一、豆包大模型简介
豆包大模型是由字节跳动开发的人工智能。它具有强大的语言理解与生成能力、广泛的知识覆盖以及个性化的交互体验,本文旨在使用Python调用豆包大模型API,并实现TTS文本转语音,将大模型输出结果播报出来。

二、环境描述
我使用的环境如下所示:
计算机系统架构:x86
Python版本:Python 3.11.3(官方要求上大于2.7即可)
Pycharm版本:Pycharm 2023.1(专业版)
三、 Python库安装
1. 基础库安装
为了实现文本转语音TTS以及加载.env配置文件,首先需要安装一些python的基础库:
pip install pyttsx3pip install dotenv2. 豆包大模型python库安装
在终端使用以下命令安装:
pip install volcengine-python-sdk如果报以下错误:
note: This error originates from a subprocess, and is likely not a problem with pip. ERROR: Failed building wheel for volcengine-python-sdk Running setup.py clean for volcengine-python-sdkFailed to build volcengine-python-sdkERROR: ERROR: Failed to build installable wheels for some pyproject.toml based projects (volcengine-python-sdk)是因为Windows 系统有最长路径限制,可能会导致安装失败,请按照以下方式设置:
1. 按下 Win+R ,输入 regedit 打开注册表编辑器。2. 设置 \HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem 路径下的变量 LongPathsEnabled 为 1 即可。修改完注册表后再次运行pip命令即可成功安装volcengine-python-sdk。
四、大模型后台设置
1. 注册登录
进入火山引擎官网,注册并登录:
https://console.volcengine.com/auth/login?redirectURI=%2Fhome2. 获取API访问密钥
进入火山引擎API访问密钥网页,获取API访问密钥:
https://console.volcengine.com/iam/keymanage/具体流程如下:
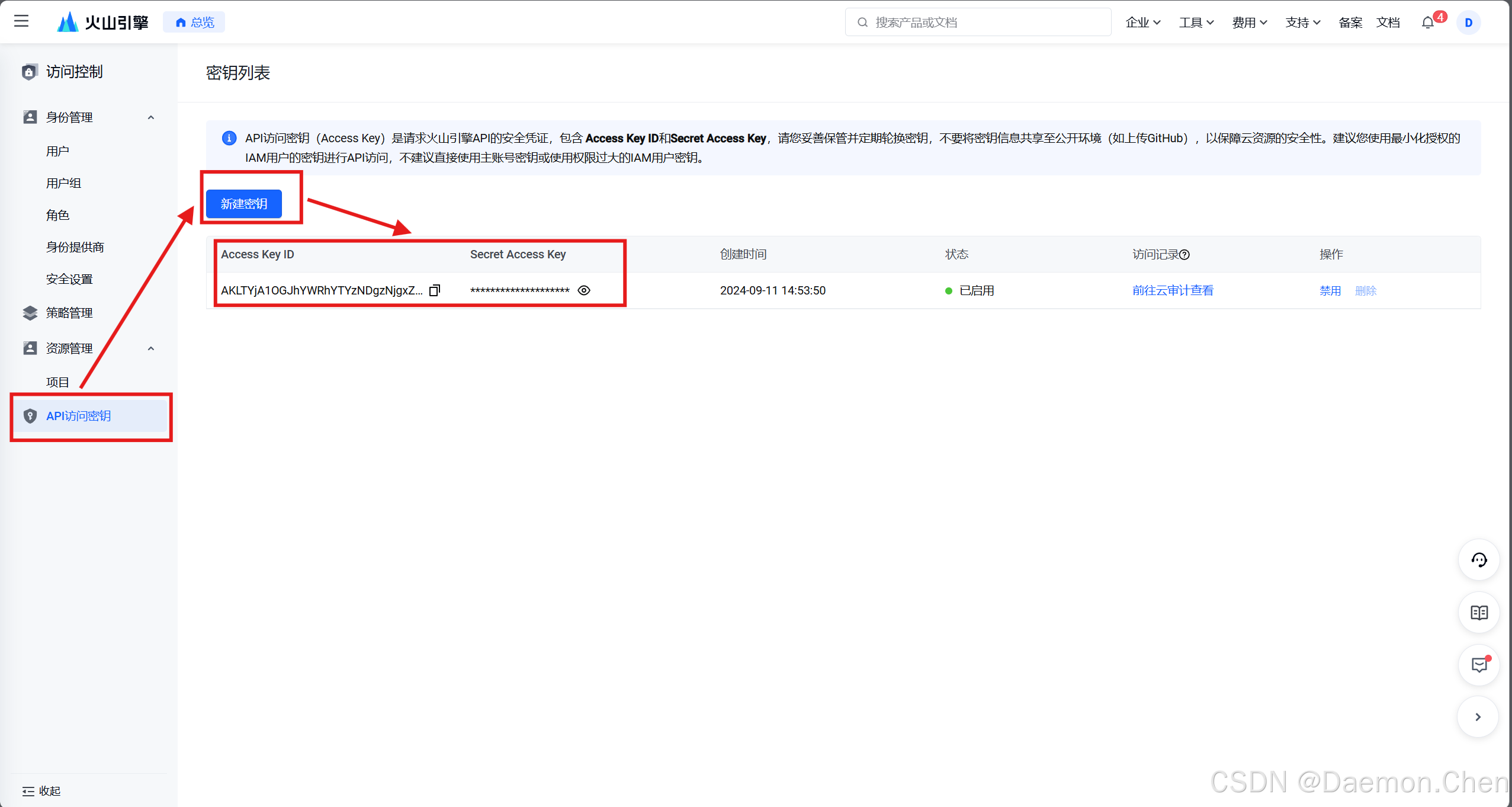
此处获得的Access Key和Secret Access Key非常重要,后续需要配置到Python程序中。
3. 获取API Key
进入火山引擎API Key网页,获取API Key:
https://console.volcengine.com/ark/region:ark+cn-beijing/apiKey具体流程如下:
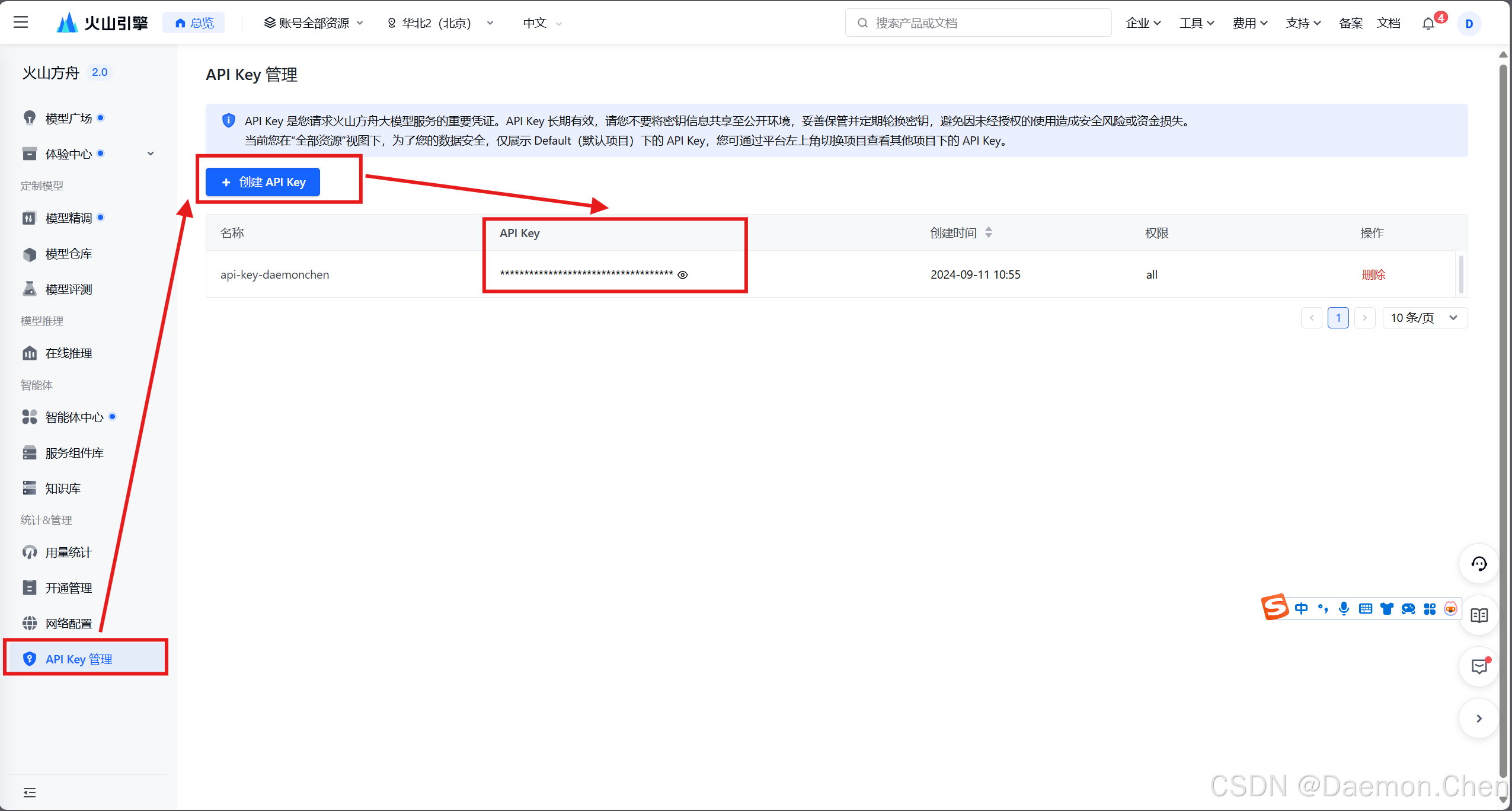
即可获取到API Key。
4. 获取model
进入火山引擎model获取网页,获取model:
https://console.volcengine.com/ark/region:ark+cn-beijing/endpoint?current=1&pageSize=10具体流程如下:
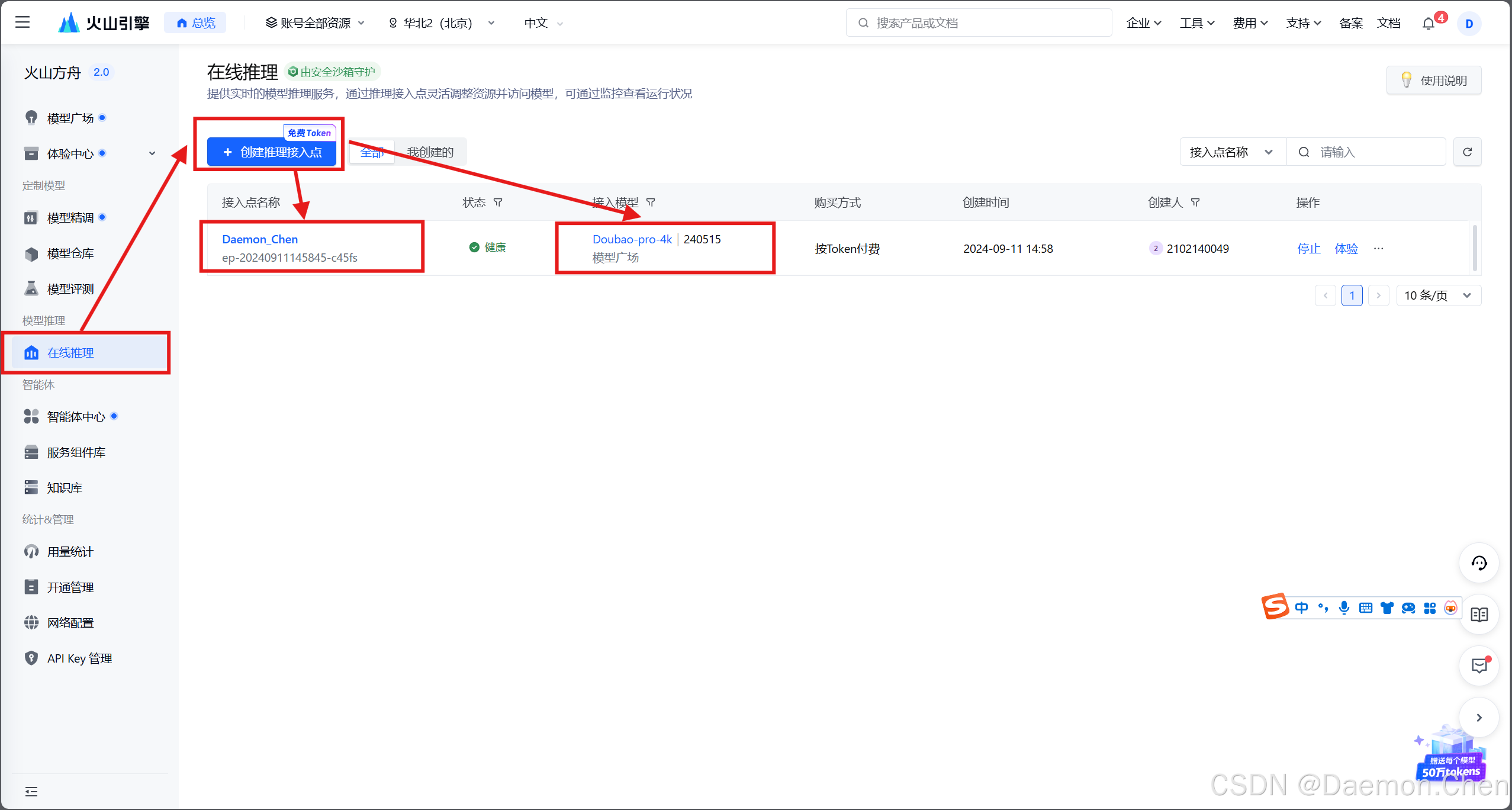
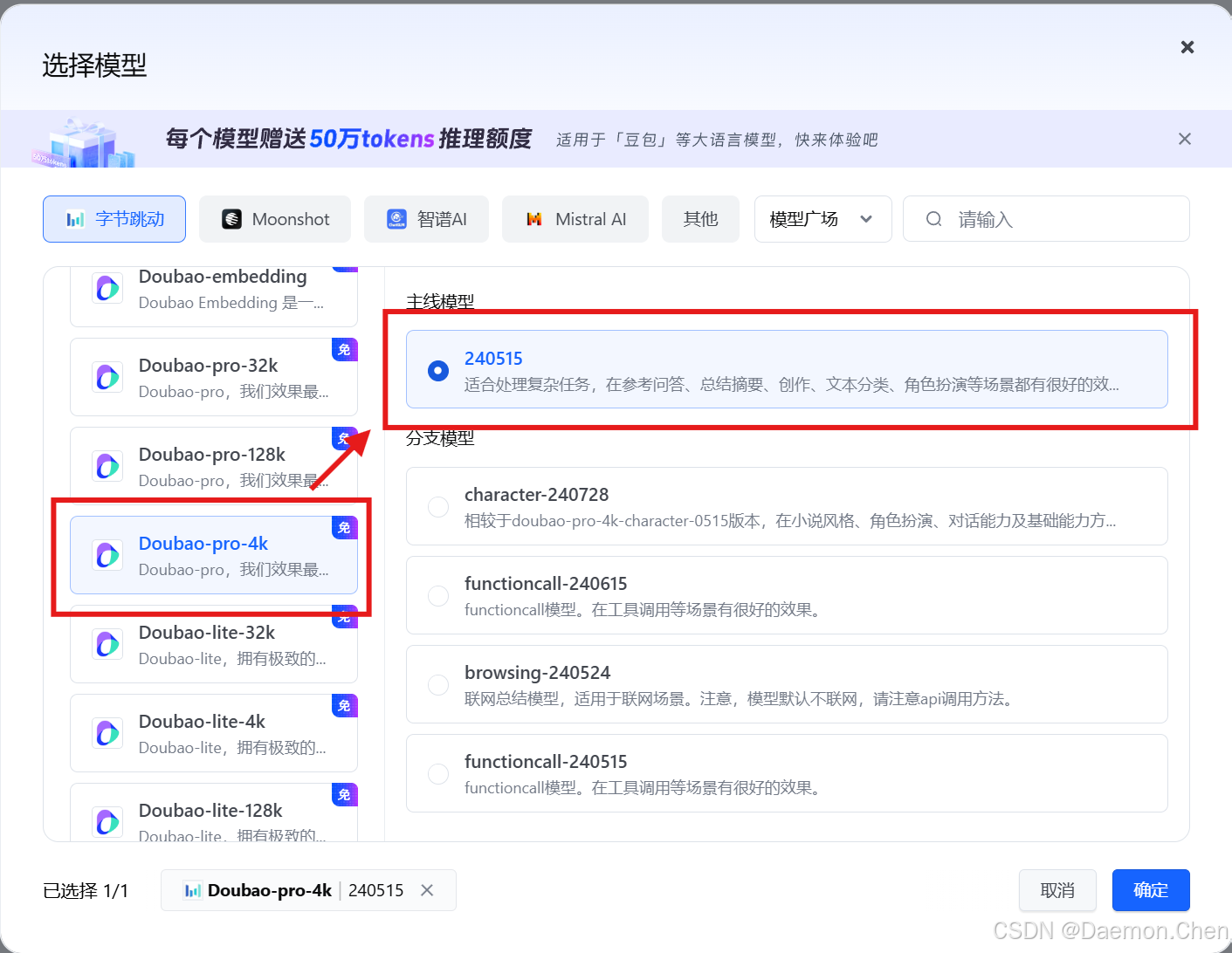
模型选择Doubao-pro-4k,主线模型选择240515即可。
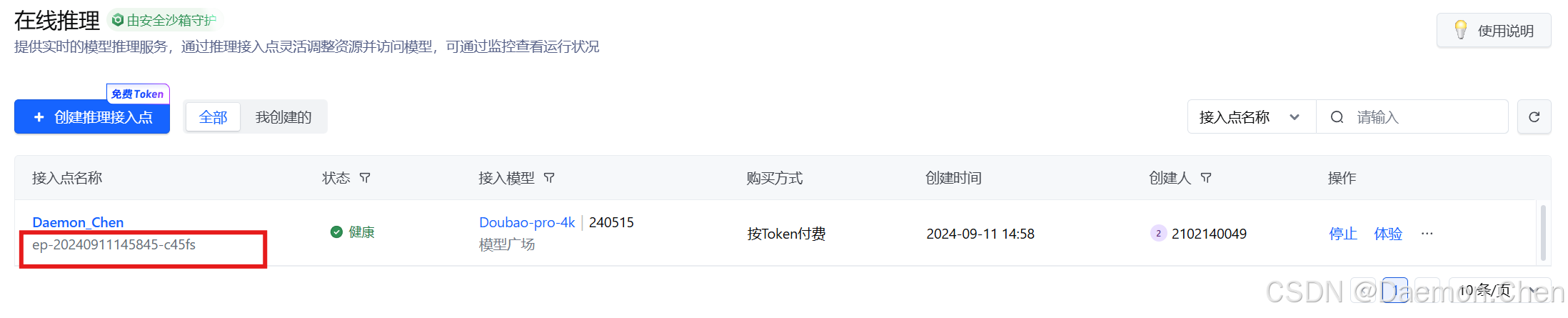
接入点名称下的这一串代码就是 ENDPOINT_ID,非常重要,后续需要填到Python程序中。
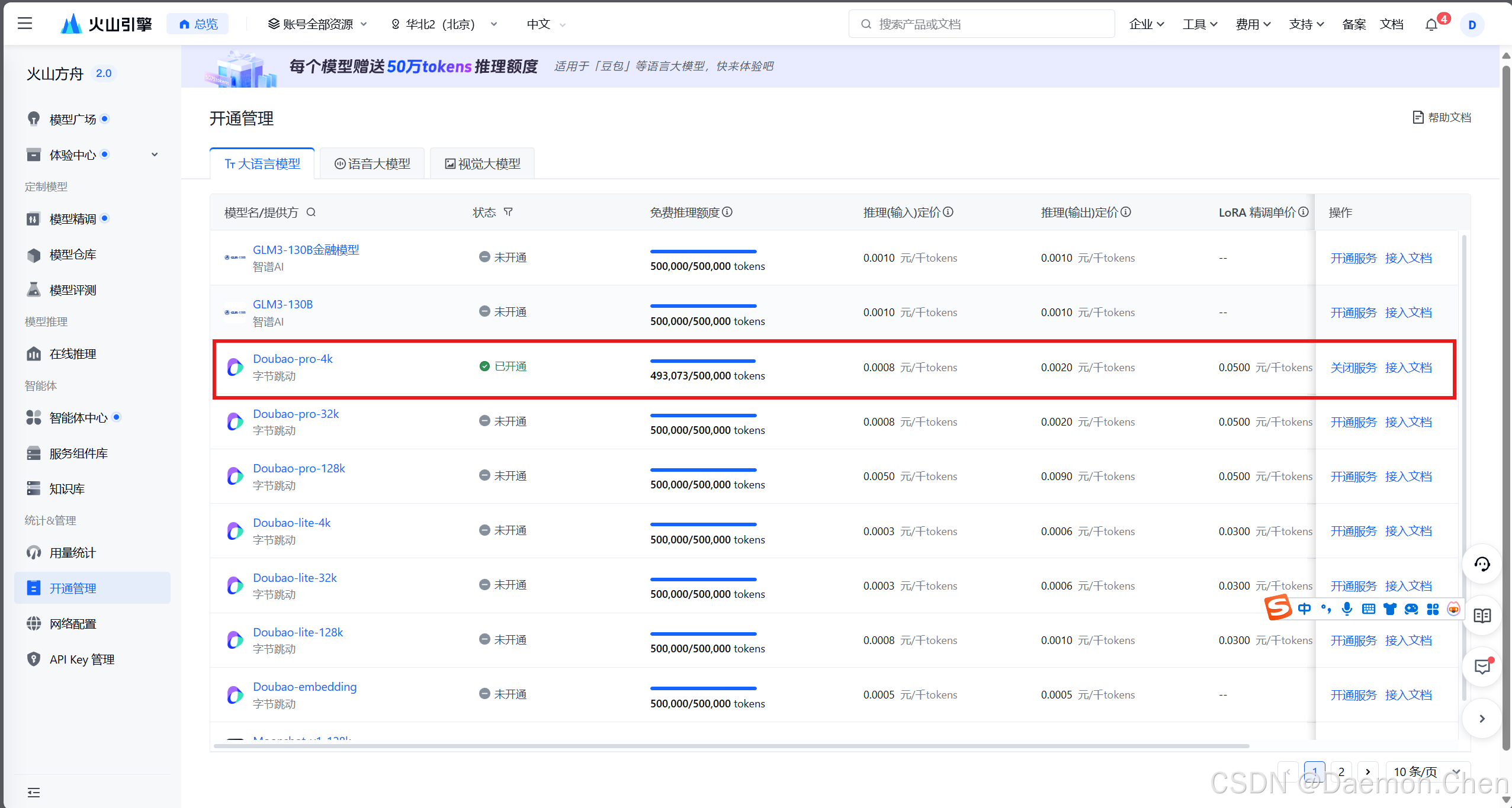
5. 开通模型
进入以下网站,开通模型:
https://console.volcengine.com/ark/region:ark+cn-beijing/openManagement开通Doubao-pro-4k的模型服务。
五、编写程序
1. 文件夹配置
使用pycharm新建工程,在工程中新建.env和main.py这两个文件,如下图所示:

2. 程序编写
在.env文件中填入以下内容:
VOLC_ACCESSKEY= your Access KeyVOLC_SECRETKEY= your Secret Access KeyENDPOINT_ID= your ENDPOINT_ID将your Access Key替换成你自己的 Access Key,your Secret Access Key和 your ENDPOINT_ID也一样替换成自己的。
编写main.py:
import osimport pyttsx3from volcenginesdkarkruntime import Arkimport dotenv# 加载环境变量dotenv.load_dotenv(".env")# 初始化 Ark 客户端client = Ark()# 初始化 pyttsx3 引擎engine = pyttsx3.init()# 配置 TTS 的语速和音量(可选)engine.setProperty('rate', 150) # 语速engine.setProperty('volume', 1) # 音量# 从环境变量中获取模型 IDmodel_id = os.getenv("ENDPOINT_ID")# 欢迎语Welcome_Text = "您好,我是豆包,您的大模型对话助手,请问有什么可以帮到您?(输入 'exit' 退出对话)"print(Welcome_Text)engine.say(Welcome_Text)engine.runAndWait() # 等待语音播放完毕# 进入多轮对话的循环while True: # 从终端获取用户输入 user_input = input("User:\r\n") # 检查用户是否想退出 if user_input.lower() in ["exit", "quit"]: print("AI:感谢您的使用,再见!") break # 创建流式对话请求 stream = client.chat.completions.create( model=model_id, messages=[ {"role": "system", "content": "你是豆包,是由字节跳动开发的 AI 人工智能助手"}, {"role": "user", "content": user_input}, # 使用终端输入的内容 ], stream=True ) print("AI:") # 初始化一个空字符串来存储所有文本 full_text = "" # 逐块读取流式输出并将结果打印 for chunk in stream: if not chunk.choices: continue # 获取文本内容 text = chunk.choices[0].delta.content # 输出文本到控制台 print(text, end="") # 将文本累积到 full_text full_text += text # 当流式结果全部接收完成后,开始将累积的文本通过 TTS 朗读出来 if full_text: engine.say(full_text) engine.runAndWait() # 等待语音播放完毕 print("\r\n")六、最终效果
最终实现的效果如视频所示:
Python调用豆包大模型API
平均反应时间不到2s,嘎嘎nice!
七、源码分享
源码放在这里了,需要的同学请自取~
https://download.csdn.net/download/Jlinkneeder/89743078