前言
马上临近中秋了,月饼的销量持续增长,也推出了各个不同口味类别的月饼,价格差异也较大。我们究竟应该买哪种月饼呢?今天就一起用Python爬取某宝月饼信息,并对爬取的数据进行可视化分析,一起来看看哪种月饼最受欢迎,哪家店铺月饼销量最高吧~
直接跳到文末获取粉丝专属福利。
一、核心功能设计
总体来说,我们需要先从网站爬虫获取月饼数据,并将这些数据进行清洗,最后可视化分析展示。拆解需求,大致可以整理出我们需要分为以下几步完成:
- 通过爬虫获取月饼数据,主要包括月饼名称、销量、店铺、省份城市等。
- 对获取的数据进行预处理清洗,统一销量数据单位、省份城市等,获取清洗后的各个月饼数量。
- 对清洗的数据进行可视化展示,主要包括热销月饼口味TOP10、热销月饼店铺Top10、月饼价格区间分布、各省份城市月饼销量分布情况等。
二、实现步骤
1. 爬取数据
本文我们通过selenium模块进行月饼数据爬取。为了保证数据爬取顺利,首先我们需要安装selenium模块,通过pip指令即可安装。
pip install selenium
如果第一次安装使用selenium,不少人有可能会出现以下异常,那该怎么解决呢?

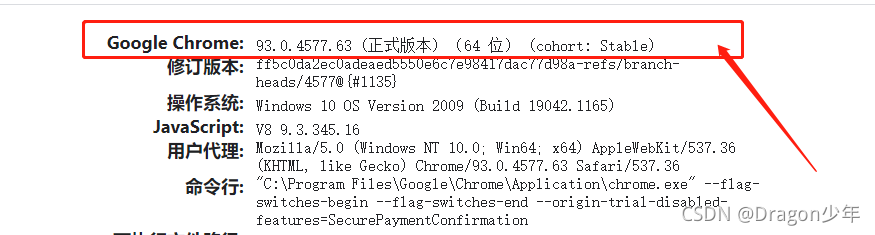
出现的主要原因是因为selenium模拟的客户端对浏览器的操作,但相应浏览器的驱动版本不匹配导致的。所以我们需要先了解我们当前浏览器的版本,可以打开浏览器,地址栏输入chrome://version/查看到谷歌当前的版本号。
这样我们就可以到谷歌浏览器驱动找到对应版本下载驱动就可以了。下载解压之后,可以看到chromedriver.exe。
我们需要把它拷贝到Python路径下面,至此我们就可以正常使用selenium模拟客户端浏览器操作了。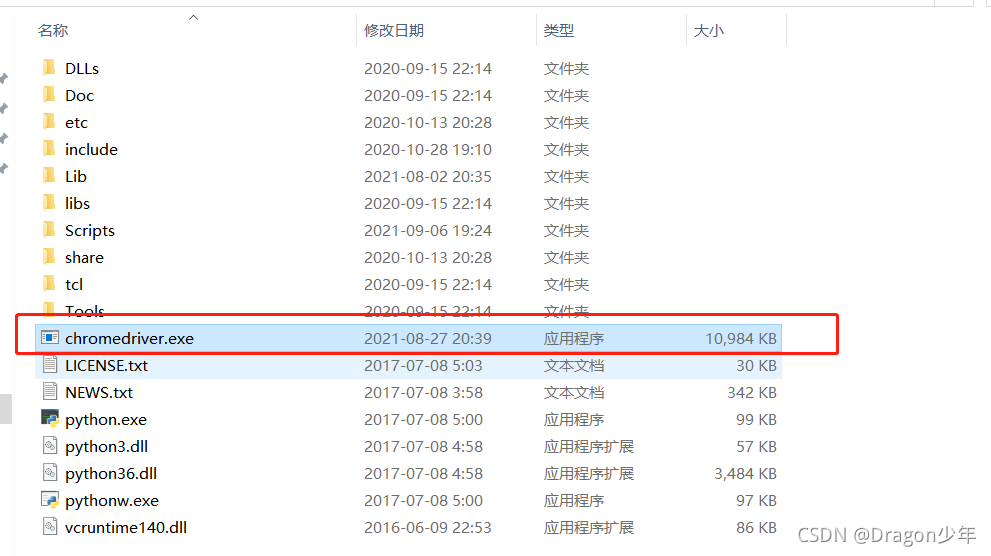
接下来我们进行网页分析,获取对应的月饼名称、店铺名、销售量、价格、地区。根据对数据分析,可以发现:
- 各个月饼信息都在item的class=“item J_MouserOnverReq”
- 月饼名称对应的class=“row row-2 title”
- 价格对应的strong标签
- 付款人数对应class=“deal-cnt”
- 店铺信息在class="shop"中
- 发货地区对应class=“location”
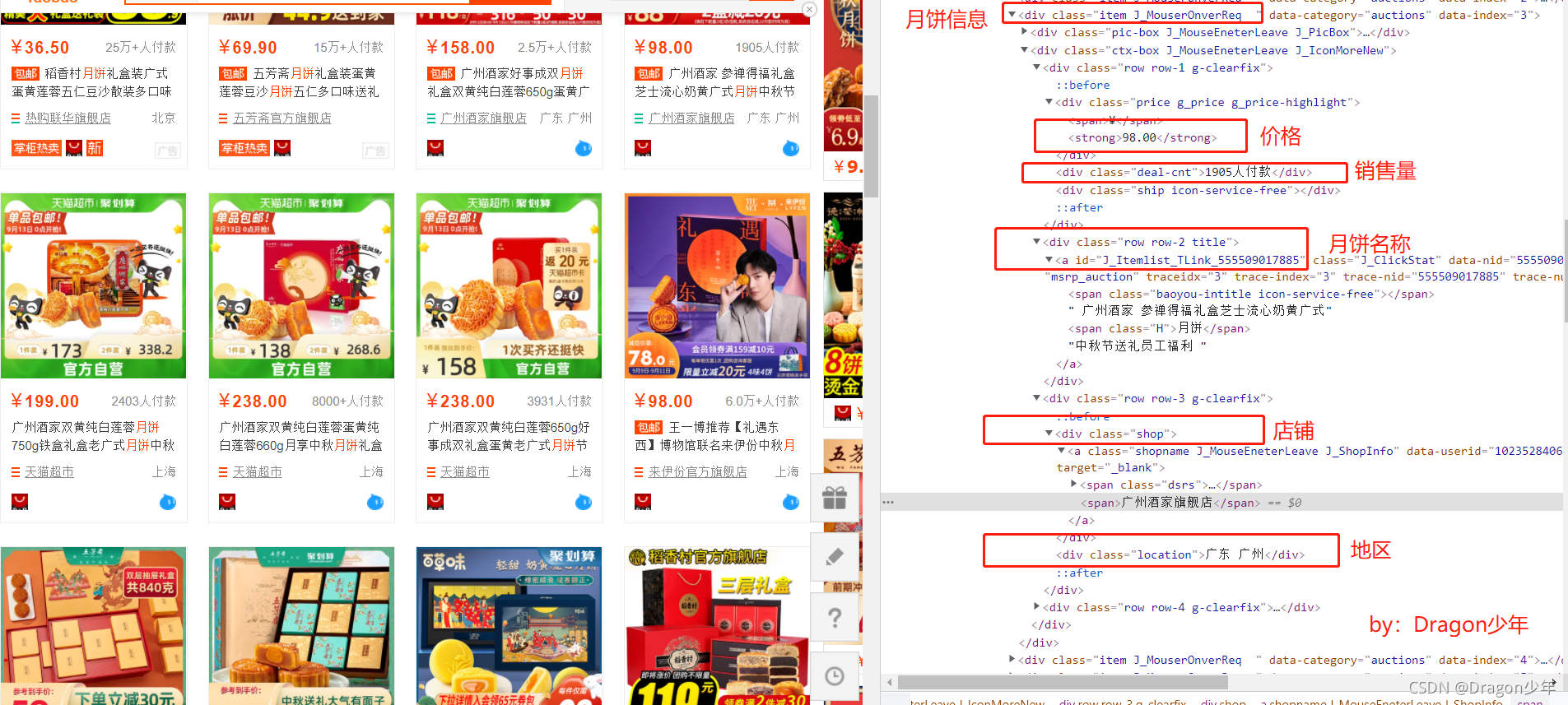
网页结构我们上面已经分析好了,那么我们就可以来动手爬取我们所需要的数据了,获取到所有的数据资源之后,可以把这些数据保存下来。
获取商品:
# author:Dragon少年
# 获取商品
def get_product(key_word):
# 定位输入框
browser.find_element_by_id("q").send_keys(key_word)
# 定义点击按钮,并点击
browser.find_element_by_class_name('btn-search').click()
browser.maximize_window()
# 等待20秒,方便手动登录
time.sleep(20)
# 定位这个“页码”,获取“共100页这个文本”
page_info = browser.find_element_by_xpath('//div[@class="total"]').text
# findall()返回的是一个列表
page = re.findall("(\d+)", page_info)[0]
return page
获取数据:
# author:Dragon少年
# 获取数据
def get_data():
# 所有的信息都在items节点下
items = browser.find_elements_by_xpath('//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for item in items:
pro_desc = item.find_element_by_xpath('.//div[@class="row row-2 title"]/a').text
# 价格
pro_price = item.find_element_by_xpath('.//strong').text
# 付款人数
buy_num = item.find_element_by_xpath('.//div[@class="deal-cnt"]').text
# 店铺
shop = item.find_element_by_xpath('.//div[@class="shop"]/a').text
# 发货地
address = item.find_element_by_xpath('.//div[@class="location"]').text
with open('{}.csv'.format(key_word), mode='a', newline='', encoding='utf-8-sig') as f:
csv_writer = csv.writer(f, delimiter=',')
csv_writer.writerow([pro_desc, pro_price, buy_num, shop, address])
selenium模拟爬取:
# author:Dragon少年
key_word = input("请输入您要搜索的商品:")
browser = webdriver.Chrome()
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
browser.get('https://www.taobao.com/')
page = get_product(key_word)
print(page)
get_data()
page_num = 1
while int(page) != page_num:
print("=" * 100)
print("正在爬取第{}页".format(page_num + 1))
browser.get('https://s.taobao.com/search?q={}&s={}'.format(key_word, page_num * 44))
browser.implicitly_wait(15)
get_data()
page_num += 1
print("爬取结束!")
至此我们就可以爬取月饼的数据并保存下来,如下图所示。
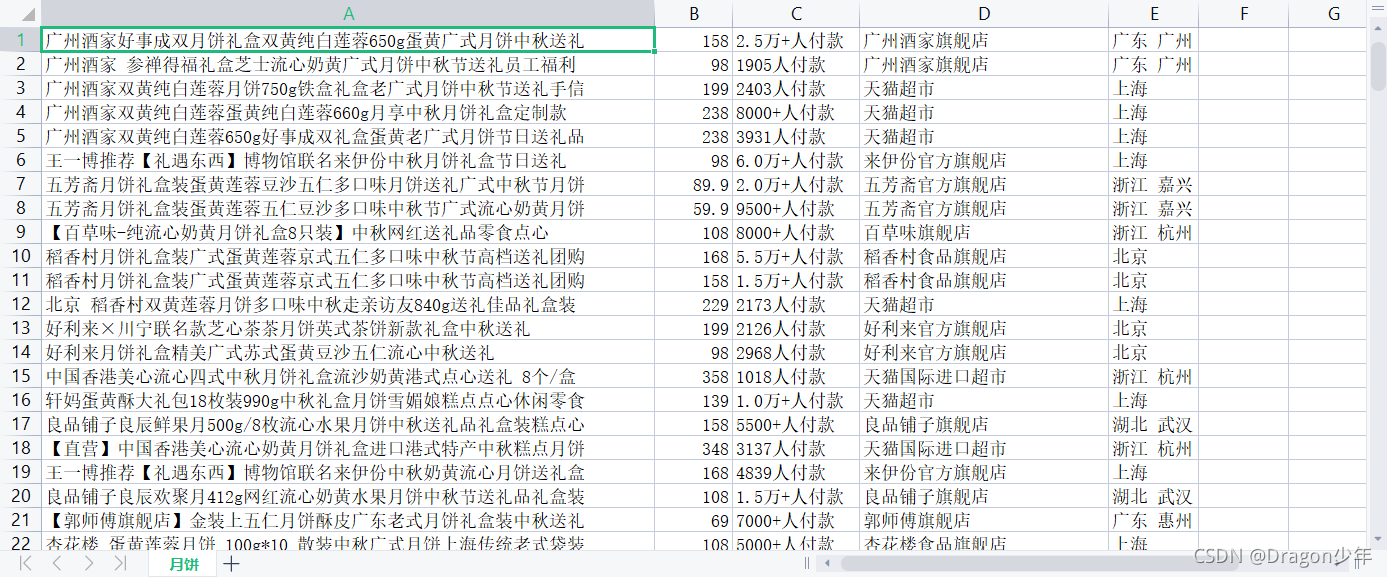
2. 数据清洗
接下来我们需要把爬虫获取的数据进行清洗,首先可以去除重复数据,删除没有人购买的记录。核心代码如下:
# author:Dragon少年
# 读取爬虫数据
df = pd.read_csv("月饼.csv", encoding='utf-8-sig', header=None)
df.columns = ["商品名", "价格", "购买人数", "店铺", "地址"]
# 去除重复的数据
df.drop_duplicates(inplace=True)
print(df.shape)
# 删除购买人数0的记录
df['购买人数'] = df['购买人数'].replace(np.nan,'0人付款')
对于购买人数,有些是按照万为单位显示,我们需要将销售量进行统一,并将发货地区进行整理出各个省份信息,最后将这些清洗的数据保存下来。核心代码如下:
df['num'] = [re.findall(r'(\d+\.{0,1}\d*)', i)[0] for i in df['购买人数']] # 提取数值
df['num'] = df['num'].astype('float') # 转化数值型
# 提取单位(万)
df['unit'] = [''.join(re.findall(r'(万)', i)) for i in df['购买人数']] # 提取单位(万)
df['unit'] = df['unit'].apply(lambda x:10000 if x=='万' else 1)
# 计算销量
df['销量'] = df['num'] * df['unit']
# 删除没有发货地址的店铺数据 获取省份
df = df[df['地址'].notna()]
df['省份'] = df['地址'].str.split(' ').apply(lambda x:x[0])
# 删除多余的列
df.drop(['购买人数', '地址', 'num', 'unit'], axis=1, inplace=True)
# 重置索引
df = df.reset_index(drop=True)
df.to_csv('月饼清洗数据.csv')
至此我们就可以把爬取的月饼数据整理清洗完毕,如下图所示。
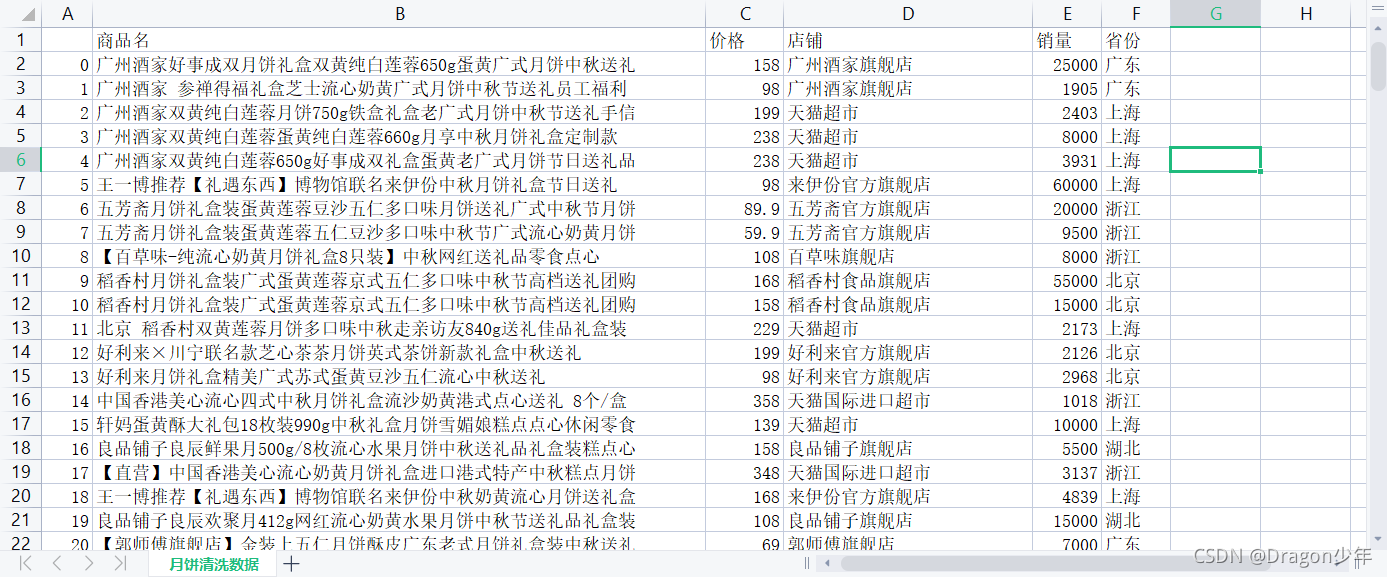
3. 可视化分析
接下来我们就需要对数据进行可视化显示, 这里使用的是pyecharts,是一个用于生成Echarts图表的类库,便于在Python中根据数据生成可视化的图表。
之前博主有写过一篇关于pyecharts的文章,里面很详细的介绍了各类图表的使用方法和案例,不会的可以先去学习下pyecharts相关的内容。【一文学会炫酷图表利器pyecharts】
销量Top10店铺:
下面我们可以读取清洗结束的数据,通过对店铺分组获取各个店铺的月饼销量数据,统计出销量前十的店铺,通过柱状图显示。核心代码如下:
# 计算月饼总销量Top10的店铺
shop_top10 = df.groupby('店铺')['销量'].sum().sort_values(ascending=False).head(10)
# 绘制柱形图
bar1 = Bar(init_opts=opts.InitOpts(width='600px', height='450px'))
bar1.add_xaxis(shop_top10.index.tolist())
bar1.add_yaxis('销量', shop_top10.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='销量Top10店铺-Dragon少年'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)))
bar1.render("销量Top10店铺-Dragon少年.html")
bar1.render_notebook()
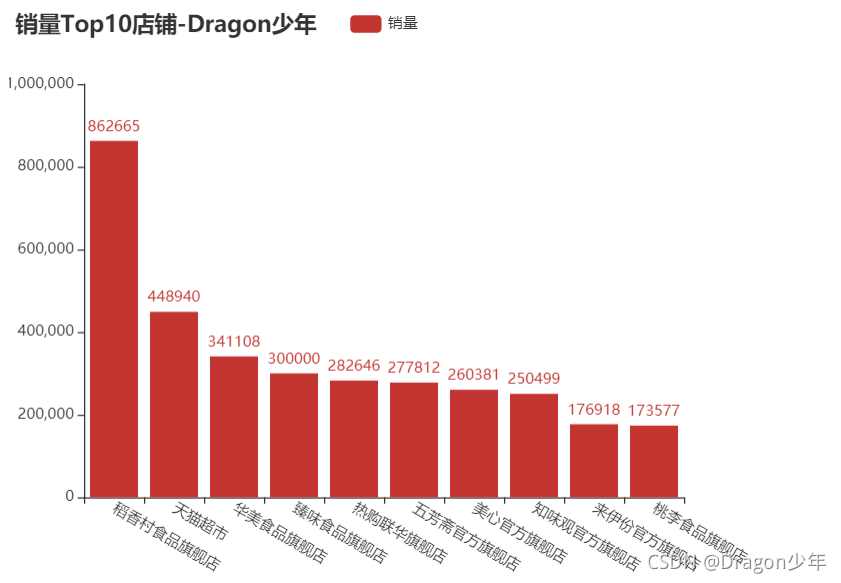
我们可以看到稻香村食品店、天猫超市、华美食品、臻味食品等销量居前,其中销量最好的是稻香村,总销量遥遥领先。
销量Top10月饼:
我们还可以通过对月饼名称进行月饼分组获取销量最好的月饼,统计出销量前十的月饼,通过柱状图显示。核心代码如下:
# 计算销量top10月饼
shop_top10 = df.groupby('商品名')['销量'].sum().sort_values(ascending=False).head(10)
# 绘制柱形图
bar0 = Bar(init_opts=opts.InitOpts(width='750px', height='450px'))
bar0.add_xaxis(shop_top10.index.tolist())
bar0.add_yaxis('销量', shop_top10.values.tolist())
bar0.set_global_opts(title_opts=opts.TitleOpts(title='销量Top10月饼-Dragon少年'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)))
bar0.render("销量Top10月饼-Dragon少年.html")
bar0.render_notebook()
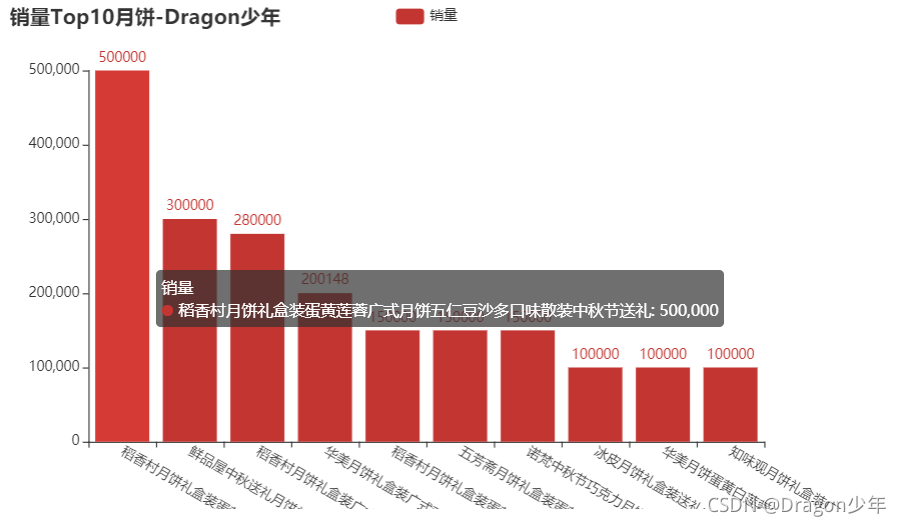
我们可以看到最受欢迎的10种月饼,其中的稻香村月饼礼盒装最受欢迎,销量达到了50w份。
不同价格月饼销量占比:
我们接下来还可以根据月饼的价格区间进行划分,统计50元以下,50-150元,150-500元,500元以上的各个价格区间月饼的销量分布,并通过饼图进行可视化显示。核心代码如下:
def price_range(x): #按照淘宝推荐划分价格区间
if x <= 50:
return '50元以下'
elif x <= 150:
return '50-150元'
elif x <= 500:
return '150-500元'
else:
return '500元以上'
df['price_range'] = df['价格'].apply(lambda x: price_range(x))
price_cut_num = df.groupby('price_range')['销量'].sum()
data_pair = [list(z) for z in zip(price_cut_num.index, price_cut_num.values)]
# 饼图
pie1 = Pie(init_opts=opts.InitOpts(width='750px', height='350px'))
# 内置富文本
pie1.add(
series_name="销量",
radius=["35%", "55%"],
data_pair=data_pair,
label_opts=opts.LabelOpts(formatter='{b}—占比{d}%'),
)
pie1.set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", pos_top='30%', orient="vertical"),
title_opts=opts.TitleOpts(title='不同价格月饼销量占比-Dragon少年'))
pie1.render("不同价格月饼销量占比-Dragon少年.html")
pie1.render_notebook()
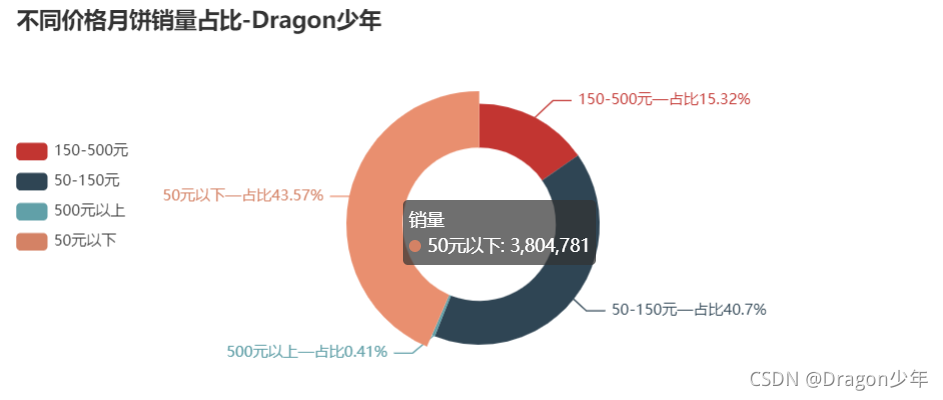
可以看出来,月饼的销售价格主要分布在≤150元之间,占据了销量的84%左右,单份月饼价格超过500元的购买的人较少。
各省月饼销量分布:
最好我们在统计下,月饼的产地销量分布省份地区,并通过地图可视化显示。核心代码如下:
# 计算销量
province_num = df.groupby('省份')['销量'].sum().sort_values(ascending=False)
# 绘制地图
map1 = Map(init_opts=opts.InitOpts(width='750px', height='350px'))
map1.add("", [list(z) for z in zip(province_num.index.tolist(), province_num.values.tolist())],
maptype='china'
)
map1.set_global_opts(title_opts=opts.TitleOpts(title='各省月饼销量分布-Dragon少年'),
visualmap_opts=opts.VisualMapOpts(max_=300000)
)
map1.render("各省月饼销量分布-Dragon少年.html")
map1.render_notebook()
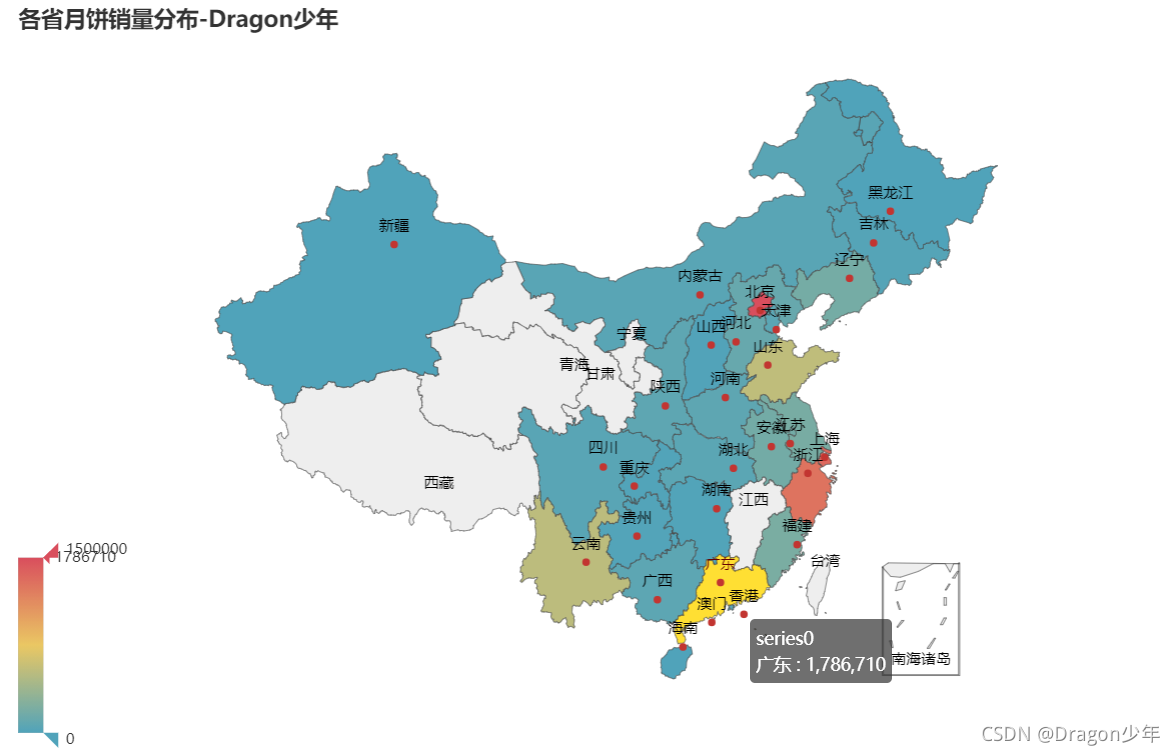
可以看到月饼的销售地分布最多的是广东和浙江省,这两个省月饼销量最受欢迎。至此,月饼数据爬虫及分析可视化就完成啦~ 大家看完分析想好买什么月饼了吗?
源码及数据已上传,关注文末公众号回复【月饼源码】即可获取完整源码
Python往期精彩:
见过仙女蹦迪吗?一起用python做个小仙女代码蹦迪视频
python自制一款炫酷音乐播放器,想听啥随便搜!
斗地主老是输?一起用Python做个AI出牌器,豆子蹭蹭涨!
桌面太单调?一起用Python做个自定义动画挂件,好玩又有趣!
一起用Python做个车牌自动识别系统,好玩又实用!
桌面太单调?一起用Python做个自定义动态壁纸,竟然还可以放视频!
一起用Python做个自动化弹钢琴脚本,我竟然弹出了《天空之城》!
往期精彩源码均可通过下方公众号获取