❤️思维导图整理大厂面试高频数组: 两万字详解各种数组求和(建议收藏)❤️_孤柒的博客
此专栏文章是对力扣上算法题目各种方法的总结和归纳, 整理出最重要的思路和知识重点并以思维导图形式呈现, 当然也会加上我对导图的详解.
目的是为了更方便快捷的记忆和回忆算法重点(不用每次都重复看题解), 毕竟算法不是做了一遍就能完全记住的. 所以本文适合已经知道解题思路和方法, 想进一步加强理解和记忆的朋友, 并不适合第一次接触此题的朋友(可以根据题号先去力扣看看官方题解, 然后再看本文内容).
关于本专栏所有题目的目录链接, 刷算法题目的顺序/注意点/技巧, 以及思维导图源文件问题请点击此链接.
想进大厂, 刷算法是必不可少的, 欢迎和博主一起打卡刷力扣算法, 博主同步更新了算法视频讲解 和 其他文章/导图讲解, 更易于理解, 欢迎来看!
文章目录
- 一.你还在用暴力法解 两数之和 吗? 力扣1详细注解
- 0.导图整理
- 1.暴力法
- 2.两遍哈希表
- 3.一遍哈希表
- 4.哈希表中的循环和异议
- 5.java和Python中哈希表的差别
- 源码
- Python:
- java:
- 二.两数之和II有序数组, 多个有序, 思路全变, 力扣167详细注解
- 0.导图整理
- 1.两数之和中有序和无序的区别
- 2.二分法和寻找插入位置的区别
- 3.双指针思想
- 源码
- Python:
- java:
- 三.三数之和 相比于 两数之和 的难点, 力扣15详细注解
- 0.导图整理
- 1.对于不重复三元组的处理
- 2.双指针的思想
- 3.元素为整型链表的数组链表: ArrayList
一.你还在用暴力法解 两数之和 吗? 力扣1详细注解
题目链接: https://leetcode-cn.com/problems/two-sum/
0.导图整理
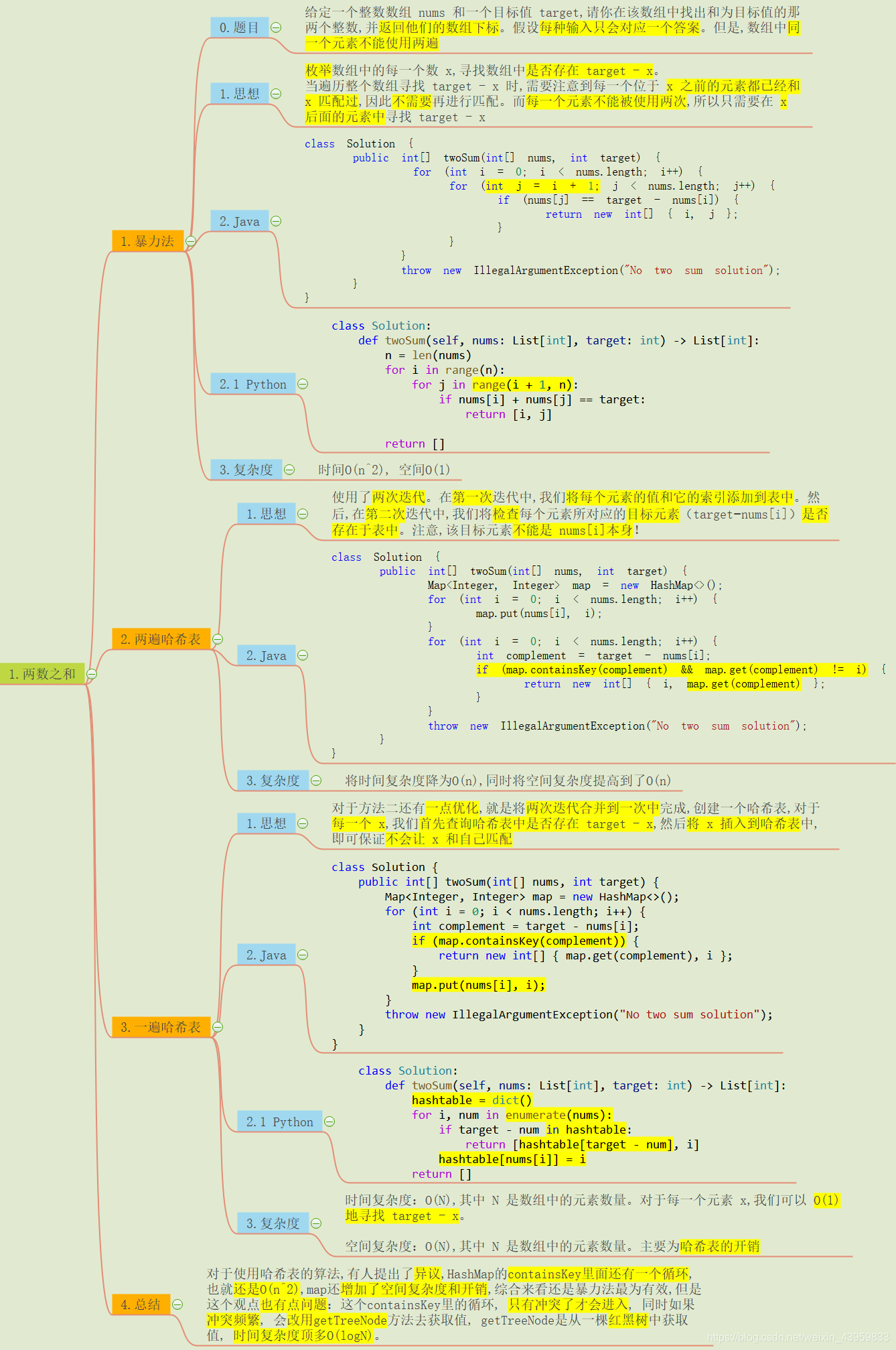
1.暴力法
暴力法的思想很简单, 就是两层循环: 一层用来遍历所有元素, 另一层用来寻找目标数.
但此题中的注意点是题目中的: 假设每种输入只会对应一个答案. 但是, 数组中同一个元素不能使用两遍.
每种输入只对应一个输出 也就是要求我们找到满足的元素直接返回就可以了, 并不需要再去找其他满足的元素, 这也为下面使用哈希表的方法提供了前提, 因为如果需要找到所有满足的元素, 那么哈希表的结构就不能满足要求了.
数组中同一个元素不能使用两遍 这个要求就是代码中标注重点的部分 j = i + 1; 的含义. 当遍历整个数组寻找 target - x 时, 需要注意到每一个位于 x 之前的元素都已经和 x 匹配过, 因此不需要再进行匹配. 而每一个元素不能被使用两次, x本身也不需要进行匹配, 所以只需要在 x 后面的元素中寻找 target - x, 也就是从i+1开始遍历.
2.两遍哈希表
暴力法使用了两层循环, 时间复杂度达到了O(n^2), 而使用哈希表就可以将寻找目标数的操作降为O(1), 直接降了一个量级, 具体过程如下:
使用了两次迭代。在第一次迭代中, 将每个元素的值和它的索引添加到表中。然后, 在第二次迭代中, 检查每个元素所对应的目标元素(target−nums[i])是否存在于表中。注意, 该目标元素不能是 nums[i]本身!也就是 map.get(complement) != i 的含义.
3.一遍哈希表
对于上面方法还有一点优化, 就是将两次迭代合并到一次中完成, 先进行匹配, 再插入到哈希表中!
首先创建一个哈希表, 对于每一个 x, 首先查询哈希表中是否存在 target - x, 如果存在直接返回结果就可以了. 之后将 x 插入到哈希表中, 即可保证不会让 x 和自己匹配, 因为在匹配时, x还未插入到哈希表中.
这种优化对于时间复杂度没有太大影响, 但是代码看起来更简洁了.
4.哈希表中的循环和异议
对于使用哈希表的算法, 有人提出了异议, HashMap的containsKey里面还有一个循环, 也就还是O(n^2), map还增加了空间复杂度和开销, 综合来看还是暴力法最为有效, 但是这个观点也有点问题: 这个containsKey里的循环, 只有冲突了才会进入, 同时如果冲突频繁, 会改用getTreeNode方法去获取值, getTreeNode是从一棵红黑树中获取值, 时间复杂度顶多O(logN), 综合来看, 还是降低了时间复杂度.
5.java和Python中哈希表的差别
从上述代码可以看出, 两者对于哈希表的实现还是有很大的差别的.
首先java中的哈希表是用Map类实现的, 判断是否包含一个元素用的是 map.containsKey(Key) 函数, 获取 键 对应的 值 使用的是 map.get(Key) 函数, 插入到哈希表中使用的是 map.put(Key, Value)
但是在Python中直接使用它自带的数据类型 字典dict 就实现了哈希表的操作, 并不需要新建类, 而且相应的操作也非常简单, 几乎不需要通过其他函数来实现. 判断是否包含一个元素用的是 in, 获取 键 对应的 值 使用的是 hashtable[Key] 函数, 插入到哈希表中使用的是 hashtable[Key] = Value
仔细对比会发现, Python语法是真的简洁明了, 这也是博主喜欢Python的原因.
这里补充说明一下Python中的 enumerate(nums) 函数, 简单来说就是对nums数组中的所有数添加了下标, 它返回的是 由下标和数据构成的二元元组, 在Python的for循环中还是挺经常使用的函数.
源码
Python:
# 暴力法
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
n = len(nums)
for i in range(n):
for j in range(i + 1, n):
if nums[i] + nums[j] == target:
return [i, j]
return []
# 一遍哈希表
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
hashtable = dict()
for i, num in enumerate(nums):
if target - num in hashtable:
return [hashtable[target - num], i]
hashtable[nums[i]] = i
return []
java:
// 暴力法
class Solution {
public int[] twoSum(int[] nums, int target) {
for (int i = 0; i < nums.length; i++) {
for (int j = i + 1; j < nums.length; j++) {
if (nums[j] == target - nums[i]) {
return new int[] { i, j };
}
}
}
throw new IllegalArgumentException("No two sum solution");
}
}
//两遍哈希表
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
map.put(nums[i], i);
}
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i];
if (map.containsKey(complement) && map.get(complement) != i) {
return new int[] { i, map.get(complement) };
}
}
throw new IllegalArgumentException("No two sum solution");
}
}
//一遍哈希表
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i];
if (map.containsKey(complement)) {
return new int[] { map.get(complement), i };
}
map.put(nums[i], i);
}
throw new IllegalArgumentException("No two sum solution");
}
}
二.两数之和II有序数组, 多个有序, 思路全变, 力扣167详细注解
题目链接: https://leetcode-cn.com/problems/two-sum-ii-input-array-is-sorted/
0.导图整理
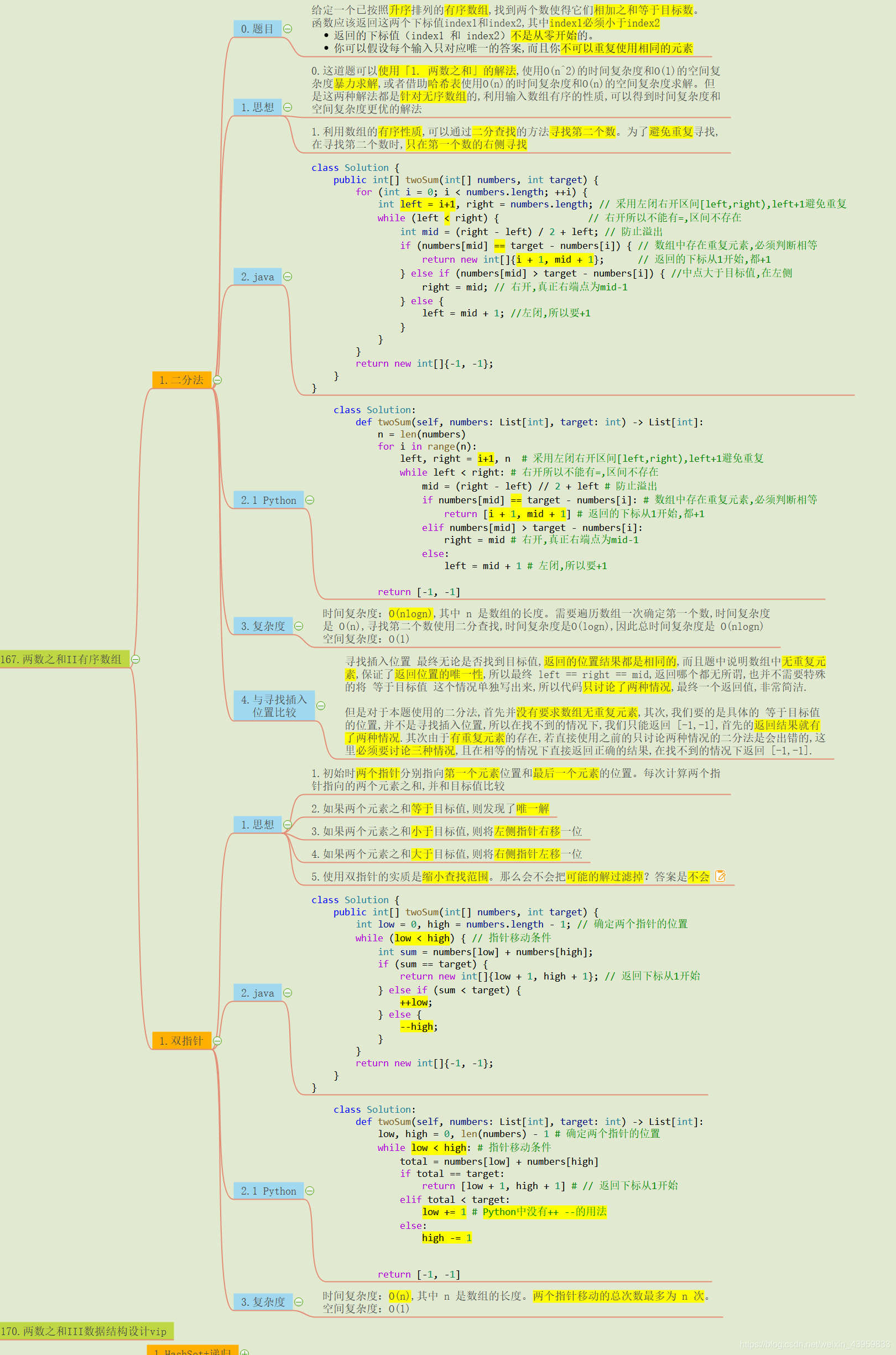
1.两数之和中有序和无序的区别
之前写了一篇关于无序数组的两数之和问题, 在无序数组中寻找第二个数就没有多少捷径, 毕竟数组无序, 很多经典的方法都用不上, 最后只能牺牲空间来换取时间, 利用哈希表将空间复杂度增加到了O(n), 从而降低了寻找第二个数的时间复杂度.
但是当数组有序之后, 就能使用一些经典的算法同时仍然保证空间复杂度为O(1), 不需要牺牲空间来换取时间, 比如下面马上介绍的 二分法 和 双指针 方法.
这里给我们提供了一种思维, 那我们是不是也可以将无序数组先进行排序后, 再使用这些经典算法呢? 当然可以这么做, 但对于两数之和来说, 必要性不是太大. 因为最快的排序算法也需要O(nlogn)的时间复杂度, 对于两数之和确实提升也不是太大, 但是对于 三数之和/四数之和 还是挺实用的, 后续文章将很快讲到.
2.二分法和寻找插入位置的区别
数组有序了, 使用二分法寻找第二个数就可以将时间复杂度降到O(logn)了, 关于二分法, 之前的这篇文章已经讲解的很清楚了, 这里就不再重复介绍了.
这里说说 二分法 和 寻找插入位置的不同, 也是两篇文章中代码不同的部分.
寻找插入位置 最终无论是否找到目标值, 返回的位置结果都是相同的, 而且题中说明数组中无重复元素, 保证了返回位置的唯一性, 所以最终 left == right == mid, 返回哪个都无所谓, 也并不需要特殊的将 等于目标值 这个情况单独写出来, 所以代码只讨论了两种情况, 最终一个返回值, 非常简洁.
但是对于本题使用的二分法, 首先并没有要求数组无重复元素, 其次, 我们要的是具体的 等于目标值 的位置, 并不是寻找插入位置, 所以在找不到的情况下, 我们只能返回 [-1, -1], 首先的返回结果就有了两种情况.
其次由于有重复元素的存在, 若直接使用之前的只讨论两种情况的二分法是会出错的, 这里必须要讨论三种情况, 且在相等的情况下直接返回正确的结果, 在找不到的情况下返回 [-1, -1].
本题另外的一个小的注意点是: 返回的下标从1开始, 只要在原本的返回结果上+1就可以了.
还有一个注意点是, 为了避免重复寻找,在寻找第二个数时,只在第一个数的右侧寻找, 也就是left = i+1.
3.双指针思想
双指针在有序数组中是非常重要的思想, 一定要掌握. 思想还是挺简单的, 但是优化的效果是非常棒的, 比二分法更加优秀. 导图中对思想的描述挺清楚了, 这里说下它的适用范围吧.
最基本最首要的前提是 数组一定要是有序的, 其次, 一定要涉及到几个数之间的相互关系, 最常用的也就是几个数相加等于某一定值的情况, 其他情况, 今后遇到了再细说. 常用于数组和链表之中.
源码
Python:
# 二分法
class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
n = len(numbers)
for i in range(n):
left, right = i+1, n # 采用左闭右开区间[left,right),left+1避免重复
while left < right: # 右开所以不能有=,区间不存在
mid = (right - left) // 2 + left # 防止溢出
if numbers[mid] == target - numbers[i]: # 数组中存在重复元素,必须判断相等
return [i + 1, mid + 1] # 返回的下标从1开始,都+1
elif numbers[mid] > target - numbers[i]:
right = mid # 右开,真正右端点为mid-1
else:
left = mid + 1 # 左闭,所以要+1
return [-1, -1]
# 双指针
class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
low, high = 0, len(numbers) - 1 # 确定两个指针的位置
while low < high: # 指针移动条件
total = numbers[low] + numbers[high]
if total == target:
return [low + 1, high + 1] # // 返回下标从1开始
elif total < target:
low += 1 # Python中没有++ --的用法
else:
high -= 1
return [-1, -1]
java:
// 二分法
class Solution {
public int[] twoSum(int[] numbers, int target) {
for (int i = 0; i < numbers.length; ++i) {
int left = i+1, right = numbers.length; // 采用左闭右开区间[left,right),left+1避免重复
while (left < right) { // 右开所以不能有=,区间不存在
int mid = (right - left) / 2 + left; // 防止溢出
if (numbers[mid] == target - numbers[i]) { // 数组中存在重复元素,必须判断相等
return new int[]{i + 1, mid + 1}; // 返回的下标从1开始,都+1
} else if (numbers[mid] > target - numbers[i]) { //中点大于目标值,在左侧
right = mid; // 右开,真正右端点为mid-1
} else {
left = mid + 1; //左闭,所以要+1
}
}
}
return new int[]{-1, -1};
}
}
// 双指针
class Solution {
public int[] twoSum(int[] numbers, int target) {
int low = 0, high = numbers.length - 1; // 确定两个指针的位置
while (low < high) { // 指针移动条件
int sum = numbers[low] + numbers[high];
if (sum == target) {
return new int[]{low + 1, high + 1}; // 返回下标从1开始
} else if (sum < target) {
++low;
} else {
--high;
}
}
return new int[]{-1, -1};
}
}
三.三数之和 相比于 两数之和 的难点, 力扣15详细注解
题目链接: https://leetcode-cn.com/problems/3sum/
0.导图整理

1.对于不重复三元组的处理
本题最大的难点在于题目要求的 不重复的三元组, 三数之和 不像 两数之和 那样简单, 它的可重复情况是非常多的, 无法像 两数之和 那样, 只要将第一个元素放入哈希表中, 就可以轻松解决元素重复的问题了.
对于三数之和, 即使使用哈希表去重, 它的操作也是比较困难的. 所以我们不能简单地使用三重循环枚举所有的三元组, 然后使用哈希表进行去重操作, 这样的工作量比较大.
因此我们必须换一种方法来解决此题, 从源头上解决元素重复的问题. 如果给定的数组是有序的, 那么其中可重复的情况就是完全可以控制的了, 处理起来也是很简单的. 所以我们首先将数组中的元素从小到大进行排序, 随后使用普通的三重循环就可以满足上面的要求.
我们会发现其中重复的元组都是相邻的元组, 只需要保证在每一重循环时, 相邻两次枚举的元素不是相同的元素, 这样就可以避免元组重复的情况了. 也就是导图中每层循环时的 if判断语句.
2.双指针的思想
使用普通的三层循环确实也能解决问题, 但是O(n^3)的时间复杂度也确实太高了, 这时我们想到了在 有序数组的两数之和 中使用的双指针的方式(双指针在此文已说明清楚, 这里就不重复讲解了), 虽然现在是三数之和, 但当我们正常遍历了第一层循环之后, 剩下的两个数不就形成了 有序数组的两数之和 了吗? 所以我们只要 保持第二重循环不变, 而将第三重循环变成一个从数组最右端开始向左移动的指针, 同时加上上述讨论的避免重复的条件, 最终代码就完成了.
时间复杂度也从O(n^3) 降到了 O(n^2), 至于空间复杂度, 有两种情况: 如果允许我们改变原来的数组, 那么只需要排序算法额外的空间复杂度O(logN), 如果不允许的话, 那就要使用了一个额外的数组存储了nums的副本并进行排序,空间复杂度为 O(N).
3.元素为整型链表的数组链表: ArrayList<List>()
这里补充说明下这个数据结构, 对于新手来说, 看着还是挺吓人的呢! 我们从外到里依次来拆分这个结构. 首先最外面 ArrayList() 表明它的本质是一个数组链表, 无论里面的元素是什么类型, 它最本质的结构都不会发生变化的. 再来看它里面所装的结构是 List, 就是说这个数组链表中的每一个元素都是一个链表List, 长度可以是任意的长度, 但是这个链表List中的元素的类型必须是整型Integer. 这里的<>用到了java中的 泛型 的概念, 简单来说就是一个写一个通用的模板, 里面所包含元素的类型可以是任意的, 具体使用时对其指定具体的类型即可. 对于较复杂的数据类型, 一般都是采用这种由外到内的分析方法.
对应本题来说下具体的应用: ans.add(Arrays.asList(nums[first],nums[second],nums[third])), 首先ans这个数组链表使用.add函数添加了一个链表, 而这个链表是通过 3个整型数据 由Arrays.asList()这个方法转换成的链表, 这样就成功添加了一个链表. 之后每次循环, 只要有满足条件的三元组都会添加一个链表, 最终所有满足条件的三元组链表形成了最终结果的数组链表ans.
对于java和C++这种强类型的语言, 使用时要明确指明所用到的数据类型, 但对于Python这种弱类型的语言来说, 用起来就非常简单了, 你只需要创建了链表list(), 不需要指明任何类型, 使用时直接添加某种特定类型的数据即可. 而且每次添加的数据会自动保存为一个链表的形式添加到链表中, 不需要显式地自己将其转化为链表, 用起来还是很简单的.
源码
Python:
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]: # 元素为整型链表的数组链表
n = len(nums)
nums.sort() # 将数组进行排序
ans = list()
# 枚举 a
for first in range(n):
# 需要和上一次枚举的数不相同
if first > 0 and nums[first] == nums[first - 1]:
continue
# c 对应的指针初始指向数组的最右端
third = n - 1
target = -nums[first]
# 枚举 b
for second in range(first + 1, n):
# 需要和上一次枚举的数不相同
if second > first + 1 and nums[second] == nums[second - 1]:
continue
# 需要保证 b 的指针在 c 的指针的左侧
while second < third and nums[second] + nums[third] > target:
third -= 1
if second == third: # 如果指针重合,后续也不会满足条件,可以退出循环
break
if nums[second] + nums[third] == target:
ans.append([nums[first], nums[second], nums[third]])
return ans
java:
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
int n = nums.length;
Arrays.sort(nums); //将数组进行排序
List<List<Integer>> ans = new ArrayList<List<Integer>>(); //元素为整型链表的数组链表
// 枚举 a
for (int first = 0; first < n; ++first) {
// 需要和上一次枚举的数不相同
if (first > 0 && nums[first] == nums[first - 1]) {
continue;
}
// c 对应的指针初始指向数组的最右端
int third = n - 1;
int target = -nums[first];
// 枚举 b
for (int second = first + 1; second < n; ++second) {
// 需要和上一次枚举的数不相同
if (second > first + 1 && nums[second] == nums[second - 1]) {
continue;
}
// 需要保证 b 的指针在 c 的指针的左侧
while (second < third && nums[second] + nums[third] > target) {
--third;
}
if (second == third) { // 如果指针重合,后续也不会满足条件,可以退出循环
break;
}
if (nums[second] + nums[third] == target) {
ans.add(Arrays.asList(nums[first],nums[second],nums[third]));
}
}
}
return ans;
}
}
四.四数之和 相比 三数之和 的大量优化, 力扣18详细注解
题目链接: https://leetcode-cn.com/problems/4sum/
0.导图整理

1.思想同三数之和: 排序+双指针
四数之和 本质上和 三数之和 是一样的, 由于都有大量重复元素的存在, 都不能使用哈希表进行简单的去重, 都需要先进行排序后才方便遍历处理, 同时为了优化时间复杂度, 再加上双指针方法的使用, 如果只是想简单实现的话, 那么在 三数之和 上直接多加一重循环, 修改一下细节, 本题就可以实现了, 但是上述代码的不同点在于: 并非只是简单的加了一重循环而已, 而是进行了大量的优化处理.
2.在三数之和基础上进行了大量的优化
因为 四数之和 相比较于 三数之和 来说, 情况更加复杂, 时间复杂度也更高, 而且这个时间复杂度通过算法是很难降下来的, 我们只能通过对代码进行优化, 直接减少大量不必要的遍历情况, 从而来缩短代码的运行时间.
对于代码的优化主要分为两大块: 一部分是为了避免出现重复的四元组, 在遍历上面的优化, 这部分内容和 三数之和 中是相似的处理, 只不过更加复杂.
首先是对前两重循环进行的去重操作, 当 i 或者 j 的值与前面的值相等时忽略, 之后又对 双指针 进行了去重操作, 这里有个重要的注意点: 一定注意代码中是 先进行了指针的移动还是先进行了去重的比较, 对于不同的顺序, 比较的元素是完全不同的. 如果先进行了指针的移动, 对于左指针来说, 需要比较的元素就是 当前元素和前面的一个元素, 如果是先进行去重的比较, 那比较的元素就是 当前元素和后面的一个元素, 再进行指针的移动. 对于右指针的情况正好是完全相反的.
第二部分就是在循环遍历中先通过计算特定的四个数之和, 以此来判断接下来的循环操作情况.
比如 在确定第一个数 nums[i] 之后, 如果nums[i]+nums[i+1]+nums[i+2]+nums[i+3]>target, 也就是此时的最小的4个数之和都大于target, 说明此时剩下的三个数无论取什么值, 四数之和一定大于 target, 因此直接退出第一重循环就可以了, 使用 break 关键字.
在确定第一个数 nums[i] 之后,如果nums[i]+nums[n−3]+nums[n−2]+nums[n−1]<target, 也就是此时的最大的4个数之和都小于target, 说明此时剩下的三个数无论取什么值, 四数之和一定小于 target,因此第一重循环直接进入下一轮, 枚举nums[i+1], 使用 continue 关键字.
对于第二层循环也是同样的判断方法, 通过这两层循环的判断优化, 能直接删去大量的不满足情况, 减少代码运行的时间. 这也能给我们带来启发, 在算法层面不能进行优化的时候, 可以选择对代码的细节进行优化, 同样可以起到节省时间的效果.
源码
Python:
class Solution:
def fourSum(self, nums: List[int], target: int) -> List[List[int]]:
quadruplets = list() # 定义一个返回值
if not nums or len(nums) < 4:
return quadruplets
nums.sort()
length = len(nums)
# 定义4个指针i,j,left,right i从0开始遍历,j从i+1开始遍历,留下left和right作为双指针
for i in range(length - 3):
if i > 0 and nums[i] == nums[i - 1]: # 当i的值与前面的值相等时忽略
continue
# 获取当前最小值,如果最小值比目标值大,说明后面越来越大的值根本没戏
if nums[i] + nums[i + 1] + nums[i + 2] + nums[i + 3] > target:
break # 这里使用的break,直接退出此次循环,因为后面的数只会更大
# 获取当前最大值,如果最大值比目标值小,说明后面越来越小的值根本没戏,忽略
if nums[i] + nums[length - 3] + nums[length - 2] + nums[length - 1] < target:
continue # 这里使用continue,继续下一次循环,因为下一次循环有更大的数
# 第二层循环j,初始值指向i+1
for j in range(i + 1, length - 2):
if j > i + 1 and nums[j] == nums[j - 1]: # 当j的值与前面的值相等时忽略
continue
if nums[i] + nums[j] + nums[j + 1] + nums[j + 2] > target:
break
if nums[i] + nums[j] + nums[length - 2] + nums[length - 1] < target:
continue
left, right = j + 1, length - 1
# 双指针遍历,如果等于目标值,left++并去重,right--并去重,当当前和大于目标值时right--,当当前和小于目标值时left++
while left < right:
total = nums[i] + nums[j] + nums[left] + nums[right]
if total == target:
quadruplets.append([nums[i], nums[j], nums[left], nums[right]])
left += 1 # left先+1之后,和它前面的left-1进行比较,若后+1,则和它后面的left+1进行比较
while left < right and nums[left] == nums[left - 1]:
left += 1
right -= 1
while left < right and nums[right] == nums[right + 1]:
right -= 1
elif total < target:
left += 1
else:
right -= 1
return quadruplets
java:
class Solution {
public List<List<Integer>> fourSum(int[] nums, int target) {
List<List<Integer>> quadruplets = new ArrayList<List<Integer>>(); // 定义一个返回值
if (nums == null || nums.length < 4) {
return quadruplets;
}
Arrays.sort(nums);
int length = nums.length;
// 定义4个指针i,j,left,right i从0开始遍历,j从i+1开始遍历,留下left和right作为双指针
for (int i = 0; i < length - 3; i++) {
if (i > 0 && nums[i] == nums[i - 1]) { // 当i的值与前面的值相等时忽略
continue;
}
// 获取当前最小值,如果最小值比目标值大,说明后面越来越大的值根本没戏
if (nums[i] + nums[i + 1] + nums[i + 2] + nums[i + 3] > target) {
break; // 这里使用的break,直接退出此次循环,因为后面的数只会更大
}
// 获取当前最大值,如果最大值比目标值小,说明后面越来越小的值根本没戏,忽略
if (nums[i] + nums[length - 3] + nums[length - 2] + nums[length - 1] < target) {
continue; // 这里使用continue,继续下一次循环,因为下一次循环有更大的数
}
// 第二层循环j,初始值指向i+1
for (int j = i + 1; j < length - 2; j++) {
if (j > i + 1 && nums[j] == nums[j - 1]) { // 当j的值与前面的值相等时忽略
continue;
}
if (nums[i] + nums[j] + nums[j + 1] + nums[j + 2] > target) {
break;
}
if (nums[i] + nums[j] + nums[length - 2] + nums[length - 1] < target) {
continue;
}
int left = j + 1, right = length - 1;
// 双指针遍历,如果等于目标值,left++并去重,right--并去重,当当前和大于目标值时right--,当当前和小于目标值时left++
while (left < right) {
int sum = nums[i] + nums[j] + nums[left] + nums[right];
if (sum == target) {
quadruplets.add(Arrays.asList(nums[i], nums[j], nums[left], nums[right]));
left++; // left先+1之后,和它前面的left-1进行比较,若后+1,则和它后面的left+1进行比较
while (left < right && nums[left] == nums[left - 1]) {
left++;
}
right--;
while (left < right && nums[right] == nums[right + 1]) {
right--;
}
} else if (sum < target) {
left++;
} else {
right--;
}
}
}
}
return quadruplets;
}
}
五.四数组的四数之和II,详解Counter类实现哈希表计数,力扣454
题目链接: https://leetcode-cn.com/problems/4sum-ii/
0.导图整理

1.维数太高, 分治处理
此题乍一看似乎和 四数之和 差不多, 但是本质上却有着很大的区别, 首先无论是 三数之和 还是 四数之和, 它们都是在一个数组上的操作, 本质上都是一维的, 同时它们都要求找到 不重复 的元组, 这就限制了我们不能简单的使用哈希表进行去重操作, 最终只能将数组排序后使用双指针的方法.
但是本题是 四个独立的数组, 相当于是 四个维度, 想在四个维度上使用双指针的方法显然是不现实的. 同时此题只要求我们找到所有4个元素的和为0的元组个数即可, 并没有要求是不重复的元组, 这样就简单了很多, 也是可以使用哈希表的方法的.
此题在使用哈希表的时候, 会遇到如下的三种情况:
1.HashMap存一个数组,如A。然后计算三个数组之和,如BCD。时间复杂度为:O(n)+O(n^3),得到O(n^3).
2.HashMap存三个数组之和,如ABC。然后计算一个数组,如D。时间复杂度为:O(n^3)+O(n),得到O(n^3).
3.HashMap存两个数组之和,如AB。然后计算两个数组之和,如CD。时间复杂度为:O(n^2)+O(n^2),得到O(n^2).
根据时间复杂度来看, 我们肯定选择第三种情况.
确定了使用的方法(哈希表)以及分类的方法(两两分组), 接下来就是代码的书写了. 此题和 两数之和 中使用的哈希表有着很大的区别, 在两数之和中, 我们需要的是满足条件的下标值, 所以在哈希表中的值存取的就是元组的下标值, 这点是很容易实现的. 但是在此题中我们需要的是所有满足元素的个数, 所以哈希表中的值应存取出现的次数. 这相对于只存下标是有点难度的. 这就涉及到下文要讲的几个方法和类了.
2.Java中map的merge和getOrDefault方法
统计出现的次数, 在java中可以使用map类中的两个方法进行实现.
一种是countAB.put(u + v, countAB.getOrDefault(u + v, 0) + 1), 这里比较重要的是getOrDefault(u + v, 0)方法, 它的含义是获得键u + v对应的值, 也就是出现的次数, 如果当然哈希表中未出现, 则返回默认值0. 通过后面的+1操作, 实现在现有次数上+1或者初始化次数为1, 然后将这个键值对放入到哈希表中.
另一种方法是countAB.merge(u+v, 1, (old,new_)->old+1), 这里使用了merge方法, 从名字就可以看出是 合并 的意思, 也就是将新出现的键值对和原来已有的键值对进行合并, 形成新的键值对. 中间的1表示如果原来没有此键值对, 那么这个新键值对的值就是1(出现次数为1次). 最后的参数表示了新的值的相对于旧的值的变化情况, 这里就是+1的操作. 有一点要主要的是new_有个下划线, 因为在java中new是创建对象的关键词, 这里是为了区别开来. 这个函数的语法就是上文所示那样, 具体的操作情况都可以根据实际来更改.
3.Python中的Counter类
在Python中哈希表是利用dict()字典来实现的, 但毕竟不是专为哈希表设计的类, 也没有那么丰富的方法来使用. 但是Python中直接设计了能够对哈希对象进行计数的类, 并且在功能上更加优秀, 下面我们重点介绍一下这个类.
3.1 简介
1.一个 Counter 是一个 dict 的子类, 用于计数可哈希对象。它是一个集合, 元素像字典键(key)一样存储, 它们的计数存储为值。计数可以是任何整数值, 包括0和负数.
2.通常字典方法都可用于 Counter 对象,除了有两个方法工作方式与字典并不相同
fromkeys(iterable)这个类方法没有在 Counter 中实现
update([iterable-or-mapping]是在原有的键值对上加上,而不是替换
sum(c.values()) # total of all counts
c.clear() # reset all counts
list(c) # list unique elements
set(c) # convert to a set
dict(c) # convert to a regular dictionary
c.items() # convert to a list of (elem, cnt) pairs
Counter(dict(list_of_pairs)) # convert from a list of (elem, cnt) pairs
c.most_common()[:-n-1:-1] # n least common elements
+c # remove zero and negative counts
3.2 初始化
元素从一个 iterable 被计数或从其他的 mapping (or counter)初始化
c = Counter() # a new, empty counter
c = Counter('gallahad') # a new counter from an iterable
c = Counter({'red': 4, 'blue': 2}) # a new counter from a mapping
c = Counter(cats=4, dogs=8) # a new counter from keyword args
3.3 空的处理
Counter对象有一个字典接口,如果引用的键没有任何记录,就返回一个0,而不是弹出一个KeyError
c = Counter(['eggs', 'ham'])
c['bacon'] # count of a missing element is zero
0
3.4 删除元素
设置一个计数为0不会从计数器中移去一个元素。使用 del 来删除它
c['sausage'] = 0 # counter entry with a zero count
del c['sausage'] # del actually removes the entry
3.5 elements()方法
返回一个迭代器, 其中每个元素将重复出现计数值所指定次。元素会按首次出现的顺序返回。如果一个元素的计数值小于1, elements()将会忽略它
c = Counter(a=4, b=2, c=0, d=-2)
sorted(c.elements())
['a', 'a', 'a', 'a', 'b', 'b']
3.6 most_common([n])方法
返回一个列表, 其中包含 n 个最常见的元素及出现次数, 按常见程度由高到低排序。 如果 n 被省略或为 None, most_common()将返回计数器中的所有元素。计数值相等的元素按首次出现的顺序排序
Counter('abracadabra').most_common(3)
[('a', 5), ('b', 2), ('r', 2)]
3.7 subtract([iterable-or-mapping])方法
从 迭代对象 或 映射对象 减去元素。像dict.update()但是是减去, 而不是替换。输入和输出都可以是0或者负数
c = Counter(a=4, b=2, c=0, d=-2)
d = Counter(a=1, b=2, c=3, d=4)
c.subtract(d)
c
Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})
3.8 数学操作
提供了几个数学操作, 可以结合 Counter 对象, 以生产multisets (计数器中大于0的元素)。
加和减, 结合计数器, 通过加上或者减去元素的相应计数。
交集和并集返回相应计数的最小或最大值。
每种操作都可以接受带符号的计数, 但是输出会忽略掉结果为零或者小于零的计数
sum(c.values()) # total of all counts
c.clear() # reset all counts
list(c) # list unique elements
set(c) # convert to a set
dict(c) # convert to a regular dictionary
c.items() # convert to a list of (elem, cnt) pairs
Counter(dict(list_of_pairs)) # convert from a list of (elem, cnt) pairs
c.most_common()[:-n-1:-1] # n least common elements
+c # remove zero and negative counts
3.9 注意点
1.计数器主要是为了表达运行的正的计数而设计;但是, 小心不要预先排除负数或者其他类型
2.Counter 类是一个字典的子类,不限制键和值。值用于表示计数, 但你实际上可以存储任何其他值
3.most_common()方法在值需要排序的时候用
4.原地操作比如 c[key] += 1, 值类型只需要支持加和减。所以分数,小数,和十进制都可以用, 负值也可以支持。这两个方法update()和subtract()的输入和输出也一样支持负数和0
5.Multiset多集合方法只为正值的使用情况设计。输入可以是负数或者0, 但只输出计数为正的值。没有类型限制, 但值类型需要支持加, 减和比较操作
6.elements()方法要求正整数计数。忽略0和负数计数
4.总结
1.看到形如:A+B…+N=0的式子,要转换为(A+…T)=-((T+1)…+N)再计算,这个T的分割点一般是一半,特殊情况下需要自行判断。定T是解题的关键
2.dp一般不会超过二维, 这里都四维了, 维度太高, 需要分治
3.算法中间使用了map的新方法merge和getOrDefault, 相比较于传统的判断写法, 大大提高了效率
源码
Python:
class Solution:
def fourSumCount(self, A: List[int], B: List[int], C: List[int], D: List[int]) -> int:
# Counter类是dict()子类, 用于计数可哈希对象
# 它是一个集合,元素像字典键(key)一样存储,它们的计数存储为值
countAB = collections.Counter(u + v for u in A for v in B)
ans = 0
for u in C:
for v in D:
if -u - v in countAB:
ans += countAB[-u - v]
return ans
java:
class Solution {
public int fourSumCount(int[] A, int[] B, int[] C, int[] D) {
Map<Integer, Integer> countAB = new HashMap<Integer, Integer>();
for (int u : A) {
for (int v : B) {
// 存储u+v的结果,不存在赋值为1,存在在原来基础上+1
// 另一种表达countAB.merge(u+v, 1, (old,new_)->old+1);
countAB.put(u + v, countAB.getOrDefault(u + v, 0) + 1);
}
}
int ans = 0;
for (int u : C) {
for (int v : D) {
if (countAB.containsKey(-u - v)) {
ans += countAB.get(-u - v);
}
}
}
return ans;
}
}
六.总结 n数之和 的各种情况 和 使用方法
前几次的讲解, 我们几乎将数组的各种求和都讲解了一遍, 今天我们来对数组的n数之和做个总结.
1.两种常用的方法
1.1 哈希表
哈希表的方法首先用在了两数之和(无序数组)上, 哈希表的使用最主要的目的就是为了降低时间复杂度, 缩减寻找第二个元素使用的时间(将时间复杂度由O(n)降为O(1)), 其中无序数组是哈希表使用的重要条件, 因为当数组有序后, 我们完全可以直接使用 双指针 的方法来降低时间复杂度, 它的使用比 哈希表 更加方便快捷, 空间复杂度也更低, 所以数组有序之后, 我们应该首选 双指针 的方法.
在使用哈希表的时候, 也有一个很重要的优化点, 就是 遍历两遍哈希表 和 遍历一遍哈希表 的区别. 简单来说就是, 如果我们先将第一个元素放入哈希表中, 然后再寻找第二个元素, 那么我们就需要 遍历两遍哈希表, 如果我们先寻找第二个元素, 之后再将元素放入到哈希表中, 那么就只需要 遍历一遍哈希表. 说起来比较抽象, 大家可以看下面的两种方法的代码, 还不太清楚的话, 可以看上面 两数之和 的文章.

上面是我们第一次使用哈希表的情况, 第二次使用哈希表就到了 四数之和II四数组相加, 首先由于它具有四个独立的数组, 相当于四维空间, 所以我们很难在这么高的空间维度上直接使用 双指针 的方法, 其次它并没有要求 不重复元组 的情况, 这就给了我们使用 哈希表 的可能性, 因为不用担心复杂的去重操作, 但是使用哈希表一般也是两维的空间, 所以我们必须先进行降维操作, 也就是将四个数组进行分组, 由三种结果的时间复杂度来判断, 我们很容易就选择了 两两分组 的情况.

之后对于哈希表的使用, 就是两种不同情况的使用了. 如果需要直接返回相应数组的下标值, 那是很简单的, 我们只需要将 下标值 当做 哈希表的值 即可.(两数之和 中的使用)
如果需要进行计数, 那就有点麻烦了, 在java中我们可以使用map类的 getOrDefault 或者 merge 方法来实现, 在Python中我们可以直接使用 Counter类 实现, 具体过程可以看 四数之和II四数组相加 的文章.
这是目前我们见到的使用哈希表的情况 和 哈希表的两种使用方法, 今后遇到会再加以补充.
1.2 双指针
对于n数之和, 除了哈希表的方法, 最常用的就是 双指针 的方法了, 上文也提到了, 使用双指针最重要的条件就是数组是有序的, 当然这只是针对n数之和的题型, 对于其他题型, 并不需要要求数组是有序, 例如我们马上就会讲到的 移除元素.
在n数之和中使用双指针必要条件就是数组是有序的, 这就需要我们根据实际情况来判断 数组是否需要进行排序. 比如在 两数之和 中, 就算使用暴力法也才 O ( n 2 ) O(n^2) O(n2), 但进行排序最快也需要 O ( n l o n g ) O(nlong) O(nlong)的时间复杂度, 所以对于两数之和来说, 是真的没必要.
但是对于 三数之和 和 四数之和 就很有必要了, 因为它们时间复杂度实在太高了, 最关键的是它们元组的重复情况也比较多, 想利用哈希表进行去重是非常困难的, 最终只能选择将数组排序后使用 双指针 的方法.
2. n数之和方法总结
对于两数之和, 看它是否是有序的, 如果是无序的就使用 哈希表 的方法, 如果是有序的, 就可以使用 双指针 的方法.
对于一个数组上的三数之和/四数之和等, 无论数组是否有序, 都排序后使用 双指针 的方法.
对于多个数组之和的情况, 首先对它们进行分组来实现降维操作, 一般来说都是分为两个相等的小组, 之后再使用 哈希表 的方法.
情况比较多, 大家要根据具体情况判断具体哪个方法更好, 时间/空间复杂度更低, 选择最优秀的算法.

我的更多精彩文章链接, 欢迎查看
各种电脑/软件/生活/音乐/动漫/电影技巧汇总(你肯定能够找到你需要的使用技巧)
力扣算法刷题 根据思维导图整理笔记快速记忆算法重点内容(欢迎和博主一起打卡刷题哦)
计算机专业知识 思维导图整理
最值得收藏的 Python 全部知识点思维导图整理, 附带常用代码/方法/库/数据结构/常见错误/经典思想(持续更新中)
最值得收藏的 C++ 全部知识点思维导图整理(清华大学郑莉版), 东南大学软件工程初试906科目
最值得收藏的 计算机网络 全部知识点思维导图整理(王道考研), 附带经典5层结构中英对照和框架简介
最值得收藏的 算法分析与设计 全部知识点思维导图整理(北大慕课课程)
最值得收藏的 数据结构 全部知识点思维导图整理(王道考研), 附带经典题型整理
最值得收藏的 人工智能导论 全部知识点思维导图整理(王万良慕课课程)
最值得收藏的 数值分析 全部知识点思维导图整理(东北大学慕课课程)
最值得收藏的 数字图像处理 全部知识点思维导图整理(武汉大学慕课课程)
红黑树 一张导图解决红黑树全部插入和删除问题 包含详细操作原理 情况对比
各种常见排序算法的时间/空间复杂度 是否稳定 算法选取的情况 改进 思维导图整理
人工智能课件 算法分析课件 Python课件 数值分析课件 机器学习课件 图像处理课件
考研相关科目 知识点 思维导图整理
考研经验–东南大学软件学院软件工程(这些基础课和专业课的各种坑和复习技巧你应该知道)
东南大学 软件工程 906 数据结构 C++ 历年真题 思维导图整理
东南大学 软件工程 复试3门科目历年真题 思维导图整理
最值得收藏的 考研高等数学 全部知识点思维导图整理(张宇, 汤家凤), 附做题技巧/易错点/知识点整理
最值得收藏的 考研线性代数 全部知识点思维导图整理(张宇, 汤家凤), 附带惯用思维/做题技巧/易错点整理
高等数学 中值定理 一张思维导图解决中值定理所有题型
考研思修 知识点 做题技巧 同类比较 重要会议 1800易错题 思维导图整理
考研近代史 知识点 做题技巧 同类比较 重要会议 1800易错题 思维导图整理
考研马原 知识点 做题技巧 同类比较 重要会议 1800易错题 思维导图整理
考研数学课程笔记 考研英语课程笔记 考研英语单词词根词缀记忆 考研政治课程笔记
Python相关技术 知识点 思维导图整理
Numpy常见用法全部OneNote笔记 全部笔记思维导图整理
Pandas常见用法全部OneNote笔记 全部笔记思维导图整理
Matplotlib常见用法全部OneNote笔记 全部笔记思维导图整理
PyTorch常见用法全部OneNote笔记 全部笔记思维导图整理
Scikit-Learn常见用法全部OneNote笔记 全部笔记思维导图整理
Java相关技术/ssm框架全部笔记
Spring springmvc Mybatis jsp
科技相关 小米手机
小米 红米 历代手机型号大全 发布时间 发布价格
常见手机品牌的各种系列划分及其特点
历代CPU和GPU的性能情况和常见后缀的含义 思维导图整理
登录后可发表评论
点击登录