YOLO v4论文:https://arxiv.org/abs/2004.10934
YOLO v4源码:https://github.com/AlexeyAB/darknet
给学妹写的教程,发上来作为学习记录吧,数据集用的是开源车牌数据集CCPD,本文章介绍的只是检测车牌框,并不带车牌识别功能。有错误或者有疑问的欢迎底下评论。
文章目录
- 1、环境配置(亲测可用)
- 2、下载安装
- 1.CUDA 11.2
- 2.OpenCV
- 3、编译Darknet
- 1.下载安装VS Code
- 2.本地代码与github同步
- 3.编译
- 4、准备数据
- 1.生成标注文件(txt)
- 2.修改配置文件
- 5、训练模型
- 6、测试模型
1、环境配置(亲测可用)
- Ubuntu 20.04
- CUDA 11.2
- cuDNN
- OpenCV_contrib 4.3.0
- OpenCV 4.3.0
2、下载安装
1.CUDA 11.2
- CUDA下载链接:官网下载
百度网盘链接 提取码:9oi5 - CUDA安装
a.禁用集成的nouveau驱动
gedit打开blacklist.conf
sudo gedit /etc/modprobe.d/blacklist.conf
blacklist.conf末尾添加:
blacklist nouveau
options nouveau modeset=0
更新系统
sudo update-initramfs -u
重启系统
reboot
验证nouveau是否禁用(没有任何输出说明已经禁用)
lsmod | grep nouveau
b.运行cuda文件
sudo sh cuda_11.2.0_460.27.04_linux.run
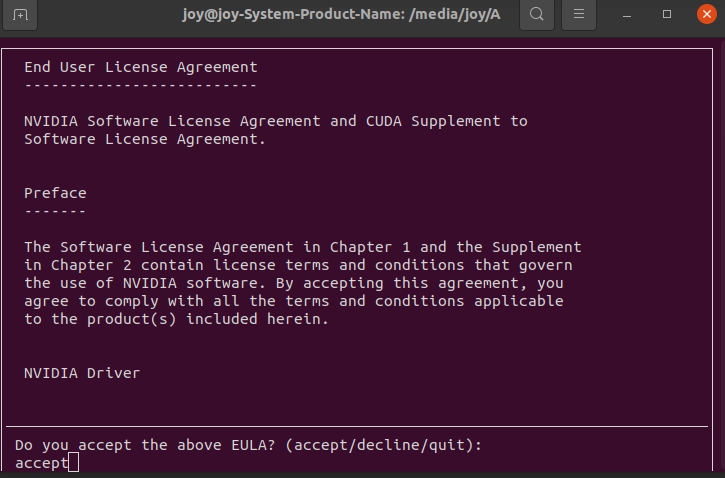
如果之前已经安装过显卡驱动,这里就不需要选择第一个了
Install
添加环境变量
sudo gedit ~/.bashrc
在最后一行加上
export PATH=/usr/local/cuda-11.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.2/lib64:$LD_LIBRARY_PATH
激活环境变量
source ~/.bashrc
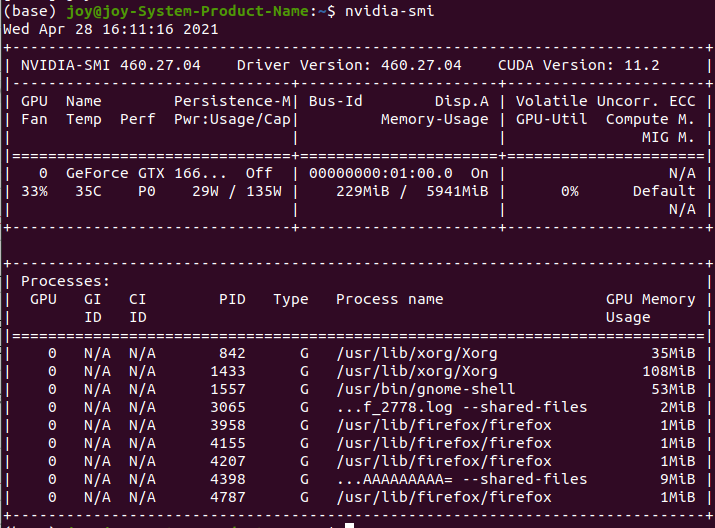
检测是否安装成功
nvidia-smi
nvcc -V

- cuDNN下载链接:官网下载(需要登录)
百度网盘链接 提取码:80rv - 解压cuDNN压缩包,并在文件夹下的cuda文件夹下打开终端

将include和lib64文件夹下的内容复制到CUDA安装目录下对应名称的文件夹下
sudo cp -r include/* /usr/local/cuda/include/
sudo cp -r lib64/* /usr/local/cuda/lib64/
2.OpenCV
- 参考:OpenCV官网 友友的博客
- a.安装依赖
$ sudo apt-get install -y build-essential checkinstall cmake pkg-config yasm git gfortran
# 添加源,防止可能会出现的找不到所需安装的库的情况
$ sudo add-apt-repository -y "deb http://security.ubuntu.com/ubuntu xenial-security main"
$ sudo apt-get update
$ sudo apt-get install -y libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev
$ sudo apt-get install -y libjpeg8-dev libjasper-dev libpng12-dev libtiff5-dev libavcodec-dev libavformat-dev libswscale-dev libdc1394-22-dev libxine2-dev libv4l-dev
$ sudo apt-get install -y libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libgtk2.0-dev libtbb-dev libatlas-base-dev libfaac-dev libmp3lame-dev libtheora-dev libvorbis-dev libxvidcore-dev libopencore-amrnb-dev libopencore-amrwb-dev x264 v4l-utils
-
b.下载两个安装包
OpenCV_contrib 4.3.0 github下载
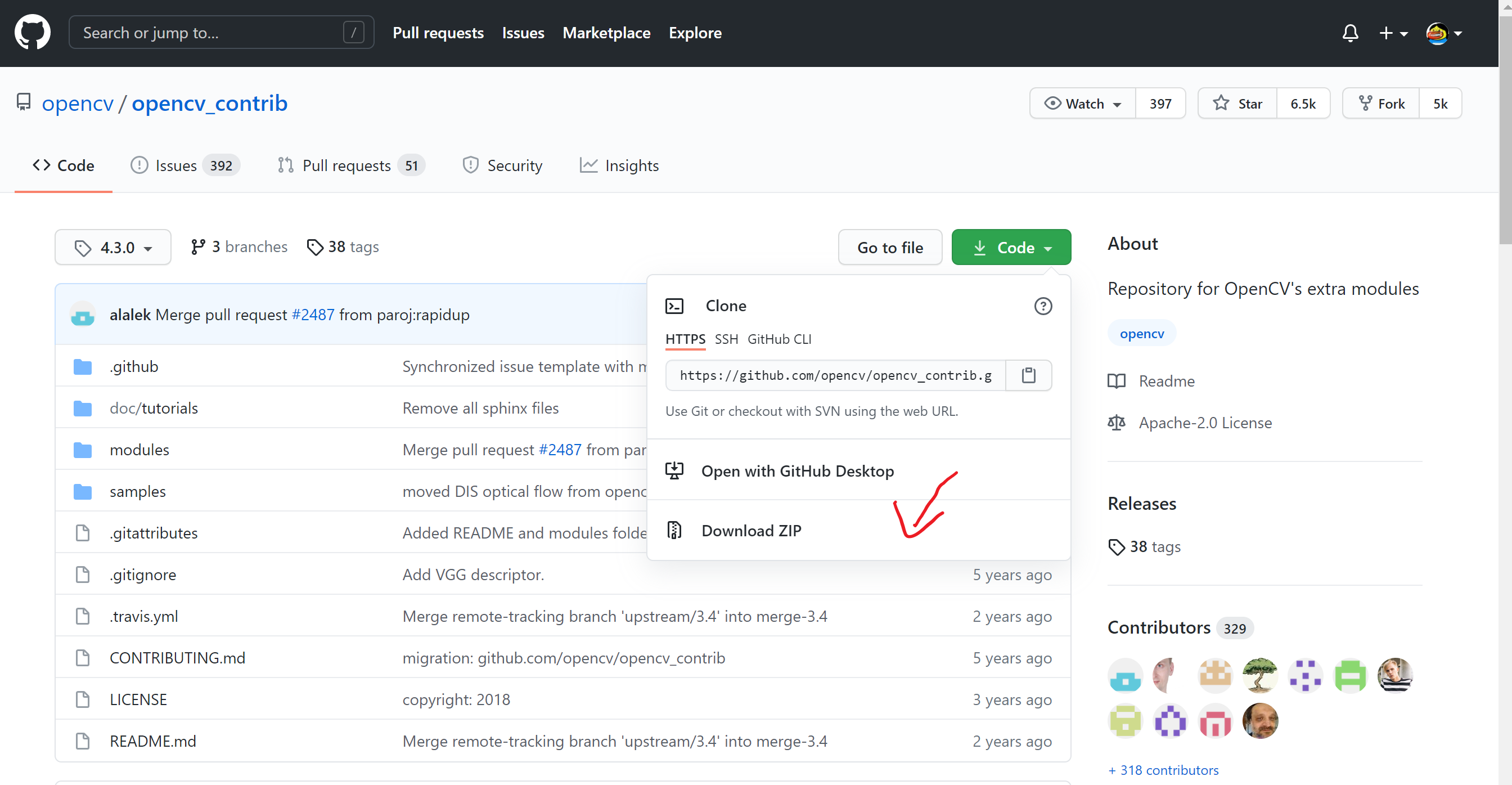
OpenCV 4.3.0 官网下载
-
c.解压下载的两个压缩包,并在opencv-4.3.0文件夹下新建一个build文件夹
-
d.安装cmake-gui

-
e.
设置Where is the source code为 /home/joy/下载/opencv-4.3.0(安装包所在位置)
设置Where to build the binaries为 /home/joy/下载/opencv-4.3.0/build
点击Configure
点击Generate

-
f.点击Finsh
-
g.选择需要的参数(✔或者选择路径)
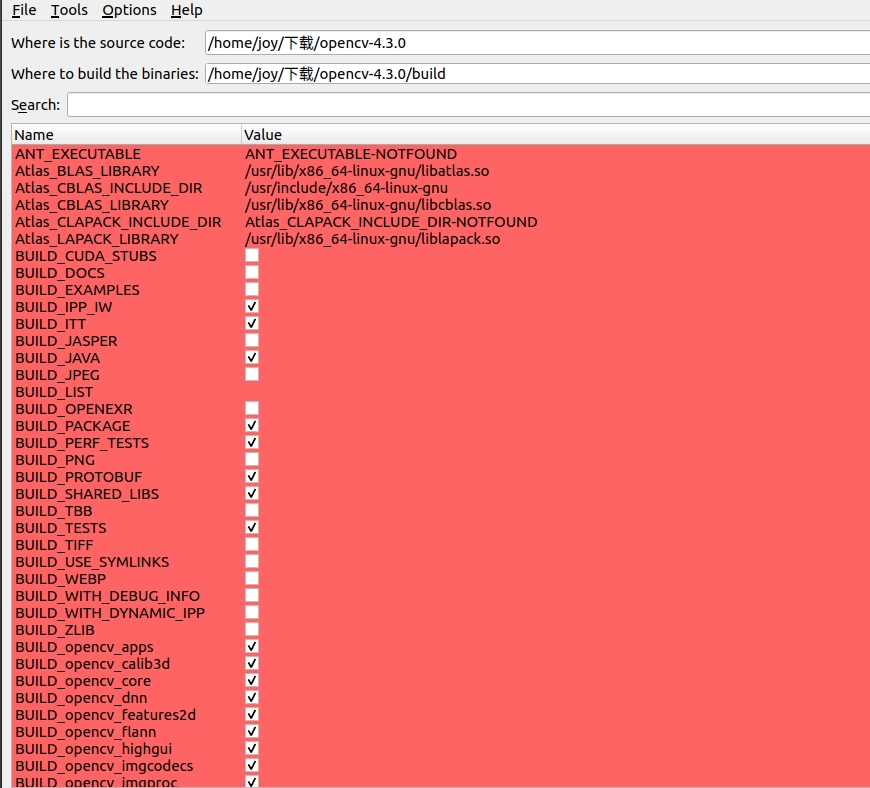
官方参数说明,友友们根据需要选择
CMAKE_BUILD_TYPE = RELEASE
WITH_QT = √ #使用QT支持
WITH_OPENGL = √ #
OPENCV_EXTRA_MODULES_PATH= /home/joy/opencv-4.3.0/build #opencv_contrib modules路径
-
h.点击Configure

如果报错提示缺少xxx包
参考:https://blog.csdn.net/a985588764/article/details/103494670
https://blog.csdn.net/AlexWang30/article/details/99612188 -
i.Config成功后点击Generate
-
j.make编译安装
#使用nproc确定CPU核心数
$ nproc
$ make -j6 #根据CPU核心数确定编译线程数
$ sudo make install #安装
3、编译Darknet
1.下载安装VS Code
官网下载
2.本地代码与github同步
根据需要选择,不需要的也可以直接在AlexeyAB的仓库中下载压缩包在VS Code中打开
-
a.安装插件

-
b.登录github

-
c. fork yolov4仓库并克隆到VS Code中,选择一个文件夹保存到本地


-
现在就可以愉快的commit、push到远程github仓库上了
3.编译
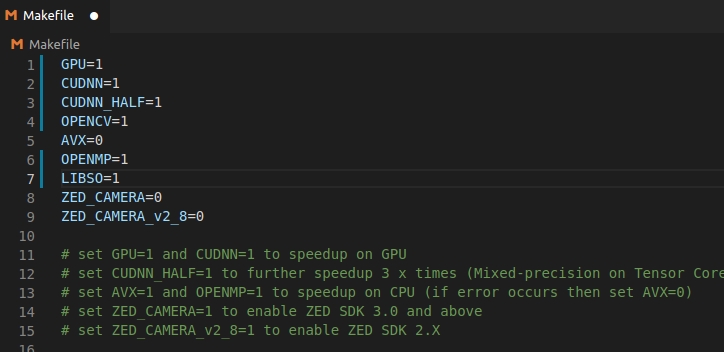
- 编辑Makefile文件
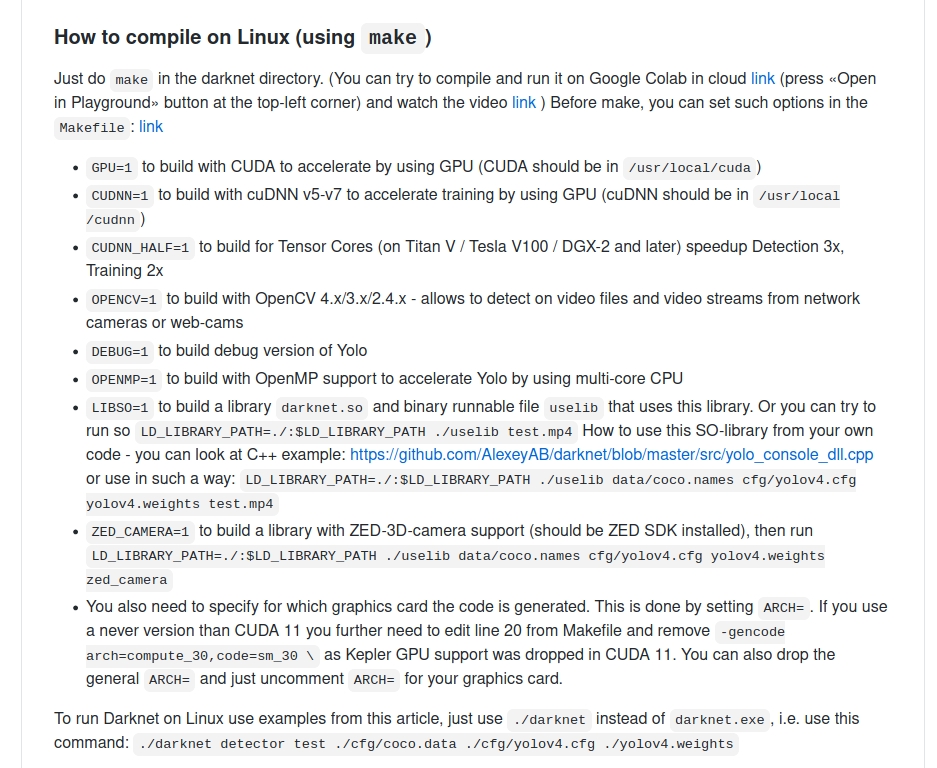
Makefile官方说明
- make编译

编译成功后会生成如图darknet文件

4、准备数据
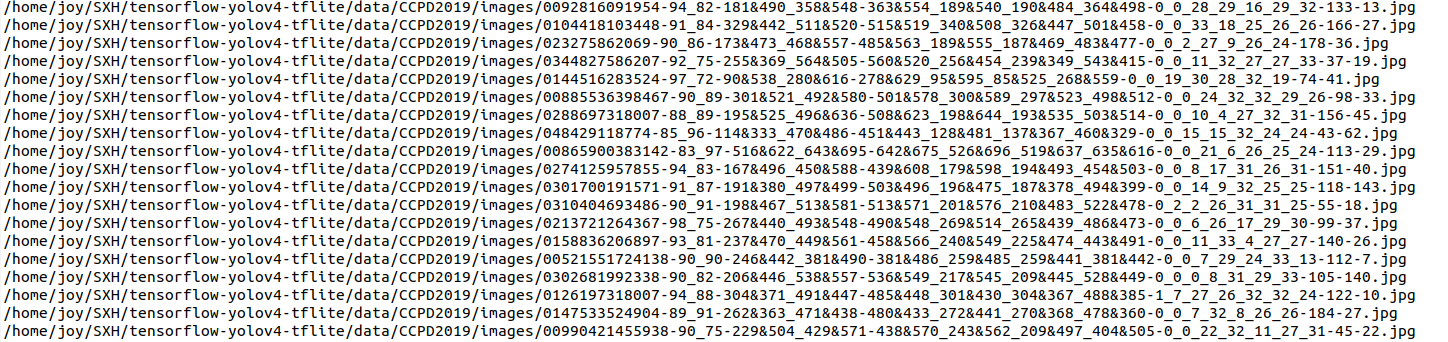
1.生成标注文件(txt)
标注框信息从图片名称中提取,而由于只有一个类(plate),默认标签为0,图片和txt文件要放在一个文件夹下
import os
import re
import cv2
root_path = r'/home/joy/SXH/tensorflow-yolov4-tflite/data/CCPD2019/images/' # 根据本地自己路径进行更改
file_name = os.listdir(root_path)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
for image_id in file_name:
id = image_id.split('.')[0]
out_file = open('/home/joy/SXH/tensorflow-yolov4-tflite/data/CCPD2019/images/%s.txt' % id,
'w') # 需要保存的txt格式文件路径
img = cv2.imread((root_path + image_id))
height = img.shape[0]
width = img.shape[1]
point = image_id.split('.')[0].split('-')[3]
# Xmin = point.split('_')[2].split('&')[0]
num = re.findall('\d+\d*', point) # 正则表达式 从字符串中提取数值
Xmin = min(num[0::2]) # list[start:stop:step]
Ymin = min(num[1::2])
Xmax = max(num[0::2])
Ymax = max(num[1::2])
b = (float(Xmin), float(Xmax), float(Ymin),
float(Ymax))
bb = convert((width, height), b)
out_file.write('0' + " " + " ".join([str(a) for a in bb]) + '\n')
print('end')
2.修改配置文件
- a.生成plate_train.txt和plate_val.txt
复制/CCPD2019/splits/下的两个txt文件到darknet/data/下并分别改名为plate_train.txt和plate_val.txt
修改txt文件内的路径为自己的本地数据集路径(相对路径和绝对路径都可以)

- b.在darknet/data/下新建plate.data文件
classes = 1 #类别数量
train = data/plate_train.txt
valid = data/plate_val.txt
#valid = data/coco_val_5k.list
names = data/plate.names
backup = backup/ # 保存模型的位置
- c.在darknet/data/下新建plate.names文件
plate
- d.复制darknet/cfg/下yolov4-custom.cfg文件到darknet文件夹下,并重命名为yolov4-plate.cfg
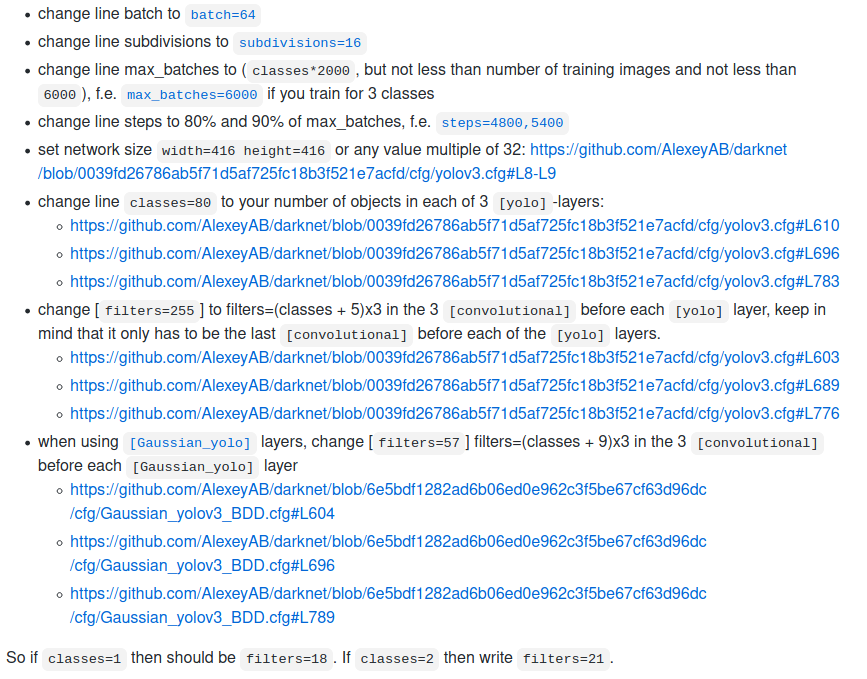
- e.修改yolov4-plate.cfg文件
官方说明
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=32 # 如果显存不够就调小一点
subdivisions=64
width=512
height=512
max_batches = 6000
policy=steps
steps=4800,5400
scales=.1,.1
#cutmix=1
mosaic=1
#:104x104 54:52x52 85:26x26 104:13x13 for 416
共三处如下图片修改(一样的内容)
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 0,1,2
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=1
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.2
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5
- f.下载预训练模型
百度网盘链接
提取码:1plh
5、训练模型

./darknet detector train data/plate.data yolov4-plate.cfg yolov4.conv.137 -map
如图表示开始训练
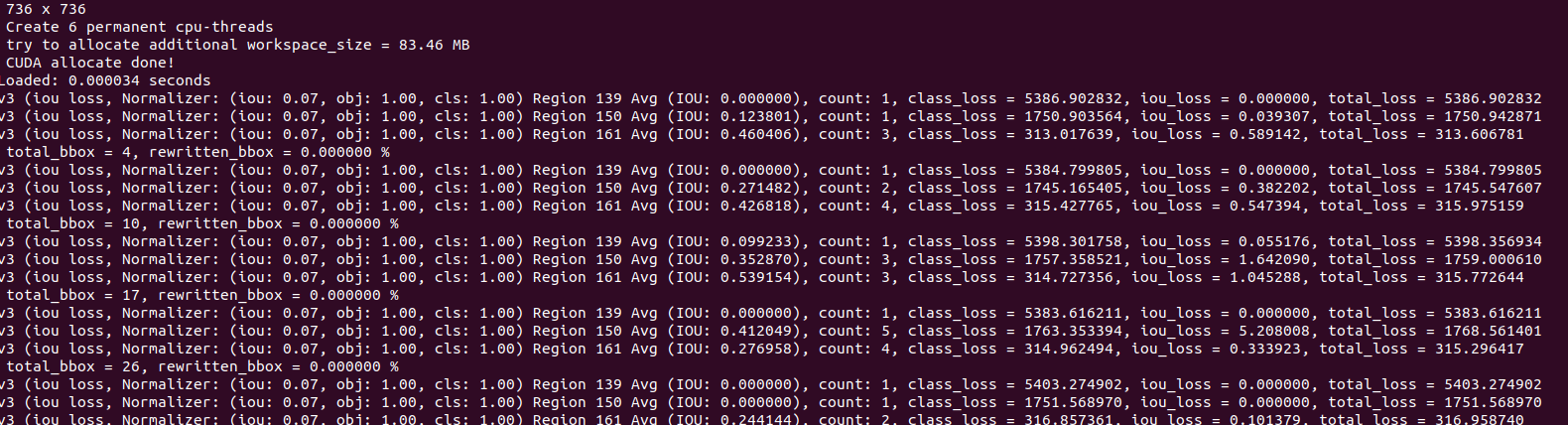 训练结束(模型保存在darknet/backup/文件夹下)
训练结束(模型保存在darknet/backup/文件夹下)

6、测试模型
修改yolov4-plate.cfg文件
[net]
# Testing
batch=1
subdivisions=1
# Training
#batch=32
#subdivisions=64
width=512
height=512
channels=3
测试命令
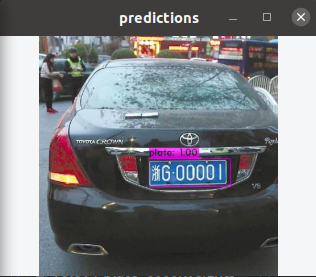
./darknet detector test data/plate.data yolov4-plate.cfg backup/yolov4-plate_best.weights
输入测试图片路径
 输出结果
输出结果