0 前言
0.1 概述
2015年,深度学习三巨头Yann LeCun、Yoshua Bengio、Geoffrey Hinton在Nature杂志上发表深度学习综述论文 Deep Learning,并与2018年同时获得图灵奖,侧面展现了深度学习对当今时代带来的巨大影响。深度学习(Deep Learning, DL)是人工智能(Artificial Intelligence, AI)领域、机器学习方向(Machine Learning, ML)、人工神经网络技术(Artificial Neural Network, ANN)的主流,实际上ANN只有在深度学习时代才真正具备改变世界的能力。从数学本质上来说,深度学习技术是利用多参数函数进行万能拟合的技术,即只要参数量足够、结构合理,我们就能用函数式对任何对象进行建模。更进一步,2018年斯坦福和加州大学的研究人员在论文Polynomial Regression As an Alternative to Neural Nets中提出了NNAEPR原理,认为神经网络本质上就是多项式回归。回归思想最早开始于19世纪初提出的最小二乘法(Least Square Method, LSM),也即后来线性神经网络的原型。此外,受益于一直以来对人类思维中枢的探索和神经元机制的发现,人类在1950s年代提出了第一个可用于分类学习的人工神经网络Perception。从彼时至今70年的时间里,人工神经网络技术先坎坷前进而后飞速发展,并最终促成了Transformer架构大模型的诞生。值得重点一提的是,Transformer之前的两个技术基础分别为Encoder-Decoder 框架和 Attention 机制(改善Encoder-Decoder输出结果的机制)。
本篇文章将分类别按时间顺序梳理里程碑事件,重点将放在神经网络的起源和核心数学基础,全连接网络和BP算法,CNN,RNN,Encoder-Decoder架构,以及预训练+微调范式带来的深度学习应用。
0.2 神经网络模型分类
为提纲挈领,先将神经网络模型分类如下,其中仅涵盖代表性模型:
前馈神经网络FFN (Feed Forward Network):同一数据不二次经过任意层的网络结构 全连接神经网络FCN/密集网络Dense 线性模型:无/线性激活,应用于神经网络后成为最简单的神经网络模型。因为线性组合(linear combination)仍是线性。如果激活函数是线性,那么不管网络有多少层,都等价于一个仿射变换(affine transformation)。(仿射变换是一次线性变换,加上一个平移。像旋转、伸缩之类的,都是线性变换)。然后,仿射变换的表达能力是很弱的。很多问题,靠仿射变换解决不了。最知名的例子是XOR问题。感知机Perceotion:1958,非线性激活单层全连接,最原始的是阶跃激活多层感知机MLP:1981,非线性激活多层全连接 卷积神经网络CNN LeNet:1988年-1993年之间诞生,1993年用于展示识别手写数字,1998年Yann LeCun的论文中正式提出改进后的LeNet-5。AlexNet:2012VGG:2014NiN (Network in Network):2014GoogleNet:2014ResNet:2015,残差网络,Batch Norm批归一化DenseNet:2017,稠密连接网络 反馈神经网络(Feedback Neural Network):数据会在相同的层上迭代 时间递归神经网络:循环神经网络(Recurrent Neural Network, RNN),也是现在RNN默认所指。 门控GRU:1997雏形,2014正式提出长短期记忆网络(LSTM):1997Bi-LSTM双向:2005 空间递归神经网络:递归神经网络(Recursive Neural Network, RNN),递归神经网络作为专属名词则特指能处理树形结构的空间递归神经网络,是循环神经网络的变体,但目前较少使用,可能不太work,注意区别。 Hopfield网络:1982,单层互相全连接的反馈型神经网络。每个神经元既是输入也是输出,网络中的每一个神经元都将自己的输出通过连接权传送给所有其它神经元,同时又都接收所有其它神经元传递过来的信息。Boltzmann Machine玻尔兹曼机:1985年,Hinton,随机递归神经网络。Restricted Boltzmann Machine受限玻尔兹曼机:RBM,1986年深度信念网络 (DBN):基于玻尔兹曼机,2006年,生成式模型。 组合结构:基本神经单元的堆叠 编码器-解码器Encoder-Decoder:非简单前馈或反馈,解决Seq2seq问题的框架 变分自动编码器(VAE):2013,自动编码器学习一个输入(可以是图像或文本序列)的压缩表示,例如,压缩输入,然后解压缩回来匹配原始输入,而变分自动编码器学习表示的数据的概率分布的参数。不仅仅是学习一个代表数据的函数,它还获得了更详细和细致的数据视图,从分布中抽样并生成新的输入数据样本。生成对抗网络GAN:2014,生成模型+判别模型互相对抗,专门设计用于生成图像的网络Transformer:2017,原始Block包含Encoder-Decoder架构,但目前主流仅包含Decoder架构。详细见下一篇文章。1 人工神经网络起源:数学准备与生物神经元模型
1.1 核心数学准备
链式法则(Chain Rule)与回归(Regression)是ANN的两大数学基础,前者是BP算法的基础(链式求导),后者则是神经网络万能拟合的数学原理。其中,回归是一种用于预测因果关系的统计模型,它通常用于研究与某些因素有关的连续变量。它基于已知数据的线性或非线性方程,通过最小化误差或损失函数来拟合数据,并通过该方程对未知数据进行预测。回归模型可以用于分析多种因素对某一变量的影响,例如在经济学、社会学、医学、工程学等领域中,它经常被用于探索因果关系和预测未来趋势。常见的回归模型包括线性(Linear)回归、多项式(Polynomial)回归、对数几率(Logistic,常误译为逻辑)回归等。回归模型的起源可以追随至18世纪,成熟于19世纪,并在20世纪计算机发展的背景下被广泛应用于显示问题求解,如依托于神经网络模型。
1676年,戈特弗里德·威廉·莱布尼茨Gottfried Wilhelm Leibniz在回忆录中发表了微积分的链式法则。如今,这条规则成为了现代深度学习梯度下降技术(Gradient Descend)的基础。1757年,统计学家约翰·格拉斯哥John Graunt使用回归分析方法来探究英国人口与疾病之间的关系。1805年左右,法国科学家勒让德Legendre和德国数学家高斯Gauss独立地提出了最小二乘法的概念,为线性回归提供了数学基础。这种方法可以对数据进行拟合,并找到最适合的一条直线来表示数据之间的关系。1821年,高斯提出最大似然估计(Maximum Likelihood Estimate,MLE)。1844年,Logistic函数提出。比利时数学家Pierre François Verhulst在阅读了马尔萨斯世纪描述人口增长的模型的工作后,提出了更好描述人口增长理论的模型。他称该模型为Logsitique,区别于指数增长,当时指数的术语Logarithmique,即反函数对数。Logsitique就是今天的Logistic,Logistic函数也被称为Sigmoid函数。此外,19世纪早期,多项式回归作为线性回归的一种扩展,其基本思想已经在的统计学中得到了应用。然而,关于多项式回归这个具体术语的最早使用,可能要追溯到20世纪初或中期的统计学文献中。1855年,回归(Regression)术语正式提出。最早由英国生物统计学家弗朗西斯·高尔顿(Francis Galton)和他的学生皮尔逊在研究父母和子女的身高遗传特性时提出的。1868年,奥地利物理学家和哲学家Ludwig Boltzmann提出softmax函数,事实上,softmax函数来自于物理学和统计力学,因波尔兹曼分布和吉布斯分布而知名。1895年,皮尔逊提出了相关系数的概念,将线性回归引入统计学领域。线性回归分析(Linear Regression Analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。本质上说,这种变量间依赖关系就是一种线性相关性,线性相关性是线性回归模型的理论基础。1922年,英国的统计学家罗纳德·费舍尔(Ronald Fisher)提出了最小二乘估计的统计性质,正式命名极大似然估计,并发表了关于线性回归的经典论文。20世纪前半叶,Fisher、Neyman等人提出了一系列参数估计方法,进一步发展了线性回归模型。1960年代,提出了多元线性回归,允许模型包含多个自变量。1970年代,出现了岭回归、lasso回归、ElasticNet等正则化方法,用于处理多重共线性和特征选择问题。1990年代至今:随着机器学习和统计学的快速发展,线性回归仍然是许多预测建模和数据分析任务中的重要方法,并出现了更复杂的回归模型和非线性回归方法,如支持向量回归、决策树回归。1.2 生物神经元
生物神经元理论的发展也直接为人工神经网络提供设计灵感。
1890年,神经元特性明确,美国著名心理学家W.James关于人脑结构与功能的研究,指出神经元有四大特性。1904年,神经元之间传递信息的神经递质被提出,即神经元之间通过胆碱类等化学物质传递信息。1943年,心里学家麦卡洛克Warren McCulloch和数学逻辑学家皮兹Walter Pitts发表论文《A logical calculus of the ideas immanent in nervous activity神经活动中内在思想的逻辑演算》,提出了MP模型。MP模型是模仿神经元的结构和工作原理,构成出的一个基于神经网络的数学模型,本质上是一种“模拟人类大脑”的神经元模型,该模型将神经元简化为了三个过程:输入信号线性加权,求和,非线性激活(阈值法)。MP模型作为人工神经网络的起源,开创了人工神经网络的新时代,也奠定了神经网络模型的基础。1949年,加拿大著名心理学家唐纳德·赫布Donald Hebb在《行为的组织》中提出了一种基于无监督学习的规则——海布学习规则(Hebb’s Rule)。海布规则模仿人类认知世界的过程建立一种“网络模型”,该网络模型针对训练集进行大量的训练并提取训练集的统计特征,然后按照样本的相似程度进行分类,把相互之间联系密切的样本分为一类,这样就把样本分成了若干类。海布学习规则与“条件反射”机理一致,为以后的神经网络学习算法奠定了基础,具有重大的历史意义。2 Perception到MLP:全连接网络与BP算法的发展
1958年,美国科学家罗森布拉特Frank Rosenblatt发现了一种类似于人类学习过程的学习算法,正式提出了由两层神经元组成的神经网络,称之为感知器Perception,具有两层神经元(一层权重)和阶跃激活函数,虽然阶跃函数是非线性的,但感知器本质上是一种线性模型,可以对输入的训练集数据进行二分类,且能够在训练集中自动更新权值。感知器的提出吸引了大量科学家对人工神经网络研究的兴趣,对神经网络的发展具有里程碑式的意义。

1960,维德罗首次使用Delta学习规则(最小均方误差LMS,最小二乘法)训练感知机,大多数当代误差修正器的基本算法。
1969,马文·明斯基Minsky和西蒙·派珀特Papert共同编写了一本书籍《感知器》,对单层感知机质疑:本质是线性分类器,无法求解非线性分类问题(XOR异或问题)。由于这个致命的缺陷,在20世纪70年代,人工神经网络进入了第一个寒冬期,人们对神经网络的研究也停滞了将近20年。
1974,误差逆传播算法(Error BackPropagation),Paul J. Werbos,以自动微分的反向模型(reverse mode of automatic differentiation)为名提出,尝试改进感知机参数需要人工设定的不足,BP算法的前身,但仅仅停留在理论阶段。
1981,伟博斯Werbos提出多层感知机MLP(Multi-Layer Perceptron),突破感知机局限,可解非线性问题,层数一般8层内。请注意,多层感知机的命名由来已久,甚至可追随至19世纪之前。但一般认为1981年伟博斯在神经网络反向传播(BP)算法中具体提出多层感知机模型为正式起点。
1986,Rumelhart,Hinton和Williams联合在Nature杂志发文Learning Internal Representations by Error propagation,重新提出反向传播BP(Backpropagation)算法,自动求解MLP最优参数组合,并采用Sigmoid进行非线性映射,有效解决了非线性分类和训练的问题。BP算法完美的解决了非线性分类问题,让人工神经网络再次的引起了人们广泛的关注。
1989年,John S. Bridle提出在神经网络前向传播中由softmax取代argmax,因为softmax维持了输入值的等级序列,是捷取最大值赢家通吃操作的有区分度的一般化过程。近些年来,随着神经网络广泛应用,softmax因为上述性质变得众所周知。softmax回归是logistic回归模型在多分类问题上的推广,都是在多元线性回归模型的基础上,进行一个映射。
1991年,Sepp Hochreiter在他的毕业论文中阐述了梯度消失问题,当梯度通过深度神经网络中的各层反向传播时,它们往往会变得非常小,导致较早的层训练速度非常慢或完全不训练。这个问题在循环神经网络(RNN)和深度前馈网络中尤其严重。
由于梯度问题,神经网络的研究进展停滞了十余年,直到2006年Hinton的团队提出预训练+微调。
3 RNN的发展:时间序列问题
RNN模型一般指循环神经网络(Recurrent Neural Network),如LSTM在时序向量上工作,在宏观上属于递归神经网络(Recursive Neural Network)中的时序递归,与空间递归神经网络(如波兹曼机在空间结构上递归)并列。在时间检验下,目前RNN较少指涉空间结构递归网络。
3.1 RNN理论奠基
1924年,物理学家恩斯特·伊辛(Ernst Ising)和威廉·楞次(Wilhelm Lenz)引入并分析了第一个非学习RNN架构:伊辛模型(Ising model)。它根据输入条件进入平衡状态,是第一个RNN学习模型的基础。
1972年,甘利俊一(Shun-Ichi Amari)使伊辛模型循环架构具有自适应性,Amari模型,可以通过改变其连接权值来学习将输入模式与输出模式相关联。这是世界上第一个学习型RNN。
1982年,Amari网络被重新发表,Hopfield提出了具备能量函数及网络稳定性等概念的神经网络,一般被视作RNN循环神经网络 (Recurrent Neural Network) /递归神经网络(Recursive Neural Network )的正式起源。Hopfield神经网络是一种结合存储系统和二元系统的循环神经网络。Hopfield网络也可以模拟人类的记忆,根据激活函数的选取不同,有连续型和离散型两种类型,分别用于优化计算和联想记忆。但由于容易陷入局部最小值的缺陷,该算法并未在当时引起很大的轰动。
1985年,随机循环神经网络,杰弗里·辛顿 (Geoffrey Hinton) 和特里·谢泽诺斯基 (Terry Sejnowski) 发明玻尔兹曼机Boltzmann machine,玻尔兹曼机可被视作随机过程的,可生成的相应的 Hopfield 神经网络,它是最早能够学习内部表达,并能表达和解决复杂的组合优化问题的神经网络。由于局部性和训练算法的赫布性质 (Hebbian nature),以及它们和简单物理过程相似的并行性,如果连接方式是受约束的,学习方式在解决实际问题上将会足够高效。 它得名于玻尔兹曼分布,该分布用于玻尔兹曼机的抽样函数。
1986年,受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)。后来成为深度信念网络的组成块进而流行,但并不好用。
1990年,Jeffrey Elman发表论文Finding structure in time,提出 SRNs(也叫 Elman Networks),其核心概念就是今天所熟知的循环神经网络(RNN)。
1994年,Bengio提出RNN在处理长期依赖方面的实际困难。
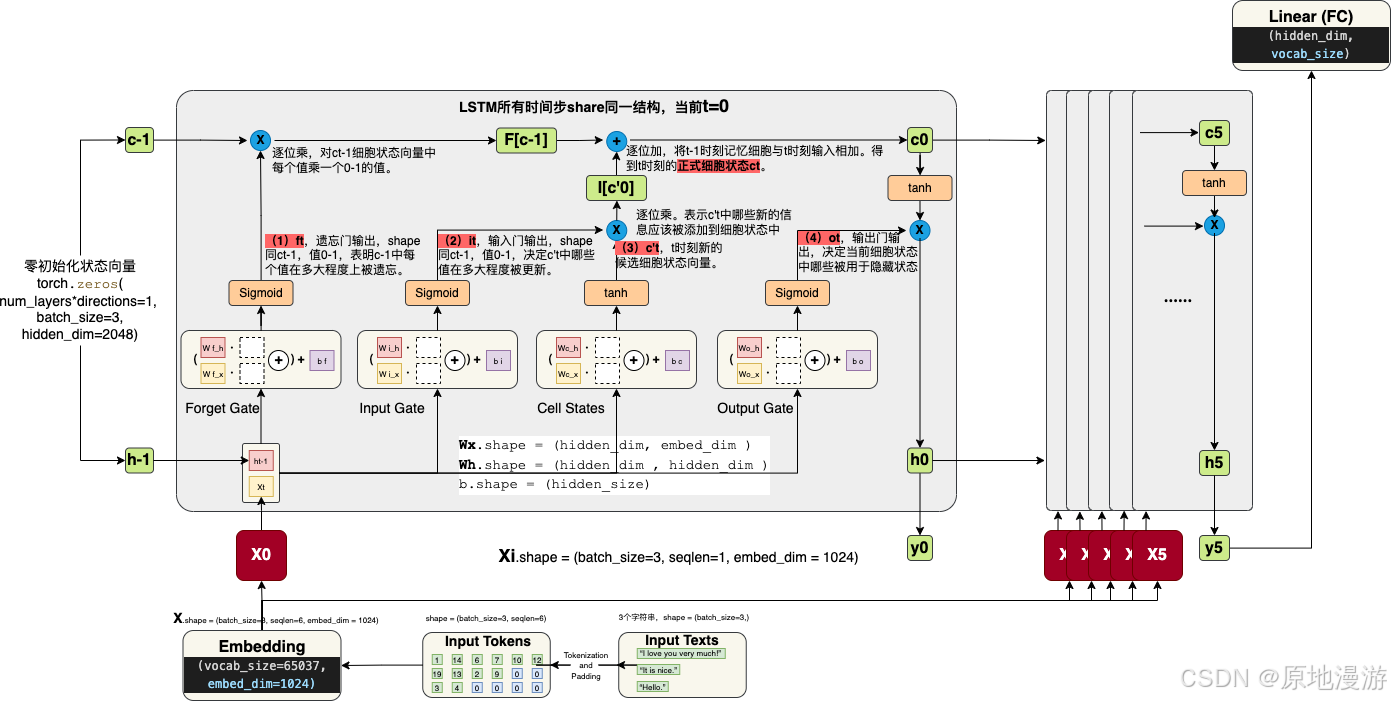
1997年,Sepp Hochreiter和Jürgen Schmidhuber在论文Long Short-Term Memory提出LSTM单元,用于解决标准循环神经网络时间维度的梯度消失问题(vanishing gradient problem)。标准的循环神经网络结构存储的上下文信息的范围有限,限制了RNN的应用。LSTM型RNN用LSTM单元替换标准结构中的神经元节点,LSTM单元使用输入门、输出门和遗忘门控制序列信息的传输,从而实现较大范围的上下文信息的保存与传输。这是首个门控循环神经网络(Gated Recurrent Neural Network,简称“门控循环神经网络”或“门循环神经网络”),它包含了一些门控机制,可以更好地捕捉时间序列数据中的长期依赖关系。但是由于当时缺乏计算能力和数据集,它并没有得到广泛应用。
1997年,论文Bidirectional recurrent neural networks与LSTM同一年提出了双向RNN(BRNN),可以通过前向和后向两个方向来训练网络,在序列学习问题上显示出了优势。
1998年,Williams和Zipser提出名为随时间反向传播(Backpropagation Through Time, BPTT)的循环神经网络训练算法。
2001年,Gers和Schmidhuber提出了具有重大意义的LSTM型RNN优化模型,在传统的LSTM单元中加入了窥视孔连接(peephole connections)。具有窥视孔连接的LSTM型RNN模型是循环神经网络最流行的模型之一,窥视孔连接进一步提高了LSTM单元对具有长时间间隔相关性特点的序列信息的处理能力。
2005年,Graves在论文Framewise phoneme classification with bidirectional LSTM and other neural network architectures中提出了将LSTM与BRNN结合到一起,成为双向LSTM(BLSTM)。相比较于BRNN,BLSTM可以更好的处理梯度消失和爆炸的问题,因此可以获得上下文相关的长时信息。然而,这时的BLSTM是一个浅层的网络。
2007年,Hochreiter将LSTM型RNN应用于生物信息学研究。
3.2 深度学习背景下的RNN
2013年,Graves和Hinton在论文Speech recognition with deep recurrent neural networks中提出了深层的BLSTM(DBLSTM),可以更好的对特征进行提取和表示,效果相比较于BLSTM也更加优越。随后的几年,学者们将DBLSTM应用到语音,图像等领域,获得了优越的效果。2014年,由Cho等人引入的简化版门控循环单元(Gated Recurrent Unit, GRU),它将遗忘和输入门组合成一个“更新门”。它还合并了单元状态和隐藏状态,并进行了一些其他更改。它比传统的门控循环神经网络更易于训练和实现,并且在很多任务上取得了优秀的结果。2013-2015,深层的BLSTM应用到语音,图像等领域,获得了优越的效果。如Graves A等人2013年的Hybrid speech recognition with deep bidirectional LSTM,Fan Y等人2014年的TTS synthesis with bidirectional LSTM based recurrent neural networks,Huang Z等人2015年的Bidirectional LSTM-CRF models for sequence tagging,.2014年6月24日,Google DeepMind发表论文Recurrent Models of Visual Attention,使得注意力机制(Attention Mechanism)开始受到广泛关注。该论文采用了循环神经网络(RNN)模型,并集成了注意力机制来处理图像分类任务,开创了将注意力机制应用于深度学习模型的先河。4 CNN的发展:空间建模问题
4.1 CNN理论奠基
1962,Hubel-Wiese生物视觉模型,CNN雏形。1979,福岛邦彦(Kunihiko Fukushima)在STRL开发了一种用于模式识别的神经网络模型:Neocognitron,这是首个使用卷积和下采样的卷积神经网络(CNN)计算模型雏形。1987年,Alex Waibel将具有卷积的神经网络与权值共享和反向传播相结合,提出了延时神经网络(TDNN)的概念。1989年,Yann LeCun等人发表论文Backpropagation Applied to Handwritten Zip Code Recognition反向传播应用于手写邮政编码识别,使用BP算法训练卷积神经网络(CNN)用于手写数字识别。1993年,Yann LeCun向大家展示了当时世界上第一个可以快速准确识别手写数字的卷积网络,LeNet。据LeCun自己的介绍,LeNet 于1988年至1993年,诞生自新泽西州霍姆德尔(Holmdel)贝尔实验室的自适应系统研究部门。他协助开发的银行支票识别系统读取了20世纪90年代末至21世纪初全美国超过10%的支票。1998年,Yann LeCun等人发表论文Gradient-based learning applied to document recognition,改进了之前的CNN,提出了LeNet-5,专为MNIST 数据集手写数字识别而设计,LeNet-5 引入了卷积、池化和激活函数的使用等关键概念,这些概念已成为现代深度学习和当代卷积神经网络的雏形。早期CNN中最有代表性之一,这篇论文也是CNN领域第一篇经典之作。使用pooling层和全连接层来简化网络结构4.2 深层CNN
2011年末,Schmidhuber的团队大大加快了深度CNN的训练速度,使其在机器学习社区中变得更加流行。团队推出基于GPU的CNN:DanNet,比早期的CNN更深入、运算更快。同年,DanNet成为第一个赢得计算机视觉竞赛的纯深度CNN。2012年,在著名的ImageNet图像识别大赛中,杰弗里·辛顿和另外两名学生Alex Krizhevsky采用深度学习模型AlexNet一举夺冠。AlexNet采用ReLU激活函数、Dropout层和LRN(Local Response Normalization,局部响应归一化)层,从根本上解决了梯度消失问题,并采用GPU极大的提高了模型的运算速度。AlexNet展示了卷积神经网络 (CNN) 的强大功能,并标志着计算机视觉的转折点,普及了深度学习技术。2013年12月19日,Google DeepMind发表论文Playing Atari with Deep Reinforcement Learning,提出了Deep Q-Network (DQN),将深度学习与强化学习相结合。DQN通过使用卷积神经网络 (CNN) 估计Q值,成功在Atari游戏中实现了超越人类的表现。DQN对人工智能和自动化控制系统产生了深远影响。2014,提出了VGGNet,它通过堆叠更多的卷积层和池化层,提出了简化网络结构的路径,并在ImageNet数据集上取得了显著的成功。2014年,VGGNet模型通过堆叠更多的卷积层和池化层,提出了简化网络结构的路径,并在ImageNet数据集上取得了显著的成功,获得2014年ILSVRC竞赛的第二名,第一名是GoogLeNet,但效果并不好。此外,**NiN(Network in Network)**也是2014年提出的一种深度学习模型,它通过串联多个由卷积层和全连接层构成的小网络来构建一个深层网络。NiN模型的主要创新在于引入了NiN块(由一个CNN层和两个1x1卷积层组成的块)以及全局平均池化层,这些设计显著减少了模型的参数量并提高了模型的非线性拟合能力。Facebook基于深度学习技术的DeepFace项目,在人脸识别方面的准确率已经能达到97%以上,跟人类识别的准确率几乎没有差别。这样的结果也再一次证明了深度学习算法在图像识别方面的一骑绝尘。2015年5月18日,Ronneberger等人发表论文U-Net: Convolutional Networks for Biomedical Image Segmentation,提出了U-Net,U-Net采用对称的U形架构,通过跳跃连接融合不同层次的特征信息,实现高精度的分割。其设计有效解决了小样本问题,广泛应用于医学影像分析、遥感图像处理等领域,对图像分割任务的发展产生了深远影响。2015年12月10日,Microsoft Research的4位学者何凯明等人发表论文Deep Residual Learning for Image Recognition,提出了ResNet(残差网络),展示了一种通过残差连接解决深层神经网络训练难题的方法。ResNet在ILSVRC 2015竞赛中获得冠军,显著提高了深度学习模型的性能和可训练性。其创新架构允许构建更深的网络,推动了图像识别、目标检测等计算机视觉任务的发展,成为深度学习领域的重要基石。Schmidhuber 表示,ResNet是其团队研发的高速神经网络(Highway Net)的一个早期版本。相较于以前的神经网络最多只有几十层,这是第一个真正有效的、具有数百层的深度前馈神经网络。2015年,YOLO系列发布,主打快速反应。因其性能强大、消耗算力较少,至今仍是实时目标检测领域的主要范式。2017,DenseNet,Densely Connected Convolutional Networks,CVPR2017 的 oral,一般而言,为提升网络效果,研究者多从增加网络深/宽度方向着力。但 DenseNet 另辟蹊径,聚焦于特征图的极致利用。延续借助跳层连接解决梯度消失 (如 ResNet) 的思路,论文提出的 Dense Block 将所有层直接相连 (密集连接),保证特征信息最大程度的传输利用,大幅提升网络性能。5 Encoder-Decoder框架:生成式模型与seq2seq任务
机器学习模型可以分为判别式模型(Discriminative Model)和生成式模型(Generative Model),前者学习样本到标签的映射即直接学习条件概率分布P(Y|X),后者学习样本数据内部联合概率分布P(X,Y)。LLMs就是典型的生成式模型(学习语言token的联合分布)。自编码器是典型的生成式模型,无标签半监督,采用Encoder-Decoder架构,可以理解为一个试图去还原其原始输入的系统。
自编码器的主要组成部分有三个:编码器、潜在特征表示和解码器。一般来说,我们希望自编码器能够很好地重建输入。同时,它还应该创建一个有用且有意义的潜在表示。在基于神经网络的自编码器中,输出层的激活函数起着特别重要的作用。最常用的函数是ReLU和Sigmoid。由于自编码器试图解决回归问题,最常用的损失函数是均方差(MSE)。主流是前馈自编码器(Feed-Forward Autoencoder,FFA)是由具有特定结构的密集层组成的神经网络。重构误差 (RE) 是一个度量,它指示了自编码器能够重建输入观测值 x_i 的好坏。最典型的 RE 应用是 MSE。这很容易计算出来。在使用自编码器进行异常检测时,常常用到 RE。对于重建误差有一个简单的直观解释。当 RE 值较大时,自编码器不能很好地重构输入信号,当 RE 值较小时,重构是成功的。
1986 年,Rumelhart、Hinton 和 Williams 首次提出了自编码器(Auto Encoder, AE),旨在学习以尽可能低的误差重建输入观测值 x_i。1993年,Geoffrey Hinton发表论文Autoencoders, minimum description length and Helmholtz free energy,发表了关于自编码器(Autoencoders)的研究。2006,Baldi等人提出最初自编码器(Early Autoencoders),这些模型主要用于无监督学习和数据压缩2009年,Bengio等人提出深度自编码器(Deep Autoencoders):随着深度学习的发展,这些模型通过多层神经网络实现了更高的表示能力。2010年,Burger等人提出卷积自编码器(Convolutional Autoencoders),这些模型特别适用于图像数据的压缩和特征学习。2013年12月20日,Kingma和Welling发表论文Auto-Encoding Variational Bayes,提出了变分自编码器(VAE),展示了一种结合贝叶斯推理和深度学习的生成模型。VAE通过编码器-解码器结构学习数据的潜在表示,并能够生成新样本。VAE在图像生成、异常检测、数据压缩等领域取得显著成果。其创新方法为生成模型提供了概率框架,推动了深度学习在生成任务中的应用和发展。2014年6月10日,Ian Goodfellow等人发表论文Generative Adversarial Nets提出生成对抗网络(GAN),在图像生成、图像修复、超分辨率等领域取得了显著成果,为生成模型带来了新的方向。它们通过一对网络(生成器和判别器)实现数据生成和模型学习。自编码器在GAN的设计中发挥着重要作用。6 预训练+微调范式:开启深度学习时代
6.1 预训练+微调的提出
2003年,LeCun成为纽约大学教师,Hinton成为加拿大高等研究院(Canadian Institute forAdvanced Research,简称CIFAR)神经计算和自适应感知项目(NeuralComputation andAdaptive Perception,简称NCAP)的带头人。该项目由来自加拿大和其他国家的约25位研究人员组成,专注于解决机器学习的难题。三巨头在该项目中共同主导了神经网络的复兴。2003年,Bengio正式将Embedding的形式被确定为神经网络模型,同时预训练+微调范式被发现。 Bengio在论文A neural probabilistic language model中提出神经网络语言模型NNLM ,统一NLP特征形式为Dense Embedding。通过线性变换压缩,当一个n长度的词表中的每个词都被映射到m维度的空间中,必然会导致向量在一些维度上同时存在值,可以使用举例算法计算similarity。并首次观察到预训练的作用。Bengio在神经网络语言模型中首次观察到,先在一个大型数据集上进行无监督的预训练,得到一个具有强泛化能力的模型,然后在具体的任务上进行有监督的微调。这种方法属于基于模型的迁移学习(Parameter/Model-based Transfer Learning),可以有效地利用已有的知识和数据。分解损失函数,有效缓解了梯度问题,深度学习拉开序幕。 2006年,杰弗里·辛顿以及他的学生鲁斯兰·萨拉赫丁诺夫正式提出了深度学习的概念。 Geoffrey Hinton等人发表论文A Fast Learning Algorithm for Deep Belief Nets,提出深度信念网络(DBN)。这篇论文被认为是近代的深度学习方法的开始。与传统的训练方式不同,深度信念网络有一个**预训练(pre-training)的过程,这可以方便地让神经网络中的权值找到一个接近最优解的值,之后再使用微调”(fine-tuning)**技术来对整个网络进行优化训练。这种分阶段两部训练技术的运用大幅度减少了训练多层神经网络的时间。深度信念网络正是深度学习爆发前夕重要的研究成果之一。他们在世界顶级学术期刊《科学》发表的一篇文章Reducing the Dimensionality of Data with Neural Networks神经网络减少数据维度,提出深度自编码器。以上这两篇论文都提出深层网络训练中梯度消失问题的解决方案:逐层贪心预训练,即通过无监督预训练对权值进行初始化+有监督训练微调。该深度学习方法的提出,立即在学术圈引起了巨大的反响,以斯坦福大学、多伦多大学为代表的众多世界知名高校纷纷投入巨大的人力、财力进行深度学习领域的相关研究。而后又在迅速蔓延到工业界中. 2006年,NVIDIA 推出 CUDA框架,利用 GPU 的并行处理能力,将 GPU 用作通用并行计算设备,以加速各种计算任务,而不仅限于图形处理。CUDA框架大大提升了深度学习算法的效率。2009年,辛顿(Hinton)和他的两名学生使用多层神经网络在语音识别方面取得重大突破。随后2011年IBM沃森在电视节目《危险边缘》中战胜人类辩手,苹果公司将Siri整合到iPhone4S中。2012年,Yann LeCun的文章依然在顶会CVPR上发表困难,甚至惨遭拒稿。审稿人表示他的论文结果存疑。同年,LeCun 和 Bengio 共同创办了ICLR(International Conference on Learning Representations,国际学习表征会议),目前已成为机器学习三大会议之一,希望为深度学习提供一个专业化的交流平台。2013年,其他两类任务的成果,带动了NLP领域的预训练实践。Word2Vec是首个采用大规模语料预训练的Dense Embedding模型。2014年9月1日,Dzmitry Bahdanau、KyungHyun Cho 和 Yoshua Bengio 发表论文Neural Machine Translation by Jointly Learning to Align and Translate,将注意力机制(Attention Mechanism)引入机器翻译,以提高长序列处理能力。它在机器翻译的历史中标志着一个重要的转折点。2015年-2016年,Google,Facebook相继推出TensorFlow、PyTorch 和 Keras,极大地促进了深度学习研究和应用的发展,使得复杂的神经网络模型的开发和训练变得更加便捷和高效。2016年,随着谷歌公司基于深度学习开发的AlphaGo以4:1的比分战胜了国际顶尖围棋高手李世石,深度学习的热度一时无两。后来,AlphaGo又接连和众多世界级围棋高手过招,均取得了完胜。这也证明了在围棋界,基于深度学习技术的机器人已经超越了人类。2017年,基于强化学习算法的AlphaGo升级版AlphaGo Zero横空出世。其采用“从零开始”、“无师自通”的学习模式,以100:0的比分轻而易举打败了之前的AlphaGo。除了围棋,它还精通国际象棋等其它棋类游戏,可以说是真正的棋类“天才”。此外在这一年,深度学习的相关算法在医疗、金融、艺术、无人驾驶等多个领域均取得了显著的成果。所以,也有专家把2017年看作是深度学习甚至是人工智能发展最为突飞猛进的一年。2017年,Google Brain发表了Attention is All You Need,提出了Transformer,彻底放弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)结构,转而完全采用注意力机制来执行机器翻译任务。这一创新犹如火星撞地球一般迅速横扫了整个自然语言处理学术界。彻底改变了自然语言处理(NLP)领域。对后续的BERT、GPT等模型产生了深远影响。2018,承上启下。一方面传统NLP达到了巅峰,代表作品是两个动态词向量模型(1)Allen AI2提出的ELMo,本质是Bi-RNN;(2)Fast.ai+DeepMind合作提出的ULMFit。另一方面,Google和OpenAI分别推出首代BERT和GPT模型,自然语言处理技术推进到新的时代。6.2 深度学习时代背景:三大革命与三大巨头
21世纪深度学习的爆发并不是偶然现象,反而具备深刻的时代背景因素,即算法、数据、算力三大革命:
算法革命:人工神经网络变体不断涌现,如卷积神经网络、循环神经网络、长短期记忆网络等,其中深度学习三巨头在算法革命中做出了无匹的贡献。Transformer架构之前主流是RNN、CNN,前者善于处理时间序列,后者善于空间关系。数据革命:随着互联网的快速发展,人类进入了大数据时代,提供了大量数据源与高效标注工具与平台,由此产生了许多高质量公开数据集,为人工智能的发展提供了广阔的应用空间,包括:(1)用户上网产生海量行为数据:比如购物网站浏览、收藏、购买数据,社交网站关注、点赞、评论数据,视频网站浏览、观看、付费数据。这为人工智能在互联网企业的大规模应用提供了肥沃的土壤。
(2)移动互联图像数据:智能手机支持随手拍照并分享到网络,出现了图像识别、图像分割等需求,同时CIFAR、ImageNet、VisualQA等大型的图像数据集开始出现,推动深度学习图像处理算法的快速演进。
(3)内容平台产生大量文本数据:新闻媒体每天各语种的新闻报道,自媒体平台产生大量文本作品,维基百科等记载大量结构化知识。这为自然语言算法的研究和应用提供了广阔的天地。算力革命:新的软硬件平台的出现,催生了算力革命。大数据量处理推动算力的革命,推动了GPU集群、大数据集群乃至专用的AI芯片的大踏步发展。算力提升拓宽了算法的探索空间,强化学习、AUTOML等算力密集型的算法不断取得突破。其中代表性的突破有:
(1)大数据集群(CPU集群):2004年谷歌推出了分布式文件系统(GFS)、分布式计算框架(MapReduce),2006年Doug Cutting推出基于谷歌技术改进的Hadoop,2010年,Facebook 推出大数据分析工具 Hive。2012年,UC 伯克利推出替代MapReduce的Spark。至此,大数据处理形成了完整的技术框架
(2)图形处理器(GPU):GPU原本主要用于图形图像的渲染,2006年,英伟达(NVIDIA)推出CUDA (统一计算架构) ,GPU开始用于解决商业、工业以及科学方面的复杂计算,GPU与深度学习结合,模型的训练速度有了数量级的提升。CPU和GPU的架构如右图:CPU有更多控制单元,而GPU将更多的晶体管用于数据处理。
深度学习三位大牛:Bengio、Hinton、Yann LeCun,在AI寒冬依然坚持深耕,2018同获图灵奖,传为一桩美谈。
约书亚·本吉奥(Yoshua Bengio):1964年3月5日出生于法国巴黎,2018年图灵奖得主,英国皇家学会院士,蒙特利尔大学教授,Element AI联合创始人。
2003年开创神经语言模型NNLM,将语言模型的形式确定为Dense Embedding。2014年与伊恩·古德费洛(Ian Goodfellow)合作研发的生成对抗网络(Generative Adversarial Networks ,简称GAN),引发了计算机视觉和计算机图形学的革命。带领开发出Theano框架和Word2Vec的雏形。启发了Tensorflow等众多后续框架的发展,创办AI顶会ICLR。他也是权威教材《深度学习》一书的合著者。是神经网络复兴的主要的三个发起人之一,提出了包括pretraining的问题,如何initialize参数的问题,以de-noising auto-encoder为代表的各种各样的auto-encoder结构,Generative model等等。
杰弗里·辛顿(Geoffrey Hinton):1947年12月6日出生于英国,2018年图灵奖得主,2016年至2023年担任谷歌副总裁兼工程研究员。神经网络之父,机器学习子领域深度学习之父,我一直以来都确信,实现人工智能的唯一方式,就是按人类大脑的方式去进行计算。
1986年发明了受限玻尔兹曼机RBM。将反向传播算法BP应用于多层神经网络。2006年提出深度信念网络DBN和逐层预训练(逐层贪婪训练受限玻尔兹曼机)培养了杨乐昆等一众大牛级学生。推动谷歌的图像和音频识别性能大幅提升。
杨立昆(Yann LeCun):1960年出生于法国巴黎附近,担任Facebook首席人工智能科学家和纽约大学教授,2018年图灵奖(Turing Award)得主。我们之所以为人,是因为我们具有智能,而人工智能是这一能力的扩展。
CNN之父(不发明,但首个将BP算法用于CNN),1989年使用反向传播和神经网络识别手写数字,用来读取银行支票上的手写数字,首次实现神经网络商业化,1998 ,提出LeNet5卷积神经网络,是CNN早期最经典的模型。Facebook人工智能实验室负责人。
大佬们的关系网可参考深度学习&自然语言处理领域的牛人、贡献及关系网。此外,本文主要参考文章如下:
前言 — 动手学深度学习 2.0.0 documentation (d2l.ai)、从感知机到Transformer,一文概述深度学习简史 (thepaper.cn)、全网最新!| 深度学习发展史(1943-2024编年体)(The History of Deep Learning)_深度学习发展历程-CSDN博客、深度学习发展史 - 知乎 (zhihu.com)、【神经网络本质是多项式回归】Jeff Dean等论文发现逻辑回归和深度学习一样好…-CSDN博客、双向长短时记忆网络 | 机器之心 (jiqizhixin.com)