
文章目录
前言1. "引用"的概念1.1 "引用"的语法 2. "引用"的特性3. "引用"的使用场景3.1 "引用"做参数3. 2 "引用"做返回值3.2.1 "引用"做返回值时需要注意的点 4. 常引用5. "引用"在底层的实现6. "引用"和"指针"的不同点(面试常考)
前言
本文会着重的讲解"引用"的各项用法以及使用时需要注意的一些规则,另外这部分是面试官比较喜欢与指针一起作为问题来提问我们的,所以我在文章的末尾,给大家也准备好了答案!
话不多说,让我们从现在开始与"引用"进行一场浪漫的邂逅的吧!!!

1. "引用"的概念
引用不是一种新的数据类型,而是在C++中给已存在变量起一个别名。编译器不会给引用变量开辟内存空间,它和它引用的变量共用同一块空间。
举个例子,在《水浒传》中,李逵在家中被宋江叫做"铁牛",在江湖上人称"黑旋风"。那么,我们说"铁牛"和"黑旋风"都是在说李逵这个人,所以说"铁牛"和"黑旋风"就是别名。 在代码的世界里,相信大家已经对别名有所使用,就是typedef这个关键字通常被有做对结构体起别名。在C++中,引用是对变量起别名!
讲解完引用是什么之后,那我们就来看看,引用是如何在代码中表示的。
1.1 "引用"的语法
数据类型& 引用变量名(对象名) = 引用实体;下面我来写一段代码,带着大家感受一下"引用"的魅力:
#include<iostream>using namespace std;int main(){int a = 10;int& ra = a; //类型& 引用变量名 = 引用实体;cout << "a = " << a << endl;cout << "ra = " << ra << endl;return 0;}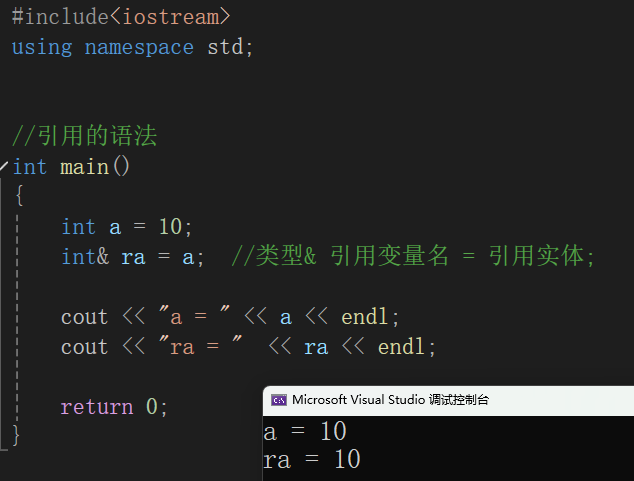
大家在注意引用的定义时,引用变量与引用实体必须得是相同的数据类型。否则,程序会报错的!
2. "引用"的特性
1. 引用在定义时必须初始化;
2. 一个变量可以有多个引用;
3. 一旦有个实体被引用,那么这个引用变量就不能再引用其它实体。
int main(){int a = 10;//int&ra; //该条语句在编译时会报错int& ra = a;int& rra = a;printf("%p %p %p",&a,&ra,&rra);}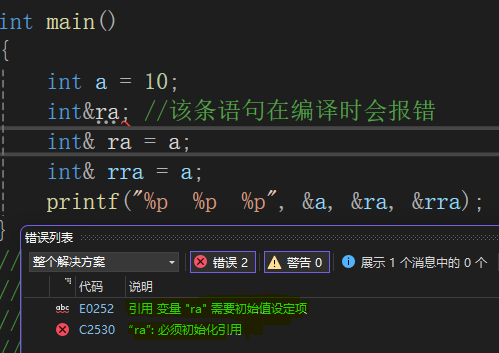
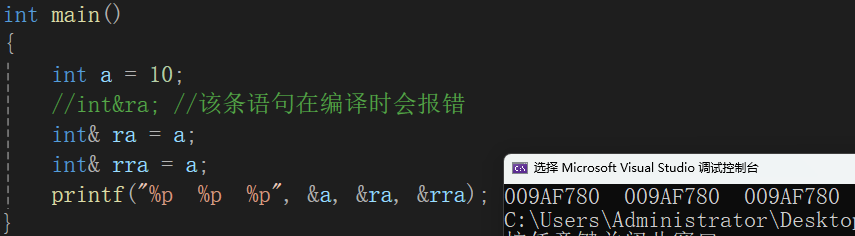
以上的代码案例就能很好的体现出引用的特性!

3. "引用"的使用场景
光讲引用的定义和特性,相信这一定不能让大家认识到"引用"有多强大,有多舒服。那么,接下来,我结合C语言的代码场景来对比在C++下,引用的强大之处。
3.1 "引用"做参数
"引用"做参数,主要是针对输出型参数。
什么是输出型参数?
输出型参数:通过形参的改变能影响实参的改变。 这类的形参,我们就把它称为输出型参数。当然与之对应的还有输入型参数,这个参数想必大家肯定用的不少,==输入型参数:形参的改变不会影响到实参。==这类的形参,我们称它为输入型参数。
好处:
1. 针对输出型参数
2. 减少拷贝,提高效率(特别是大对象/深拷贝对象)
为了让大家更好的感受到"引用"的"爽",我将用多个代码在C语言下和C++下做比较:
//场景一:交换两个数(用C语言)void Swap(int* x, int* y){int tmp = *x;*x = *y;*y = tmp;}//交换两个数(用C++的"引用")void Swap(int& x, int& y){int tmp = x;x = y;y = tmp;}struct Stack{int* a;int top;int capacity;};//场景二:给栈初始化(用C语言)void StackInit(struct Stack* pst,int STDefault = 4){pst->a = (int*)malloc(sizeof(int)*STDefault);if(pst->a == NULL){perror("malloc fail");exit(1);}pst->top = 0;pst->capacity = STDefault;}//给栈初始化(用C++的"引用")void StackInit(struct Stack& st,int STDefault = 4){st.a = (int*)malloc(sizeof(int)*STDefault);if(st.a == NULL){perror("malloc fail");exit(1);}st.top = 0;st.capacity = STDefault;}int main(){struct Stack st;//用C语言的版本StackInit(&st);//用C++的版本StackInit(st);}大家可以仔细对比一下,是C语言指针的写法好用,还是C++的"引用"好用。
在StackInit函数中struct Stack& st这个形参就相当于输出型参数,当然这个想象在Swap函数更加明显。
好了,"引用"作为形参的第一个好处我理解了,那第二个好处又怎么解读呢?
我说引用作为参数,可以减少拷贝,提高效率 ,这个点就体现在函数栈帧的创建和销毁中。如果对这方面不了解的读者,可以看一下往期我写的文章:【C语言】函数栈帧的创建和销毁(启航——迎接崭新的自己)。
回到主线上,我们在调用一个函数时,会在栈区给函数的调用开辟一块空间,这块空间就是函数的栈帧,编译器开会就会往栈中压入以西寄存器之类的东西。重点来了,随后,它就会把我们的形参从右往左依次压入栈中,在这个过程中是通过寄存器将形参先拷贝下来,而这段拷贝是要花时间的。 而我们使用"引用"的话,就可以掠过拷贝的过程,这将这个变量给放到栈中,减少了拷贝的花销。
大家可以拷贝一下程序,在你自己的电脑检测一下:
#include<iostream>#include<time.h>using namespace std;//减少拷贝,提高效率struct test //创建一个大对象{int a[10000];};test a;void Func1(test a) {};void Func2(test& a) {};int main(){int begin1 = clock();for (int i = 1; i <= 10000; i++){Func1(a);}int end1 = clock();int begin2 = clock();for (int i = 1; i <= 10000; i++){Func2(a);}int end2 = clock();cout << "time void Func1(test a) : " << end1 - begin1 << endl;cout << "time void Func2(test& a) : " << end2 - begin2 << endl;return 0;}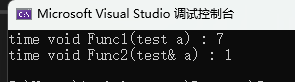
可以看到,引用确实是提高了程序的效率!
当然,引用不仅在参数中能大放异彩,它在做函数返回值时也同样优秀。
3. 2 "引用"做返回值
好处:
1. 减少拷贝,提高效率(特别是大对象/深拷贝对象)
2. 修改返回值 + 获取返回值
请大家看下面的代码:
#include <time.h>struct A{ int a[10000]; };A a;// 值返回A TestFunc1() { return a;}// 引用返回A& TestFunc2(){ return a;}void TestReturnByRefOrValue(){ // 以值作为函数的返回值类型 size_t begin1 = clock(); for (size_t i = 0; i < 100000; ++i) TestFunc1(); size_t end1 = clock(); // 以引用作为函数的返回值类型 size_t begin2 = clock(); for (size_t i = 0; i < 100000; ++i) TestFunc2(); size_t end2 = clock(); // 计算两个函数运算完成之后的时间 cout << "TestFunc1 time:" << end1 - begin1 << endl; cout << "TestFunc2 time:" << end2 - begin2 << endl;}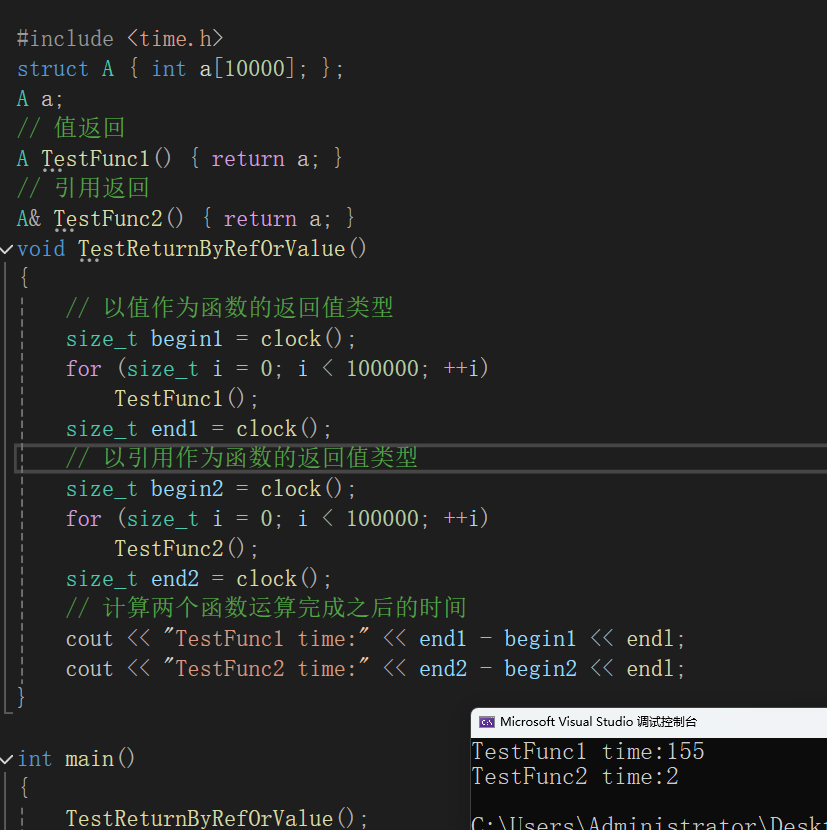
3.2.1 "引用"做返回值时需要注意的点
请大家想看看下面这个代码的结果:
int& Add(int a, int b){ int c = a + b; return c;}int main(){ int& ret = Add(1, 2); Add(3, 4); cout << "Add(1, 2) is :"<< ret <<endl; return 0;}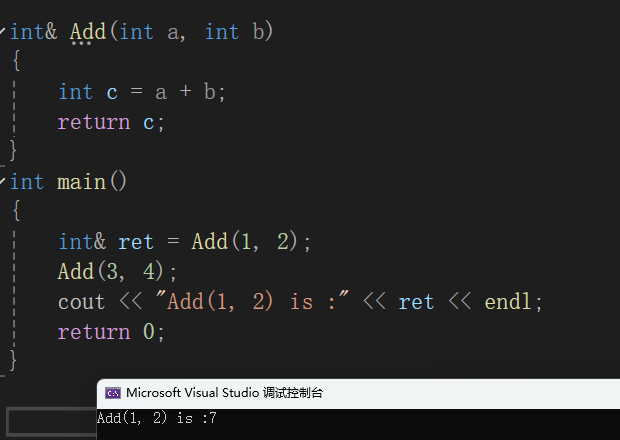
可以看到引用作为返回值时,及其容易出错,那错误的原因就是"非法访问"。
有的读者此时就会说,程序也没有崩溃,何来的"非法访问"一说?
有时候并不是编译器不报错就不代表你这个代码没有问题,就像数组越界一样。
?那我们该怎么理解"非法访问"这一说呢?
这就又要牵扯到函数栈帧的知识了。函数栈帧在被销毁时,编译器做了一个这样的策略,它会将这个返回值用一个寄存器给保存起来。如果我们用"引用"的话,就相当于直接拿着这个返回值的地址了,所以函数栈帧销毁时,会把这块返回值空间的使用权归还给操作系统,此时我们还要用的话,就相当于"非法访问"了。
那有眼尖的读者就会看到,就算是这样,结果也是没有问题的啊。
这是因为编译器在函数栈帧销毁时的处理方式不同:
两种处理方式:
函数栈帧销毁时,编译器不清空栈帧里面的内容函数栈帧销毁时,编译器会清空栈帧里面的内容显然,我们的编译器是选择前者的方案。
可以看看一下这个代码,让你感觉到用"引用"作为返回值是否非法访问了:
#include<stdlib.h>#include<iostream>using namespace std;int& count(int x){int n = x;n++;//...return n;}int main(){int& ret = count(10);cout << ret << endl;printf("ssssssssssssssssssssssssss\n");rand();cout << ret << endl;return 0;}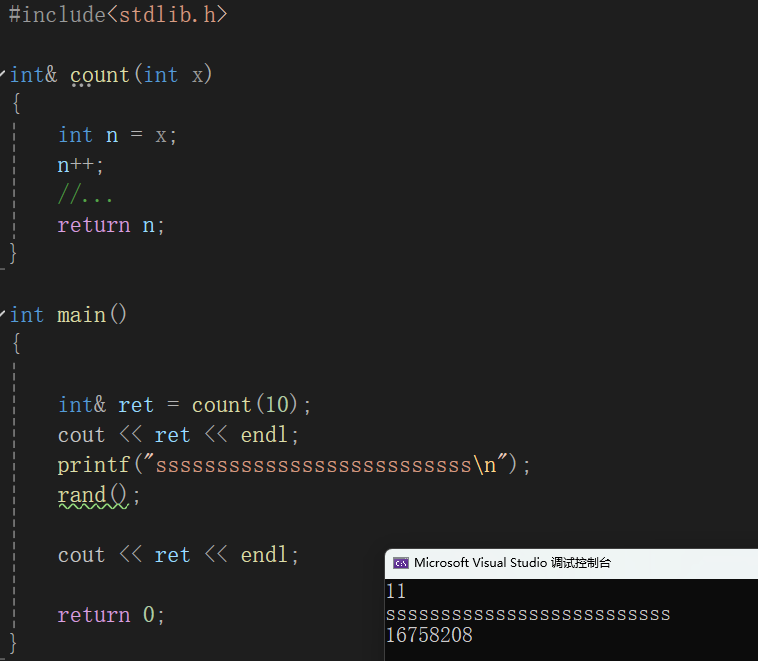
结果分析:可以看到第二次打印变量ret的值时,发现是一个随机值,这也就是说明了我i们正在非法的访问者我们的内存。
总结:所以我们在用"引用"作为返回值时,一定不要用局部变量作为函数的返回值,或者和说不要使用在栈区上创建的变量,可以使用静态区或者堆区上的变量!
4. 常引用
“引用"还有一种场景,那就是"常引用”。
常引用通常搭配着一个关键字const使用。
int main(){int& ret1 = func1(); // 权限放大,编译器会报错const int& ret1 = func1(); // 权限平移int ret1 = func1(); // 拷贝int& ret2 = func2();// 权限平移const int& rret2 = func2(); // 权限缩小return 0;}以上的写法都是被允许的。可以看到常引用的权限是小于引用的权限的。
?总结:在使用常引用时,我们要注意权限之间的问题,只能进行权限的平移或者权限的缩小。权限的大小关系:"引用"权限 > "常引用"权限。
5. "引用"在底层的实现
大家可以看一下下面代码的反汇编代码:
int main(){int a = 10;int& ra = a;ra = 20;int* pa = &a;*pa = 20;return 0;}以下是对应代码的反汇编代码:

可以看到的是,"引用"的底层也是用指针来实现的!
重点说明:在底层实现上"引用"的确是消耗了空间,但是在语法概念上,我们是认为"引用"是不会单独开辟空间的。我们会通常使用后者的说法。
6. "引用"和"指针"的不同点(面试常考)
1. ?引用概念上定义一个变量的别名,指针存储一个变量地址。
2. ?引用在定义时必须初始化,指针没有要求
3. ?引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
4. ?没有NULL引用,但有NULL指针
5. ?在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
6. ?引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
7. ?有多级指针,但是没有多级引用
8. ?访问实体方式不同,指针需要显式解引用,引用编译器自己处理
9. ?引用比指针使用起来相对更安全
以上就是本文的全部内容了,如果觉得本文对你有帮助的话,麻烦给偶点个赞吧!!!
