聊聊我最近的分库分表骚操作_七里翔的博客
聊聊我最近的分库分表骚操作
- 前言
- 背景
- 分库分表方案
- 切分策略
- 不分库,只分表
- 技术选型
- 问题及解决方案
- 分布式ID实现
- 不重复的ID该怎么实现?
- 表下标维护
- 插入前查询maxId
- 插入后查询maxId
- 预留ID
- 预留ID + 不依赖redis
- 多数据源、sharding-jdbc、主从怎么结合到一块?
- 怎么解决多数据源和shardingsphere数据源冲突的问题?
- 怎么解决分表+主从数据库不适合用shardingsphere的问题?
- 影响
- 部分SQL性能问题
- 上线前准备
- 数据迁移
- 服务切换
- 预留一部分主键ID
- 最后的方案
- 其它
- 存储过程
- 多数据源组件
- 后续思考
- 假如要分库
前言
国庆前这段时间一直都在搞分库分表相关的东西,中间遇到了比较多的问题,不过最后还是都艰难地解决掉了。这段时间感觉挺累但又挺有意思的,需要思考的点很多,所以决定写篇博客水总结一下。毕竟因为最近在刷算法题,没更新过什么博客了,趁国庆时间比较多,赶紧卷一卷。

背景
先说一下背景吧。我们项目之前是完全没做分库分表的,现在有几张核心的表,数据量已经非常大了,数据量最大的一张表已经有接近250亿的数据了……我刚开始看到这张表的数据量是比较惊讶的,而且还跟DBA大佬了解了一下,现在线上这张表的操作耗时非常短,暂时没有性能问题。一般来说,千万级的数据量应该已经比较影响性能了,现在这个表已经差不多250亿数据了,还不出问题?

我分析了一下这张表的结构,然后看了一下相关的SQL,我认为这张表暂时还没有性能问题有以下两点:
- 数据结构简单。这是一张文件表,里面的字段不多,只有主键id、文件名、key、hash、url、大小等字段,占用的空间也不大
- SQL不复杂。我分析了一下与这张表有关系的所有SQL,发现这张表几乎没有update操作(有是有,但是只有一个SQL,而且那个方法还被废弃了,我们现在的业务基本上不会对这张表的数据进行修改),只有insert和select操作,而且select操作大部分都是通过主键id作为条件查询,少量是通过hash字段来进行查询,所以需要维护的索引也不多,只有主键索引和这个hash字段的普通索引。所以这张表的相关SQL是比较简单的。
虽然现在没有性能问题,但是嘛……现在这张表每个月的增长速度是亿级别的,再不做分库分表,迟早要出问题。所以我决定先对它出手了!另外几张表的数据量也很大,但是与之相关的操作太复杂了,所以我觉得我得先找个简单的表实践实践,积累一点经验后再对其它几张表下手。

分库分表方案
分库分表主要有垂直切分和水平水平,这次针对的问题是单表容量达到瓶颈的问题,因此采用水平切分。
以下把这张表叫做 t_file 表吧。
切分策略
水平切分策略主要有hash切分和范围切分,优缺点如下表。
| 切分策略 | 实现 | 优点 | 缺点 |
|---|---|---|---|
| hash切分 | hash取模mod | 数据分片相对比较均匀,不容易出现热点和并发访问的瓶颈 | 1.后期分片集群扩容需要迁移旧的数据。 2.容易面临跨分片查询的复杂问题 |
| 范围切分 | 按照时间区间或ID区间来切分 | 1.单表大小可控 2.便于水平扩展 3.对范围查找友好 | 热点可能容易成为性能瓶颈 |
最终经过考虑,决定采用范围切分策略,主要原因是 t_file 的主键原来是整型的自增主键,不适合用hash切分。目前数据量非常大,并且还涉及到另外几张表,有些表存储了一个列表,列表里存的就是整型ID,那些表也非常大,改的话影响范围太大,所以不可能把整型修改成其它类型。
不分库,只分表
这张表我们有没有必要分库呢?我和我的mentor讨论了一下,觉得是暂时只做分表即可。只要原因有以下几个:
- 我们有主从,做了读写分离(也不算完全读写分离,个别对延时方面要求高的SQL读的是主库),并且跟DBA大佬讨论过,数据库压力并没有那么大。而且我们如果在主从上又做分库,那每个实例启动后都需要连接并且管理大量的数据源,需要消耗大量资源,不是很值得
- 这张表,是存在一个独立的库中的,那个库只有这一张表!由于这张表数据里较大,之前我们就把这张表分出来放到一个独立的库中了,它跟其它表并不是在同一个数据库。所以它压力更小了
- 由于是水平切分,我们后期要是再想做分库的话,不用再次迁移数据,或者说迁移数据的复杂度很低,并且路由规则也不需要改太多。以后我们想做分库再做就是了,现在不用一步到位
所以最终决定不分库,只分表。
技术选型
目前比较主流的分库分表中间件有mycat、sharding-jdbc、tidb,最终决定使用sharding-jdbc,原因有下:
- 现在只打算分表,而不分库,Mycat和tidb并没有太大优势
- mycat是proxy层解决方案,需要部署、维护,并且本身是单点的,高可用性差,如果想要集群还需要再引入别的中间件
- tidb资源利用率低、维护成本也很高
综合业务及中间件优缺点考虑,sharding-jdbc较为合适。

问题及解决方案
写的过程碰到了几个问题,搞了点骚操作。

分布式ID实现
不重复的ID该怎么实现?
分库分表后,需要保证数据插入后ID的唯一性,实现不重复的ID一般有以下几种方案:
- 使用雪花算法生成ID。雪花算法会生成64 bit的ID,转成字符串后长度是19位(有个表需要存储文件表数据ID),长度比较长。如果我们使用了雪花算法,那另一个表每一行的数据都会膨胀很多,这就不是很划算了……
- 实现发号器。可通过redis的incrby实现全局单调ID生成器,从而保证唯一性。但是这个方案会使插入数据操作强依赖于中间件,必须考虑到持久化、高可用等问题,实现一个靠谱的发号器需要考虑到的地方太多,不容易落地。
- 使用UUID。我们要用整型ID,UUID没法满足。
- 使用数据库的自增ID。该表的数据比较特殊,只会新增,不会删除,并且极少有修改操作,因此可以考虑继续使用数据库的自增ID。而要保证每个表的ID都不重复,那就要先确定好每个表的ID范围没有交集,再在建表时设置好表的起始自增序列号,业务方需要确保在插入数据时判断该表的最大ID必须小于下一个表的起始自增序列号。例如我们打算每个表存储100行数据,那么 t_file_0 表的ID范围为 0 ~ 99(当然,我们没有ID为0的数据,最小的是1),t_file_1 表的ID范围为 100 ~ 199 ,t_file_2 表的ID范围为 200 ~ 299……
方案四实现全局唯一ID比较简单,类型符合我们要求,性能也没有损耗,因此决定采用方案四。但是问题接踵而至。
使用方案四,就会有三个问题:
- 建表前需要确认好每个表的ID范围,建表时设置好起始自增序列号
- 在插入ID时维护好当前要插入的数据对应的表下标,根据上面的例子,当 t_file 里的数据最大ID为99时,后面的数据不能再插入到该表中,而是要插入到 t_file_1 中,这意味着我们需要维护一个当前数据对应的表下标,即“我需要知道现在的数据需要插入到哪个表”
- 使用自己的策略就意味着不能使用sharding-jdbc的ID生成策略了
第一个问题只需运维或者后端开发建表前注意一下即可,而第二个问题则需要在代码中解决,而第三个问题,只需要我们把表下标传进mapper,交给mybatis帮我们拼装到SQL里面即可。
所以现在主要是要解决第二个问题。

表下标维护
那么要怎么维护这个表下标呢?我当时是思考了一个下午,一步步优化,得到一个自认为不错的方案(太佩服我自己了吧),而且实现也不复杂。这个方案就是每个表预留一部分ID,然后每个实例各自维护一个表下标,不存储在redis中。
下面来看看整个优化的过程。

插入前查询maxId
最直接的写法就是每次批量插入数据前,先查询表的最大ID,再加上当前的数据量,预测插入数据后的ID是否还在范围内,若超过了该范围,就把下标+1,更新到redis中,然后把数据插入到下一个表中。
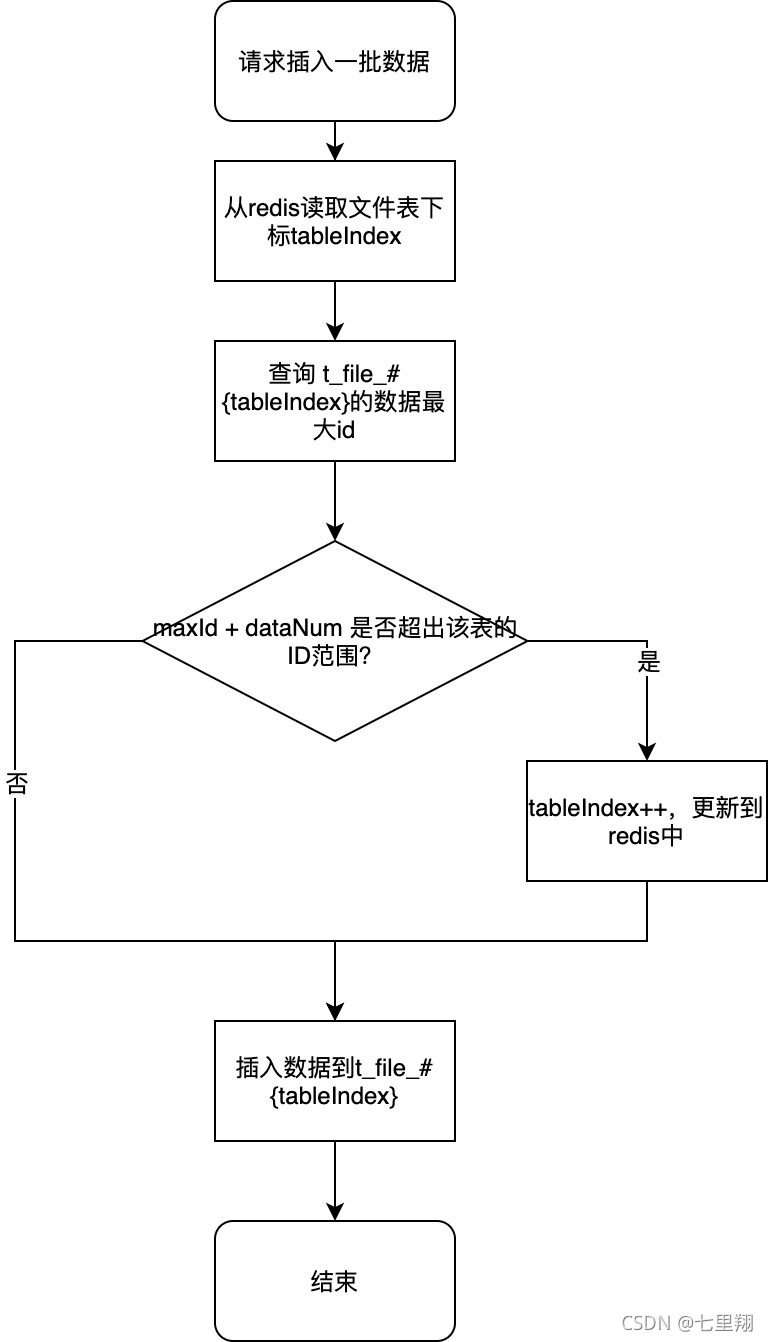
单线程下这种做法当然没有问题,但是多线程问题就大了,何况这个业务并发量还那么高。
假设 t_file_0 的ID范围是0 ~ 9999,现在该表最大的ID是9995,此时2个线程同时插入数据,这2个线程都插入4行数据……2个线程获取到的tableIndex都是0,并且查了一下maxId加上自己的数据量,最后得到9999,在范围内,然后同时插入数据……那么 t_file_0 这个表就会出现ID超过了9999的情况,而 t_file_1 的ID范围是 10000~19999,ID重复了!
所以很明显,这个方案不靠谱。
插入后查询maxId
既然插入后的ID可能会超出范围,那我们能不能在插入后再检查一下maxId呢?如果maxId超出范围,就回滚事务,再更新tableIndex,把数据插入到下一张表中。

这种做法比较靠谱,插入后再检查ID,再决定是否提交事务,就不会出现最大ID超过该表范围这种情况了。但是却要手动控制事务。
预留ID
那能不能再优化一下呢?我不想控制事务回滚然后再提交一次……
所以我想到了预留最后一部分ID的做法,我可以让每张表都预留一部分ID,这部分ID可以插入一部分数据,但是插入之后,以后的数据就插入到下一张表。只要我们预留的ID范围足够大,那在高并发场景下就不会出现ID超范围的情况。
比如 t_file_0 的预留ID范围是 9000~9999,当插入一批数据后得到的最大ID是9100,达到了预留ID范围,那就更新表下标,以后的数据插入到 t_file_1 中。即使多个线程同时插入一大批数据,只要我们预留的范围足够大,就不会出现最大ID超过这张表范围的情况。这样就不用手动控制事务了。
而我们需要查询的时候,ID为 0 ~ 9999(包括预留的那部分ID,9000 ~ 9999) 还是路由到 t_file_0 进行查询,所以插入和查询都是不会有问题的。
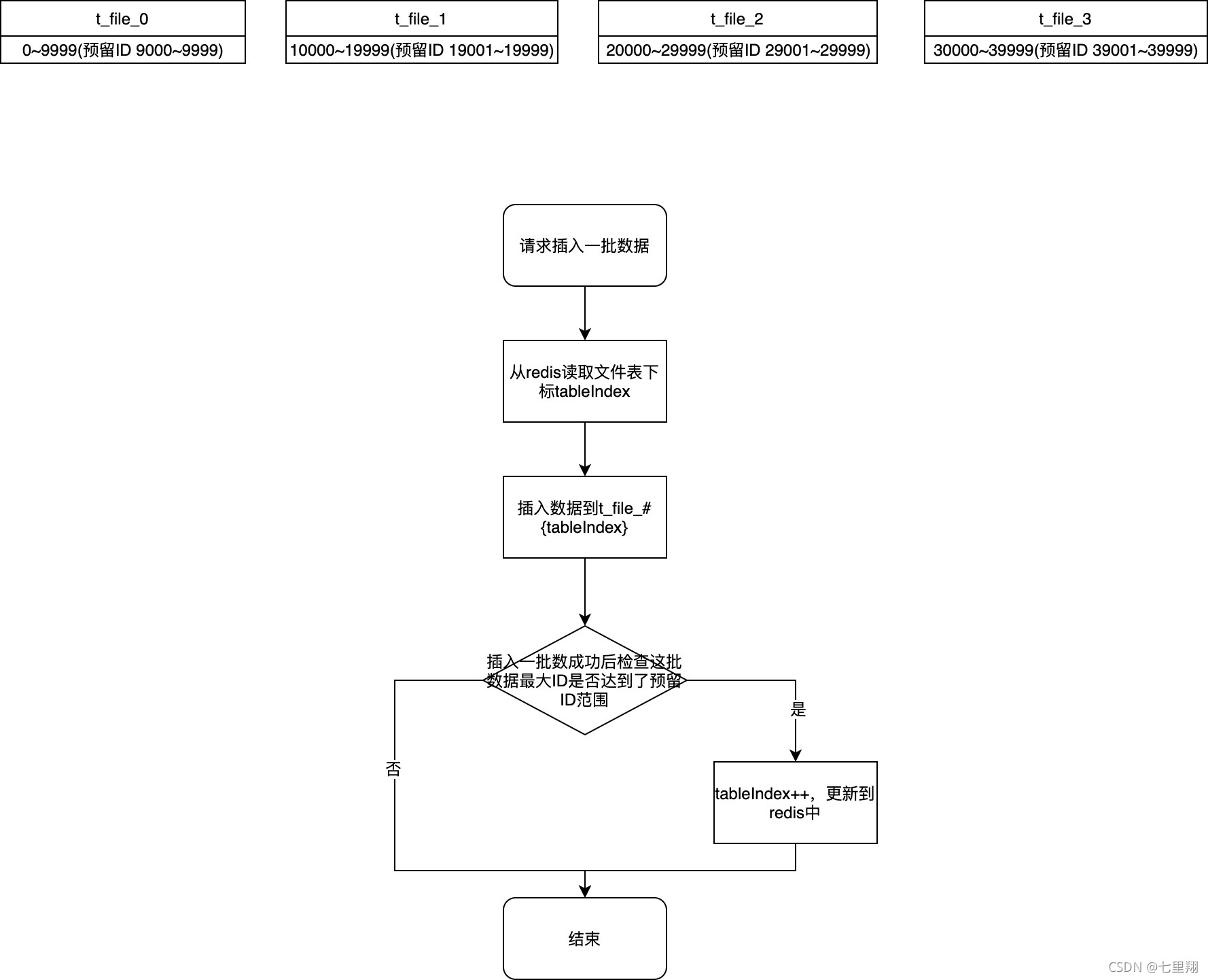
但是这样又依赖与中间件了,这样的话,redis一出问题,那可能就会影响到当前业务的新增操作了。
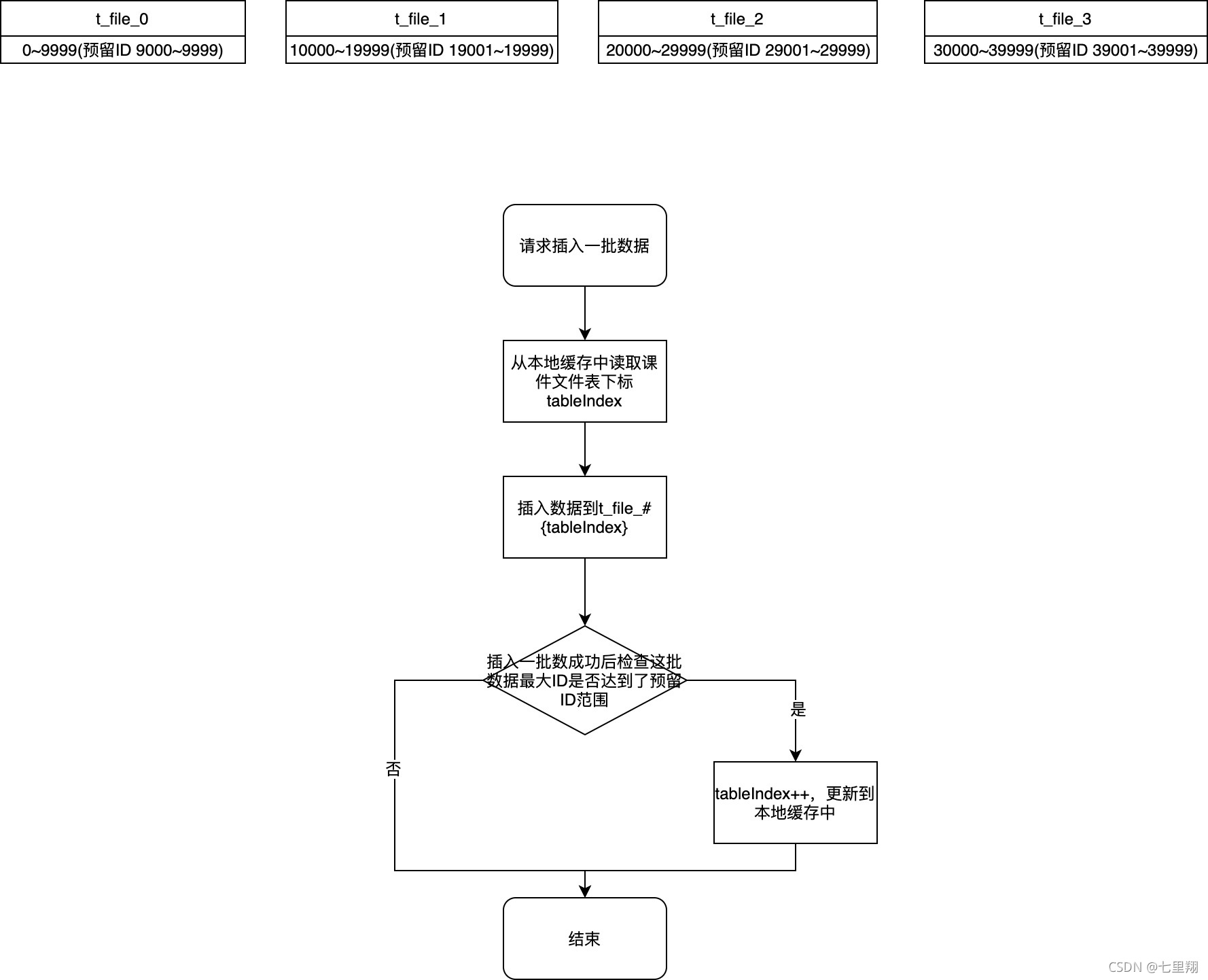
预留ID + 不依赖redis
上面的方案,都是在redis维护了一个表下标。这样的话,redis一出问题,那可能就会影响到当前业务的新增操作了,但是实际上表下标是不需要在redis中再维护一份的,我只需要在每个实例中维护自己的一个下标就行了!
这样的话,会有这个问题:当其中一个实例插入数据后,发现自己的下标要+1了,其它的实例无法感知到。
但是这个问题并不会使ID重复,因为只要我预留的ID足够大,保证其它实例再插入数据的时候,不会超过当前表的最大ID,就不会出现问题!并且我们插入数据是分批插入的,每批最多100个数据。比如要插入1000个数据,我会分成10批数据,每批数据插入完成后都会检查一下maxId并更新表。所以理论上,只要满足这个条件,就绝对不会有重复ID的问题发生(当然我是测过的,你完全可以相信七里翔):
预留ID数 > 实例数 * 每个实例的最大线程数 * 100
多数据源、sharding-jdbc、主从怎么结合到一块?
使用sharding-jdbc的shardingsphere,我又遇到了以下两个问题:
- 在项目中使用了我们自己写的一个多数据源的组件,与shardingsphere数据源冲突
- 我们的分表+主从数据库架构不适合用shardingsphere
针对这两个问题,我决定优化多数据源组件,整合shardingsphere。
怎么解决多数据源和shardingsphere数据源冲突的问题?
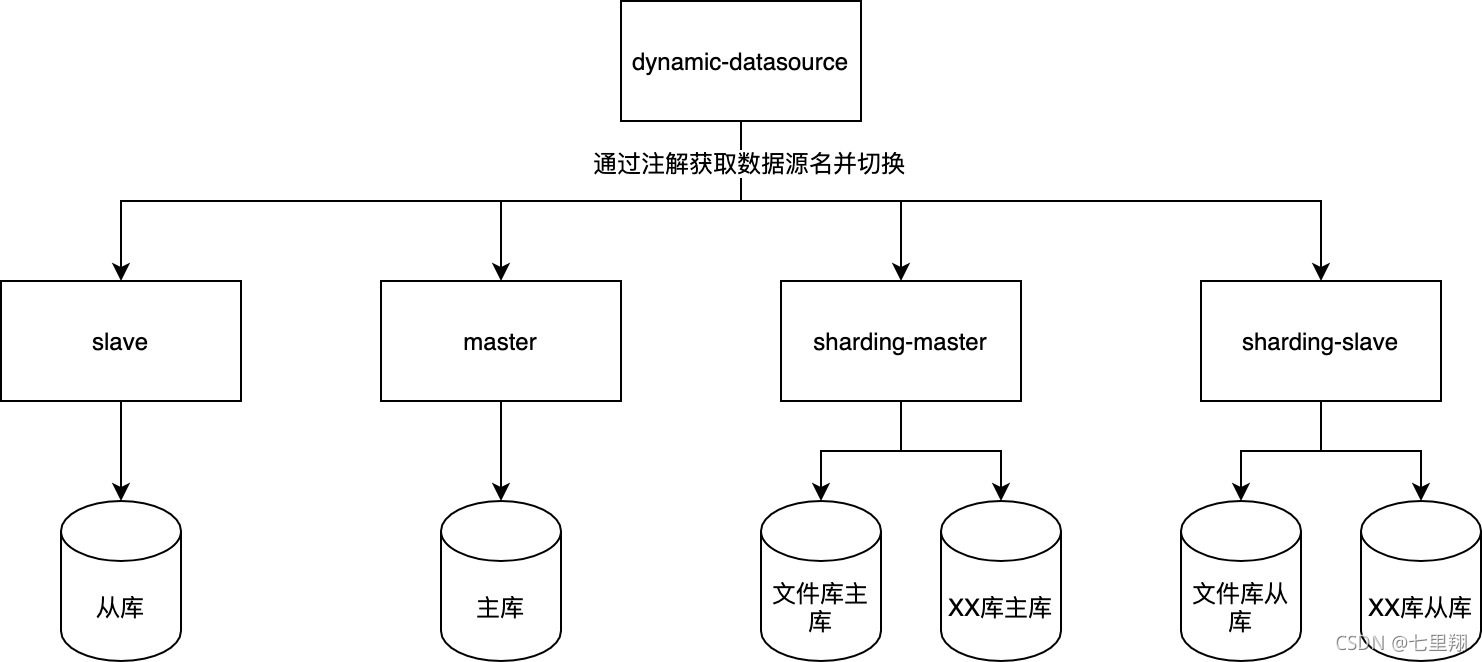
我们的项目中要到了一个自己开发多数据源组件,把这个多数据源组件的DataSource注到mybatis中,可以通过注解动态切换数据源。但是现在用shardingsphere,会跟这个组件起冲突。
看了一天源码后,我最后决定把shardingsphere集成到我们的多数据源组件中。我先在shardingsphere基础上写个自动配置类,封装多个shardingsphere的datasource,然后交给多数据源去管理。也就是,数据源组件只需要负责帮我切换数据源到shardingsphere,剩下的分片、路由相关的操作还是交给shardingsphere本身去完成。完美解决二者冲突的问题!
怎么解决分表+主从数据库不适合用shardingsphere的问题?
我们的数据库是主从,现在使用shardingsphere来管理 t_file 表的路由,想要切换到从库数据源,只有两个办法:
- 使用Hint分片策略,强制切换数据源。这种办法不靠谱,每次使用前都需要路由到指定的具体库和表,将产生大量重复的业务代码
- 配置shardingsphere的读写分离。这种方法也不靠谱,我们不一定所有的读都走从库,再加上我们有个别sql查询是不走shardingsphere的,这意味着这部分查询语句没法使用shardingsphere的读写分离。
这两种方法都没法满足我们的业务需求,最终我决定再优化多数据源组件,使用多数据源管理多个shardingsphere DataSource。
通过配置多个shardingsphere数据源,把主数据库和从数据库配置到不同的shardingsphere数据源中,再注入到多数据源组件中,通过注解切换到不同的shardingsphere数据源,即可实现主从库数据源的切换,同时还能使用shardingsphere的功能,主从数据源共用同一套表路由算法,并且方便以后其它表使用shardingsphere来进行表路由。
影响
部分SQL性能问题
虽然这个表涉及的SQL不多,并且不复杂,但是还是有个别SQL可能会出现问题。
比如刚才说到的,通过hash查询某一行数据。有2个SQL,分别是这样:需要通过hash匹配查询第一行数据;需要通过hash匹配查询最后一行数据。
这2个SQL肯定不能走shardingsphere来查询的了,因为我的分片键只有id,这种查询条件不是分片键的SQL,会在所有的表中执行一次,最后在汇合处理,这样的效率肯定是非常低的。
还好这2个SQL也不复杂,我最后自己优化了一下。不通过shardingsphere去做路由,而是我自己传入表下标。比如需要通过hash匹配查询第一行数据,我传下标0进去执行SQL,数据为空,下标+1再查下一个表。直到查询到一行数据或者下标超出了当前插入数据的表下标(tableIndex)为止。
上线前准备
数据迁移
上线前需要运维协助建表并迁移数据,分表后每张表数据量为20亿,预留10万个ID。

服务切换
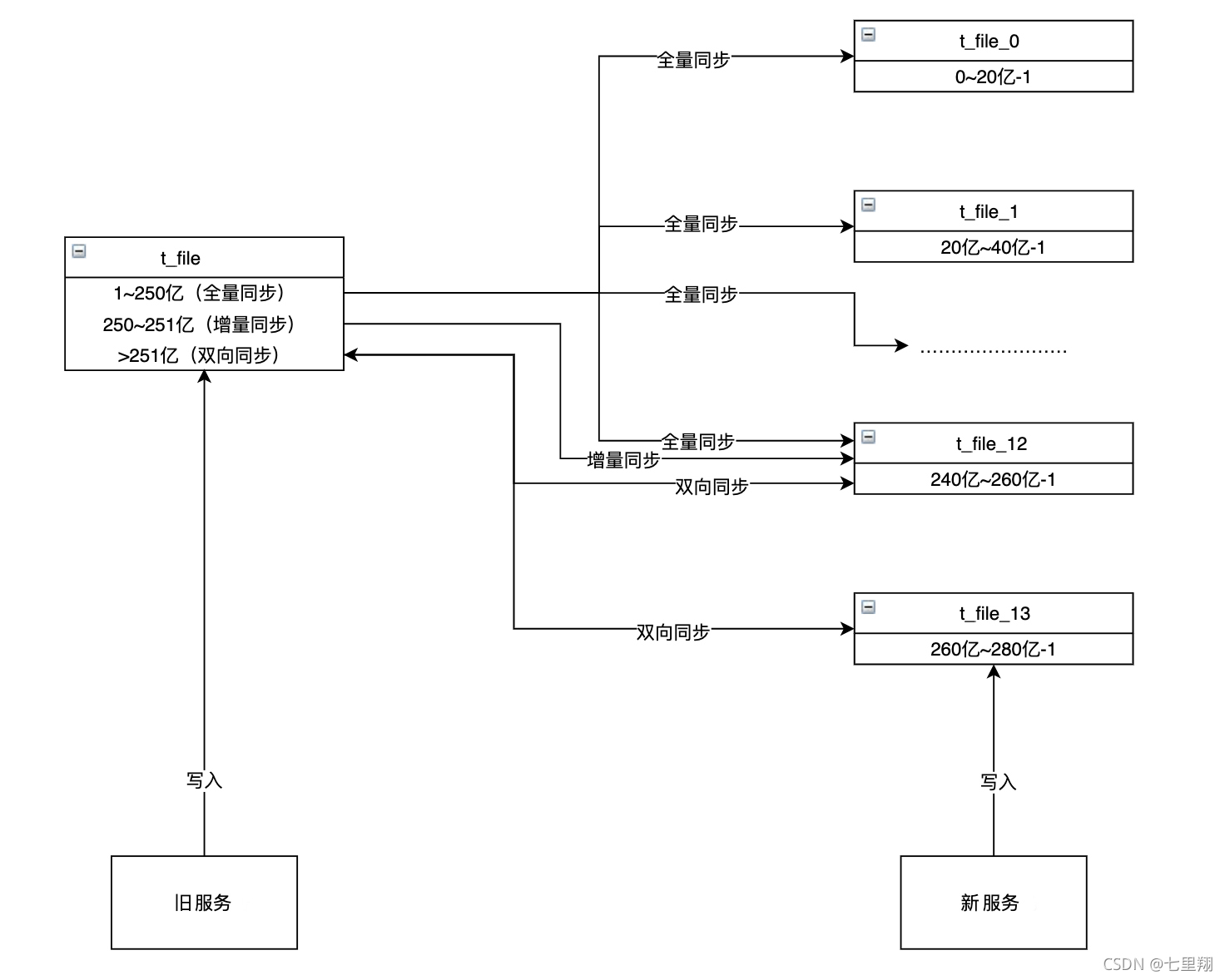
服务更新与服务回滚是比较重要的环节,这个得要提前规划好。考虑好怎么样才能将服务切换时的影响降到最低。我刚开始的方案是,预留一部分主键ID,具体方案如下。
预留一部分主键ID
采取预留一部分主键ID的方案让新旧服务能同时运行而不会产生主键冲突。
假如现在线上有250亿数据,按照每张表20亿数据分表,则可以分为13张表,下标为 0 ~ 12 ,t_file_12 的主键范围是 240亿~260亿-1,全量同步后开启增量同步,把后续新增的数据也同步过去。
假设增量的数据有1亿,那么增量同步差不多完成后,t_file_12 中的最大主键大概是251亿,还有9亿的ID可用。
这个时候新服务上线,新服务新增的数据插入到 t_file_13 中,而 t_file_13 的起始自增序列号为260亿,所以新旧服务一起运行时,一定时间内并不会出现主键冲突的情况。因此新服务上线后可以开启双向同步,观察新服务上线后的情况,确认完全没有问题后再关闭旧服务、双向同步。
整个过程的步骤为:
- 在新库中新建课件文件表
- 全量同步
- 增量同步追加数据
- 开启双向同步
- 上线新服务
- 新服务无异常,关掉旧服务和双向同步
当我说完这个方案后,我自信满满,此时我的表情是这样的👇。

但是,DBA大佬的表情先是这样的👇。

然后,变成了这样👇。

我内心慌了起来。
DBA大佬说:小伙子,这个上线方案不行。假如一个表原本的当前的自增序列号是10,而你插入了一行数据,这行数据里面包含了ID(即不是使用自增ID)的话,是会更新自增序列号的,比如你插入了一个ID为15的数据,那这个时候表的自增序列号就会变成16,而不是原来的10了。
我……

最后的方案
还是DBA大佬经验丰富,和他讨论过后,我豁然开朗。最终的上线步骤是这样的。
- 运维开启全量同步,把旧库数据同步到新库中
- 上线新服务(版本1),双写,先旧后新,数据全部从旧库读取。新库中的ID需和旧库中保持一致
- 下线旧服务,新旧服务同时运行的过程中旧服务产生的增量数据由运维处理,补到新库中
- 上线新服务(版本2),双写,先旧后新,数据全部从新库中读取
- 上线新服务(版本3),双写,先新后旧,数据全部从新库中读取。旧库的ID需和新库保持一致
- 新服务在线上运行一段时间没出现问题后,再更新代码上线新服务(版本4),去除双写机制,只需在新库中读写数据,旧库废弃
其它
存储过程
新建表的时候的存储过程如下:
create procedure create_tables()
begin
set @str = "(
`c_id` bigint unsigned NOT NULL AUTO_INCREMENT,
`c_create_time` datetime NOT NULL,
`c_modify_time` datetime NOT NULL,
PRIMARY KEY (`c_id`),
KEY `idx_c_hash` (`c_hash`) USING BTREE,
KEY `idx_name` (`c_name`)
) ENGINE=InnoDB AUTO_INCREMENT=";
set @j = 0;
while @j < 100 do
set @auto_increment = @j * 2000000000;
set @table = concat('t_file_',@j);
set @end = " DEFAULT CHARSET=utf8";
set @sql_t = concat("CREATE TABLE ",@table, @str, @auto_increment, @end);
prepare sql_t from @sql_t;
execute sql_t;
set @j = @j + 1;
end while;
end;
call create_tables();
drop procedure create_tables;
多数据源组件
我感觉这个多数据源组件有点意思。所以我在国庆这两天自己也写了个多数据源组件,并且集成了shardingsphere。感兴趣的可以点我头像,里面有我github主页链接,里面一个名为 dynamic-datasource-spring-boot-starter 的仓库就是这个项目了。
后续思考
假如要分库
现在是只做分表的情况,我可以把表下标传进去给mybatis拼到SQL里面。但是如果做了分库后要怎么办呢?
这个我也考虑到了,假如要做分库的话,那数据库的路由就需要交给sharingsphere去完成了,我能想到的是:用shardingsphere的hint强制路由策略,然后自己实现自定义注解,并且实现相应的路由策略,按理说是可以满足分库的需求的。
不过嘛,没实践过怎么会知道有没有其它问题呢?等有空了我再实现试试。

登录后可发表评论
点击登录