用python爬取某宝热卖网站商品信息(爬虫之路,永无止境!)
代码操作展示:


开发环境:
windows10
python3.6
开发工具:
pycharm
chromedriver
库:
selenium、os、csv
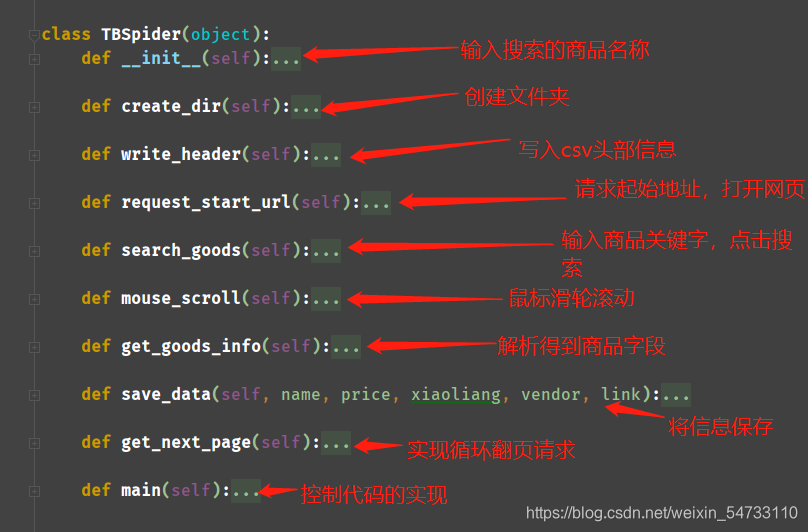
代码全解
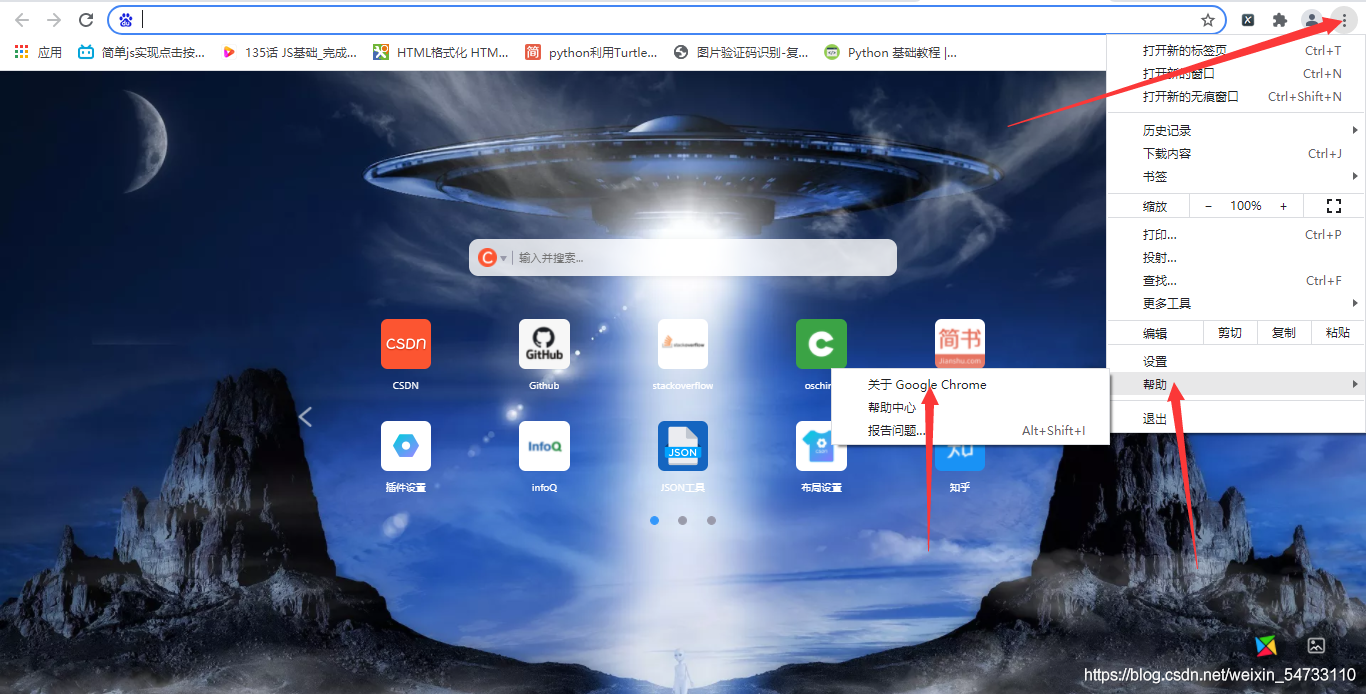
安装插件
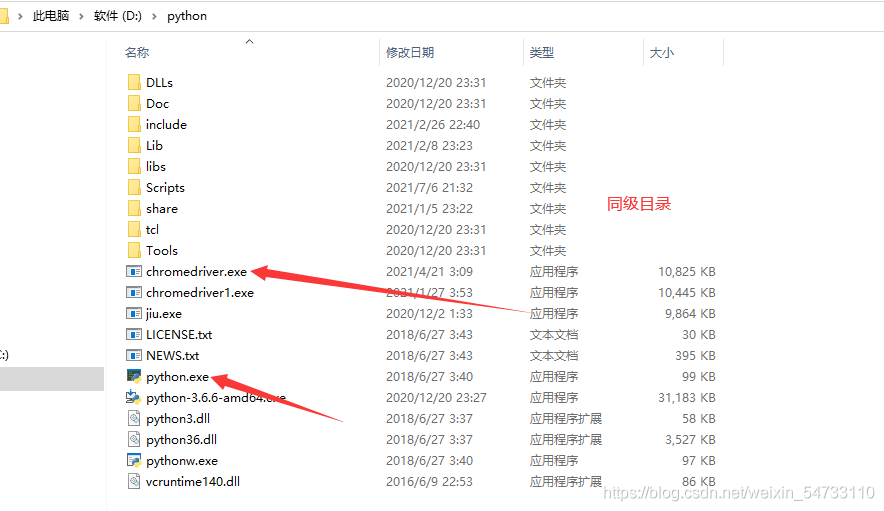
首先要安装webdriver插件,本文以谷歌浏览器为例,点开谷歌浏览器,点击右上角三个点,然后点击帮助,然后点击关于Google Chrome,查看浏览器的版本,然后点击网址http://npm.taobao.org/mirrors/chromedriver寻找自己浏览器对应的版本进行下载,下载之后将chromedriver.exe的文件最好放在你python解释器的同级目录下

本文采用自动化获取商品信息
start_url = 'https://uland.taobao.com/sem/tbsearch?refpid=mm_26632258_3504122_32538762&keyword=&clk1=b563659abe93a96a4e4c136b8d38b209&upsId=b563659abe93a96a4e4c136b8d38b209&spm=a2e0b.20350158.31919782.1&pnum=0’
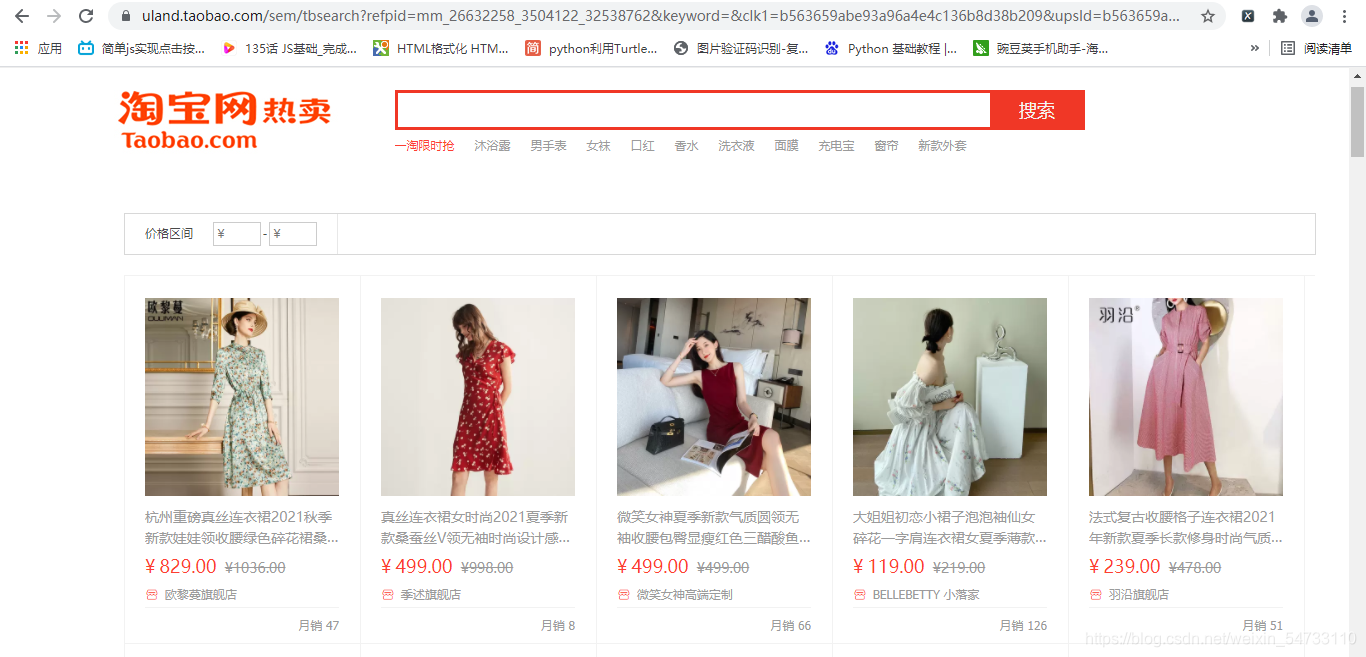
1.打开网址是这样的
2.在搜索框中输入要搜索的商品名称,并点击搜索
self.driver.find_element_by_id('J_search_key').send_keys(self.keyword)
self.driver.find_element_by_class_name('submit').click()
3.跳转网页之后,进行鼠标自动化滚轮操作
for i in range(1, 11):
js = r'scrollTo(0, {})'.format(600 * i)
self.driver.execute_script(js)
time.sleep(1)
4.解析得到商品数据
li_list = self.driver.find_elements_by_xpath('//div[@class="lego-pc-search-list pc-search-list"]/ul')
for li in li_list:
name = li.find_elements_by_xpath(r'//li[@class="pc-items-item item-undefined"]/a/div['
r'@class="pc-items-item-title pc-items-item-title-row2"]/span')
price = li.find_elements_by_xpath(r'//li[@class="pc-items-item item-undefined"]/a/div['
r'@class="price-con"]/span[2]')
xiaoliang = li.find_elements_by_xpath(r'li[@class="pc-items-item item-undefined"]/a/div['
r'@class="item-footer"]/div[2]')
vendor = li.find_elements_by_xpath(r'//*[@id="mx_5"]/ul/li/a/div[3]/div')
link = li.find_elements_by_xpath(r'//li[@class="pc-items-item item-undefined"]/a')
5.保存数据
with open(r'./{}/{}.csv'.format('商品信息数据', self.file_name), 'a+', newline='', encoding='gbk') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, price, xiaoliang, vendor, link])
print(r'***商品数据保存成功:{}'.format(name))
6.定位翻页,翻页之后进行滚轮操作
self.driver.find_element_by_xpath(r'//*[@id="J_pc-search-page-nav"]/span[3]').click()
self.mouse_scroll()
7.实现主要逻辑
self.create_dir()
self.get_next_page()
源码展示:
# !/usr/bin/nev python
# -*-coding:utf8-*-
import time, os, csv, datetime
from selenium import webdriver
class TBSpider(object):
def __init__(self):
self.count = 1
self.keyword = input(r'请输入要查询的淘宝商品信息名称:')
self.file_name = self.keyword + datetime.datetime.now().strftime('%Y-%m-%d')
self.driver = webdriver.Chrome(executable_path=r'chromedriver.exe的路径')
def create_dir(self):
'''
创建文件夹
'''
if not os.path.exists(r'./{}'.format('商品信息数据')):
os.mkdir(r'./{}'.format('商品信息数据'))
self.write_header()
def write_header(self):
'''
写入csv头部信息
'''
if not os.path.exists(r'./{}.csv'.format(r'***商品数据保存成功:{}'.format(self.keyword))):
csv_header = ['商品名称', '商品价格', '销量', '商品店铺', '商品链接']
with open(r'./{}/{}.csv'.format('商品信息数据', self.file_name), 'w', newline='', encoding='gbk') as file_csv:
csv_writer_header = csv.DictWriter(file_csv, csv_header)
csv_writer_header.writeheader()
self.request_start_url()
def request_start_url(self):
'''
请求起始url
'''
self.driver.get('https://uland.taobao.com/sem/tbsearch?refpid=mm_26632258_3504122_32538762&keyword=&clk1=b563659abe93a96a4e4c136b8d38b209&upsId=b563659abe93a96a4e4c136b8d38b209&spm=a2e0b.20350158.31919782.1&pnum=0')
self.driver.maximize_window()
self.driver.implicitly_wait(10)
self.search_goods()
def search_goods(self):
'''
输入商品关键字
'''
print('\n' + r'----------------正在搜索商品信息:{}--------------------'.format(self.keyword) + '\n')
self.driver.find_element_by_id('J_search_key').send_keys(self.keyword)
self.driver.find_element_by_class_name('submit').click()
time.sleep(3)
self.mouse_scroll()
def mouse_scroll(self):
'''
鼠标滑轮滚动,实现懒加载过程
'''
print(r'----------------正在请求第{}页数据--------------------'.format(self.count) + '\n')
for i in range(1, 11):
js = r'scrollTo(0, {})'.format(600 * i)
# js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %s' % (i / 20)
self.driver.execute_script(js)
time.sleep(1)
self.get_goods_info()
def get_goods_info(self):
'''
解析得到商品信息字段
'''
li_list = self.driver.find_elements_by_xpath('//div[@class="lego-pc-search-list pc-search-list"]/ul')
for li in li_list:
name = li.find_elements_by_xpath(r'//li[@class="pc-items-item item-undefined"]/a/div['
r'@class="pc-items-item-title pc-items-item-title-row2"]/span')
price = li.find_elements_by_xpath(r'//li[@class="pc-items-item item-undefined"]/a/div['
r'@class="price-con"]/span[2]')
xiaoliang = li.find_elements_by_xpath(r'li[@class="pc-items-item item-undefined"]/a/div['
r'@class="item-footer"]/div[2]')
vendor = li.find_elements_by_xpath(r'//*[@id="mx_5"]/ul/li/a/div[3]/div')
link = li.find_elements_by_xpath(r'//li[@class="pc-items-item item-undefined"]/a')
for a, b, c, d, e in zip(name, price, xiaoliang, vendor, link):
f = a.text
g = b.text
h = c.text
i = d.text.replace('', '')
j = e.get_attribute('href')
self.save_data(f, g, h, i, j)
def save_data(self, name, price, xiaoliang, vendor, link):
'''
写入csv文件主体信息
'''
try:
with open(r'./{}/{}.csv'.format('商品信息数据', self.file_name), 'a+', newline='', encoding='gbk') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, price, xiaoliang, vendor, link])
print(r'***商品数据保存成功:{}'.format(name))
except Exception as e:
pass
def get_next_page(self):
'''
实现循环请求
'''
time.sleep(4)
for index in range(2, 101):
print(r'----------------第{}页数据保存完成--------------------'.format(self.count) + '\n')
time.sleep(4)
self.count += 1
if index <= 100:
self.driver.find_element_by_xpath(r'//*[@id="J_pc-search-page-nav"]/span[3]').click()
self.mouse_scroll()
else:
print('\n' + r'---------------所有商品数据保存完成------------------')
break
def main(self):
'''
实现主要逻辑
'''
self.create_dir()
self.get_next_page()
print('\n' + r'-------------文件保存成功------------------')
if __name__ == '__main__':
tb = TBSpider()
tb.main()
