每天日志打卡1/1
一直知道Pearl老先生很厉害,买了书一直也没看,这次先找一篇简单的入个门。
这篇发表于2019年的论文我一直没找到什么笔记和评论,只能自己看看了。这篇笔记也是大概梳理一下我看到的重点和思路。
INTRODUCTION
在机器学习蓬勃发展的时候,人们期望AI获得很大成功,但有三个障碍:鲁棒性、可解释性和因果关系的理解。作者认为,想要解决这三个问题需要在机器学习中加入因果模型的工具。
THE THREE LAYER CAUSAL HIERARCHY
接下来,作者解释了因果的三个等级,我之前在知乎看过一篇文章,讲的很详细。
https://zhuanlan.zhihu.com/p/258562953

具体来说,是把因果信息按照能回答的问题不同分成三类层次结构中的每一层都有一个特征式子。
例如,关联层的特征是条件概率。
干预层的特征是 P(y|do(x), z) ,它表示“假设我们进行干预并将 X 的值设置为 x 并随后观察事件 Z =z ,事件 Y = y 的概率。 可以通过随机试验或使用因果贝叶斯网络进行分析来估计此类表达式。人工智能规划者通过执行他们指定的一系列动作来获得干预知识。 关键性区别在于:无论数据有多大,都不能仅从被动观察中推断出干预性表达。
最后,在反事实层面,我们有P(y |x′,y′) 代表“假设我们实际上观察到 X 是 x' 并且 Y 是 y',我们想知道如果 X 是 x 的时候事件 Y = y 的概率' 。 例如,Joe的实际薪水是 y′ 并且他只上过两年大学,如果他大学毕业,他的薪水是 y 的概率。” 只有当我们拥有函数或结构方程模型或这些模型的属性时,才能计算这些概率。
THE SEVEN TOOLS OF CAUSAL INFERENCE (OR WHAT YOU CAN DO WITH A CAUSAL MODEL THAT YOU COULD NOT DO WITHOUT?)
标题很长,其实没那么复杂。首先作者老生常谈了他的独创model:“Structural Causal Models (SCM).”

SCM由三部分组成。图像模型用于表示我们知道的信息(我们知道的关于这个世界的东西);反事实和干预逻辑帮助我们利用我们知道的东西,结构性公式把它俩结合起来。这么说有点绕给个栗子:
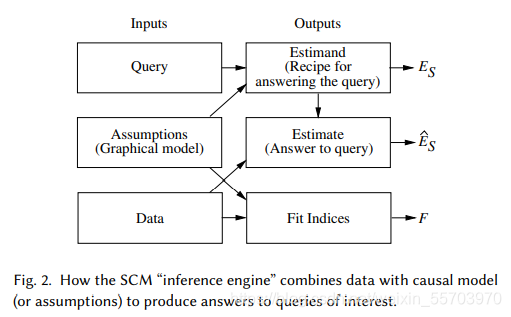
我们利用SCM建模一个干预机器。该机器接受三个输入:假设(assumption)、查询(query)和数据(data),并产生三个输出:估计(estimand)、估计’(estimate)和拟合指数(fit indices)。 Estimand (ES) 是一个数学公式,它基于假设,提供了从任何假设数据(只要它们可用)回答查询的方法。 接收到数据后,机器使用 Estimand 产生一个实际的对答案的估计 (ES ),以及对该答案置信度的统计估计(以反映数据集的有限大小,以及可能的测量误差或缺失数据。)最后,引擎生成“拟合指数”衡量数据与模型传达的假设的兼容性。
之后,作者以“吃药”“性别”和“病愈”为例介绍了一个SCM模型。接下来,作者介绍了七种SCM框架可以完成的任务、和在完成任务中用到的tools。
1.编码因果假设——透明度和可测试性
一旦我们认真对待透明度和可测试性的要求,以紧凑和可用的形式编码假设的任务就不是一件小事。透明度使分析师能够辨别编码的假设是否合理(基于科学依据),或者其他假设是否合理保证。可测试性允许我们(无论是分析师还是机器)确定编码的假设是否与可用数据兼容,如果不兼容,则确定需要修复的假设。
图形模型的进步使紧凑编码(compact encoding)成为可能。它们的透明度自然源于这样一个事实,即所有假设都以图形形式定性编码,反映了研究人员对该领域因果关系的看法;不需要反事实或统计依赖的判断,因为这些可以从图的结构中读出。可测试性通过称为 d-separation 的图形标准得到促进,该标准提供了原因和概率之间的基本联系。它告诉我们,对于模型中任何给定的路径模式,我们应该期望在数据中找到什么样的依赖模式。
2.Do-calculus 和混杂控制
混淆、或两个或多个变量存在未观察到的原因,长期以来一直被认为是从数据中得出因果推断的主要障碍,这个障碍已经通过称为“后门”的图形标准被揭开神秘面纱和“解混”。 特别是,选择一组合适的协变量来控制混杂的任务已经简化为一个简单的“路障”难题,可以通过简单的算法进行管理 [Pearl 1993]。 对于“后门”标准不成立的模型,可以使用称为 do-calculus 的符号引擎,它在可行的情况下预测政策干预的效果,并在无法通过指定的假设确定预测时以失败退出。 [Bareinboim and Pearl 2012; Pearl 1995; Shpitser and Pearl 2008; Tian and Pearl 2002]
3.反事实的算法化
反事实分析处理特定个人的行为,由一组不同的特征确定,例如,假设乔的薪水是 Y = y,并且他上了 X = x 年的大学,如果他再多上一年大学乔的薪水会是多少。
现代因果关系工作的最高成就之一是在图形表示中形式化反事实推理——研究人员用来编码科学知识的表示。每个结构方程模型决定了每个反事实句子的真值。因此,我们可以通过分析来确定句子的概率是否是可估计的。例如,经济学家选择了代数而不是图形表示,被剥夺了基本的可测试性检测特征 [Pearl 2015b]。来自实验或观察研究,或其组合 [Balke and Pearl 1994;珍珠 2000,第 7 章]。因果论述中特别感兴趣的是关于“结果的原因”的反事实问题,而不是“原因的结果”。例如,乔的游泳运动是乔死亡的必要(或充分)原因的可能性有多大 [Halpern and Pearl 2005; Pearl 2015a]。
4.中介分析(Mediation Analysis)和直接和间接影响的评估
中介分析涉及将变化从原因传递到其结果的机制。 这种中间机制的识别对于产生解释至关重要,必须调用反事实分析来促进这种识别。 反事实的图形表示使我们能够定义直接和间接影响,并决定何时可以从数据或实验中估计这些影响 [Pearl 2001; Robins and Greenland 1992; VanderWeele 2015].。 可回答的典型查询分析是:X 对 Y 的影响有多少是由变量 Z 介导的。
5.适应性、外部有效性和样本选择偏差
每项实验研究的有效性都受到实验和实施设置之间差异的挑战。当环境条件发生变化时,不能期望在一种环境中训练的机器表现良好,除非这些变化被定位和识别。这个问题及其各种表现已经被人工智能研究人员所熟知,诸如“领域适应”、“迁移学习”、“终身学习”和“可解释人工智能”等企业[Chen and Liu 2016],只是其中的一部分。研究人员和资助机构确定的子任务,以试图缓解鲁棒性的一般问题。不幸的是,问题鲁棒性的最广泛形式需要环境的因果模型,不能在关联级别处理。关联不足以识别受所发生变化影响的机制 [Pearl 和 Bareinboim 2014]。原因是观察到的关联中的表面变化并不能唯一确定导致变化的潜在机制。上面讨论的 do-calculus 现在提供了一个完整的方法来克服由于环境变化引起的偏差。可以使用既用于重新调整学习政策以规避环境变化,也用于控制非代表性样本与目标人群之间的差异 [Bareinboim and Pearl 2016]。
6.从丢失的数据中恢复
缺失数据的问题困扰着实验科学的每个分支。 受访者不会回答问卷中的每个项目,传感器会随着天气条件的恶化而发生故障,并且患者经常因未知原因退出临床研究。 关于这个问题的丰富文献与关联分析的无模型范式结合在一起,因此,它严重限于随机发生缺失的情况,即独立于模型中其他变量所取的值。 使用缺失过程的因果模型,我们现在可以形式化可以从不完整数据中恢复因果关系和概率关系的条件,并且只要满足条件,就可以对所需关系进行一致的估计 [Mohan and Pearl 2018; Mohan et al. 2013]。
7.因果发现
上面描述的 d-separation 标准使我们能够检测和枚举给定因果模型的可测试含义。这开启了以温和假设推断与数据兼容的模型集并紧凑地表示该集的可能性。已经开发了系统搜索,在某些情况下,它可以显着修剪兼容模型集到可以直接从该集估计因果查询的程度[Jaber et al. 2018; Pearl 2000; Peters et al. 2017; Spirtes et al. 2000]。
或者,Shimizu et al. [2006] 提出了一种基于功能分解发现因果方向性的方法 [[Peters et al. 2017]。这个想法是,在具有非高斯噪声的线性模型 X → Y 中,P(y) 是两个非高斯分布的卷积,形象地说,比 P(x)“更高斯”。 “高斯比”的关系可以给出精确的数值度量,并用于推断某些箭头的方向性。
Tian 和 Pearl [2002] 开发了另一种基于检测“冲击”的因果发现方法,或环境中自发的局部变化,其作用类似于“自然的干预”,并揭示了对这些冲击后果的因果方向性。
结论
因果推理是人类思想不可或缺的组成部分,应该将其形式化和算法化以实现人类水平的机器智能。文章以三级层次结构的形式解释了实现该目标的一些障碍,并表明对 2 级和 3 级的推断需要一个环境的因果模型。此外,文章描述已经描述了七项认知任务,这些任务需要来自这两个推理级别的工具,并演示了如何在 SCM 框架中完成这些任务。
需要注意的是,用于完成这些任务的模型是结构性的(或概念性的),不需要承诺所涉及的特定形式的分布。另一方面,所有推论的有效性关键取决于假设结构的真实性。如果真实结构与假设的结构不同,并且数据对两者的拟合程度相同,则可能会产生大量错误,有时可以通过敏感性分析来评估这些错误。同样重要的是要记住,无模型机器学习的理论局限性不适用于预测、诊断和识别任务,其中干预和反事实扮演次要角色。
然而,规避这些限制的模型辅助方法仍然适用于不透明性、鲁棒性、可解释性和缺失数据的问题,这些问题对于机器学习任务来说是通用的。此外,鉴于因果建模对社会科学和医学科学产生的变革性影响,一旦在数据生成模型的指导下丰富了机器学习技术,就很自然地期望类似的变革席卷机器学习技术。过程。作者希望这种共生能够产生以用户的母语因果关系进行交流的系统,并利用这种能力成为下一代人工智能的主导范式。
[1]Pearl, Judea. (2019). The seven tools of causal inference, with reflections on machine learning. Communications of the ACM. 62. 54-60. 10.1145/3241036.