判别式AI(Discriminative AI)和生成式AI(Generative AI)是两种不同类型的人工智能模型,它们在目标、方法和应用方面有所区别:
判别式AI(Discriminative AI)
判别式AI主要关注区分不同类别或结果的能力。这种类型的AI模型通常用于分类、检测和识别任务,其核心是判断输入数据属于哪个预定义的类别。
任务类型: 分类(例如,图像分类、文本分类)。检测(例如,物体检测、面部识别)。识别(例如,语音识别、手写识别)。 工作原理: 通过学习数据的特征和模式,判别式AI模型能够识别输入数据与特定类别之间的关系。 常见算法: 支持向量机(SVM)。决策树。逻辑回归。神经网络(特别是用于分类的卷积神经网络CNN)。 应用领域: 医疗诊断(识别疾病类型)。金融(欺诈检测)。安全(异常行为检测)。 特点: 需要大量标注数据进行训练。模型输出是确定性的,即给出明确的类别标签。生成式AI(Generative AI)
生成式AI则关注于生成新的数据实例,这些数据与训练数据具有相似的分布特性。这种类型的AI模型用于创造全新的内容,如图像、文本、音频等。
任务类型: 图像生成(例如,使用生成对抗网络GANs)。文本生成(例如,自然语言生成)。音频合成(例如,音乐或语音合成)。 工作原理: 学习训练数据的分布,并生成新的数据点,这些数据点在统计上与真实数据不可区分。 常见算法: 生成对抗网络(GANs)。变分自编码器(VAEs)。循环神经网络(RNN)用于文本和序列生成。 应用领域: 艺术创作(生成新的艺术作品)。娱乐(生成游戏内容或虚拟角色)。设计(如,室内设计或时尚设计)。 特点: 可以生成新的、之前未见过的数据实例。模型输出是创造性的,可能具有多样性和不确定性。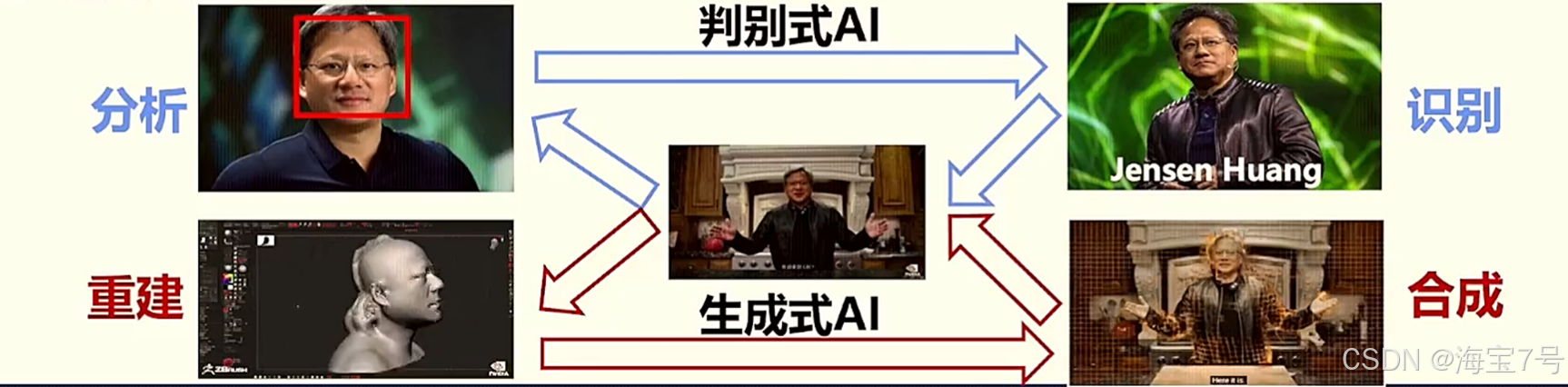
详细说明
判别式AI: 判别式AI模型通常用于解决监督学习问题,它们通过学习输入数据的特征来区分不同的输出类别。这类模型的关键在于区分能力,即它们能够识别和分类不同的数据实例。它们通常需要大量的标注数据来训练,以便模型能够学习到区分不同类别的特征。 生成式AI: 生成式AI模型则用于无监督学习或半监督学习问题,它们的目标是学习数据的生成过程。这类模型不仅学习数据的特征,还学习如何创造新的数据实例,这些实例在统计上与训练数据相似。生成式AI可以用于数据增强、创意内容生成或模拟复杂系统。两种类型的AI在实际应用中可以相互补充,例如,在数据标注成本较高的情况下,可以使用生成式AI来生成伪标签数据,再利用判别式AI进行分类任务。随着技术的发展,这两种范式将继续推动人工智能领域的创新和应用。

判别式AI和生成式AI各有其优缺点,适用于不同的应用场景。
判别式AI的优缺点:
优点:
明确性:判别式AI提供明确的输出,即直接给出分类或识别结果。效率:对于分类和识别任务,判别式AI通常训练和推理速度较快。解释性:某些判别式模型(如决策树、逻辑回归)的决策过程较为容易解释。成熟度:判别式AI技术相对成熟,有大量的研究和应用案例。缺点:
数据依赖性:需要大量标注数据进行训练,对于数据稀缺的问题可能表现不佳。泛化能力:可能在面对与训练数据分布不同的测试数据时泛化能力不足。创新性限制:主要用于识别和分类,不擅长创造新的数据实例。过拟合风险:在数据量不足或模型复杂度过高时,可能发生过拟合。生成式AI的优缺点:
优点:
创造性:能够生成全新的数据实例,具有很高的创新性。数据增强:可以用于生成额外的训练数据,有助于提高模型性能。多样性:生成的数据具有多样性,可以探索不同的可能结果。应用广泛:适用于艺术创作、娱乐、设计等多个领域。缺点:
控制性:生成结果可能难以控制,有时可能生成不符合预期的数据。计算资源:训练生成式模型通常需要更多的计算资源和时间。评估难度:生成的数据质量评估可能较为主观和复杂。技术挑战:生成对抗网络等技术仍然面临稳定性和收敛性等挑战。综合评价:
适用性:判别式AI更适合于需要明确分类或识别的任务,而生成式AI更适合于需要创造新内容的场景。数据需求:判别式AI对标注数据的依赖性较高,生成式AI可以通过生成数据来辅助学习。创新与控制:生成式AI在创新性方面具有优势,但可能牺牲了一定程度的控制性;判别式AI则在控制性方面表现更好。技术发展:两种AI范式都在快速发展中,随着技术的进步,它们的优点可能会被进一步放大,缺点也可能会得到改善。在选择AI模型时,需要根据具体的应用场景、数据可用性、性能要求和创新需求来综合考虑使用判别式AI还是生成式AI。
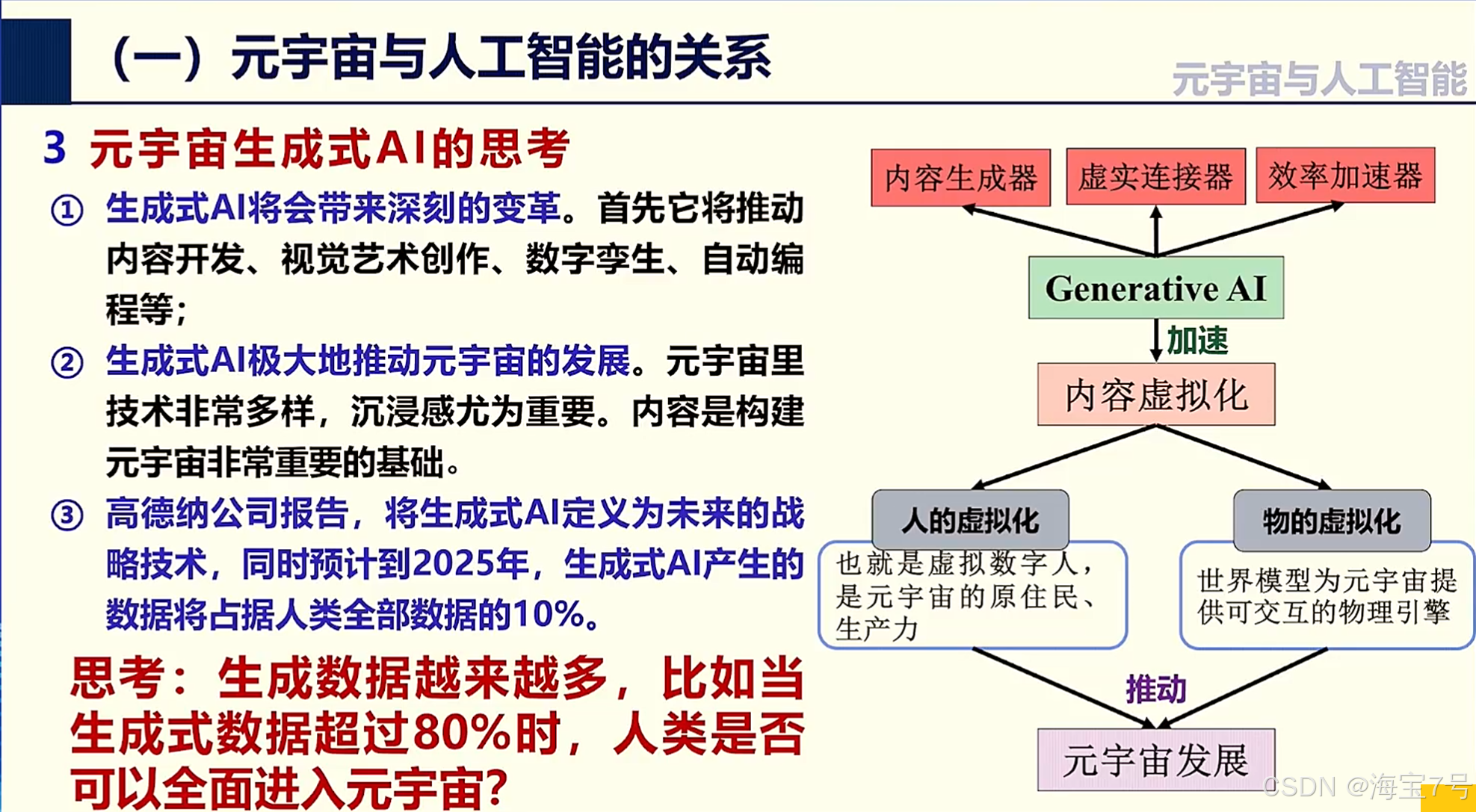
在某些情况下,两者可以结合使用,以发挥各自的优势。