摘要
在学习数据库原理之前很多小伙伴可能都会接触文件系统管理,现在我们用一个实例来理解一下它。假如我们有一个教学管理系统,所有的数据都用csv文件保存,我们如何模拟对这个系统的一系列操作呢?且听我慢慢道来
目录
压缩文件说明
文件的随机生成
1.首先是记录学生选课信息的文件StudentClassChoose.csv
2.其次是记录学生每门课程分数的文件CourseGrades.csv
3.然后是课程信息文件CourseInfo.csv
4.最后是教师信息文件
模拟数据管理
1.如果我们需要查询某个学生的选课情况,请问怎么实现?
2.如果我们要查询某门课程的选课情况,如何实现?
3.如果我们要修改某个学生某门课程的分数,怎么实现?
4.如果我们要给某个学生退课,怎么操作实现?
5.如果一个教师没有开课,我们怎么查询这个教师的信息?
6.如果我们需要约束每个学生每个选课的学分不能低于20,如何实现?
总结
压缩文件说明
我将我用到的所有代码都保存为了一个R脚本文件FonctionCode.R并放在了文件夹中,里面的csv文件是我在模拟过程中用到的文件,读者也可以删除以后自己调用函数来模拟~
点这里下载~
文件的随机生成
为了模拟文件系统的管理方式,在这里我使用R语言作为工具,首先假设有一个教学管理系统,我们先为它随机生成一些数据文件:
1.首先是记录学生选课信息的文件StudentClassChoose.csv
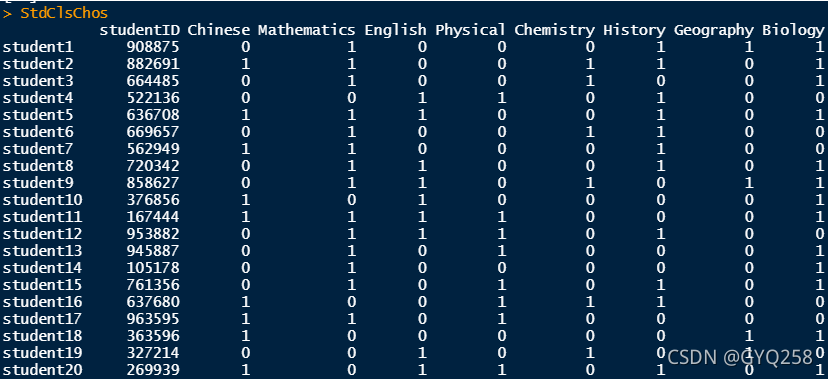
假设我们有100个学生,这里用一个6位的学号作为其唯一标识,假设有八门课程分别为Chinese,Mathematics,English,Physical,Chemistry,Biology,History和Geography,为便于读者模拟,我把它放到函数StudentChooseClass中,调用StudentChooseClass(),即可生成文件StudentClassChoose.csv,模拟学生选课的这一过程,表中0表示为选课,1表示已选课:
StudentChooseClass <- function(){
studentID <- as.character(sample(100000:999999,100))
Chinese <- sample(0:1,100,replace = T)
Mathematics <- sample(0:1,100,replace = T)
English <- sample(0:1,100,replace = T)
Physical <- sample(0:1,100,replace = T)
Chemistry <- sample(0:1,100,replace = T)
Biology <- sample(0:1,100,replace = T)
History <- sample(0:1,100,replace = T)
Geography <- sample(0:1,100,replace = T)
StdClsChos <- data.frame(studentID,Chinese,Mathematics,English,Physical,Chemistry,History,Geography,Biology)
rownames(StdClsChos) <- paste("student",1:100,sep = "")
write.csv(StdClsChos,"StudentClassChoose.csv")
}可以看一下随机生成的结果(这里只展示前20条):
2.其次是记录学生每门课程分数的文件CourseGrades.csv
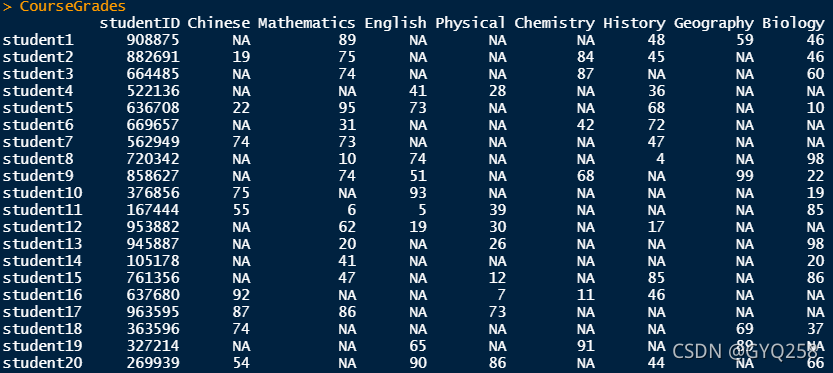
在这里需要注意的是,学生只有在选了课程以后相应的课程才会有分数,所以在随机生成这一文件的时候是有一定的条件的,需要参照StudentClassChoose.csv里的选课信息来赋予分数,在这里我用两重循环来实现,未选的课程用NA来表示,并放到了函数RandomCourseGrades()中:
RandomCourseGrades <- function(){
CourseGrades <- StdClsChos
for(i in 1:nrow(CourseGrades)){
for(j in 2:ncol(CourseGrades)){
if(StdClsChos[i,j]==1)CourseGrades[i,j] <- sample(0:100,1)
else if(StdClsChos[i,j]==0)CourseGrades[i,j] <- NA
}
}
write.csv(CourseGrades,"CourseGrades.csv")
}我们看一下随机生成的结果:
3.然后是课程信息文件CourseInfo.csv
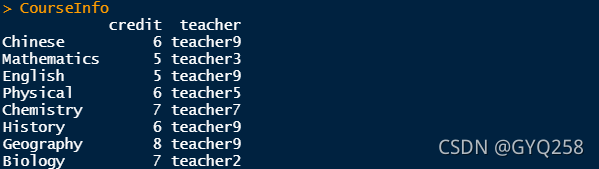
假设每个课程包含课程学分和任课教师的信息,我们也同样可以通过模拟生成一个文件:
RandCourseInfo <- function(){
AllTeacher <- paste("teacher",1:9,sep = "")
course <- c("Chinese","Mathematics","English","Physical","Chemistry","History","Geography","Biology")
teacher <- sample(AllTeacher,8,replace = T)
credit <- sample(5:8,8,replace = T)
CourseInfo <- data.frame(credit,teacher)
row.names(CourseInfo) <- course
write.csv(CourseInfo,"CourseInfo.csv")
}这里假设课程学分从5到8分不等,我们可以看看生成的结果:
4.最后是教师信息文件
延续上一步的工作,假设总共有9个教师,他们的信息包括教职工ID、职称、开课信息等,这里需要注意开课信息需要和课程信息文件相吻合,具体代码如下,经实现这一功能的函数命名为RandTeacherInfo():
RandTeacherInfo <- function(){
CourseInfo <- read.csv("CourseInfo.csv",header = T,row.names = 1)
ID <- as.character(sample(1000:9999,9))
AllTitle <- c("pro","resercher","assistant","lecturer")
Title <- sample(AllTitle,9,replace = T)
AllTeacher <- paste("teacher",1:9,sep = "")
course <- rep("",9)
TeacherInfo <- data.frame(ID,Title,course)
row.names(TeacherInfo) <- AllTeacher
for(i in 1:nrow(CourseInfo)){
TeacherInfo[CourseInfo[i,"teacher"],"course"] <- paste(TeacherInfo[CourseInfo[i,"teacher"],"course"],row.names(CourseInfo)[i],sep = " ")
}
write.csv(TeacherInfo,"TeacherInfo.csv")
}可以查看一下结果:
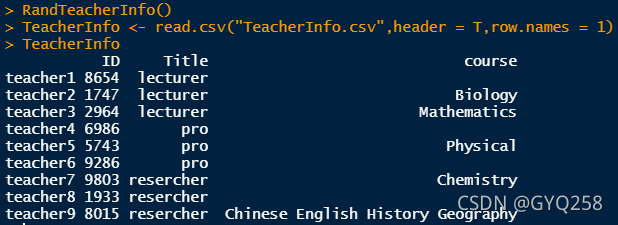
teacher9确实开了很多课......
模拟数据管理
1.如果我们需要查询某个学生的选课情况,请问怎么实现?
由于StudentClassChoose.csv保存了学生的选课信息,我们只需打开该文件后查询特定学生的选课情况即可,为此编写一个函数Search_StudentChoosing:
Search_StudentChoosing <- function(ID){
StdClsChos <- read.csv("StudentClassChoose.csv",header = T,row.names = 1)
colnames(StdClsChos)[StdClsChos[which(StdClsChos[,"studentID"]==ID),]==1]
}比如我们要查看学号为882691的学生的选课信息:
![]()
发现该学生选的课程有语文、数学、化学、历史和生物。
2.如果我们要查询某门课程的选课情况,如何实现?
同样的道理,这一信息也存储于StudentClassChoose.csv文件中,我们同样可以编写一个函数Search_CourseChoosing来实现这一功能:
Search_CourseChoosing <- function(course){
StdClsChos <- read.csv("StudentClassChoose.csv",header = T,row.names = 1)
rownames(StdClsChos)[StdClsChos[course]==1]
}假如要查看哪些同学选了生物课:

看来选生物课的同学还是挺多的哈哈哈
3.如果我们要修改某个学生某门课程的分数,怎么实现?
由于学生的课程分数保存在CourseGrades.csv文件中,我们先在其中查找某个学生的某个课程分数,如果为NA则说明他没选这门课,提示错误信息,如果有则根据给出的grades将该课程分数改为grades并保存,为实现这一功能,编写函数ModifyGrades():
ModifyGrades <- function(ID,course,grades){
CourseGrades <- read.csv("CourseGrades.csv",header = T,row.names = 1)
n <- which(CourseGrades$studentID==ID)
if(is.na(CourseGrades[n,course]))print("he/she hasn't chosen this course")
else {
CourseGrades[n,course]=grades
write.csv(CourseGrades,"CourseGrades.csv")
}
}我们先来看一下student16的成绩信息:

假如要修改它的历史和生物成绩:

4.如果我们要给某个学生退课,怎么操作实现?
学生退课涉及到要同时修改CourseGrades.csv和StudentClassChoose.csv两个文件,首先还是检查学生是否选修对应课程,若未选则报错,选择了需要同时修改该学生对该课程的选课情况为0,同时更改其分数为NA,为实现这一功能,编写函数DropOut():
DropOut <- function(ID,course){
StdClsChos <- read.csv("StudentClassChoose.csv",header = T,row.names = 1)
CourseGrades <- read.csv("CourseGrades.csv",header = T,row.names = 1)
n <- which(StdClsChos$studentID==ID)
if(StdClsChos[n,course]==0){
print("he/she hasn't chosen this course")
}else{
StdClsChos[n,course] <- 0
CourseGrades[n,course] <- NA
}
write.csv(StdClsChos,"StudentClassChoose.csv")
write.csv(CourseGrades,"CourseGrades.csv")
}来看看22号学生的信息:

假如他要退掉成绩最差的化学课:

退课成功!
5.如果一个教师没有开课,我们怎么查询这个教师的信息?
学生在选课时可以通过CourseInfo.csv中的课程信息看到开课教师的信息,但如果有的教师没有开课(比如我们这里模拟的结果总共有9个老师,但是只有teacher2、3、5、7、9五位老师有开课,其他的老师怎么办呢,这时候就只能直接查找教师信息了,由于这一工作只有一行的代码量,比较简单,我就没有单独写函数了。假如要查找teacher4的信息,直接在控制台输入:
> TeacherInfo["teacher4",]结果如下:
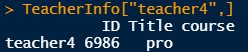
可以看到这位教授确实是没有开课的
6.如果我们需要约束每个学生每个选课的学分不能低于20,如何实现?
我们来模拟一下某个学生的选课过程,由于要检测这个学生所选的学分是否低于20,我们就需要用到课程信息文件CourseInfo.csv和学生选课信息的文件StudentClassChoose.csv。如果这是学生选的最后一门课,则参数op需要改为"end",否则默认会继续进行选课,当参数op为"end"时就会检测这个学生所选的学分是否低于20,如果低于20则会给出提示信息,并强制进行继续选课
SelectCourse <- function(ID,course,op="continue"){
StdClsChos <- read.csv("StudentClassChoose.csv",header = T,row.names = 1)
CourseGrades <- read.csv("CourseGrades.csv",header = T,row.names = 1)
n <- which(StdClsChos$studentID==ID)
if(StdClsChos[n,course]==1){
print("he/she has already chosen this course")
}else{
StdClsChos[n,course] <- 1
CourseGrades[n,course] <- sample(0:100,1)
}
if(op=="end"){
CourseInfo <- read.csv("CourseInfo.csv",header = T,row.names = 1)
TotalCredit <- 0
for(i in 2:ncol(StdClsChos)){
if(StdClsChos[n,i]==1)TotalCredit <- TotalCredit+CourseInfo[colnames(StdClsChos)[i],"credit"]
}
if(TotalCredit<20){
write.csv(StdClsChos,"StudentClassChoose.csv")
write.csv(CourseGrades,"CourseGrades.csv")
print("the total credits of your selected courses still less than 20!!!please input an another course and your op")
course <- readline()
op <- readline()
SelectCourse(ID,course,op)
}else{
write.csv(StdClsChos,"StudentClassChoose.csv")
write.csv(CourseGrades,"CourseGrades.csv")
}
}
else{
write.csv(StdClsChos,"StudentClassChoose.csv")
write.csv(CourseGrades,"CourseGrades.csv")
print("please input an another course and your op")
course <- readline()
op <- readline()
SelectCourse(ID,course,op)
}
}现在我们找一个选课比较少的学生来看看:

让我们看看课程信息:

因此他只选了历史是不够的,只有6学分,我们来模拟一下选课:

第一次选了数学就想结束?不存在的,系统会让你继续选课,然后选了英语又想结束选课,同样没到标准,最后再选了一门生物才终于能结束选课,这时候我们可以来看看他的选课信息:
![]()
这时候已经选了四门课了
总结
从以上的例子可以看出,文件系统管理数据有很多麻烦的地方:
1.文件系统面向某一应用程序,共享性差,冗余度大,每次需要实现一个应用程序功能都要有一个专门为他服务的文件,这样也会造成存在很多冗余信息。
2.数据独立性差,记录内有结构,整体无结构,很容易把人绕晕。(我做完这个真的已经晕了)
3.文件系统中的程序和数据的联系很大,开发应用的人需要对数据文件也很熟悉,不能做到程序和数据相分离。
4.安全性不高,从上面我做的例子就可以看出,修改某一内容需要同时更改好几个文件里的内容,否则数据自身就可能会出现矛盾(不同文件中信息不一致)
......
这也是我们为什么要用数据库来管理数据的原因,之后有时间(等我学好了数据库)我们再一起来谈一谈数据库的管理以及它的优点~
第一篇文章不容易,还希望各位老爷点个赞多多支持呜呜呜