之前搞过不少部署,也玩过tensorRT部署模型(但都是模型推理用gpu,后处理还是用cpu进行),有网友问能出一篇tensorRT用gpu对模型后处理进行加速的。由于之前用的都是非cuda支持的边缘芯片,没有写过cuda代码,这个使得我犹豫不决。零零总总恶补了一点cuda编程,于是就有了这篇博客【yolov11 部署 TensorRT,预处理和后处理用 C++ cuda 加速,速度快到飞起】。既然用cuda实现,就不按照部署其他芯片(比如rk3588)那套导出onnx的流程修改导出onnx代码,要尽可能多的操作都在cuda上运行,这样导出onnx的方式就比较简单(yolov11官方导出onnx的方式)。
rtx4090显卡、模型yolov11n(输入分辨率640x640,80个类别)、量化成FP16模型,最快1000fps
本示例中,包含完整的代码、模型、测试图片、测试结果。
后处理部分用cuda 核函数实现,并不是全部后处理都用cuda实现【cuda实现后处理代码】;纯cpu实现后处理部分代码分支【cpu实现后处理代码】
使用的TensorRT版本:TensorRT-8.6.1.6
cuda:11.4
显卡:RTX4090
cuda 核函数主要做的操作
由于按照yolov11官方导出的onnx,后处理需要做的操作只有nms了。mns流程:选出大于阈值的框,在对这些大于阈值的框进行排序,在进行nms操作。这几部中最耗时的操作(对类别得分选出最大对应的类别,判断是否大于阈值)是选出所有大于阈值的框,经过这一步后实际参加nms的框没有几个(比如图像中有30个目标,每个目标出来了15个框,也才450个框),因此主要对这一步操作“选出所有大于阈值的框”用cuda实现。当然后续还可以继续优化,把nms的过程用cuda核函数进行实现。
核函数的实现如下:模型输出维度(1,(4+80),8400),主要思想流程用8400个线程,实现对80个类别选出最大值,并判断是否大于阈值。
__global__ void GetNmsBeforeBoxesKernel(float *SrcInput, int AnchorCount, int ClassNum, float ObjectThresh, int NmsBeforeMaxNum, DetectRect* OutputRects, int *OutputCount){/***功能说明:用8400个线程,实现对80个类别选出最大值,并判断是否大于阈值,把大于阈值的框记录下来后面用于参加mnsSrcInput: 模型输出(1,84,8400)AnchorCount: 8400ClassNum: 80ObjectThresh: 目标阈值(大于该阈值的目标才输出)NmsBeforeMaxNum: 输入nms检测框的最大数量,前面申请的了一块儿显存来装要参加nms的框,防止越界OutputRects: 大于阈值的目标框OutputCount: 大于阈值的目标框个数***/ int ThreadId = blockIdx.x * blockDim.x + threadIdx.x; if (ThreadId >= AnchorCount) { return; } float* XywhConf = SrcInput + ThreadId; float CenterX = 0, CenterY = 0, CenterW = 0, CenterH = 0; float MaxScore = 0; int MaxIndex = 0; DetectRect TempRect; for (int j = 4; j < ClassNum + 4; j ++) { if (4 == j) { MaxScore = XywhConf[j * AnchorCount]; MaxIndex = j; } else { if (MaxScore < XywhConf[j * AnchorCount]) { MaxScore = XywhConf[j * AnchorCount]; MaxIndex = j; } } } if (MaxScore > ObjectThresh) { int index = atomicAdd(OutputCount, 1); if (index > NmsBeforeMaxNum) { return; } CenterX = XywhConf[0 * AnchorCount]; CenterY = XywhConf[1 * AnchorCount]; CenterW = XywhConf[2 * AnchorCount]; CenterH = XywhConf[3 * AnchorCount ]; TempRect.classId = MaxIndex - 4; TempRect.score = MaxScore; TempRect.xmin = CenterX - 0.5 * CenterW; TempRect.ymin = CenterY - 0.5 * CenterH; TempRect.xmax = CenterX + 0.5 * CenterW; TempRect.ymax = CenterY + 0.5 * CenterH; OutputRects[index] = TempRect; }}导出onnx模型
按照yolov11官方导出的方式如下:
from ultralytics import YOLOmodel = YOLO(model='yolov11n.pt') # load a pretrained model (recommended for training)results = model(task='detect', source=r'./bus.jpg', save=True) # predict on an imagemodel.export(format="onnx", imgsz=640, simplify=True)编译
修改 CMakeLists.txt 对应的TensorRT位置
cd yolov11_tensorRT_postprocess_cudamkdir buildcd buildcmake ..make运行
# 运行时如果.trt模型存在则直接加载,若不存会自动先将onnx转换成 trt 模型,并存在给定的位置,然后运行推理。cd build./yolo_trt测试效果
onnx 测试效果
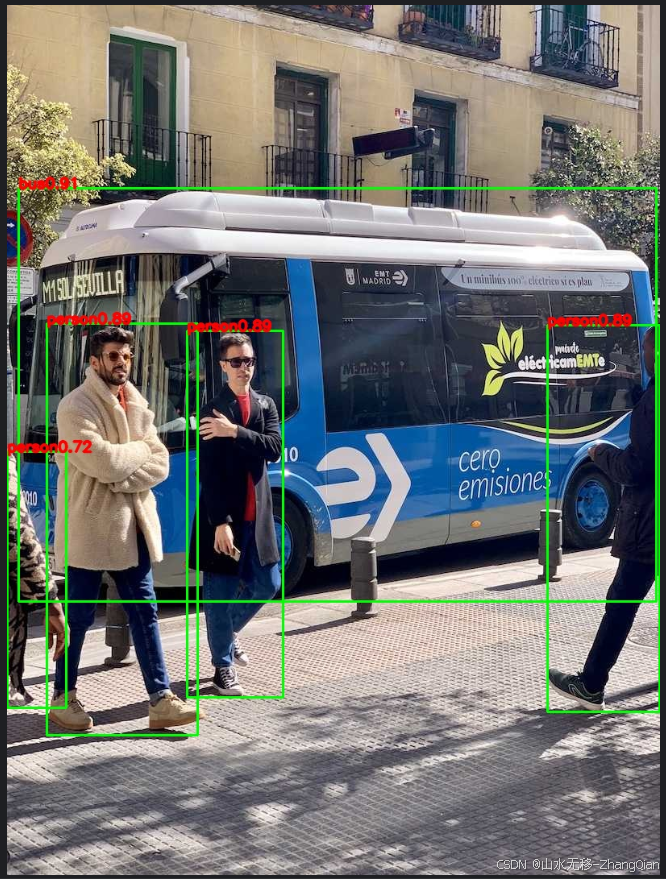
tensorRT 测试效果

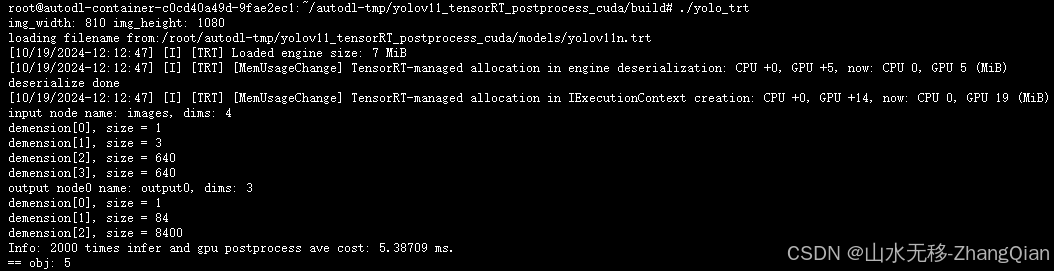
tensorRT 时耗(cuda实现部分后处理)
示例中用cpu对图像进行预处理(由于本台机器搭建的环境不匹配,不能用cuda对预处理进行加速)、用rtx4090显卡进行模型推理、用cuda对后处理进行加速。使用的模型yolov11n(输入分辨率640x640,80个类别)、量化成FP16模型。以下给出的时耗是:预处理+模型推理+后处理。
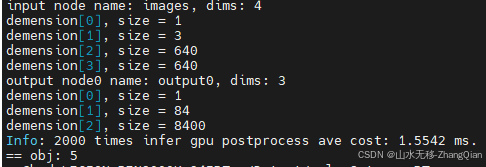
cpu做预处理+模型推理+gpu做后处理
tensorRT 时耗(纯cpu实现后处理)【cpu实现后处理代码分支】
cpu做预处理+模型推理+cpu做后处理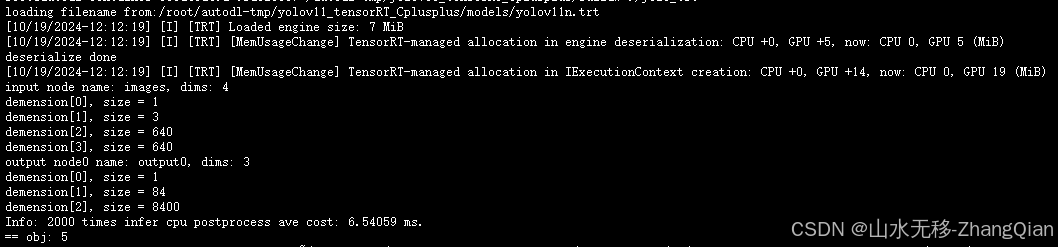
替换模型说明
修改相关的路径
std::string OnnxFile = "/root/autodl-tmp/yolov11_tensorRT_postprocess_cuda/models/yolov11n.onnx"; std::string SaveTrtFilePath = "/root/autodl-tmp/yolov11_tensorRT_postprocess_cuda/models/yolov11n.trt"; cv::Mat SrcImage = cv::imread("/root/autodl-tmp/yolov11_tensorRT_postprocess_cuda/images/test.jpg"); int img_width = SrcImage.cols; int img_height = SrcImage.rows; std::cout << "img_width: " << img_width << " img_height: " << img_height << std::endl; CNN YOLO(OnnxFile, SaveTrtFilePath, 1, 3, 640, 640); auto t_start = std::chrono::high_resolution_clock::now(); int Temp = 2000; int SleepTimes = 0; for (int i = 0; i < Temp; i++) { YOLO.Inference(SrcImage); std::this_thread::sleep_for(std::chrono::milliseconds(SleepTimes)); } auto t_end = std::chrono::high_resolution_clock::now(); float total_inf = std::chrono::duration<float, std::milli>(t_end - t_start).count(); std::cout << "Info: " << Temp << " times infer and gpu postprocess ave cost: " << total_inf / float(Temp) - SleepTimes << " ms." << std::endl;预处理用cuda加速
代码中已实现用CUDA_npp_LIBRARY进行预处理,如果有环境可以打开进一步加速(修改位置:CMakelist.txt 已进行了注释、用CPU或GPU预处理打开对应的宏 #define USE_GPU_PREPROCESS 1))
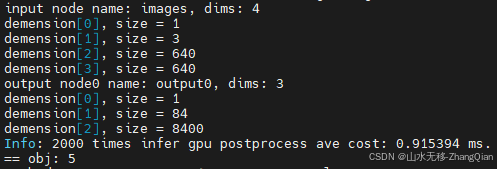
重新搭建了一个支持用gpu对预处理进行加速的环境:rtx4090显卡、模型yolov11n(输入分辨率640x640,80个类别)、量化成FP16模型。对比结果如下:这台机器相比上面贴图中时耗更短,可能是这台机器的cpu性能比较强。以下给出的时耗是:预处理+模型推理+后处理。
cpu做预处理+模型推理+cpu做后处理
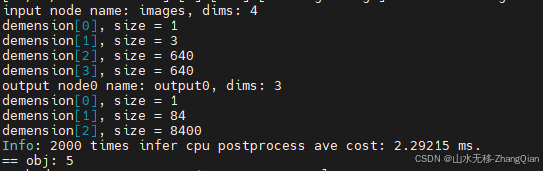
cpu做预处理+模型推理+gpu做后处理
gpu做预处理+gpu做后处理
后续优化点
1、把nms过程也用cuda实现,参加nms的框不多,但也是一个优化点,持续更新中