T. Song, W. Zheng, P. Song and Z. Cui, “EEG Emotion Recognition Using Dynamical Graph Convolutional Neural Networks,” in IEEE Transactions on Affective Computing, vol. 11, no. 3, pp. 532-541, 1 July-Sept. 2020, doi: 10.1109/TAFFC.2018.2817622.
Dynamical graph convolutional neural networks (DGCNN) 是一种基于图神经网络的EEG情绪识别模型,引用量截至2024年7月达到了1000+,模型较为简单,所以适合以此了解图神经网络。
文章目录
什么是Chebynet?图的拉普拉斯矩阵图拉普拉斯矩阵的多项式滤波器Chebyshev 多项式滤波器代码:Chebyshev多项式邻接矩阵 “动态”图卷积 模型的调用以及输入模型结构的细节1x1卷积层正则化
DGCNN的代码参考以下链接:
https://github.com/xueyunlong12589/DGCNNtorcheeg: https://torcheeg.readthedocs.io/en/latest/generated/torcheeg.models.DGCNN.html#torcheeg.models.DGCNN 什么是Chebynet?
频谱图理论 (Spectral Graph Theory) 是用线性代数概念(如特征向量和特征值理论)研究图的性质。
(想要简单了解频谱图理论可以参考这个视频。)
DGCNN的基础是Chebynet。Chebynet是一种频谱图神经网络(Spectral GNNs) 在频谱域中操作,具体指的是在图的拉普拉斯矩阵上应用卷积算子。
图的拉普拉斯矩阵
A A A 是邻接矩阵, D D D 是度矩阵。 L L L 是拉普拉斯矩阵,假定它是对称的:
L = D − A L=D-A L=D−A
L L L 通过 SVD(奇异值分解)获得 U U U 中的特征向量和特征值。
L = U Λ U T L=UΛU^T L=UΛUT
传统频谱滤波器:图上的频谱卷积可以定义为节点信号 x ∈ R N x ∈ R^N x∈RN 与在傅里叶域中的卷积滤波器 g θ = diag ( θ ) g_θ = \operatorname{diag}(θ) gθ=diag(θ) 的乘积,其中 θ \theta θ 是滤波器的编号。
g θ ⋆ x = U g θ U T x g_\theta \star \mathbf{x}=U g_\theta U^T \mathbf{x} gθ⋆x=UgθUTx
U T x U^T\mathbf{x} UTx 是输入信号 x x x 的图傅里叶变换。
图拉普拉斯矩阵的多项式滤波器
图拉普拉斯矩阵的多项式滤波器是一种用于在图结构数据上执行卷积操作的技术。
g θ ( L ) = ∑ k = 0 K k θ L k g_θ(L)=\sum_{k=0}^K k_\thetaL^k gθ(L)=k=0∑KkθLk
其中, g θ ( L ) g_\theta(L) gθ(L) 是多项式滤波器, θ k \theta_k θk 是需要学习的参数, L k L^k Lk 是图拉普拉斯矩阵 L L L 的 k k k 次幂。
Chebyshev 多项式滤波器
g θ ⋆ x = U g θ U T x g_\theta \star \mathbf{x}=U g_\theta U^T \mathbf{x} gθ⋆x=UgθUTx
然而如上式所示,直接在频域进行图卷积需要计算图拉普拉斯矩阵的特征分解,SVD分解的计算量较大。
所以为了提高计算效率,Chebyshev 多项式滤波被引入来近似图拉普拉斯矩阵的多项式滤波器 使用 Chebyshev 多项式。我们将滤波器定义为 Chebyshev 多项式的线性组合:
g θ ( L ) ≈ ∑ k = 0 K k θ T k ( L ~ ) g_θ(L)≈\sum_{k=0}^Kk_\theta T_k(\tilde L) gθ(L)≈k=0∑KkθTk(L~)
其中, L ~ \tilde{L} L~ 是归一化后的图拉普拉斯矩阵, θ k \theta_k θk 是需要学习的参数, T k ( L ~ ) T_k(\tilde{L}) Tk(L~) 是 Chebyshev 多项式。
最终卷积操作为:
g θ ( L ~ ) ⋆ x ≈ ∑ k = 0 K θ k T k ( L ~ ) x g_θ(\tilde L) \star \mathbf{x} \approx \sum_{k=0}^K \theta_k T_k(\tilde L) \mathbf{x} gθ(L~)⋆x≈k=0∑KθkTk(L~)x
代码:Chebyshev多项式邻接矩阵
def generate_cheby_adj(A: torch.Tensor, num_layers: int) -> torch.Tensor: support = [] for i in range(num_layers): if i == 0: support.append(torch.eye(A.shape[1]).to(A.device)) elif i == 1: support.append(A) else: temp = torch.matmul(support[-1], A) support.append(temp) return supportgenerate_cheby_adj() 是一个生成 Chebyshev 多项式邻接矩阵的方法
i == 0 时,添加单位矩阵 I I I。当 i == 1 时,添加邻接矩阵 A A A。对于 i > 1 的情况,利用前一个支持矩阵与邻接矩阵 A A A 的矩阵乘法生成新的 Chebyshev 多项式邻接矩阵。 Chebyshev 多项式滤波器 T k ( A ) T_k(A) Tk(A) 是通过递归方式生成的,其中 T 0 ( A ) = I T_0(A) = I T0(A)=I(单位矩阵), T 1 ( A ) = A T_1(A) = A T1(A)=A,接下来的多项式可以通过以下递归公式生成:
T k ( A ) = 2 A T k − 1 ( A ) − T k − 2 ( A ) Tk(A)=2AT_{k−1}(A)−T_{k−2}(A) Tk(A)=2ATk−1(A)−Tk−2(A)
注:代码的切比雪夫多项式的计算公式代码和原文不一致,参考 https://github.com/xueyunlong12589/DGCNN/issues/4
“动态”图卷积
D代表的是Dynamic,指图的邻接矩阵本身是模型的参数 A A A. 这样可以动态学习不同脑电图(EEG)通道之间的内在关系。
相当于在邻接矩阵上计算更高纬度的。数学上通常假设邻接矩阵是对称的,虽然代码里并不假设邻接矩阵是对称的。
使用每个 n n n阶以内的Cheby邻接矩阵可以得到聚合特征,Chebynet把这些聚合特征加在一起最后通过RELU函数
Chebynet的输出变形为1维特征以后再过由两个MLP组成的解码器进行预测。
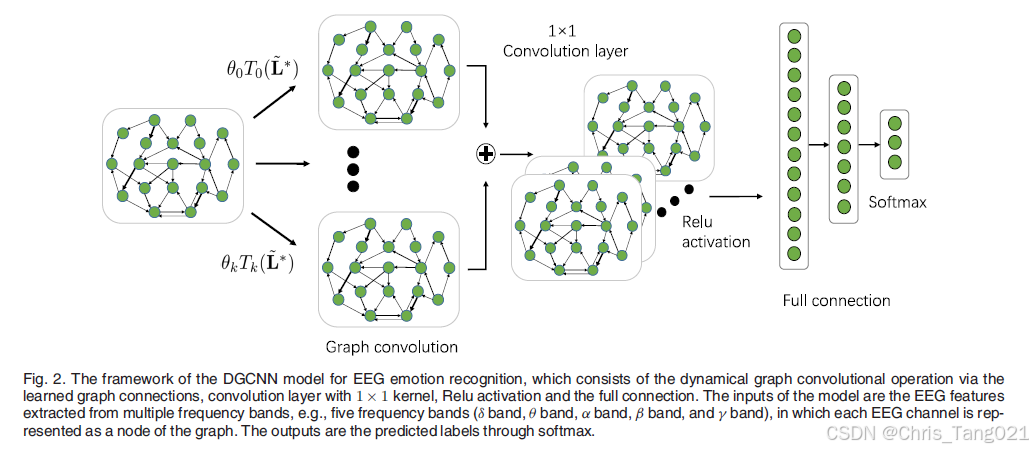
模型的调用以及输入
在 DGCNN 模型中,EEG 通道在五个频带中表示为一个节点。
使用torcheeg.transforms.BandDifferentialEntropy 进行频带微分熵计算。返回类型:np.ndarray,形状为 [电极数量, 子频带数量] 假设有一个包含 32 个电极的 EEG 数据集,并将其划分为 5 个频带。微分熵计算的返回数组将是一个 32 x 5 的矩阵,其中每一行代表一个电极,每一列代表一个频带上的微分熵值。 from torcheeg.models import DGCNNfrom torcheeg.datasets import SEEDDatasetfrom torcheeg import transformsdataset = SEEDDataset(root_path='./Preprocessed_EEG', offline_transform=transforms.BandDifferentialEntropy(band_dict={ "delta": [1, 4], "theta": [4, 8], "alpha": [8, 14], "beta": [14, 31], "gamma": [31, 49] }), online_transform=transforms.Compose([ transforms.ToTensor() ]), label_transform=transforms.Compose([ transforms.Select('emotion'), transforms.Lambda(lambda x: x + 1) ]))model = DGCNN(in_channels=5, num_electrodes=62, hid_channels=32, num_layers=2, num_classes=2)x, y = next(iter(DataLoader(dataset, batch_size=64)))model(x)模型结构的细节
1x1卷积层
代码里似乎对切比雪夫多项式的每一个部分都新建了一个1*1卷积。这有助于突出重要特征,并抑制不太有用的特征。
# 图卷积操作的前向步骤def forward(self, x: torch.Tensor, adj: torch.Tensor) -> torch.Tensor: out = torch.matmul(adj, x) out = torch.matmul(out, self.weight) if self.bias is not None: return out + self.bias else: return out正则化
首先,特征经过BatchNormalization,当张量有三个维度时,维度代表 ( N , C , L ) (N, C, L) (N,C,L)
self.BN1(x.transpose(1, 2)).transpose(1, 2)
BatchNorm1d和BatchNorm2d的区别
BatchNorm1d 设计用于处理 2D 或 3D 输入张量。对于给定的 3D 张量,BatchNorm1d 将在维度(batch_size, time_length) 上计算均值和方差,对每个通道单独进行归一化。换句话说,它将最后一个维度视为时间维度(如时间序列中的时间),并沿着这个维度计算统计量。另一方面,BatchNorm2d 设计用于处理 4D 输入张量,通常形状为 (batch_size, channel_num, height, width)。它将在维度 (batch_size, height, width) 上计算均值和方差,对每个通道单独进行归一化。