从最开始接触fme的时候,我就一直有一个想法,fme能不能和机器学习、深度学习、统计学回归算法结合实现大批量数据的智能操作,奈何学识一直有限,到目前都没实现突破。
但是房地一体确权登记项目的扫描件相对很多不规范数据来说通过提取特征文字实现自动分类归档是可以通过用python调用谷歌的汉字识别库pytesseract来实现特征值提取,然后用fme进行数据清洗,最后整理数据输出成我们想要的档案档案结构。
既然大体思路已经定下来了,剩下的就是从各个技术难度逐一突破的问题了,首先python提取图片的包OpenCV,我们通过这个模块来实现fme的pythoncaller的对接
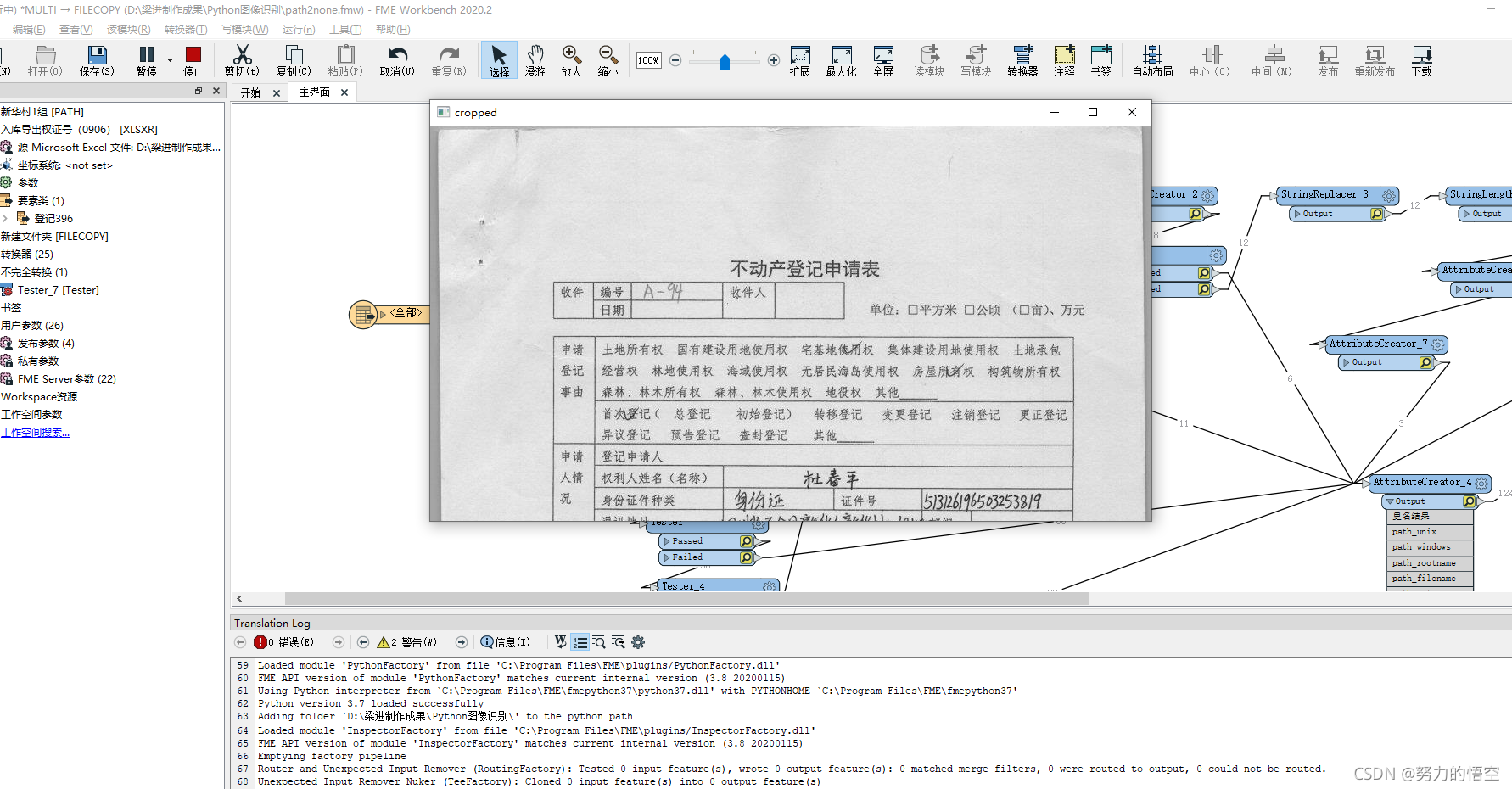
设置为截取图片上半截,可以看到fme成功和对接上了图片,接下来我们只需要调用pytesseract库来提取里面的文字,然后把提取出来的成果封装到字段内
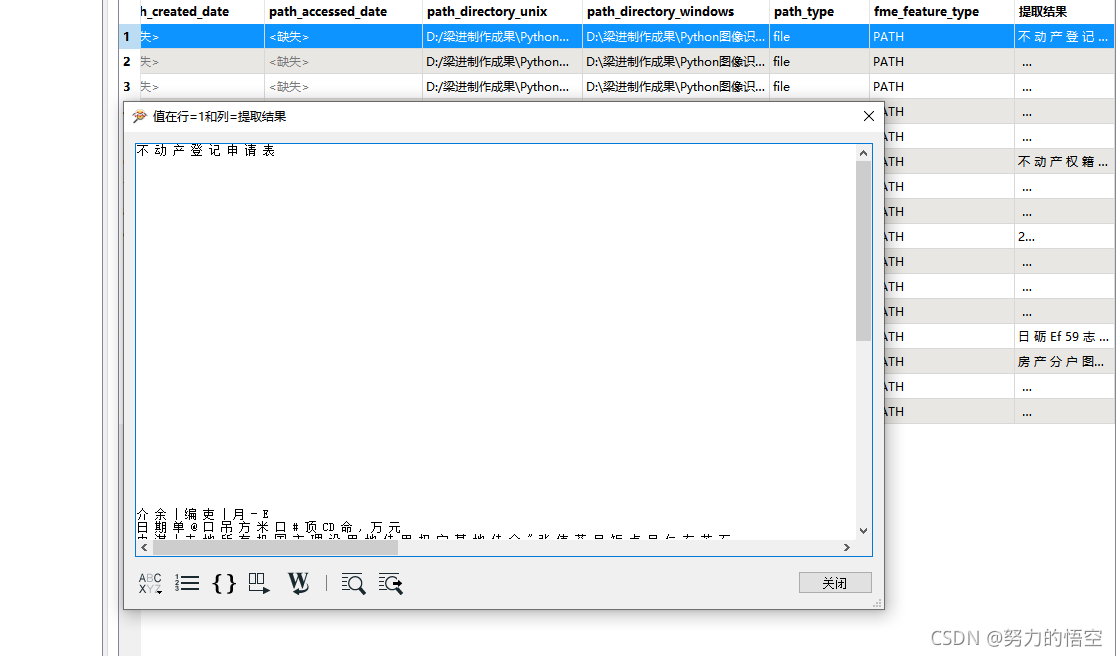
可以看到提取效果并不是很理想,但是核心关键的属性提取出来,给我们做分类是没有什么问题的。
接下来就是运用大量正则表达式,大量的字段替换清洗,特征值判断,来得到我们最终需要的属性
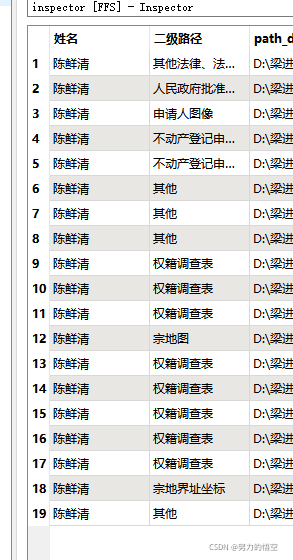
最终是将这些繁琐的扫描件成果分类,但是依旧存在少数文字识别错误无法提取对应特征值的属性,这种目前我只有将其单独标注出来,整理完成后手动修改,我测试了117条数据,有3条数据无法判读。
最后我们就只需要整理一下路径、参数,然后封装成映射文件,就可以投入使用了。下面是成果展示:
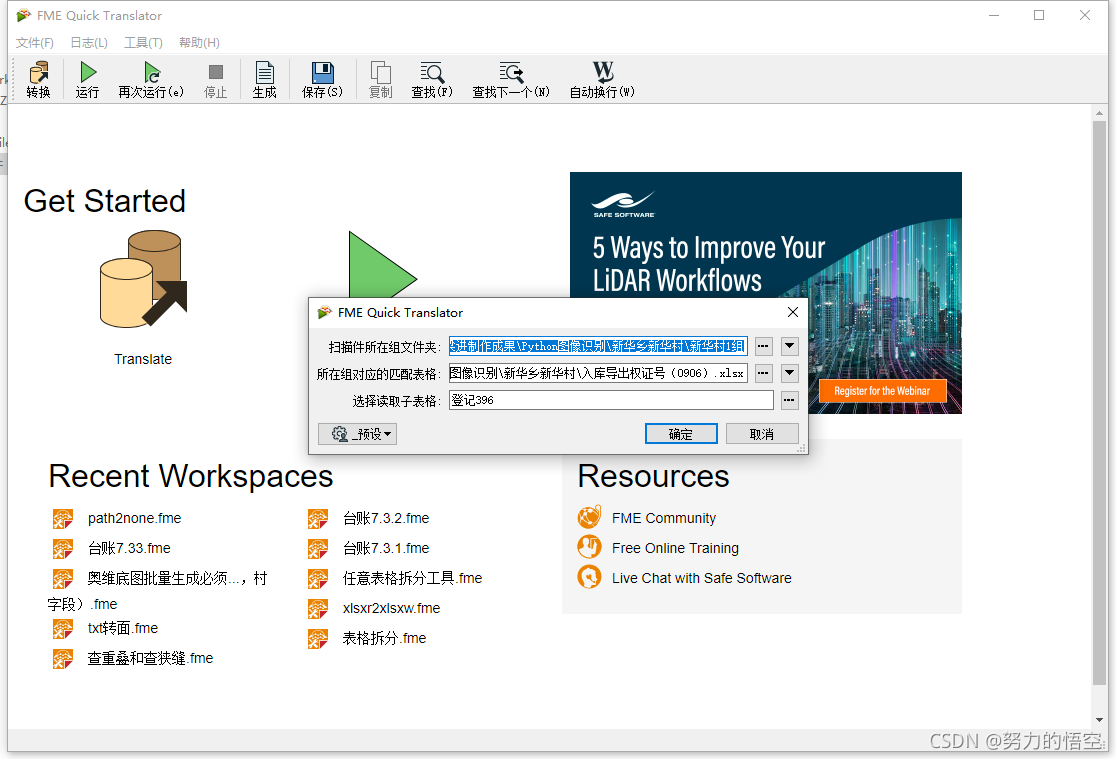
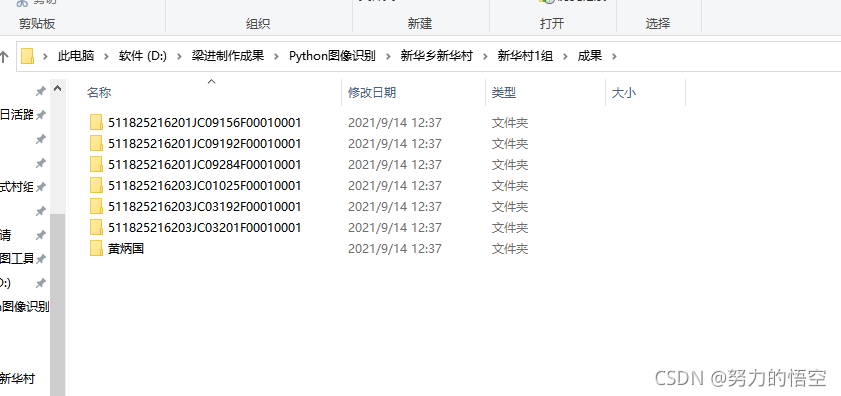
因为命名要求不同,这边项目要求没得权属来源的户按名字命名,其他则按照不动产单元号命名。
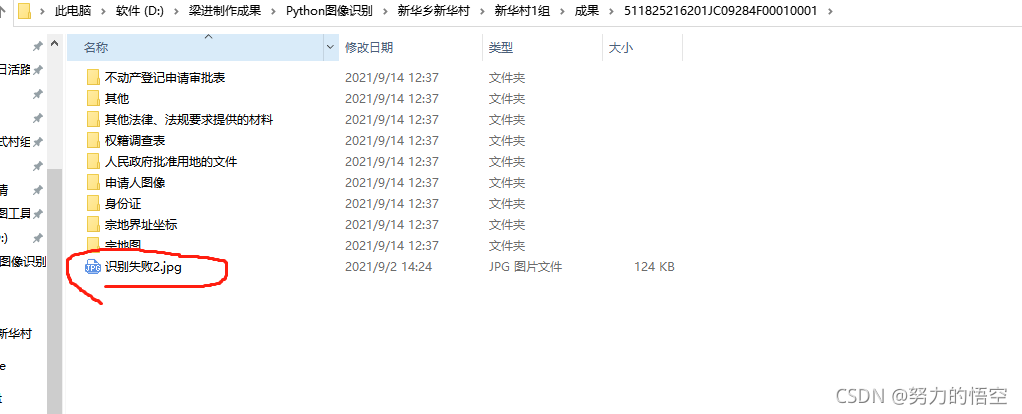 可以看到判读失败的图片被放在了最下方方便人工处理
可以看到判读失败的图片被放在了最下方方便人工处理
总结:谷歌研发文字识别库pytesseract对文字的识别效率还是太低,但是用于分类还是能满足项目需求。但是悟空依然觉得这套模板还有很大的进步空间,已经扩展性。或许使用sklearn做SVM监督学习,然后通过大量的数据投放,训练学习,最终实现0误差分类。或者用OpenCV和深度学习结合,生成智能识别框,按指定位置提取指定信息到指定字段,或许还能实现身份证、户口簿图片的信息提取。虽然现在市面上充斥着大量的这种产品,但是大都是调用的开源的识别的库,错误率非常之大,因为训练出一个合格的识别库需要花大量的时间精力,同时还得有顶级设备的支持。还好我之前提前购买了3090,希望后面能用他24的显存来让这个模板实现突破。需要该模板的小伙伴可以私聊我。关注一手,持续更新各种fme的扩展玩法。