超详细的C进阶教程!(四)深度解剖C语言自定义类型_东条希尔薇的博客
作者的码云地址:https://gitee.com/dongtiao-xiewei
后续作者会更新力扣的每日一题系列,原代码会全部上传码云,推荐关注哦,笔芯~
还像更深入地了解c语言?快来订阅作者的c语言进阶专栏!作者承诺本系列不会TJ!预计更新:指针,字符串处理,内存管理,结构体,预处理等等
自定义变量
- 引言
- 结构体
- 结构体声明
- 匿名结构体类型
- 结构体自引用
- 结构体的定义与初始化
- 结构体内存对齐
- 结构体传参
- 位段
- 枚举
- 枚举的定义
- 枚举的取值
- 枚举的应用
- 联合体
- 联合体定义
- 联合的特点
- 联合体大小的计算
引言
嗨喽小伙伴们我又来啦!冲冲冲!

在我们刚开始学C语言,还是个C语言萌新时候,想必已经对结构类型这四个字已经耳朵都快听出茧子了吧!
为了让计算机能够控制各种各样的数据,C语言中引入了像char,short,int,float,等基本数据类型。使我们能够控制一些简单的数据。
但是,有没有想过,有些复杂的数据类型,不能单纯的由一个基本数据类型描述的,该怎么办?
比如,我们要描述一个学生
| 变量名 | 基本数据类型 |
|---|---|
| 姓名 | char |
| 年龄 | int |
| 性别 | char |
| 成绩 | float |
亦或者,我们要描述一本书的信息
| 变量名 | 基本数据类型 |
|---|---|
| 书名 | char |
| 价格 | float |
| 作者 | char |
| 出版社 | char |
我们可以观察到,这些信息只用一个基本数据类型是远远不能描述的,所以,为了解决这个问题,我们引入了自定义类型
而解决以上的问题,用到结构体就行了
结构体
结构体是一堆值的集合,这些值被称为成员变量
我们可以在结构体类型中封装一系列变量,方便描述我们在引例中给出的复杂类型
结构体声明
它的声明通用方式是
struct tag//结构体类型名
{
//member
//这里定义成员变量
};//分号千万不能丢
可以紧跟在分号后面创建变量,创建的为全局变量,也可以直接在此进行初始化
{
...
}s1,s2;//创建方式
例如,我们将引例中的例子来用结构体说明
//学生类型
struct Stu
{
char name[20];
int age;
char sex[5];
float score;
};
//书信息类型
struct Book
{
float price;
char name[20];
char author[20];
};
等等。
但是下面有一种不寻常的声明方式
匿名结构体类型
声明的时候,可以省略结构体的名字
struct//这里的tag被省略了
{
int a;
int b;
}x;
因为省略了结构体类型名,所以我们不能在主函数中定义结构体变量了
在声明后面定义也是唯一的方式
结构体自引用
我们应该都接触过链表这种数据结构,它在内存中不是连续存放的,但它们之间有一种逻辑关系,可以把它们联系在一起
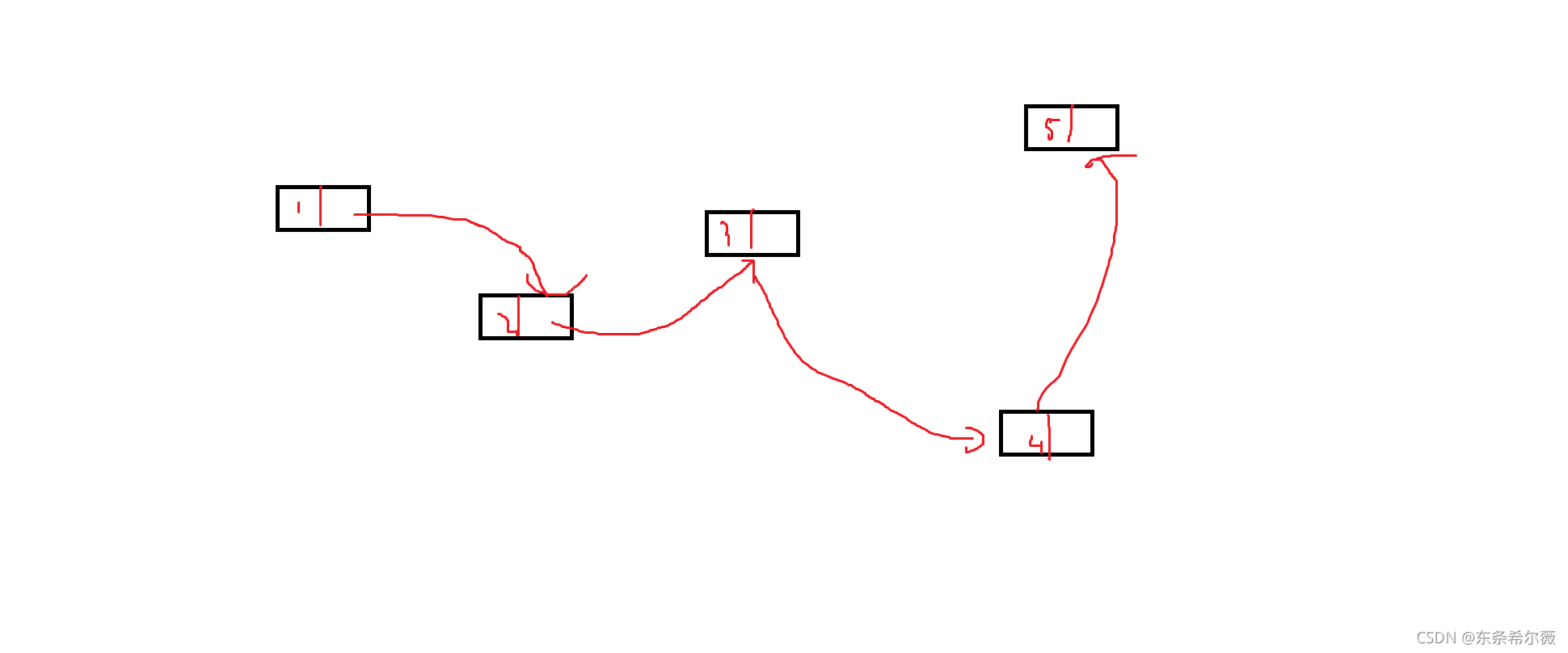
有没有想过,它们是如何联系起来的呢?
这样定义链表可以吗?
struct ListNode
{
int data;
struct ListNode next;
};
萌新可能比较容易理解为,一个链表先是一个数据,而为了存放下一个链表,在结构体中再定义一个结点结构体,方便查找下一个结点
如果这样可行的话,那这个你怎么算?
sizeof(struct ListNode)
很显然算不出来,因为在一个结构体中再定义一个自己,自己套自己,将会无限套娃下去
所以这个方法显然不可行
那么,如何实现正确的自引用呢?
正确的自引用方式
可以考虑使用地址,还是拿链表举例
struct ListNode
{
int data;
struct ListNode* next;
};
它现在在内存中的存储就是这样的了
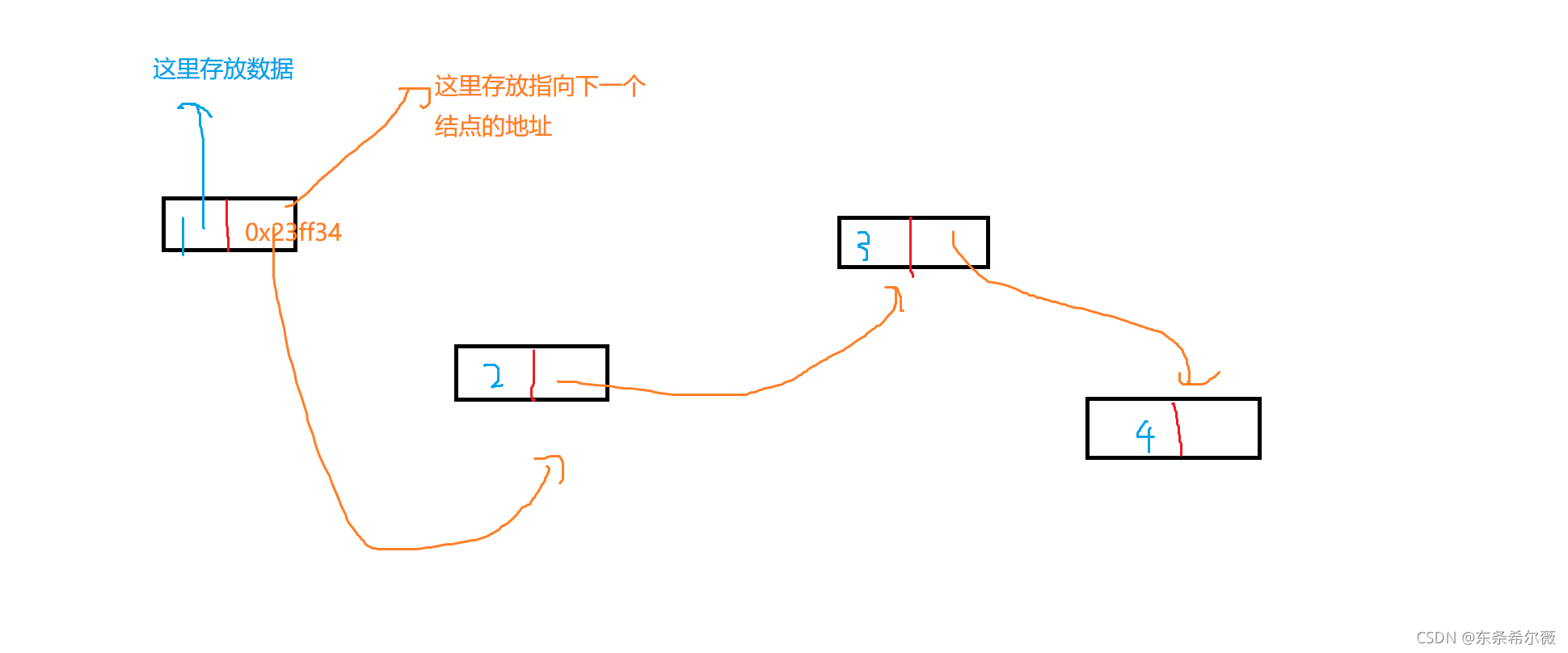
结构体的定义与初始化
定义:全局定义,局部定义
定义的类型名:struct tag
例如定义一个学生变量
struct Stu s1;
初始化:用大括号初始化,成员变量用逗号隔开
还是上面的学生类型
s1={"zhangsan",18,"man",99,5};
初始化也可以嵌套初始化
结构体内存对齐
这里我们主要讨论一个问题:如何计算结构体类型的大小
struct S1
{
char a;
char b;
int c;
};
struct S2
{
char a;
int b;
char c;
};
int main()
{
printf("%d,%d\n",sizeof(struct S1),sizeof(struct S2));
return 0;
}
可能大家就猜测了,一个char1字节,一个int4字节,大小是不是就是6字节啊?
遗憾的是,并不是,不仅不是,这两个结构体大小都不一样

那怎么计算结构体变量大小的呢?
这里就需要用到结构体对齐了,直接先上结论再解释
- 第一个成员在与结构体变量偏移量为0的地址处。
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。
VS中默认的值为8
Linux中的默认值为4
- 结构体总大小为最大对齐数的整数倍。
这里画图为大家详细的解释一下
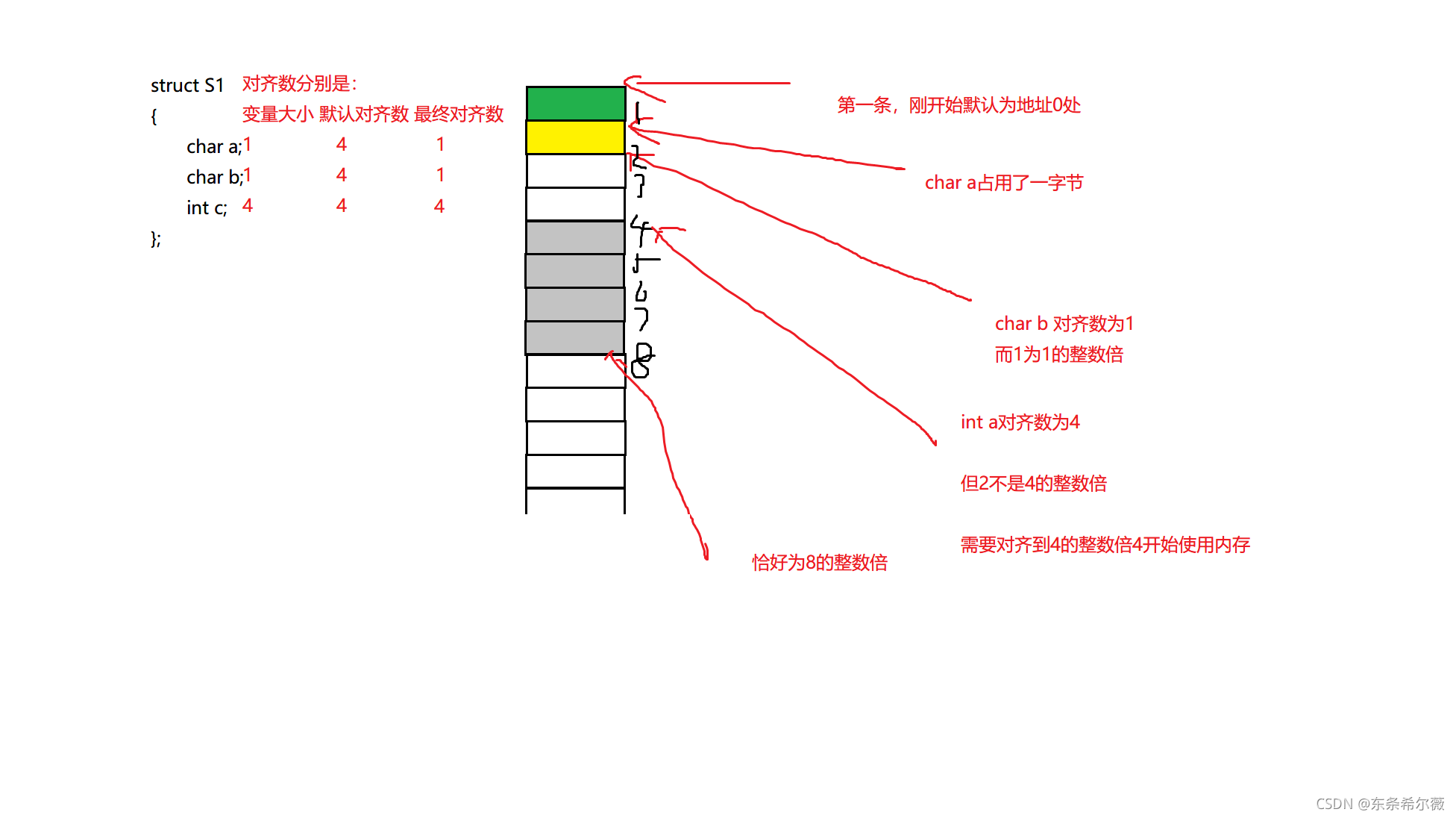
现在大家应该就会算结构体类型大小的吧?
那为什么会存在内存对齐现象呢?
大家可以重点记住,这是一种用空间换取时间的做法
为了节省空间,我们可以把小的成员变量定义在一起
默认对齐数也是可以修改的
#pragma pack()//括号内是默认对齐数,建议修改为2^n
结构体传参
结论:传参的时候尽量使用指针,因为传值调用需要压栈,会重新复制一份
结构体,导致性能的下降,而在函数内修改结构体的内容也必须用到指针
使用方法
void func(struct S2* ps)
{
ps->a=0//注意这里使用箭头,结构体为指针时的成员访问方式
}
位段
这里好多教材上都没有哦!
我们需要先明白几个概念:
- 这里的位,指的是二进制的位
- 位段可以同样使用结构体实现
- 位段的成员必须是int,unsigned int(标准的定义没有char类型,但经过实验,char类型也可实现位段)
位段的声明如下
struct Test
{
char a:3;
char b:4;
char c:5;
char d:4;
};
位段名后面必须跟一个冒号和数字
那么,位段是如何开辟的空间?
重点:位段后面的数字,表示这个变量需要占用的比特位
例如test结构体位段
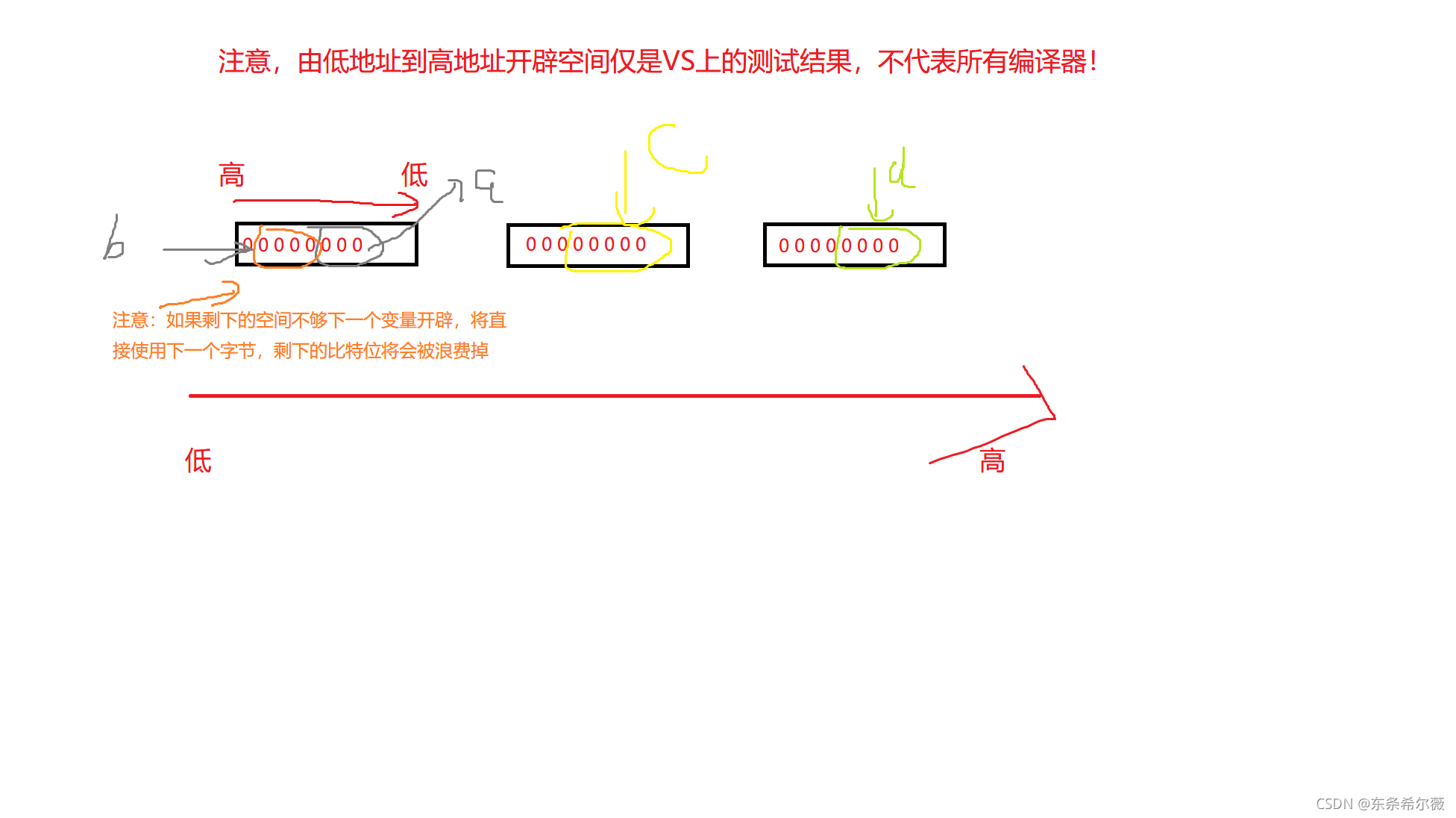
如果我们尝试修改呢?
注意,这里同样会发生截断现象!
struct Test
{
char a : 3;
char b : 4;
char c : 5;
char d : 4;
}s;
int main()
{
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
return 0;
}
它在内存中的情况就应该是以下这样
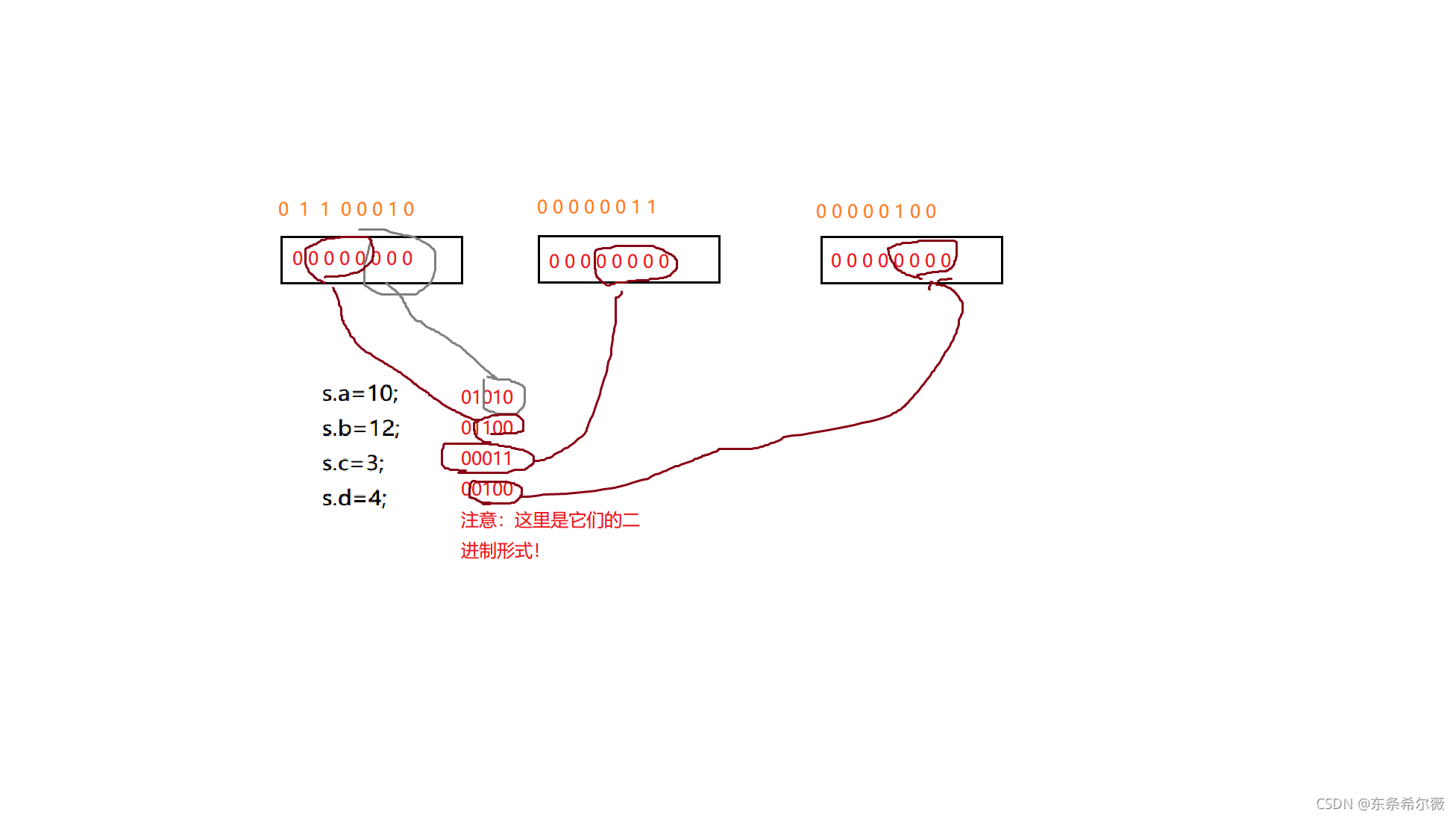
通过调试,验证了我们的结论
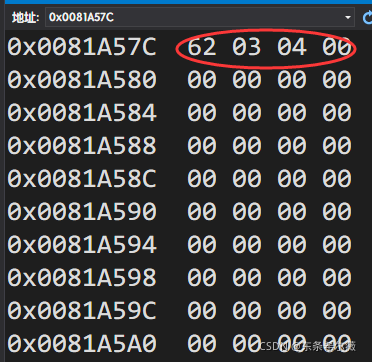
位段设计出来,有什么作用呢?
可以节省空间
比如,我们的学生类型中的分数变量,我们发现分数永远不会超过100分,所以我们只需要7个比特位存储,而不需要占用4字节,也就是32比特位了
枚举
注意,枚举是一种常量类型!
它与define定义的宏,和const都属于常量
顾名思义,枚举类型就是把可能的取值,一一列举出来
枚举的定义
枚举的通用定义如下
//enum枚举关键字
enum name//枚举类型名
{
//member list枚举成员名
};
比如我们要定义一个星期
//enum为枚举类型关键字
enum Day
{
MON,
TUES,
WED,
THUR,
FRI,
SAT,
SUN
};
枚举的取值
默认第一个变量为0,一次递增1,当然可以在定义中赋予初值,后面的变量会继续以被赋予的值继续加一
enum Day
{
MON=1,
TUES,
WED,
THUR,
FRI,
SAT,
SUN
};
枚举的应用
基本使用:
可以定义枚举类型的变量,注意!定义了便不能被修改!
enum Day day1=MON;//定义了一个day1的枚举类型常用,初始化为MON
应用
比如我们要实现一个计算器
写一个计算器的菜单
- add 2. sub
- mul 4. div
我们在代码的选项中可以这样写
switch (option)
case 1:
case 2:
case 3:
case 4:
用数字来代替选项,会带来许多不必要的麻烦,如菜单对照等
我们考虑可以使用枚举变量
enum Option
{
ADD=1,
SUB,
MUL,
DIV
};
将菜单改为以下这样,就方便我们进行对照了
switch (option)
case ADD:
case SUB:
case MUL:
case DIV:
联合体
它的特征是成员变量共用一块存储空间
联合体定义
与结构体定义类似
union Test
{
char c;
int i;
}
联合的特点
就是共用一块成员变量,我们可以写个简单的代码验证一下
union U
{
int i;
char c;
}u;
int main()
{
u.i = 0x11223344;
u.c = 0x55;
printf("%x\n",u.i);
return 0;
}
输出结果为

联合体大小的计算
也存在内存对齐现象
- 至少为成员最大变量的大小,因为要确保能容纳下最大的变量
- 当最大成员大小不是最大对齐数整数倍的时候,要对齐到最大对齐数的整数倍
例如
union U
{
char c[5];
int i;
}
因为最大对齐数是4(int),并不是最大变量5的整数倍(char[5])
所以对齐前是5字节,对齐后就是8字节
登录后可发表评论
点击登录