python爬虫爬取百度图片
- 开发环境
- 涉及的知识点
- os
- time
- urllib.error
- quote
- re
- (.*?)
- re.compile(key)
- 代码实现
开发环境
- 日期:2021.9.11
- 开发环境:python 3.9和pycharm
ps:pycharm今天第一次用,随着将越来越多开发环境集成到vscode上,感觉太复杂了,配置又不太懂,总是有问题,虽然很喜欢vscode的自由度,但不想折腾了,简单的开发环境更重要! - 第三方库:
- requests 2.25.1
- urlibs 1.26.4
涉及的知识点
os
用来实现对文件的操作
第一个函数:检测文件是否存在
第二个函数用来新建文件
os.path.exists(base_dir)
os.mkdir
time
用来延时,防止封 ip
time。sleep(1)#延时1ms
urllib.error
当图片网址失效时,用以实现 异常检测,使程序不中断,继续爬下一个图片,同时输出异常
try:
# 爬取代码
except urllib.error.URLError:
print("下载失败")
quote
URL只允许一部分ASCII字符,其他字符(如汉字)是不符合标准的,此时就要进行编码。
将搜素内容进行编码
keyword = quote("猫", encoding='utf-8')
#最终编码的后的是 %E7%8C%AB (没看错就是这样一串字符)
re
正则表达式
查看百度图片的源码可找到图片的地址
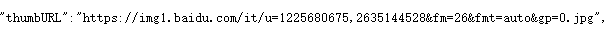
这里相当于去获取https://img1.baidu.com/it/u=1225680675,2635144528&fm=26&fmt=auto&gp=0.jpg
注意见面的 r ,所以’ ‘单引号是字符串 ,而里面的 双引号就是单纯的双引号字符
查找的是括号里面的内容
r'thumbURL":"(.*?)"'
"thumbURL":"https://img1.baidu.com/it/u=1225680675,2635144528&fm=26&fmt=auto&gp=0.jpg"
(.*?)
再讲讲这个
正则表达式中的 .? 或 .+
后边多一个?表示懒惰模式。
必须跟在*或者+后边用
如:
<img src="test.jpg" width="60px" height="80px"/>
如果用正则匹配src中内容非懒惰模式匹配
src=".*"
匹配结果是:
src="test.jpg" width="60px" height="80px"
意思是从 =" 往后匹配,直到最后一个 " 匹配结束
懒惰模式正则:
src=".*?"
结果:src="test.jpg"
匹配到第一个"就结束了一次匹配。不会继续向后匹配。因为他懒惰嘛。
re.compile(key)
预编译,不用每次find的时候去编译
代码实现
首先是import 需要使用的库
import os
import urllib.request
from urllib.parse import quote
import re
import urllib.error
import requests
import time
首先,不想每次都手动复制cookie,所以先进入百度知道界面获取 cookie
get_cookie_headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/92.0.4515.159 Safari/537.36 "}
get_cookie_html = "https://www.baidu.com/?tn=49055317_4_hao_pg"
get_cookie_target = requests.session()
cookie_target = get_cookie_target.get(get_cookie_html, headers=get_cookie_headers)
cookie = requests.utils.dict_from_cookiejar(cookie_target.cookies)
print(cookie)
然后打印出来可以发现,格式是字典,并不是我们想要的格式
于是,我们将其简单处理一下变成我们需要的格式
key = []
value = []
result_cookie = ""
for i in cookie.keys():
key.append(i)
for i in cookie.values():
value.append(i)
for i in range(len(key)):
result_cookie += key[i] + '=' + value[i] + ";"
print(result_cookie)
myheaders = {
"Cookie": result_cookie,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/92.0.4515.159 Safari/537.36 "
}
接下来就是 获取输入关键字 并建立文件夹
pic_dir_name = input("输入想要爬取的主题:")
base_dir = r"C:\Users\dawn\Desktop\百度图片/"
#pic_dir_name = "猫"
pic_dir = base_dir + pic_dir_name
if os.path.exists(base_dir):
if os.path.exists(pic_dir):
print(pic_dir + " 文件已存在")
else:
os.mkdir(pic_dir)
else:
os.mkdir(base_dir)
os.mkdir(pic_dir)
这里去建立 图片的链接 和正则表达式
链接里面的
pn是值图片的开始 值 ,0指第一张
rn指每次服务器给你的图片数量,一次最多60
keyword = quote(pic_dir_name, encoding='utf-8')
start_number = 0
base_url = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&queryWord=" + keyword + "&word=" + keyword + "&pn%d=&rn=60" % start_number
key = r'thumbURL":"(.*?)"'
pic_url = re.compile(key) # 预编译
进行循环,爬取,并保存在文件夹
number = 1
while start_number < 1800:
response = urllib.request.Request(base_url, headers=myheaders)
result = urllib.request.urlopen(response).read().decode("utf-8")
for i in re.findall(pic_url, result):
print(i)
try:
response = urllib.request.Request(i, headers=myheaders)
pic_result = urllib.request.urlopen(response).read()
with open(pic_dir + "/" + pic_dir_name + str(number) + ".jpg", "wb+") as f:
f.write(pic_result)
number += 1
time.sleep(0.5)
except urllib.error.URLError:
print("下载失败")
start_number += 60