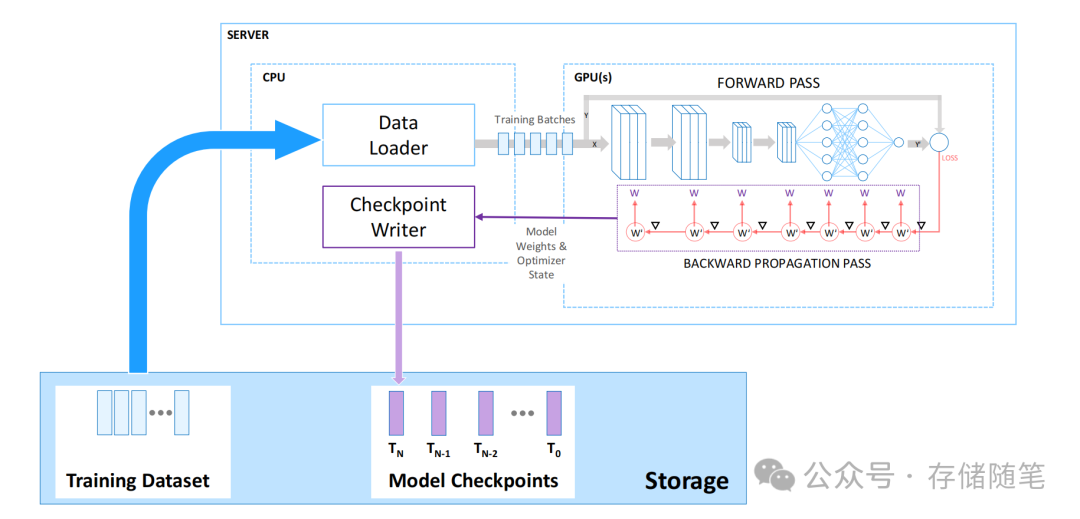
检查点(Checkpoints)是机器学习和深度学习训练过程中的一个重要机制,旨在定期保存训练状态,以便在训练过程中遇到失败或中断时能够从中断处恢复训练,而无需从头开始。
随着模型参数量的剧增,Checkpoint文件的大小也随之膨胀,传统的存储解决方案难以满足快速恢复的需求。因此,如何设计存储架构以支持快速读写Checkpoint文件,从而减少模型训练的中断时间,成为了亟待解决的技术难题。这要求存储系统不仅要有高带宽,还要能优化读写路径,减少恢复时延。
恢复训练的必要性:在复杂的模型训练过程中,可能会遇到各种意外情况,如电源故障、计算资源崩溃或人为终止等。通过定期创建检查点,可以确保即使遇到这些情况,也能从最近的一个检查点恢复训练状态,而不是从头开始,从而节省大量时间和计算资源。
检查点内容:检查点主要包含两部分重要信息:
学习到的模型权重:这是模型训练的核心成果,代表了模型当前对数据的理解和拟合程度。
优化器状态信息:除了模型参数外,还包括了优化器的状态,如动量(momentum)、学习率计划等,这对于恢复训练后继续沿用之前的优化策略至关重要。
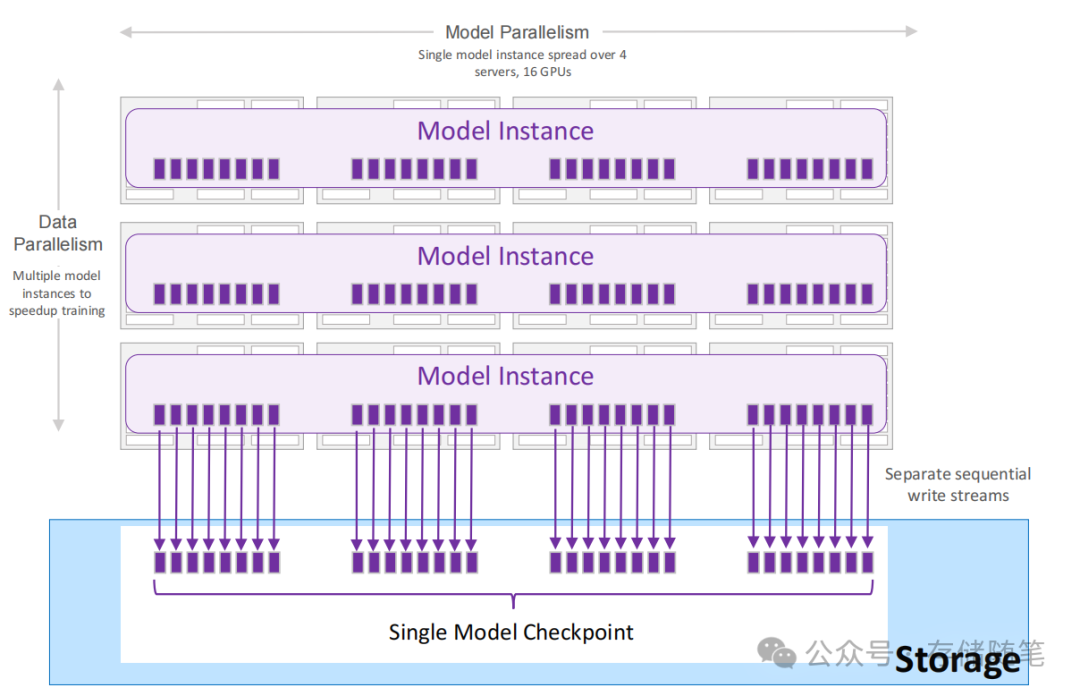
文件存储方式:检查点的存储形式可以根据实际需求和实现方式有所不同,可能是一个或多个文件。这种灵活性适应了不同的模型并行化策略(如模型并行、数据并行)和技术实现。例如,在模型并行场景中,每个模型的部分可能需要单独保存为一个文件;而在数据并行训练中,由于所有GPU上的模型实例理论上是相同的,通常只需要保存一个实例的模型权重。
写入机制:每个检查点文件是由单个写入器顺序写入的,这有助于保持文件的完整性和一致性,避免并发写入可能导致的数据损坏问题。
数据并行训练中的效率考虑:在数据并行的设置下,由于所有GPU上运行的是模型的相同副本,只需保存一个GPU上的模型实例即可,无需为每个GPU都保存一份完整的内存状态。这样做大大减少了存储空间的需求,并提高了效率。
检查点对训练暂停的影响:由于保存检查点需要将模型状态写入磁盘,这一过程可能会暂时占用计算资源,特别是GPU,导致训练暂停或GPU利用率下降。因此,快速完成检查点的保存操作对于维持整体训练效率非常重要。为了减少这种影响,实践中可能会采用异步保存机制或优化I/O操作来加速检查点的生成和存储过程。
存储考量:考虑到检查点文件可能非常大,尤其是在处理大规模模型时,有效的存储管理变得尤为重要。这包括但不限于使用高效的压缩算法减小文件大小、定期删除旧的或不必要的检查点以释放存储空间,以及可能利用分布式存储系统来提高访问速度和可靠性。
模型的大小直接决定了检查点文件的体积。大型模型,尤其是深度学习领域中的许多现代架构,可能包含数百万乃至数十亿个参数。这些参数在形成检查点时需要被序列化并写入存储介质,因此模型越大,所需的存储空间越多,进而要求更高的写入带宽以确保检查点能够及时完成保存。同时,模型参数的数量直接影响到检查点文件的大小。参数越多,写入时需要传输的数据量就越大,对存储系统的写入带宽要求自然更高。
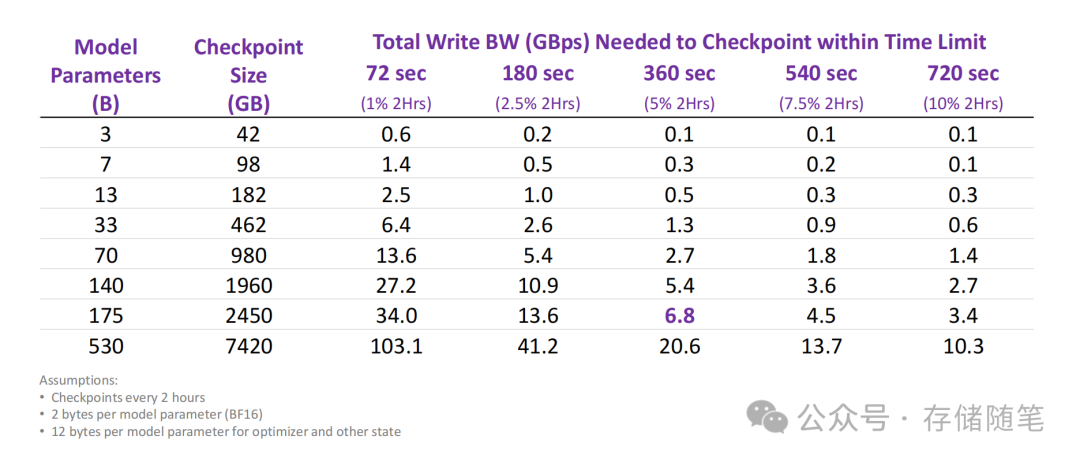
在训练过程中,通常会设定一个最大允许的检查点保存时间窗口。这个时间限制是为了最小化检查点操作对整体训练进度的影响,确保GPU或其他计算资源的高效利用。如果允许的时间很短,那么就需要极高的写入带宽来迅速完成数据的保存。允许的最大时间还影响到如何设计检查点策略及选择存储解决方案。例如,如果时间窗口很小,可能需要采用高速的SSD来增加写入速度,或者采用分块写入、异步写入等技术来优化写入流程。
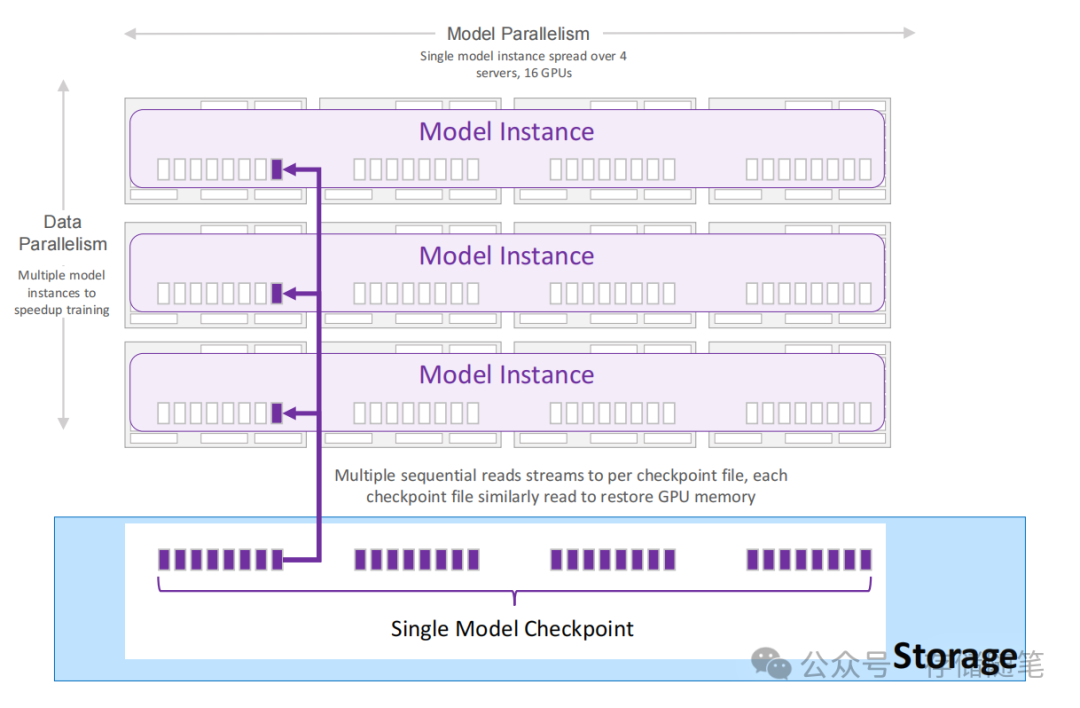
从检查点恢复训练的过程涉及到将之前保存的状态重新加载到所有参与训练的GPU上:
GPU内存重初始化:为了从之前中断的地方继续训练,每一个GPU都需要重新加载其对应的模型权重和优化器状态。这意味着必须从检查点文件中读取这些信息,并准确无误地分配给各个GPU,以确保模型状态与中断前一致。
顺序读取检查点文件:通常情况下,检查点文件是按顺序读取的,这意味着恢复过程会逐一处理这些文件,以确保模型和优化器的状态得到完整且正确的重建。
模型并行下的恢复:在采用模型并行的场景中,一个单一的检查点文件可能包含了多个GPU所需的信息。这是因为模型并行往往涉及将模型分割到不同GPU上处理,但它们共享相同的参数集。因此,这样的设计允许高效地从一个统一的源恢复所有相关GPU的状态。
数据并行与读取器数量:数据并行指的是将训练数据分割到多个GPU上并行处理同一模型的多个副本。在这种情况下,每份检查点文件可能对应于一个或多个GPU的状态。读取器的数量(即同时读取检查点文件的进程数量)取决于数据并行的程度——如果数据并行度高,即有更多的GPU参与,可能就需要更多的读取器来加速状态恢复过程。
训练启动条件:直到所有GPU的内存状态都成功从检查点中恢复,训练才能重新开始。这意味着整个恢复过程的效率直接影响到训练的连续性和总体耗时。任何GPU的恢复延迟都将阻碍整个训练任务的重启,因此优化恢复流程,确保快速且同步地完成所有GPU的状态加载,是提高系统恢复效率的关键。