
list和我们之前讲的东西都一样,list第二个参数是一个空间配置器,是一个内存池, 底层是一个带头双向循环列表。list可以重载[],但是效率太低了。

list的遍历不能使用下标+[],因为它的空间不是连续的,可以使用迭代器,也可以使用范围for。
#include<iostream>
#include<list>
using namespace std;
int main()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
list<int>::iterator it = lt.begin();
while (it != lt.end())
{
cout << *it << " ";
it++;
}
cout << endl;
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
return 0;
}
1. list的介绍及使用
1.1 list的介绍
1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。
2. list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向其前一个元素和后一个元素。
3. list与forward_list非常相似:最主要的不同在于forward_list是单链表,只能朝前迭代,已让其更简单高效。
4. 与其他的序列式容器相比(array,vector,deque),list通常在任意位置进行插入、移除元素的执行效率 更好。
5. 与其他序列式容器相比,list和forward_list最大的缺陷是不支持任意位置的随机访问,比如:要访问list 的第6个元素,必须从已知的位置(比如头部或者尾部)迭代到该位置,在这段位置上迭代需要线性的时间 开销;list还需要一些额外的空间,以保存每个节点的相关联信息(对于存储类型较小元素的大list来说这 可能是一个重要的因素)
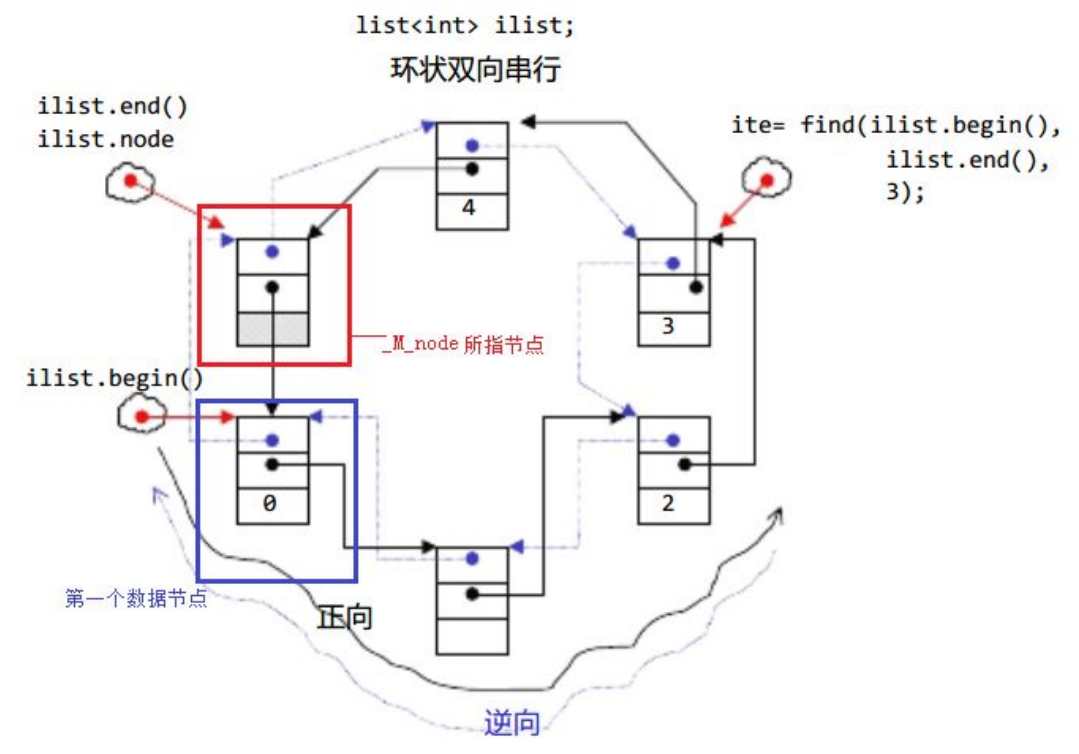
1.2 list的使用
list中的接口比较多,此处类似,只需要掌握如何正确的使用,然后再去深入研究背后的原理,已达到可扩展的能力。以下为list中一些常见的重要接口。list的头插和头删复杂度都为O(1)。
从string之后,position都变了,在string的部分都是用下标去插入,现在的位置都是迭代器,但是和vector还是有点区别的。比如下面的在第五个位置插入数据:
int main()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_front(10);
lt.push_front(20);
//如果要在第五个位置插入数据
//下面这种方法是不行的
//lt.insert(lt.begin() + 5, 10);
//因为vector是一个连续的物理空间,是支持+的,但是插入的代价比较大,数据要往后挪动。
//list和vector各有各的优缺点。
//list的物理空间不是连续的,可以支持+,但是代价比较大,库立面没有直接支持。
//只有一种方法
auto it = lt.begin();
for (size_t i = 0; i < 5; i++)
{
++it;
}
lt.insert(it, 100);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
return 0;
}
这是vector和list的第一个差别,这种差别是迭代器的差别导致的,list的插入代价是很低的,把前后位置的指向关系改变一下就可以了,排序都写到算法里面去了。
还有一种插入的场景,就是找到一个值,在它的前面插入一个数据。list和vector都没有提供find接口。
对于vector来说用小于没有问题,但对于list来讲,迭代器中end()节点的地址不一定比begin()大, end()的节点是有效数据的下一个位置,也就是哨兵位。
list中的insert接口不存在迭代器失效的问题,比如我要在这个位置插入接点,没有扩容的问题,没有野指针的问题,没有位置改变的问题,因为不需要挪动数据。vector在这个位置插入之前有两大问题,第一大问题就是扩容,第二大问题就是插入这个数据之后,位置往后挪,它的位置意义都变了。
erase节点存在迭代器失效的问题,因为节点都没了。

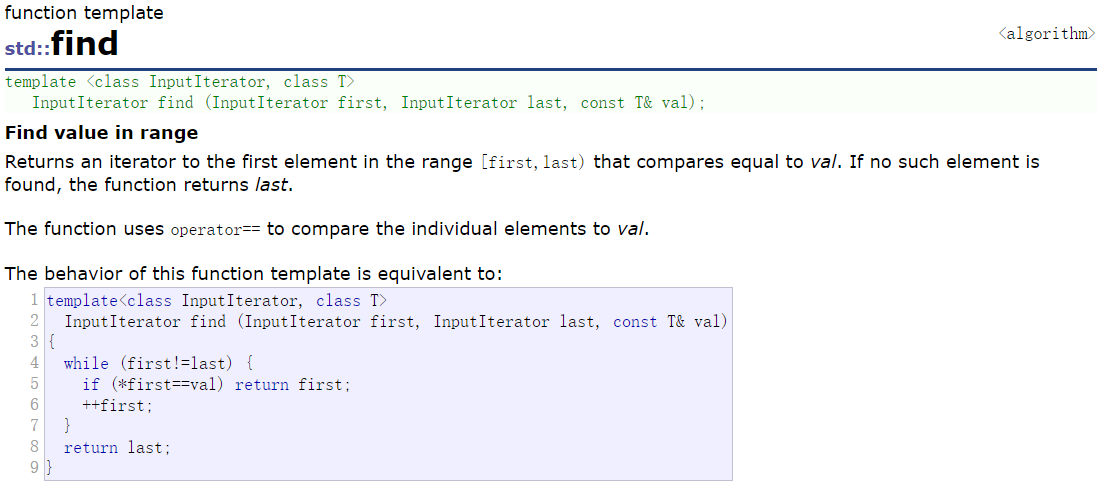
算法中的find,找到就返回这个节点,找不到就返回end节点。
int main()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_front(10);
lt.push_front(20);
auto it = lt.begin();
it = find(lt.begin(), lt.end(), 3);
if (it != lt.end())
{
lt.insert(it, 3);
*it *= 100;
}
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
it = find(lt.begin(), lt.end(), 3);
if (it != lt.end())
{
lt.insert(it, 30);
*it *= 100;
}
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
return 0;
}
如果是erase的话,程序就会崩溃:
int main()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_front(10);
lt.push_front(20);
auto it = lt.begin();
it = find(lt.begin(), lt.end(), 3);
if (it != lt.end())
{
lt.insert(it, 3);
*it *= 100;
}
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
it = find(lt.begin(), lt.end(), 3);
if (it != lt.end())
{
lt.erase(it);
*it *= 100;
}
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
return 0;
}
如果要用erase删除list中的偶数:
int main()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_front(10);
lt.push_front(20);
auto it = lt.begin();
//如果要用erase删除list中的偶数:
while (it != lt.end())
{
if (*it % 2 == 0)
{
it = lt.erase(it);
}
else
{
++it;
}
}
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
return 0;
}
 swap就是两个链表直接交换。
swap就是两个链表直接交换。
int main()
{
list<int> lt1;
lt1.push_back(1);
lt1.push_back(2);
lt1.push_back(3);
lt1.push_back(4);
list<int> lt2;
lt2.push_back(10);
lt2.push_back(20);
lt2.push_back(30);
lt2.push_back(40);
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
for (auto e : lt2)
{
cout << e << " ";
}
cout << endl;
lt1.swap(lt2);
for (auto e : lt1)
{
cout << e << " ";
}
cout << endl;
for (auto e : lt2)
{
cout << e << " ";
}
cout << endl;
return 0;
}
容器都是通过迭代器区间去访问的,比如这有一个容器,想在这一段查找,给这个容器的区间查找这个val就可以了。

clear就是把我们的节点删掉等等这些情况。
list中sort的价值大不大,库里面也有一个sort,list中也提供了一个sort,有啥意义呢?编译报错了,有时候掉不调到库里面去了,就看这个库是谁的归属,那就是哪儿出错了,sort这个库用这个迭代器我们不能用,因为sort这个库里面用到一个![]() ,就一个点我们就知道了,sort是快排,快排不能用这个东西,因为快排要做过参数取中,参数取中选其中一个值的时候,选中间那个值或者选另外一个值的时候,我直接要选那个位置,快排不适合,就是那个链表没办法适应这个场景。
,就一个点我们就知道了,sort是快排,快排不能用这个东西,因为快排要做过参数取中,参数取中选其中一个值的时候,选中间那个值或者选另外一个值的时候,我直接要选那个位置,快排不适合,就是那个链表没办法适应这个场景。

所以大家仔细再看,如果我们单看算法,这些算法的名字有一些差异,他这个是函数模板,但是他在这个名字上面很有讲究,它的名字就暗示了应该传什么迭代器,这里就要迁移出一个知识讲一讲,然后再结合这这个说,迭代器从他的功能的角度是会分类的,从功能上来说,分为单向、双向、随机。功能上是什么呢?单向就只能++,双向可以++也可以--,随机是可以++、--、也可以+,也可以-。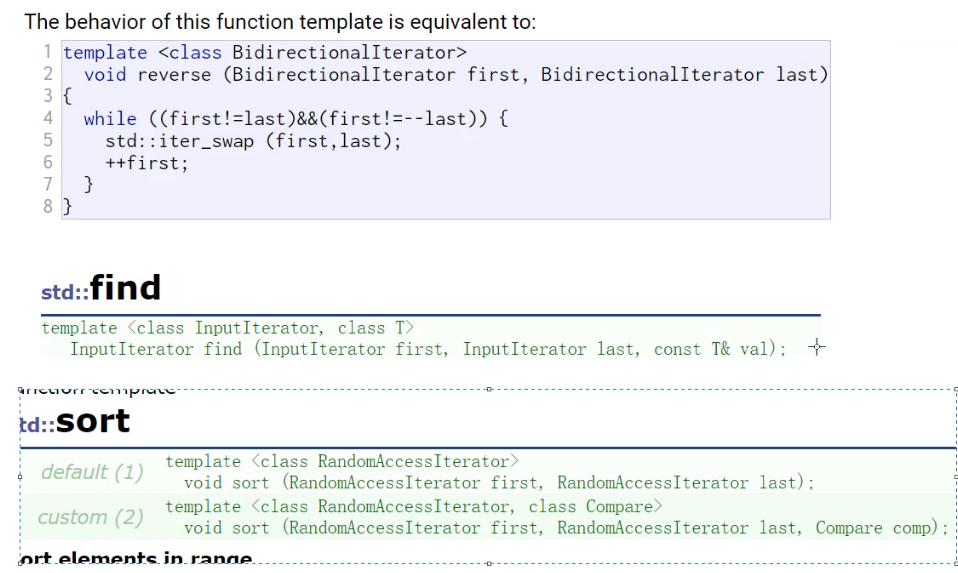

谁的迭代器就是典型的单向呢?单链表、哈希表。谁是双向迭代器呢?双向链表,其实也就是我们的list,还有map、set,也就是树。谁是随机迭代器呢?vector、string、双端队列deque。它这的名字就暗示了你用哪种算法,reverse就适合用双向,find就适合用单向,sort就适合用随机。这个地方对迭代器是一个隐式的分类,可以认为它是一个性质进行划分,这个性质跟容器的底层结构有关系。

谁可以调用这个sort算法呢,这个sort底层是快排,决定了他要用这个随机迭代器,随机是可以吊的,链表就不可以调,链表这里调就报错了,用这个算法就要看容器的迭代器到底是哪一种,能不能适应,我怎么知道我的容器是哪一种呢?这里是有说明的,它的迭代器的内容是什么,vector和string可以用这个逆置,随机迭代器可以认为是一个特殊的双向迭代器,随机迭代器满足双向的要求,满足单向的要求,![]() ,如果写这个,单向、双向、随机都可以用,写随机的就随机可以用,写双向的就双向、随机可以用,写单向的就单向、双向、随机都可以用。
,如果写这个,单向、双向、随机都可以用,写随机的就随机可以用,写双向的就双向、随机可以用,写单向的就单向、双向、随机都可以用。
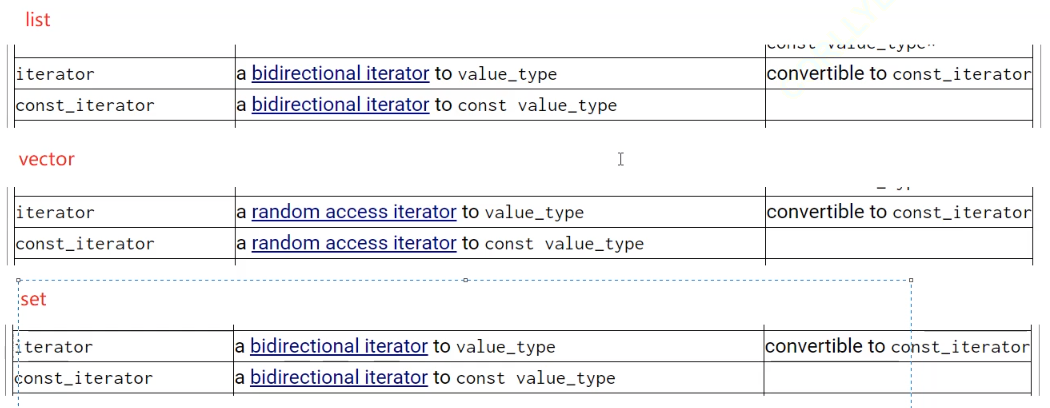
set底层就是更复杂的迭代器,也就是树了,forward_list是单向迭代器,

 排序应该用vector,不应该用list,vector的效率远高于list,
排序应该用vector,不应该用list,vector的效率远高于list,
数据量越大,差距越大一些,list排序终究还是要慢不少。如果我们真的要数据排序,我们不应该用链表,链表访问数据相比vector毕竟还是慢,list底层用的是归并算法。所以说list的sort意义不大。
void test_op()
{
srand(time(0));
const int N = 1000000;
vector<int> v;
v.reserve(N);
list<int> lt1;
//list<int> lt2;
for (int i = 0; i < N; ++i)
{
auto e = rand();
v.push_back(e);
lt1.push_back(e);
}
// 排序
int begin1 = clock();
sort(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt1.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
int main()
{
test_op();
return 0;
}
list的作用是当排序值比较小的时候,list排序才有价值。
void test_op()
{
srand(time(0));
const int N = 100000;
vector<int> v;
v.reserve(N);
list<int> lt1;
list<int> lt2;
for (int i = 0; i < N; ++i)
{
auto e = rand();
lt2.push_back(e);
lt1.push_back(e);
}
// 拷贝到vector排序,排完以后再拷贝回来
int begin1 = clock();
// 先拷贝到vector
for (auto e : lt1)
{
v.push_back(e);
}
// 排序
sort(v.begin(), v.end());
// 拷贝回去
size_t i = 0;
for (auto& e : lt1)
{
e = v[i++];
}
int end1 = clock();
int begin2 = clock();
lt2.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}
int main()
{
test_op();
return 0;
}
我们可以区分迭代器的类型,区分迭代器的类型有点复杂,叫做迭代器的萃取,就可以分辨出迭代器的类型。

merge就是连个链表可以直接进行归并,归并有一个前提就是先有序,两个链表要先sort再merge,这里还有另外一个东西叫仿函数,比较的仿函数的概念,仿函数在优先级队列再讲。

这个接口的本质是去重,去重也是有前提的,也是要先排序, 如果不排序去重的话效率是很低的。

remove就是find加erase,remove就是直接可以删。remove唯一要注意的是如果这个值不存在会不会报错?
void text_x()
{
int myints[] = { 17,89,7,14 };
std::list<int> mylist(myints, myints + 4);
mylist.remove(890);
for (auto e : mylist)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
text_x();
return 0;
}
相当于find,如果找到就删除了,没找到就啥也不干。
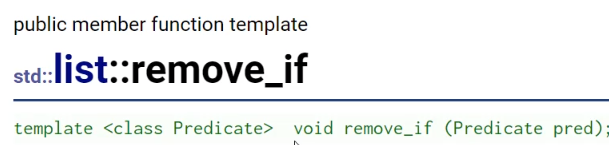
remove_if 也涉及到一个仿函数的问题。
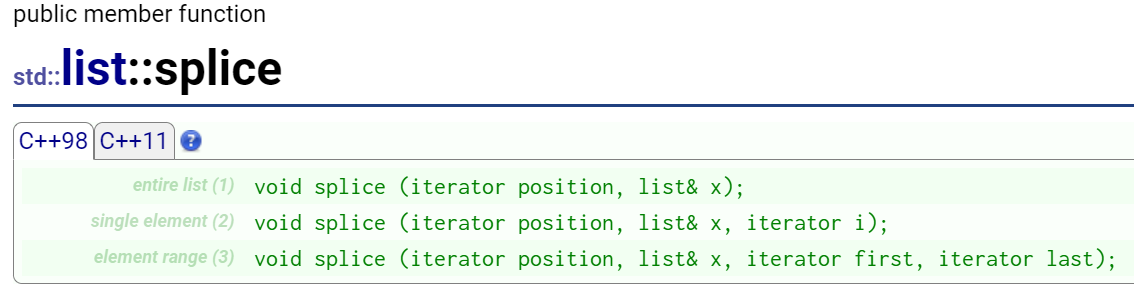
这个接口可以把一个链表的内容转移到另一个,它的转移是直接把节点拿走,就比如说有一个a链表,有一个b链表,直接把a链表的节点取下来直接插入到b链表,相当于a链表删除了数据,b链表插入了数据,严格来说就是发生了转移。也可以转移到自己身上,但是别把范围区间重叠了。
int main()
{
int myints[] = { 17,89,7,14 };
std::list<int> mylist1, mylist2;
std::list<int>::iterator it;
for (int i = 1; i <= 4; ++i)
mylist1.push_back(i); // mylist1: 1 2 3 4
for (int i = 1; i <= 3; ++i)
mylist2.push_back(i * 10); // mylist2: 10 20 30
for (auto e : mylist1)
{
cout << e << " ";
}
cout << endl;
for (auto e : mylist2)
{
cout << e << " ";
}
cout << endl << endl;
it = mylist1.begin();
++it;
// points to 2
//全部转移
//mylist1.splice(it, mylist2);
//转移一个
//mylist1.splice(it, mylist2, ++mylist2.begin());
//部分转移
//mylist1.splice(it, mylist2, ++mylist2.begin(), mylist2.end());
//把后面的数据转移到第一个的前面
mylist1.splice(mylist1.begin(), mylist1, ++mylist1.begin(), mylist1.end());
for (auto e : mylist1)
{
cout << e << " ";
}
cout << endl;
for (auto e : mylist2)
{
cout << e << " ";
}
cout << endl;
return 0;
}