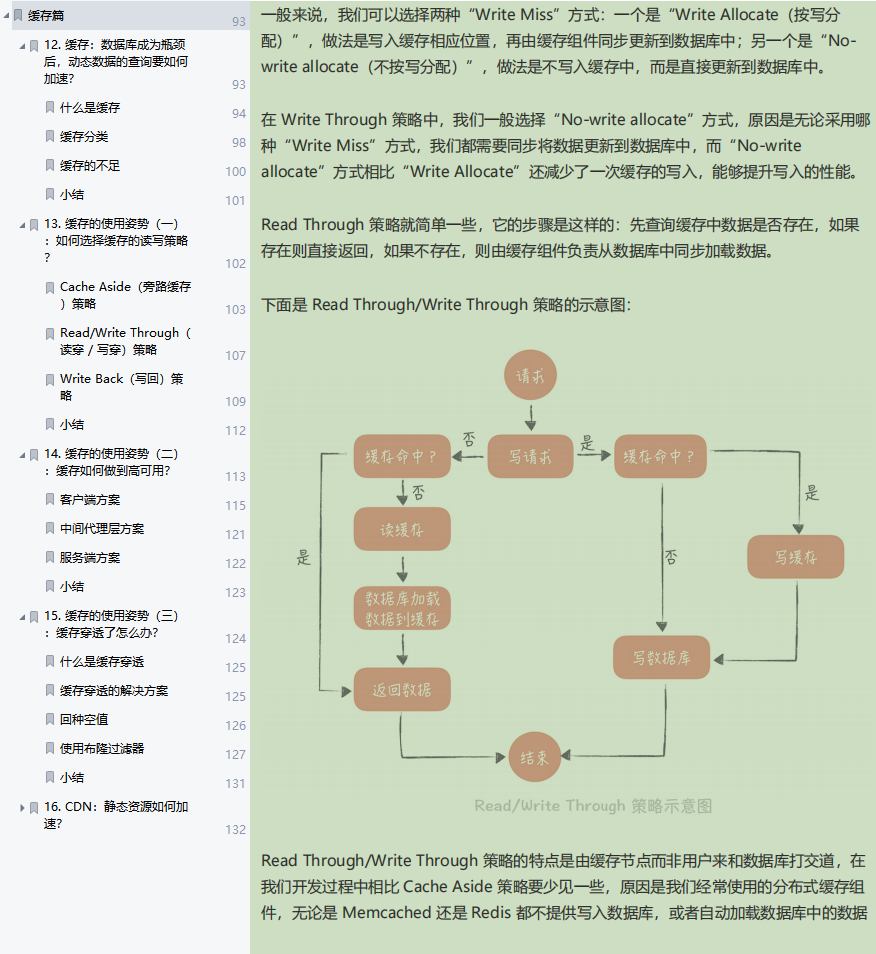
缓存:数据库成为瓶颈后,动态数据的查询要如何加速?
-
缓存的使用姿势(一):如何选择缓存的读写策略?
-
缓存的使用姿势(二):缓存如何做到高可用?
-
缓存的使用姿势(三):缓存穿透了怎么办?
-
CDN:静态资源如何加速?
Stpe ④:消息队列
1 秒钟之内,有 1 万个数据库连接同时达到,系统的数据库濒临崩溃,寻找能够应对如此高并发的写请求方案迫在眉睫。这时你想到了消息队列。
这里我会从以下几个问题去带大家学习如何使用消息队列解决秒杀场景下的问题:
-
消息队列:秒杀时如何处理每秒上万次的下单请求?
-
消息投递:如何保证消息仅仅被消费一次?
-
消息队列:如何降低消息队列系统中消息的延迟?

Step ⑤:分布式服务
通过前面几个篇章的内容,你已经从数据库、缓存和消息队列的角度对自己的垂直电商系统在性能、可用性和扩展性上做了优化。
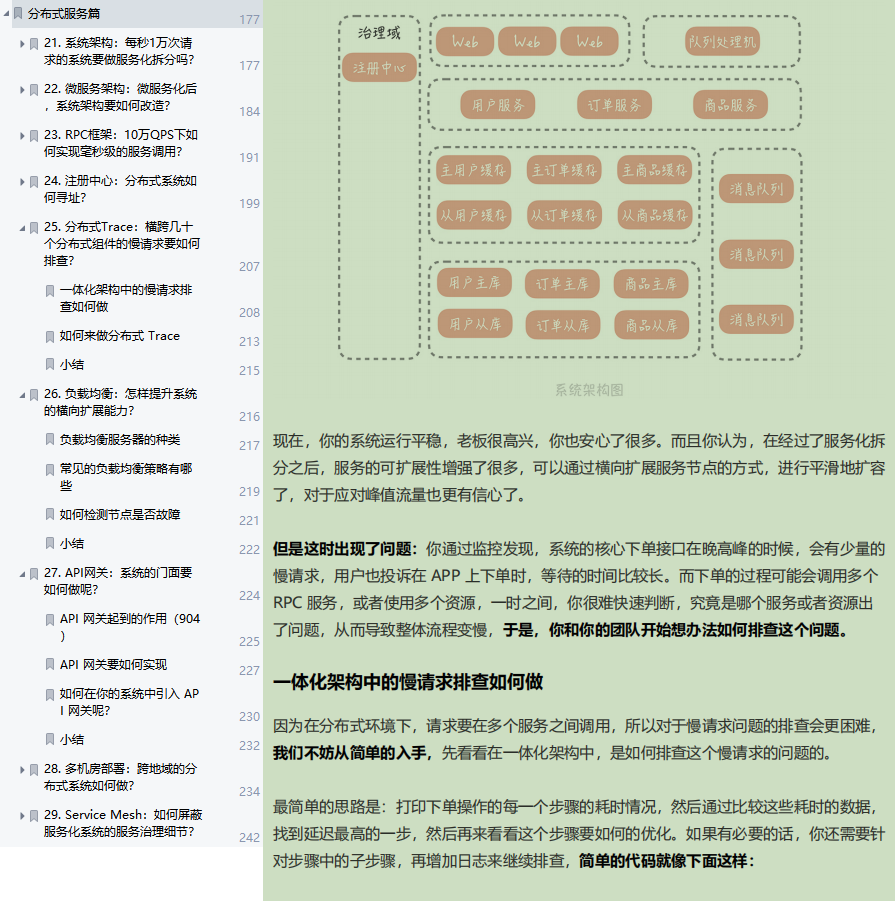
但是有一个问题一直萦绕在你的心里:究竟是什么促使我们将一体化架构,拆分成微服务化架构?是不是说系统的整体 QPS 到了 1 万,或者到了 2 万,就一定要做微服务化拆分呢?
我将从以下几个点去讲解,为什么我们要用分布式服务?它好在哪里、如何实现?
-
系统架构:每秒1万次请求的系统要做服务化拆分吗?
-
微服务架构:微服务化后,系统架构要如何改造?
-
RPC框架:10万QPS下如何实现毫秒级的服务调用?
-
注册中心:分布式系统如何寻址?
-
分布式Trace:横跨几十个分布式组件的慢请求要如何排查?
-
负载均衡:怎样提升系统的横向扩展能力?
-
API网关:系统的门面要如何做呢?
-
多机房部署:跨地域的分布式系统如何做?
-
Service Mesh:如何屏蔽服务化系统的服务治理细节?

Step ⑥:维护
要想快速地发现和定位业务系统中出现的问题,必须搭建一套完善的服务端监控体系。正所谓“道路千万条,监控第一条,监控不到位,领导两行泪”。不过,在搭建的过程中,你的团队又陷入了困境:
-
首先,监控的指标要如何选择呢?
-
采集这些指标可以有哪些方法和途径呢?
-
指标采集到之后又要如何处理和展示呢?
这些问题,一环扣一环,关乎着系统的稳定性和可用性,通过完成一下这些,我就带你解决这些问题,搭建一套服务端监控体系。
-
给系统加上眼睛:服务端监控要怎么做?
-
应用性能管理:用户的使用体验应该如何监控?
-
压力测试:怎样设计全链路压力测试平台?
-
配置管理:成千上万的配置项要如何管理?
-
降级熔断:如何屏蔽非核心系统故障的影响?
-
流量控制:高并发系统中我们如何操纵流量?

Step ⑦:实战
在前面,我分别从数据库、缓存、消息队列和分布式服务化的角度,带你了解了面对高并发的时候要如何保证系统的高性能、高可用和高可扩展。其中虽然有大量的例子辅助你理解理论知识,但是没有一个完整的实例帮你把知识串起来。
所以,为了将我们提及的知识落地,在实战篇中,我会以微博为背景,用两个完整的案例带你从实践的角度应对高并发大流量的冲击,期望给你一个更加具体的感性认识,为你在实现类似系统的时候提供一些思路。
-
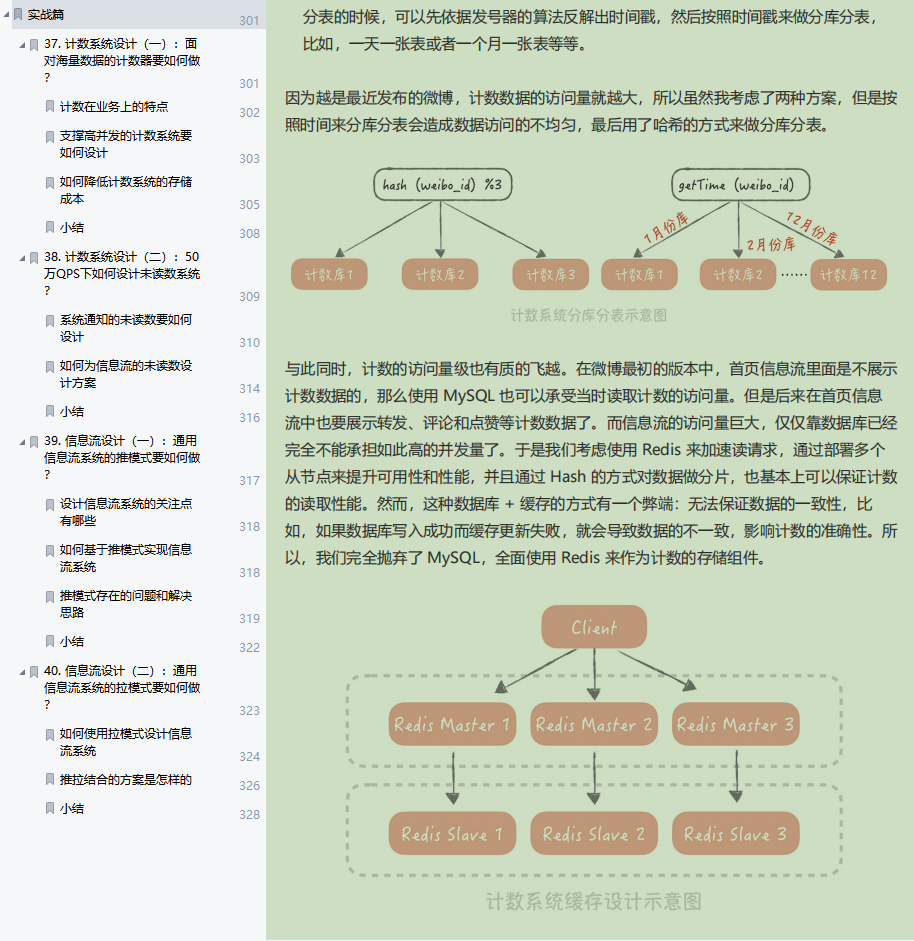
计数系统设计(一):面对海量数据的计数器要如何做?
-
计数系统设计(二):50万QPS下如何设计未读数系统?
-
信息流设计(一):通用信息流系统的推模式要如何做?
-
信息流设计(二):通用信息流系统的拉模式要如何做?