
客座博文 / Ido Gus,来自 CEVA
CEVA 是无线连接和智能传感技术的领先授权商。我们的产品可帮助原始设备制造商 (OEM) 为移动设备、消费者、汽车、机器人、工业和物联网等多种终端市场,设计节能、智能和联网的设备。
-
CEVA
https://www.ceva-dsp.com/
在本文中,我们将说明如何使用适用于微控制器的 TensorFlow Lite (TensorFlow Lite for Microcontrollers, TFLM),在基于 CEVA-BX DSP 内核的裸机开发板上部署名为 WhisPro 的语音识别引擎及前端。WhisPro 可在设备端有效识别随时出现的唤醒词和语音命令。
-
适用于微控制器的 TensorFlow Lite
https://tensorflow.google.cn/lite/microcontrollers

图 1 CEVA 多麦克风 DSP 开发板
WhisPro 简介
WhisPro 是语音识别引擎及前端,主要在低功耗、资源受限的边缘设备上运行,包含负责音频样本处理到检测的整个数据流。
WhisPro 支持两种边缘设备用例:
-
始终开启的唤醒词检测引擎。在此用例中,WhisPro 用于在检测到预定义的短语时唤醒处于睡眠模式下的设备。
-
语音指令。在此用例中,WhisPro 用于启用基于语音的接口。用户可以使用自己的声音来控制设备。常用指令有:调高音量、调低音量、播放、停止等。
WhisPro 可在集成了 CEVA BX DSP 内核的任何 SoC 上启用语音接口,从而为希望参与语音接口变革的 OEM 和原始设计制造商 (ODM) 降低了准入门槛。
我们的动机
最初,WhisPro 是使用名为 CEVA NN Lib 的内部神经网络库实现的。尽管该实现具有出色的性能,但是开发过程相当复杂。我们意识到,我们可以通过移植 TFLM 运行库,并针对目标硬件对其进行优化的方式,让整个模型移植过程将变得透明且更加可靠(大幅减少需要编写、修改和维护的代码量)。
为 CEVA-BX DSP 系列构建 TFLM
首先,我们需要弄清楚如何将 TFLM 移植到我们的平台上。我们发现,遵循《指南:移植到新平台》会非常有用。
-
指南:移植到新平台
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/docs/new_platform_support.md
在指南的指导下,我们执行了以下操作:
-
验证我们的平台支持 DebugLog() 实现。
-
在 CEVA 基于 Eclipse 的 IDE 中创建 TFLM 运行库项目:
-
在 CEVA 的 IDE 中创建新的 CEVA-BX 项目
-
-
将所有必需的源文件添加到项目中
-
为 CEVA-BX 内核构建 TFLM 运行库。
这需要对路径(并非所有必需文件都在“micro”目录下)、链接器脚本文件等编译器标记进行常规的调整。
-
DebugLog()
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/debug_log.cc
模型移植过程
我们将从模型中的 Keras 实现开始演示。以下是我们在裸机目标硬件上部署模型所采取的步骤:
使用 TF 内置转换器将 TensorFlow 模型转换为 TensorFlow Lite 模型:
$ python3 -m tensorflow_docs.tools.nbfmt [options] notebook.ipynb
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
converter.experimental_new_converter = True
tflite_model = converter.convert()
open("converted_to_tflite_model.tflite", "wb").write(tflite_model)
执行量化操作:
$ python3 -m tensorflow_docs.tools.nbfmt [options] notebook.ipynb
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.representative_dataset = representative_data_gen
使用 xxd 将 TensorFlow Lite 模型转换为 TFLM 模型:
$ python3 -m tensorflow_docs.tools.nbfmt [options] notebook.ipynb
$> xxd –I model.tflite > model.cc
-
TF 内置转换器
https://tensorflow.google.cn/lite/convert -
量化
https://tensorflow.google.cn/lite/performance/model_optimization#quantization -
xxd
https://linux.die.net/man/1/xxd
这里,我们发现TFLM(在当时)未能很好地支持模型的某些层(如GRU)。我们期待,随着 TFLM 的继续完善,以及 Google 和 TFLM 社区的持续投入,类似问题将大幅减少。
在我们的案例中,我们选择了相对容易的方式:在完全连接层方面重新实现GRU层。
集成
接下来是将 TFLM 运行库和转换后的模型集成到我们现有的嵌入式 C 前端。该前端将处理音频预处理和特征提取操作。
即使我们的前端在编写时并未考虑 TFLM,但因其有较高的模块化程度,可通过实现单个简单的封装容器函数来轻松完成集成,具体步骤如下:
-
将 TFLM 运行库链接到我们的嵌入式 C 应用(WhisPro 前端)
-
实现 wrapper-over-setup 函数,用于将模型映射到可用的数据结构中,以分配解释器和张量
-
实现 wrapper-over-execute 函数,用于将 WhisPro 前端传递的数据映射到实际执行函数使用的 tflite 张量
-
将对原始模型执行函数的调用替换为对 TFLM 实现的调用
过程可视化
模型的移植过程将由以下两者执行:
-
微控制器供应商(在本例中为 CEVA),负责为自身硬件架构优化 TFLM。
-
微控制器用户(在本例中为 CEVA WhisPro 开发者),负责使用优化的 TFLM 运行库在目标微控制器上部署基于神经网络的模型。
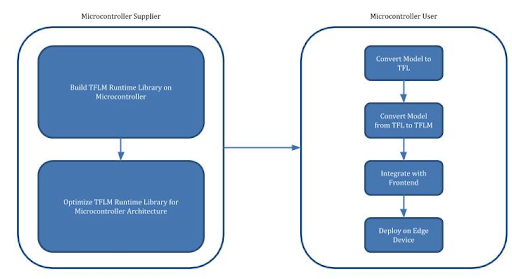
未来计划
此项研究已证实 TFLM 平台对我们非常重要。此外,通过支持 TFLM,我们可以在边缘设备上轻松部署神经网络模型,从而为我们的客户和合作伙伴带来更多的价值。我们致力于通过以下方式在 CEVA-BX DSP 系列上深化对 TFLM 的支持:
-
积极开发 TFLM 项目,以便提高层覆盖率和平台总体的成熟度。
-
对于在 CEVA-BX 内核上执行的 TFLM 运算符,加大对其的优化力度,以实现完整覆盖。
最终想法
尽管移植过程中遇到了一些困难,但我们最终还是取得了巨大的成功,整个项目耗时约 4 至 5 天。除此之外,从头开始用 C 语言实现模型,以及手动编写从 Python 到 C 的模型转换脚本还需要耗费 2 至 3 周的时间,并进行大量的调试工作。
CEVA 技术虚拟研讨会
如需了解更多信息,欢迎观看 CEVA 虚拟研讨会 - 无线音频会议,内容涵盖 TFLM 和其他主题。
-
CEVA 虚拟研讨会 - 无线音频会议
https://bit.ly/3koIVgm
想了解更多 TensorFlow Lite 案例,请扫描下方二维码,关注 TensorFlow 官方公众号,并回复 CSDN Lite。

同时,我们将邀请 TensorFlow Lite 工程师团队,坐客本周四(5 月 20 日)的社区说。届时,将会为大家带来 TensorFlow Lite 的最新进展、TensorFlow Lite 在 Android 上的案例分享,机会难得,快快点击下方链接,即刻报名参加。
-
腾讯会议
https://meeting.tencent.com/s/nmWpoMmBlPJs
会议 ID:526 876 125
-
Bilibili(B站)
http://live.bilibili.com/21170438