点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已更完)Kudu(已更完)Druid(已更完)Kylin(已更完)Elasticsearch(已更完)DataX(已更完)Tez章节内容
上节我们完成了如下的内容:
DataX 异构数据源DataX 使用指南 上手测试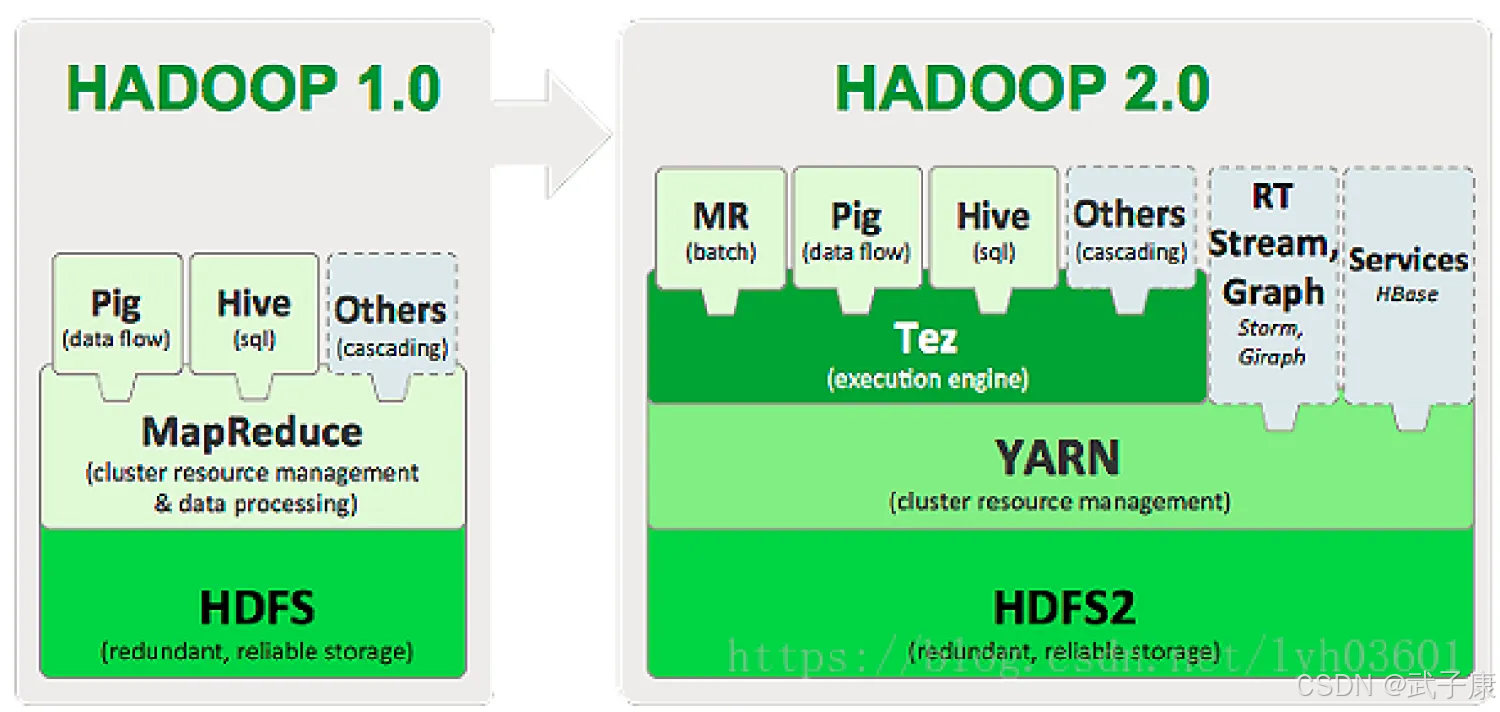
基本介绍
Tez 是一个运行在 Hadoop 生态系统中的高效数据处理框架,旨在优化批处理和交互式查询。它是 Apache 基金会下的一个开源项目,作为替代 MapReduce 的执行引擎使用。Tez 被设计为高度可扩展和灵活的平台,可以处理复杂的数据处理任务,而不仅限于传统的 MapReduce 计算模型。
Tez 的背景
MapReduce 的局限性: Hadoop 最初是基于 MapReduce 编程模型,这种模型虽然简单,但在处理复杂数据处理任务时效率较低。MapReduce 的每一个任务阶段(map 或 reduce)都需要写入磁盘,这会增加 IO 开销和延迟。Tez 的引入: 为了解决这个问题,Tez 允许开发者灵活地构建数据处理 DAG(有向无环图),从而减少中间的磁盘 IO 和不必要的数据处理步骤,提高执行效率。核心解释
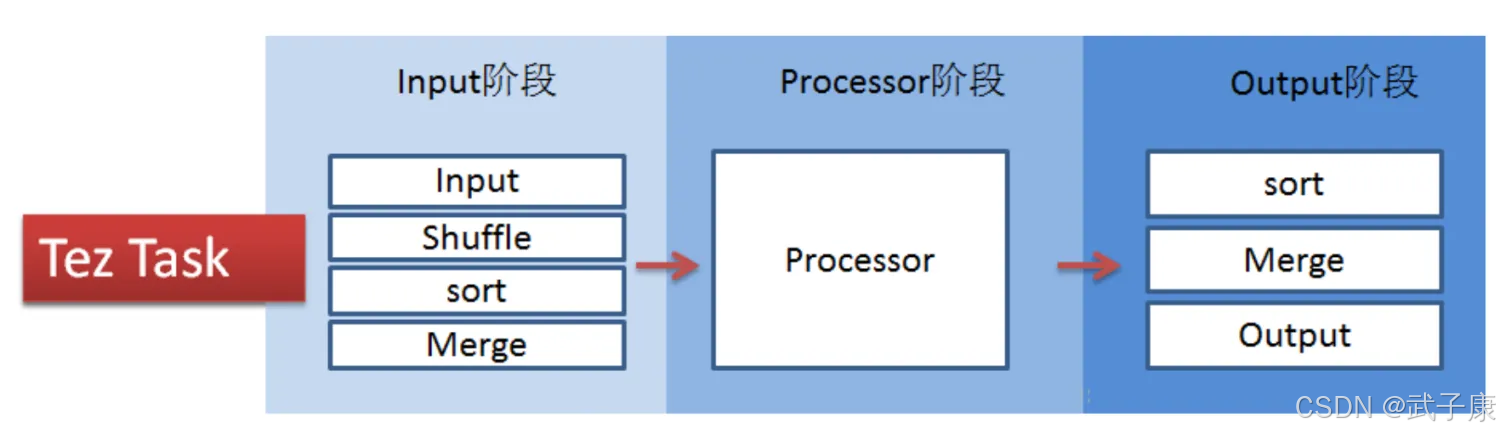
Tez将MapTask和ReduceTask进一步拆分为如下所示的内容:

Tez的Task由Input、Processor、Output阶段组成,可以表达所有复杂的Map、Reduce操作,如下图所示:
Tez可以将多个有依赖的作业转换为一个作业(只需要写一次HDFS,中间环节较少),从而大大提升DAG作业的性能,Tez已经被Hortonworks用于Hive引擎优化,经过测试一般小任务比HiveMR的2-3倍速度左右,大任务7-10倍左右,根据情况不同可能不一样。
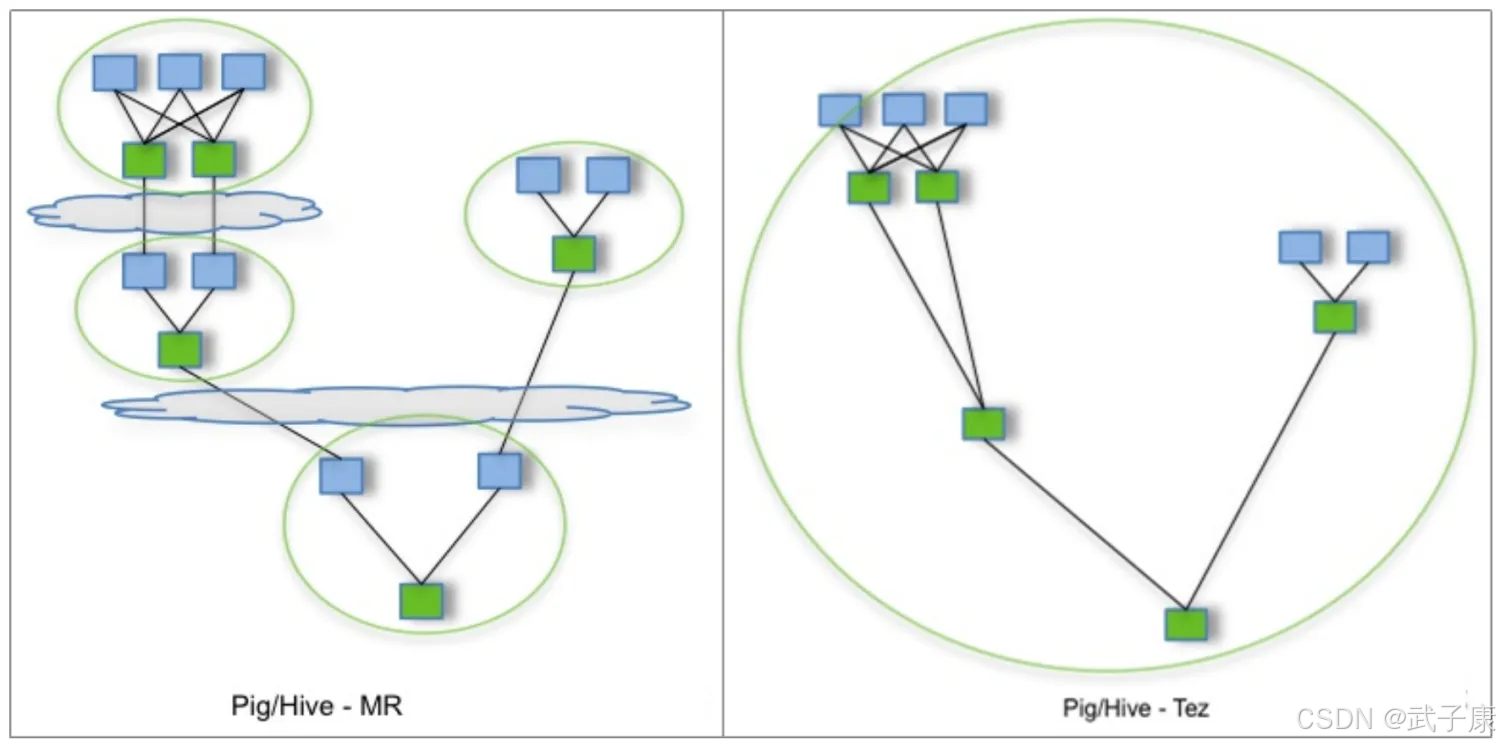
Tez+Hive仍然采用MapReduce计算框架,但对DAG的作业依赖关系进行了裁剪,并将多个小作业合并成一个大作业,不仅减少了计算量,而且写HDFS次数也大大减少。
Tez 的工作原理
DAG 结构: 在 Tez 中,数据处理任务被表示为一个 DAG(Directed Acyclic Graph,有向无环图),其中每个节点代表一个处理任务,边表示数据的流动方向。不同于 MapReduce 固定的 map 和 reduce 阶段,Tez 可以定义任意数量的任务节点和数据流,从而更加灵活高效。按需计算模型: Tez 支持按需加载数据,避免了不必要的中间结果存储。数据可以直接在内存中传递,减少磁盘操作,从而加速计算。Tez 的特点
高效资源管理: Tez 与 YARN(Yet Another Resource Negotiator)无缝集成,能够更高效地分配和使用集群资源。它可以根据工作负载的需求动态调整资源使用,避免了资源的浪费。可重用的容器: Tez 可以在多个任务之间重用容器(容器是 YARN 分配的执行环境),减少了每次任务启动的开销。延迟优化: Tez 可以通过减少中间数据的存储和优化数据流来降低任务执行的延迟,这使得它比传统的 MapReduce 更适合实时或近实时的数据处理。容错性: Tez 支持任务重试和部分失败重算,这意味着在某些任务失败时,不需要重新计算整个作业,能够提高整体的容错性和稳定性。安装部署
下载软件包: apache-tez-0.9.2-bin.tar.gz
解压缩:
tar -zxvf apache-tez-0.9.0-bin.tar.gzcd apache-tez-0.9.0-bin/share将tez的压缩包放到HDFS上:
hdfs dfs -mkdir -p /user/tezhdfs dfs -put tez.tar.gz /user/tez$HADOOP_HOME/etc/hadoop/ 下创建 tez-site.xml 文件,做如下配置:
<?xml version="1.0" encoding="UTF-8"?><configuration> <!-- 指定在hdfs上的tez包文件 --> <property> <name>tez.lib.uris</name> <value>hdfs://hadoop1:9000/user/tez/tez.tar.gz</value> </property></configuration>保存后将文件复制到集群所有节点
环境变量
增加客户端节点的配置:
vim /etc/profileexport TEZ_CONF_DIR=$HADOOP_CONF_DIRexport TEZ_JARS=/opt/apps/tez/*:/opt/apps/tez/lib/*exportHADOOP_CLASSPATH=$TEZ_CONF_DIR:$TEZ_JARS:$HADOOP_CLASSPATH单次配置
Hive这是Tez执行
xhiveset hive.execution.engine=tez;永久配置
如果是想默认使用Tez,则需要在配置文件中进行修改:
vim $HIVE_HOME/conf/hive-site.xml<property><name>hive.execution.engine</name><value>tez</value></property>