数据仓库理论_努力推石头的西西弗斯
文章目录
- 数据仓库理论
- 1. 前置知识
- 1.1. 联机事务处理 OLTP
- 1.1.1. OLTP的特点
- 1.2. 联机分析处理 OLAP
- 1.2.1. OLAP的特点
- 1.3. 数据库
- 1.4. 数据库设计三范式
- 1.4.1. 第一范式(1NF)
- 1.4.2. 第二范式(2NF)
- 1.4.3. 第三范式(3NF)
- 1.5. ER实体关系模型
- 1.5.1. 实体(Entity)
- 1.5.2. 属性(Attribute)
- 1.5.3. 关系(Relationship)
- 2. 数据仓库
- 2.1. 数据仓库的提出
- 2.2. 数据库vs数据仓库
- 3. 维度建模
- 3.1. 事实表
- 3.2. 维度表
- 3.3. 维度建模模型
- 3.3.1. 星型模型
- 3.3.2. 雪花模型
- 3.3.3. 星座模型
- 4. 数据仓库分层架构
- 4.1. 分层架构的优势
- 4.1.1. 清晰的数据结构
- 4.1.2. 减少重复开发
- 4.1.3. 统一数据出口
- 4.1.4. 简化问题
- 4.2. 分层思想
- 4.2.1. ODS(Operational Data Store)
- 4.2.2. DW(Data Warehouse)
- 4.2.3. DWD(Data Warehouse Detail)
- 4.2.4. DWM(Data Warehouse Middle)
- 4.2.5. DWS(Data Warehouse Service)
- 4.2.6. DM(Data Mart)
当前编辑版本为v0.2(2021.09.10)。
本博客主要参考资料为网上诸多博客,可能存在一定的错误,望指正。
数据仓库理论
数据仓库(Data Warehouse)是面向主题的、数据集成的(非简单的数据堆积)、相对稳定的、反应历史变化的数据集合,数仓中的数据是有组织有结构的存储数据集合,用于对管理决策过程的支持。
1. 前置知识
1.1. 联机事务处理 OLTP
联机事务处理(OLTP,on-line transaction processing) 主要是执行基本日常的事务处理,比如数据库记录的增删查改。比如在银行的一笔交易记录,就是一个典型的事务。
1.1.1. OLTP的特点
- 实时性要求高。我记得之前上大学的时候,银行异地汇款,要隔天才能到账,而现在是分分钟到账的节奏,说明现在银行的实时处理能力大大增强。
- 数据量不是很大,生产库上的数据量一般不会太大,而且会及时做相应的数据处理与转移。
- 交易一般是确定的,比如银行存取款的金额肯定是确定的,所以OLTP是对确定性的数据进行存取
- 高并发,并且要求满足ACID原则。比如两人同时操作一个银行卡账户,比如大型的购物网站秒杀活动时上万的QPS请求。
1.2. 联机分析处理 OLAP
联机分析处理OLAP(On-Line Analytical Processing) 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态的报表系统。
1.2.1. OLAP的特点
- 实时性要求不是很高,比如最常见的应用就是天级更新数据,然后出对应的数据报表。
- 数据量大,因为OLAP支持的是动态查询,所以用户也许要通过将很多数据的统计后才能得到想要知道的信息,例如时间序列分析等等,所以处理的数据量很大;
- OLAP系统的重点是通过数据提供决策支持,所以查询一般都是动态,自定义的。所以在OLAP中,维度的概念特别重要。一般会将用户所有关心的维度数据,存入对应数据平台。
1.3. 数据库
数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
数据库是以一定方式储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合,可视为电子化的文件柜,存储电子文件的处所,用户可以对文件中的数据进行新增、查询、更新、删除等操作,数据组织主要是面向事务处理任务。
1.4. 数据库设计三范式
关系型数据库设计时,遵照一定的规范要求,目的在于降低数据的冗余性和保证数据的一致性,这些规范就可以称为范式NF(Normal Form),大多数情况下,关系型数据库的设计符合三范式即可。
三范式并非相互独立,而是一种约束上层层严苛的关系。
1.4.1. 第一范式(1NF)
在第一范式中,数据库所有字段值都是不可分解、具备原子性的值。
1.4.2. 第二范式(2NF)
第二范式在第一范式的基础上更进一层。第二范式需要确保数据库表中的每一列都和主键相关。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
*: 有主键,非主键字段依赖主键。
1.4.3. 第三范式(3NF)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
1.5. ER实体关系模型
ER实体关系模型(Entity-Relationship)是数据库设计的理论基础,当前几乎所有的OLTP系统设计都采用ER模型建模的方式,这种建模方式基于三范式。在信息系统中,将事物抽象为“实体”、“属性”、“关系”来表示数据关联和事物描述。
1.5.1. 实体(Entity)
实体是一类数据模型,指应用中可以区别的客观存在的事物,它具有自己的属性。在ER实体关系模型中实体使用方框表示。
1.5.2. 属性(Attribute)
对实体的描述、修饰就是属性,即实体的某一特性称为属性。在ER实体关系模型中属性使用椭圆来表示。
1.5.3. 关系(Relationship)
关系表示一个或多个实体之间的关联关系,可分为一对一关系、一对多关系和多对多关系。
2. 数据仓库
2.1. 数据仓库的提出
1991年,比尔·恩门(Bill Inmon)出版了他的第一本关于数据仓库的书《Building the Data Warehouse》,标志着数据仓库概念的确立。该书定义了数据仓库非常具体的原则,包括:
- 数据仓库是面向主题的(Subject-Oriented)
- 集成的(Integrated)
- 包含历史的(Time-variant)
- 不可更新的(Nonvolatile)
- 面向决策支持的(Decision Support)
- 面向全企业的(Enterprise Scope)
- 最明细的数据存储(Atomic Detail)
- 数据快照式的数据获取(Snap Shot Capture)
这些原则到现在仍然是指导数据仓库建设的最基本原则。凭借着这本书,Bill Inmon被称为“数据仓库之父”。
2.2. 数据库vs数据仓库
传统关系型数据库的主要应用是OLTP(On-Line Transaction Processing),主要是基本的、日常的事务处理,例如银行交易。主要用于业务类系统,主要供基层人员使用,进行一线业务操作。
数仓系统的主要应用主要是OLAP(On-Line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。OLAP数据分析的目标是探索并挖掘数据价值,作为企业高层进行决策的参考。
| 功能 | 数据库 | 数据仓库 |
|---|---|---|
| 数据范围 | 当前状态数据 | 存储历史、完整、反应历史变化数据 |
| 数据变化 | 支持频繁的增删改查操作 | 可增加、查询,无更新、删除操作 |
| 应用场景 | 面向业务交易流程 | 面向分析、支持侧重决策分析 |
| 处理数据量 | 频繁、小批次、高并发、低延迟 | 非频繁、大批量、高吞吐、有延迟 |
| 设计理论 | 遵循数据库三范式、避免冗余 | 违范式、适当冗余 |
| 建模方式 | ER实体关系建模(范式建模) | 范式建模+维度建模 |
3. 维度建模
维度建模主要源自数据集市,主要面向分析场景。
维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。它与实体-关系(ER)建模有很大的区别,实体-关系建模是面向应用,遵循第三范式,以消除数据冗余为目标的设计技术。维度建模是面向分析,为了提高查询性能可以增加数据冗余,反规范化的设计技术。
Ralph Kimball推崇数据集市的集合为数据仓库,同时也提出了对数据集市的维度建模,将数据仓库中的表划分为事实表、维度表两种类型。
3.1. 事实表
发生在现实世界中的操作型事件,其所产生的可度量数值,存储在事实表中。
3.2. 维度表
维度表包含了维度的每个成员的特定名称。维度成员的名称称为“属性”(Attribute)。
3.3. 维度建模模型
3.3.1. 星型模型
当所有的维度表都由连接键连接到事实表时,结构图如星星一样,这种分析模型就是星型模型。
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。
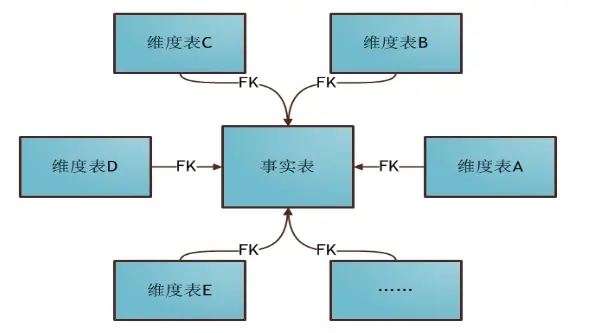
星型模型
3.3.2. 雪花模型
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其结构图就像雪花连接在一起,这种分析模型就是雪花模型。如下图,雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的“层次”区域,这些被分解的表都连接到主维度表而不是事实表。
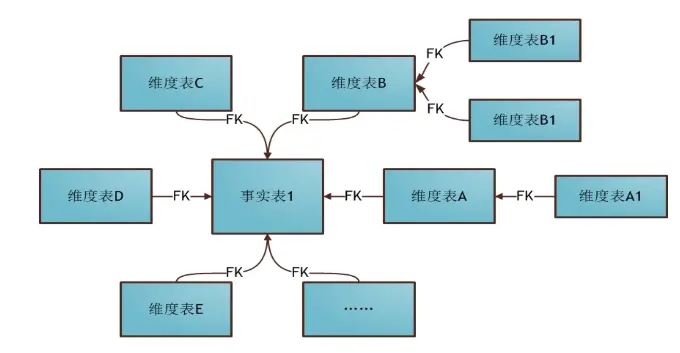
雪花模型
星型模型和雪花模型主要区别就是对维度表的拆分,对于雪花模型,维度表的设计更加规范,一般符合三范式设计;而星型模型,一般采用降维的操作,维度表设计不符合三范式设计,反规范化,利用冗余牺牲空间来避免模型过于复杂,提高易用性和分析效率。
雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,数仓构建实际运用中星型模型使用更多,也更有效率。
3.3.3. 星座模型
星座模式也是星型模式的扩展,星型模型和雪花模型都是基于多维表对应事实表,有的时候多个事实表共用多张维度表,这个时候就需要采用星座模式。
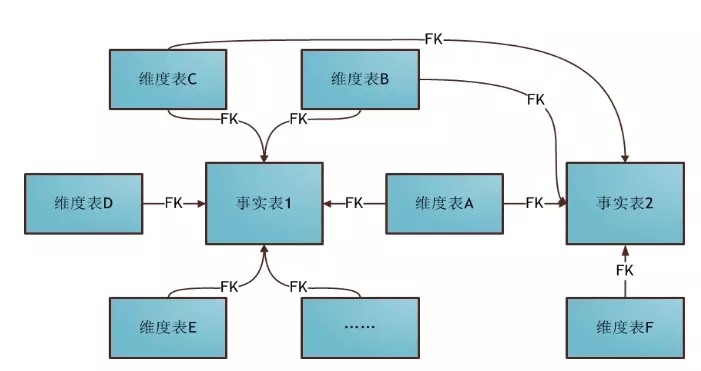
星座范式
4. 数据仓库分层架构
4.1. 分层架构的优势
4.1.1. 清晰的数据结构
每层数据都有各自的作用域和职责,在使用表的时候更方便定位和理解。
4.1.2. 减少重复开发
规范数据分层,开发一层公用的中间层数据,减少重复计算流转数据。
4.1.3. 统一数据出口
通过数据分层,提供统一的数据出口,保证对外输出数据口径一致。
4.1.4. 简化问题
通过数据分层,将复杂的业务简单化,将复杂的业务拆解为多层数据,每层数据负责解决特定的问题。
4.2. 分层思想

数据仓库-分层架构
4.2.1. ODS(Operational Data Store)
ODS层,操作数据层,也叫贴源层,本层直接存放从业务系统抽取过来的数据。这些数据从结构上和数据上与业务系统保持一致,降低了数据抽取的复杂性,本层数据大多是按照源头业务系统的分类方式而分类的。一般来讲,为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可。
4.2.2. DW(Data Warehouse)
DW层,数据仓库层,是我们在做数据仓库时要核心设计的一层,本层将从 ODS 层中获得的数据按照主题建立各种数据模型,每一个主题对应一个宏观的分析领域,数据仓库层排除对决策无用的数据,提供特定主题的简明视图。DW层又细分为 DWD(Data Warehouse Detail)层、DWM(Data Warehouse Middle)层和DWS(Data Warehouse Service)层。
4.2.3. DWD(Data Warehouse Detail)
DWD,数据明细层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证,在ODS的基础上对数据进行加工处理,提供更干净的数据。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,当一个维度没有数据仓库需要的任何数据时,就可以退化维度,将维度退化至事实表中,减少事实表和维表的关联。例如:订单id,这种量级很大的维度,没必要用一张维度表来进行存储,而我们一般在进行数据分析时订单id又非常重要,所以我们将订单id冗余在事实表中,这种维度就是退化维度。
4.2.4. DWM(Data Warehouse Middle)
DWM,数据中间层,是会在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工处理数据。简单来说,就是对通用的维度进行聚合操作,算出相应的统计指标,方便复用。
4.2.5. DWS(Data Warehouse Service)
DWS,数据服务层数据表会相对比较少,大多都是宽表(一张表会涵盖比较多的业务内容,表中的字段较多)。按照主题划分,如订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
在实际业务处理中,如果直接从DWD或者ODS计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在DWM层先计算出多个小的中间表,然后再拼接成一张DWS的宽表。由于宽和窄的界限不易界定,也可以去掉DWM这一层,只留DWS层,将所有的数据在放在DWS也没有问题。
4.2.6. DM(Data Mart)
DM层,数据集市层,也可以称为数据应用层,基于DW上的基础数据,整合汇总成分析某一个主题域的报表数据。主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、PostgreSql、Redis等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。比如我们经常说的报表数据,一般就放在这里。
登录后可发表评论
点击登录