效果图展示!
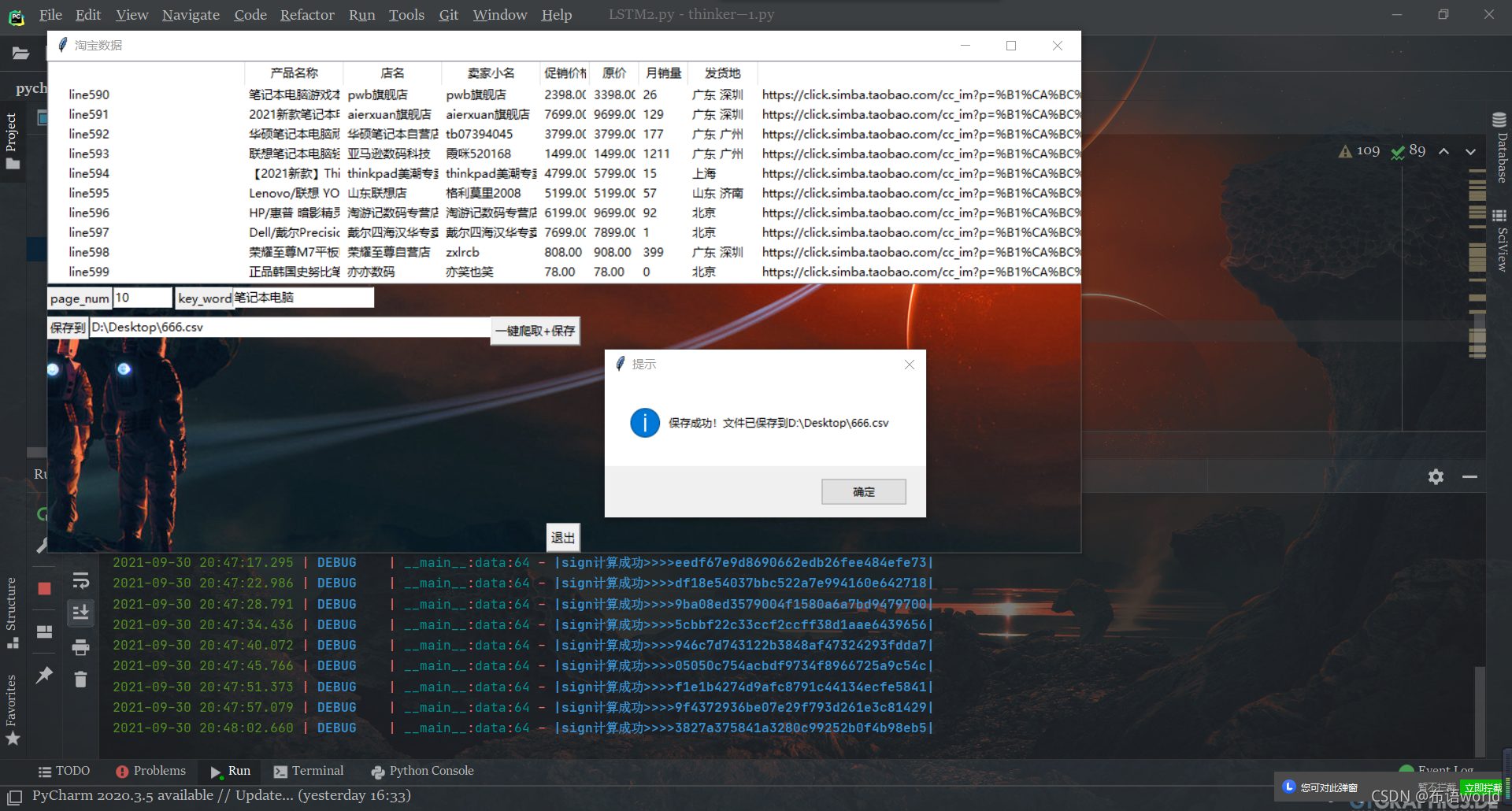
所用背景图片。。。。

代码展示!!!!
import hashlib,requests,json5,time
from requests.utils import dict_from_cookiejar
from loguru import logger
import pandas as pd
import tkinter.messagebox
import tkinter
from tkinter import ttk
from tkinter import *
from PIL import ImageTk, Image
'''
函数部分
'''
appKey = '12574478'
def get_sign(token, t, ___):
'''
获取sign值
:param token:
:param t:
:param ___:
:return: sign
'''
pre_sign = token + '&' + t + '&' + appKey + '&' + ___
sign = hashlib.md5(pre_sign.encode(encoding='UTF-8')).hexdigest()
return sign
def get_cookies():
'''
获取cookie值
:return: cookie
'''
url = 'https://h5api.m.taobao.com/h5/mtop.alimama.union.xt.en.api.entry/1.0/?jsv=2.5.1&appKey=12574478&t=1622426487791&sign=7771a311a65bbb533c3f3d4534d50f5e&api=mtop.alimama.union.xt.en.api.entry&v=1.0&AntiCreep=true&timeout=20000&AntiFlood=true&type=jsonp&dataType=jsonp&callback=mtopjsonp2&data=%7B%22floorId%22%3A195%2C%22count%22%3A10%2C%22p4pPid%22%3A%22430748_1006%22%2C%22spm%22%3A%22a2e1u.19484427.29996459%22%2C%22app_pvid%22%3A%22201_11.11.62.22_407060_1622426486844%22%2C%22ctm%22%3A%22spm-url%3Aa231o.13503973.search.1%3Bpage_url%3Ahttps%253A%252F%252Fai.taobao.com%252Fsearch%252Findex.htm%253Fspm%253Da231o.13503973.search.1%2526key%253D%2525E4%2525B8%2525B8%2525E7%2525BE%25258E%2526pid%253Dmm_110807073_1262350149_109959000489%2526union_lens%253Drecoveryid%25253A201_11.11.62.22_399283_1622423612735%25253Bprepvid%25253A201_11.11.62.22_399283_1622423612735%22%2C%22variableMap%22%3A%22%7B%5C%22union_lens%5C%22%3A%5C%22recoveryid%3A201_11.11.62.22_399283_1622423612735%3Bprepvid%3A201_11.11.62.22_399283_1622423612735%5C%22%2C%5C%22recoveryId%5C%22%3A%5C%22201_11.11.62.22_407060_1622426486844%5C%22%7D%22%7D'
headers = {
'referer': 'https://ai.taobao.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
}
res = requests.get(url, headers=headers).cookies
cook = dict_from_cookiejar(res)
cooks = ''
for i, k in cook.items():
cooks += i + '=' + k + ';'
return cooks
def data(num,x):
'''
生成post请求的data数据
:param num:
:param x:
:return: header,data_a
'''
# cookie
ck = get_cookies()
# mm_110807073_1262350149_109959000489
data_s = '{"pNum":%s,"pSize":"60","refpid":"mm_26632258_3504122_32538762",' % num
# data_tm = r'"variableMap":"{\"q\":\"手机\",\"navigator\":true,\"usertype\":\"1\",\"union_lens\":\"recoveryid:201_11.11.43.24_685807_1619341742886;prepvid:201_11.27.89.99_473565_1619342131641\",\"recoveryId\":\"201_11.186.139.24_536838_1619342621063\"}","qieId":"34374","spm":"a2e1u.19484427.29996460","app_pvid":"201_11.186.139.24_536838_1619342621063","ctm":"spm-url:a2e1u.19484427.filter.6;page_url:https%3A%2F%2Fai.taobao.com%2Fsearch%2Findex.htm%3Fkey%3D%25E4%25B8%25B8%25E7%25BE%258E%26pid%3Dmm_110807073_1262350149_109959000489%26union_lens%3Drecoveryid%253A201_11.11.43.24_685807_1619341742886%253Bprepvid%253A201_11.27.89.99_473565_1619342131641%26spm%3Da2e1u.19484427.filter.6%26usertype%3D1%26pnum%3D0"}'.replace('手机',x)
data_tm=r'"variableMap":"{\"q\":\"手机\",\"navigator\":false,\"clk1\":\"25b8f4d10e5d19d5a1b4c05c0cda428b\",\"union_lens\":\"recoveryid:201_11.20.200.89_16797742_1632624677134;prepvid:201_11.20.207.176_16801805_1632625096923\",\"recoveryId\":\"201_11.175.96.106_16839576_1632632392630\"}","qieId":"36308","spm":"a2e0b.20350158.31919782","app_pvid":"201_11.175.96.106_16839576_1632632392630","ctm":"spm-url:a2e0b.20350158.31919782.1;page_url:https%3A%2F%2Fuland.taobao.com%2Fsem%2Ftbsearch%3Frefpid%3Dmm_26632258_3504122_32538762%26keyword%3Dadidas%2520yeezy%2520boost%26clk1%3D25b8f4d10e5d19d5a1b4c05c0cda428b%26upsId%3D25b8f4d10e5d19d5a1b4c05c0cda428b%26spm%3Da2e0b.20350158.31919782.1%26pid%3Dmm_26632258_3504122_32538762%26union_lens%3Drecoveryid%253A201_11.20.200.89_16797742_1632624677134%253Bprepvid%253A201_11.20.207.176_16801805_1632625096923%26pnum%3D1"}'.replace('手机',x)
data_s = data_s + data_tm
# 获取token
token = re.findall(r"_m_h5_tk=(.*?);", ck)
token = ''.join([i.split("_")[0] for i in token])
# 获取时间戳
date = int(time.time() * 1000)
# 运算sign加密
cx = get_sign(token, str(date), data_s)
logger.debug("|sign计算成功>>>>%s|" % cx)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
"cookie": ck}
data_a = {
'jsv': '2.5.1',
'appKey': '12574478',
't': date,
'sign': cx,
'api': 'mtop.alimama.union.xt.en.api.entry',
'v': '1.0',
'AntiCreep': 'true',
'timeout': '20000',
'AntiFlood': 'true',
'type': 'jsonp',
'dataType': 'jsonp',
'callback': 'mtopjsonp2',
'data': data_s
}
return headers, data_a
def run(num,word):
'''
得到未经处理的数据
:param num:
:param word:
:return:a
'''
datas=[]
for page in range(int(num)):
headers, data_s = data(page,word)
# data_s={"pNum":2,"pSize":"60","refpid":"mm_26632258_3504122_32538762","variableMap":"{\"q\":\"adidas yeezy boost\",\"navigator\":false,\"clk1\":\"25b8f4d10e5d19d5a1b4c05c0cda428b\",\"union_lens\":\"recoveryid:201_11.20.200.89_16797742_1632624677134;prepvid:201_11.20.207.176_16801805_1632625096923\",\"recoveryId\":\"201_11.0.174.53_16801750_1632625790037\"}","qieId":"36308","spm":"a2e0b.20350158.31919782","app_pvid":"201_11.0.174.53_16801750_1632625790037","ctm":"spm-url:a2e0b.20350158.search.1;page_url:https%3A%2F%2Fuland.taobao.com%2Fsem%2Ftbsearch%3Frefpid%3Dmm_26632258_3504122_32538762%26keyword%3Dadidas%2520yeezy%2520boost%26clk1%3D25b8f4d10e5d19d5a1b4c05c0cda428b%26upsId%3D25b8f4d10e5d19d5a1b4c05c0cda428b%26spm%3Da2e0b.20350158.search.1%26pid%3Dmm_26632258_3504122_32538762%26union_lens%3Drecoveryid%253A201_11.20.200.89_16797742_1632624677134%253Bprepvid%253A201_11.20.207.176_16801805_1632625096923"}
url='https://h5api.m.taobao.com/h5/mtop.alimama.union.xt.en.api.entry/1.0/'
# url = 'https://h5api.m.taobao.com/h5/mtop.alimama.union.xt.en.api.entry/1.0/'
res = requests.get(url, headers=headers,params=data_s,timeout=30).content.decode('utf-8')
a = json5.loads(str(res).replace('mtopjsonp2', '').replace('(', '').replace(')', ''))
a = a['data']['recommend']['resultList']
datas.append(a)
for x,y in enumerate(a):
x=x+page*60
tree.insert("", x,text=f"line{x}", values=(y['itemName'],y['shopTitle'],y['sellerNickName'],y['promotionPrice'],y['price'],y['monthSellCount'],y['provcity'],y['url']))
return datas
def save_to_csv():
'''
保存数据到csv文件中
:return: all_data
'''
word = w.get()
n = num.get()
data=run(n,word)
itemname,shoptitle,sellernickname,promotionprice,price,monthsellcount,provcity,url=[],[],[],[],[],[],[],[]
for y in data:
for x in y:
itemname.append(x['itemName'])
shoptitle.append(x['shopTitle'])
sellernickname.append(x['sellerNickName'])
promotionprice.append(x['promotionPrice'])
price.append(x['price'])
monthsellcount.append(x['monthSellCount'])
provcity.append(x['provcity'])
url.append(x['url'])
all_data={'itemname':itemname,"shoptitle":shoptitle,"sellernickname":sellernickname,"promotionprice":promotionprice,"price": price,"monthsellcount":monthsellcount,"provcity":provcity,"url":url}
# def sort():
# '''
# 对数据进行排序
# :return:
# '''
# data = pd.DataFrame(all_data)
# atoz = data['promotionprice'].index
# # 查询商品销量的前十和后十
# productId_orderCount = data.groupby('itemname').count()['monthsellcount'].sort_values(ascending=False)
# tree.insert("", x, text=f"line{x}", values=(
# y['itemName'], y['shopTitle'], y['sellerNickName'], y['promotionprice'], y['price'], y['monthSellCount'],
# y['provcity'], y['url']))
# pass
# sort_monthsell=tkinter.Button(win,text='月销量从大到小排序',command=sort)
# sort_monthsell.pack()
# sort_monthsell.place(x=260,y=230)
path=e.get()
df=pd.DataFrame(all_data)
df.to_csv(fr"{path}",encoding="utf8")
tkinter.messagebox.showinfo("提示",f"保存成功!文件已保存到{path}")
return all_data
'''
tkinter界面设置
'''
win = tkinter.Tk()
win.title("淘宝数据")
win.geometry("1050x500+40+30")
image2 = Image.open(r'D:\Desktop\C~O)OKLBO]{3H{KE$J4%12M.png')
background_image = ImageTk.PhotoImage(image2)
background_label = Label(win, image=background_image)
background_label.place(x=0, y=0, relwidth=1, relheight=1)
# # 表格
tree = ttk.Treeview(win)
tree.pack()
tree.place(x=0,y=0)
# 定义列
tree["columns"] = ("itemname", "shoptitle", "sellernickname", "promotionprice","price","monthsellcount","provcity","url")
# 设置列,列还不显示
tree.column("itemname", width=100)
tree.column("shoptitle", width=100)
tree.column("sellernickname", width=100)
tree.column("promotionprice", width=50)
tree.column("price", width=50)
tree.column("monthsellcount", width=50)
tree.column("provcity", width=70)
tree.column("url", width=1000)
# 设置表头
tree.heading("itemname", text="产品名称")
tree.heading("shoptitle", text="店名")
tree.heading("sellernickname", text="卖家小名")
tree.heading("promotionprice", text="促销价格")
tree.heading("price", text="原价")
tree.heading("monthsellcount", text="月销量")
tree.heading("provcity", text="发货地")
tree.heading("url", text="网址")
e = tkinter.Variable()
path_entry = tkinter.Entry(win, textvariable=e,width=60)
path_entry.pack()
path_entry.place(x=43, y=260)
e.set("请填写csv文件的绝对路径")
label_num=tkinter.Label(win,text='page_num')
label_num.pack()
label_num.place(x=0,y=230)
label_word=tkinter.Label(win,text='key_word')
label_word.pack()
label_word.place(x=130,y=230)
label_save=tkinter.Label(win,text="保存到")
label_save.pack()
label_save.place(x=0,y=260)
num = tkinter.Entry(win, width=8)
num.pack()
num.place(x=67, y=230)
w = tkinter.Entry(win, width=20)
w.pack()
w.place(x=188, y=230)
button1=tkinter.Button(win,text="退出",command=win.quit)
button1.pack(side="bottom")
button2=tkinter.Button(win,text="一键爬取+保存",command=save_to_csv)
button2.pack()
button2.place(x=450,y=260)
win.mainloop()爬多了可能会遇到滑块(滑块协议过的源码不可泄露,可以买),或者页数过多也会报错,你们也可以自己写判断,我写的没有对一些特殊事件进行判断,毕竟。。。爬那么多干嘛。。。仅供学习使用!!!
如果觉得有帮助,又想感谢的!可以通过以下方式感谢!!!
