
string的学习会分为两个大步骤,第一步就是会使用string,第二部是模拟实现string。这篇文章我们介绍一下string类以及它的使用。string大概有一百多个接口,我们需要重点掌握的就十几二十个。string其实就是字符串,严格来说string类是一个管理字符串的类,它就是一个字符顺序表。
1.标准库中的string类
下面是string类的文档介绍。
cplusplus.com/reference/string/string/?kw=string https://cplusplus.com/reference/string/string/?kw=string
https://cplusplus.com/reference/string/string/?kw=string
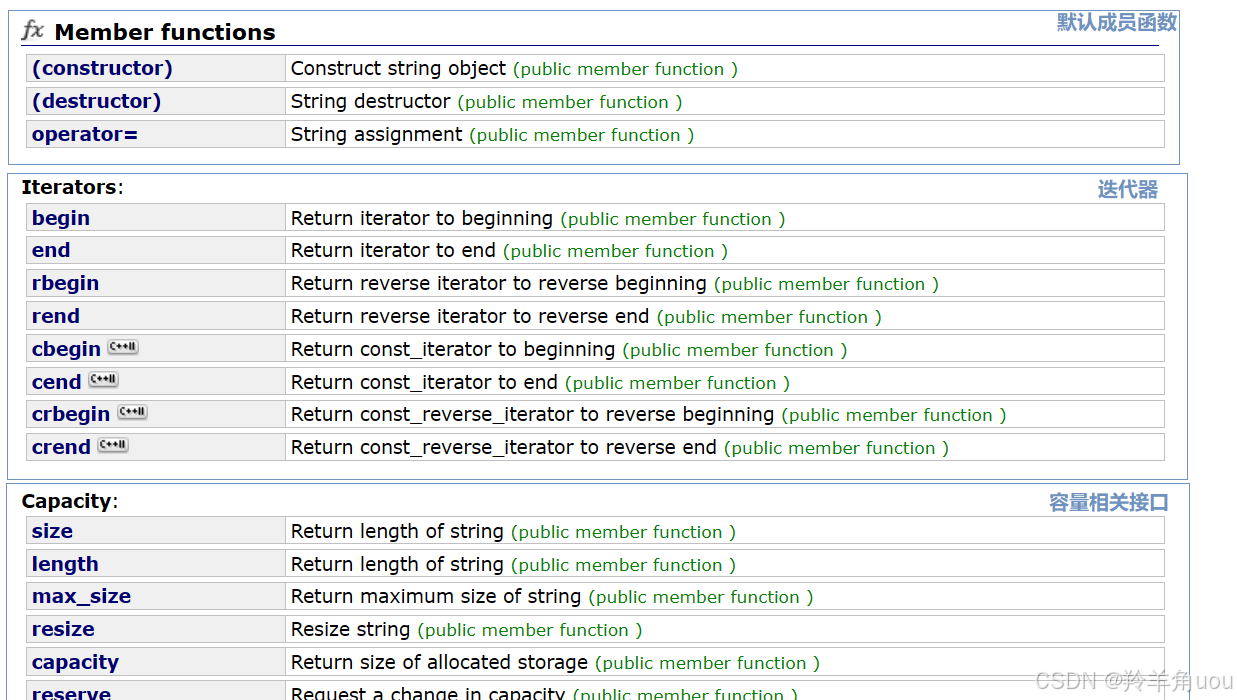
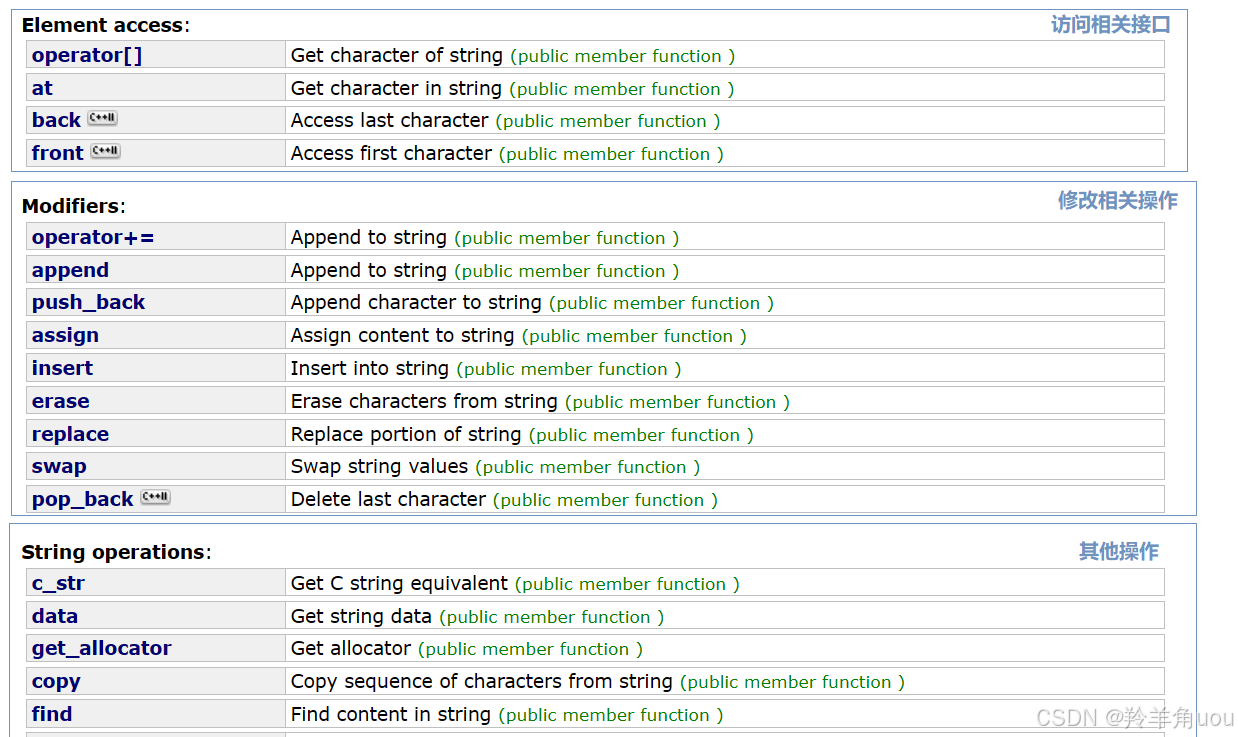
string其实是typedef出来的,原型是basic_string<char>,除了char类型其实还有其他的,只是不常用,了解一下即可。


2.string类的常用接口说明
2.1 string类对象的常见构造
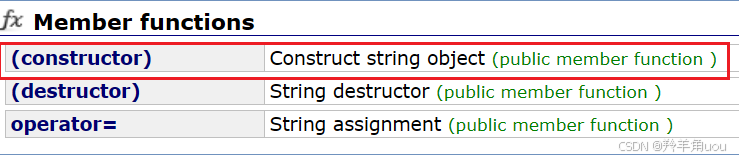

文档里C++98就提供了7种构造函数接口,重点有三个。

我们现在把这三种方式使用一下。
#include <iostream>#include <string> //头文件using namespace std;int main(){string s1; //默认构造string s2("111111"); //带参构造string s3(s2); //拷贝构造return 0;}string是重载了流插入和流提取的,所以是可以直接用的。

string s1; //默认构造string s2("111111"); //带参构造string s3(s2); //拷贝构造cout << s2 << endl; //流提取cout << s3 << endl;cin >> s1; //流插入cout << s1 << endl;
输入中文也可以。

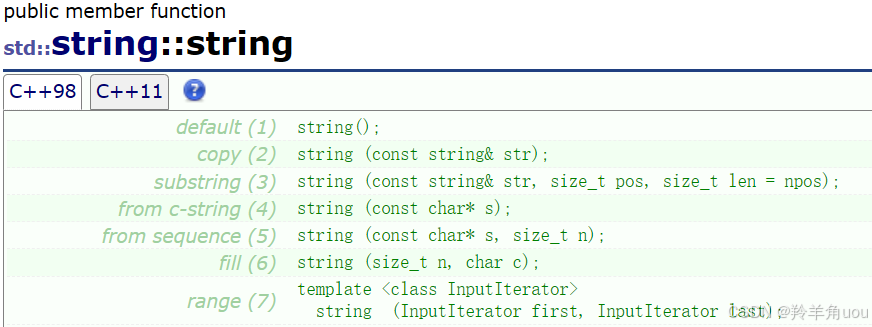
2.2 其他构造函数(简单介绍)
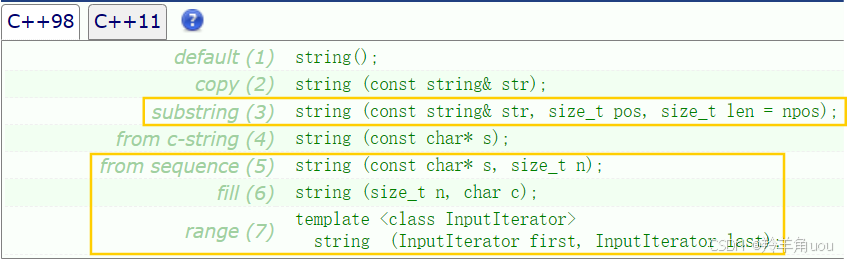

来看(3)string (const string& str, size_t pos, size_t len = npos); 它可以算是拷贝构造(2)的一个变型,和(2)对比着来看,(2)是全部拷贝,(3)就是拷贝一部分。
从pos这个位置开始,拷贝len的长度过去。
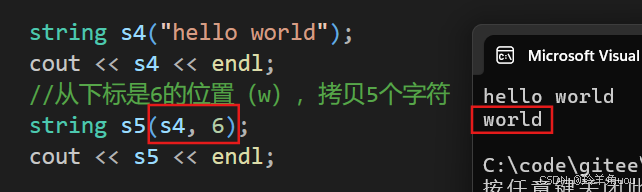
string s4("hello world");cout << s4 << endl;//从下标是6的位置(w),拷贝5个字符string s5(s4, 6, 5);cout << s5 << endl;
如果len比剩余字符大,不会报错,会默认拷贝到字符串结束 。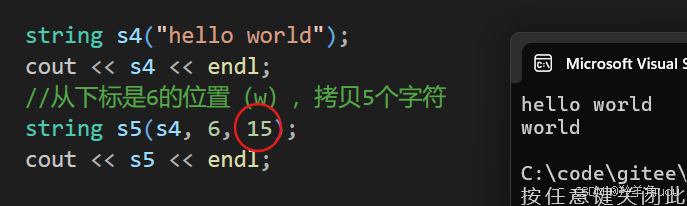
不传第三个参数,也是默认拷贝到字符串结束 。
我们可以点进这个npos看一下是什么。

 这里想表达的意思就是,字符串有多长取多长。
这里想表达的意思就是,字符串有多长取多长。
来看(5)string (const char* s, size_t n); 它其实可以看成(4)的变形。
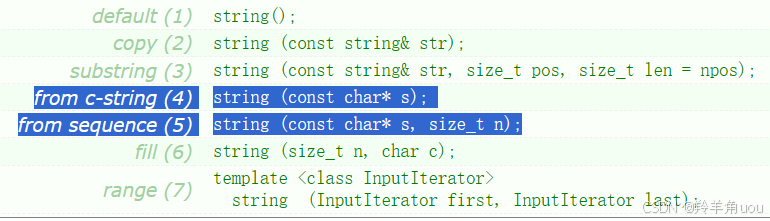
取字符串s的前n个初始化。
//取hello world的前6个字符初始化string s6("hello world", 6);cout << s6 << endl;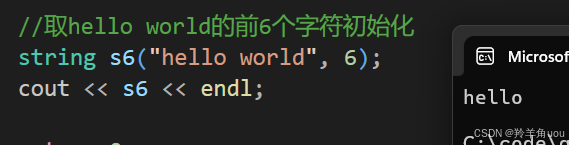
来看(6)string (size_t n, char c);
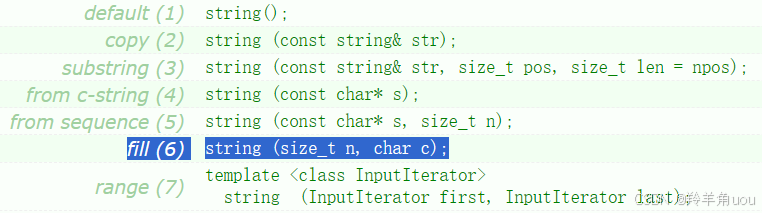
取n个c字符初始化。
string s7(3, 'a');cout << s7 << endl;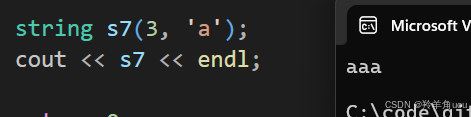
2.3 析构函数
string类里的析构函数是自动调用的,我们不需要管。


2.4 string类对象的容量操作
有星号的为重点。
2.4.1 size和length
size和length返回字符串有效字符长度,它们两个基本没什么区别。那为什么同样的东西有两个?这就跟C++的发展历史有关了,感兴趣的可以去了解一下,这里就不多说了。
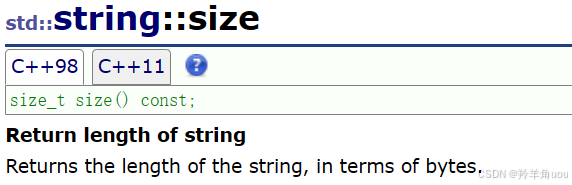
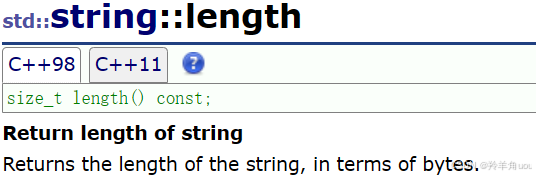
//获取长度string s8("hello world");cout << s8.length() << endl;cout << s8.size() << endl;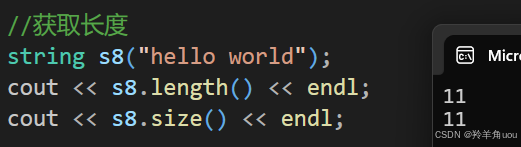
我们以后经常用到的是size。
2.4.2 capacity

我们前面写的数据结构都了解过capacity的含义,所以在这里capacity也很好理解,就是容量。
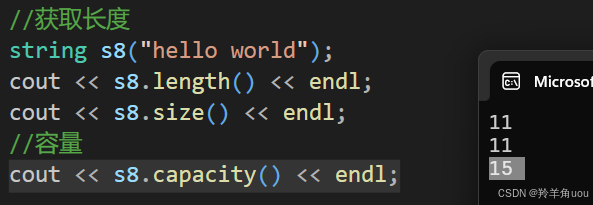
这里我们可以了解一下vs编译器下如何扩容,看下面一段代码。
void TestPushBack(){string s;size_t sz = s.capacity(); //保存之前容量cout << "capacity changed: " << sz << '\n';cout << "making s grow:\n";for (int i = 0; i < 100; ++i){s.push_back('c');if (sz != s.capacity()) //capacity变化了,打印一下之前的容量大小{sz = s.capacity();cout << "capacity changed: " << sz << '\n';}}}int main(){TestPushBack();return 0;}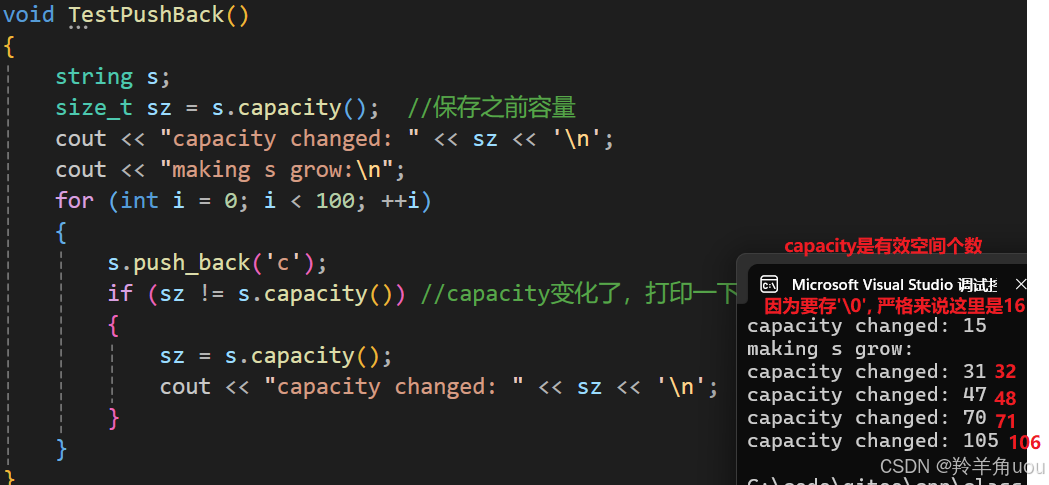
初始空间大小是15,第一次扩容,是2倍扩,从16到32,后面就是1.5倍扩。
vs下做了特殊处理,对小于16个空间时,vs把内容存到了一个_Buf里,这个buff也并不在堆上,大于16字节之后,_Buf就废弃了,vs重新在堆上开辟一块空间存数据。所以第一次扩容是二倍扩就是因为数据从一个地方到了另一个空间,后面就都是1.5倍扩容,所以整体来看,vs下的扩容是1.5倍扩。这是vs自己的设计,不同编译器的扩容不同。了解一下即可。
2.4.3 reserve和resize
频繁的扩容其实是不好的,扩容也是一种消耗。解决方法就是用reserve和resize。常用的是reverse。

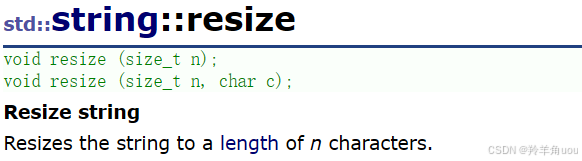
reserve支持我们给一个n,提前开好空间。这里的规定就是,开的空间只能大于等于n,不能少于n。vs下选择开比100大的,别的编译器可能就是刚好开100。

这里开空间是不包含'\0'的,所以实际最少最少开101字节,但是string这个capacity返回的大小都不包含'\0'的。
提前开空间可以减少扩容。
但是reserve还有可能会缩容。这取决于编译器。

文档的意思就是:n大于或等于capacity就行,其他情况(就是小于)下capacity是否会缩小自己,是不一定的。但是capacity一定不会对string的内容和length造成影响。
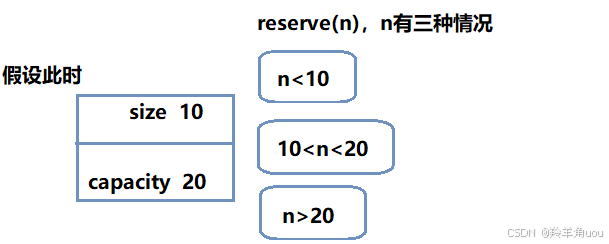
n<10和n>20是确定的,前者一定不会变,capacity不会缩的小于size,后者一定会变,变成n的大小,现在不确定的就是10<n<20的情况。
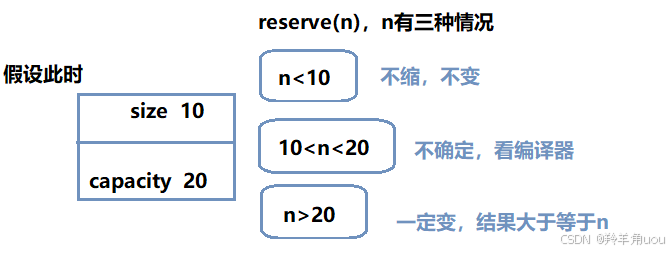
在vs上验证一下。
string s1("aaaaaaaaaaaaaaaaaa");cout << s1.size() << endl;cout << s1.capacity() << endl;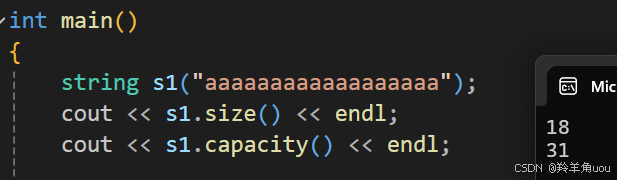
然后reserve一个比size(18)小的数。
s1.reserve(17);cout << s1.size() << endl;cout << s1.capacity() << endl; 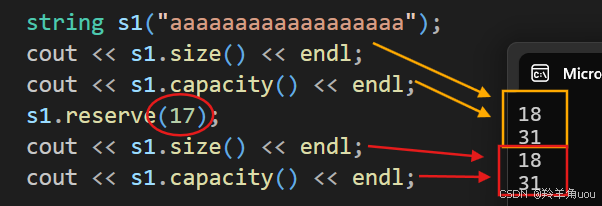
vs下结果不变。我们再给18到31之间的值。
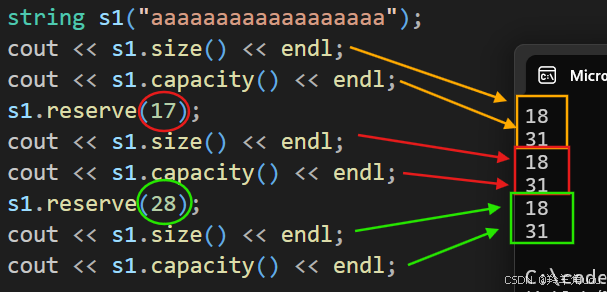
vs下选择不缩小,不同的编译器处理方式会不同。我们再给比capacity(31)大的值。
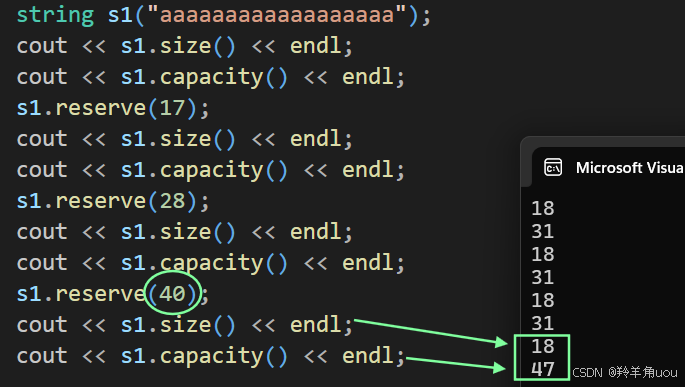 vs下结果是一定会扩的大于n。
vs下结果是一定会扩的大于n。
2.4.4 clear和empty
clear就是把数据清除,有的编译器可能还会把容量也清除了,一般不清容量。
直接上代码演示。
string s1("aaaaaaaaaaaaaaaaaa");cout << s1.size() << endl;cout << s1.capacity() << endl;s1.clear();cout << s1.size() << endl;cout << s1.capacity() << endl;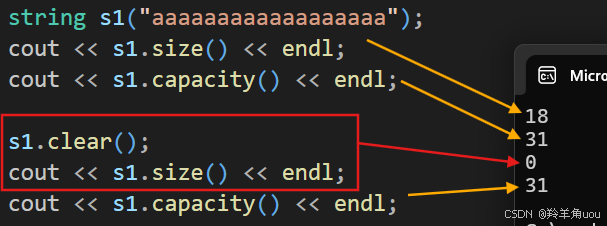
empty就是判空,这没啥多说的。

2.5 string类对象的访问及遍历操作
2.5.1 operator[]


有了operator[]我们就可以访问pos位置的字符,就像我们在使用数组。同时也方便我们对其修改。
string s7(10, 'x');cout << s7 << endl;//访问下标为5的字符,并且修改它s7[5] = 'b';cout << s7 << endl;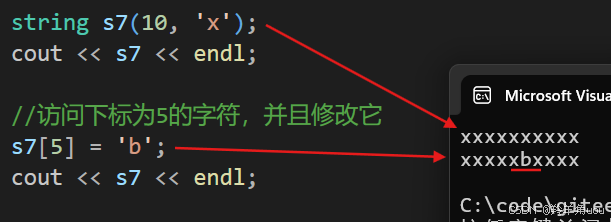
数组的越界C++的检查是不确定的,有了operator[],如果我们越界访问,是一定会被检查出来的。
string s7(10, 'x');cout << s7 << endl;//越界访问s7[11] = 'b';cout << s7 << endl;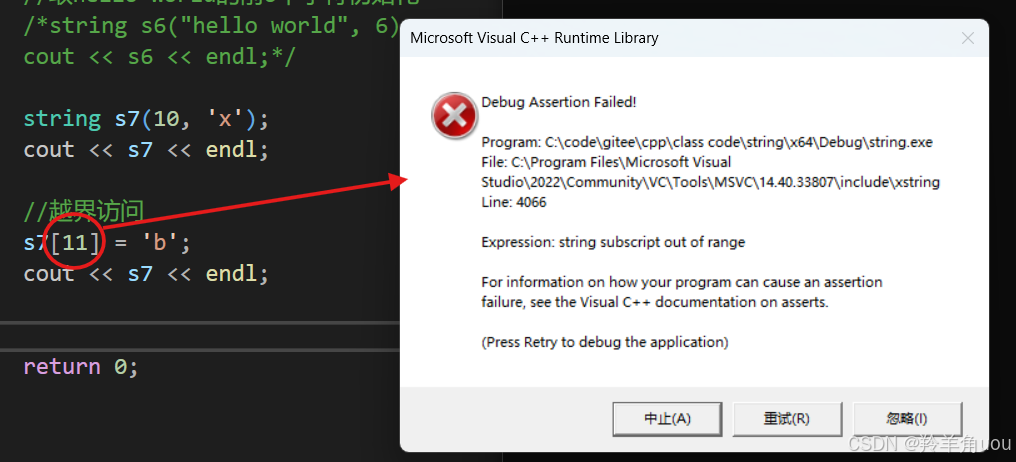
有了[]的重载,我们就可以配合size对这个字符串进行遍历。
//下标+[]的遍历方式string s8("hello world");for (int i = 0; i < s8.size(); i++){cout << s8[i] << " ";}cout << endl;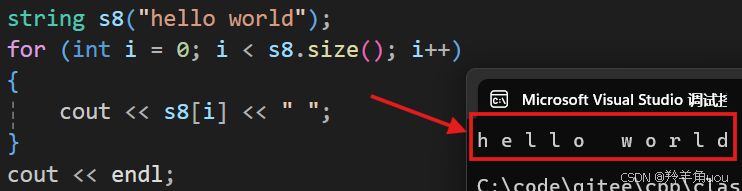
2.5.2 迭代器 begin+end
除了上面这种下标+[]的遍历方式,string还支持迭代器的方式进行遍历。迭代器是我们前面提到过的STL六大组件其中一个,可以用来遍历和访问容器。先看下面代码,后面会解释。
//迭代器遍历string s8("hello world");string::iterator it = s8.begin();while (it != s8.end()){cout << *it << " ";++it;}cout << endl;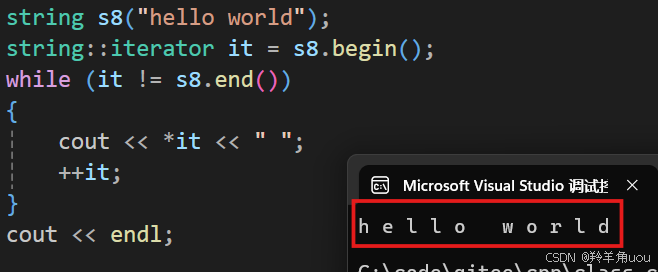
现在来对这几行代码进行一个解释。


迭代器提供了一种通用的访问方式,所有的容器都可以用iterator访问,所有容器都有自己的iterator。begin和end在文档的iterators这个位置。
 更详细的介绍自己去文档里看一下,这里就不细说了。
更详细的介绍自己去文档里看一下,这里就不细说了。
2.5.3 auto和范围for
C++11里面提供的遍历方式,叫范围for,所有容器也都可以用它遍历。先看代码。
//范围forstring s8("hello world");for (auto ch : s8){cout << ch << " ";}cout << endl;
现在来解释一下这个范围for和auto。
范围for自动从s8这个容器获取每一个字符,给ch这个变量,ch变量的类型是auto,auto的意思就是自动推导,自动推导ch的类型。当然把auto换成char也可以。
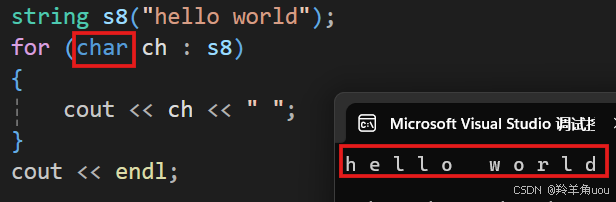
只要类型匹配就行,auto就是自动匹配类型。范围for自动赋值,自动迭代,自动判断结束,它的底层就是迭代器。
这里要注意,范围for改变不影响容器的值。
string s8("hello world");string::iterator it = s8.begin();while (it != s8.end()){*it += 2; //把所有字符加2cout << *it << " ";it++;}cout << endl;for (char ch : s8){ch -= 2; //还原所有字符cout << ch << " ";}cout << endl;cout << s8 << endl; //s8还原了吗??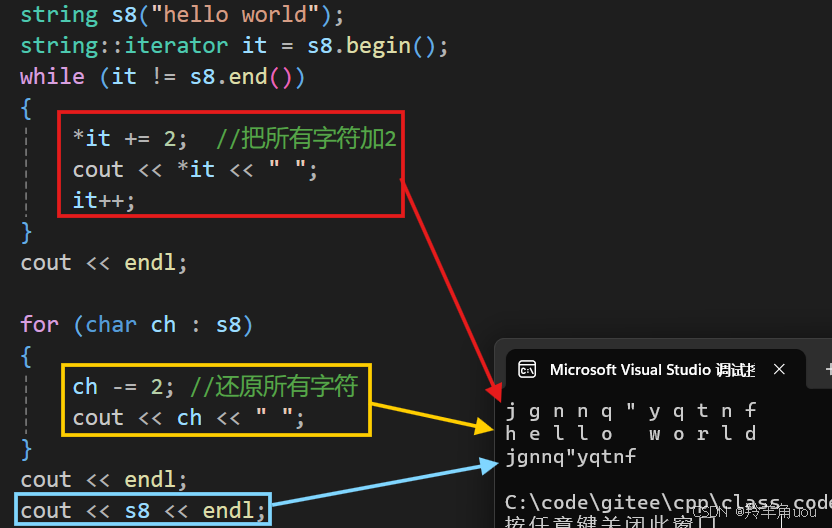
我们一顿操作之后发现,s8在迭代器里改变了,范围for里并没有被还原。
前面说过,范围for底层就是迭代器,范围for部分的代码从迭代器角度理解就相当于我们把*it给给了ch,而ch只是string里面每个字符的拷贝,相当于ch只是一个局部变量,我们只是修改了这个局部变量,并没有修改string里面对应的字符。迭代器为什么可以修改?迭代器可以想象成是一个像指针的东西,*it就是string里的一个字符,直接修改。
如果范围for想修改s8,我们可以引用传参。如下。
for (auto& ch : s8) //引用传参,参数类型自动推导{ch -= 2; //还原所有字符cout << ch << " ";}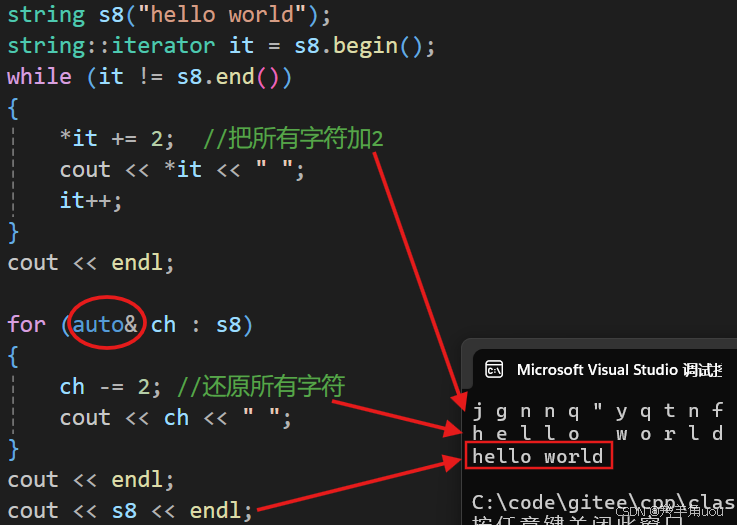
前面提到的三种遍历方式没特别大的区别,按需使用。
范围for遍历数组是非常方便的,如下。
for (auto a : arr) //不做修改 cout << a << " "; //要修改就引用传参
在这里补充2个C++11的小语法,方便我们后面的学习。
·在早期 C/C++ 中 auto 的含义是:使用 auto 修饰的变量,是具有自动存储器的局部变量,后来这个 不重要了。 C++11 中,标准委员会变废为宝赋予了 auto 全新的含义即: auto 不再是一个存储类型 指示符,而是作为一个新的类型指示符来指示编译器, auto 声明的变量必须由编译器在编译时期 推导而得 。 ·用 auto 声明指针类型时,用 auto 和 auto* 没有任何区别,但用 auto 声明引用类型时则必须 加 &。 ·当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译 器实际 只对第一个类型进行推导,然后用推导出来的类型定义其他变量 。 ·auto 不能作为函数的参数,可以做返回值,但是建议谨慎使用。 ·auto 不能直接用来声明数组。
2.5.4 反向迭代器rbegin
前面说到的迭代器是正向迭代器,string里还有反向迭代器rbegin。
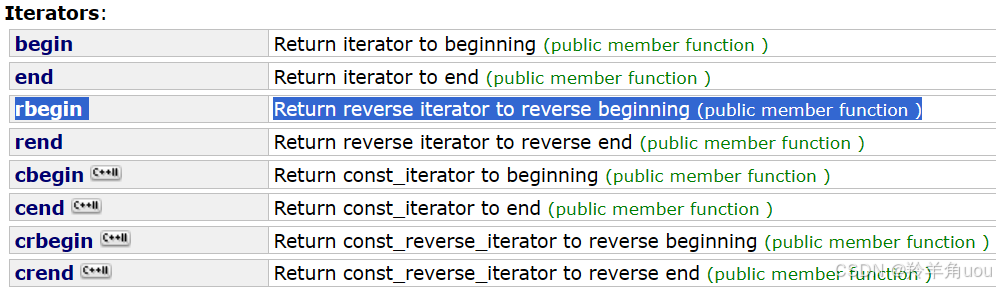
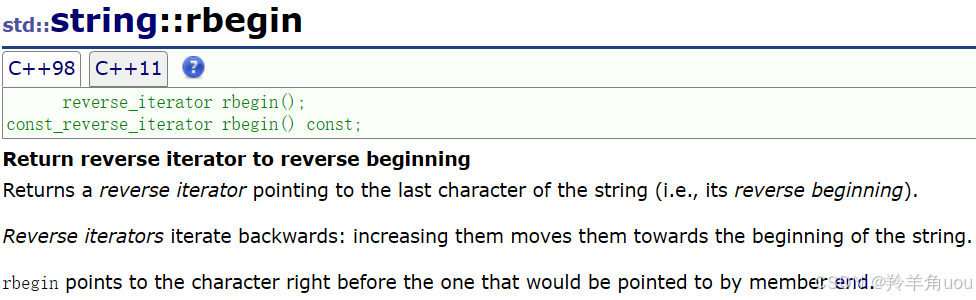
先看一下反向迭代器的使用效果。
//反向迭代器string::reverse_iterator rit = s8.rbegin();while (rit != s8.rend()){cout << *rit << " ";rit++; //这里还是++不是--}cout << endl;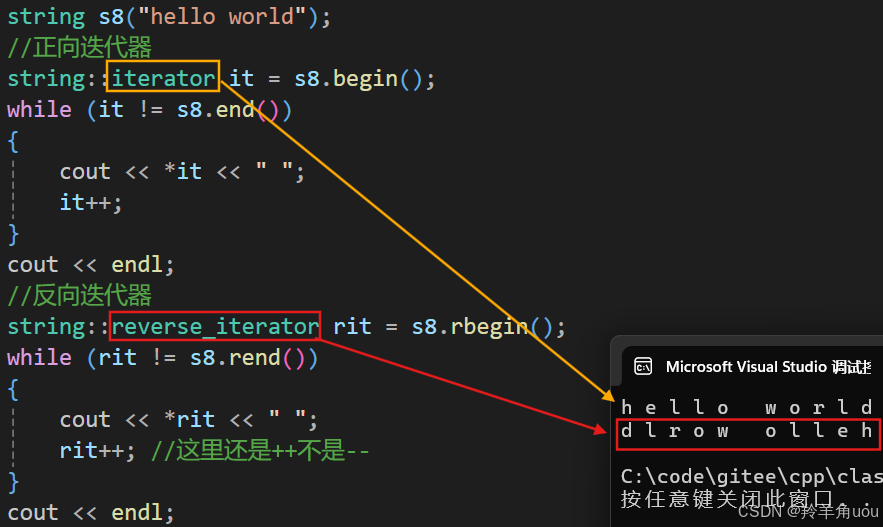
来解释一下反向迭代器。 只是简单像下面这样理解。

这里的rit已经不是原生指针了,指针++绝对不会是倒着加。现在我们只需要知道、会用反向迭代器就行。

还有一种情况就是const修饰的string。仔细看迭代器其实给了两种情况,拿begin举例。
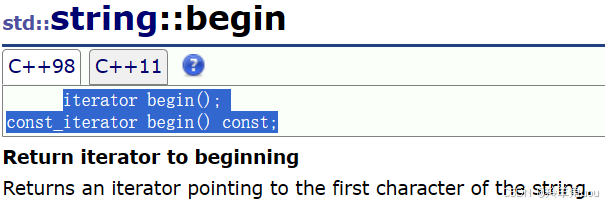
普通对象返回普通迭代器,const对象返回const迭代器。const迭代器的特点就是只能读不能写。
const string s9("hello world");string::const_iterator cit = s9.begin();while (cit != s9.end()){cout << *cit << " ";//只读++cit; //自己可以改,s9不可以改}总结:
迭代器有4种:
iterator (正向迭代器,最常见)
const_iterator ( const正向迭代器)
reverse_iterator (反向迭代器)
const_reverse_iterator (const反向迭代器)
3.string类对象的修改操作
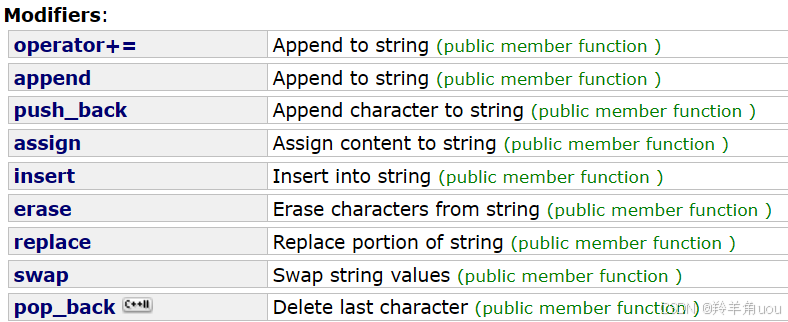
我们就说一下用的比较多的接口。
3.1 operator+=

这个接口可以尾插一个字符,或者一个字符串,或者一个对象。
string s1("hello world!");string s2("qqqqqqq");s1 += 'x'; // 尾插一个字符s1 += "yyyyy"; //尾插一个字符串s1 += s2; //尾插一个对象cout << s1 << endl;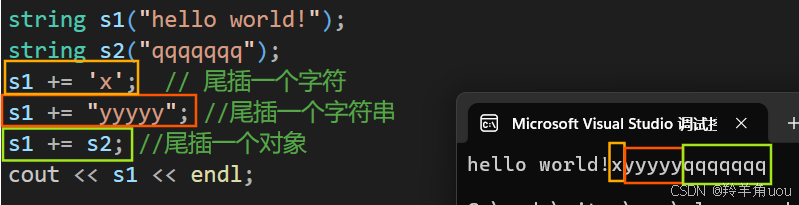
在实践中直接用这个接口尾插就行。
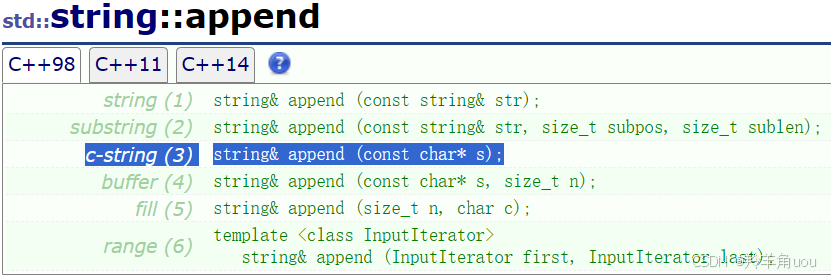
3.2 append 和 push_back
这两个接口也是尾插的,了解一下即可,我们一般就用前面介绍的operator+=。
push_back是尾插一个字符。

append是尾插一个字符串,对象,对象的一部分等等,详细的看文档。
string s1("hello world!");s1.push_back('q'); //尾插一个字符s1.append("xxxxxx"); //尾插字符串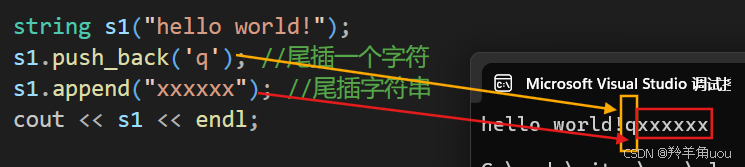
常用的用法就是上面这样,append的其他接口基本不咋用。
3.3 insert
这是插入数据的接口,提供了7个,不过大部分用的不多。

常用的用法就两个,用这个头插,或者字符串中间位置插入数据。其他接口用的不多。
string s1("hello world!");cout << s1 << endl;s1.insert(0, 2, 'a'); //在下标为0的位置开始插入2个acout << s1 << endl;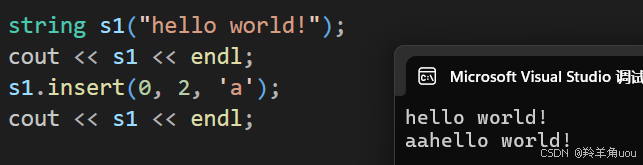
string s1("hello world!");cout << s1 << endl;s1.insert(0, 2, 'a'); cout << s1 << endl;s1.insert(8, 4, 'x');cout << s1 << endl;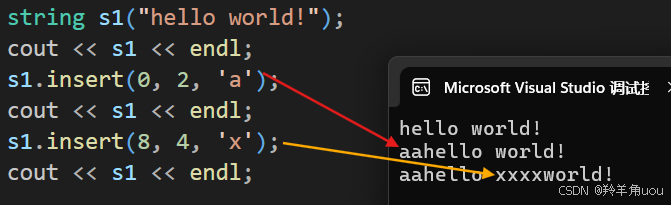
但是头插和中间插入的使用需谨慎,我们学过顺序表可以知道,头插或者中间插入需要把后面的数据都往后移动,如果空间不够还要扩容。
在使用这些接口的时候,不确定用法就看文档介绍。
3.4 erase
erase是用来删除数据的。

在实践中用的最多的还是第一个接口:从pos的位置开始删除npos个数据。
string s1("hello world");s1.erase(6, 1); //从下标为6的位置,删除1个数据cout << s1 << endl; 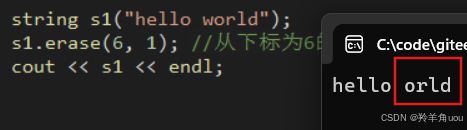
如果我们要头删,如下。
s1.erase(0, 1); //头删 cout << s1 << endl;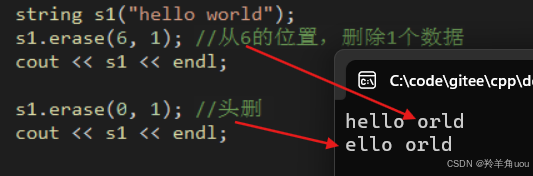
这个接口的npos也是缺省参数,pos位置后面字符剩多少就是多少 。
如果我们想把pos位置之后的全删了,第二个参数可以不传,就用npos的缺省值。
string s1("hello world");s1.erase(6); //从6的位置开始后面全删除 cout << s1 << endl;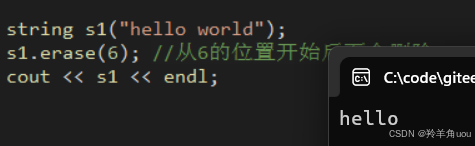
还提供了一个迭代器的版本,就是(3).

用迭代器版本头删也可以。
s1.erase(s1.begin()); //迭代器版头删 cout << s1 << endl;
用迭代器版本尾删也可以。
s1.erase(--s1.end()); //迭代器版尾删 cout << s1 << endl;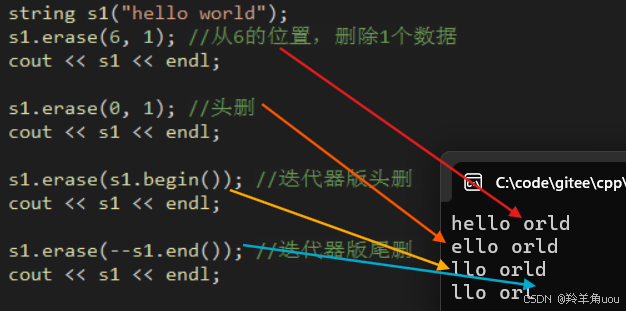
注意括号里是s1.end()的前置减减,因为end()返回的是最后一个字符的下一位,减减end()才是返回最后一个字符。
//迭代器版尾删另一种写法s1.erase(s1.size()-1, 1);
3.5 replace
replace就是替换,它提供的接口也是非常多。

大概就是我们可以把pos位置开始的len个字符替换字符串、字符串的一部分,对象,对象的一部分,迭代器,迭代器的一部分。来简单运用一下。
少被替换多
string s1("hello world");//把5位置开始的1个字符替换成2个%s1.replace(5, 1, "%%");cout << s1 << endl; 
多被替换少
string s1("hello world");s1.replace(5, 1, "%%");cout << s1 << endl;//把0开始的4个字符替换成3个xs1.replace(0, 4, "xxx");cout << s1 << endl;
等大小替换
s1.replace(0, 3, "yyy");cout << s1 << endl;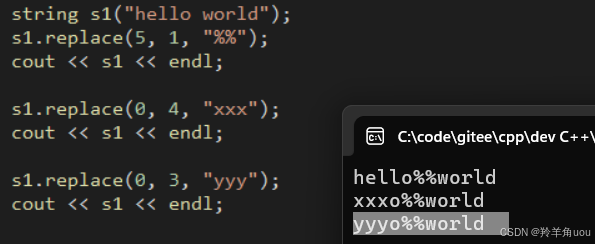
3.6 swap和pop_back
一个是交换,一个是尾删,了解一下即可。


string的其他接口在这就不一一介绍了,大家在使用的时候不清楚的话查一下文档就好了。

4.find系列接口
4.1 find

从pos位置查找字符,字符串,对象,返回值是size_t类型。

如果找到了,返回找到的第一个目标的下标位置。 如果没找到,返回npos。
举个例子。
string s2("hello world hello csdn");size_t pos = s2.find(" "); //找空格如果我们找到空格,把空格全部换成%%。
size_t pos = s2.find(" "); //找空格,把下标存在pos里 while (pos != string::npos) {s2.replace(pos, 1, "%%"); //替换 pos = s2.find(" "); //找下一个空格 }cout << s2 << endl; 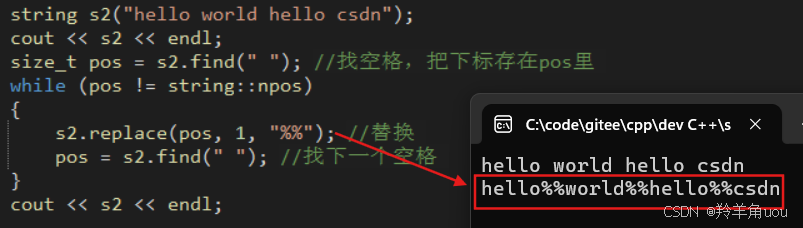
但是这样写的话,我们不给第二个参数传参,find每次都要从头找,很麻烦,我们给第二个参数传参,可以从指定位置开始找。把while循环里面的第二条语句改一下。
while (pos != string::npos) {s2.replace(pos, 1, "%%"); //替换 pos = s2.find(" ", pos + 2); //pos+2位置开始找下一个空格 }这里第二个参数是pos+2,是因为我们把空格这一个字符替换成了两个%。结果是一样的。
4.2 rfind 和substr

rfind和find差不多,只不过rfind是倒着找。
substr是把pos位置的len个字符拿出来拷贝到新的string里,这里npos是老朋友了,如果npos不给值,就是拷贝到结尾。返回值类型是string。

rfind和substr结合起来用,可以用在找文件的后缀。
//假设文件是string.cppstring s3("string.cpp"); size_t pos = s3.rfind('.'); //从后开始找. string suffix = s3.substr(pos); //找到后把后缀存到suffix里 cout << suffix << endl;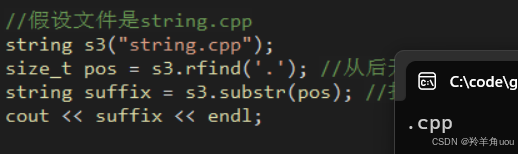
//假设文件是string.cpp.zipstring s3("string.cpp.zip"); size_t pos = s3.rfind('.'); //从后开始找. string suffix = s3.substr(pos); //找到后把后缀存到suffix里 cout << suffix << endl;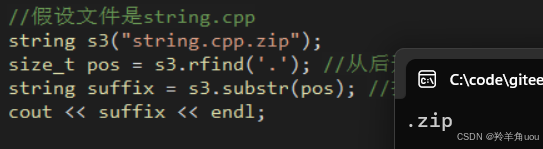
4.3 find_first_of
名字看起来是找第一个,其实并不是,别被名字迷惑哦。

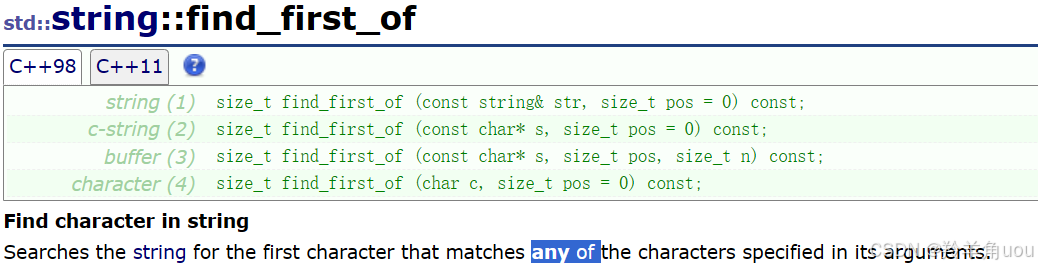
find_first_of 是找任意一个字符,举个例子,如下。
string str ("Please, replace the vowels in this sentence by asterisks.");cout << str << '\n';size_t found = str.find_first_of("abcd");//找abcd的任意一个,a或者b或者c或者d while (found!=string::npos){ str[found]='*'; //只要是a或者b或者c或者d都会被替换成* found=str.find_first_of("abcd",found+1);}cout << str << '\n';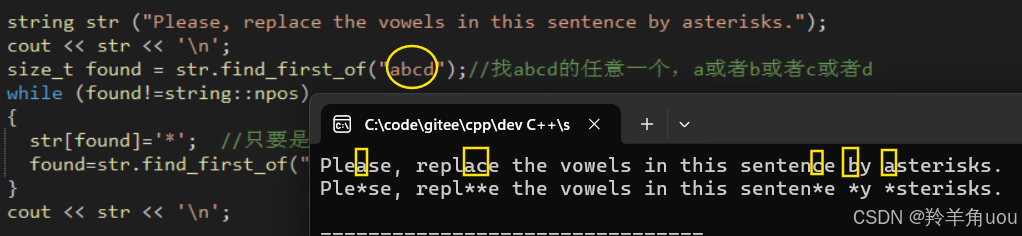
大家一定不能被名字迷惑!是传的任意一个字符都会被找到!
从下面这句代码也可以看出,第二个参数是从pos位置开始找,不传默认为0位置开始。
found=str.find_first_of("abcd",found+1);
4.4 find_last_of
这个函数和find_first_of 功能是一样的,只不过是从后面往前找。


举个例子,还是用文件举例。假设我们要把文件路径和文件名分隔开看,Windows和Linux下的文件分隔符不一样,Windows下是\,Linux下是/,代码如下。
void SplitFilename (const std::string& str){ cout << "Splitting: " << str << '\n'; size_t found = str.find_last_of("/\\");//从后往前,找/和\\的任意一个 cout << " path: " << str.substr(0,found) << '\n'; cout << " file: " << str.substr(found+1) << '\n';}int main (){ string str1 ("/usr/bin/man"); //Linux路径 string str2 ("c:\\windows\\winhelp.exe");//Windows路径 SplitFilename (str1); SplitFilename (str2); return 0;}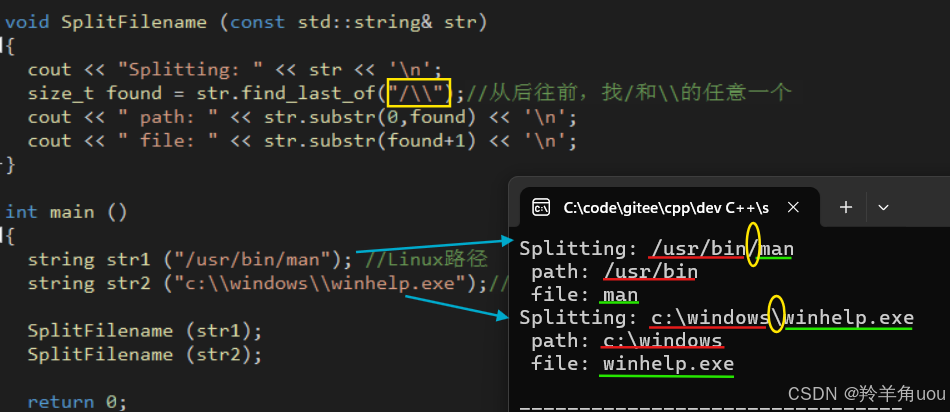
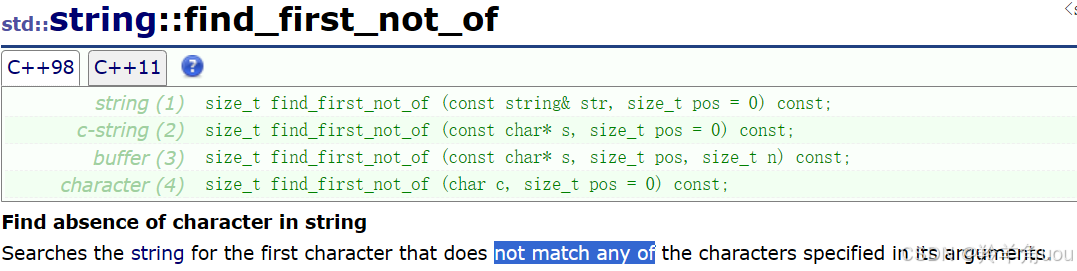
4.5 find_first_not_of和find_last_not_of
这两个和find_first_of、find_last_of相反,比如说前面我们要把是abcd任意一个的找到,这两个接口就是把不是abcd任意一个都找到。

那我们还是拿前面的abcd举例吧,这次换成abcdef。
string str ("Please, replace the vowels in this sentence by asterisks.");cout << str << '\n';size_t found = str.find_first_not_of("abcdef");//找不是abcdef的任意一个while (found!=string::npos){ str[found]='*'; //除了abcdef,其它都会被替换成* found=str.find_first_of("abcdef",found+1);}cout << str << '\n';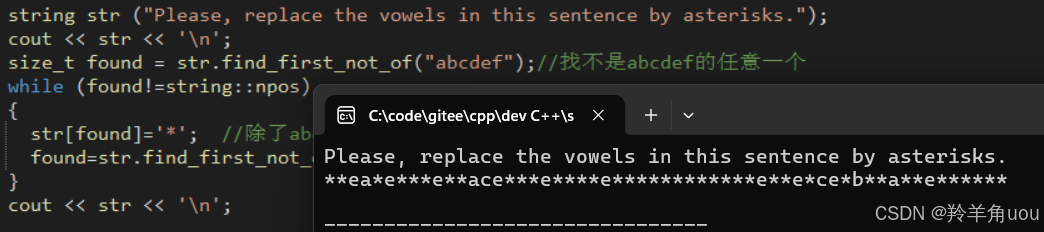 除了abcdef,其它都被替换成*了。
除了abcdef,其它都被替换成*了。
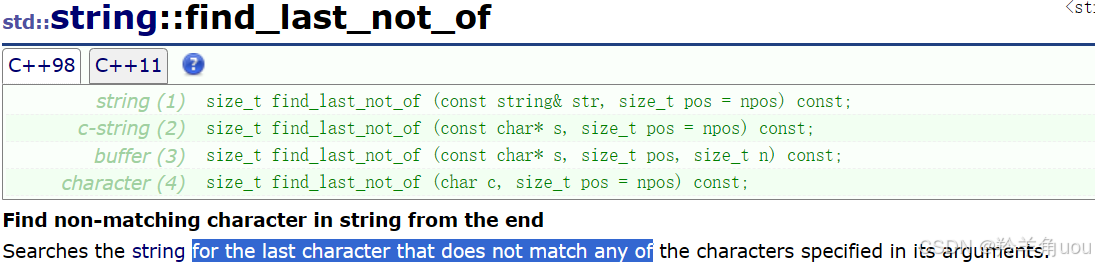
find_last_not_of是一样的,只是从后往前找。

5.string类的非成员函数

5.1 operator+
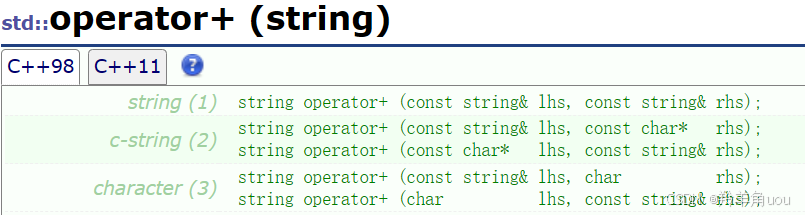
这个函数为什么没有写成成员函数,而是重载成全局的呢?因为它主要想支持字符串+string的功能。如下。
string s4("hello");string s5 = s4 + "world";//string+字符串cout << s5 << endl; string s6 = "world" + s4;//字符串+string cout << s6 << endl;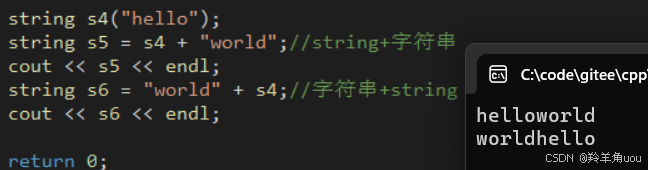
我们说过重载运算符,二元的,两个操作数左右顺序一一对应,如果是成员函数,左操作数只能是string,重载成全局的函数,就可以支持字符串是左操作数。
5.2 比较大小
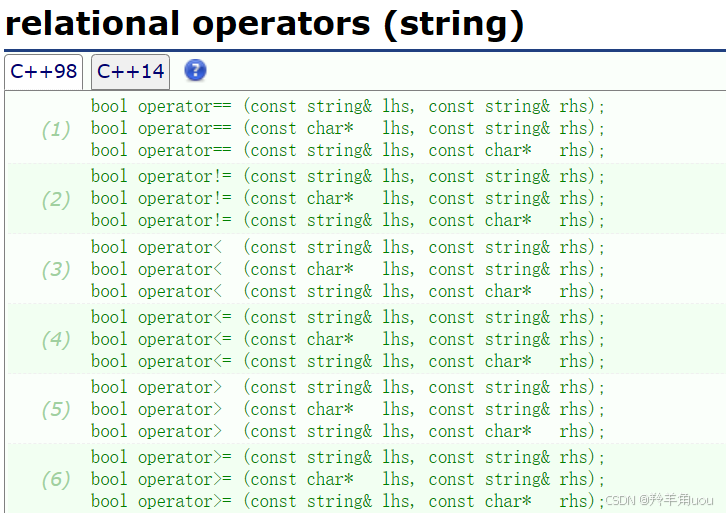
比较大小的接口也是重载了一大堆,在这里就不说了 。
5.3 <<、>>、 swap

swap留到后面再说,流插入和流提取也没啥说的~
5.4 getline
 cin和scanf默认我们输入空格或者换行符就停止一个输入,如果我们要输入hello world,输入到str里,str只会存hello进去,world会认为是另一个对象的。
cin和scanf默认我们输入空格或者换行符就停止一个输入,如果我们要输入hello world,输入到str里,str只会存hello进去,world会认为是另一个对象的。
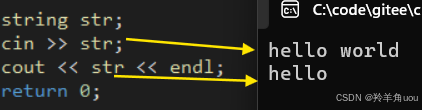
我们用getline输入的话,第一个参数传cin,第二个参数传对象,第三个参数不传,默认以换行符未结束标志。
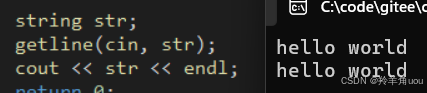
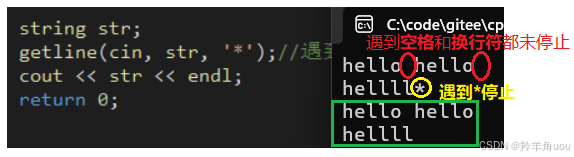
第三个参数传的话,传什么,就以什么为结束标志。
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invit
本次分享就到这里,拜拜~
