基于深度学习的手部21类关键点检测
基于深度学习的人体关键点检测
开发环境
* Python 3.7
* PyTorch >= 1.5.1
* opencv-python
数据源
- 普通USB彩色(RGB)网络摄像头
- 已经存储下来的视频或者图片
数据集
本项目数据集百度网盘下载地址:下载地址
该数据集包括网络图片及数据集<<Large-scale Multiview 3D Hand Pose Dataset>>筛选动作重复度低的部分图片,进行制作(如有侵权请联系删除),共49062个样本。
<<Large-scale Multiview 3D Hand Pose Dataset>>数据集,其官网地址 http://www.rovit.ua.es/dataset/mhpdataset/
感谢《Large-scale Multiview 3D Hand Pose Dataset》数据集贡献者:Francisco Gomez-Donoso, Sergio Orts-Escolano, and Miguel Cazorla. “Large-scale Multiview 3D Hand Pose Dataset”. ArXiv e-prints 1707.03742, July 2017.
本项目训练测试数据集、训练测试代码和演示demo
打包下载地址:下载地址
本项目demo


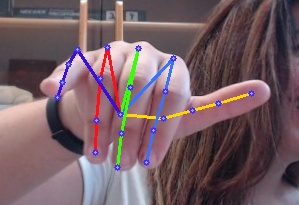
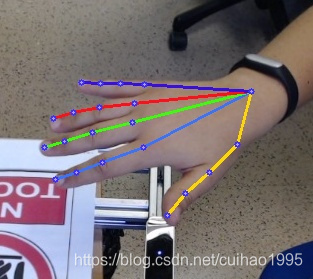
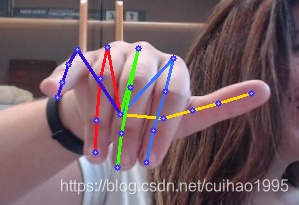

目前支持的模型 (backbone)
- resnet18 & resnet34 & resnet50 & resnet101
- squeezenet1_0 & squeezenet1_1
- ShuffleNet & ShuffleNetV2
- MobileNetV2
- rexnetv1
- shufflenet_v2_x1_5 ,shufflenet_v2_x1_0 , shufflenet_v2_x2_0 (torchvision 版本)
预训练模型
- 预训练模型:代码下载地址中,见文件夹W
模型训练
- 运行命令: python train.py
#-*-coding:utf-8-*-
import os
import argparse
import torch
import torch.nn as nn
import torch.optim as optim
import sys
from utils.model_utils import *
from utils.common_utils import *
from hand_data_iter.datasets import *
from models.resnet import resnet18,resnet34,resnet50,resnet101
from models.squeezenet import squeezenet1_1,squeezenet1_0
from models.shufflenetv2 import ShuffleNetV2
from models.shufflenet import ShuffleNet
from models.mobilenetv2 import MobileNetV2
from models.rexnetv1 import ReXNetV1
from torchvision.models import shufflenet_v2_x1_5 ,shufflenet_v2_x1_0 , shufflenet_v2_x2_0
from loss.loss import *
import cv2
import time
import json
from datetime import datetime
import random
def trainer(ops,f_log):
try:
os.environ['CUDA_VISIBLE_DEVICES'] = ops.GPUS
if ops.log_flag:
sys.stdout = f_log
set_seed(ops.seed)
#---------------------------------------------------------------- 构建模型
if ops.model == 'resnet_50':
model_ = resnet50(pretrained = True,num_classes = ops.num_classes,img_size = ops.img_size[0],dropout_factor=ops.dropout)
elif ops.model == 'resnet_18':
model_ = resnet18(pretrained = True,num_classes = ops.num_classes,img_size = ops.img_size[0],dropout_factor=ops.dropout)
elif ops.model == 'resnet_34':
model_ = resnet34(pretrained = True,num_classes = ops.num_classes,img_size = ops.img_size[0],dropout_factor=ops.dropout)
elif ops.model == 'resnet_101':
model_ = resnet101(pretrained = True,num_classes = ops.num_classes,img_size = ops.img_size[0],dropout_factor=ops.dropout)
elif ops.model == "squeezenet1_0":
model_ = squeezenet1_0(pretrained=True, num_classes=ops.num_classes,dropout_factor=ops.dropout)
elif ops.model == "squeezenet1_1":
model_ = squeezenet1_1(pretrained=True, num_classes=ops.num_classes,dropout_factor=ops.dropout)
elif ops.model == "shufflenetv2":
model_ = ShuffleNetV2(ratio=1., num_classes=ops.num_classes, dropout_factor=ops.dropout)
elif ops.model == "shufflenet_v2_x1_5":
model_ = shufflenet_v2_x1_5(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet_v2_x1_0":
model_ = shufflenet_v2_x1_0(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet_v2_x2_0":
model_ = shufflenet_v2_x2_0(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet":
model_ = ShuffleNet(num_blocks = [2,4,2], num_classes=ops.num_classes, groups=3, dropout_factor = ops.dropout)
elif ops.model == "mobilenetv2":
model_ = MobileNetV2(num_classes=ops.num_classes , dropout_factor = ops.dropout)
elif ops.model == "ReXNetV1":
model_ = ReXNetV1(num_classes=ops.num_classes , width_mult=0.9, depth_mult=1.0, dropout_factor = ops.dropout)
else:
print(" no support the model")
use_cuda = torch.cuda.is_available()
device = torch.device("cuda:0" if use_cuda else "cpu")
model_ = model_.to(device)
# print(model_)# 打印模型结构
# Dataset
dataset = LoadImagesAndLabels(ops= ops,img_size=ops.img_size,flag_agu=ops.flag_agu,fix_res = ops.fix_res,vis = False)
print("handpose done")
print('len train datasets : %s'%(dataset.__len__()))
# Dataloader
dataloader = DataLoader(dataset,
batch_size=ops.batch_size,
num_workers=ops.num_workers,
shuffle=True,
pin_memory=False,
drop_last = True)
# 优化器设计
optimizer_Adam = torch.optim.Adam(model_.parameters(), lr=ops.init_lr, betas=(0.9, 0.99),weight_decay=1e-6)
# optimizer_SGD = optim.SGD(model_.parameters(), lr=ops.init_lr, momentum=ops.momentum, weight_decay=ops.weight_decay)# 优化器初始化
optimizer = optimizer_Adam
# 加载 finetune 模型
if os.access(ops.fintune_model,os.F_OK):# checkpoint
chkpt = torch.load(ops.fintune_model, map_location=device)
model_.load_state_dict(chkpt)
print('load fintune model : {}'.format(ops.fintune_model))
print('/**********************************************/')
# 损失函数
if ops.loss_define == 'mse_loss':
criterion = nn.MSELoss(reduce=True, reduction='mean')
elif ops.loss_define == 'adaptive_wing_loss':
criterion = AdaptiveWingLoss()
step = 0
idx = 0
# 变量初始化
best_loss = np.inf
loss_mean = 0. # 损失均值
loss_idx = 0. # 损失计算计数器
flag_change_lr_cnt = 0 # 学习率更新计数器
init_lr = ops.init_lr # 学习率
epochs_loss_dict = {}
for epoch in range(0, ops.epochs):
if ops.log_flag:
sys.stdout = f_log
print('\nepoch %d ------>>>'%epoch)
model_.train()
# 学习率更新策略
if loss_mean!=0.:
if best_loss > (loss_mean/loss_idx):
flag_change_lr_cnt = 0
best_loss = (loss_mean/loss_idx)
else:
flag_change_lr_cnt += 1
if flag_change_lr_cnt > 50:
init_lr = init_lr*ops.lr_decay
set_learning_rate(optimizer, init_lr)
flag_change_lr_cnt = 0
loss_mean = 0. # 损失均值
loss_idx = 0. # 损失计算计数器
for i, (imgs_, pts_) in enumerate(dataloader):
# print('imgs_, pts_',imgs_.size(), pts_.size())
if use_cuda:
imgs_ = imgs_.cuda() # pytorch 的 数据输入格式 : (batch, channel, height, width)
pts_ = pts_.cuda()
output = model_(imgs_.float())
if ops.loss_define == 'wing_loss':
loss = got_total_wing_loss(output, pts_.float())
else:
loss = criterion(output, pts_.float())
loss_mean += loss.item()
loss_idx += 1.
if i%10 == 0:
loc_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print(' %s - %s - epoch [%s/%s] (%s/%s):'%(loc_time,ops.model,epoch,ops.epochs,i,int(dataset.__len__()/ops.batch_size)),\
'Mean Loss : %.6f - Loss: %.6f'%(loss_mean/loss_idx,loss.item()),\
' lr : %.8f'%init_lr,' bs :',ops.batch_size,\
' img_size: %s x %s'%(ops.img_size[0],ops.img_size[1]),' best_loss: %.6f'%best_loss, " {}".format(ops.loss_define))
# 计算梯度
loss.backward()
# 优化器对模型参数更新
optimizer.step()
# 优化器梯度清零
optimizer.zero_grad()
step += 1
#set_seed(random.randint(0,65535))
torch.save(model_.state_dict(), ops.model_exp + '{}-size-{}-loss-{}-model_epoch-{}.pth'.format(ops.model,ops.img_size[0],ops.loss_define,epoch))
except Exception as e:
print('Exception : ',e) # 打印异常
print('Exception file : ', e.__traceback__.tb_frame.f_globals['__file__'])# 发生异常所在的文件
print('Exception line : ', e.__traceback__.tb_lineno)# 发生异常所在的行数
if __name__ == "__main__":
parser = argparse.ArgumentParser(description=' Project Hand Train')
parser.add_argument('--seed', type=int, default = 126673,
help = 'seed') # 设置随机种子
parser.add_argument('--model_exp', type=str, default = './model_exp',
help = 'model_exp') # 模型输出文件夹
parser.add_argument('--model', type=str, default = 'shufflenet_v2_x2_0',
help = '''model : resnet_34,resnet_50,resnet_101,squeezenet1_0,squeezenet1_1,shufflenetv2,shufflenet,mobilenetv2
shufflenet_v2_x1_5 ,shufflenet_v2_x1_0 , shufflenet_v2_x2_0,ReXNetV1''') # 模型类型
parser.add_argument('--num_classes', type=int , default = 42,
help = 'num_classes') # landmarks 个数*2
parser.add_argument('--GPUS', type=str, default = '0',
help = 'GPUS') # GPU选择
parser.add_argument('--train_path', type=str,
default = "./handpose_datasets_v1/",
help = 'datasets')# 训练集标注信息
parser.add_argument('--pretrained', type=bool, default = True,
help = 'imageNet_Pretrain') # 初始化学习率
parser.add_argument('--fintune_model', type=str, default = 'None',
help = 'fintune_model') # fintune model
parser.add_argument('--loss_define', type=str, default = 'adaptive_wing_loss',
help = 'define_loss : wing_loss, mse_loss ,adaptive_wing_loss') # 损失函数定义
parser.add_argument('--init_lr', type=float, default = 1e-3,
help = 'init learning Rate') # 初始化学习率
parser.add_argument('--lr_decay', type=float, default = 0.1,
help = 'learningRate_decay') # 学习率权重衰减率
parser.add_argument('--weight_decay', type=float, default = 1e-6,
help = 'weight_decay') # 优化器正则损失权重
parser.add_argument('--momentum', type=float, default = 0.9,
help = 'momentum') # 优化器动量
parser.add_argument('--batch_size', type=int, default = 16,
help = 'batch_size') # 训练每批次图像数量
parser.add_argument('--dropout', type=float, default = 0.5,
help = 'dropout') # dropout
parser.add_argument('--epochs', type=int, default = 3000,
help = 'epochs') # 训练周期
parser.add_argument('--num_workers', type=int, default = 10,
help = 'num_workers') # 训练数据生成器线程数
parser.add_argument('--img_size', type=tuple , default = (256,256),
help = 'img_size') # 输入模型图片尺寸
parser.add_argument('--flag_agu', type=bool , default = True,
help = 'data_augmentation') # 训练数据生成器是否进行数据扩增
parser.add_argument('--fix_res', type=bool , default = False,
help = 'fix_resolution') # 输入模型样本图片是否保证图像分辨率的长宽比
parser.add_argument('--clear_model_exp', type=bool, default = False,
help = 'clear_model_exp') # 模型输出文件夹是否进行清除
parser.add_argument('--log_flag', type=bool, default = False,
help = 'log flag') # 是否保存训练 log
#--------------------------------------------------------------------------
args = parser.parse_args()# 解析添加参数
#--------------------------------------------------------------------------
mkdir_(args.model_exp, flag_rm=args.clear_model_exp)
loc_time = time.localtime()
args.model_exp = args.model_exp + '/' + time.strftime("%Y-%m-%d_%H-%M-%S", loc_time)+'/'
mkdir_(args.model_exp, flag_rm=args.clear_model_exp)
f_log = None
if args.log_flag:
f_log = open(args.model_exp+'/train_{}.log'.format(time.strftime("%Y-%m-%d_%H-%M-%S",loc_time)), 'a+')
sys.stdout = f_log
print('---------------------------------- log : {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", loc_time)))
print('\n/******************* {} ******************/\n'.format(parser.description))
unparsed = vars(args) # parse_args()方法的返回值为namespace,用vars()内建函数化为字典
for key in unparsed.keys():
print('{} : {}'.format(key,unparsed[key]))
unparsed['time'] = time.strftime("%Y-%m-%d %H:%M:%S", loc_time)
fs = open(args.model_exp+'train_ops.json',"w",encoding='utf-8')
json.dump(unparsed,fs,ensure_ascii=False,indent = 1)
fs.close()
trainer(ops = args,f_log = f_log)# 模型训练
if args.log_flag:
sys.stdout = f_log
print('well done : {}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())))
模型推理
- 运行命令: python inference.py
#-*-coding:utf-8-*-
import os
import argparse
import torch
import torch.nn as nn
import numpy as np
import time
import datetime
import os
import math
from datetime import datetime
import cv2
import torch.nn.functional as F
from models.resnet import resnet18,resnet34,resnet50,resnet101
from models.squeezenet import squeezenet1_1,squeezenet1_0
from models.shufflenetv2 import ShuffleNetV2
from models.shufflenet import ShuffleNet
from models.mobilenetv2 import MobileNetV2
from torchvision.models import shufflenet_v2_x1_5 ,shufflenet_v2_x1_0 , shufflenet_v2_x2_0
from models.rexnetv1 import ReXNetV1
from utils.common_utils import *
import copy
from hand_data_iter.datasets import draw_bd_handpose
if __name__ == "__main__":
parser = argparse.ArgumentParser(description=' Project Hand Pose Inference')
parser.add_argument('--model_path', type=str, default = './w/resnet50_2021-418.pth',
help = 'model_path') # 模型路径
parser.add_argument('--model', type=str, default = 'resnet_50',
help = '''model : resnet_34,resnet_50,resnet_101,squeezenet1_0,squeezenet1_1,shufflenetv2,shufflenet,mobilenetv2
shufflenet_v2_x1_5 ,shufflenet_v2_x1_0 , shufflenet_v2_x2_0,ReXNetV1''') # 模型类型
parser.add_argument('--num_classes', type=int , default = 42,
help = 'num_classes') # 手部21关键点, (x,y)*2 = 42
parser.add_argument('--GPUS', type=str, default = '0',
help = 'GPUS') # GPU选择
parser.add_argument('--test_path', type=str, default = './image/',
help = 'test_path') # 测试图片路径
parser.add_argument('--img_size', type=tuple , default = (256,256),
help = 'img_size') # 输入模型图片尺寸
parser.add_argument('--vis', type=bool , default = True,
help = 'vis') # 是否可视化图片
print('\n/******************* {} ******************/\n'.format(parser.description))
#--------------------------------------------------------------------------
ops = parser.parse_args()# 解析添加参数
#--------------------------------------------------------------------------
print('----------------------------------')
unparsed = vars(ops) # parse_args()方法的返回值为namespace,用vars()内建函数化为字典
for key in unparsed.keys():
print('{} : {}'.format(key,unparsed[key]))
#---------------------------------------------------------------------------
os.environ['CUDA_VISIBLE_DEVICES'] = ops.GPUS
test_path = ops.test_path # 测试图片文件夹路径
#---------------------------------------------------------------- 构建模型
print('use model : %s'%(ops.model))
if ops.model == 'resnet_50':
model_ = resnet50(num_classes = ops.num_classes,img_size=ops.img_size[0])
elif ops.model == 'resnet_18':
model_ = resnet18(num_classes = ops.num_classes,img_size=ops.img_size[0])
elif ops.model == 'resnet_34':
model_ = resnet34(num_classes = ops.num_classes,img_size=ops.img_size[0])
elif ops.model == 'resnet_101':
model_ = resnet101(num_classes = ops.num_classes,img_size=ops.img_size[0])
elif ops.model == "squeezenet1_0":
model_ = squeezenet1_0(num_classes=ops.num_classes)
elif ops.model == "squeezenet1_1":
model_ = squeezenet1_1(num_classes=ops.num_classes)
elif ops.model == "shufflenetv2":
model_ = ShuffleNetV2(ratio=1., num_classes=ops.num_classes)
elif ops.model == "shufflenet_v2_x1_5":
model_ = shufflenet_v2_x1_5(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet_v2_x1_0":
model_ = shufflenet_v2_x1_0(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet_v2_x2_0":
model_ = shufflenet_v2_x2_0(pretrained=False,num_classes=ops.num_classes)
elif ops.model == "shufflenet":
model_ = ShuffleNet(num_blocks = [2,4,2], num_classes=ops.num_classes, groups=3)
elif ops.model == "mobilenetv2":
model_ = MobileNetV2(num_classes=ops.num_classes)
elif ops.model == "ReXNetV1":
model_ = ReXNetV1( width_mult=1.0, depth_mult=1.0, num_classes=ops.num_classes)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda:0" if use_cuda else "cpu")
model_ = model_.to(device)
model_.eval() # 设置为前向推断模式
# print(model_)# 打印模型结构
# 加载测试模型
if os.access(ops.model_path,os.F_OK):# checkpoint
chkpt = torch.load(ops.model_path, map_location=device)
model_.load_state_dict(chkpt)
print('load test model : {}'.format(ops.model_path))
#---------------------------------------------------------------- 预测图片
'''建议 检测手bbox后,crop手图片的预处理方式:
# img 为原图
x_min,y_min,x_max,y_max,score = bbox
w_ = max(abs(x_max-x_min),abs(y_max-y_min))
w_ = w_*1.1
x_mid = (x_max+x_min)/2
y_mid = (y_max+y_min)/2
x1,y1,x2,y2 = int(x_mid-w_/2),int(y_mid-w_/2),int(x_mid+w_/2),int(y_mid+w_/2)
x1 = np.clip(x1,0,img.shape[1]-1)
x2 = np.clip(x2,0,img.shape[1]-1)
y1 = np.clip(y1,0,img.shape[0]-1)
y2 = np.clip(y2,0,img.shape[0]-1)
'''
with torch.no_grad():
idx = 0
for file in os.listdir(ops.test_path):
if '.jpg' not in file:
continue
idx += 1
print('{}) image : {}'.format(idx,file))
img = cv2.imread(ops.test_path + file)
img_width = img.shape[1]
img_height = img.shape[0]
# 输入图片预处理
img_ = cv2.resize(img, (ops.img_size[1],ops.img_size[0]), interpolation = cv2.INTER_CUBIC)
img_ = img_.astype(np.float32)
img_ = (img_-128.)/256.
img_ = img_.transpose(2, 0, 1)
img_ = torch.from_numpy(img_)
img_ = img_.unsqueeze_(0)
if use_cuda:
img_ = img_.cuda() # (bs, 3, h, w)
pre_ = model_(img_.float()) # 模型推理
output = pre_.cpu().detach().numpy()
output = np.squeeze(output)
pts_hand = {} #构建关键点连线可视化结构
for i in range(int(output.shape[0]/2)):
x = (output[i*2+0]*float(img_width))
y = (output[i*2+1]*float(img_height))
pts_hand[str(i)] = {}
pts_hand[str(i)] = {
"x":x,
"y":y,
}
draw_bd_handpose(img,pts_hand,0,0) # 绘制关键点连线
#------------- 绘制关键点
for i in range(int(output.shape[0]/2)):
x = (output[i*2+0]*float(img_width))
y = (output[i*2+1]*float(img_height))
cv2.circle(img, (int(x),int(y)), 3, (255,50,60),-1)
cv2.circle(img, (int(x),int(y)), 1, (255,150,180),-1)
if ops.vis:
cv2.namedWindow('image',0)
cv2.imshow('image',img)
cv2.imwrite(file, img)
if cv2.waitKey(600) == 27 :
break
cv2.destroyAllWindows()
print('well done ')