点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已更完)Kudu(已更完)Druid(已更完)Kylin(正在更新…)章节内容
上节我们完成了如下的内容:
Kylin 历史Kylin 历程Kylin 特点Kylin 架构Kylin 组件
依赖环境
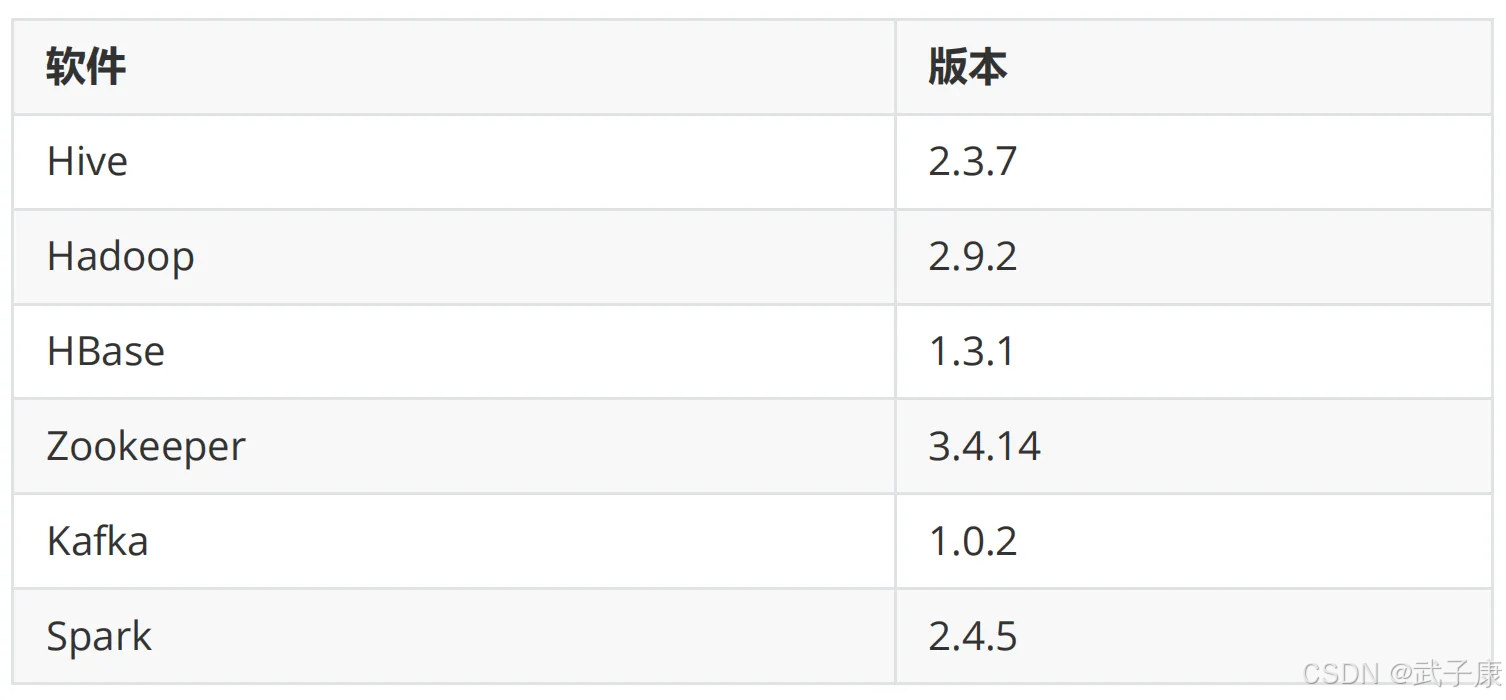
集群规划
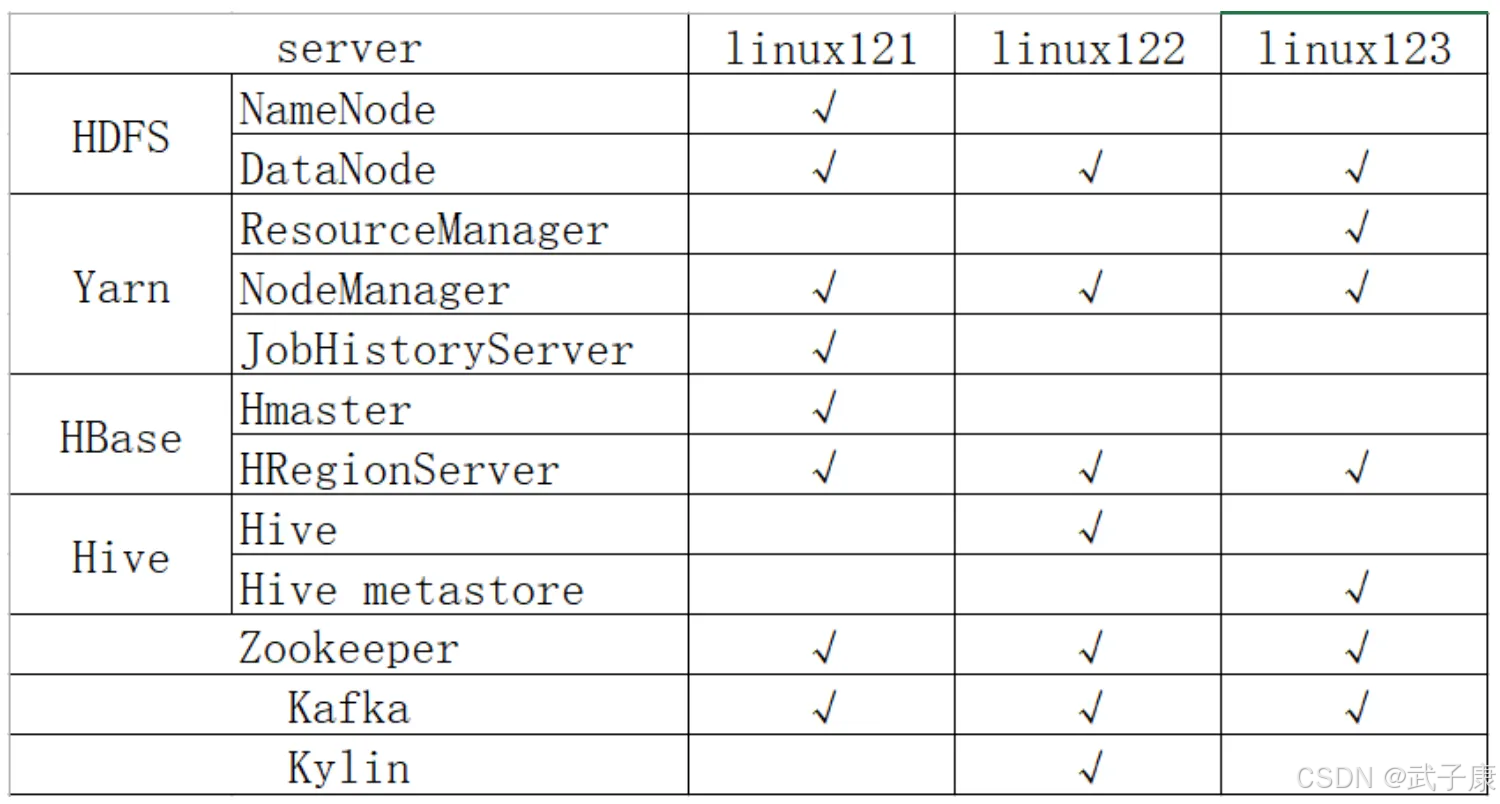
我这里就不根据上图来做了,因为我的服务器资源比较紧张,我就自由安排了。
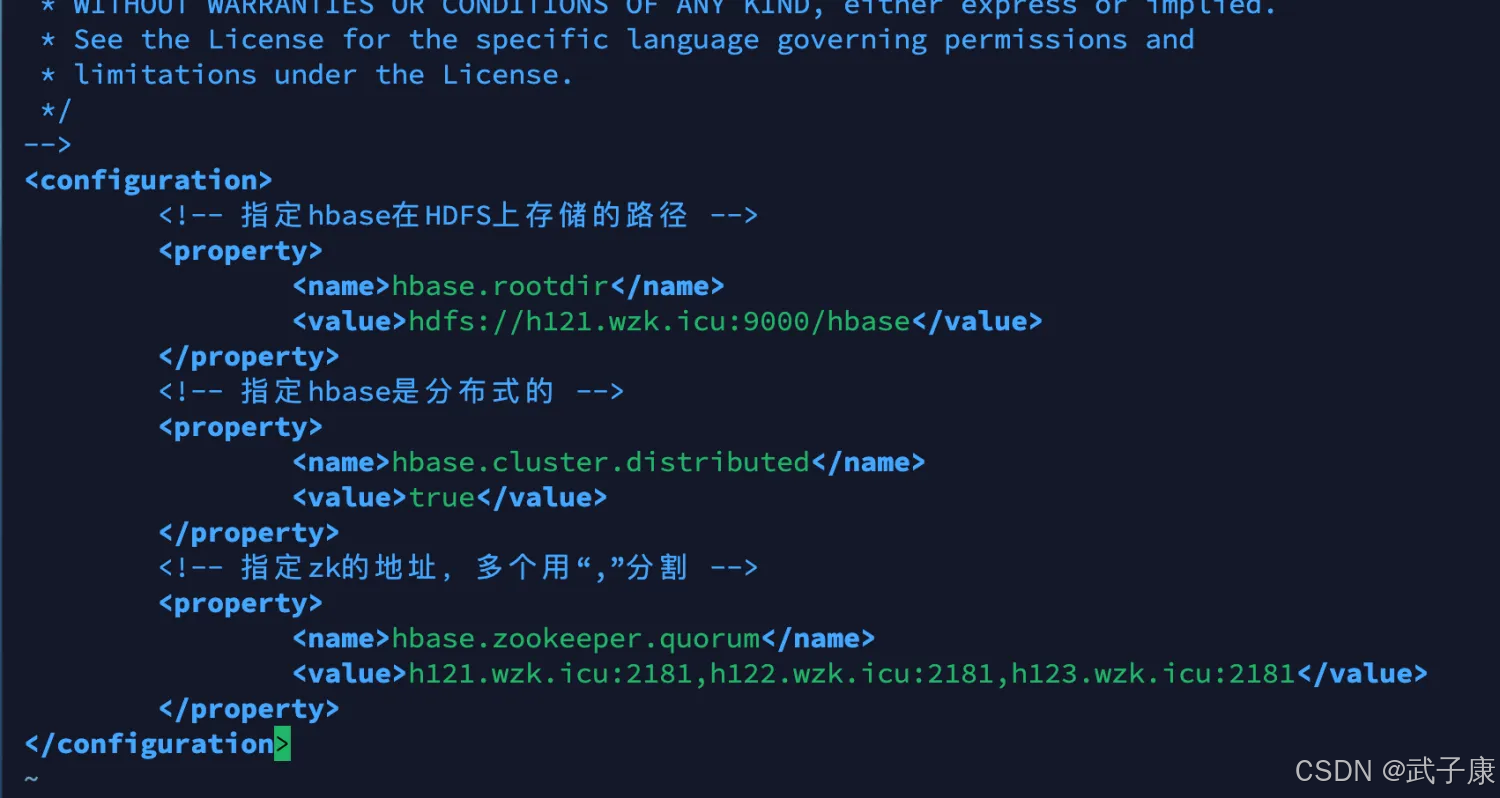
需要注意:要求HBase的hbase.zookeeper.quorum值必须只能是 host1、host2这种,不允许host1:2181、host2:2181这种。
cd /opt/servers/hbase-1.3.1/confvim hbase-site.xml(之前HBase实验已经做过了,配置就是这样的)
保险起见,放一个截图:
项目下载
下载地址如下:
https://archive.apache.org/dist/kylin/这里使用的是:
https://archive.apache.org/dist/kylin/apache-kylin-3.1.1/apache-kylin-3.1.1-bin-hbase1x.tar.gz你可以通过wegt或者本地下载完传到服务器上,按照需求,我这里是上传到 h122 节点上
cd /opt/softwarewget https://archive.apache.org/dist/kylin/apache-kylin-3.1.1/apache-kylin-3.1.1-bin-hbase1x.tar.gz等待下载完毕
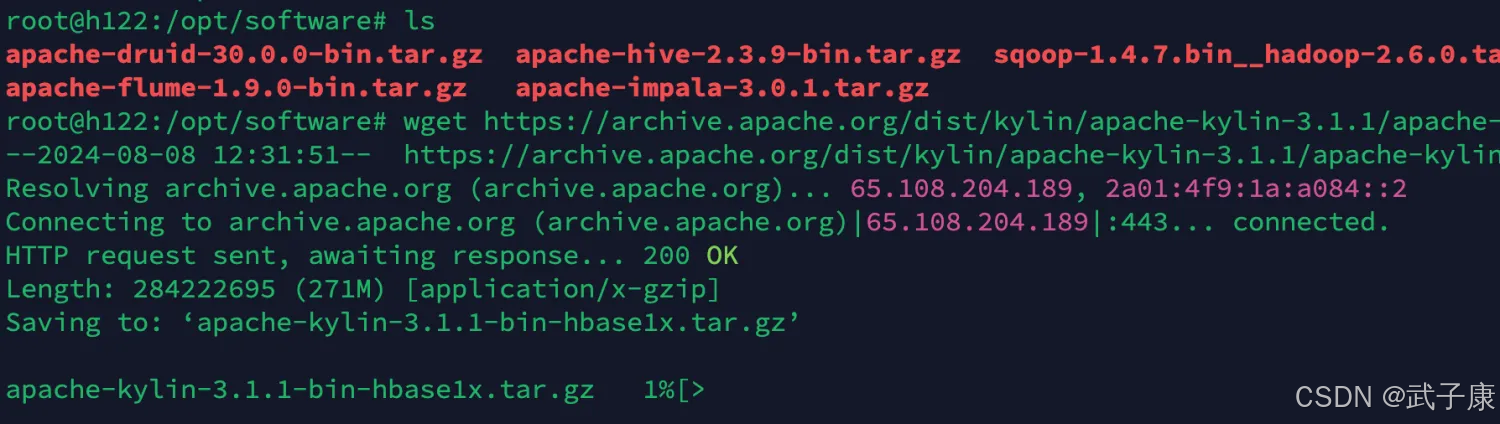
解压移动
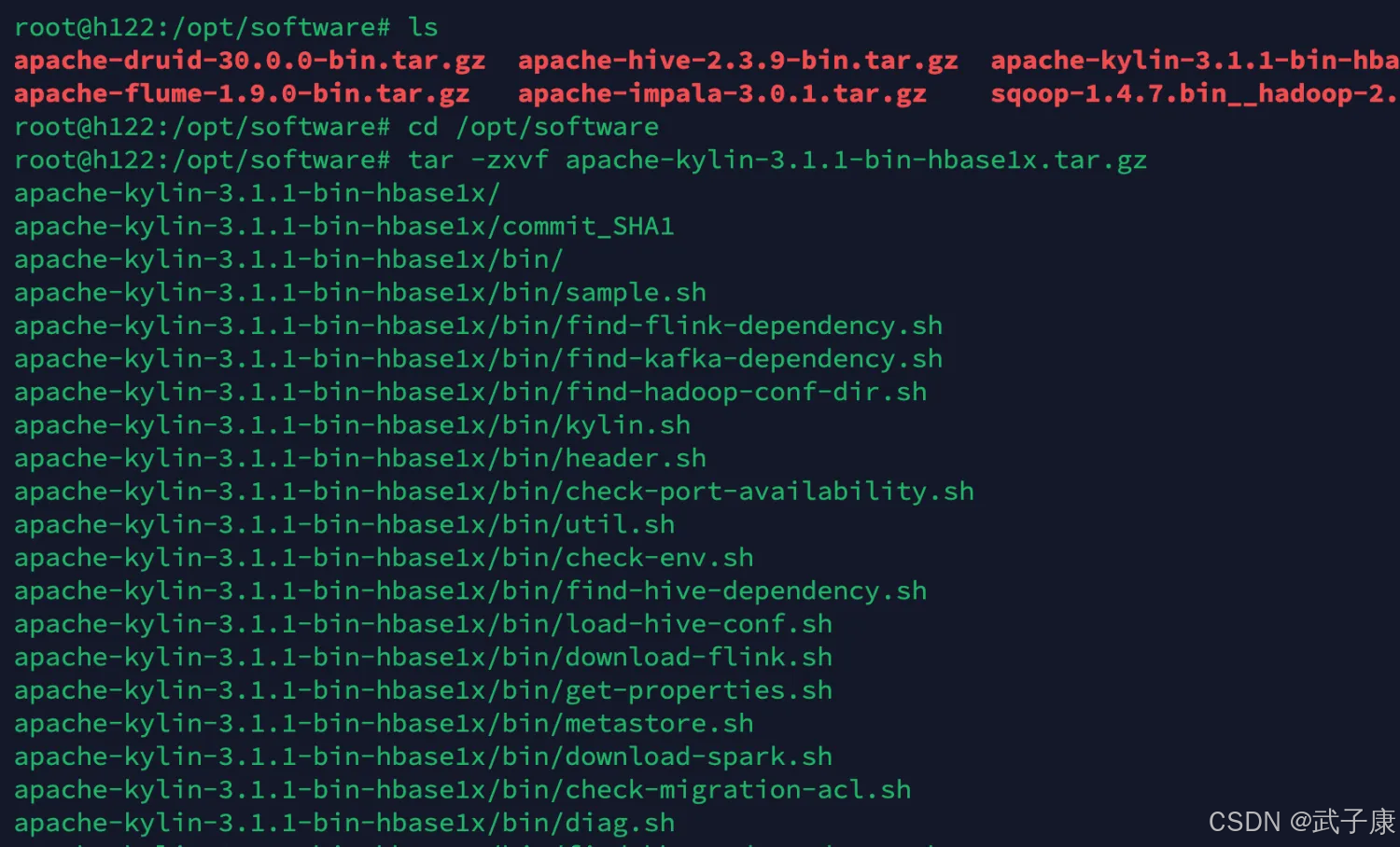
cd /opt/softwaretar -zxvf apache-kylin-3.1.1-bin-hbase1x.tar.gz运行结果如下图所示:
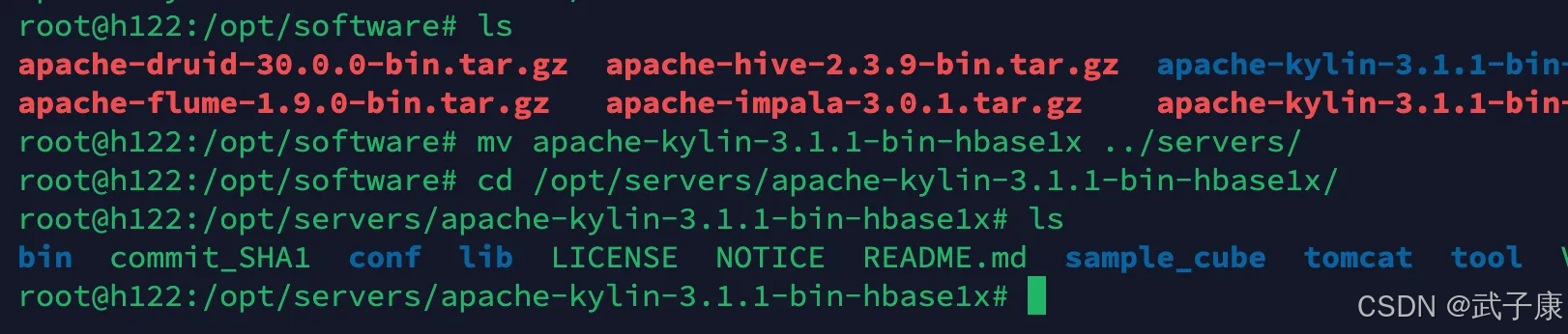
接着将其移动到servers目录,方便后续的管理:
环境变量
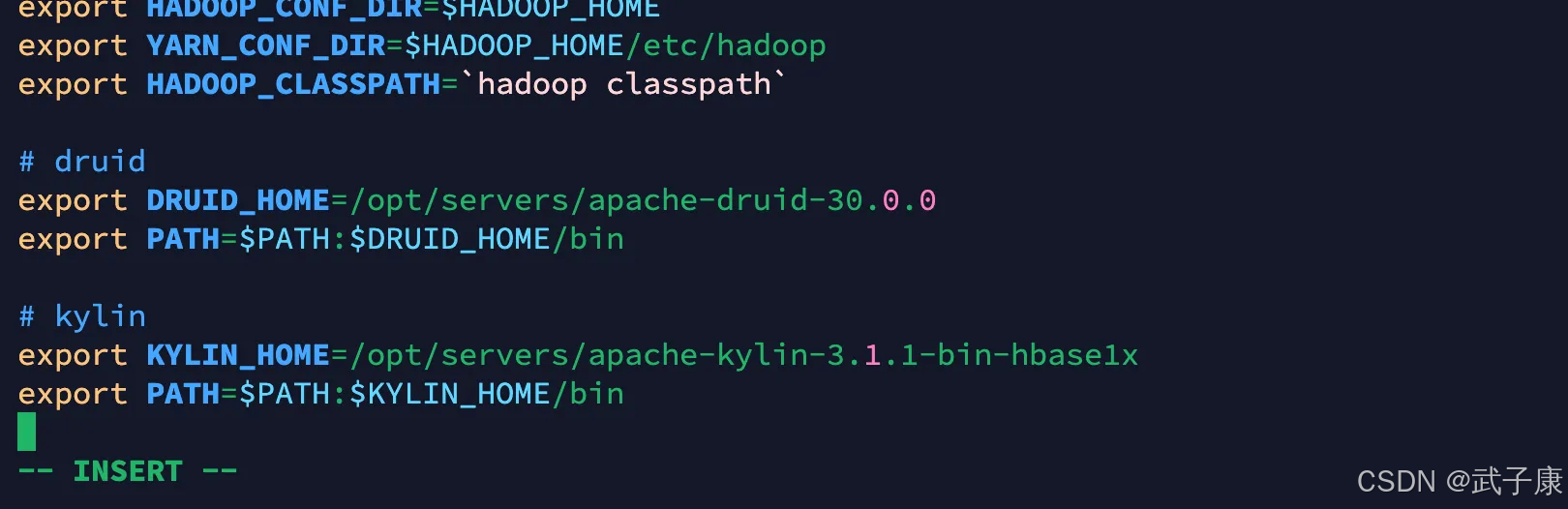
vim /etc/profile我们需要加入Kylin的环境变量:(记得刷新环境变量)
export KYLIN_HOME=/opt/servers/apache-kylin-3.1.1-bin-hbase1xexport PATH=$PATH:$KYLIN_HOME/bin配置环境变量如下图所示:
依赖组件
cd $KYLIN_HOME/confln -s $HADOOP_HOME/etc/hadoop/hdfs-site.xml hdfs-site.xmlln -s $HADOOP_HOME/etc/hadoop/core-site.xml core-site.xmlln -s $HBASE_HOME/conf/hbase-site.xml hbase-site.xmlln -s $HIVE_HOME/conf/hive-site.xml hive-site.xmlln -s $SPARK_HOME/conf/spark-defaults.conf spark-defaults.conf执行的结果如下图所示:
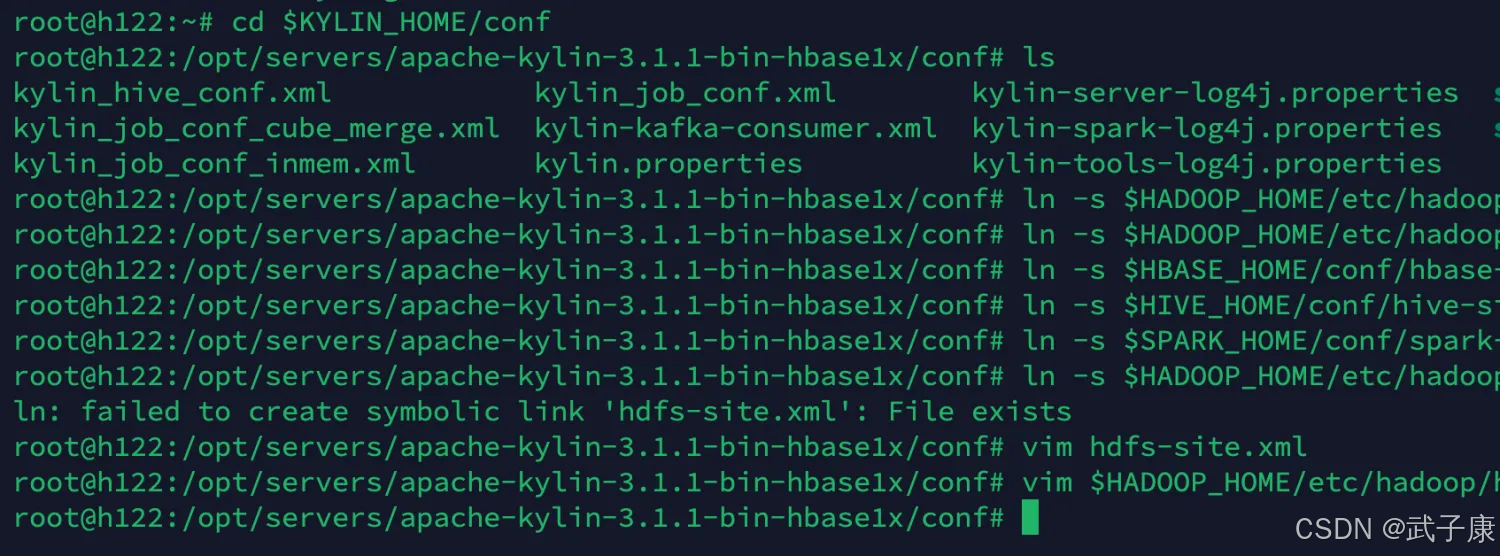
配置环境
我们需要修改 kylin.sh
cd $KYLIN_HOME/binvim kylin.sh# 需要写入这些依赖 防止后续报错export HADOOP_HOME=/opt/servers/hadoop-2.9.2export HIVE_HOME=/opt/servers/apache-hive-2.3.9-binexport HBASE_HOME=/opt/servers/hbase-1.3.1export SPARK_HOME=/opt/servers/spark-2.4.5-bin-without-hadoop-scala-2.12配置结果如下图所示:
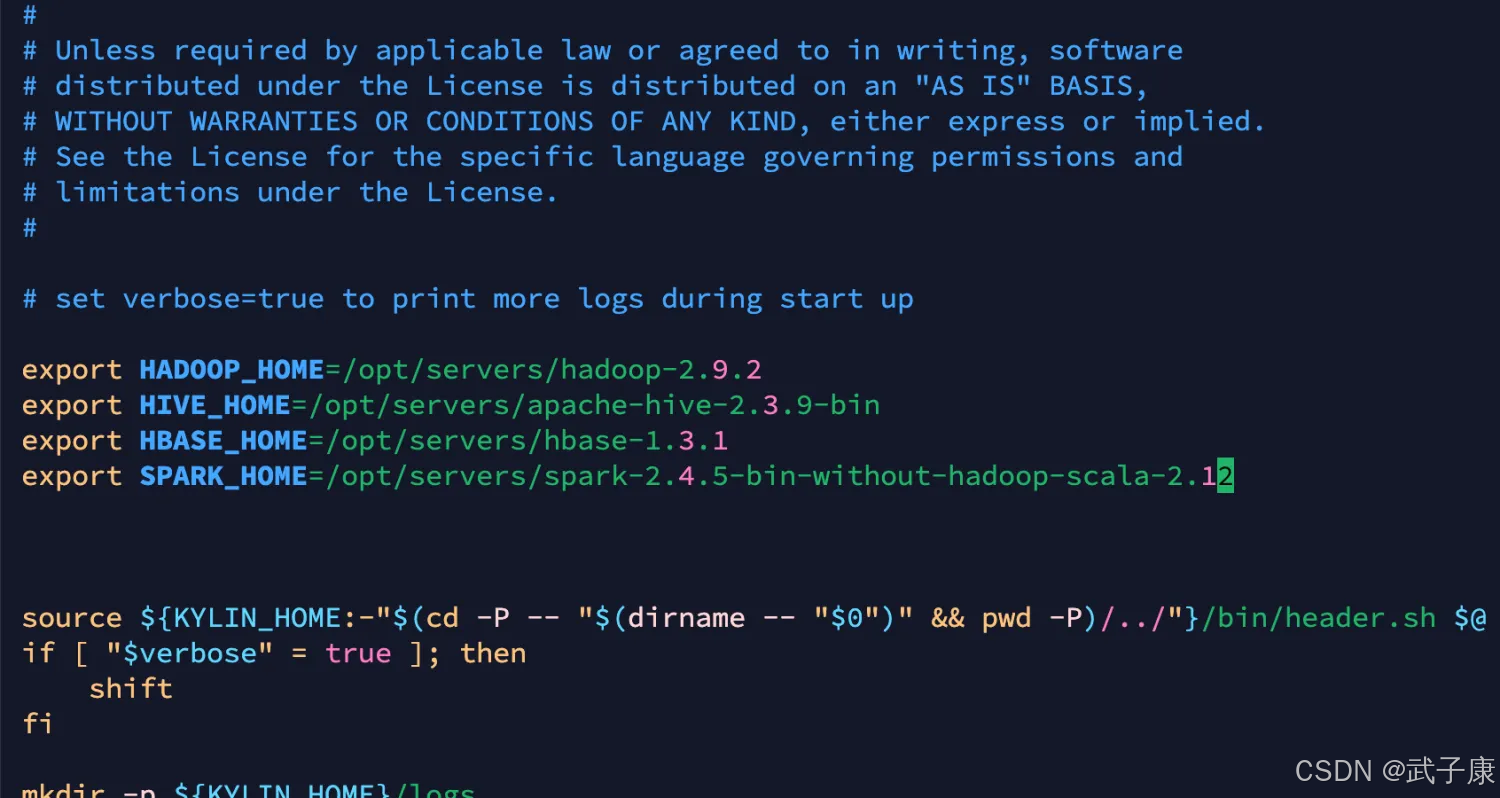
检查依赖
$KYLIN_HOME/bin/check-env.sh我这里报错了,可能是之前的环境变量有问题:
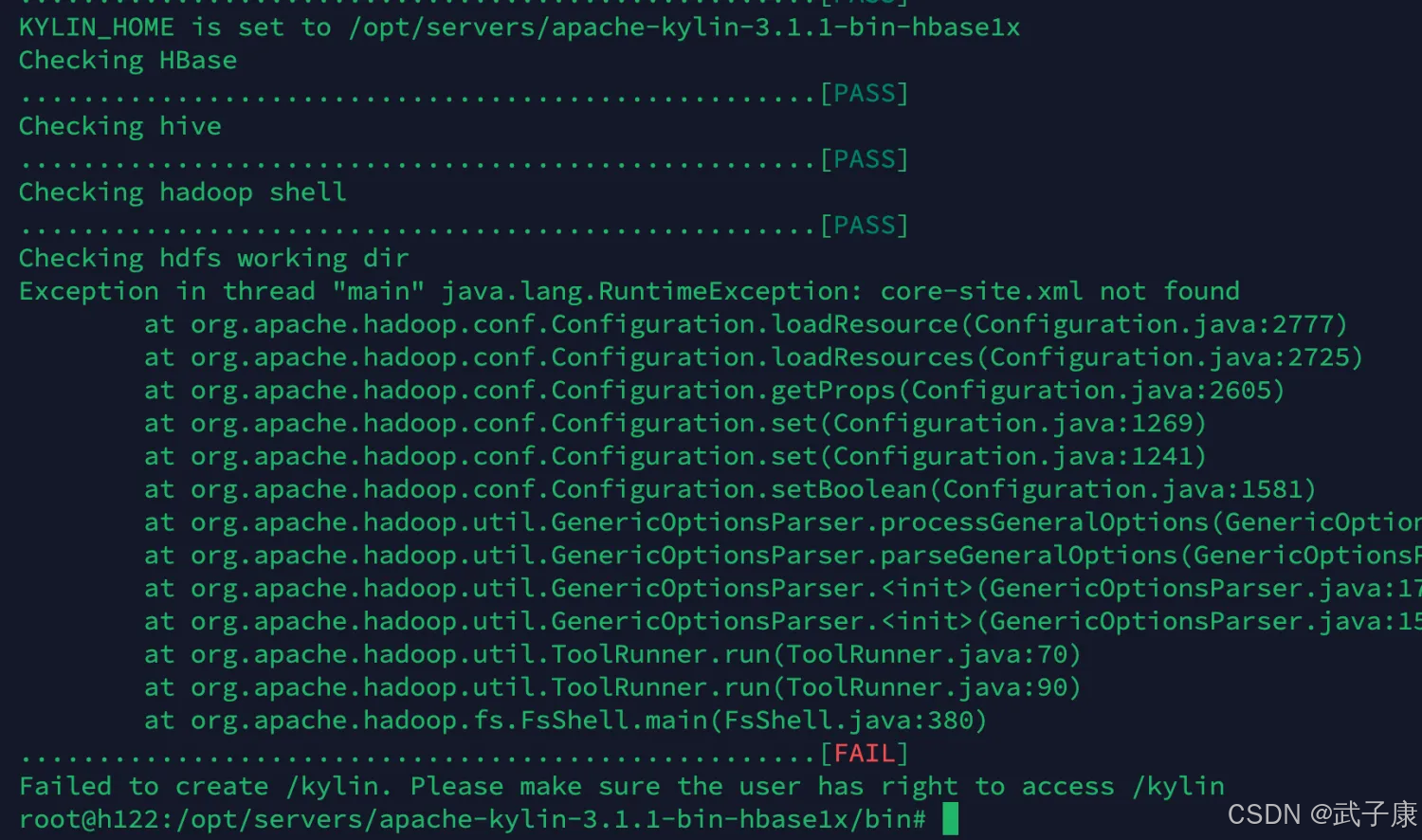
我找了一圈,看到 Flink YARN 这里HADOOP_CONF_DIR可能配置错了:
# Flink YRAN# export HADOOP_CONF_DIR=$HADOOP_HOMEexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport YARN_CONF_DIR=$HADOOP_HOME/etc/hadoopexport HADOOP_CLASSPATH=`hadoop classpath`修改完的结果为如下:(这里我暂时注释了,防止我的FlinkYRAN以后不能用了)
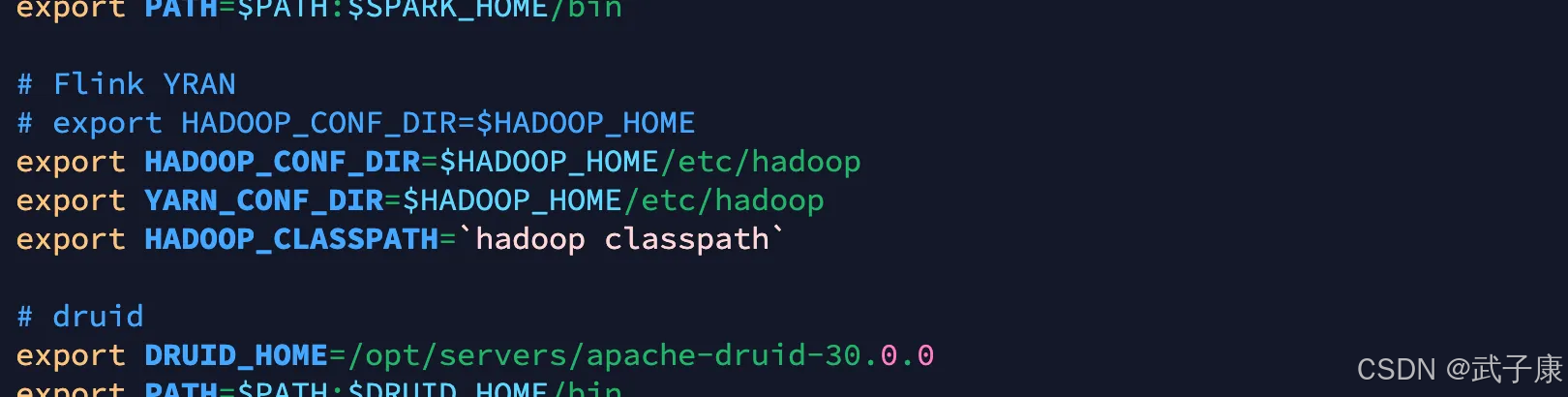
重新进行测试环境,检查顺利通过,看里边还有一些和Flink、Kafka的配置等,你需要的话可以加入:
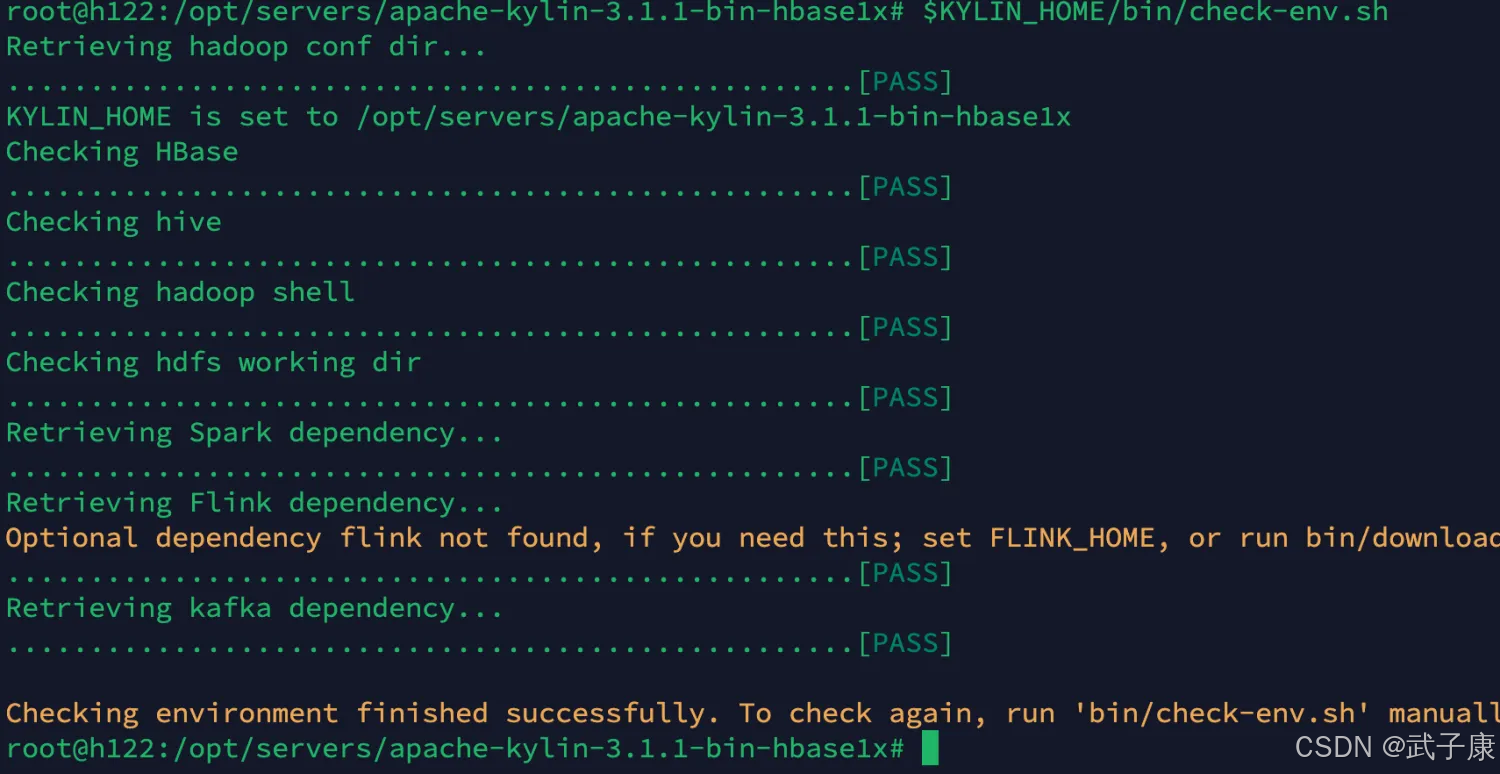
启动集群
ZooKeeper
启动 h121 h122 h123集群模式
需要每个节点都运行
zkServer.sh startHDFS
启动 h121 h122 h123
h121运行即可,但是要检查确认
start-dfs.shYRAN
启动 h121 h122 h123
h121运行即可,但是要检查确认
start-yarn.shHBase
启动 h121 h122 h123
h121运行即可,但是要检查确认
start-hbase.shMetastore
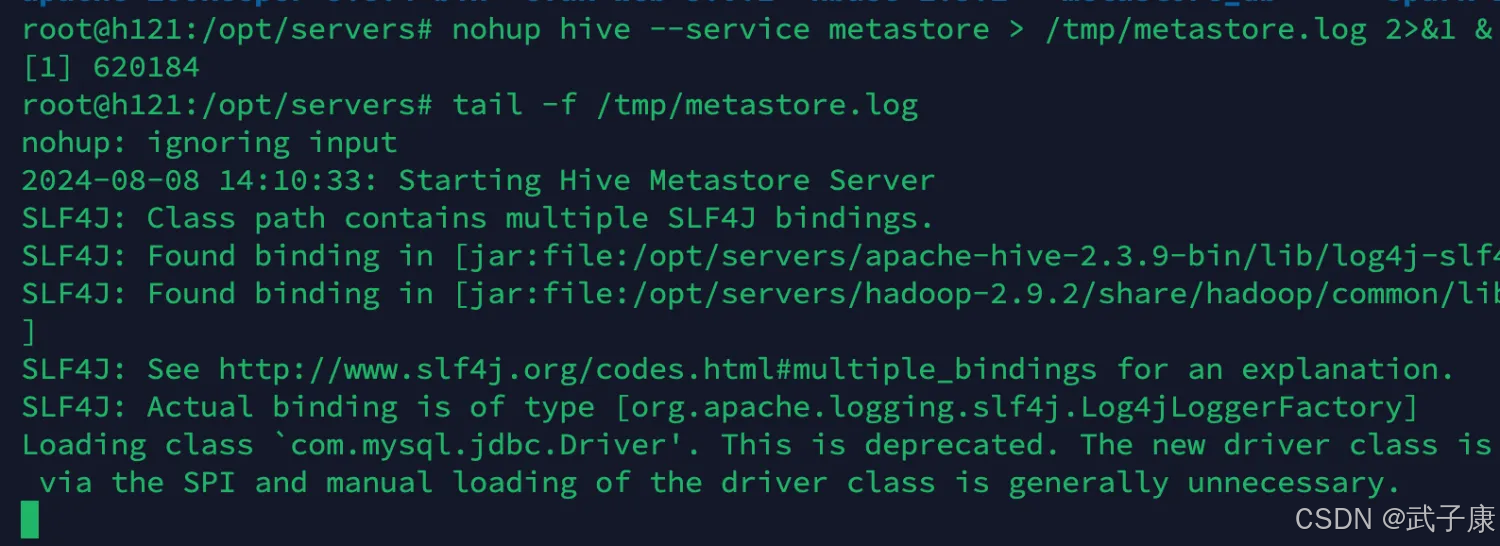
启动 h121 即可
nohup hive --service metastore > /tmp/metastore.log 2>&1 &运行结果如下图:
history server
启动 h121 即可
mr-jobhistory-daemon.sh start historyserverKylin
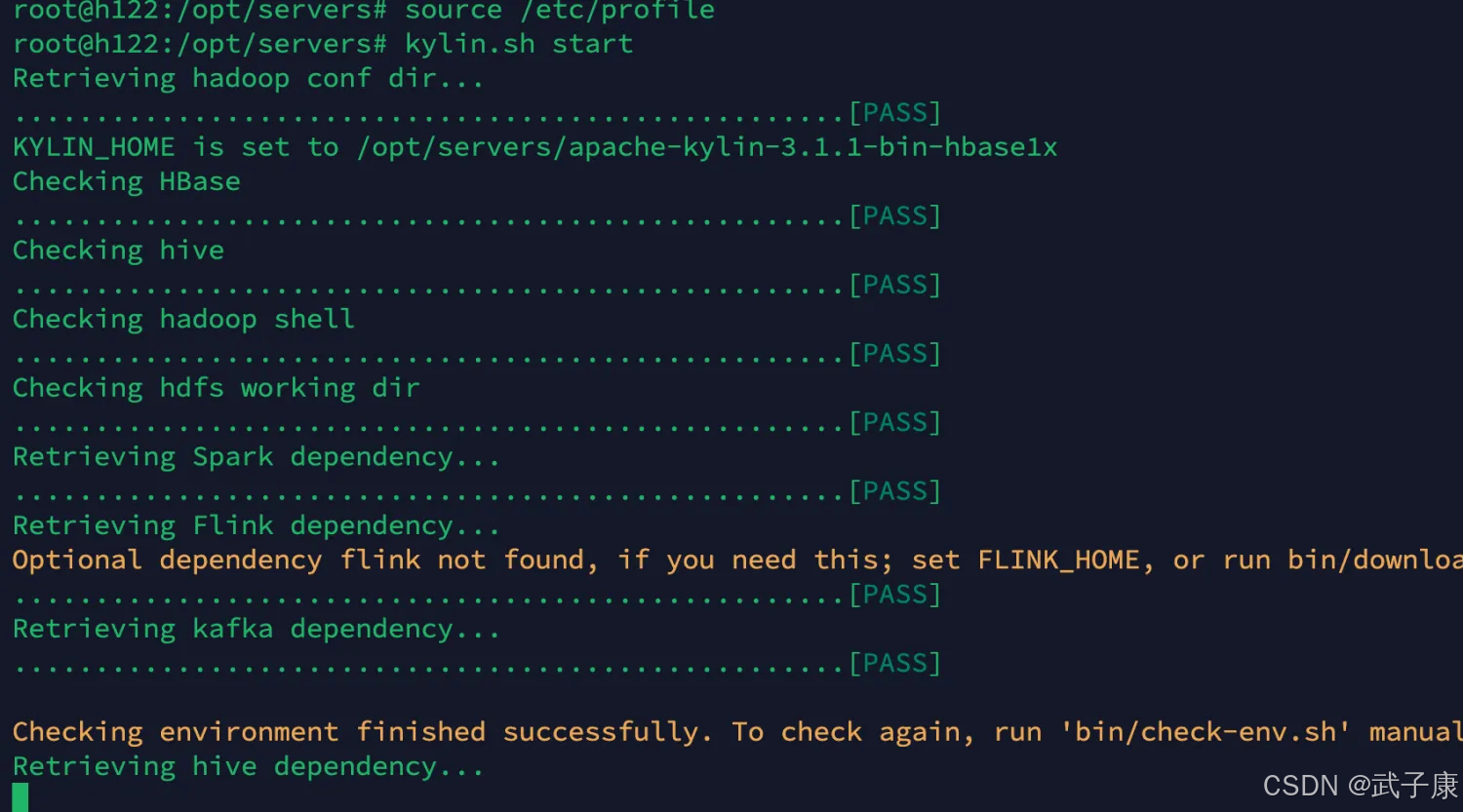
启动 h122
kylin.sh start运行过程如下图所示:
节点详情
h121
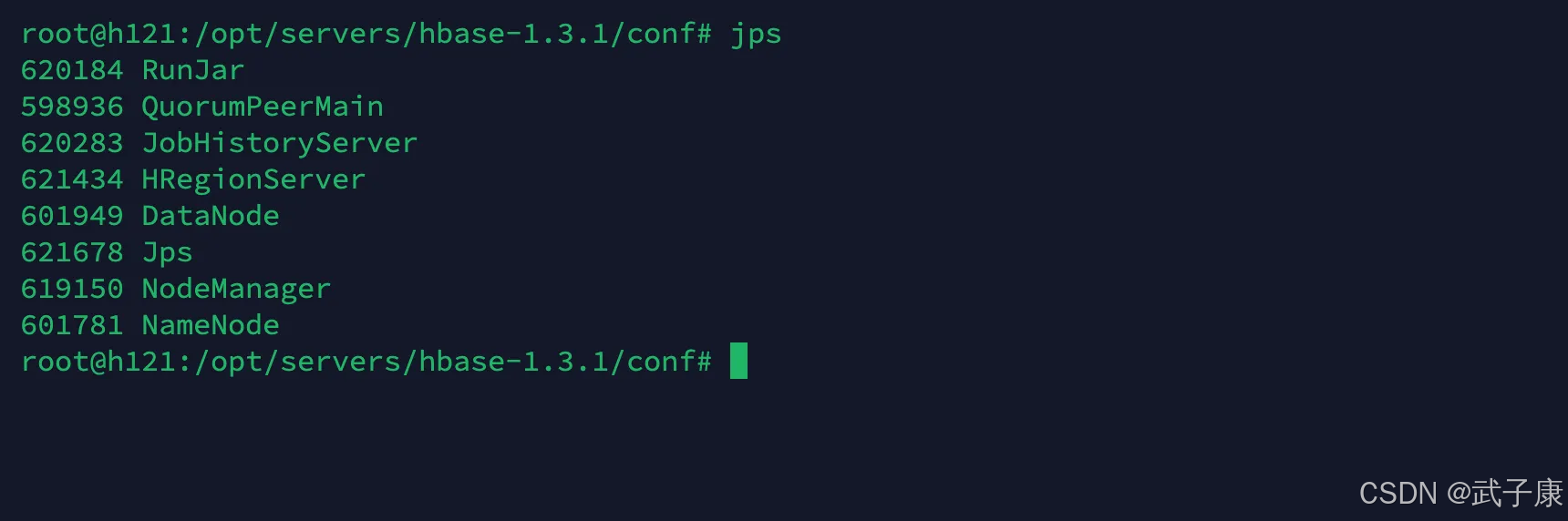
与上图对应一下:
h122

h123
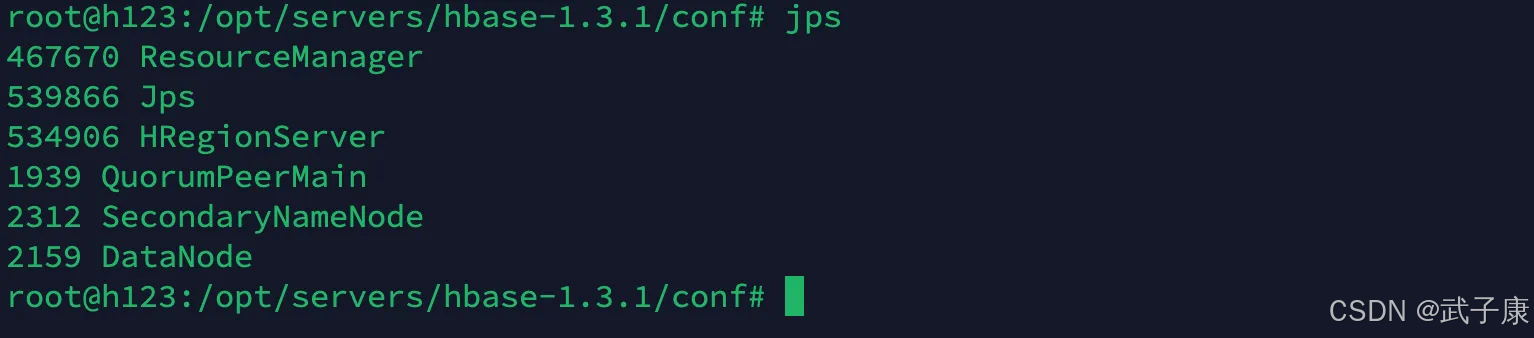
启动结果
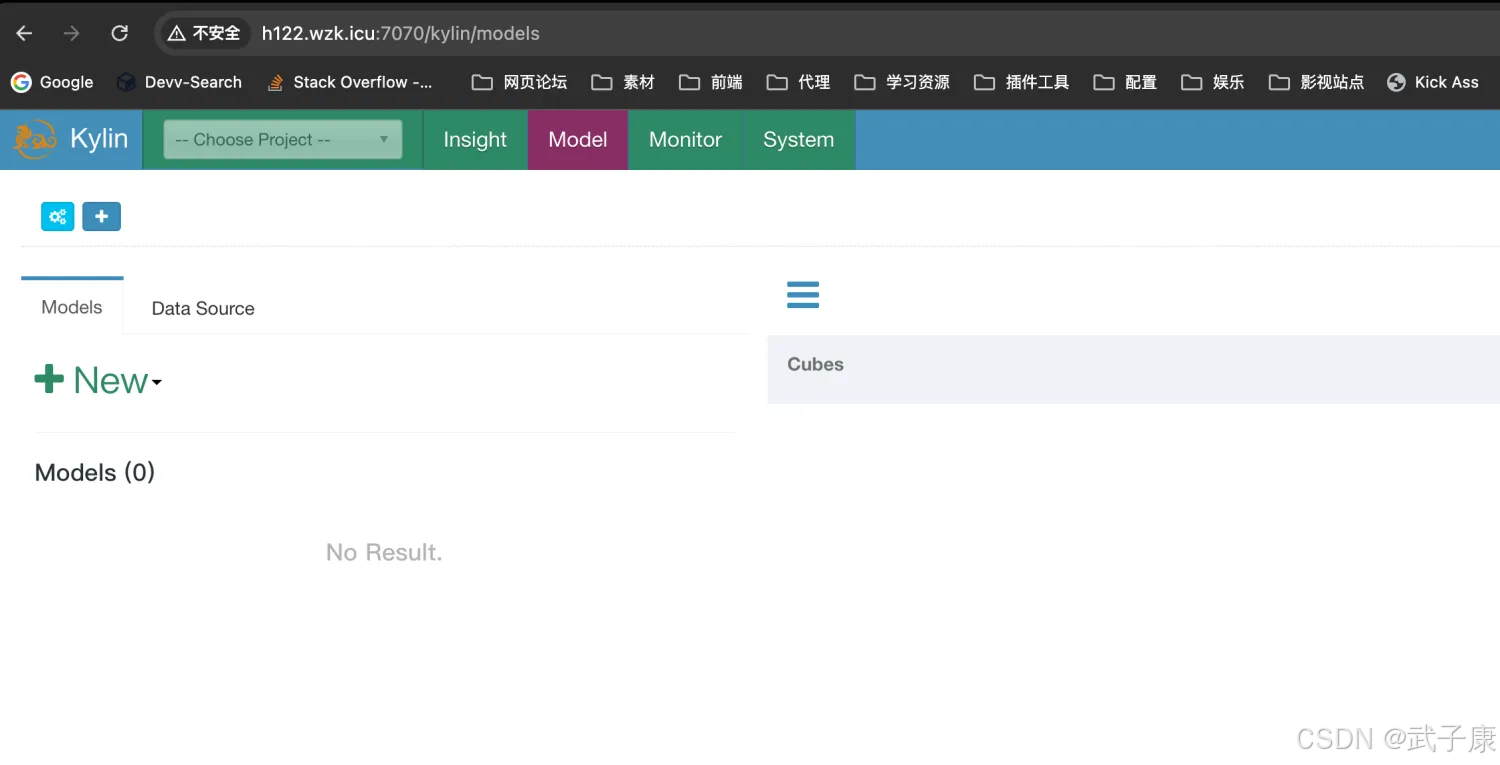
http://h122.wzk.icu:7070/kylin/login我们访问之后可以看到如下的内容:
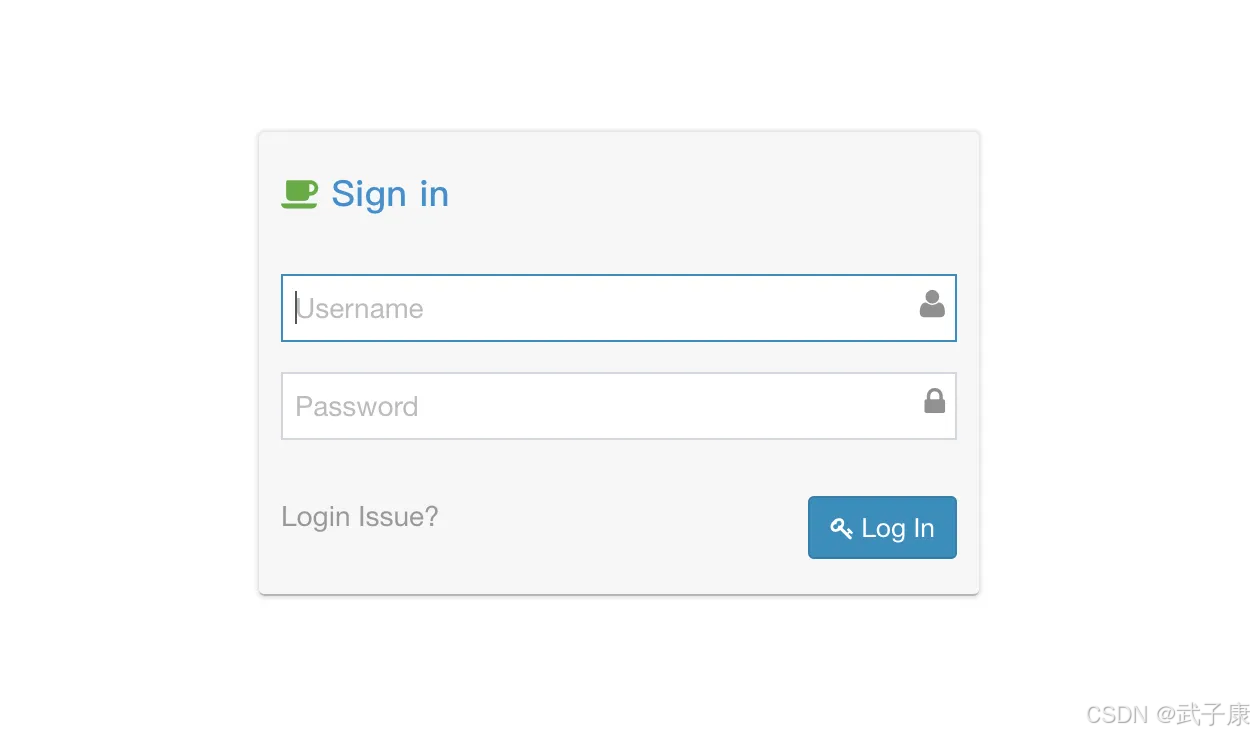
登录进入
默认都是大写账号 ADMIN密码 KYLIN登录进入之后,就是如下的结果: