
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry”
绪论:
本章将写到一些手搓常用工具,方便在项目中的使用,并且在手搓的过程中一些函数如:日志 宏中的__VA_ARGS__接收可变参、SQLlit数据库的C语言接口、Split中string的使用,以及UUID中随机数的生成和数据范围的限制,全文10000字包含实现细节 和 源码 开始学习吧。后续还将持续更新,敬请期待!
————————
早关注不迷路,话不多说安全带系好,发车啦(建议电脑观看)。
1. 日志打印工具
创建命名空间 mq;在mqdemo下创建log/log.cpp
封装一个日志的宏,通过这个宏打印,带上
时间-文件名-行号[12:21:22][文件名:行号]打开失败文件名的宏:FILE、行号的宏:LINE获取时间的函数 :
头文件:#include <time.h>size_t strftime(char *s, size_t max, const char *format, const struct tm *tm);参数:1. s:输出型参数,最终返回的时间放在此处2. maxsize:最大的长度3. format:时间格式(年月日 时分秒结构:"%H%M%S")4. tm:当前的时间结构localtime:一般要配合localtime函数来生成tm结构体(该结构体事用于生成所需的时间结构的结构体)struct tm *localtime(const time_t *timep);struct tm { int tm_sec; /* seconds */ int tm_min; /* minutes */ int tm_hour; /* hours */ int tm_mday; /* day of the month */ int tm_mon; /* month */ int tm_year; /* year */ int tm_wday; /* day of the week */ int tm_yday; /* day in the year */ int tm_isdst; /* daylight saving time */};其中localtime还需配合time函数头文件:#include <time.h>time_t time(time_t *t);得到time_t 的变量,当成localtime函数的参数,最终返回获取tm结构体实现流程:
获取time_t当前系统时间获取tm系统时间结构创建一个存放数据的缓冲区(第一个参数s)使用strftime函数进行获取格式化时间打印查看(Debug)定义宏 日志等级宏:DBG_LEVEL 0INF_LEVEL 1ERR_LEVEL 2DEFAULT_LEVEL DBG_LEVEL LOG宏 参数: 等级format要打印的内容类型可变参 (作用配合format实现类似于print:"%s","666"的打印) 判断只有大于等于 DEFAULT_LEVEL 才进行将之前写的 1 ~ 5 在LOG宏后面用括号包起来,并且用 \ 连接(\:作用是将末尾默认的换行去掉,确保宏是在同一行的!!!)打印时间([时间][文件:行号] format) 其中注意的是format可能有参数,对于可变参数来说,使用宏:##__VA_ARGS__来获取外部的变量(其中__VA_ARGS__是format附加的参数,而==##的作用是防止没有参数时报错==!)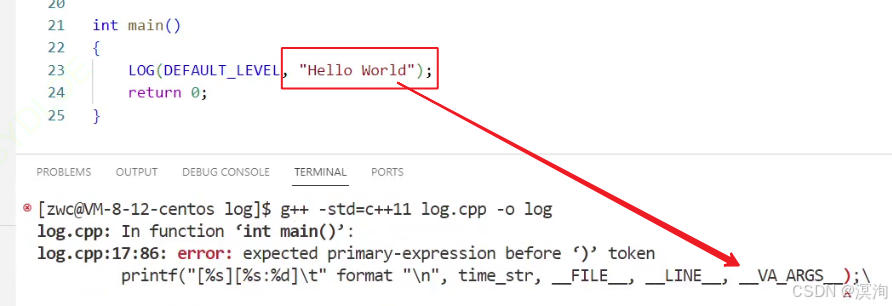 其中在打印" “内部添加变量:用空格空开然后添加变量,后继续使用”"往后继续写
其中在打印" “内部添加变量:用空格空开然后添加变量,后继续使用”"往后继续写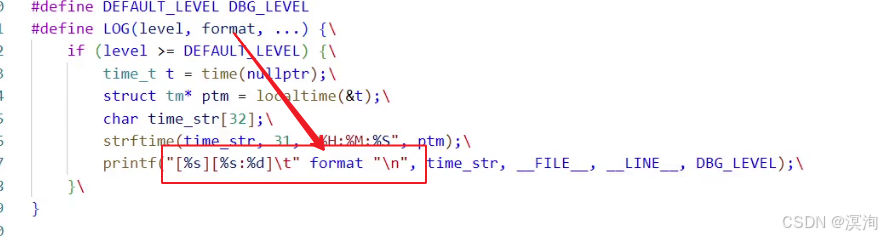
修改:
再LOG宏参数内部添加第一个参数lev_str,表示要传入的日志的等级,并且打印出来(同步也要修改下面)
再定义三种日志打印宏来真正给外部用户使用:
DLOG:内部调用LOG("DEBUG","DBG_LEVEL",format,##__VA_ARGS__ )LOGE:…ELOG:… 项目操作(仿MQ)
最后将写好的日志工具放进mqcommon中logger.hpp
添加条件变量:
1.#ifndef __M_LOG_H__
2. #define __M_LOG_H__
3. #endif
日志源码
#include <iostream>#include <ctime>using namespace std;#define DBG_LEVEL 0#define INF_LEVEL 1#define ERR_LEVEL 2#define DEFAULT_LEVEL DBG_LEVEL#define LOG(level_str,level,format, ...){\ if(level >= DEFAULT_LEVEL){\ time_t t = time(nullptr);\ struct tm* tm = localtime(&t);\ char s[1024];\ size_t size = strftime(s,1023,"%H:%M:%S",tm);\ printf("[%s][%s][%s:%d]\t" format "\n",level_str,s,__FILE__,__LINE__,##__VA_ARGS__);\ }\}\#define DLOG(format, ...) LOG("DEBUG",DBG_LEVEL,format, ##__VA_ARGS__)#define ILOG(format, ...) LOG("INFO",INF_LEVEL,format, ##__VA_ARGS__ )#define ELOG(format, ...) LOG("ERROR",ERR_LEVEL,format, ##__VA_ARGS__ )// int main()// {// // time_t t = time(nullptr);//获取系统时间// // //为localtime创建变量// // struct tm* tm = localtime(&t);//得到tm结构体// // char s[1024];// // //生成格式化时间:使用strftime// // size_t size = strftime(s,1023,"%H:%M:%S",tm);//“%H%M%S” 小时:分钟:秒,存放到s中 // // printf("[%s][%s:%d]\n",s,__FILE__,__LINE__);//[时间][文件:行数]// DLOG("DEBUG%s","aaa");// ILOG("INFO%s","aaa");// ELOG("ERROR%s","aaa"); // return 0;// }2. SQLite数据库
将之间写好的sqlit代码拷贝过来(见blog)并且带上条件变量(具体看该(blog)[])
#ifndef __M_HELPER_H__#define __M_HELPER_H__#endif将内部的打印改成日志模式。
SQLite数据库源码:
#include <iostream>#include <string>#include <sqlite3.h>#include <vector>#include <cassert>#include "loger.hpp"class SqliteHelper{typedef int (*SqliteCallback)(void*,int,char**,char**);public: SqliteHelper(const std::string& dbfile):_dbfile(dbfile),_handler(nullptr){}//int sqlite3_open_v2(const char *filename, sqlite3 **ppDb, int flags, const char *zVfs );bool open(int safe_leve = SQLITE_OPEN_FULLMUTEX)//SQLITE_OPEN_FULLMUTEX默认就为串行化模式{ int ret = sqlite3_open_v2(_dbfile.c_str(),&_handler,safe_leve | SQLITE_OPEN_CREATE | SQLITE_OPEN_READWRITE,nullptr); //第一个参数是db文件路径 //第二个参数是一个输出型变量,我们将sqlite的句柄传进去,获取open后db的句柄 //第三个参数是文件打开的默认权限和方式 和 线程的安全等级 //SQLITE_OPEN_CREATE: 不存在数据库⽂件则创建 // SQLITE_OPEN_READWRITE -- 以可读可写⽅式打开数据库⽂件 //第四个参数设为空即可 if(ret != SQLITE_OK) { ELOG( "创建/打开sqlite数据库失败:%s",sqlite3_errmsg(_handler)); return false; } else{ DLOG("打开成功"); return true; }}//提前设置 SqliteCallback == int (*SqliteCallback)(void*,int,char**,char**)回调函数bool exec(const std::string& sql,SqliteCallback cb,void* arg){ int ret = sqlite3_exec(_handler,sql.c_str(),cb,arg,nullptr); // if(ret != SQLITE_OK) { std::cout << sql << std::endl; ELOG( "执行失败、查看错误信息: %s",sqlite3_errmsg(_handler)); return false; } else{ DLOG ("执行成功"); return true; }}bool close(){ sqlite3_close_v2(_handler);// return true;}private: std::string _dbfile; sqlite3 * _handler;};3. Split字符串工具类
项目操作(仿MQ)
在demo中创建split.cpp
size_t split 函数
参数:
分隔思想:
从0位置开始查找指定字符的位置,找到后进行分隔从上次查找的位置后继续向后查找 指定字符 重复上述 过程 pos查找到的当前字符串分隔符的位置、idx当前字符串的首字符位置遍历字符串,使用find查找分隔符,给到pos判断是否结束 (若找不到pos == string::npos(结尾))没找到(表示直接结尾了):直接使用substr截取到末尾,返回result的数量那么就是从idx开始,到pos - idx的长度截取(string::substr) 但注意分割符 连接起来时的情况(如以.为分隔符时字符串为:ab...c):此时find查找到的 pos == idx此时事没数据的就不用截取了 那么就直接:将 idx赋值为分隔符加上pos(跳到下一个要分割的字符串),然后直接continue循环。 将idx赋值为分隔符加上pos(跳到下一个要分割的字符串) 测试方法:
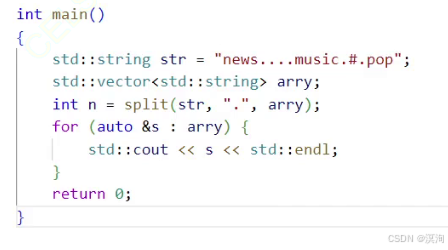
注意:
stiring::find的使用(sep,pos)
sep要找的字符串pos开始的位置项目操作(仿MQ)
测试完成后:
创建StrHelper类
将spilt函数拷贝进去(改静态)
字符串分割工具源码:
#include <iostream>#include <vector>/** * 返回分隔后字符串的个数 * * str:要分割的字符串 * sep:分隔符 * result:结果 */size_t split(const std::string& str,const std::string& sep,std::vector<std::string>& result){ //将str 通过 sep 分隔 //将结果全部存放到 result int pos = 0 , idx = 0;//pos表示要分割的字符串的首位置,idx表示分隔符的下标 while(idx <= str.size()){ idx = str.find(sep,pos); if(idx == std::string::npos){ //如果找不到就表示不需要分隔 std::string tmp_str = str.substr(pos); std::cout << tmp_str << std::endl; result.push_back(tmp_str);//不写len,直接将所有都获取了 return result.size(); } //需要将出现连续分隔符的情况进行 特殊处理: news....music.#.pop 此处就 . 为分割符 就会出现连续的问题,而出现连续的时候,会截取到空字符串,就没必要 if(pos == idx)//当出现连续时 pos 会等于 idx { pos = idx + sep.length();//注意也需要往前走哈 continue; } std::string tmp_str = str.substr(pos,idx - pos); std::cout << tmp_str << std::endl; result.push_back(tmp_str);//len = idx - pos pos = idx + sep.length();// } return result.size();}int main(){ std::vector<std::string> res; std::cout << split("news....music.#.pop",".",res) << std::endl; // for(auto& s : res){ // std::cout << s << std::endl; // } return 0;}4. UUID唯一标识生成器
UUID(Universally Unique Identifier), 也叫通⽤唯⼀识别码,通常由32位16进制数字字符组成。
(不用自增的数字做唯一标识码:因为有可能会越界重复的)
UUID的标准型式包含32个16进制数字字符(两位的十六进制数 最大 刚好为 = 1字节 = 255),以连字号分为五段,形式为8-4-4-4-12的32个字符,如:550e8400-e29b-41d4-a716-446655440000
在这⾥,uuid⽣成,我们采⽤
生成思想:
生成8个0~255之间的随机数(到255的意思就是生成1字节,那么8个就是8字节)加上一个8字节的序号通过以上数据,组成16字节的数据,转换为16进制字符,共32位4.1 生成机器随机数类:random_device
头文件:#include < random >
学习使用:
//生成random_device类对象std::random_device rd;//生成一个机器随机数(效率较低)//直接通过对象rd()仿函数生成机器随机数num = rd();4.2 生成伪随机数类:mt19937_64
梅森旋转算法,效率就比机器随机数高许多
使用方法:
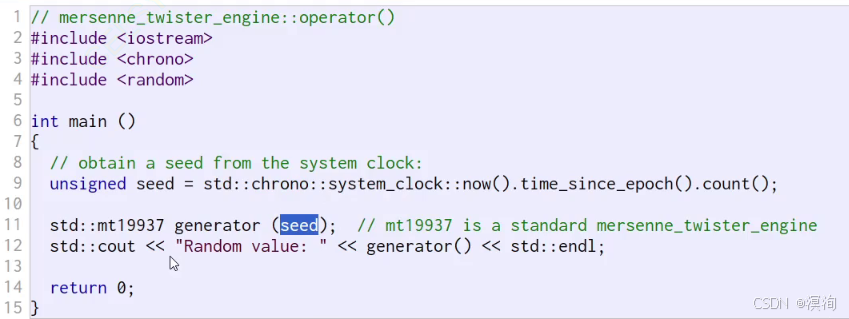
1. 构造时给到随机数种子:seed
2. 此处:结合random_device机器随机数生成种子、给到 mt19937_64 使用 生成对象gernator
3. 再通过gernator仿函数直接生成随机数。
具体如下图
4.3 限制数据范围uniform_nit_distribution类
1. 生成uniform_int_distribution类对象,构造时设置限制范围:0 ~ 255std::uniform_int_distribution<int> (0,255);2. 要限制的数丢进仿函数中:将伪随机数放进去distribution(gernator);//对gernator对象丢仿函数中进行范围的限制//同样是使用了仿函数实操如下图:


4.4 学习使用stringstream类生成16进制的数字字符
头文件:include< sstream >
//头文件:include <sstream>stringstream ss;ss << std::setw(2) << std::setfill('0') << std::hex << distribution(gernator);1. setw设置宽度:头文件:iomanip2. fill填充,这样就能防止原本数字小于16时打印个位字符的情况,如:7 -》 073. hex:设置为十六进制std::cout << ss.str() << std::endl;这样就将1byte随机数变成了两位的16进制(再次重复:两位的16进制数最大 就刚好为1byte (ee = 15 + 15 * 161 = 255),所以将1字节的随机数变成两位的十六进制数)
实现唯一标识UUID源码:
项目操作(仿MQ)
demo/random 目录 random.cpp,创建函数random
目的:生成8-4-4-4-12结构的32个十六进制数字字符(16byte)
先生成前面8byte的随机数:8-4-4(刚好16位16进制数) ,再生成后8byte的序号:4-12
现在需要生成前8个,有了上面的基础
使用伪随机数 ms19937_64(对象的伪函数生成)伪随机数种子使用机器随机数 random_device (对象的伪函数生成)在将生成的随机数 变成 16进制,并且保留两位,且补充0那么就是循环8次,循环中设置条件当生成完第4、第6、第8个字符后打印-符号,这样就能生成前16位16进制数 8-4-4
具体如下代码:
#include <iostream>#include <string>#include <random>#include <chrono>#include <sstream>//输入输出流#include <iomanip>int main(){//创建机器随机数对象 std::random_device rd; std::mt19937_64 generator(rd());//rd()仿函数生成随机数种子 std::uniform_int_distribution<int> distri(0,255);//uniform_int_distribution是一个限制类 std::stringstream ss; //使用str打印 for(int i = 0; i < 8 ;i++){//循环8次生成前8byte ss << std::setw(2) << std::setfill('0') << std::hex <<distri(generator); if(i == 3 || i == 5 || i == 7){ ss << "-"; } //将生成的随机数丢给distri对象的仿函数中进行限制大小 } std:: cout << ss.str() << std::endl; return 0;}
再生成后16为序号数(4-12),其中是生成序号,所以需要保证其唯一性(所以在生成时需要使用原子类型,来实现原子性保证其不能出现重复的情况)
步骤如下:
使用类型 size_t = unsigned long = 8byte(64bit)
这样和前面的8-4-4拼接起来,就形成了:8-4-4-4-12的包含32个16进制数字字符, 最终所有代码合起来如下:
#include <iostream>#include <unistd.h>#include <stdlib.h>#include <string>#include <random>#include <chrono>#include <sstream>//输入输出流#include <iomanip>#include <atomic>int main(){//创建机器随机数对象 std::random_device rd; std::mt19937_64 generator(rd());//rd()仿函数生成随机数种子 std::uniform_int_distribution<int> distri(0,255);//uniform_int_distribution是一个限制类 std::stringstream ss; //使用str打印 for(int i = 0; i < 8 ;i++){//循环8次生成前8byte ss << std::setw(2) << std::setfill('0') << std::hex <<distri(generator); if(i == 3 || i == 5 || i == 7){ ss << "-"; } //将生成的随机数丢给distri对象的仿函数中进行限制大小 } //实现后8byte的序号 static std::atomic<size_t> seq(1);//初始值为1 //静态原子的保证每次 进来 在之前序号的基础上继续 size_t num = seq.fetch_add(1);//设置 自增长 //同样事在num上操作 //生成后面的 4 - 12,生成byte,16位十六进制 // for(int i = 0;i < 8;i++){ // ss << std::setw(2) << std::setfill('0') << std::hex << ((num >> (i*8)) & (0xff)); // //其中 (num >> (i*8) & (0xff)) 的作用是: // //首先:我们需要将num值每次取出8位,也就是1byte,也就是2位16进制(4位 = 1十六进制),所以每次移动8byte,其中我们拿第一个举例:移动i == 0 的 时候就是取前8为,当为1当时后,先右移1 * 8位,就能取到后面9 ~ 16 // // 然后 需要 按位与& 0xff,这里好理解,通过按位与操作,只取前8位 // if(i == 1 ){//分成 4 - 12 // ss << "-"; // } // } //上述写法虽然也ok,但是有点反人性(得到的序号是反过来的)不好看,解决也很简单我们就将循环遍历翻过来就哈 for(int i = 7;i >= 0;i--){ ss << std::setw(2) << std::setfill('0') << std::hex << ((num >> (i*8)) & (0xff)); //其中 (num >> (i*8) & (0xff)) 的作用是: //首先:我们需要将num值每次取出8位,也就是1byte,也就是2位16进制(4位 = 1十六进制),所以每次移动8byte,其中我们拿第一个举例:移动i == 0 的 时候就是取前8为,当为1当时后,先右移1 * 8位,就能取到后面9 ~ 16 // 然后 需要 按位与& 0xff,这里好理解,通过按位与操作,只取8位 if(i == 6){//分成 4 - 12 ss << "-"; } } std:: cout << ss.str() << std::endl; return 0;}最终生成了32位十六进制数值的UUID唯一标识(扩展:该唯一标识若想跨主机使用,该唯一标识就还有一定的可能出现冲突问题,此时我们能在UUID 数值中再加上该主机的MAC地址(该地址一定是每台主机单独的),这样就能一定的保证唯一性)

项目操作(仿MQ):
将上述函数摘出来,放进helper.hpp中,创建类:UUIDHelper,得到静态函数uuid()
本章完。预知后事如何,暂听下回分解。
如果有任何问题欢迎讨论哈!
如果觉得这篇文章对你有所帮助的话点点赞吧!
持续更新大量C++细致内容,早关注不迷路。