作者基于多年的大数据处理经验,当前管理着100PB+数据仓库和2000+节点的集群。持续系统化给大家分享一下关于数据仓库建设的经验总结。本系列既有数据仓库的形而上学理论体系,也有结合公司业务的实践,既有大厂如阿里巴巴,京东,头条的分享交流,也有小公司数仓迭代案例的建设分析。感兴趣的小伙伴可以私信交流。
0.历史系列篇章回顾
先见森林:数据仓库的前世今生与体系框架
1.什么是数仓建模本质?
所谓的数据仓库建模,听着很高大,我们要透过现象看本质。其实本质就是解决如何管理组织企业中数据,并将其用于业务用户的决策制定过程中的方法体系;从企业来说就是数据如何更好地商业智能(BI),从技术角度来说就是如何合理化管理企业数据的存储和计算。
因为对于企业来说,数据规模可能是MB,GB,TB,PB等。不同数据体量数仓的管理模式是不一样,数据规模越大,场景越复杂,管理起来的细节越丰富,需要考虑的问题也就越多,数仓建设管理也就越规范。故对于企业来说,会因为如数据规模,业务场景,成本,决策战略等各种原因选择不同的数据仓库架构与建设方式。所以数据仓库的数据组织建设方法其实有很多种方式,只是主流的,大家通用的就那么几种,更常用的就是Killball的维度建模。这就好比android,ios是移动操作系统的标杆,你可以搞一个其他的出来,但是没人用,影响力有限。

要知道Kimball的数据仓库工具书1996就出版了,维度建模方法思想上个世纪就提出来了。截止到当前,唯一没变的是其数据仓库维度建模的思想,而很多最早Kimball提出来的数仓维度建模的细节已经跟实际脱节了,不过有些概念通过新的技术和实践被逐渐完。企业实际数仓建设过程中都是用其维度建模思想方法体系,具体细节要结合实际去优化,所以如果你看数据仓库工具书这本书时发现其中有很多想法跟实操都不一样,请不要惊讶。
2.数据仓库建模有哪些方法体系?
编程大家都是从基础语法学习,然后不断细节深入,最后技术高阶后都要看一本编程思想的书。其实数仓建设也是这样,要有数仓建设的思想转变。数据仓库建模本质就是组织管理企业数据,为企业数据商业智能服务。条条大路通罗马,所以他的方法体系也不是唯一的。但是要抓住数仓的本质,企业付出成本搜集数据,存储数据目的是为了挖掘数据价值。
所以数据仓库的建设要能给用户以简单可理解的方式建设管理数据,同时给企业提供高效的数据查询性能。一句话不能太复杂,建设不能太麻烦,成本太高,得不偿失。后面大家发现还是用维度建模的方法体系建设数据仓库的性价比最高,简单高效。其他方法体系了解即可,一般面试时候会问下,重点了解其思想体系,以及之间的区别。
其他方法体系介绍参考博客:数据仓库常见建模方法与建模实例演示
3.基于维度建模的数仓架构方案有哪些?
既然说数据仓库的建设,是历史和经验让我们选择了维度建模方法体系。那么什么是维度建模,维度建模实施起来的的架构怎么样?既然维度建模只是一个数据仓库建设的方法体系,是方法体系那么不同的公司实施起来也有不同的架构方案,实施样式。注意区别维度建模和数据仓库架构的关系,维度建模只是数仓架构的环节的一部分应用,数仓架构是维度建模的实施方案。
3.1独立的数据孤岛架构
这种数仓架构最简单。大企业,各个部门子公司每个部门都直接从源数据获取数据ETL,然后创建属于自己部门的独立数据集市。这些数据集市采用维度建模方法,实现简单快速建设,高效查询的功能。但是这种架构不利于企业数据的融合,容易形成数据孤岛,对企业数据的挖掘价值降低,存储计算浪费等。好处就是各搞各的,不用考虑跨组织的数据控制和协调管理。不建议使用,大公司也很少使用了,当然也有公司还在使用,比如国企。
3.2 Killball大佬的数仓架构(主流)

Killball的数仓架构核心是数据隔离。整个后端从ETL开始关注数据质量,数据从不同的源系统获取后,进行统一的数据ETL(转换,清洗),划分维度和事实的同时关注数据的完整性,一致性。最终将数据加载到展示区域里的目标维度模型中。
3.3 Inmon的数仓架构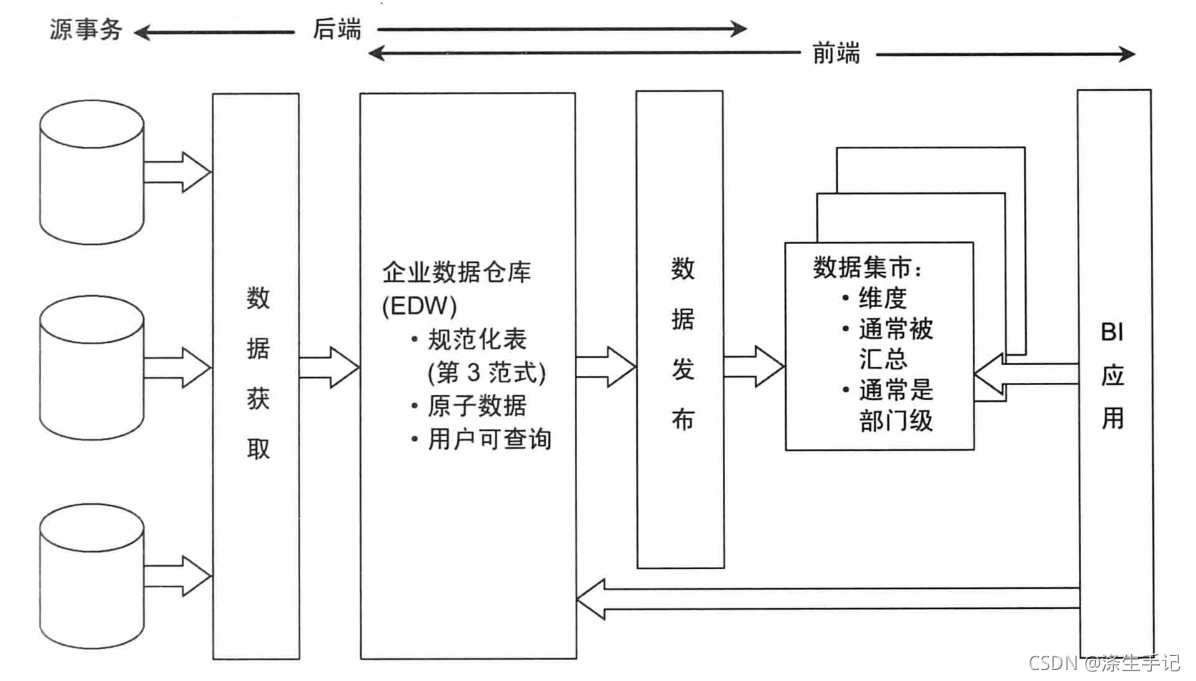
这个Inmon的架构是比较有影响力的,采用CIF模式(Corparate Information factiory企业信息工厂模式),主要和killball区别是规范化ETL数据处理,采用数据库3NF,其次数据架构建设理念也不同,双方都有支持者。
关于具体Killball 和Inmon数仓建设都推荐维度建模,但是两者数据架构建设理念不同,有所区别。小伙伴可以参考这篇博客了解下,没必须纠结过多的细节。而且随着发展,架构的区别也越来越小: 数据仓库 Inmon与Kimball数仓理论对比
4.维度建模概述与步骤
4.1 维度建模是什么?
- 维度建模是数据仓库大师Ralph Kimball提出的,是数据仓库工程领域最流行的数仓建模经典。
- 维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务。因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
- 维度建模是面向分析的,为了提高查询性能可以增加数据冗余,反规范化的设计技术。
- 维度建模是一种抽象出来的企业数据仓库中数据组织与管理的方法体系。直白点说就是组织管理数据仓库中各种业务数据表的,如何基于业务场景,业务过程,业务需求组织创建表,最终提供高效的查询性能。
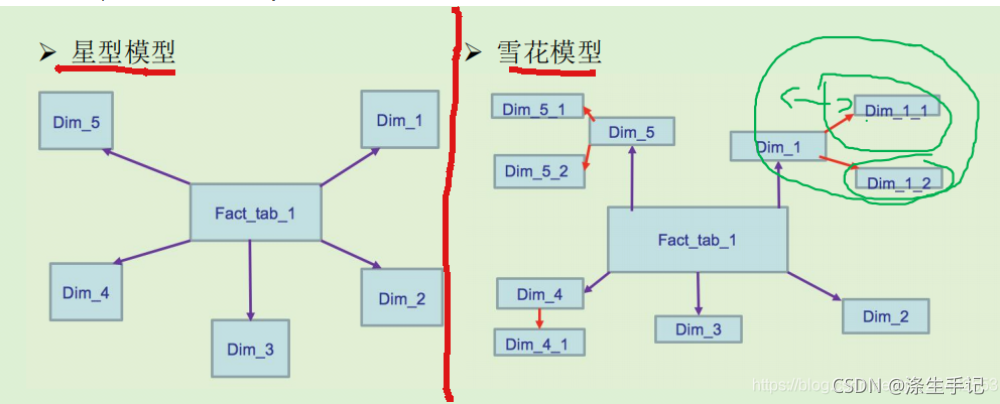
尖叫总结一下:换一种方式来解释什么是维度建模。学过数据库的小伙伴都应该都知道数据库表之间关系:星型模型,一个业务表通过外挂了很多维表,这就是一个典型的维度模型。我们在进行维度建模的时候会建一张事实表,这个事实表就是星型模型的中心,然后会有一堆维度表,这些维度表就是向外发散的星星,而实际开发中维度表也不是那么严格,又可以有自己的维度表,维度表上可以挂维度表,这样就像雪花一样叫雪花模型。
4.2数仓采用维度建模的好处和坏处
4.2.1 数据仓库采用使用维度建模的好处
- 简单易理解、构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,属于业务决策需求性。所以相比数据库的3NF等规范要求的不高,规范也不那么严格。
- 查询的高性能、较好的大规模复杂查询的响应,基于技术框架实现,后面再说。
- 修改的灵活性和可扩充性。维度建模是一个可不断扩充添加的过程。比如1.在现有的事实表中增加维度。2.在事实表中增加事实。3.在维度表中增加属性。
4.2.2 维度建模的“坏处”:
有好处就是弊端,维度建模的坏处体现在,比如对于公共层,一致性维度规划建设,数据模型的建设需要花费很大人天,这样就没有直接把结果搞出来的省事。
4.3 维度建模的步骤
所谓维度建模抽象出来其实就4个步骤,基于这四个步骤组织管理企业的数据,其他所有的展开都是围绕和丰富这四个步骤细节的,以应对不同的业务场景。举个例子,怎么把大象装进冰箱?抽象完就三步,第一打开冰箱门,第二步把大象放进去,第三步关上冰箱门。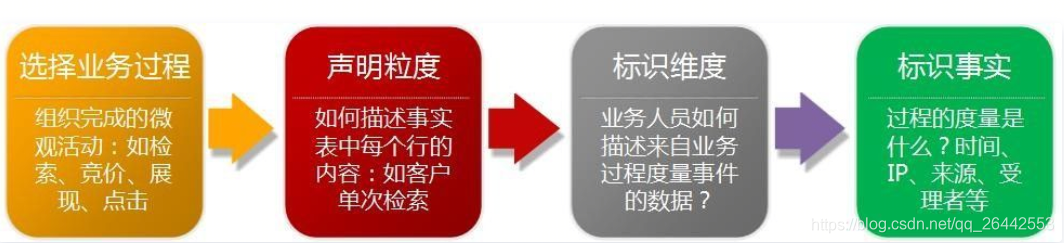
1.维度模式设计主要四个步骤过程:
- 选择业务过程
- 声明粒度
- 确认维度(也有叫标识维度)
- 确认事实(也有叫标识事实)
先这样了解这些概念,胸有成竹,先见森林,再去结合实践,先不要太关注细节。就像盖房子一样,你把沙子,石头,水泥,钢筋摸牌的再熟练,掌握的再熟悉,没有建设过大楼,在应用实践中操作过对你来说还是一堆零散的东西。学习掌握细节的最好的过程就是应用中。
4.3 维度建模里术语与概念
4.3.1 表分为:维度表和事实表
数仓基于维度建模,那么数仓里的表按这种分类只有两种,一种是事实表,一种是维度表。所谓事实表简单理解就是存放业务数据,业务事务过程的表。当然从各种业务源的数据中如何抽象出事实表,哪些字段算是事实而不是维度,事实表有分哪些?所以这些会基于业务场景去详细介绍。
同理维度表也是存放用户分析维度的表。但维度表如何抽象出维度,维度缓慢变化的如何处理,有哪些处理方式?维表的存储分类等等?这些只所以分的那么细,是因为有业务应用场景。后面详细介绍。
4.3.2维度建模数据之间关系
维度建模按数据组织类型划分可分为
- 星型模型
- 雪花模型
- (星座模型),这个非主流认证
后续几乎所有关于数仓维度建模的所以细节都是围绕上面两大模块,表是维度表和事实表。表之间的组织关系则是为星型模型、雪花模型、星座模型