文章目录
- Linux发行版简介
- 学习Linux的必备硬件知识
- 关键硬件器件——CPU
- 关键硬件器件——存储
- 关键硬件器件——内存
- 其他一些查看硬件信息的命令
- Linux开机过程(以Ubuntu16.04为例)
- 阶段1:BIOS
- 阶段2:boot Loader
- 阶段3:kernel
- 阶段4:systemd
- 阶段5:应用软件
- Linux常用命令
- 基本命令
- 文件管理
- 文本操作
- 磁盘管理
- 系统管理
- 网络通信
- 压缩解压
- 查询硬件信息的命令
- 多命令协作
- git操作命令
- Reference
Linux发行版简介
-
严格来讲,Linux这个词本身只表示Linux内核,但实际上人们已经习惯了用Linux来形容整个基于Linux内核的操作系统。
-
Linux 的发行版简单说就是将 Linux 内核与应用软件做一个打包。知名的发行版有:Ubuntu、RedHat、CentOS、Debian、Fedora、SuSE、OpenSUSE、Arch Linux
-
云桌面的Linux终端采用Ubuntu 16.04 server版,服务器采用CentOS6.5
-
Linux发行版主要有Debian与Redhat两大系列
| Debian | Redhat | |
|---|---|---|
| 发行版代表 | Debian,Ubuntu,Linux Mint | Redhat,CentOS,Fedora |
| 软件包管理方式 | dpkg(管理本地的软件包,无法处理依赖关系)、 apt(联网下载软件包,自动处理依赖关系) | rpm(管理本地的软件包,无法处理依赖关系)、 yum(联网下载软件包,自动处理依赖关系) |
| 安装包格式 | deb | rpm |
学习Linux的必备硬件知识
关键硬件器件——CPU
CPU是计算机的运算核心和控制核心,部分CPU内置核芯显卡
- x86架构:云桌面采用Intel、AMD、海光、兆芯等芯片
- ARM架构:云桌面采用Rockchip的芯片
查看CPU的信息
lscpu
cat /proc/cpuinfo
关键硬件器件——存储
类型
- 固态硬盘(SSD):读写速度快,价格较高
- 机械硬盘(HDD):读写速度慢,价格便宜,容量大
- EMMC:多用于低端嵌入式设备,容量较小,云终端的EMMC有4GB、8GB、32GB几种规格
查看存储设备信息的命令
fdisk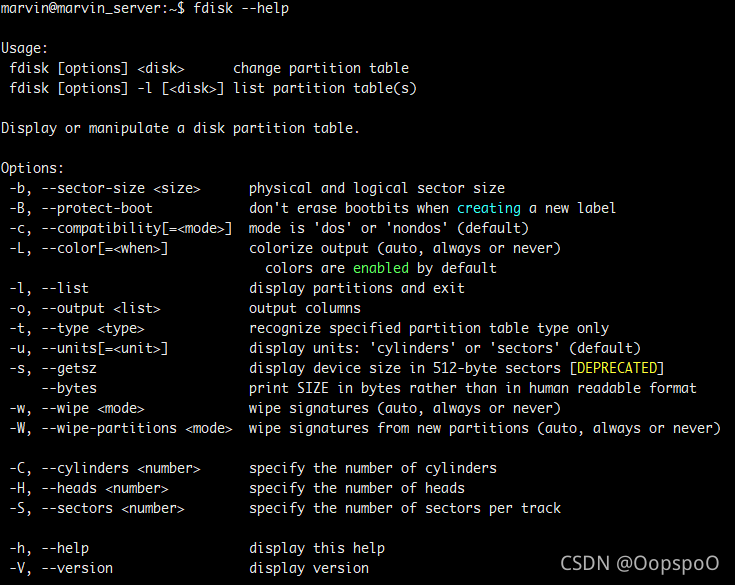
blkid
smartctlpartedlsblk
关键硬件器件——内存
目前最新是DDR4技术,速率可达3.2GHz
分为板载和插槽两种接口
云桌面的瘦终端采用1-2GB内存,胖终端标配4G或8GB内存,服务器一般是16GB*N的内存
查看内存的命令
freecat /proc/meminfo
其他一些查看硬件信息的命令
查看PCI设备信息:lspci
查看USB设备信息: lsusb
查看网卡信息:ifconfig、ethtool、ip
Linux开机过程(以Ubuntu16.04为例)
- 命令行中输入
systemd-analyze plot > boot.svg,用浏览器查看boot.svg 
- 从上图可看出开机过程包含了BIOS(firmware)、boot loader、kernel、systemd这4个阶段,再加上启动应用软件,共5个阶段

- 虚拟中运行的Ubuntu则没有BIOS(firmware)和boot loader这两个阶段。
阶段1:BIOS
BIOS是(Basic Input Output System),是一组固化到计算机内主板上一个ROM芯片上的程序。它保存着计算机最重要的基本输入输出的程序、系统设置信息、开机后自检程序和系统自启动程序。 其主要功能是为计算机提供最底层的、最直接的硬件设置和控制。X86架构才有BIOS,ARM架构没有BIOS
DMI
-
DMI (Desktop Management Interface)是帮助收集电脑系统信息的管理系统。通过DMI可以在Linux中查询到包括CPU、内存、
I/O扩展槽等在内的系统配置信息。DMI通常将上述信息存储在BIOS中一个4KB大小的DMI数据区中 -
云终端的产品ID、产品型号、硬件版本、SN都存储在DMI中,可通过
dmidecode命令查看。
BIOS与boot loader
- MBR与GPT
MBR:Master Boot Record,主引导扇区,它在硬盘上的三维地址为**(柱面,磁头,扇区)=(0,0,1)**。MBR中存放着boot loader(446字节)、分区表(64字节)和硬盘有效标志(55AA) 。MBR最多只能支持4个主分区,无法支持超过2T的硬盘。
GPT: GUID Partition Table ,是一个实体硬盘的分区结构。最多支持 128 个分区,允许大于 2 TB 的卷容量
Legacy BIOS 与UEFI BIOS
Legacy BIOS:传统BIOS。Legecy BIOS从MBR中寻找boot loader。目前云桌面的服务器大多还是用Legacy BIOS。
UEFI BIOS:只支持64位系统且磁盘分区必须为GPT模式,可引导大于2T的硬盘,更快的启动速度。 UEFI BIOS会自动搜索硬盘根目录的EFI目录,而boot loader就在EFI文件夹中。目前云终端都采用UEFI BIOS。
**总结:**BIOS从硬盘的特定位置寻找boot loader
阶段2:boot Loader
主要功能
- 提供选择菜单,让使用者选择不同的开机项
- 加载内核,启动操作系统
- 将开机管理功能转交其他boot loader负责
常见的boot loader有GRUB(GRand Unified Bootloader )、uboot、LILO,云桌面的终端和服务器都使用GRUB
为什么平时一般见不到BootLoader的界面?因为超时时间被设为0了,直接从默认的启动项启动
-
修改终端的grub超时时间:vim.tiny /boot/grub/custom.cfg,将第一行的set timeout=0改为set timeout=3
-
查看grub.cfg:vi /boot/grub/grub.cfg
修改grub配置以及grub配置文件的各种设置选项:
https://help.ubuntu.com/community/Grub2/Setup
https://www.jianshu.com/p/a24d51276a82
https://blog.csdn.net/mr_zing/article/details/41055617
https://blog.csdn.net/dc_show/article/details/47396649
https://blog.csdn.net/shana_8/article/details/81455657
gurb.cfg
grub.cfg中,会用到/boot/vmlinuz和/boot/initrd.img两个文件
vmlinuz是可引导的、压缩的内核。“vm”代表 “Virtual Memory”,z代表用gzip压缩
initrd.img是个RAM Disk(通过软件将一部分RAM模拟为硬盘的技术)的映像文件,里面包含了linux启动时需要的目录、可执行文件、内核驱动模块等。
阶段3:kernel

当前流行的Linux版本一般都采用模块化的内核,这种方式可以在不重新编译构建内核的情形下增加功能模块(ko)。但考虑一种场景,如果磁盘是EMMC的,但相应驱动没有编译进kernel,kernel就无法访问磁盘了,更谈不上加载ko了。这时候就需要用到RAM Disk技术了。
-
boot loader载入kernel和initrd.img到内存中 -
kernel启动后自解压,将
initrd.img的内容挂载为init根文件系统 -
kernel从init根文件系统中加载所需功能模块
-
kernel会根据
grub.cfg中“root=XXX”部分所指定的内容创建一个根设备,然后将根文件系统以只读的方式挂载,并切换到真正的根文件系统上 -
调用systemd程序,进入系统初始化阶段。
详细流程可以参考man initrd
Bootloader引导内核后,进入第三个阶段:内核。这边并不打算介绍内核的函数调用流程,因为目前我自己在工作中还没遇到需要解决的问题。今天想要介绍的是内核阶段可能存在两个根文件系统。
阶段4:systemd
systemd 是 Linux 系统中最新的初始化系统,它主要的设计目标是克服 sysv init 固有的缺点,提高系统的启动速度。
在硬件驱动成功后,kernel 会主动呼叫 systemd 。从右图可以看出,graphical.target、multi-user.tartget、basic.target、sysinit.target存在依次依赖的关系,systemd按照依赖关系并发启动target包含的服务后,完成图形界面的启动
rc-local.service会执行/etc/rc.local,自研脚本可以从/etc/rc.local中进行启动

阶段5:应用软件
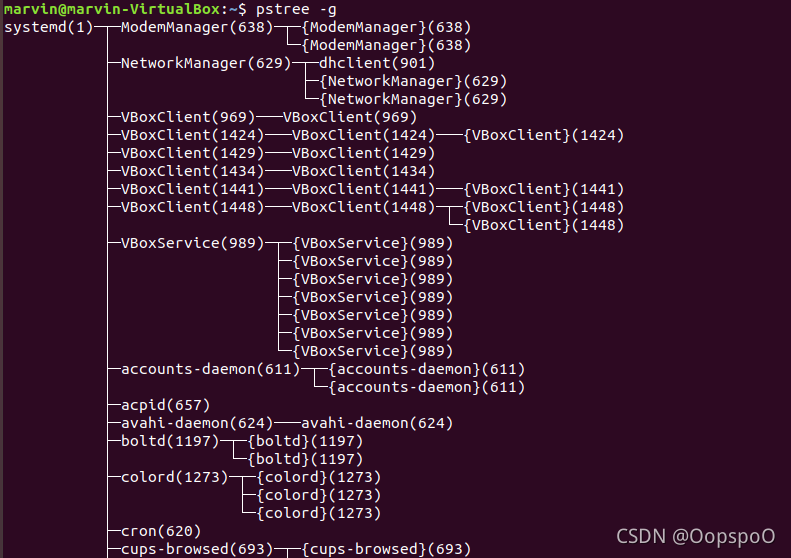
使用pstree可以查看进程树。可以看到systemd的PID为1,所有应用软件都是从systemd派生出来的
学习完linux开机的5个阶段,请大家思考下,我们学习这部分知识的目的是什么,能解决什么问题?
1 开机速度的优化
2 定位BUG在哪个阶段发生
3 调试,例如grub选择内核,编辑启动参数
4 功能开发,例如自研脚本的加入,systemd服务的编写
Linux常用命令
基本命令
文件管理
ls, mv, cp, rm, chown, chmod, mkdir, find, touch, ln
-
ls
ls [-alrtAFR] [name...] 参数 : -a 显示所有文件及目录 (ls内定将文件名或目录名称开头为"."的视为隐藏档,不会列出) -l 除文件名称外,亦将文件型态、权限、拥有者、文件大小等资讯详细列出 -r 将文件以相反次序显示(原定依英文字母次序) -t 将文件依建立时间之先后次序列出 -A 同 -a ,但不列出 "." (目前目录) 及 ".." (父目录) -F 在列出的文件名称后加一符号;例如可执行档则加 "*", 目录则加 "/" -R 若目录下有文件,则以下之文件亦皆依序列出 -
mv
mv [options] source dest mv [options] source... directory 参数说明: -i: 若指定目录已有同名文件,则先询问是否覆盖旧文件; -f: 在mv操作要覆盖某已有的目标文件时不给任何指示;-
mv参数设置与运行结果
命令格式 运行结果 mv 文件名 文件名 将源文件名改为目标文件名 mv 文件名 目录名 将文件移动到目标目录 mv 目录名 目录名 目标目录已存在,将源目录 移动到目标目录;目标 目录不存在则改名 mv 目录名 文件名 出错
-
-
cp
cp [options] source dest cp [options] source... directory 参数说明: -a:此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容。其作用等于dpR参数组合。 -d:复制时保留链接。这里所说的链接相当于Windows系统中的快捷方式。 -f:覆盖已经存在的目标文件而不给出提示。 -i:与-f选项相反,在覆盖目标文件之前给出提示,要求用户确认是否覆盖,回答"y"时目标文件将被覆盖。 -p:除复制文件的内容外,还把修改时间和访问权限也复制到新文件中。 -r:若给出的源文件是一个目录文件,此时将复制该目录下所有的子目录和文件。 -l:不复制文件,只是生成链接文件。 -
rm
rm [options] name... 参数: -i 删除前逐一询问确认。 -f 即使原档案属性设为唯读,亦直接删除,无需逐一确认。 -r 将目录及以下之档案亦逐一删除。 -
chown
chown [-cfhvR] [--help] [--version] user[:group] file... 参数 : user : 新的文件拥有者的使用者 ID group : 新的文件拥有者的使用者组(group) -c : 显示更改的部分的信息 -f : 忽略错误信息 -h :修复符号链接 -v : 显示详细的处理信息 -R : 处理指定目录以及其子目录下的所有文件 --help : 显示辅助说明 --version : 显示版本 实例 将文件 file1.txt 的拥有者设为 runoob,群体的使用者 runoobgroup : chown runoob:runoobgroup file1.txt 将目前目录下的所有文件与子目录的拥有者皆设为 runoob,群体的使用者 runoobgroup: chown -R runoob:runoobgroup * -
chmod
chmod [-cfvR] [--help] [--version] mode file... 参数说明 mode : 权限设定字串,格式如下 : [ugoa...][[+-=][rwxX]...][,...] 其中: u 表示该文件的拥有者,g 表示与该文件的拥有者属于同一个群体(group)者,o 表示其他以外的人,a 表示这三者皆是。 + 表示增加权限、- 表示取消权限、= 表示唯一设定权限。 r 表示可读取,w 表示可写入,x 表示可执行,X 表示只有当该文件是个子目录或者该文件已经被设定过为可执行。 其他参数说明: -c : 若该文件权限确实已经更改,才显示其更改动作 -f : 若该文件权限无法被更改也不要显示错误讯息 -v : 显示权限变更的详细资料 -R : 对目前目录下的所有文件与子目录进行相同的权限变更(即以递回的方式逐个变更) --help : 显示辅助说明 --version : 显示版本 实例 将文件 file1.txt 设为所有人皆可读取: chmod ugo+r file1.txt 将文件 file1.txt 设为所有人皆可读取: chmod a+r file1.txt 将文件 file1.txt 与 file2.txt 设为该文件拥有者,与其所属同一个群体者可写入,但其他以外的人则不可写入 : chmod ug+w,o-w file1.txt file2.txt 将 ex1.py 设定为只有该文件拥有者可以执行: chmod u+x ex1.py 将目前目录下的所有文件与子目录皆设为任何人可读取: chmod -R a+r * 此外chmod也可以用数字来表示权限如: chmod 777 file 语法为: chmod abc file 其中a,b,c各为一个数字,分别表示User、Group、及Other的权限。 r=4,w=2,x=1 若要rwx属性则4+2+1=7; 若要rw-属性则4+2=6; 若要r-x属性则4+1=5。 chmod a=rwx file 和 chmod 777 file 效果相同 chmod ug=rwx,o=x file 和 chmod 771 file 效果相同 若用chmod 4755 filename可使此程序具有root的权限 -
mkdir
mkdir [-p] dirName 参数说明: -p 确保目录名称存在,不存在的就建一个。 实例 在工作目录下,建立一个名为 AAA 的子目录 : mkdir AAA 在工作目录下的 BBB 目录中,建立一个名为 Test 的子目录。 若 BBB 目录原本不存在,则建立一个。(注:本例若不加 -p,且原本 BBB目录不存在,则产生错误。) mkdir -p BBB/Test -
find
find path -option [ -print ] [ -exec -ok command ] {} \; 参数说明 : find 根据下列规则判断 path 和 expression,在命令列上第一个 - ( ) , ! 之前的部份为 path,之后的是 expression。如果 path 是空字串则使用目前路径,如果 expression 是空字串则使用 -print 为预设 expression。 expression 中可使用的选项有二三十个之多,在此只介绍最常用的部份。 -mount, -xdev : 只检查和指定目录在同一个文件系统下的文件,避免列出其它文件系统中的文件 -amin n : 在过去 n 分钟内被读取过 -anewer file : 比文件 file 更晚被读取过的文件 -atime n : 在过去n天内被读取过的文件 -cmin n : 在过去 n 分钟内被修改过 -cnewer file :比文件 file 更新的文件 -ctime n : 在过去n天内被修改过的文件 -empty : 空的文件-gid n or -group name : gid 是 n 或是 group 名称是 name -ipath p, -path p : 路径名称符合 p 的文件,ipath 会忽略大小写 -name name, -iname name : 文件名称符合 name 的文件。iname 会忽略大小写 -size n : 文件大小 是 n 单位,b 代表 512 位元组的区块,c 表示字元数,k 表示 kilo bytes,w 是二个位元组。-type c : 文件类型是 c 的文件。 d: 目录 c: 字型装置文件 b: 区块装置文件 p: 具名贮列 f: 一般文件 l: 符号连结 s: socket -pid n : process id 是 n 的文件 你可以使用 ( ) 将运算式分隔,并使用下列运算。 exp1 -and exp2 ! expr -not expr exp1 -or exp2 exp1, exp2 实例 将目前目录及其子目录下所有延伸档名是 c 的文件列出来。 # find . -name "*.c" 将目前目录其其下子目录中所有一般文件列出 # find . -type f 将目前目录及其子目录下所有最近 20 天内更新过的文件列出 # find . -ctime -20 查找/var/log目录中更改时间在7日以前的普通文件,并在删除之前询问它们: # find /var/log -type f -mtime +7 -ok rm {} \; 查找前目录中文件属主具有读、写权限,并且文件所属组的用户和其他用户具有读权限的文件: # find . -type f -perm 644 -exec ls -l {} \; 为了查找系统中所有文件长度为0的普通文件,并列出它们的完整路径: # find / -type f -size 0 -exec ls -l {} \; -
touch
touch [-acfm][-d<日期时间>][-r<参考文件或目录>] [-t<日期时间>][--help][--version][文件或目录…] 参数说明: a 改变档案的读取时间记录。 m 改变档案的修改时间记录。 c 假如目的档案不存在,不会建立新的档案。与 --no-create 的效果一样。 f 不使用,是为了与其他 unix 系统的相容性而保留。 r 使用参考档的时间记录,与 --file 的效果一样。 d 设定时间与日期,可以使用各种不同的格式。 t 设定档案的时间记录,格式与 date 指令相同。 --no-create 不会建立新档案。 --help 列出指令格式。 --version 列出版本讯息。 实例 使用指令"touch"修改文件"testfile"的时间属性为当前系统时间,输入如下命令: $ touch testfile #修改文件的时间属性 首先,使用ls命令查看testfile文件的属性,如下所示: $ ls -l testfile #查看文件的时间属性 #原来文件的修改时间为16:09 -rw-r--r-- 1 hdd hdd 55 2011-08-22 16:09 testfile 执行指令"touch"修改文件属性以后,并再次查看该文件的时间属性,如下所示: $ touch testfile #修改文件时间属性为当前系统时间 $ ls -l testfile #查看文件的时间属性 #修改后文件的时间属性为当前系统时间 -rw-r--r-- 1 hdd hdd 55 2011-08-22 19:53 testfile 使用指令"touch"时,如果指定的文件不存在,则将创建一个新的空白文件。例如,在当前目录下,使用该指令创建一个空白文件"file",输入如下命令: $ touch file #创建一个名为“file”的新的空白文件 -
ln
ln [参数][源文件或目录][目标文件或目录] 其中参数的格式为 [-bdfinsvF] [-S backup-suffix] [-V {numbered,existing,simple}] [--help] [--version] [--] 命令功能 : Linux文件系统中,有所谓的链接(link),我们可以将其视为档案的别名,而链接又可分为两种 : 硬链接(hard link)与软链接(symbolic link),硬链接的意思是一个档案可以有多个名称,而软链接的方式则是产生一个特殊的档案,该档案的内容是指向另一个档案的位置。硬链接是存在同一个文件系统中,而软链接却可以跨越不同的文件系统。 不论是硬链接或软链接都不会将原本的档案复制一份,只会占用非常少量的磁碟空间。 软链接: 1.软链接,以路径的形式存在。类似于Windows操作系统中的快捷方式 2.软链接可以 跨文件系统 ,硬链接不可以 3.软链接可以对一个不存在的文件名进行链接 4.软链接可以对目录进行链接 硬链接: 1.硬链接,以文件副本的形式存在。但不占用实际空间。 2.不允许给目录创建硬链接 3.硬链接只有在同一个文件系统中才能创建 命令参数 必要参数: -b 删除,覆盖以前建立的链接 -d 允许超级用户制作目录的硬链接 -f 强制执行 -i 交互模式,文件存在则提示用户是否覆盖 -n 把符号链接视为一般目录 -s 软链接(符号链接) -v 显示详细的处理过程 选择参数: -S "-S<字尾备份字符串> "或 "--suffix=<字尾备份字符串>" -V "-V<备份方式>"或"--version-control=<备份方式>" --help 显示帮助信息 --version 显示版本信息 实例 给文件创建软链接,为log2013.log文件创建软链接link2013,如果log2013.log丢失,link2013将失效: ln -s log2013.log link2013 输出: [root@localhost test]# ll -rw-r--r-- 1 root bin 61 11-13 06:03 log2013.log [root@localhost test]# ln -s log2013.log link2013 [root@localhost test]# ll lrwxrwxrwx 1 root root 11 12-07 16:01 link2013 -> log2013.log -rw-r--r-- 1 root bin 61 11-13 06:03 log2013.log 给文件创建硬链接,为log2013.log创建硬链接ln2013,log2013.log与ln2013的各项属性相同 ln log2013.log ln2013 输出: [root@localhost test]# ll lrwxrwxrwx 1 root root 11 12-07 16:01 link2013 -> log2013.log -rw-r--r-- 1 root bin 61 11-13 06:03 log2013.log [root@localhost test]# ln log2013.log ln2013 [root@localhost test]# ll lrwxrwxrwx 1 root root 11 12-07 16:01 link2013 -> log2013.log -rw-r--r-- 2 root bin 61 11-13 06:03 ln2013 -rw-r--r-- 2 root bin 61 11-13 06:03 log2013.log
文本操作
grep, cat, wc, cut, awk, sed, tr
-
grep
grep 命令用于查找文件里符合条件的字符串。 grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。 语法 grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...] 参数: -a 或 --text : 不要忽略二进制的数据。 -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。 -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。 -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。 -c 或 --count : 计算符合样式的列数。 -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。 -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。 -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。 -E 或 --extended-regexp : 将样式为延伸的普通表示法来使用。 -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。 -F 或 --fixed-regexp : 将样式视为固定字符串的列表。 -G 或 --basic-regexp : 将样式视为普通的表示法来使用。 -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。 -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。 -i 或 --ignore-case : 忽略字符大小写的差别。 -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。 -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。 -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。 -o 或 --only-matching : 只显示匹配PATTERN 部分。 -q 或 --quiet或--silent : 不显示任何信息。 -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。 -s 或 --no-messages : 不显示错误信息。 -v 或 --revert-match : 显示不包含匹配文本的所有行。 -V 或 --version : 显示版本信息。 -w 或 --word-regexp : 只显示全字符合的列。 -x --line-regexp : 只显示全列符合的列。 -y : 此参数的效果和指定"-i"参数相同。 实例 1、在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令: grep test *file 结果如下所示: $ grep test test* #查找前缀有“test”的文件包含“test”字符串的文件 testfile1:This a Linux testfile! #列出testfile1 文件中包含test字符的行 testfile_2:This is a linux testfile! #列出testfile_2 文件中包含test字符的行 testfile_2:Linux test #列出testfile_2 文件中包含test字符的行 2、以递归的方式查找符合条件的文件。例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串"update"的文件,并打印出该字符串所在行的内容,使用的命令为: grep -r update /etc/acpi 输出结果如下: $ grep -r update /etc/acpi #以递归的方式查找“etc/acpi” /etc/acpi/events/thinkpad-cmos:action=/usr/sbin/thinkpad-keys--update 3、反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容。 查找文件名中包含 test 的文件中不包含test 的行,此时,使用的命令为: grep -v test *test* 结果如下所示: $ grep-v test* #查找文件名中包含test 的文件中不包含test 的行 testfile1:helLinux! testfile1:Linis a free Unix-type operating system. testfile1:Lin testfile_1:HELLO LINUX! testfile_1:LINUX IS A FREE UNIX-TYPE OPTERATING SYSTEM. testfile_1:THIS IS A LINUX TESTFILE! testfile_2:HELLO LINUX! testfile_2:Linux is a free unix-type opterating system. -
cat
cat [-AbeEnstTuv] [--help] [--version] fileName 参数说明: -n 或 --number:由 1 开始对所有输出的行数编号。 -b 或 --number-nonblank:和 -n 相似,只不过对于空白行不编号。 -s 或 --squeeze-blank:当遇到有连续两行以上的空白行,就代换为一行的空白行。 -v 或 --show-nonprinting:使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外。 -E 或 --show-ends : 在每行结束处显示 $。 -T 或 --show-tabs: 将 TAB 字符显示为 ^I。 -A, --show-all:等价于 -vET。 -e:等价于"-vE"选项; -t:等价于"-vT"选项; 实例: 把 textfile1 的文档内容加上行号后输入 textfile2 这个文档里: cat -n textfile1 > textfile2 把 textfile1 和 textfile2 的文档内容加上行号(空白行不加)之后将内容附加到 textfile3 文档里: cat -b textfile1 textfile2 >> textfile3 清空 /etc/test.txt 文档内容: cat /dev/null > /etc/test.txt cat 也可以用来制作镜像文件。例如要制作软盘的镜像文件,将软盘放好后输入: cat /dev/fd0 > OUTFILE 相反的,如果想把 image file 写到软盘,输入: cat IMG_FILE > /dev/fd0 注: 1. OUTFILE 指输出的镜像文件名。 2. IMG_FILE 指镜像文件。 3. 若从镜像文件写回 device 时,device 容量需与相当。 4. 通常用制作开机磁片。 -
wc
Linux wc命令用于计算字数。 利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。 语法 wc [-clw][--help][--version][文件...] 参数: -c或--bytes或--chars 只显示Bytes数。 -l或--lines 只显示行数。 -w或--words 只显示字数。 --help 在线帮助。 --version 显示版本信息。 实例 在默认的情况下,wc将计算指定文件的行数、字数,以及字节数。使用的命令为: wc testfile 先查看testfile文件的内容,可以看到: $ cat testfile Linux networks are becoming more and more common, but scurity is often an overlooked issue. Unfortunately, in today’s environment all networks are potential hacker targets, fro0m tp-secret military research networks to small home LANs. Linux Network Securty focuses on securing Linux in a networked environment, where the security of the entire network needs to be considered rather than just isolated machines. It uses a mix of theory and practicl techniques to teach administrators how to install and use security applications, as well as how the applcations work and why they are necesary. 使用 wc统计,结果如下: $ wc testfile # testfile文件的统计信息 3 92 598 testfile # testfile文件的行数为3、单词数92、字节数598 其中,3 个数字分别表示testfile文件的行数、单词数,以及该文件的字节数。 如果想同时统计多个文件的信息,例如同时统计testfile、testfile_1、testfile_2,可使用如下命令: wc testfile testfile_1 testfile_2 #统计三个文件的信息 输出结果如下: $ wc testfile testfile_1 testfile_2 #统计三个文件的信息 3 92 598 testfile #第一个文件行数为3、单词数92、字节数598 9 18 78 testfile_1 #第二个文件的行数为9、单词数18、字节数78 3 6 32 testfile_2 #第三个文件的行数为3、单词数6、字节数32 15 116 708 总用量 #三个文件总共的行数为15、单词数116、字节数708 -
cut
Linux cut命令用于显示每行从开头算起 num1 到 num2 的文字。 语法 cut [-bn] [file] cut [-c] [file] cut [-df] [file] 使用说明: cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。 如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。 参数: -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。 -c :–characters=列表 只选中指定的这些字符以字符为单位进行分割。 -d : –delimiter=分界符 使用指定分界符代替制表符作为区域分界,默认为制表符。 -f :–fields=LIST与-d一起使用,指定显示哪个区域。 -n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的范围之内,该字符将被写出;否则,该字符将被排除 实例 当你执行who命令时,会输出类似如下的内容: $ who rocrocket :0 2009-01-08 11:07 rocrocket pts/0 2009-01-08 11:23 (:0.0) rocrocket pts/1 2009-01-08 14:15 (:0.0) 如果我们想提取每一行的第3个字节,就这样: $ who|cut -b 3 c c //显示查询结果的 1-10个字符 ll | cut -c 1-10 //显示用空格切割后的 第一个元素 ll | cut -d ' ' -f 1 history |uniq|cut -c 8-999 #截取8到999位的内容 cat /etc/passwd|awk 'NR==1' |cut -c 1,8,10,15,22- #过滤passwd密码第一行,截取指定位置,22- 为22位以后所有字符,-10为10位之前 -
awk
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。 之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。 语法 awk [选项参数] 'script' var=value file(s) 或 awk [选项参数] -f scriptfile var=value file(s) 选项参数说明: -F fs or --field-separator fs 指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。 -v var=value or --asign var=value 赋值一个用户定义变量。 -f scripfile or --file scriptfile 从脚本文件中读取awk命令。 -mf nnn and -mr nnn 对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。 -W compact or --compat, -W traditional or --traditional 在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。 -W copyleft or --copyleft, -W copyright or --copyright 打印简短的版权信息。 -W help or --help, -W usage or --usage 打印全部awk选项和每个选项的简短说明。 -W lint or --lint 打印不能向传统unix平台移植的结构的警告。 -W lint-old or --lint-old 打印关于不能向传统unix平台移植的结构的警告。 -W posix 打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。 -W re-interval or --re-inerval 允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。 -W source program-text or --source program-text 使用program-text作为源代码,可与-f命令混用。 -W version or --version 打印bug报告信息的版本。 基本用法 log.txt文本内容如下: 2 this is a test 3 Are you like awk This's a test 10 There are orange,apple,mongo 用法一: awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号 实例: # 每行按空格或TAB分割,输出文本中的1、4项 $ awk '{print $1,$4}' log.txt --------------------------------------------- 2 a 3 like This's 10 orange,apple,mongo # 格式化输出 $ awk '{printf "%-8s %-10s\n",$1,$4}' log.txt --------------------------------------------- 2 a 3 like This's 10 orange,apple,mongo 用法二: awk -F #-F相当于内置变量FS, 指定分割字符 实例: # 使用","分割 $ awk -F, '{print $1,$2}' log.txt --------------------------------------------- 2 this is a test 3 Are you like awk This's a test 10 There are orange apple # 或者使用内建变量 $ awk 'BEGIN{FS=","} {print $1,$2}' log.txt --------------------------------------------- 2 this is a test 3 Are you like awk This's a test 10 There are orange apple # 使用多个分隔符.先使用空格分割,然后对分割结果再使用","分割 $ awk -F '[ ,]' '{print $1,$2,$5}' log.txt --------------------------------------------- 2 this test 3 Are awk This's a 10 There apple 用法三: awk -v # 设置变量 实例: $ awk -va=1 '{print $1,$1+a}' log.txt --------------------------------------------- 2 3 3 4 This's 1 10 11 $ awk -va=1 -vb=s '{print $1,$1+a,$1b}' log.txt --------------------------------------------- 2 3 2s 3 4 3s This's 1 This'ss 10 11 10s 用法四: awk -f {awk脚本} {文件名} 实例: $ awk -f cal.awk log.txthttps://www.runoob.com/linux/linux-comm-awk.html
-
sed
Linux sed 命令是利用脚本来处理文本文件。 sed 可依照脚本的指令来处理、编辑文本文件。 Sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。 语法 sed [-hnV][-e<script>][-f<script文件>][文本文件] 参数说明: -e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。 -f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。 -h或--help 显示帮助。 -n或--quiet或--silent 仅显示script处理后的结果。 -V或--version 显示版本信息。 动作说明: a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~ c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行! d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚; i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行); p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~ s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦! 实例 在testfile文件的第四行后添加一行,并将结果输出到标准输出,在命令行提示符下输入如下命令: sed -e 4a\newLine testfile 首先查看testfile中的内容如下: $ cat testfile #查看testfile 中的内容 HELLO LINUX! Linux is a free unix-type opterating system. This is a linux testfile! Linux test 使用sed命令后,输出结果如下: $ sed -e 4a\newline testfile #使用sed 在第四行后添加新字符串 HELLO LINUX! #testfile文件原有的内容 Linux is a free unix-type opterating system. This is a linux testfile! Linux test newline 以行为单位的新增/删除 将 /etc/passwd 的内容列出并且列印行号,同时,请将第 2~5 行删除! [root@www ~]# nl /etc/passwd | sed '2,5d' 1 root:x:0:0:root:/root:/bin/bash 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown .....(后面省略)..... sed 的动作为 '2,5d' ,那个 d 就是删除!因为 2-5 行给他删除了,所以显示的数据就没有 2-5 行罗~ 另外,注意一下,原本应该是要下达 sed -e 才对,没有 -e 也行啦!同时也要注意的是, sed 后面接的动作,请务必以 '' 两个单引号括住喔! 只要删除第 2 行 nl /etc/passwd | sed '2d' 要删除第 3 到最后一行 nl /etc/passwd | sed '3,$d' 在第二行后(亦即是加在第三行)加上『drink tea?』字样! [root@www ~]# nl /etc/passwd | sed '2a drink tea' 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin drink tea 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin .....(后面省略)..... 那如果是要在第二行前 nl /etc/passwd | sed '2i drink tea' 如果是要增加两行以上,在第二行后面加入两行字,例如 Drink tea or ..... 与 drink beer? [root@www ~]# nl /etc/passwd | sed '2a Drink tea or ......\ > drink beer ?' 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin Drink tea or ...... drink beer ? 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin .....(后面省略)..... 每一行之间都必须要以反斜杠『 \ 』来进行新行的添加喔!所以,上面的例子中,我们可以发现在第一行的最后面就有 \ 存在。 以行为单位的替换与显示 将第2-5行的内容取代成为『No 2-5 number』呢? [root@www ~]# nl /etc/passwd | sed '2,5c No 2-5 number' 1 root:x:0:0:root:/root:/bin/bash No 2-5 number 6 sync:x:5:0:sync:/sbin:/bin/sync .....(后面省略)..... 透过这个方法我们就能够将数据整行取代了! 仅列出 /etc/passwd 文件内的第 5-7 行 [root@www ~]# nl /etc/passwd | sed -n '5,7p' 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 可以透过这个 sed 的以行为单位的显示功能, 就能够将某一个文件内的某些行号选择出来显示。 数据的搜寻并显示 搜索 /etc/passwd有root关键字的行 nl /etc/passwd | sed '/root/p' 1 root:x:0:0:root:/root:/bin/bash 1 root:x:0:0:root:/root:/bin/bash 2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh 3 bin:x:2:2:bin:/bin:/bin/sh 4 sys:x:3:3:sys:/dev:/bin/sh 5 sync:x:4:65534:sync:/bin:/bin/sync ....下面忽略 如果root找到,除了输出所有行,还会输出匹配行。 使用-n的时候将只打印包含模板的行。 nl /etc/passwd | sed -n '/root/p' 1 root:x:0:0:root:/root:/bin/bash 数据的搜寻并删除 删除/etc/passwd所有包含root的行,其他行输出 nl /etc/passwd | sed '/root/d' 2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh 3 bin:x:2:2:bin:/bin:/bin/sh ....下面忽略 #第一行的匹配root已经删除了 数据的搜寻并执行命令 搜索/etc/passwd,找到root对应的行,执行后面花括号中的一组命令,每个命令之间用分号分隔,这里把bash替换为blueshell,再输出这行: nl /etc/passwd | sed -n '/root/{s/bash/blueshell/;p;q}' 1 root:x:0:0:root:/root:/bin/blueshell 最后的q是退出。 数据的搜寻并替换 除了整行的处理模式之外, sed 还可以用行为单位进行部分数据的搜寻并取代。基本上 sed 的搜寻与替代的与 vi 相当的类似!他有点像这样: sed 's/要被取代的字串/新的字串/g' 先观察原始信息,利用 /sbin/ifconfig 查询 IP [root@www ~]# /sbin/ifconfig eth0 eth0 Link encap:Ethernet HWaddr 00:90:CC:A6:34:84 inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0 inet6 addr: fe80::290:ccff:fea6:3484/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 .....(以下省略)..... 本机的ip是192.168.1.100。 将 IP 前面的部分予以删除 [root@www ~]# /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g' 192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0 接下来则是删除后续的部分,亦即: 192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0 将 IP 后面的部分予以删除 [root@www ~]# /sbin/ifconfig eth0 | grep 'inet addr' | sed 's/^.*addr://g' | sed 's/Bcast.*$//g' 192.168.1.100 多点编辑 一条sed命令,删除/etc/passwd第三行到末尾的数据,并把bash替换为blueshell nl /etc/passwd | sed -e '3,$d' -e 's/bash/blueshell/' 1 root:x:0:0:root:/root:/bin/blueshell 2 daemon:x:1:1:daemon:/usr/sbin:/bin/sh -e表示多点编辑,第一个编辑命令删除/etc/passwd第三行到末尾的数据,第二条命令搜索bash替换为blueshell。 直接修改文件内容(危险动作) sed 可以直接修改文件的内容,不必使用管道命令或数据流重导向! 不过,由於这个动作会直接修改到原始的文件,所以请你千万不要随便拿系统配置来测试! 我们还是使用文件 regular_express.txt 文件来测试看看吧! regular_express.txt 文件内容如下: [root@www ~]# cat regular_express.txt runoob. google. taobao. facebook. zhihu- weibo- 利用 sed 将 regular_express.txt 内每一行结尾若为 . 则换成 ! [root@www ~]# sed -i 's/\.$/\!/g' regular_express.txt [root@www ~]# cat regular_express.txt runoob! google! taobao! facebook! zhihu- weibo- :q:q 利用 sed 直接在 regular_express.txt 最后一行加入 # This is a test: [root@www ~]# sed -i '$a # This is a test' regular_express.txt [root@www ~]# cat regular_express.txt runoob! google! taobao! facebook! zhihu- weibo- # This is a test 由於 $ 代表的是最后一行,而 a 的动作是新增,因此该文件最后新增 # This is a test! sed 的 -i 选项可以直接修改文件内容,这功能非常有帮助!举例来说,如果你有一个 100 万行的文件,你要在第 100 行加某些文字,此时使用 vim 可能会疯掉!因为文件太大了!那怎办?就利用 sed 啊!透过 sed 直接修改/取代的功能,你甚至不需要使用 vim 去修订! -
tr
Linux tr 命令用于转换或删除文件中的字符。 tr 指令从标准输入设备读取数据,经过字符串转译后,将结果输出到标准输出设备。 语法 tr [-cdst][--help][--version][第一字符集][第二字符集] tr [OPTION]…SET1[SET2] 参数说明: -c, --complement:反选设定字符。也就是符合 SET1 的部份不做处理,不符合的剩余部份才进行转换 -d, --delete:删除指令字符 -s, --squeeze-repeats:缩减连续重复的字符成指定的单个字符 -t, --truncate-set1:削减 SET1 指定范围,使之与 SET2 设定长度相等 --help:显示程序用法信息 --version:显示程序本身的版本信息 字符集合的范围: \NNN 八进制值的字符 NNN (1 to 3 为八进制值的字符) \\ 反斜杠 \a Ctrl-G 铃声 \b Ctrl-H 退格符 \f Ctrl-L 走行换页 \n Ctrl-J 新行 \r Ctrl-M 回车 \t Ctrl-I tab键 \v Ctrl-X 水平制表符 CHAR1-CHAR2 :字符范围从 CHAR1 到 CHAR2 的指定,范围的指定以 ASCII 码的次序为基础,只能由小到大,不能由大到小。 [CHAR*] :这是 SET2 专用的设定,功能是重复指定的字符到与 SET1 相同长度为止 [CHAR*REPEAT] :这也是 SET2 专用的设定,功能是重复指定的字符到设定的 REPEAT 次数为止(REPEAT 的数字采 8 进位制计算,以 0 为开始) [:alnum:] :所有字母字符与数字 [:alpha:] :所有字母字符 [:blank:] :所有水平空格 [:cntrl:] :所有控制字符 [:digit:] :所有数字 [:graph:] :所有可打印的字符(不包含空格符) [:lower:] :所有小写字母 [:print:] :所有可打印的字符(包含空格符) [:punct:] :所有标点字符 [:space:] :所有水平与垂直空格符 [:upper:] :所有大写字母 [:xdigit:] :所有 16 进位制的数字 [=CHAR=] :所有符合指定的字符(等号里的 CHAR,代表你可自订的字符) 实例 将文件testfile中的小写字母全部转换成大写字母,此时,可使用如下命令: cat testfile |tr a-z A-Z testfile文件中的内容如下: $ cat testfile #testfile原来的内容 Linux networks are becoming more and more common, but scurity is often an overlooked issue. Unfortunately, in today’s environment all networks are potential hacker targets, fro0m tp-secret military research networks to small home LANs. Linux Network Securty focuses on securing Linux in a networked environment, where the security of the entire network needs to be considered rather than just isolated machines. It uses a mix of theory and practicl techniques to teach administrators how to install and use security applications, as well as how the applcations work and why they are necesary. 使用 tr 命令大小写转换后,得到如下输出结果: $ cat testfile | tr a-z A-Z #转换后的输出 LINUX NETWORKS ARE BECOMING MORE AND MORE COMMON, BUT SCURITY IS OFTEN AN OVERLOOKED ISSUE. UNFORTUNATELY, IN TODAY’S ENVIRONMENT ALL NETWORKS ARE POTENTIAL HACKER TARGETS, FROM TP-SECRET MILITARY RESEARCH NETWORKS TO SMALL HOME LANS. LINUX NETWORK SECURTY FOCUSES ON SECURING LINUX IN A NETWORKED ENVIRONMENT, WHERE THE SECURITY OF THE ENTIRE NETWORK NEEDS TO BE CONSIDERED RATHER THAN JUST ISOLATED MACHINES. IT USES A MIX OF THEORY AND PRACTICL TECHNIQUES TO TEACH ADMINISTRATORS HOW TO INSTALL AND USE SECURITY APPLICATIONS, AS WELL AS HOW THE APPLCATIONS WORK AND WHY THEY ARE NECESARY. 大小写转换,也可以通过[:lower][:upper]参数来实现。例如使用如下命令: cat testfile |tr [:lower:] [:upper:] 输出结果如下: $ cat testfile | tr [:lower:] [:upper:] #转换后的输出 LINUX NETWORKS ARE BECOMING MORE AND MORE COMMON, BUT SCURITY IS OFTEN AN OVERLOOKED ISSUE. UNFORTUNATELY, IN TODAY’S ENVIRONMENT ALL NETWORKS ARE POTENTIAL HACKER TARGETS, FROM TP-SECRET MILITARY RESEARCH NETWORKS TO SMALL HOME LANS. LINUX NETWORK SECURTY FOCUSES ON SECURING LINUX IN A NETWORKED ENVIRONMENT, WHERE THE SECURITY OF THE ENTIRE NETWORK NEEDS TO BE CONSIDERED RATHER THAN JUST ISOLATED MACHINES. IT USES A MIX OF THEORY AND PRACTICL TECHNIQUES TO TEACH ADMINISTRATORS HOW TO INSTALL AND USE SECURITY APPLICATIONS, AS WELL AS HOW THE APPLCATIONS WORK AND WHY THEY ARE NECESARY.
磁盘管理
cd, pwd, df, du, dd, fdisk, mount/umount, mkfs
-
cd
cd [dirName] dirName:要切换的目标目录。 实例 跳到 /usr/bin/ : cd /usr/bin 跳到自己的 home 目录 : cd ~ 跳到目前目录的上上两层 : cd ../.. -
pwd
pwd [--help][--version] 参数说明: --help 在线帮助。 --version 显示版本信息。 -
df
Linux df命令用于显示目前在Linux系统上的文件系统的磁盘使用情况统计。 语法 df [选项]... [FILE]... 文件-a, --all 包含所有的具有 0 Blocks 的文件系统 文件--block-size={SIZE} 使用 {SIZE} 大小的 Blocks 文件-h, --human-readable 使用人类可读的格式(预设值是不加这个选项的...) 文件-H, --si 很像 -h, 但是用 1000 为单位而不是用 1024 文件-i, --inodes 列出 inode 资讯,不列出已使用 block 文件-k, --kilobytes 就像是 --block-size=1024 文件-l, --local 限制列出的文件结构 文件-m, --megabytes 就像 --block-size=1048576 文件--no-sync 取得资讯前不 sync (预设值) 文件-P, --portability 使用 POSIX 输出格式 文件--sync 在取得资讯前 sync 文件-t, --type=TYPE 限制列出文件系统的 TYPE 文件-T, --print-type 显示文件系统的形式 文件-x, --exclude-type=TYPE 限制列出文件系统不要显示 TYPE 文件-v (忽略) 文件--help 显示这个帮手并且离开 文件--version 输出版本资讯并且离开 显示文件系统的磁盘使用情况统计: # df Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda6 29640780 4320704 23814388 16% / udev 1536756 4 1536752 1% /dev tmpfs 617620 888 616732 1% /run none 5120 0 5120 0% /run/lock none 1544044 156 1543888 1% /run/shm 第一列指定文件系统的名称,第二列指定一个特定的文件系统1K-块1K是1024字节为单位的总内存。用和可用列正在使用中,分别指定的内存量。 使用列指定使用的内存的百分比,而最后一栏"安装在"指定的文件系统的挂载点。 df也可以显示磁盘使用的文件系统信息: # df test Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda6 29640780 4320600 23814492 16% / 用一个-i选项的df命令的输出显示inode信息而非块使用量。 df -i Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sda6 1884160 261964 1622196 14% / udev 212748 560 212188 1% /dev tmpfs 216392 477 215915 1% /run none 216392 3 216389 1% /run/lock none 216392 8 216384 1% /run/shm 显示所有的信息: # df --total Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda6 29640780 4320720 23814372 16% / udev 1536756 4 1536752 1% /dev tmpfs 617620 892 616728 1% /run none 5120 0 5120 0% /run/lock none 1544044 156 1543888 1% /run/shm total 33344320 4321772 27516860 14% 我们看到输出的末尾,包含一个额外的行,显示总的每一列。 -h选项,通过它可以产生可读的格式df命令的输出: # df -h Filesystem Size Used Avail Use% Mounted on /dev/sda6 29G 4.2G 23G 16% / udev 1.5G 4.0K 1.5G 1% /dev tmpfs 604M 892K 603M 1% /run none 5.0M 0 5.0M 0% /run/lock none 1.5G 156K 1.5G 1% /run/shm 我们可以看到输出显示的数字形式的'G'(千兆字节),"M"(兆字节)和"K"(千字节)。 这使输出容易阅读和理解,从而使显示可读的。请注意,第二列的名称也发生了变化,为了使显示可读的"大小"。 -
du
Linux du命令用于显示目录或文件的大小。 du会显示指定的目录或文件所占用的磁盘空间。 语法 du [-abcDhHklmsSx][-L <符号连接>][-X <文件>][--block-size][--exclude=<目录或文件>][--max-depth=<目录层数>][--help][--version][目录或文件] 参数说明: -a或-all 显示目录中个别文件的大小。 -b或-bytes 显示目录或文件大小时,以byte为单位。 -c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。 -D或--dereference-args 显示指定符号连接的源文件大小。 -h或--human-readable 以K,M,G为单位,提高信息的可读性。 -H或--si 与-h参数相同,但是K,M,G是以1000为换算单位。 -k或--kilobytes 以1024 bytes为单位。 -l或--count-links 重复计算硬件连接的文件。 -L<符号连接>或--dereference<符号连接> 显示选项中所指定符号连接的源文件大小。 -m或--megabytes 以1MB为单位。 -s或--summarize 仅显示总计。 -S或--separate-dirs 显示个别目录的大小时,并不含其子目录的大小。 -x或--one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。 -X<文件>或--exclude-from=<文件> 在<文件>指定目录或文件。 --exclude=<目录或文件> 略过指定的目录或文件。 --max-depth=<目录层数> 超过指定层数的目录后,予以忽略。 --help 显示帮助。 --version 显示版本信息。 实例 显示目录或者文件所占空间: # du 608 ./test6 308 ./test4 4 ./scf/lib 4 ./scf/service/deploy/product 4 ./scf/service/deploy/info 12 ./scf/service/deploy 16 ./scf/service 4 ./scf/doc 4 ./scf/bin 32 ./scf 8 ./test3 1288 . 只显示当前目录下面的子目录的目录大小和当前目录的总的大小,最下面的1288为当前目录的总大小 显示指定文件所占空间 # du log2012.log 300 log2012.log 方便阅读的格式显示test目录所占空间情况: # du -h test 608K test/test6 308K test/test4 4.0K test/scf/lib 4.0K test/scf/service/deploy/product 4.0K test/scf/service/deploy/info 12K test/scf/service/deploy 16K test/scf/service 4.0K test/scf/doc 4.0K test/scf/bin 32K test/scf 8.0K test/test3 1.3M test -
dd
Linux dd命令用于读取、转换并输出数据。 dd可从标准输入或文件中读取数据,根据指定的格式来转换数据,再输出到文件、设备或标准输出。 参数说明: if=文件名:输入文件名,默认为标准输入。即指定源文件。 of=文件名:输出文件名,默认为标准输出。即指定目的文件。 ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。 obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。 bs=bytes:同时设置读入/输出的块大小为bytes个字节。 cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。 skip=blocks:从输入文件开头跳过blocks个块后再开始复制。 seek=blocks:从输出文件开头跳过blocks个块后再开始复制。 count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。 conv=<关键字>,关键字可以有以下11种: conversion:用指定的参数转换文件。 ascii:转换ebcdic为ascii ebcdic:转换ascii为ebcdic ibm:转换ascii为alternate ebcdic block:把每一行转换为长度为cbs,不足部分用空格填充 unblock:使每一行的长度都为cbs,不足部分用空格填充 lcase:把大写字符转换为小写字符 ucase:把小写字符转换为大写字符 swab:交换输入的每对字节 noerror:出错时不停止 notrunc:不截短输出文件 sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。 --help:显示帮助信息 --version:显示版本信息 实例 在Linux 下制作启动盘,可使用如下命令: dd if=boot.img of=/dev/fd0 bs=1440k 将testfile文件中的所有英文字母转换为大写,然后转成为testfile_1文件,在命令提示符中使用如下命令: dd if=testfile_2 of=testfile_1 conv=ucase 其中testfile_2 的内容为: $ cat testfile_2 #testfile_2的内容 HELLO LINUX! Linux is a free unix-type opterating system. This is a linux testfile! Linux test 转换完成后,testfile_1 的内容如下: $ dd if=testfile_2 of=testfile_1 conv=ucase #使用dd 命令,大小写转换记录了0+1 的读入 记录了0+1 的写出 95字节(95 B)已复制,0.000131446 秒,723 KB/s cmd@hdd-desktop:~$ cat testfile_1 #查看转换后的testfile_1文件内容 HELLO LINUX! LINUX IS A FREE UNIX-TYPE OPTERATING SYSTEM. THIS IS A LINUX TESTFILE! LINUX TEST #testfile_2中的所有字符都变成了大写字母 由标准输入设备读入字符串,并将字符串转换成大写后,再输出到标准输出设备,使用的命令为: dd conv=ucase 输入以上命令后按回车键,输入字符串,再按回车键,按组合键Ctrl+D 退出,出现以下结果: $ dd conv=ucase Hello Linux! #输入字符串后按回车键 HELLO LINUX! #按组合键Ctrl+D退出,转换成大写结果 记录了0+1 的读入 记录了0+1 的写出 13字节(13 B)已复制,12.1558 秒,0.0 KB/s -
fdisk
Linux fdisk是一个创建和维护分区表的程序,它兼容DOS类型的分区表、BSD或者SUN类型的磁盘列表。 语法 fdisk [必要参数][选择参数] 必要参数: -l 列出素所有分区表 -u 与"-l"搭配使用,显示分区数目 选择参数: -s<分区编号> 指定分区 -v 版本信息 菜单操作说明 m :显示菜单和帮助信息 a :活动分区标记/引导分区 d :删除分区 l :显示分区类型 n :新建分区 p :显示分区信息 q :退出不保存 t :设置分区号 v :进行分区检查 w :保存修改 x :扩展应用,高级功能 实例 显示当前分区情况: # fdisk -l Disk /dev/sda: 10.7 GB, 10737418240 bytes 255 heads, 63 sectors/track, 1305 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Device Boot Start End Blocks Id System /dev/sda1 * 1 13 104391 83 Linux /dev/sda2 14 1305 10377990 8e Linux LVM Disk /dev/sdb: 5368 MB, 5368709120 bytes 255 heads, 63 sectors/track, 652 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Disk /dev/sdb doesn't contain a valid partition table 显示SCSI硬盘的每个分区情况 # fdisk -lu Disk /dev/sda: 10.7 GB, 10737418240 bytes 255 heads, 63 sectors/track, 1305 cylinders, total 20971520 sectors Units = sectors of 1 * 512 = 512 bytes Device Boot Start End Blocks Id System /dev/sda1 * 63 208844 104391 83 Linux /dev/sda2 208845 20964824 10377990 8e Linux LVM Disk /dev/sdb: 5368 MB, 5368709120 bytes 255 heads, 63 sectors/track, 652 cylinders, total 10485760 sectors Units = sectors of 1 * 512 = 512 bytes Disk /dev/sdb doesn't contain a valid partition table -
mount/umount
Linux mount命令是经常会使用到的命令,它用于挂载Linux系统外的文件。 语法 mount [-hV] mount -a [-fFnrsvw] [-t vfstype] mount [-fnrsvw] [-o options [,...]] device | dir mount [-fnrsvw] [-t vfstype] [-o options] device dir 参数说明: -V:显示程序版本 -h:显示辅助讯息 -v:显示较讯息,通常和 -f 用来除错。 -a:将 /etc/fstab 中定义的所有档案系统挂上。 -F:这个命令通常和 -a 一起使用,它会为每一个 mount 的动作产生一个行程负责执行。在系统需要挂上大量 NFS 档案系统时可以加快挂上的动作。 -f:通常用在除错的用途。它会使 mount 并不执行实际挂上的动作,而是模拟整个挂上的过程。通常会和 -v 一起使用。 -n:一般而言,mount 在挂上后会在 /etc/mtab 中写入一笔资料。但在系统中没有可写入档案系统存在的情况下可以用这个选项取消这个动作。 -s-r:等于 -o ro -w:等于 -o rw -L:将含有特定标签的硬盘分割挂上。 -U:将档案分割序号为 的档案系统挂下。-L 和 -U 必须在/proc/partition 这种档案存在时才有意义。 -t:指定档案系统的型态,通常不必指定。mount 会自动选择正确的型态。 -o async:打开非同步模式,所有的档案读写动作都会用非同步模式执行。 -o sync:在同步模式下执行。 -o atime、-o noatime:当 atime 打开时,系统会在每次读取档案时更新档案的『上一次调用时间』。当我们使用 flash 档案系统时可能会选项把这个选项关闭以减少写入的次数。 -o auto、-o noauto:打开/关闭自动挂上模式。 -o defaults:使用预设的选项 rw, suid, dev, exec, auto, nouser, and async. -o dev、-o nodev-o exec、-o noexec允许执行档被执行。 -o suid、-o nosuid:允许执行档在 root 权限下执行。 -o user、-o nouser:使用者可以执行 mount/umount 的动作。 -o remount:将一个已经挂下的档案系统重新用不同的方式挂上。例如原先是唯读的系统,现在用可读写的模式重新挂上。 -o ro:用唯读模式挂上。 -o rw:用可读写模式挂上。 -o loop=:使用 loop 模式用来将一个档案当成硬盘分割挂上系统。 实例 将 /dev/hda1 挂在 /mnt 之下。 #mount /dev/hda1 /mnt 将 /dev/hda1 用唯读模式挂在 /mnt 之下。 #mount -o ro /dev/hda1 /mnt 将 /tmp/image.iso 这个光碟的 image 档使用 loop 模式挂在 /mnt/cdrom之下。用这种方法可以将一般网络上可以找到的 Linux 光 碟 ISO 档在不烧录成光碟的情况下检视其内容。 #mount -o loop /tmp/image.iso /mnt/cdrom Linux umount命令用于卸除文件系统。 umount可卸除目前挂在Linux目录中的文件系统。 语法 umount [-ahnrvV][-t <文件系统类型>][文件系统] 参数: -a 卸除/etc/mtab中记录的所有文件系统。 -h 显示帮助。 -n 卸除时不要将信息存入/etc/mtab文件中。 -r 若无法成功卸除,则尝试以只读的方式重新挂入文件系统。 -t<文件系统类型> 仅卸除选项中所指定的文件系统。 -v 执行时显示详细的信息。 -V 显示版本信息。 [文件系统] 除了直接指定文件系统外,也可以用设备名称或挂入点来表示文件系统。 实例 下面两条命令分别通过设备名和挂载点卸载文件系统,同时输出详细信息: # umount -v /dev/sda1 通过设备名卸载 /dev/sda1 umounted # umount -v /mnt/mymount/ 通过挂载点卸载 /tmp/diskboot.img umounted 如果设备正忙,卸载即告失败。卸载失败的常见原因是,某个打开的shell当前目录为挂载点里的某个目录: # umount -v /mnt/mymount/ umount: /mnt/mymount: device is busy umount: /mnt/mymount: device is busy -
mkfs
使用方式 : mkfs [-V] [-t fstype] [fs-options] filesys [blocks] Linux mkfs命令用于在特定的分区上建立 linux 文件系统 参数 : device : 预备检查的硬盘分区,例如:/dev/sda1 -V : 详细显示模式 -t : 给定档案系统的型式,Linux 的预设值为 ext2 -c : 在制做档案系统前,检查该partition 是否有坏轨 -l bad_blocks_file : 将有坏轨的block资料加到 bad_blocks_file 里面 block : 给定 block 的大小 实例 在 /dev/hda5 上建一个 msdos 的档案系统,同时检查是否有坏轨存在,并且将过程详细列出来 : mkfs -V -t msdos -c /dev/hda5 将sda6分区格式化为ext3格式 mfks -t ext3 /dev/sda6 注意:这里的文件系统是要指定的,比如 ext3 ;reiserfs ;ext2 ;fat32 ;msdos 等。
系统管理
top, ps, pstree, date, shutdown, reboot, passwd
-
top
Linux top命令用于实时显示 process 的动态。 使用权限:所有使用者。 top [-] [d delay] [q] [c] [S] [s] [i] [n] [b] 参数说明: d : 改变显示的更新速度,或是在交谈式指令列( interactive command)按 s q : 没有任何延迟的显示速度,如果使用者是有 superuser 的权限,则 top 将会以最高的优先序执行 c : 切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称 S : 累积模式,会将己完成或消失的子行程 ( dead child process ) 的 CPU time 累积起来 s : 安全模式,将交谈式指令取消, 避免潜在的危机 i : 不显示任何闲置 (idle) 或无用 (zombie) 的行程 n : 更新的次数,完成后将会退出 top b : 批次档模式,搭配 "n" 参数一起使用,可以用来将 top 的结果输出到档案内 实例 显示进程信息 # top 显示完整命令 # top -c 以批处理模式显示程序信息 # top -b 以累积模式显示程序信息 # top -S 设置信息更新次数 top -n 2 //表示更新两次后终止更新显示 设置信息更新时间 # top -d 3 //表示更新周期为3秒 显示指定的进程信息 # top -p 139 //显示进程号为139的进程信息,CPU、内存占用率等 显示更新十次后退出 top -n 10 使用者将不能利用交谈式指令来对行程下命令 top -s -
ps
Linux ps命令用于显示当前进程 (process) 的状态。 语法 ps [options] [--help] 参数: ps 的参数非常多, 在此仅列出几个常用的参数并大略介绍含义 -A 列出所有的行程 -w 显示加宽可以显示较多的资讯 -au 显示较详细的资讯 -aux 显示所有包含其他使用者的行程 au(x) 输出格式 : USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND USER: 行程拥有者 PID: pid %CPU: 占用的 CPU 使用率 %MEM: 占用的记忆体使用率 VSZ: 占用的虚拟记忆体大小 RSS: 占用的记忆体大小 TTY: 终端的次要装置号码 (minor device number of tty) STAT: 该行程的状态: D: 无法中断的休眠状态 (通常 IO 的进程) R: 正在执行中 S: 静止状态 T: 暂停执行 Z: 不存在但暂时无法消除 W: 没有足够的记忆体分页可分配 <: 高优先序的行程 N: 低优先序的行程 L: 有记忆体分页分配并锁在记忆体内 (实时系统或捱A I/O) START: 行程开始时间 TIME: 执行的时间 COMMAND:所执行的指令 实例 # ps -A 显示进程信息 PID TTY TIME CMD 1 ? 00:00:02 init 2 ? 00:00:00 kthreadd 3 ? 00:00:00 migration/0 4 ? 00:00:00 ksoftirqd/0 5 ? 00:00:00 watchdog/0 6 ? 00:00:00 events/0 7 ? 00:00:00 cpuset 8 ? 00:00:00 khelper 9 ? 00:00:00 netns 10 ? 00:00:00 async/mgr 11 ? 00:00:00 pm 12 ? 00:00:00 sync_supers 13 ? 00:00:00 bdi-default 14 ? 00:00:00 kintegrityd/0 15 ? 00:00:02 kblockd/0 16 ? 00:00:00 kacpid 17 ? 00:00:00 kacpi_notify 18 ? 00:00:00 kacpi_hotplug 19 ? 00:00:27 ata/0 ……省略部分结果 30749 pts/0 00:00:15 gedit 30886 ? 00:01:10 qtcreator.bin 30894 ? 00:00:00 qtcreator.bin 31160 ? 00:00:00 dhclient 31211 ? 00:00:00 aptd 31302 ? 00:00:00 sshd 31374 pts/2 00:00:00 bash 31396 pts/2 00:00:00 ps 显示指定用户信息 # ps -u root //显示root进程用户信息 PID TTY TIME CMD 1 ? 00:00:02 init 2 ? 00:00:00 kthreadd 3 ? 00:00:00 migration/0 4 ? 00:00:00 ksoftirqd/0 5 ? 00:00:00 watchdog/0 6 ? 00:00:00 events/0 7 ? 00:00:00 cpuset 8 ? 00:00:00 khelper 9 ? 00:00:00 netns 10 ? 00:00:00 async/mgr 11 ? 00:00:00 pm 12 ? 00:00:00 sync_supers 13 ? 00:00:00 bdi-default 14 ? 00:00:00 kintegrityd/0 15 ? 00:00:02 kblockd/0 16 ? 00:00:00 kacpid ……省略部分结果 30487 ? 00:00:06 gnome-terminal 30488 ? 00:00:00 gnome-pty-helpe 30489 pts/0 00:00:00 bash 30670 ? 00:00:00 debconf-communi 30749 pts/0 00:00:15 gedit 30886 ? 00:01:10 qtcreator.bin 30894 ? 00:00:00 qtcreator.bin 31160 ? 00:00:00 dhclient 31211 ? 00:00:00 aptd 31302 ? 00:00:00 sshd 31374 pts/2 00:00:00 bash 31397 pts/2 00:00:00 ps 显示所有进程信息,连同命令行 # ps -ef //显示所有命令,连带命令行 UID PID PPID C STIME TTY TIME CMD root 1 0 0 10:22 ? 00:00:02 /sbin/init root 2 0 0 10:22 ? 00:00:00 [kthreadd] root 3 2 0 10:22 ? 00:00:00 [migration/0] root 4 2 0 10:22 ? 00:00:00 [ksoftirqd/0] root 5 2 0 10:22 ? 00:00:00 [watchdog/0] root 6 2 0 10:22 ? /usr/lib/NetworkManager ……省略部分结果 root 31302 2095 0 17:42 ? 00:00:00 sshd: root@pts/2 root 31374 31302 0 17:42 pts/2 00:00:00 -bash root 31400 1 0 17:46 ? 00:00:00 /usr/bin/python /usr/sbin/aptd root 31407 31374 0 17:48 pts/2 00:00:00 ps -ef -
pstree
Linux pstree命令将所有行程以树状图显示,树状图将会以 pid (如果有指定) 或是以 init 这个基本行程为根 (root),如果有指定使用者 id,则树状图会只显示该使用者所拥有的行程。 使用权限:所有使用者。 语法 pstree [-a] [-c] [-h|-Hpid] [-l] [-n] [-p] [-u] [-G|-U] [pid|user] 或 pstree -V 参数说明: -a 显示该行程的完整指令及参数, 如果是被记忆体置换出去的行程则会加上括号 -c 如果有重覆的行程名, 则分开列出(预设值是会在前面加上 *) 实例 显示进程的关系 pstree init-+-amd |-apmd |-atd |-httpd---10*[httpd] %pstree -p init(1)-+-amd(447) |-apmd(105) |-atd(339) %pstree -c init-+-amd |-apmd |-atd |-httpd-+-httpd | |-httpd | |-httpd | |-httpd .... 特别表明在运行的进程 # pstree -apnh //显示进程间的关系 同时显示用户名称 # pstree -u //显示用户名称 -
date
Linux date命令可以用来显示或设定系统的日期与时间,在显示方面,使用者可以设定欲显示的格式,格式设定为一个加号后接数个标记,其中可用的标记列表如下: 时间方面: % : 印出 % %n : 下一行 %t : 跳格 %H : 小时(00..23) %I : 小时(01..12) %k : 小时(0..23) %l : 小时(1..12) %M : 分钟(00..59) %p : 显示本地 AM 或 PM %r : 直接显示时间 (12 小时制,格式为 hh:mm:ss [AP]M) %s : 从 1970 年 1 月 1 日 00:00:00 UTC 到目前为止的秒数 %S : 秒(00..61) %T : 直接显示时间 (24 小时制) %X : 相当于 %H:%M:%S %Z : 显示时区 日期方面: %a : 星期几 (Sun..Sat) %A : 星期几 (Sunday..Saturday) %b : 月份 (Jan..Dec) %B : 月份 (January..December) %c : 直接显示日期与时间 %d : 日 (01..31) %D : 直接显示日期 (mm/dd/yy) %h : 同 %b %j : 一年中的第几天 (001..366) %m : 月份 (01..12) %U : 一年中的第几周 (00..53) (以 Sunday 为一周的第一天的情形) %w : 一周中的第几天 (0..6) %W : 一年中的第几周 (00..53) (以 Monday 为一周的第一天的情形) %x : 直接显示日期 (mm/dd/yy) %y : 年份的最后两位数字 (00.99) %Y : 完整年份 (0000..9999) 若是不以加号作为开头,则表示要设定时间,而时间格式为 MMDDhhmm[[CC]YY][.ss],其中 MM 为月份,DD 为日,hh 为小时,mm 为分钟,CC 为年份前两位数字,YY 为年份后两位数字,ss 为秒数。 使用权限:所有使用者。 当您不希望出现无意义的 0 时(比如说 1999/03/07),则可以在标记中插入 - 符号,比如说 date '+%-H:%-M:%-S' 会把时分秒中无意义的 0 给去掉,像是原本的 08:09:04 会变为 8:9:4。另外,只有取得权限者(比如说 root)才能设定系统时间。 当您以 root 身分更改了系统时间之后,请记得以 clock -w 来将系统时间写入 CMOS 中,这样下次重新开机时系统时间才会持续抱持最新的正确值。 语法 date [-u] [-d datestr] [-s datestr] [--utc] [--universal] [--date=datestr] [--set=datestr] [--help] [--version] [+FORMAT] [MMDDhhmm[[CC]YY][.ss]] 参数说明: -d datestr : 显示 datestr 中所设定的时间 (非系统时间) --help : 显示辅助讯息 -s datestr : 将系统时间设为 datestr 中所设定的时间 -u : 显示目前的格林威治时间 --version : 显示版本编号 实例 显示当前时间 # date 三 5月 12 14:08:12 CST 2010 # date '+%c' 2010年05月12日 星期三 14时09分02秒 # date '+%D' //显示完整的时间 05/12/10 # date '+%x' //显示数字日期,年份两位数表示 2010年05月12日 # date '+%T' //显示日期,年份用四位数表示 14:09:31 # date '+%X' //显示24小时的格式 14时09分39秒 按自己的格式输出 # date '+usr_time: $1:%M %P -hey' usr_time: $1:16 下午 -hey 显示时间后跳行,再显示目前日期 date '+%T%n%D' -
shutdown
Linux shutdown命令可以用来进行关机程序,并且在关机以前传送讯息给所有使用者正在执行的程序,shutdown 也可以用来重开机。 使用权限:系统管理者。 语法 shutdown [-t seconds] [-rkhncfF] time [message] 参数说明: -t seconds : 设定在几秒钟之后进行关机程序。 -k : 并不会真的关机,只是将警告讯息传送给所有使用者。 -r : 关机后重新开机。 -h : 关机后停机。 -n : 不采用正常程序来关机,用强迫的方式杀掉所有执行中的程序后自行关机。 -c : 取消目前已经进行中的关机动作。 -f : 关机时,不做 fcsk 动作(检查 Linux 档系统)。 -F : 关机时,强迫进行 fsck 动作。 time : 设定关机的时间。 message : 传送给所有使用者的警告讯息。 实例 立即关机 # shutdown -h now 指定5分钟后关机 # shutdown +5 “System will shutdown after 5 minutes” //5分钟够关机并显示警告信息 -
reboot
Linux reboot命令用于用来重新启动计算机。 若系统的 runlevel 为 0 或 6 ,则重新开机,否则以 shutdown 指令(加上 -r 参数)来取代 语法 reboot [-n] [-w] [-d] [-f] [-i] 参数: -n : 在重开机前不做将记忆体资料写回硬盘的动作 -w : 并不会真的重开机,只是把记录写到 /var/log/wtmp 档案里 -d : 不把记录写到 /var/log/wtmp 档案里(-n 这个参数包含了 -d) -f : 强迫重开机,不呼叫 shutdown 这个指令 -i : 在重开机之前先把所有网络相关的装置先停止 实例 重新启动 # reboot -
passwd
Linux passwd命令用来更改使用者的密码 语法 passwd [-k] [-l] [-u [-f]] [-d] [-S] [username] 必要参数: -d 删除密码 -f 强制执行 -k 更新只能发送在过期之后 -l 停止账号使用 -S 显示密码信息 -u 启用已被停止的账户 -x 设置密码的有效期 -g 修改群组密码 -i 过期后停止用户账号 选择参数: --help 显示帮助信息 --version 显示版本信息 实例 修改用户密码 # passwd runoob //设置runoob用户的密码 Enter new UNIX password: //输入新密码,输入的密码无回显 Retype new UNIX password: //确认密码 passwd: password updated successfully # 显示账号密码信息 # passwd -S runoob runoob P 05/13/2010 0 99999 7 -1 删除用户密码 # passwd -d lx138 passwd: password expiry information changed.
网络通信
ping, ssh, scp, ifconfig
-
ping
ping [-dfnqrRv][-c<完成次数>][-i<间隔秒数>][-I<网络界面>][-l<前置载入>][-p<范本样式>][-s<数据包大小>][-t<存活数值>][主机名称或IP地址] 参数说明: -d 使用Socket的SO_DEBUG功能。 -c<完成次数> 设置完成要求回应的次数。 -f 极限检测。 -i<间隔秒数> 指定收发信息的间隔时间。 -I<网络界面> 使用指定的网络接口送出数据包。 -l<前置载入> 设置在送出要求信息之前,先行发出的数据包。 -n 只输出数值。 -p<范本样式> 设置填满数据包的范本样式。 -q 不显示指令执行过程,开头和结尾的相关信息除外。 -r 忽略普通的Routing Table,直接将数据包送到远端主机上。 -R 记录路由过程。 -s<数据包大小> 设置数据包的大小。 -t<存活数值> 设置存活数值TTL的大小。 -v 详细显示指令的执行过程。 实例 检测是否与主机连通 # ping www.w3cschool.cc //ping主机 PING aries.m.alikunlun.com (114.80.174.110) 56(84) bytes of data. 64 bytes from 114.80.174.110: icmp_seq=1 ttl=64 time=0.025 ms 64 bytes from 114.80.174.110: icmp_seq=2 ttl=64 time=0.036 ms 64 bytes from 114.80.174.110: icmp_seq=3 ttl=64 time=0.034 ms 64 bytes from 114.80.174.110: icmp_seq=4 ttl=64 time=0.034 ms 64 bytes from 114.80.174.110: icmp_seq=5 ttl=64 time=0.028 ms 64 bytes from 114.80.174.110: icmp_seq=6 ttl=64 time=0.028 ms 64 bytes from 114.80.174.110: icmp_seq=7 ttl=64 time=0.034 ms 64 bytes from 114.80.174.110: icmp_seq=8 ttl=64 time=0.034 ms 64 bytes from 114.80.174.110: icmp_seq=9 ttl=64 time=0.036 ms 64 bytes from 114.80.174.110: icmp_seq=10 ttl=64 time=0.041 ms --- aries.m.alikunlun.com ping statistics --- 10 packets transmitted, 30 received, 0% packet loss, time 29246ms rtt min/avg/max/mdev = 0.021/0.035/0.078/0.011 ms //需要手动终止Ctrl+C 指定接收包的次数 # ping -c 2 www.w3cschool.cc PING aries.m.alikunlun.com (114.80.174.120) 56(84) bytes of data. 64 bytes from 114.80.174.120: icmp_seq=1 ttl=54 time=6.18 ms 64 bytes from 114.80.174.120: icmp_seq=2 ttl=54 time=15.4 ms --- aries.m.alikunlun.com ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1016ms rtt min/avg/max/mdev = 6.185/10.824/15.464/4.640 ms //收到两次包后,自动退出 多参数使用 # ping -i 3 -s 1024 -t 255 g.cn //ping主机 PING g.cn (203.208.37.104) 1024(1052) bytes of data. 1032 bytes from bg-in-f104.1e100.net (203.208.37.104): icmp_seq=0 ttl=243 time=62.5 ms 1032 bytes from bg-in-f104.1e100.net (203.208.37.104): icmp_seq=1 ttl=243 time=63.9 ms 1032 bytes from bg-in-f104.1e100.net (203.208.37.104): icmp_seq=2 ttl=243 time=61.9 ms --- g.cn ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 6001ms rtt min/avg/max/mdev = 61.959/62.843/63.984/0.894 ms, pipe 2 [root@linux ~]# //-i 3 发送周期为 3秒 -s 设置发送包的大小 -t 设置TTL值为 255 -
ssh
-
scp
Linux scp命令用于Linux之间复制文件和目录。 scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。 语法 scp [-1246BCpqrv] [-c cipher] [-F ssh_config] [-i identity_file] [-l limit] [-o ssh_option] [-P port] [-S program] [[user@]host1:]file1 [...] [[user@]host2:]file2 简易写法: scp [可选参数] file_source file_target 参数说明: -1: 强制scp命令使用协议ssh1 -2: 强制scp命令使用协议ssh2 -4: 强制scp命令只使用IPv4寻址 -6: 强制scp命令只使用IPv6寻址 -B: 使用批处理模式(传输过程中不询问传输口令或短语) -C: 允许压缩。(将-C标志传递给ssh,从而打开压缩功能) -p:保留原文件的修改时间,访问时间和访问权限。 -q: 不显示传输进度条。 -r: 递归复制整个目录。 -v:详细方式显示输出。scp和ssh(1)会显示出整个过程的调试信息。这些信息用于调试连接,验证和配置问题。 -c cipher: 以cipher将数据传输进行加密,这个选项将直接传递给ssh。 -F ssh_config: 指定一个替代的ssh配置文件,此参数直接传递给ssh。 -i identity_file: 从指定文件中读取传输时使用的密钥文件,此参数直接传递给ssh。 -l limit: 限定用户所能使用的带宽,以Kbit/s为单位。 -o ssh_option: 如果习惯于使用ssh_config(5)中的参数传递方式, -P port:注意是大写的P, port是指定数据传输用到的端口号 -S program: 指定加密传输时所使用的程序。此程序必须能够理解ssh(1)的选项。 实例 1、从本地复制到远程 命令格式: scp local_file remote_username@remote_ip:remote_folder 或者 scp local_file remote_username@remote_ip:remote_file 或者 scp local_file remote_ip:remote_folder 或者 scp local_file remote_ip:remote_file 第1,2个指定了用户名,命令执行后需要再输入密码,第1个仅指定了远程的目录,文件名字不变,第2个指定了文件名; 第3,4个没有指定用户名,命令执行后需要输入用户名和密码,第3个仅指定了远程的目录,文件名字不变,第4个指定了文件名; 应用实例: scp /home/space/music/1.mp3 root@www.runoob.com:/home/root/others/music scp /home/space/music/1.mp3 root@www.runoob.com:/home/root/others/music/001.mp3 scp /home/space/music/1.mp3 www.runoob.com:/home/root/others/music scp /home/space/music/1.mp3 www.runoob.com:/home/root/others/music/001.mp3 复制目录命令格式: scp -r local_folder remote_username@remote_ip:remote_folder 或者 scp -r local_folder remote_ip:remote_folder 第1个指定了用户名,命令执行后需要再输入密码; 第2个没有指定用户名,命令执行后需要输入用户名和密码; 应用实例: scp -r /home/space/music/ root@www.runoob.com:/home/root/others/ scp -r /home/space/music/ www.runoob.com:/home/root/others/ 上面命令将本地 music 目录复制到远程 others 目录下。 2、从远程复制到本地 从远程复制到本地,只要将从本地复制到远程的命令的后2个参数调换顺序即可,如下实例 应用实例: scp root@www.runoob.com:/home/root/others/music /home/space/music/1.mp3 scp -r www.runoob.com:/home/root/others/ /home/space/music/ 说明 1.如果远程服务器防火墙有为scp命令设置了指定的端口,我们需要使用 -P 参数来设置命令的端口号,命令格式如下: #scp 命令使用端口号 4588 scp -P 4588 remote@www.runoob.com:/usr/local/sin.sh /home/administrator 2.使用scp命令要确保使用的用户具有可读取远程服务器相应文件的权限,否则scp命令是无法起作用的。 -
ifconfig
Linux ifconfig命令用于显示或设置网络设备。 ifconfig可设置网络设备的状态,或是显示目前的设置。 语法 ifconfig [网络设备][down up -allmulti -arp -promisc][add<地址>][del<地址>][<hw<网络设备类型><硬件地址>][io_addr<I/O地址>][irq<IRQ地址>][media<网络媒介类型>][mem_start<内存地址>][metric<数目>][mtu<字节>][netmask<子网掩码>][tunnel<地址>][-broadcast<地址>][-pointopoint<地址>][IP地址] 参数说明: add<地址> 设置网络设备IPv6的IP地址。 del<地址> 删除网络设备IPv6的IP地址。 down 关闭指定的网络设备。 <hw<网络设备类型><硬件地址> 设置网络设备的类型与硬件地址。 io_addr<I/O地址> 设置网络设备的I/O地址。 irq<IRQ地址> 设置网络设备的IRQ。 media<网络媒介类型> 设置网络设备的媒介类型。 mem_start<内存地址> 设置网络设备在主内存所占用的起始地址。 metric<数目> 指定在计算数据包的转送次数时,所要加上的数目。 mtu<字节> 设置网络设备的MTU。 netmask<子网掩码> 设置网络设备的子网掩码。 tunnel<地址> 建立IPv4与IPv6之间的隧道通信地址。 up 启动指定的网络设备。 -broadcast<地址> 将要送往指定地址的数据包当成广播数据包来处理。 -pointopoint<地址> 与指定地址的网络设备建立直接连线,此模式具有保密功能。 -promisc 关闭或启动指定网络设备的promiscuous模式。 [IP地址] 指定网络设备的IP地址。 [网络设备] 指定网络设备的名称。 实例 显示网络设备信息 # ifconfig eth0 Link encap:Ethernet HWaddr 00:50:56:0A:0B:0C inet addr:192.168.0.3 Bcast:192.168.0.255 Mask:255.255.255.0 inet6 addr: fe80::250:56ff:fe0a:b0c/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:172220 errors:0 dropped:0 overruns:0 frame:0 TX packets:132379 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:87101880 (83.0 MiB) TX bytes:41576123 (39.6 MiB) Interrupt:185 Base address:0x2024 lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:16436 Metric:1 RX packets:2022 errors:0 dropped:0 overruns:0 frame:0 TX packets:2022 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:2459063 (2.3 MiB) TX bytes:2459063 (2.3 MiB) 启动关闭指定网卡 # ifconfig eth0 down # ifconfig eth0 up 为网卡配置和删除IPv6地址 # ifconfig eth0 add 33ffe:3240:800:1005::2/ 64 //为网卡诶之IPv6地址 # ifconfig eth0 del 33ffe:3240:800:1005::2/ 64 //为网卡删除IPv6地址 用ifconfig修改MAC地址 # ifconfig eth0 down //关闭网卡 # ifconfig eth0 hw ether 00:AA:BB:CC:DD:EE //修改MAC地址 # ifconfig eth0 up //启动网卡 # ifconfig eth1 hw ether 00:1D:1C:1D:1E //关闭网卡并修改MAC地址 # ifconfig eth1 up //启动网卡 配置IP地址 # ifconfig eth0 192.168.1.56 //给eth0网卡配置IP地址 # ifconfig eth0 192.168.1.56 netmask 255.255.255.0 // 给eth0网卡配置IP地址,并加上子掩码 # ifconfig eth0 192.168.1.56 netmask 255.255.255.0 broadcast 192.168.1.255 // 给eth0网卡配置IP地址,加上子掩码,加上个广播地址 启用和关闭ARP协议 # ifconfig eth0 arp //开启 # ifconfig eth0 -arp //关闭 设置最大传输单元 # ifconfig eth0 mtu 1500 //设置能通过的最大数据包大小为 1500 bytes
压缩解压
tar, gzip/gunzip, zip/unzip
-
tar
Linux tar命令用于备份文件。 tar是用来建立,还原备份文件的工具程序,它可以加入,解开备份文件内的文件。 语法 tar [-ABcdgGhiklmMoOpPrRsStuUvwWxzZ][-b <区块数目>][-C <目的目录>][-f <备份文件>][-F <Script文件>][-K <文件>][-L <媒体容量>][-N <日期时间>][-T <范本文件>][-V <卷册名称>][-X <范本文件>][-<设备编号><存储密度>][--after-date=<日期时间>][--atime-preserve][--backuup=<备份方式>][--checkpoint][--concatenate][--confirmation][--delete][--exclude=<范本样式>][--force-local][--group=<群组名称>][--help][--ignore-failed-read][--new-volume-script=<Script文件>][--newer-mtime][--no-recursion][--null][--numeric-owner][--owner=<用户名称>][--posix][--erve][--preserve-order][--preserve-permissions][--record-size=<区块数目>][--recursive-unlink][--remove-files][--rsh-command=<执行指令>][--same-owner][--suffix=<备份字尾字符串>][--totals][--use-compress-program=<执行指令>][--version][--volno-file=<编号文件>][文件或目录...] 参数: -A或--catenate 新增文件到已存在的备份文件。 -b<区块数目>或--blocking-factor=<区块数目> 设置每笔记录的区块数目,每个区块大小为12Bytes。 -B或--read-full-records 读取数据时重设区块大小。 -c或--create 建立新的备份文件。 -C<目的目录>或--directory=<目的目录> 切换到指定的目录。 -d或--diff或--compare 对比备份文件内和文件系统上的文件的差异。 -f<备份文件>或--file=<备份文件> 指定备份文件。 -F<Script文件>或--info-script=<Script文件> 每次更换磁带时,就执行指定的Script文件。 -g或--listed-incremental 处理GNU格式的大量备份。 -G或--incremental 处理旧的GNU格式的大量备份。 -h或--dereference 不建立符号连接,直接复制该连接所指向的原始文件。 -i或--ignore-zeros 忽略备份文件中的0 Byte区块,也就是EOF。 -k或--keep-old-files 解开备份文件时,不覆盖已有的文件。 -K<文件>或--starting-file=<文件> 从指定的文件开始还原。 -l或--one-file-system 复制的文件或目录存放的文件系统,必须与tar指令执行时所处的文件系统相同,否则不予复制。 -L<媒体容量>或-tape-length=<媒体容量> 设置存放每体的容量,单位以1024 Bytes计算。 -m或--modification-time 还原文件时,不变更文件的更改时间。 -M或--multi-volume 在建立,还原备份文件或列出其中的内容时,采用多卷册模式。 -N<日期格式>或--newer=<日期时间> 只将较指定日期更新的文件保存到备份文件里。 -o或--old-archive或--portability 将资料写入备份文件时使用V7格式。 -O或--stdout 把从备份文件里还原的文件输出到标准输出设备。 -p或--same-permissions 用原来的文件权限还原文件。 -P或--absolute-names 文件名使用绝对名称,不移除文件名称前的"/"号。 -r或--append 新增文件到已存在的备份文件的结尾部分。 -R或--block-number 列出每个信息在备份文件中的区块编号。 -s或--same-order 还原文件的顺序和备份文件内的存放顺序相同。 -S或--sparse 倘若一个文件内含大量的连续0字节,则将此文件存成稀疏文件。 -t或--list 列出备份文件的内容。 -T<范本文件>或--files-from=<范本文件> 指定范本文件,其内含有一个或多个范本样式,让tar解开或建立符合设置条件的文件。 -u或--update 仅置换较备份文件内的文件更新的文件。 -U或--unlink-first 解开压缩文件还原文件之前,先解除文件的连接。 -v或--verbose 显示指令执行过程。 -V<卷册名称>或--label=<卷册名称> 建立使用指定的卷册名称的备份文件。 -w或--interactive 遭遇问题时先询问用户。 -W或--verify 写入备份文件后,确认文件正确无误。 -x或--extract或--get 从备份文件中还原文件。 -X<范本文件>或--exclude-from=<范本文件> 指定范本文件,其内含有一个或多个范本样式,让ar排除符合设置条件的文件。 -z或--gzip或--ungzip 通过gzip指令处理备份文件。 -Z或--compress或--uncompress 通过compress指令处理备份文件。 -<设备编号><存储密度> 设置备份用的外围设备编号及存放数据的密度。 --after-date=<日期时间> 此参数的效果和指定"-N"参数相同。 --atime-preserve 不变更文件的存取时间。 --backup=<备份方式>或--backup 移除文件前先进行备份。 --checkpoint 读取备份文件时列出目录名称。 --concatenate 此参数的效果和指定"-A"参数相同。 --confirmation 此参数的效果和指定"-w"参数相同。 --delete 从备份文件中删除指定的文件。 --exclude=<范本样式> 排除符合范本样式的文件。 --group=<群组名称> 把加入设备文件中的文件的所属群组设成指定的群组。 --help 在线帮助。 --ignore-failed-read 忽略数据读取错误,不中断程序的执行。 --new-volume-script=<Script文件> 此参数的效果和指定"-F"参数相同。 --newer-mtime 只保存更改过的文件。 --no-recursion 不做递归处理,也就是指定目录下的所有文件及子目录不予处理。 --null 从null设备读取文件名称。 --numeric-owner 以用户识别码及群组识别码取代用户名称和群组名称。 --owner=<用户名称> 把加入备份文件中的文件的拥有者设成指定的用户。 --posix 将数据写入备份文件时使用POSIX格式。 --preserve 此参数的效果和指定"-ps"参数相同。 --preserve-order 此参数的效果和指定"-A"参数相同。 --preserve-permissions 此参数的效果和指定"-p"参数相同。 --record-size=<区块数目> 此参数的效果和指定"-b"参数相同。 --recursive-unlink 解开压缩文件还原目录之前,先解除整个目录下所有文件的连接。 --remove-files 文件加入备份文件后,就将其删除。 --rsh-command=<执行指令> 设置要在远端主机上执行的指令,以取代rsh指令。 --same-owner 尝试以相同的文件拥有者还原文件。 --suffix=<备份字尾字符串> 移除文件前先行备份。 --totals 备份文件建立后,列出文件大小。 --use-compress-program=<执行指令> 通过指定的指令处理备份文件。 --version 显示版本信息。 --volno-file=<编号文件> 使用指定文件内的编号取代预设的卷册编号。 实例 压缩文件 非打包 # touch a.c # tar -czvf test.tar.gz a.c //压缩 a.c文件为test.tar.gz a.c 列出压缩文件内容 # tar -tzvf test.tar.gz -rw-r--r-- root/root 0 2010-05-24 16:51:59 a.c 解压文件 # tar -xzvf test.tar.gz a.c 将文件全部打包成tar包: tar -cvf log.tar log2012.log 仅打包,不压缩! tar -zcvf log.tar.gz log2012.log 打包后,以 gzip 压缩 tar -jcvf log.tar.bz2 log2012.log 打包后,以 bzip2 压缩 在选项f之后的文件档名是自己取的,我们习惯上都用 .tar 来作为辨识。 如果加z选项,则以.tar.gz或.tgz来代表gzip压缩过的tar包;如果加j选项,则以.tar.bz2来作为tar包名。 查阅上述tar包内有哪些文件: tar -ztvf log.tar.gz 由于我们使用 gzip 压缩的log.tar.gz,所以要查阅log.tar.gz包内的文件时,就得要加上z这个选项了。 将tar包解压缩: tar -zxvf /opt/soft/test/log.tar.gz 在预设的情况下,我们可以将压缩档在任何地方解开的 只将tar内的部分文件解压出来: tar -zxvf /opt/soft/test/log30.tar.gz log2013.log 我可以透过tar -ztvf来查阅 tar 包内的文件名称,如果单只要一个文件,就可以透过这个方式来解压部分文件! 文件备份下来,并且保存其权限: tar -zcvpf log31.tar.gz log2014.log log2015.log log2016.log 这个-p的属性是很重要的,尤其是当您要保留原本文件的属性时。 在文件夹当中,比某个日期新的文件才备份: tar -N "2012/11/13" -zcvf log17.tar.gz test 备份文件夹内容是排除部分文件: tar --exclude scf/service -zcvf scf.tar.gz scf/* 其实最简单的使用 tar 就只要记忆底下的方式即可: 压 缩:tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称 查 询:tar -jtv -f filename.tar.bz2 解压缩:tar -jxv -f filename.tar.bz2 -C 欲解压缩的目录 -c: 建立压缩档案 -x:解压 -t:查看内容 -r:向压缩归档文件末尾追加文件 -u:更新原压缩包中的文件 这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个。下面的参数是根据需要在压缩或解压档案时可选的。 -z:有gzip属性的 -j:有bz2属性的 -Z:有compress属性的 -v:显示所有过程 -O:将文件解开到标准输出 下面的参数-f是必须的 -f: 使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。 # tar -cf all.tar *.jpg 这条命令是将所有.jpg的文件打成一个名为all.tar的包。-c是表示产生新的包,-f指定包的文件名。 # tar -rf all.tar *.gif 这条命令是将所有.gif的文件增加到all.tar的包里面去。-r是表示增加文件的意思。 # tar -uf all.tar logo.gif 这条命令是更新原来tar包all.tar中logo.gif文件,-u是表示更新文件的意思。 # tar -tf all.tar 这条命令是列出all.tar包中所有文件,-t是列出文件的意思 # tar -xf all.tar 这条命令是解出all.tar包中所有文件,-t是解开的意思 压缩 tar -cvf jpg.tar *.jpg //将目录里所有jpg文件打包成jpg.tar tar -czf jpg.tar.gz *.jpg //将目录里所有jpg文件打包成jpg.tar后,并且将其用gzip压缩,生成一个gzip压缩过的包,命名为jpg.tar.gz tar -cjf jpg.tar.bz2 *.jpg //将目录里所有jpg文件打包成jpg.tar后,并且将其用bzip2压缩,生成一个bzip2压缩过的包,命名为jpg.tar.bz2 tar -cZf jpg.tar.Z *.jpg //将目录里所有jpg文件打包成jpg.tar后,并且将其用compress压缩,生成一个umcompress压缩过的包,命名为jpg.tar.Z rar a jpg.rar *.jpg //rar格式的压缩,需要先下载rar for linux zip jpg.zip *.jpg //zip格式的压缩,需要先下载zip for linux 解压 tar -xvf file.tar //解压 tar包 tar -xzvf file.tar.gz //解压tar.gz tar -xjvf file.tar.bz2 //解压 tar.bz2 tar -xZvf file.tar.Z //解压tar.Z unrar e file.rar //解压rar unzip file.zip //解压zip 总结 1、*.tar 用 tar -xvf 解压 2、*.gz 用 gzip -d或者gunzip 解压 3、*.tar.gz和*.tgz 用 tar -xzf 解压 4、*.bz2 用 bzip2 -d或者用bunzip2 解压 5、*.tar.bz2用tar -xjf 解压 6、*.Z 用 uncompress 解压 7、*.tar.Z 用tar -xZf 解压 8、*.rar 用 unrar e解压 9、*.zip 用 unzip 解压 -
gzip/gunzip
Linux gzip命令用于压缩文件。 gzip是个使用广泛的压缩程序,文件经它压缩过后,其名称后面会多出".gz"的扩展名。 语法 gzip [-acdfhlLnNqrtvV][-S <压缩字尾字符串>][-<压缩效率>][--best/fast][文件...] 或 gzip [-acdfhlLnNqrtvV][-S <压缩字尾字符串>][-<压缩效率>][--best/fast][目录] 参数: -a或--ascii 使用ASCII文字模式。 -c或--stdout或--to-stdout 把压缩后的文件输出到标准输出设备,不去更动原始文件。 -d或--decompress或----uncompress 解开压缩文件。 -f或--force 强行压缩文件。不理会文件名称或硬连接是否存在以及该文件是否为符号连接。 -h或--help 在线帮助。 -l或--list 列出压缩文件的相关信息。 -L或--license 显示版本与版权信息。 -n或--no-name 压缩文件时,不保存原来的文件名称及时间戳记。 -N或--name 压缩文件时,保存原来的文件名称及时间戳记。 -q或--quiet 不显示警告信息。 -r或--recursive 递归处理,将指定目录下的所有文件及子目录一并处理。 -S<压缩字尾字符串>或----suffix<压缩字尾字符串> 更改压缩字尾字符串。 -t或--test 测试压缩文件是否正确无误。 -v或--verbose 显示指令执行过程。 -V或--version 显示版本信息。 -<压缩效率> 压缩效率是一个介于1-9的数值,预设值为"6",指定愈大的数值,压缩效率就会愈高。 --best 此参数的效果和指定"-9"参数相同。 --fast 此参数的效果和指定"-1"参数相同。 实例 压缩文件 [root@w3cschool.cc a]# ls //显示当前目录文件 a.c b.h d.cpp [root@w3cschool.cc a]# gzip * //压缩目录下的所有文件 [root@w3cschool.cc a]# ls //显示当前目录文件 a.c.gz b.h.gz d.cpp.gz [root@w3cschool.cc a]# 接范例1, 列出详细的信息 [root@w3cschool.cc a]# gzip -dv * //解压文件,并列出详细信息 a.c.gz: 0.0% -- replaced with a.c b.h.gz: 0.0% -- replaced with b.h d.cpp.gz: 0.0% -- replaced with d.cpp [root@w3cschool.cc a]# 接范例1,显示压缩文件的信息 [root@w3cschool.cc a]# gzip -l * compressed uncompressed ratio uncompressed_name 24 0 0.0% a.c 24 0 0.0% b.h 26 0 0.0% d.cpp 把test6目录下的每个文件压缩成.gz文件 gzip * 把上例中每个压缩的文件解压,并列出详细的信息 gzip -dv * 详细显示例1中每个压缩的文件的信息,并不解压 gzip -l * 压缩一个tar备份文件,此时压缩文件的扩展名为.tar.gz gzip -r log.tar 递归的压缩目录 gzip -rv test6 这样,所有test下面的文件都变成了*.gz,目录依然存在只是目录里面的文件相应变成了*.gz.这就是压缩,和打包不同。因为是对目录操作,所以需要加上-r选项,这样也可以对子目录进行递归了。 递归地解压目录 gzip -dr test6Linux gunzip命令用于解压文件。 gunzip是个使用广泛的解压缩程序,它用于解开被gzip压缩过的文件,这些压缩文件预设最后的扩展名为".gz"。事实上gunzip就是gzip的硬连接,因此不论是压缩或解压缩,都可通过gzip指令单独完成。 语法 参数: gunzip [-acfhlLnNqrtvV][-s <压缩字尾字符串>][文件...] 或 gunzip [-acfhlLnNqrtvV][-s <压缩字尾字符串>][目录] -a或--ascii 使用ASCII文字模式。 -c或--stdout或--to-stdout 把解压后的文件输出到标准输出设备。 -f或-force 强行解开压缩文件,不理会文件名称或硬连接是否存在以及该文件是否为符号连接。 -h或--help 在线帮助。 -l或--list 列出压缩文件的相关信息。 -L或--license 显示版本与版权信息。 -n或--no-name 解压缩时,若压缩文件内含有远来的文件名称及时间戳记,则将其忽略不予处理。 -N或--name 解压缩时,若压缩文件内含有原来的文件名称及时间戳记,则将其回存到解开的文件上。 -q或--quiet 不显示警告信息。 -r或--recursive 递归处理,将指定目录下的所有文件及子目录一并处理。 -S<压缩字尾字符串>或--suffix<压缩字尾字符串> 更改压缩字尾字符串。 -t或--test 测试压缩文件是否正确无误。 -v或--verbose 显示指令执行过程。 -V或--version 显示版本信息。 实例 解压文件 # gunzip ab.gz 首先将/etc目录下的所有文件以及子目录进行压缩,备份压缩包etc.zip到/opt目录,然后对etc.zip文件进行gzip压缩,设置gzip的压缩级别为9。 zip –r /opt/etc.zip /etc gzip -9v /opt/etc.zip 查看上述etc.zip.gz文件的压缩信息。 gzip -l /opt/etc.zip.gz compressed uncompressed ratio uncompressed_name 11938745 12767265 6.5% /opt/etc.zip 解压上述etc.zip.gz文件到当前目录。 [root@mylinux ~]#gzip –d /opt/etc.zip.gz 或者执行 [root@mylinux ~]#gunzip /opt/etc.zip.gz 通过上面的示例可以知道gzip –d等价于gunzip命令。 -
zip/unzip
Linux zip命令用于压缩文件。 zip是个使用广泛的压缩程序,文件经它压缩后会另外产生具有".zip"扩展名的压缩文件。 语法 zip [-AcdDfFghjJKlLmoqrSTuvVwXyz$][-b <工作目录>][-ll][-n <字尾字符串>][-t <日期时间>][-<压缩效率>][压缩文件][文件...][-i <范本样式>][-x <范本样式>] 参数: -A 调整可执行的自动解压缩文件。 -b<工作目录> 指定暂时存放文件的目录。 -c 替每个被压缩的文件加上注释。 -d 从压缩文件内删除指定的文件。 -D 压缩文件内不建立目录名称。 -f 此参数的效果和指定"-u"参数类似,但不仅更新既有文件,如果某些文件原本不存在于压缩文件内,使用本参数会一并将其加入压缩文件中。 -F 尝试修复已损坏的压缩文件。 -g 将文件压缩后附加在既有的压缩文件之后,而非另行建立新的压缩文件。 -h 在线帮助。 -i<范本样式> 只压缩符合条件的文件。 -j 只保存文件名称及其内容,而不存放任何目录名称。 -J 删除压缩文件前面不必要的数据。 -k 使用MS-DOS兼容格式的文件名称。 -l 压缩文件时,把LF字符置换成LF+CR字符。 -ll 压缩文件时,把LF+CR字符置换成LF字符。 -L 显示版权信息。 -m 将文件压缩并加入压缩文件后,删除原始文件,即把文件移到压缩文件中。 -n<字尾字符串> 不压缩具有特定字尾字符串的文件。 -o 以压缩文件内拥有最新更改时间的文件为准,将压缩文件的更改时间设成和该文件相同。 -q 不显示指令执行过程。 -r 递归处理,将指定目录下的所有文件和子目录一并处理。 -S 包含系统和隐藏文件。 -t<日期时间> 把压缩文件的日期设成指定的日期。 -T 检查备份文件内的每个文件是否正确无误。 -u 更换较新的文件到压缩文件内。 -v 显示指令执行过程或显示版本信息。 -V 保存VMS操作系统的文件属性。 -w 在文件名称里假如版本编号,本参数仅在VMS操作系统下有效。 -x<范本样式> 压缩时排除符合条件的文件。 -X 不保存额外的文件属性。 -y 直接保存符号连接,而非该连接所指向的文件,本参数仅在UNIX之类的系统下有效。 -z 替压缩文件加上注释。 -$ 保存第一个被压缩文件所在磁盘的卷册名称。 -<压缩效率> 压缩效率是一个介于1-9的数值。 实例 将 /home/html/ 这个目录下所有文件和文件夹打包为当前目录下的 html.zip: zip -q -r html.zip /home/html 如果在我们在 /home/html 目录下,可以执行以下命令: zip -q -r html.zip * 从压缩文件 cp.zip 中删除文件 a.c zip -dv cp.zip a.cLinux unzip命令用于解压缩zip文件 unzip为.zip压缩文件的解压缩程序。 语法 unzip [-cflptuvz][-agCjLMnoqsVX][-P <密码>][.zip文件][文件][-d <目录>][-x <文件>] 或 unzip [-Z] 参数: -c 将解压缩的结果显示到屏幕上,并对字符做适当的转换。 -f 更新现有的文件。 -l 显示压缩文件内所包含的文件。 -p 与-c参数类似,会将解压缩的结果显示到屏幕上,但不会执行任何的转换。 -t 检查压缩文件是否正确。 -u 与-f参数类似,但是除了更新现有的文件外,也会将压缩文件中的其他文件解压缩到目录中。 -v 执行是时显示详细的信息。 -z 仅显示压缩文件的备注文字。 -a 对文本文件进行必要的字符转换。 -b 不要对文本文件进行字符转换。 -C 压缩文件中的文件名称区分大小写。 -j 不处理压缩文件中原有的目录路径。 -L 将压缩文件中的全部文件名改为小写。 -M 将输出结果送到more程序处理。 -n 解压缩时不要覆盖原有的文件。 -o 不必先询问用户,unzip执行后覆盖原有文件。 -P<密码> 使用zip的密码选项。 -q 执行时不显示任何信息。 -s 将文件名中的空白字符转换为底线字符。 -V 保留VMS的文件版本信息。 -X 解压缩时同时回存文件原来的UID/GID。 [.zip文件] 指定.zip压缩文件。 [文件] 指定要处理.zip压缩文件中的哪些文件。 -d<目录> 指定文件解压缩后所要存储的目录。 -x<文件> 指定不要处理.zip压缩文件中的哪些文件。 -Z unzip -Z等于执行zipinfo指令。 实例 查看压缩文件中包含的文件: # unzip -l abc.zip Archive: abc.zip Length Date Time Name -------- ---- ---- ---- 94618 05-21-10 20:44 a11.jpg 202001 05-21-10 20:44 a22.jpg 16 05-22-10 15:01 11.txt 46468 05-23-10 10:30 w456.JPG 140085 03-14-10 21:49 my.asp -------- ------- 483188 5 files -v 参数用于查看压缩文件目录信息,但是不解压该文件。 # unzip -v abc.zip Archive: abc.zip Length Method Size Ratio Date Time CRC-32 Name -------- ------ ------- ----- ---- ---- ------ ---- 94618 Defl:N 93353 1% 05-21-10 20:44 9e661437 a11.jpg 202001 Defl:N 201833 0% 05-21-10 20:44 1da462eb a22.jpg 16 Stored 16 0% 05-22-10 15:01 ae8a9910 ? +-|¥+-? (11).txt 46468 Defl:N 39997 14% 05-23-10 10:30 962861f2 w456.JPG 140085 Defl:N 36765 74% 03-14-10 21:49 836fcc3f my.asp -------- ------- --- ------- 483188 371964 23% 5 files 将压缩文件text.zip在当前目录下解压缩。 unzip test.zip 将压缩文件text.zip在指定目录/tmp下解压缩,如果已有相同的文件存在,要求unzip命令不覆盖原先的文件。 unzip -n test.zip -d /tmp 查看压缩文件目录,但不解压。 unzip -v test.zip 将压缩文件test.zip在指定目录/tmp下解压缩,如果已有相同的文件存在,要求unzip命令覆盖原先的文件。 unzip -o test.zip -d tmp/
查询硬件信息的命令
-
lscpu
描述: 此命令用来显示cpu的相关信息 lscpu从sysfs和/proc/cpuinfo收集cpu体系结构信息,命令的输出比较易读 命令输出的信息包含cpu数量,线程,核数,套接字和Nom-Uniform Memeor Access(NUMA),缓存等 不是所有的列都支持所有的架构,如果指定了不支持的列,那么lscpu将打印列,但不显示数据 语法: lscpu [-a|-b|-c] [-x] [-s directory] [-e [=list]|-p [=list]] lscpu -h|-V 参数选项: -a, –all: 包含上线和下线的cpu的数量,此选项只能与选项e或-p一起指定 -b, –online: 只显示出上线的cpu数量,此选项只能与选项e或者-p一起指定 -c, –offline: 只显示出离线的cpu数量,此选项只能与选项e或者-p一起指定 -e, –extended [=list]: 以人性化的格式显示cpu信息,如果list参数省略,输出所有可用数据的列,在指定了list参数时,选项的字符串、等号(=)和列表必须不包含任何空格或其他空白。比如:’-e=cpu,node’ or ’–extended=cpu,node’ -h, –help:帮助 -p, –parse [=list]: 优化命令输出,便于分析.如果省略list,则命令的输出与早期版本的lscpu兼容,兼容格式以两个逗号用于分隔cpu缓存列,如果没有发现cpu缓存,则省略缓存列,如果使用list参数,则缓存列以冒号(:)分隔。在指定了list参数时,选项的字符串、等号(=)和列表必须不包含空格或者其它空白。比如:’-e=cpu,node’ or ’–extended=cpu,node’ -s, –sysroot directory: 为一个Linux实例收集CPU数据,而不是发出lscpu命令的实例。指定的目录是要检查Linux实例的系统根 -x, –hex:使用十六进制来表示cpu集合,默认情况是打印列表格式的集合(例如:0,1) 显示格式: Architecture: #架构 CPU(s): #逻辑cpu颗数 Thread(s) per core: #每个核心线程 Core(s) per socket: #每个cpu插槽核数/每颗物理cpu核数 CPU socket(s): #cpu插槽数 Vendor ID: #cpu厂商ID CPU family: #cpu系列 Model: #型号 Stepping: #步进 CPU MHz: #cpu主频 Virtualization: #cpu支持的虚拟化技术 L1d cache: #一级缓存(google了下,这具体表示表示cpu的L1数据缓存) L1i cache: #一级缓存(具体为L1指令缓存) L2 cache: #二级缓存 -
free
Linux free命令用于显示内存状态。 free指令会显示内存的使用情况,包括实体内存,虚拟的交换文件内存,共享内存区段,以及系统核心使用的缓冲区等。 语法 free [-bkmotV][-s <间隔秒数>] 参数说明: -b 以Byte为单位显示内存使用情况。 -k 以KB为单位显示内存使用情况。 -m 以MB为单位显示内存使用情况。 -h 以合适的单位显示内存使用情况,最大为三位数,自动计算对应的单位值。单位有: B = bytes K = kilos M = megas G = gigas T = teras -o 不显示缓冲区调节列。 -s<间隔秒数> 持续观察内存使用状况。 -t 显示内存总和列。 -V 显示版本信息。 实例 显示内存使用情况 # free //显示内存使用信息 total used free shared buffers cached Mem: 254772 184568 70204 0 5692 89892 -/+ buffers/cache: 88984 165788 Swap: 524280 65116 459164 以总和的形式显示内存的使用信息 # free -t //以总和的形式查询内存的使用信息 total used free shared buffers cached Mem: 254772 184868 69904 0 5936 89908 -/+ buffers/cache: 89024 165748 Swap: 524280 65116 459164 Total: 779052 249984 529068 周期性的查询内存使用信息 # free -s 10 //每10s 执行一次命令 total used free shared buffers cached Mem: 254772 187628 67144 0 6140 89964 -/+ buffers/cache: 91524 163248 Swap: 524280 65116 459164 total used free shared buffers cached Mem: 254772 187748 67024 0 6164 89940 -/+ buffers/cache: 91644 163128 Swap: 524280 65116 459164 -
lspci
-
lsusb
多命令协作
-
管道:
|Linux 管道使用竖线|连接多个命令,这被称为管道符。Linux 管道的具体语法格式如下: command1 | command2 command1 | command2 [ | commandN... ] 当在两个命令之间设置管道时,管道符|左边命令的输出就变成了右边命令的输入。只要第一个命令向标准输出写入,而第二个命令是从标准输入读取,那么这两个命令就可以形成一个管道。大部分的 Linux 命令都可以用来形成管道。 这里需要注意,command1 必须有正确输出,而 command2 必须可以处理 command2 的输出结果;而且 command2 只能处理 command1 的正确输出结果,不能处理 command1 的错误信息。 我们先看下面一组命令,使用 mysqldump(一个数据库备份程序)来备份一个叫做 wiki 的数据库: mysqldump -u root -p '123456' wiki > /tmp/wikidb.backup gzip -9 /tmp/wikidb.backup scp /tmp/wikidb.backup username@remote_ip:/backup/mysql/ 上述这组命令主要做了如下任务: mysqldump 命令用于将名为 wike 的数据库备份到文件 /tmp/wikidb.backup;其中-u和-p选项分别指出数据库的用户名和密码。 gzip 命令用于压缩较大的数据库文件以节省磁盘空间;其中-9表示最慢的压缩速度最好的压缩效果。 scp 命令(secure copy,安全拷贝)用于将数据库备份文件复制到 IP 地址为 remote_ip 的备份服务器的 /backup/mysql/ 目录下。其中username是登录远程服务器的用户名,命令执行后需要输入密码。 上述三个命令依次执行。然而,如果使用管道的话,你就可以将 mysqldump、gzip、ssh 命令相连接,这样就避免了创建临时文件 /tmp/wikidb.backup,而且可以同时执行这些命令并达到相同的效果。 使用管道后的命令如下所示: mysqldump -u root -p '123456' wiki | gzip -9 | ssh username@remote_ip "cat > /backup/wikidb.gz" 这些使用了管道的命令有如下特点: 命令的语法紧凑并且使用简单。 通过使用管道,将三个命令串联到一起就完成了远程 mysql 备份的复杂任务。 从管道输出的标准错误会混合到一起。 重定向和管道的区别 乍看起来,管道也有重定向的作用,它也改变了数据输入输出的方向,那么,管道和重定向之间到底有什么不同呢? 简单地说,重定向操作符>将命令与文件连接起来,用文件来接收命令的输出;而管道符|将命令与命令连接起来,用第二个命令来接收第一个命令的输出。如下所示: command > file command1 | command1 有些读者在学习管道时会尝试如下的命令,我们来看一下会发生什么: command1 > command2 答案是,有时尝试的结果将会很糟糕。这是一个实际的例子,一个 Linux 系统管理员以超级用户(root 用户)的身份执行了如下命令: cd /usr/bin ls > less 第一条命令将当前目录切换到了大多数程序所存放的目录,第二条命令是告诉 Shell 用 ls 命令的输出重写文件 less。因为 /usr/bin 目录已经包含了名称为 less(less 程序)的文件,第二条命令用 ls 输出的文本重写了 less 程序,因此破坏了文件系统中的 less 程序。 这是使用重定向操作符错误重写文件的一个教训,所以在使用它时要谨慎。http://c.biancheng.net/view/3131.html
https://www.jianshu.com/p/9c0c2b57cb73
-
输入输出重定向:
<,>,>>Shell 输入/输出重定向 大多数 UNIX 系统命令从你的终端接受输入并将所产生的输出发送回到您的终端。一个命令通常从一个叫标准输入的地方读取输入,默认情况下,这恰好是你的终端。同样,一个命令通常将其输出写入到标准输出,默认情况下,这也是你的终端。 重定向命令列表如下: 命令 说明 command > file 将输出重定向到 file。 command < file 将输入重定向到 file。 command >> file 将输出以追加的方式重定向到 file。 n > file 将文件描述符为 n 的文件重定向到 file。 n >> file 将文件描述符为 n 的文件以追加的方式重定向到 file。 n >& m 将输出文件 m 和 n 合并。 n <& m 将输入文件 m 和 n 合并。 << tag 将开始标记 tag 和结束标记 tag 之间的内容作为输入。 需要注意的是文件描述符 0 通常是标准输入(STDIN),1 是标准输出(STDOUT),2 是标准错误输出(STDERR)。 输出重定向 重定向一般通过在命令间插入特定的符号来实现。特别的,这些符号的语法如下所示: command1 > file1 上面这个命令执行command1然后将输出的内容存入file1。 注意任何file1内的已经存在的内容将被新内容替代。如果要将新内容添加在文件末尾,请使用>>操作符。 实例 执行下面的 who 命令,它将命令的完整的输出重定向在用户文件中(users): $ who > users 执行后,并没有在终端输出信息,这是因为输出已被从默认的标准输出设备(终端)重定向到指定的文件。 你可以使用 cat 命令查看文件内容: $ cat users _mbsetupuser console Oct 31 17:35 tianqixin console Oct 31 17:35 tianqixin ttys000 Dec 1 11:33 输出重定向会覆盖文件内容,请看下面的例子: $ echo "菜鸟教程:www.runoob.com" > users $ cat users 菜鸟教程:www.runoob.com $ 如果不希望文件内容被覆盖,可以使用 >> 追加到文件末尾,例如: $ echo "菜鸟教程:www.runoob.com" >> users $ cat users 菜鸟教程:www.runoob.com 菜鸟教程:www.runoob.com $ 输入重定向 和输出重定向一样,Unix 命令也可以从文件获取输入,语法为: command1 < file1 这样,本来需要从键盘获取输入的命令会转移到文件读取内容。 注意:输出重定向是大于号(>),输入重定向是小于号(<)。 实例 接着以上实例,我们需要统计 users 文件的行数,执行以下命令: $ wc -l users 2 users 也可以将输入重定向到 users 文件: $ wc -l < users 2 注意:上面两个例子的结果不同:第一个例子,会输出文件名;第二个不会,因为它仅仅知道从标准输入读取内容。 command1 < infile > outfile 同时替换输入和输出,执行command1,从文件infile读取内容,然后将输出写入到outfile中。 重定向深入讲解 一般情况下,每个 Unix/Linux 命令运行时都会打开三个文件: 标准输入文件(stdin):stdin的文件描述符为0,Unix程序默认从stdin读取数据。 标准输出文件(stdout):stdout 的文件描述符为1,Unix程序默认向stdout输出数据。 标准错误文件(stderr):stderr的文件描述符为2,Unix程序会向stderr流中写入错误信息。 默认情况下,command > file 将 stdout 重定向到 file,command < file 将stdin 重定向到 file。 如果希望 stderr 重定向到 file,可以这样写: $ command 2 > file 如果希望 stderr 追加到 file 文件末尾,可以这样写: $ command 2 >> file 2 表示标准错误文件(stderr)。 如果希望将 stdout 和 stderr 合并后重定向到 file,可以这样写: $ command > file 2>&1 或者 $ command >> file 2>&1 如果希望对 stdin 和 stdout 都重定向,可以这样写: $ command < file1 >file2 command 命令将 stdin 重定向到 file1,将 stdout 重定向到 file2。 Here Document Here Document 是 Shell 中的一种特殊的重定向方式,用来将输入重定向到一个交互式 Shell 脚本或程序。 它的基本的形式如下: command << delimiter document delimiter 它的作用是将两个 delimiter 之间的内容(document) 作为输入传递给 command。 注意: 结尾的delimiter 一定要顶格写,前面不能有任何字符,后面也不能有任何字符,包括空格和 tab 缩进。 开始的delimiter前后的空格会被忽略掉。 实例 在命令行中通过 wc -l 命令计算 Here Document 的行数: $ wc -l << EOF 欢迎来到 菜鸟教程 www.runoob.com EOF 3 # 输出结果为 3 行 $ 我们也可以将 Here Document 用在脚本中,例如: #!/bin/bash # author:菜鸟教程 # url:www.runoob.com cat << EOF 欢迎来到 菜鸟教程 www.runoob.com EOF 执行以上脚本,输出结果: 欢迎来到 菜鸟教程 www.runoob.com /dev/null 文件 如果希望执行某个命令,但又不希望在屏幕上显示输出结果,那么可以将输出重定向到 /dev/null: $ command > /dev/null /dev/null 是一个特殊的文件,写入到它的内容都会被丢弃;如果尝试从该文件读取内容,那么什么也读不到。但是 /dev/null 文件非常有用,将命令的输出重定向到它,会起到"禁止输出"的效果。 如果希望屏蔽 stdout 和 stderr,可以这样写: $ command > /dev/null 2>&1 注意:0 是标准输入(STDIN),1 是标准输出(STDOUT),2 是标准错误输出(STDERR)。
git操作命令
-
git是一个开源的分布式版本控制系统,Linux的开源代码一般都采用git管理
-
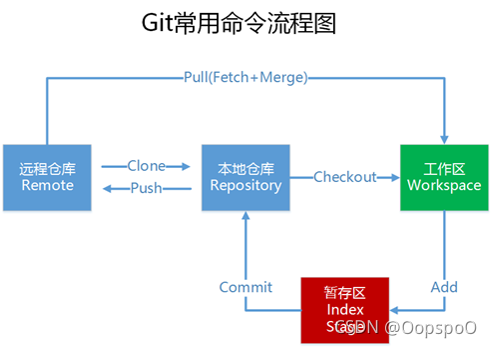
git常用命令
git clone git branch git fetch git pull git add git commit git push git log git diff git show git checkout
Reference
菜鸟教程 https://www.runoob.com/linux/linux-tutorial.html
鸟哥的私房菜 http://linux.vbird.org/
Linux就该这么学 https://www.linuxprobe.com/
Pro Git https://git-scm.com/book/zh/v2