#记录下第一次使用爬虫进行网页pdf爬取过程和踩坑记录#
1.目的
第一次做分析,想要在网上搜寻相关的研究报告之类的,但是总是有很多无关的链接文件或者不完整的引流链接,想到一般来说这种报告都是pdf居多,所以直接选择批量爬取.pdf文件再进行筛选会不会更有效率,于是直接开干。最终根据以下三个文章合并起来完成了小白的爬虫第一次。以下是本文的参考链接:
爬虫参考:2023最新使用python爬虫爬取全网.pdf网址并下载需要的pdf文件资源(可设置搜索keyword)!!!_如何通过爬虫下载一个网页里面的文档文件-CSDN博客
安装chrome driver参考:Selenium安装WebDriver最新Chrome驱动(含116/117/118/119)_chromedriver 119-CSDN博客
使用selenium打开浏览器报错 chromedriver‘ executable needs to be in PATH_chromedriver' executable needs to be in path.-CSDN博客
2.爬虫前提
2.1查看chrome浏览器版本
打开chrome浏览器,输入以下代码:
chrome://version/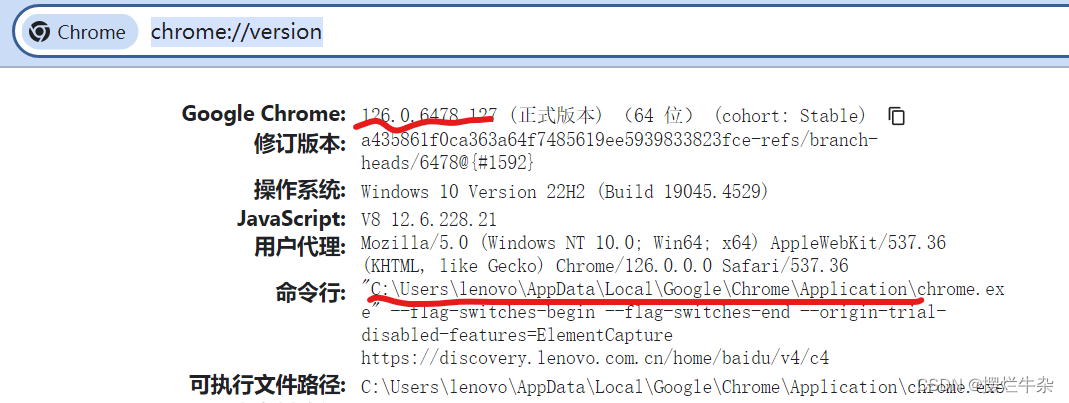
这里可以看到我们的版本是126开头且chrome的路径也出来了。
2.2下载对应版本的chrome driver
那么我们就前往官网下载对应的driver。点击这里,就会看到这样一个界面: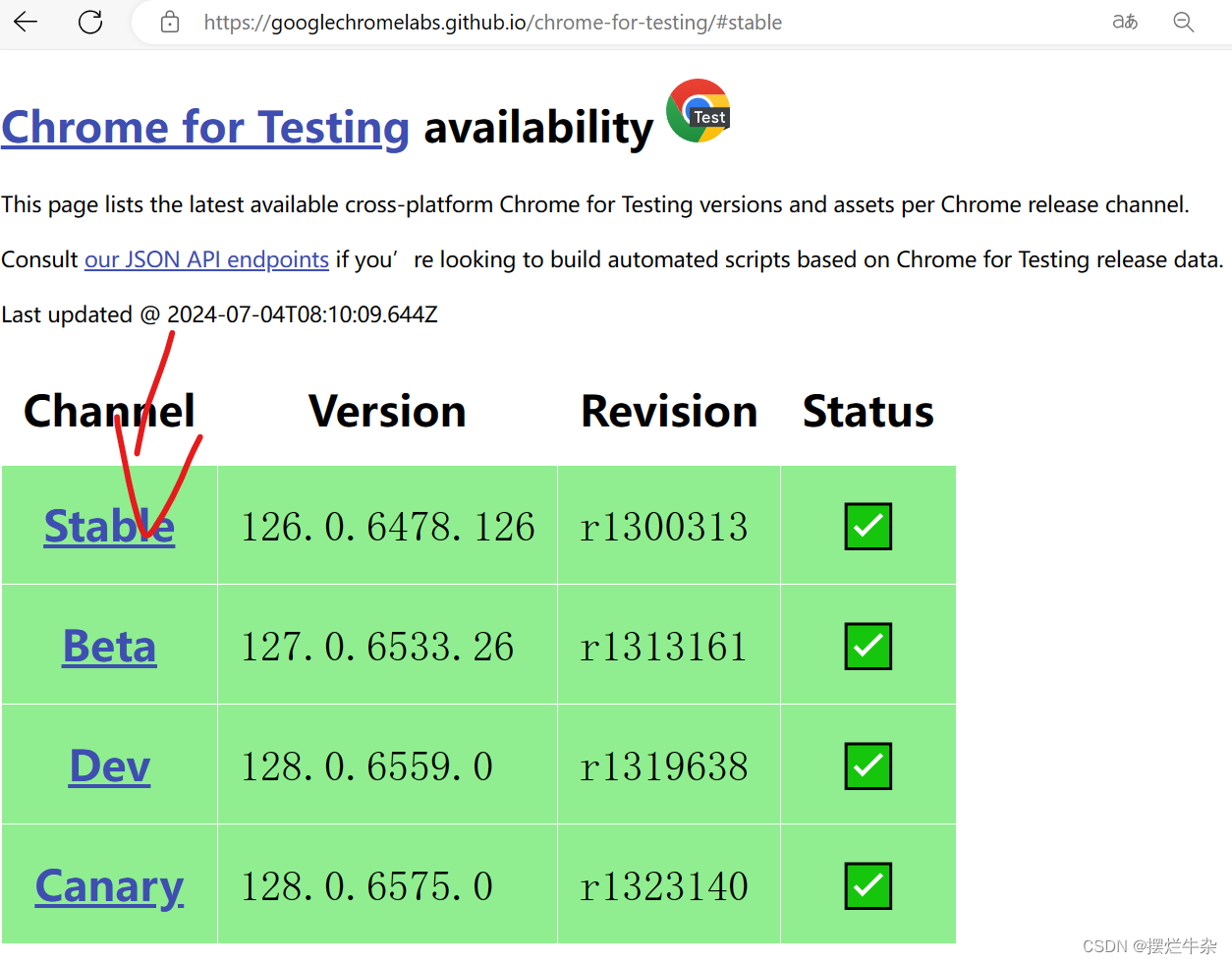
点击stable,去选择和我们系统对应的 版本,这里我们是windows,win32既可以在32也可以在64环境使用,复制链接右键选择转到就可以下载了。
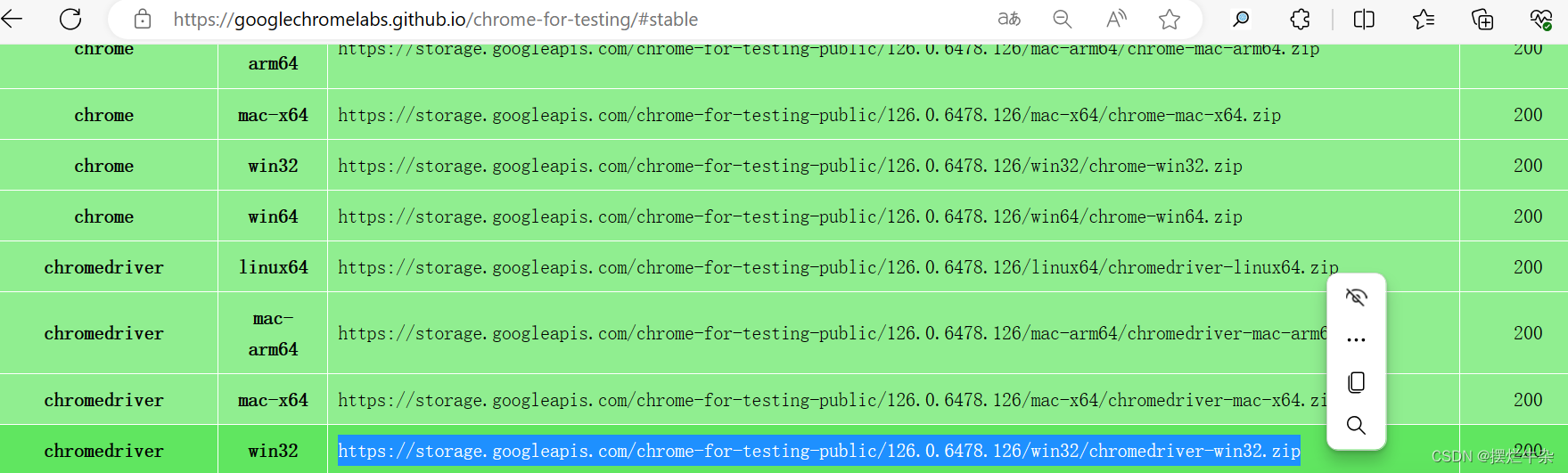
2.3移动chrome drive至python环境
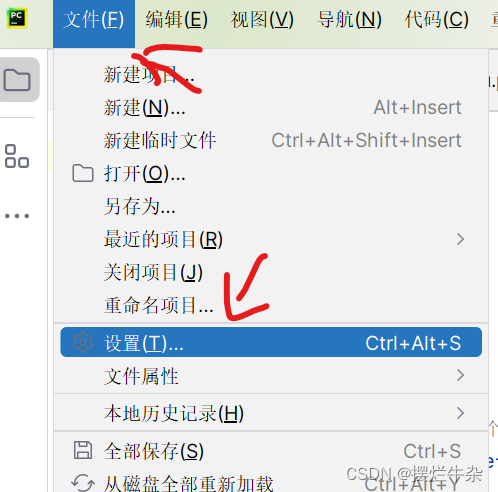
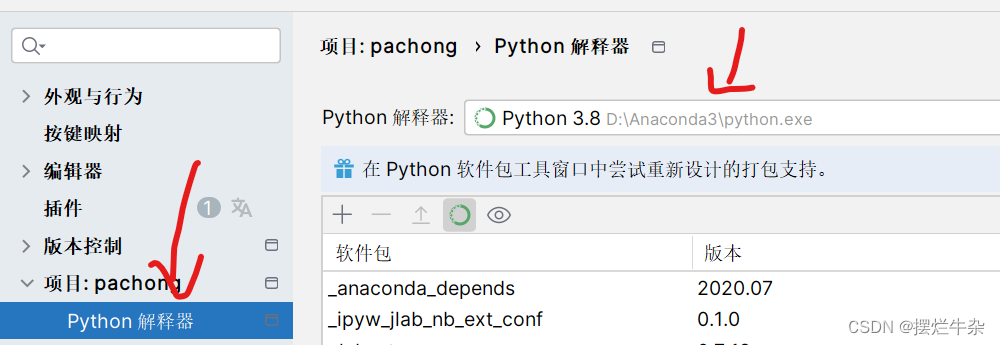
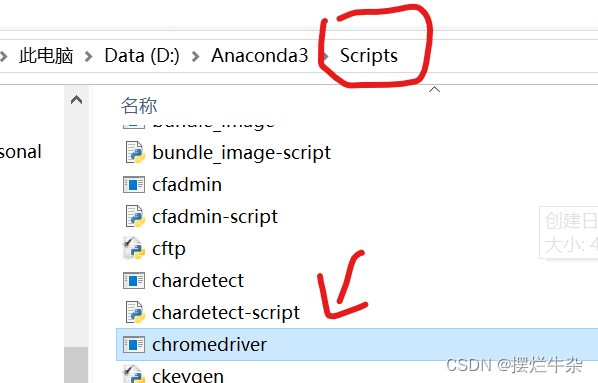
下载好了之后就进行解压,然后就要去查询到我们python路径了,具体方法如下:点击“文件”->“设置”->“python解释器”->虚字路径。找到之后我们把chrome drive直接复制到该路径下的scripts问价夹下即可。这样就算完成了,也不需要加什么环境变量了。
2.4添加selenium标准库
因为刚开始我们是没有这个库的,所以加上代码也会是报错的,所以需要按以下步骤在终端下载:
pip install selenium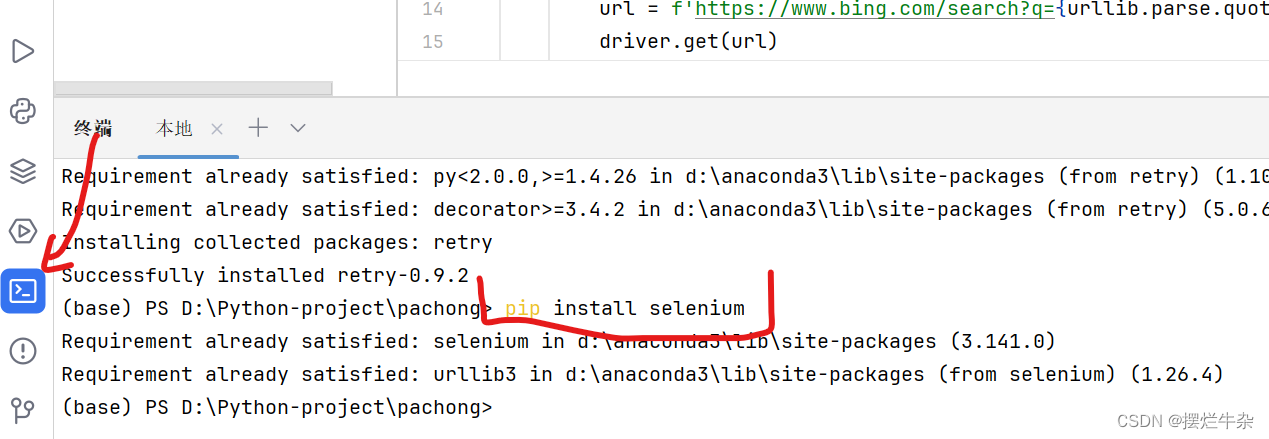
这里我已经是下载好了所以只是做演示,注意!!!如果后续仍然报错说缺少哪个模块一样采取以下命令下载补全:
pip install {模块名}2.5测试
用以下测试代码即可,注意的是:
chromedriver_path = r"D:\Anaconda3\Scripts\chromedriver.exe"
这里面的路径要改为自己计算机下对应的chromedrive路径。
from selenium import webdriverchromedriver_path = r"D:\Anaconda3\Scripts\chromedriver.exe"driver = webdriver.Chrome(chromedriver_path)# 登录百度def main(): driver.get("https://baidu.com/")if __name__ == '__main__': main()效果应该是这样的 :
3.爬虫代码
3.1爬取链接
import urllib.parse # pip install urllib3==1.26.2from selenium import webdriver # pip install selenium==3.141.0from selenium.webdriver.common.keys import Keysfrom bs4 import BeautifulSoupimport timedef scrape_pages(keyword, save_path, total_pages): num = 0 driver = webdriver.Chrome() for i in range(total_pages): page = 10 * i + 1 url = f'https://www.bing.com/search?q={urllib.parse.quote(keyword)}&first={page}' driver.get(url) elem = driver.find_element_by_tag_name("body") no_of_pagedowns = 15 while no_of_pagedowns: elem.send_keys(Keys.PAGE_DOWN) time.sleep(0.2) no_of_pagedowns -= 1 html = driver.page_source soup = BeautifulSoup(html, 'html.parser') # 获取所有 h2 元素 h2_elements = soup.find_all('h2') with open(save_path, 'a', encoding='utf-8') as f: for h2 in h2_elements: a_tag = h2.find('a') # 找到 h2 下的 a 标签 if a_tag and 'href' in a_tag.attrs: # 确保 a 标签存在并包含 href 属性 href = a_tag['href'] # 获取 href 属性的值 f.write(href + '\n') num += 1 print(f"已保存{i + 1}页,共保存了{num}个网址") driver.quit() print(f"爬取完成,共保存了{num}个网址")# 爬取200页keyword = "小红书 filetype:pdf"save_path = r"E:\xiaohongshu.txt"total_pages = 10scrape_pages(keyword, save_path, total_pages)这里要注意的是
keyword = "小红书 filetype:pdf"save_path = r"E:\xiaohongshu.txt"total_pages = 10scrape_pages(keyword, save_path, total_pages)
keyword指的是你希望搜索的关键词,save_path是在自己电脑下保存的路径也是要自己创建修改的,total_pages指的是你要爬多少页的结果。
3.2下载pdf文件
import osimport requestsfrom urllib.parse import urlparsefrom retry import retryimport urllib3import reurllib3.disable_warnings()@retry(tries=3, delay=1, backoff=2)def download_file(pdf_url, output_path): response = requests.get(pdf_url, verify=False, stream=True) content_disposition = response.headers.get('content-disposition') if content_disposition: filename = re.findall("filename=(.+)", content_disposition) if filename: output_path = os.path.join(output_path, filename[0]) with open(output_path, 'wb') as file: for chunk in response.iter_content(chunk_size=1024): if chunk: file.write(chunk)def download_pdfs_from_file(input_file, output_dir, error_file, start_from=1): # 创建输出目录 os.makedirs(output_dir, exist_ok=True) # 创建一个集合用于存放唯一的链接,去重 unique_urls = set() # 读取文本文件中的所有行,并记录原始索引位置 with open(input_file, 'r', encoding='utf-8') as file: lines = file.readlines() for line in lines: if '.pdf' in line: unique_urls.add(line.strip()) # 获取PDF文件数量 total_pdfs = len(unique_urls) unique_urls = list(unique_urls) # 从指定位置开始下载PDF文件 for idx in range(start_from - 1, total_pdfs): pdf_url = unique_urls[idx] try: # 下载PDF文件并保存至输出目录 print(f'Downloading file {idx + 1}/{total_pdfs}: {pdf_url}') parsed_url = urlparse(pdf_url) filename = os.path.basename(parsed_url.path) output_path = os.path.join(output_dir, filename) download_file(pdf_url, output_path) print(f'\nDownloaded {pdf_url}') except Exception as e: # 输出错误信息至指定文件 print(f'\nFailed to download {pdf_url}: {str(e)}') with open(error_file, 'a', encoding='utf-8') as err_file: err_file.write(f'{pdf_url}\n') finally: pass# 设定输入文件路径、输出目录路径和错误输出文件路径,并指定开始下载的位置input_file_path = r"E:\xiaohongshu.txt"output_directory = r"E:\资料\小红书\pdf" # 桌面创建pdf文件夹error_output_file = r"E:\资料\小红书\pdf\false-url.txt" # 下载失败的url,可手动下载补充start_download_from = 1 # 从第几个url开始# 调用函数下载PDF文件,传入开始下载的位置参数和错误输出文件路径download_pdfs_from_file(input_file_path, output_directory, error_output_file, start_from=start_download_from)这里要注意的仍然是路径问题,input_file_path是输入文件的路径,也就是上面爬取链接路径保存下来的那个txt文件。output_directory指的是下载下来的pdf要存放的文件夹的路径。error_output_file相当于异常处理,把下载失败的链接名记录下来。
input_file_path = r"E:\xiaohongshu.txt"output_directory = r"E:\资料\小红书\pdf" # 桌面创建pdf文件夹error_output_file = r"E:\资料\小红书\pdf\false-url.txt" # 下载失败的url,可手动下载补充
总结
以上就是一个简单的爬取pdf的方法过程了,具体实践后,会发现有可能下载到完全不相关的文件,这个就需要在进行具体筛选了,也可以在代码层面进行改进。也的确省下了不少的时间去搜索。