HyperGBM介绍
本文章主要是对autoML开源框架HyperGBM的一个介绍。
文章目录
- HyperGBM介绍
- 一、关于HyperGBM
- 二、功能特性总览
- 二、如何安装HyperGBM
- 三、HyperGBM入门样例
- 1. 准备数据集
- 2. 创建实验并进行训练
- 3. 保存模型
- 4. 评价模型
- 四、HyperGBM基础应用
- 五、HyperGBM高级应用
- 六、HyperGBM处理样本不均衡问题
- 1. 利用ClassWeight建模
- 2. 欠采样或过采样
- 七、HyperGBM自定义搜索空间
- 八、HyperGBM自定义建模算法
一、关于HyperGBM
HyperGBM是一款全Pipeline自动机器学习工具,可以端到端的完整覆盖从数据清洗、预处理、特征加工和筛选以及模型选择和超参数优化的全过程,是一个真正的结构化数据AutoML工具包。
大部分的自动机器学习工具主要解决的是算法的超参数优化问题,而HyperGBM是将从数据清洗到算法优化整个的过程放入同一个搜索空间中统一优化。这种端到端的优化过程更接近于SDP(Sequential Decision Process)场景,因此HyperGBM采用了强化学习、蒙特卡洛树搜索等算法并且结合一个meta-leaner来更加高效的解决全Pipeline优化的问题,并且取得了非常出色的效果。
正如名字中的含义,HyperGBM中的机器学习算法使用了目前最流行的几种GBM算法(更准确的说是梯度提升树模型),目前包括XGBoost、LightGBM、CatBoost和HistGridientBoosting。同时,HyperGBM也引入了Hypernets的CompeteExperiment在数据清洗、特征工程、模型融合等环节的很多高级特性。
HyperGBM中的优化算法和搜索空间表示技术以及CompeteExperiment由 hypernets项目提供支撑。
二、功能特性总览
HyperGBM有3种运行模式,分别为:
- 单机模式:在一台服务器上运行,使用Pandas和Numpy数据结构
- 单机分布式:在一台服务器上运行,使用Dask数据结构,在运行HyperGBM之前需要创建运行在单机上的Dask集群
- 多机分布式:在多台服务器上运行,使用Dask数据结构,在运行HyperGBM之前需要创建能管理多台服务器资源的Dask集群
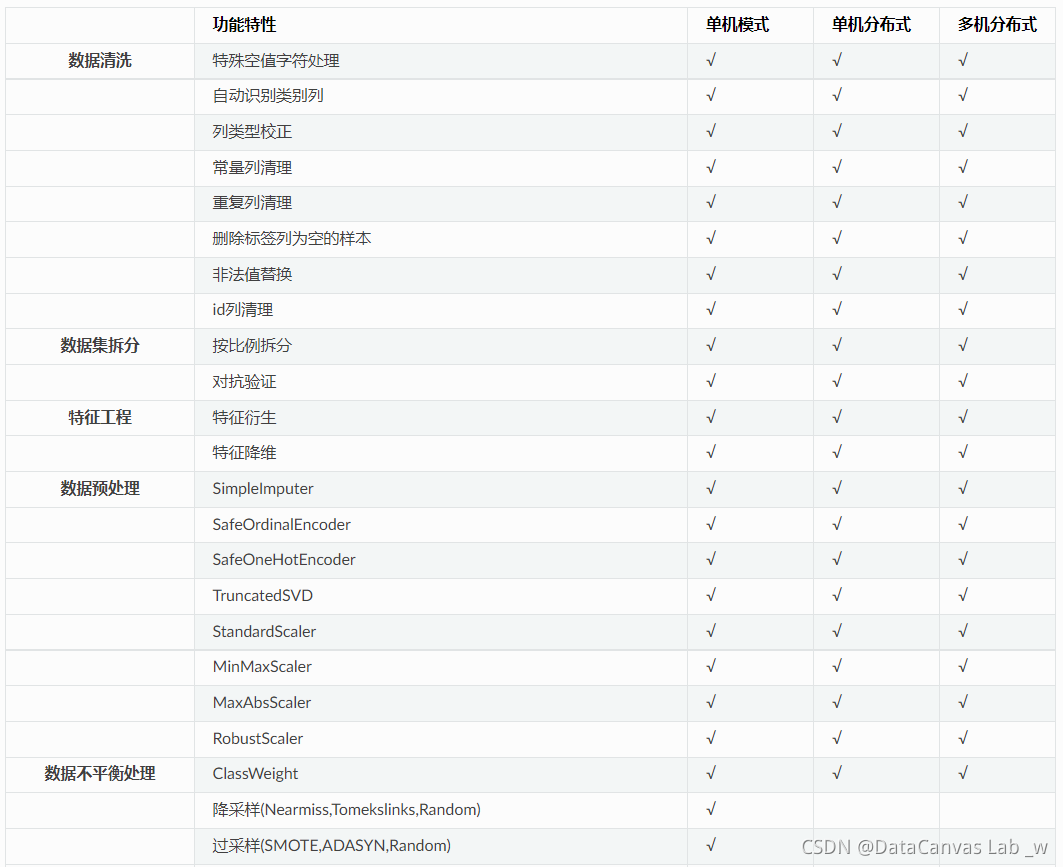
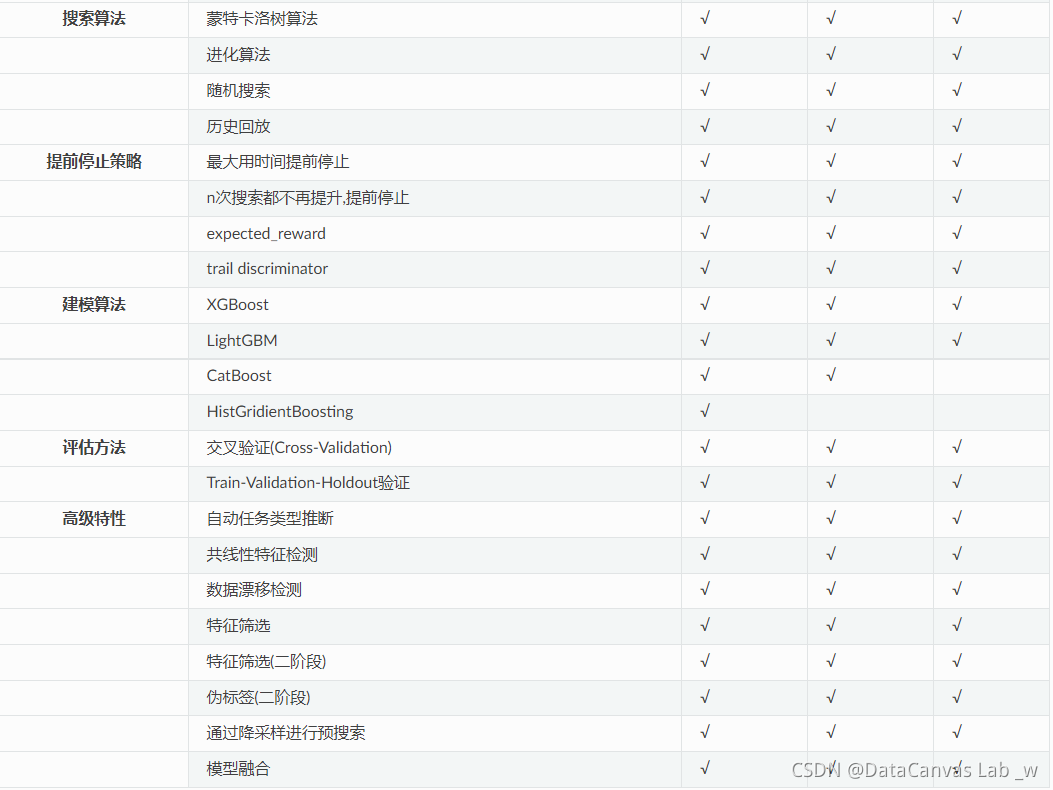
不同运行模式的功能特性支持稍有差异,HyperGBM的功能特性清单及各种的运行模式的支持情况如下表:
二、如何安装HyperGBM
可通过pip和docker两种方式进行安装,具体可参照如何安装HyperGBM
三、HyperGBM入门样例
HyperGBM基于Python开发,推荐利用 make_experiment 创建实验并进行训练得到模型。
通过 make_experiment 训练模型的基本步骤:
- 准备数据集(pandas 或 dask DataFrame)
- 通过工具 make_experiment 创建实验
- 执行实验 .run() 方法进行训练得到模型
- 利用模型进行数据预测或Python工具 pickle 存储模型
1. 准备数据集
可以根据实际业务情况通过pandas或dask加载数据,得到用于模型训练的DataFrame。
以sklearn内置数据集 breast_cancer 为例,可通过如下处理得到数据集:
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
X,y = datasets.load_breast_cancer(as_frame=True,return_X_y=True)
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.7,random_state=335)
train_data = pd.concat([X_train,y_train],axis=1)
其中 train_data 用于模型训练(包括目标列),X_test 和 y_test 用于模型评价。
2. 创建实验并进行训练
假设希望最终模型有比较好的precision,为前面准备的训练数据集创建实验并开始训练模型如下:
from hypergbm import make_experiment
experiment = make_experiment(train_data, target='target', reward_metric='precision')
estimator = experiment.run()
其中 estimator 就是训练所得到的模型。
3. 保存模型
推荐利用 pickle 存储HyperGBM模型,如下:
import pickle
with open('model.pkl','wb') as f:
pickle.dump(estimator, f)
4. 评价模型
可利用sklearn提供的工具进行模型评价,如下:
from sklearn.metrics import classification_report
y_pred=estimator.predict(X_test)
print(classification_report(y_test, y_pred, digits=5))
out[]:
precision recall f1-score support
0 0.96429 0.93103 0.94737 58
1 0.96522 0.98230 0.97368 113
accuracy 0.96491 171
macro avg 0.96475 0.95667 0.96053 171
weighted avg 0.96490 0.96491 0.96476 171
四、HyperGBM基础应用
HyperGBM的基础特性主要包含以下方面,具体请参看HyperGBM基础应用
- 以缺省配置创建并运行实验
- 设置最大搜索次数(max_trials)
- 交叉验证
- 指定验证数据集(eval_data)
- 指定模型的评价指标
- 设置搜索次数和早停(Early Stopping)策略
- 指定搜索算法(Searcher)
- 模型融合
- 调整日志级别
五、HyperGBM高级应用
HyperGBM的make_experiment 所创建的是 Hypernets 的 CompeteExeriment 实例,CompeteExeriment 具备很多建模的高级特性。具体请参考HyperGBM高级应用
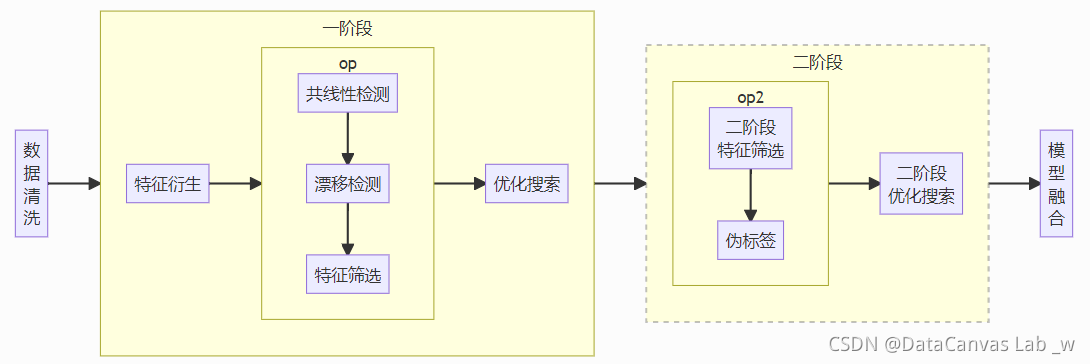
主要支持的高级特性如下:
- 数据清洗
- 特征衍生
- 共线性检测
- 漂移检测
- 特征筛选
- 降采样预搜索
- 二阶段特征筛选
- 伪标签
六、HyperGBM处理样本不均衡问题
样本不均衡也是业务建模过程中的一个重要挑战,样本不均衡往往会导致建模效果不理想。HyperGBM 在建模时支持两种类型的不平衡数据处理方式。
1. 利用ClassWeight建模
在利用底层建模算法(如lightgbm等)建模时,首先计算样本分布比例,然后利用底层算法对模型进行优化。
为了利用ClassWeight建模,在调用make_experiment时,设置参数class_balancing=‘ClassWeight’即可,示例如下:
from hypergbm import make_experiment
train_data = ...
experiment = make_experiment(train_data,
class_balancing='ClassWeight',
...)
2. 欠采样或过采样
在建模之前,通过欠采样或过采样技术调整样本数据,然后再利用调整后的数据进行建模,以得到表现较好的模型。目前支持的采样策略包括:RandomOverSampler ,SMOTE, ADASYN, RandomUnderSampler, NearMiss, TomekLinks, EditedNearestNeighbours。
为了利用欠采样或过采样技建模,在调用make_experiment时,设置参数class_balancing=‘<采用策略>’即可,示例如下:
from hypergbm import make_experiment
train_data = ...
experiment = make_experiment(train_data,
class_balancing='SMOTE',
...)
关于欠采样或过采样技术的更多信息,请参考 imbalanced-learn
七、HyperGBM自定义搜索空间
除了框架默认的搜索空间外,也支持用户自定义搜索空间,用户可以简单的设置某些参数为先验值,小范围自定义某些参数的搜索空间,大范围自定义搜索空间等,具体实现细节请参考HyperGBM自定义搜索空间
八、HyperGBM自定义建模算法
除了框架本身支持的lightgbm, xgboost, catboost,HistGradientBoosting算法外,得益于hypernets的高拓展性,我们可以很简单的自定义其他的搜索算法到HyperGBM框架中,具体实现细节请参考HyperGBM自定义建模算法