教你用python爬取王者荣耀英雄皮肤图片,并将图片保存在各自英雄的文件夹中。(附源码)
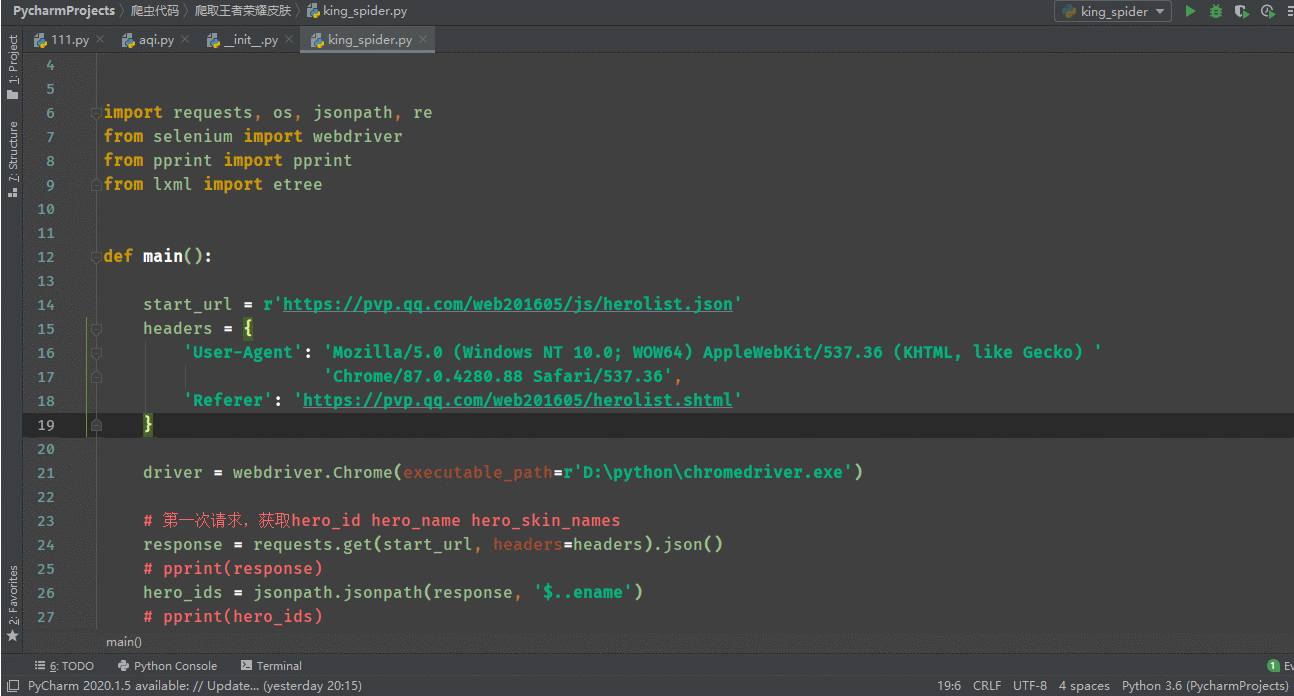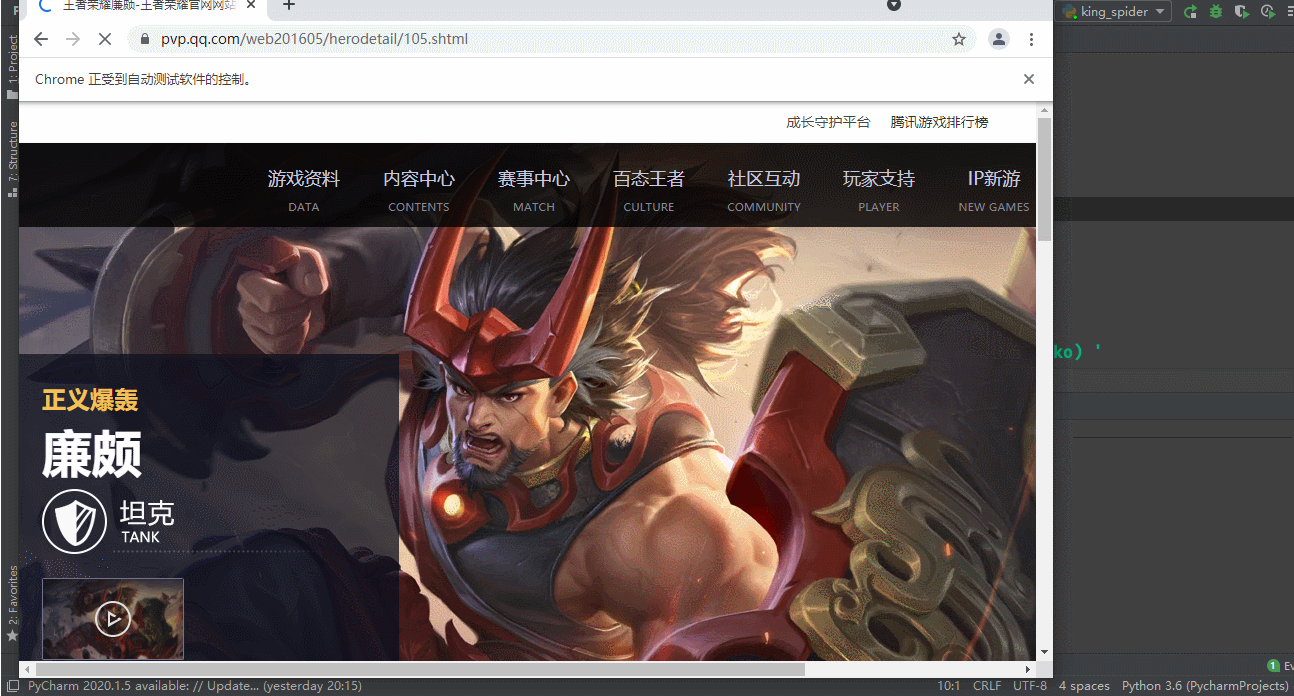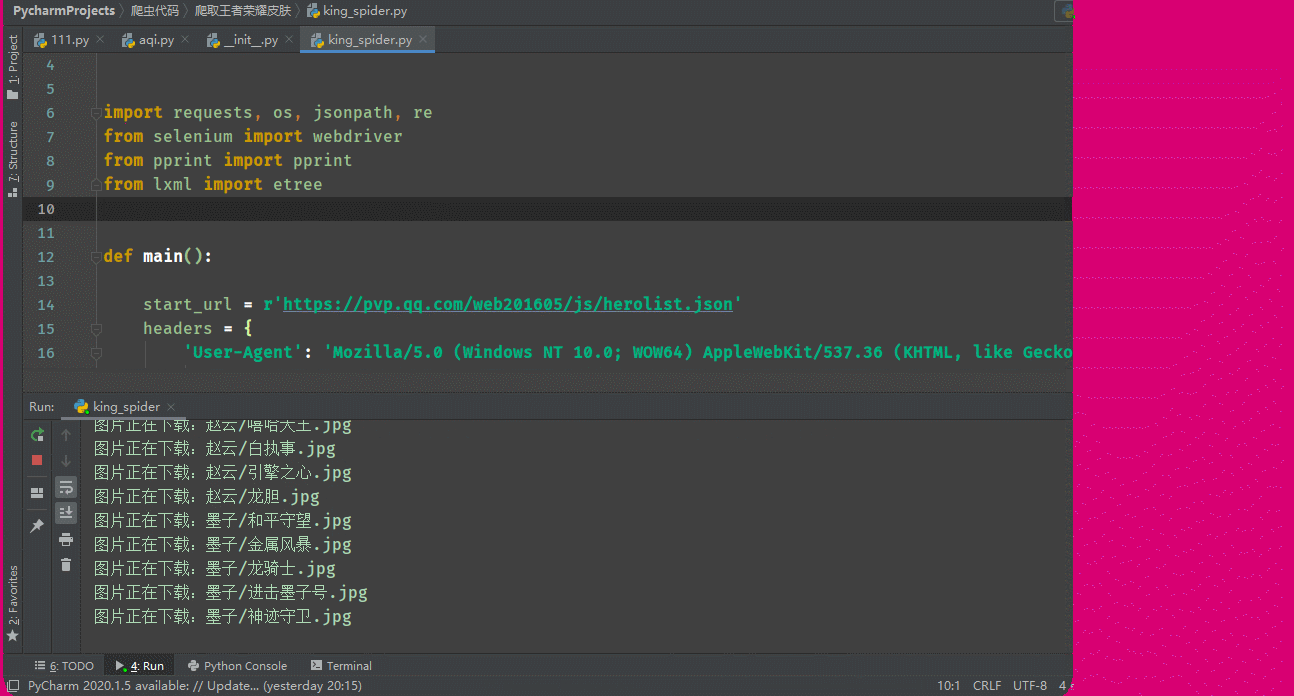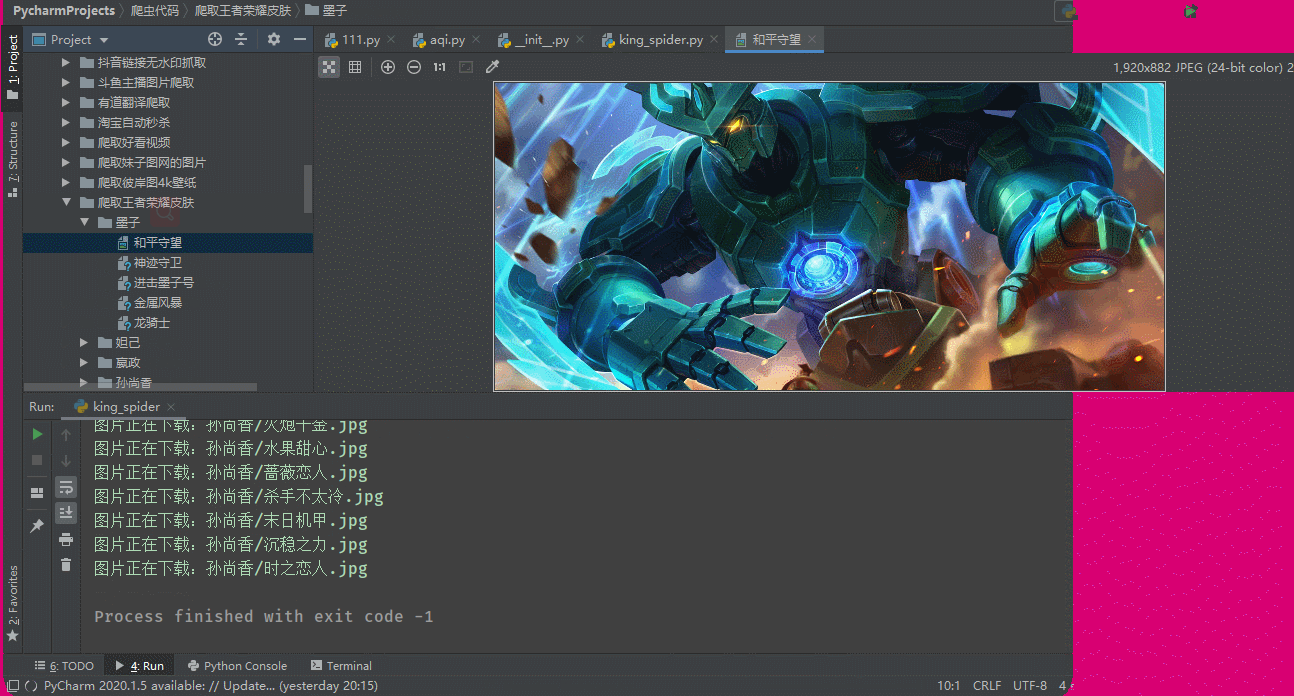
代码展示:
保存在各自的文件夹中
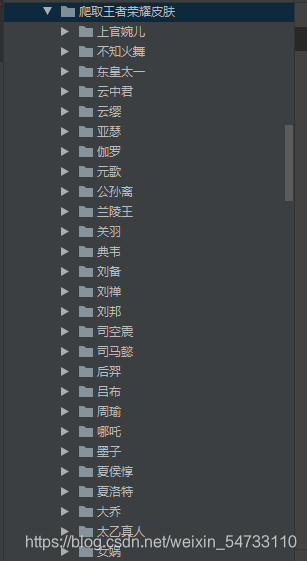
美么?

让我们开始爬虫之路
开发环境
windows 10
python3.6
开发工具
pycharm
webdriver
库
os,re,lxml,jsonpath
打开王者荣耀官网点击游戏资料
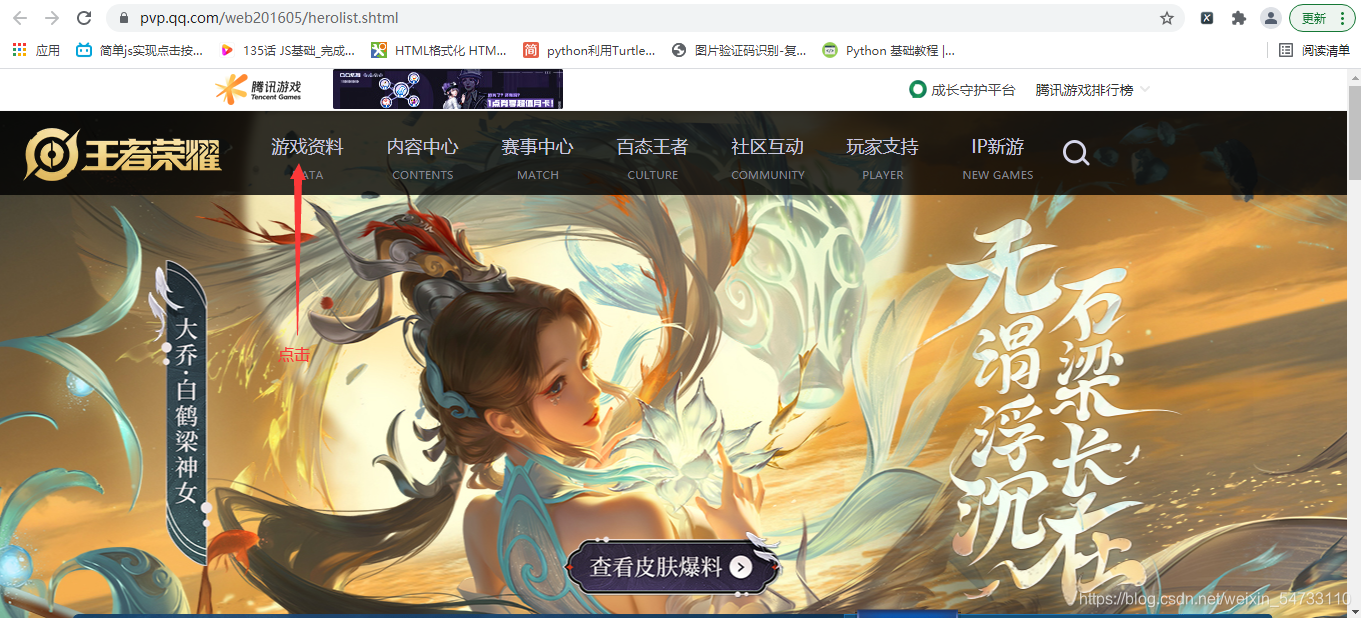
判断是同步加载还是异步加载, 可以确定为异步加载
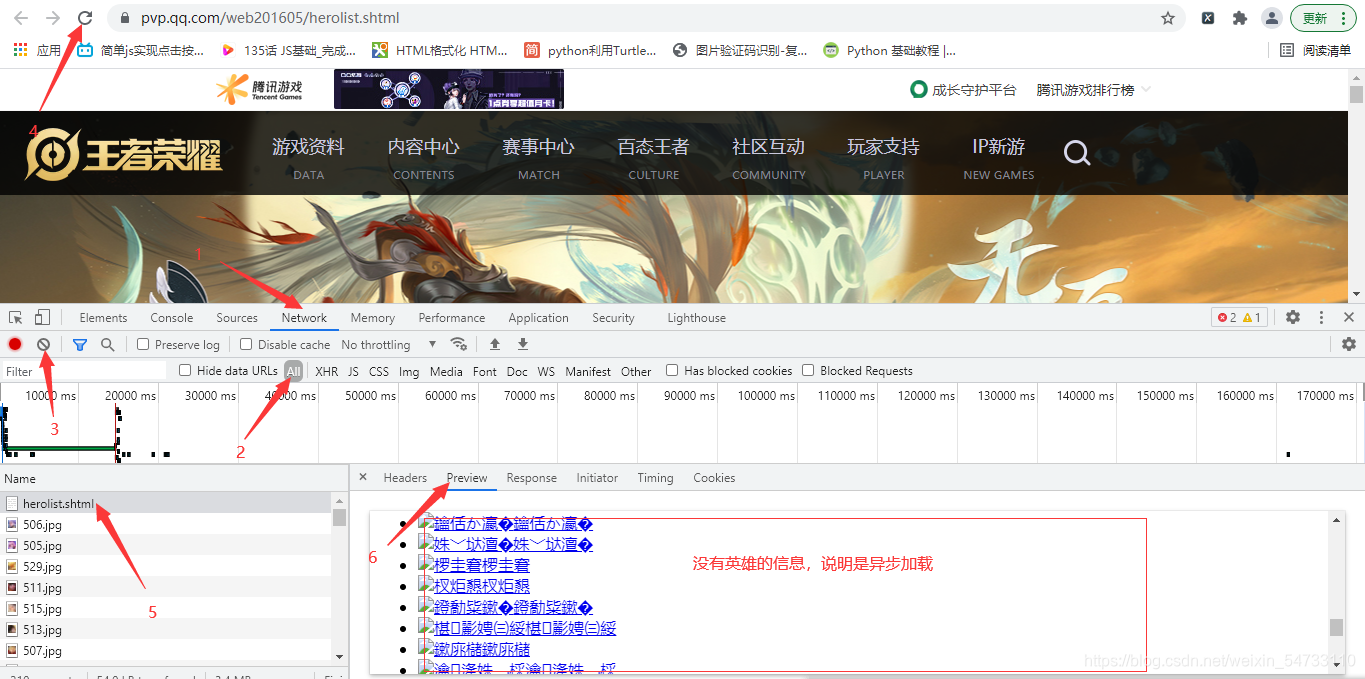
点击XHR继续抓包,ename为英雄的ID,cname为英雄的名字
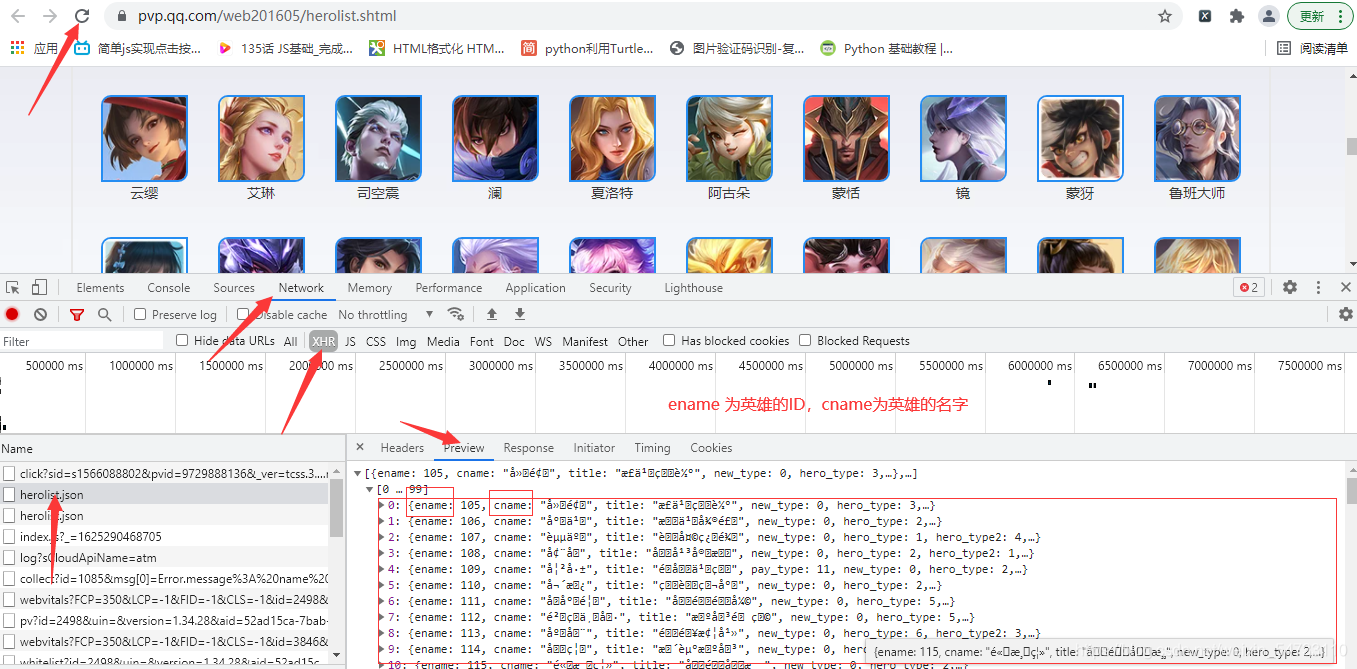
jsonpath获取
# 第一次请求,获取hero_id hero_name
response = requests.get(start_url, headers=headers).json()
# pprint(response)
hero_ids = jsonpath.jsonpath(response, '$..ename')
# pprint(hero_ids)
hero_names = jsonpath.jsonpath(response, '$..cname')
# pprint(hero_names)
构造英雄地址
hero_info_url = r’https://pvp.qq.com/web201605/herodetail/{}.shtml’.format(hero_id)
driver访问每一个英雄地址,获取源码,etree解析,xpath提取hero_skin_names,hero_skin_urls
for hero_name, hero_id in zip(hero_names, hero_ids):
hero_info_url = r'https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(hero_id)
# 发送英雄详情页请求得到 hero_info_content
driver.get(hero_info_url)
# 获取页面源码
hero_info_content = driver.page_source
# 解析网页
hero_info_content_str = etree.HTML(hero_info_content)
# 提取 hero_skin_names hero_skin_urls
hero_skin_names = hero_info_content_str.xpath(r'//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[
0].split('|')
hero_skin_urls = hero_info_content_str.xpath(r'//ul[@class="pic-pf-list pic-pf-list3"]//img/@data-imgname')
遍历hero_skin_urls地址,获取图片的二进制数据,最后进行保存,创建英雄的文件夹,将皮肤图片保存在各自的文件夹中
# 补全hero_skin_url地址
hero_skin_url = r'https:'+hero_skin_url
# 获取图片的二进制信息
img_content = requests.get(hero_skin_url, headers=headers).content
try:
# 创建文件夹
if not os.path.exists('./{}'.format(hero_name)):
os.mkdir(r'./{}'.format(hero_name))
with open(r'./{}/{}.jpg'.format(hero_name, hero_skin_name), 'wb')as f:
f.write(img_content)
print('图片正在下载:{}/{}.jpg'.format(hero_name, hero_skin_name))
except Exception as e:
continue
在执行时本来是以requests库进行获取英雄页面的源码,但是发生报错,报错原因是因为编码问题,所以采用webdriver访问每个英雄页面,driver.page_source获取源码,然后进行数据提取。
源码展示
# !/usr/bin/nev python
# -*-coding:utf8-*-
import requests, os, jsonpath, re
from selenium import webdriver
from pprint import pprint
from lxml import etree
def main():
start_url = r'https://pvp.qq.com/web201605/js/herolist.json'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36',
'Referer': 'https://pvp.qq.com/web201605/herolist.shtml'
}
driver = webdriver.Chrome(executable_path=r'D:\python\chromedriver.exe')
# 第一次请求,获取hero_id hero_name hero_skin_names
response = requests.get(start_url, headers=headers).json()
# pprint(response)
hero_ids = jsonpath.jsonpath(response, '$..ename')
# pprint(hero_ids)
hero_names = jsonpath.jsonpath(response, '$..cname')
# pprint(hero_names)
for hero_name, hero_id in zip(hero_names, hero_ids):
hero_info_url = r'https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(hero_id)
# 发送英雄详情页请求得到 hero_info_content
driver.get(hero_info_url)
# 获取页面源码
hero_info_content = driver.page_source
# lxml解析
hero_info_content_str = etree.HTML(hero_info_content)
# 提取 hero_skin_names hero_skin_urls
hero_skin_names = hero_info_content_str.xpath(r'//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[
0].split('|')
hero_skin_urls = hero_info_content_str.xpath(r'//ul[@class="pic-pf-list pic-pf-list3"]//img/@data-imgname')
# hero_skin_name进行替换不必要的信息
for hero_skin_name, hero_skin_url in zip(hero_skin_names, hero_skin_urls):
suffix_notation = re.findall(r'&\d.?', hero_skin_name)[0]
hero_skin_name = hero_skin_name.replace(suffix_notation, '')
# 补全hero_skin_url地址
hero_skin_url = r'https:'+hero_skin_url
# 获取图片的二进制信息
img_content = requests.get(hero_skin_url, headers=headers).content
try:
# 创建文件夹
if not os.path.exists('./{}'.format(hero_name)):
os.mkdir(r'./{}'.format(hero_name))
with open(r'./{}/{}.jpg'.format(hero_name, hero_skin_name), 'wb')as f:
f.write(img_content)
print('图片正在下载:{}/{}.jpg'.format(hero_name, hero_skin_name))
except Exception as e:
continue
if __name__ == '__main__':
main()
