0 背景
在上一篇文章《深度学习之openvino预训练模型测试》,我们介绍了如何使用 intel 提供的预训练模型完成语义分割任务。但在用 public 预训练模型时,发现我的 openvino 版本较低不支持,因此,对我的 sdk 进行了升级,继续介绍如何使用预训练模型的方法。
升级安装方法参考《深度学习之win10安装配置openvino》 ,升级后的版本为 Version 2021.3。
1 模型介绍
这篇文章我们以 Optical Character Recognition Models / OCR 字符识别模型(车牌识别)模型为例,首先看看模型介绍
license-plate-recognition-barrier-0007 模型是一个较小规模的端到端的中文车牌识别模型,来识别道路中的中国车牌,示例如下(出于隐私保护目的,对车牌进行了裁剪处理)
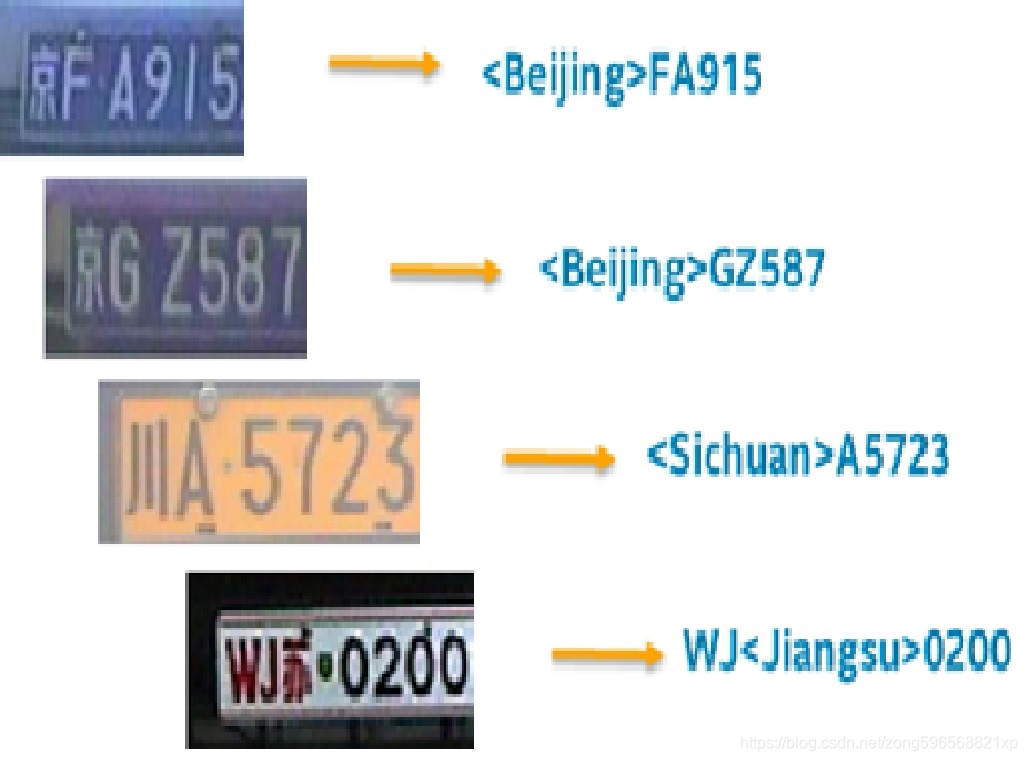
模型参数如下
| 指标 | 值 |
| 平面内旋转(Rotation in-plane) | ±10˚ |
| 平面外旋转(Rotation out-of-plane) | Yaw: ±45˚ / Pitch: ±45˚ |
| 最小宽度(Min plate width) | 94 pixels |
| 识别准确率(Ratio of correct reads) | 98% |
| 计算量(GFlops) | 0.347 |
| 参数量(MParams) | 1.435 |
| 训练框架(Source framework) | TensorFlow |
注意,上述准确率指标只针对蓝牌,其它类型的车牌性能可能会差一些。
输入信息:
Image, name: data , shape: 1,3,24,94, format is 1,C,H,W where:
C- channelH- heightW- width
Channel order is BGR.
输出信息:
Encoded vector of floats, name: decode, shape: 1,88,1,1. Each float is an integer number encoding a character according to this dictionary:
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
10 <Anhui>
11 <Beijing>
12 <Chongqing>
13 <Fujian>
14 <Gansu>
15 <Guangdong>
16 <Guangxi>
17 <Guizhou>
18 <Hainan>
19 <Hebei>
20 <Heilongjiang>
21 <Henan>
22 <HongKong>
23 <Hubei>
24 <Hunan>
25 <InnerMongolia>
26 <Jiangsu>
27 <Jiangxi>
28 <Jilin>
29 <Liaoning>
30 <Macau>
31 <Ningxia>
32 <Qinghai>
33 <Shaanxi>
34 <Shandong>
35 <Shanghai>
36 <Shanxi>
37 <Sichuan>
38 <Tianjin>
39 <Tibet>
40 <Xinjiang>
41 <Yunnan>
42 <Zhejiang>
43 <police>
44 A
45 B
46 C
47 D
48 E
49 F
50 G
51 H
52 I
53 J
54 K
55 L
56 M
57 N
58 O
59 P
60 Q
61 R
62 S
63 T
64 U
65 V
66 W
67 X
68 Y
69 Z
2 模型转换
接下来我们下载该模型,方法和上一篇文章中提到的一样,这里不赘述,直接贴出下载过程

下载的模型是 tensorflow 格式的 ckpt 文件,我们需要做一个转换,满足 openvino 框架调用

转化方法是使用 downloader 路径下的 converter.py 文件,需要指定模型名称
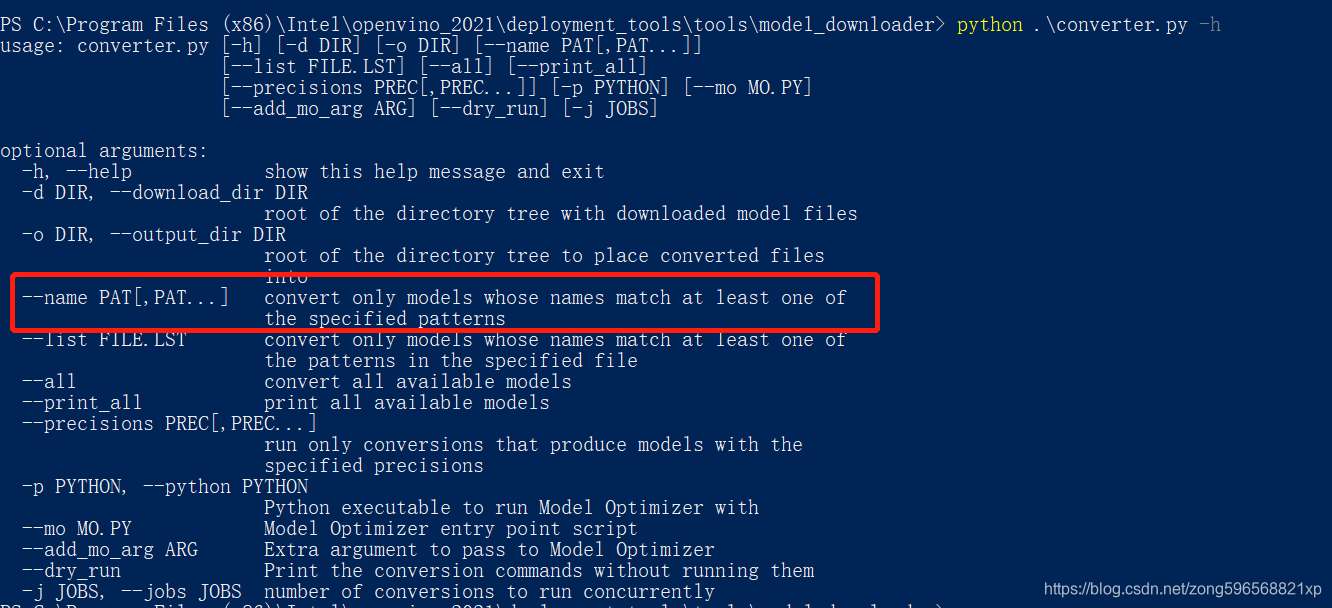
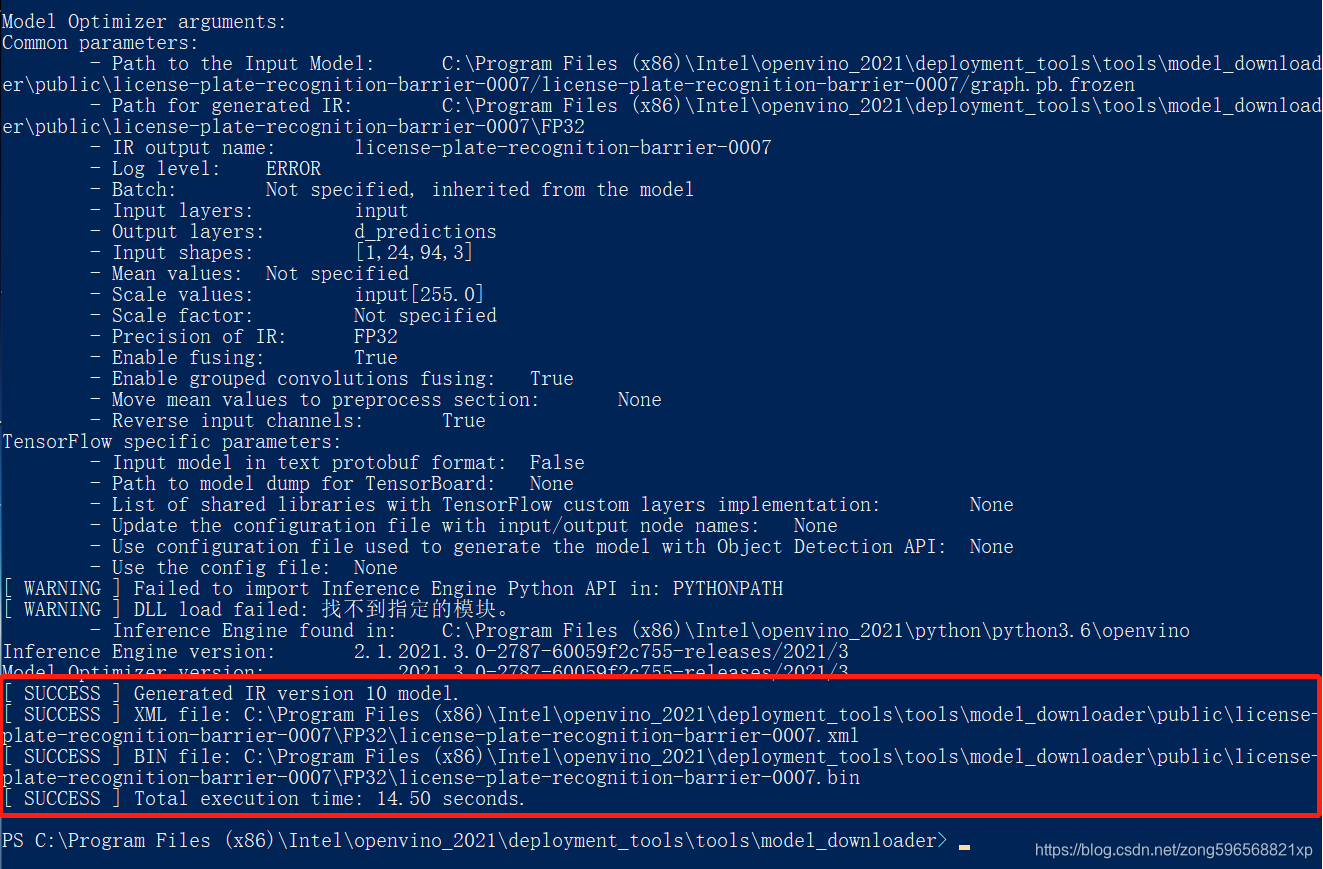
运行指令 python .\converter.py --name license-plate-recognition-barrier-0007,转换成功显示如下,在对应的路径下生成 IR 模型,包含 xml 和 bin 文件
3 模型调用
同样的,在 sdk 里提供了模型调用的 demo,我们直接运行 build_demo_msvc.bat,可以一次性把所有的 demo 进行编译
方法如下
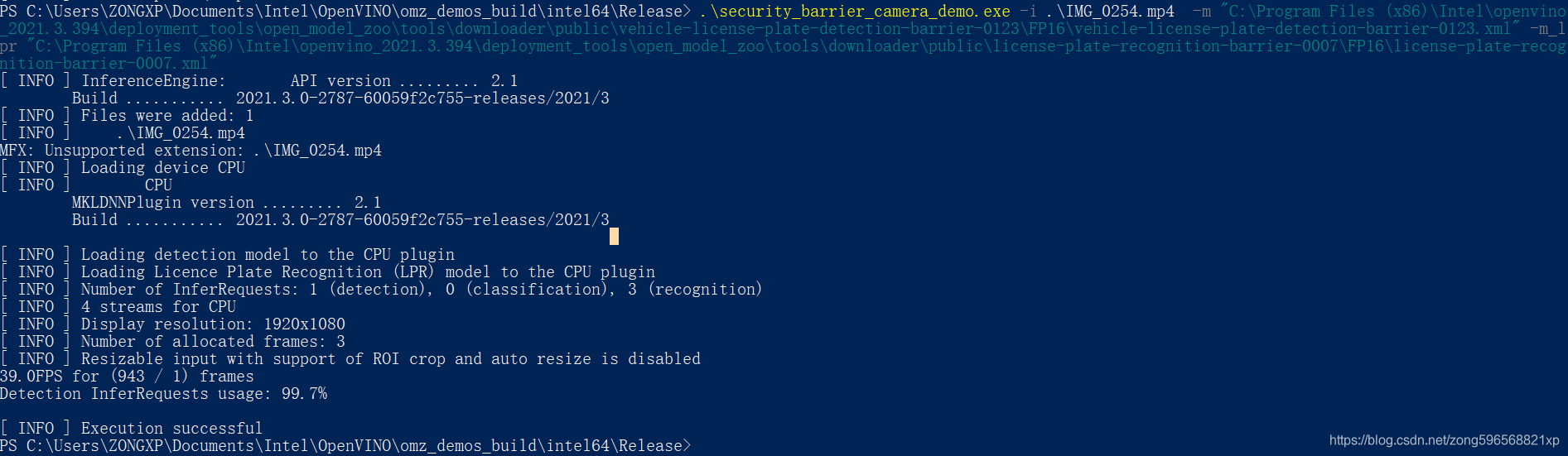
对于车牌识别功能来说,用到的项目是 security_barrier_camera_demo,生成的可执行文件为 C:\Users\ZONGXP\Documents\Intel\OpenVINO\omz_demos_build\intel64\Release\security_barrier_camera_demo.exe
查看使用说明,需要指定输入文件、车辆和车牌检测模型(-m)、车牌识别模型(-m_lpr)

其中,车牌和车辆检测模型属于 Object Detection Models / 目标检测模型 中的 vehicle-license-plate-detection-barrier-0123,下载和转化方法同上边识别模型的方法类似,这里贴一下运行指令
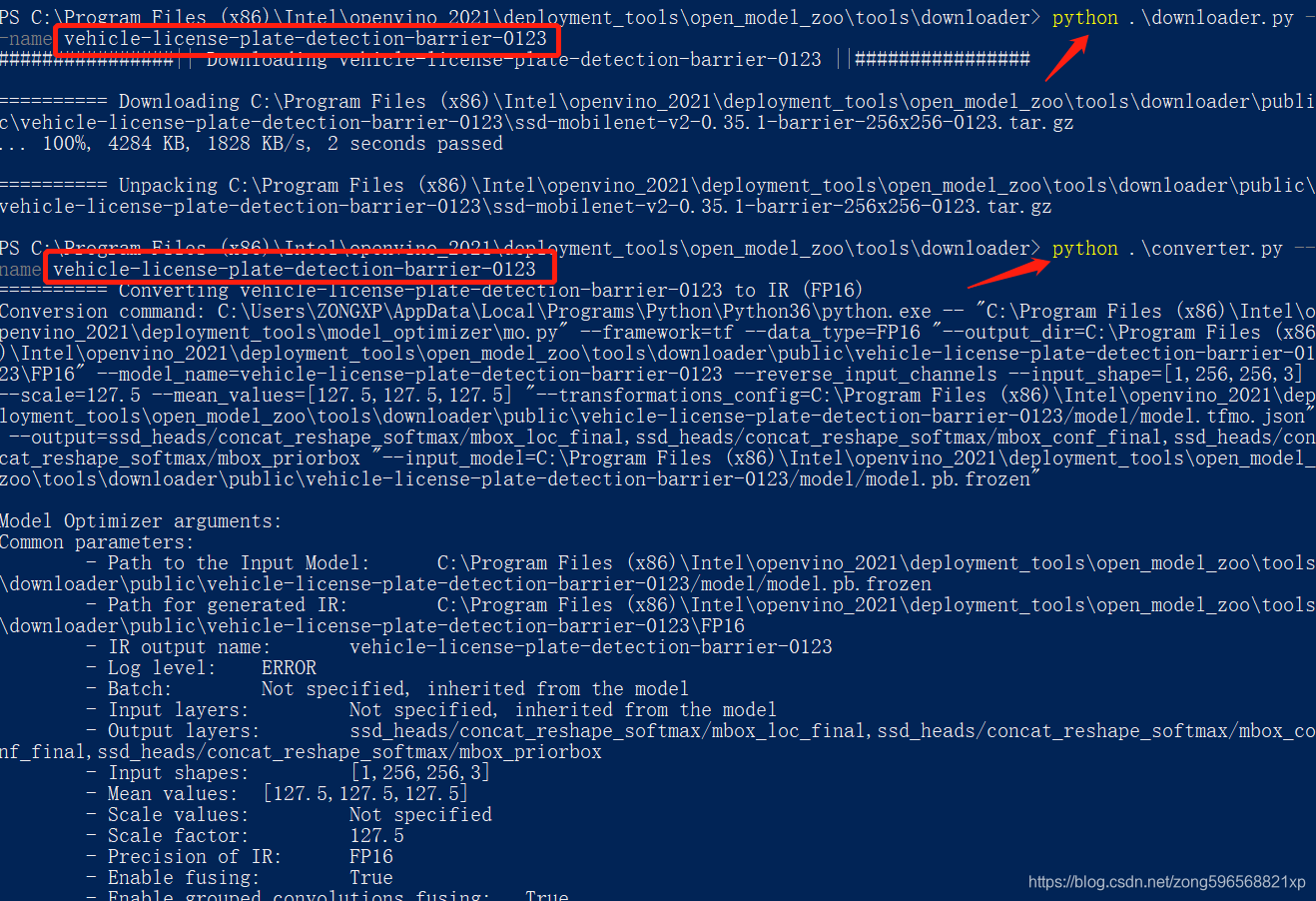
下载转换好之后,运行执行脚本
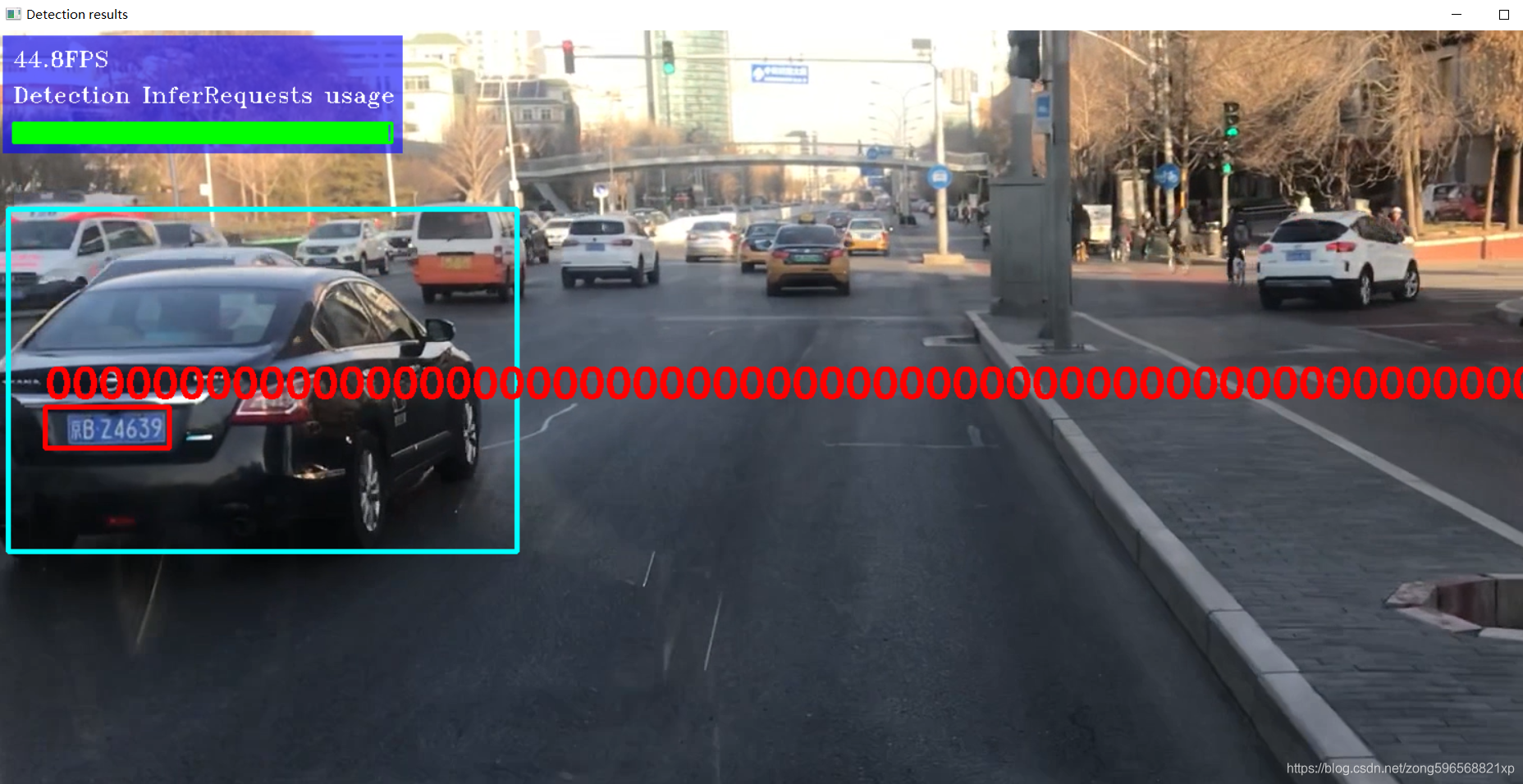
结果如下,车牌识别结果有问题,还需要进一步排查
4 总结
本文对 openvino 调用 public 预训练模型的方法进行了介绍,与 intel 预训练模型相比,主要区别在于需要一次格式转换,目前支持的转化类型包括以下几种:
- Caffe,
- TensorFlow,
- MXNet,
- ONNX,
- Kaldi.
后续会进行更加深入的研究