目标网址: https://www.ypppt.com/
目录
1、页面结构分析
第①步:解析模板列表
第②步:进入到模板详情页,点击下载
第③步:进入模板下载页,点击下载
2、网站反爬措施
3、编码程序代码
4、程序测试结果
1、页面结构分析
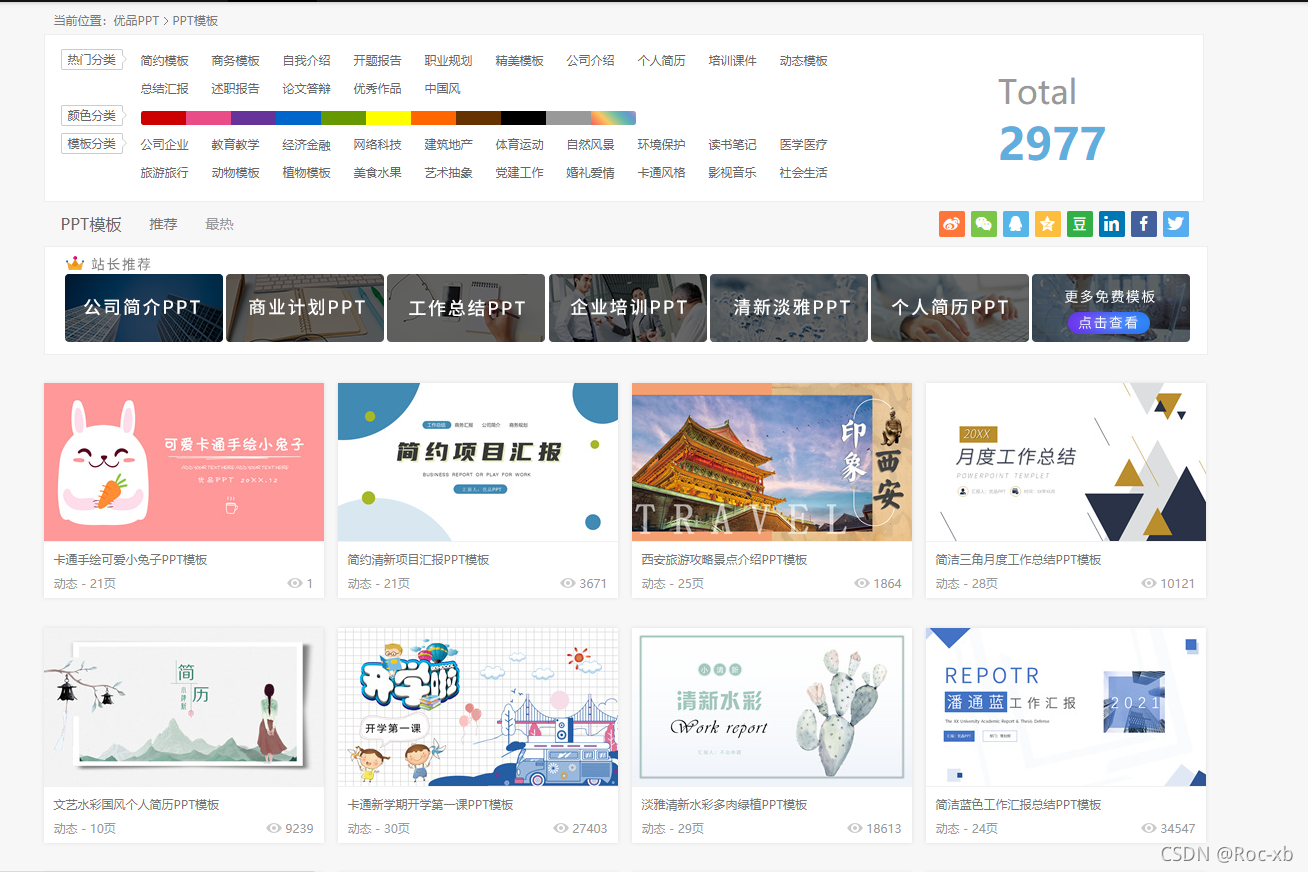
通过页面,我们可以确定我们采集的步骤。
第①步:解析模板列表

第②步:进入到模板详情页,点击下载

第③步:进入模板下载页,点击下载
2、网站反爬措施
经过测试,遇到该网站主要的反爬措施有以下几种情况。
①字符编码反爬,网站使用的字符编码是ISO-8859-1,对响应进行转码即可避免
②Cookie反爬,Cookie会不定时失效,有时候可用性很短,有时候可用性又很长。失效的时候更新一下Cookie即可,如果失效,响应状态码为503
3、编码程序代码
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@author: Roc-xb
"""
import os
import requests
from lxml import etree
headers = {
'authority': 'www.ypppt.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'upgrade-insecure-requests': '1',
'dnt': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'referer': 'https://www.ypppt.com/moban/jiaoyu/list-2.html',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': '__yjs_duid=1_6a0e3e92bfb2bf6fc44bcebab809fa271631401047877; yjs_js_security_passport=fbdf2cbff3fdc4ffbed9f5e215f2cfe87c0b9f33_1631401050_js',
}
# 获取模板列表
def get_moban_list(page_url, page=1):
print(f"正在下载第{page}页".center(100, "*"))
requests_url = page_url
if page > 1:
requests_url = page_url + f"list-{page}.html"
res = requests.get(requests_url, headers=headers)
res.encoding = res.apparent_encoding
dom = etree.HTML(res.text)
ul = dom.xpath("/html/body/div[2]/ul/li")
for li in ul:
url = "https://www.ypppt.com" + li.xpath('./a//@href')[0]
get_moban_download_page(url)
# 判断是否有下一页
next_page = dom.xpath('//div[@class="page-navi"]//text()')
if "下一页" in next_page:
get_moban_list(page_url, page + 1)
# 进入模板详情页
def get_moban_download_page(url):
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
dom = etree.HTML(res.text)
try:
download_url = dom.xpath('/html/body/div[2]/div[1]/div/div[1]/div[2]/a//@href')[0]
except Exception:
download_url = dom.xpath('/html/body/div[2]/div[2]/div/div[1]/div[2]/a//@href')[0]
url = "https://www.ypppt.com" + download_url
print("模板下载页面:", url)
get_moban_download_url(url)
# 进入模板下载页
def get_moban_download_url(url):
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
dom = etree.HTML(res.text)
download_url = dom.xpath('/html/body/div[1]/div/ul/li[1]/a//@href')[0]
print("模板下载地址:", download_url)
downlaod_file(download_url)
# 下载文件
def downlaod_file(url):
r = requests.get(url, headers=headers)
file_dir = os.getcwd() + '\\个人简历\\'
if not os.path.exists(file_dir):
os.makedirs(file_dir)
print("目录创建成功")
file_name = file_dir + str(url).split("/")[-1]
with open(file_name, 'wb') as f:
f.write(r.content)
print("文件下载成功:", file_name)
print("".center(100, "*"))
if __name__ == '__main__':
get_moban_list('https://www.ypppt.com/moban/jianli/')
4、程序测试结果
